 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
S-AT GCN: Spatial-Attention Graph Convolution Network based Feature Enhancement for 3D Object Detection
Mar 15, 2021
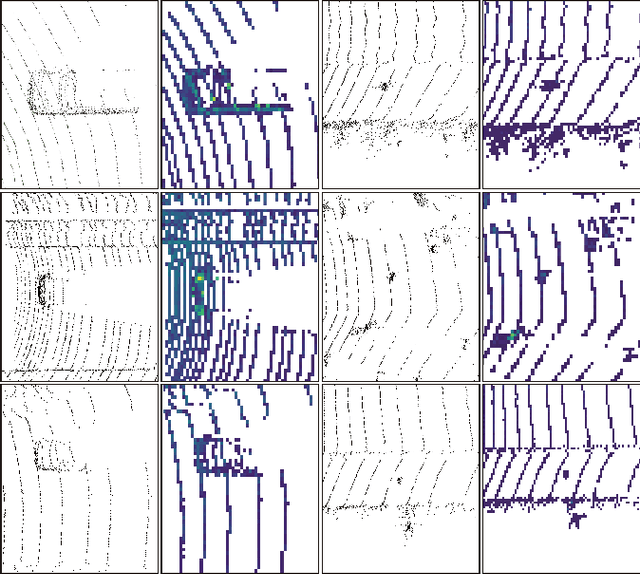
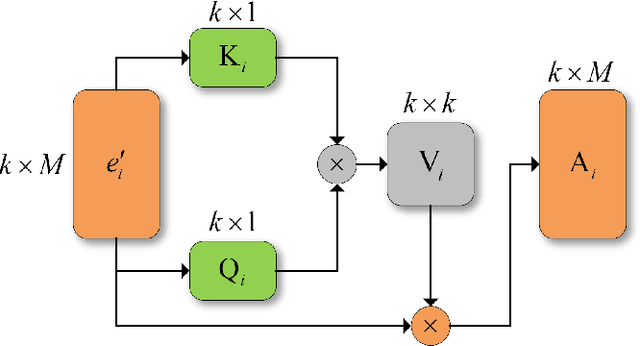
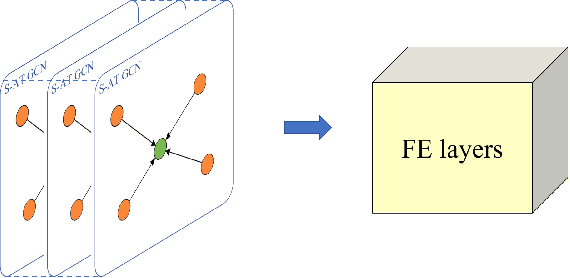
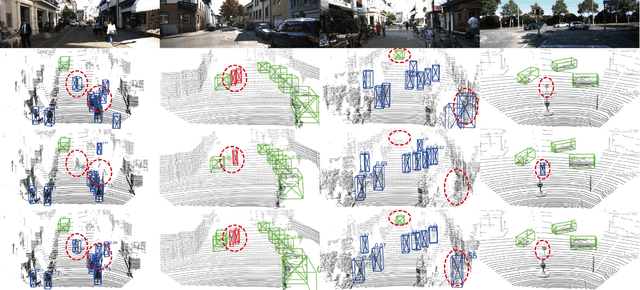
3D object detection plays a crucial role in environmental perception for autonomous vehicles, which is the prerequisite of decision and control. This paper analyses partition-based methods' inherent drawbacks. In the partition operation, a single instance such as a pedestrian is sliced into several pieces, which we call it the partition effect. We propose the Spatial-Attention Graph Convolution (S-AT GCN), forming the Feature Enhancement (FE) layers to overcome this drawback. The S-AT GCN utilizes the graph convolution and the spatial attention mechanism to extract local geometrical structure features. This allows the network to have more meaningful features for the foreground. Our experiments on the KITTI 3D object and bird's eye view detection show that S-AT Conv and FE layers are effective, especially for small objects. FE layers boost the pedestrian class performance by 3.62\% and cyclist class by 4.21\% 3D mAP. The time cost of these extra FE layers are limited. PointPillars with FE layers can achieve 48 PFS, satisfying the real-time requirement.
Dealing with training and test segmentation mismatch: FBK@IWSLT2021
Jun 23, 2021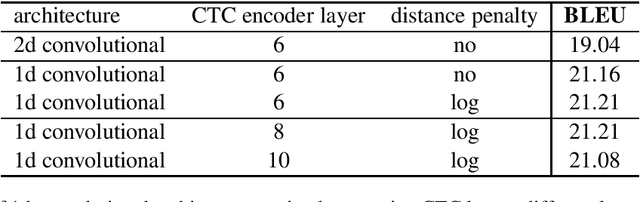

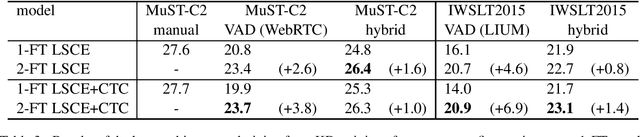
This paper describes FBK's system submission to the IWSLT 2021 Offline Speech Translation task. We participated with a direct model, which is a Transformer-based architecture trained to translate English speech audio data into German texts. The training pipeline is characterized by knowledge distillation and a two-step fine-tuning procedure. Both knowledge distillation and the first fine-tuning step are carried out on manually segmented real and synthetic data, the latter being generated with an MT system trained on the available corpora. Differently, the second fine-tuning step is carried out on a random segmentation of the MuST-C v2 En-De dataset. Its main goal is to reduce the performance drops occurring when a speech translation model trained on manually segmented data (i.e. an ideal, sentence-like segmentation) is evaluated on automatically segmented audio (i.e. actual, more realistic testing conditions). For the same purpose, a custom hybrid segmentation procedure that accounts for both audio content (pauses) and for the length of the produced segments is applied to the test data before passing them to the system. At inference time, we compared this procedure with a baseline segmentation method based on Voice Activity Detection (VAD). Our results indicate the effectiveness of the proposed hybrid approach, shown by a reduction of the gap with manual segmentation from 8.3 to 1.4 BLEU points.
Stable, Fast and Accurate: Kernelized Attention with Relative Positional Encoding
Jun 23, 2021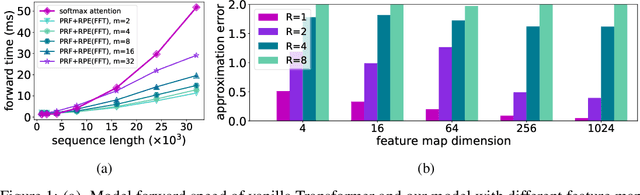


The attention module, which is a crucial component in Transformer, cannot scale efficiently to long sequences due to its quadratic complexity. Many works focus on approximating the dot-then-exponentiate softmax function in the original attention, leading to sub-quadratic or even linear-complexity Transformer architectures. However, we show that these methods cannot be applied to more powerful attention modules that go beyond the dot-then-exponentiate style, e.g., Transformers with relative positional encoding (RPE). Since in many state-of-the-art models, relative positional encoding is used as default, designing efficient Transformers that can incorporate RPE is appealing. In this paper, we propose a novel way to accelerate attention calculation for Transformers with RPE on top of the kernelized attention. Based upon the observation that relative positional encoding forms a Toeplitz matrix, we mathematically show that kernelized attention with RPE can be calculated efficiently using Fast Fourier Transform (FFT). With FFT, our method achieves $\mathcal{O}(n\log n)$ time complexity. Interestingly, we further demonstrate that properly using relative positional encoding can mitigate the training instability problem of vanilla kernelized attention. On a wide range of tasks, we empirically show that our models can be trained from scratch without any optimization issues. The learned model performs better than many efficient Transformer variants and is faster than standard Transformer in the long-sequence regime.
Evolutionary Game Theory Squared: Evolving Agents in Endogenously Evolving Zero-Sum Games
Dec 15, 2020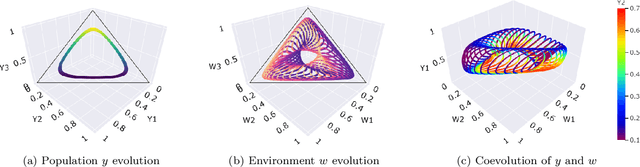
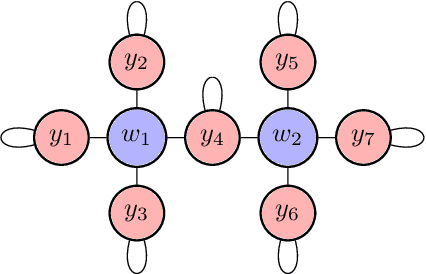
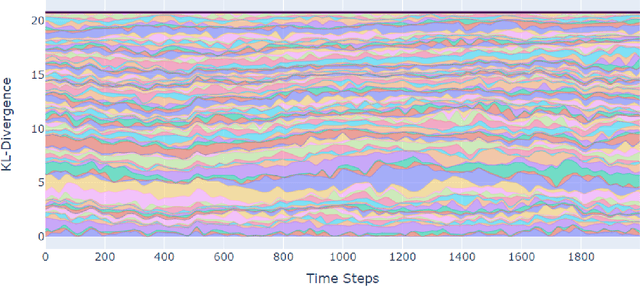
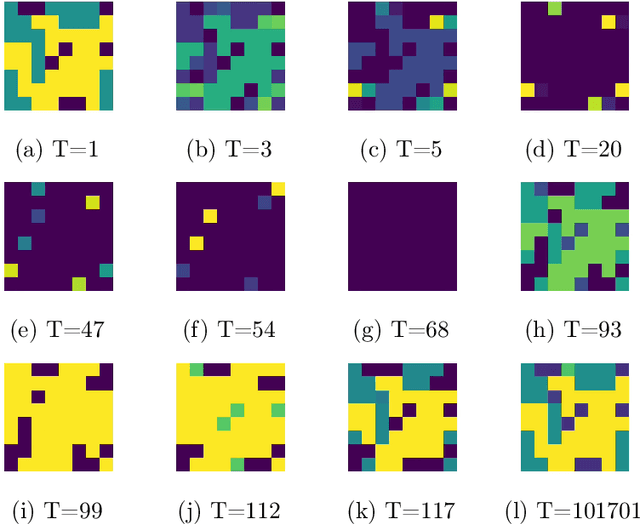
The predominant paradigm in evolutionary game theory and more generally online learning in games is based on a clear distinction between a population of dynamic agents that interact given a fixed, static game. In this paper, we move away from the artificial divide between dynamic agents and static games, to introduce and analyze a large class of competitive settings where both the agents and the games they play evolve strategically over time. We focus on arguably the most archetypal game-theoretic setting -- zero-sum games (as well as network generalizations) -- and the most studied evolutionary learning dynamic -- replicator, the continuous-time analogue of multiplicative weights. Populations of agents compete against each other in a zero-sum competition that itself evolves adversarially to the current population mixture. Remarkably, despite the chaotic coevolution of agents and games, we prove that the system exhibits a number of regularities. First, the system has conservation laws of an information-theoretic flavor that couple the behavior of all agents and games. Secondly, the system is Poincar\'{e} recurrent, with effectively all possible initializations of agents and games lying on recurrent orbits that come arbitrarily close to their initial conditions infinitely often. Thirdly, the time-average agent behavior and utility converge to the Nash equilibrium values of the time-average game. Finally, we provide a polynomial time algorithm to efficiently predict this time-average behavior for any such coevolving network game.
Scenario-Based Trajectory Optimization in Uncertain Dynamic Environments
Mar 23, 2021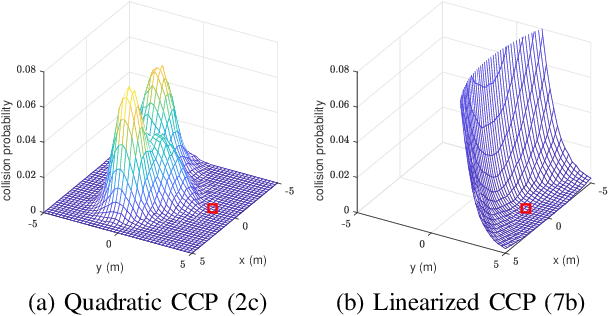
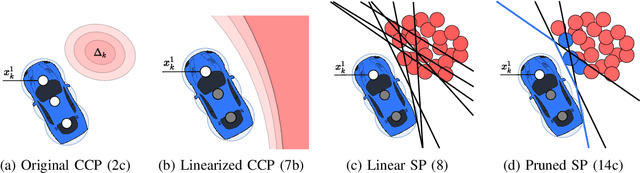
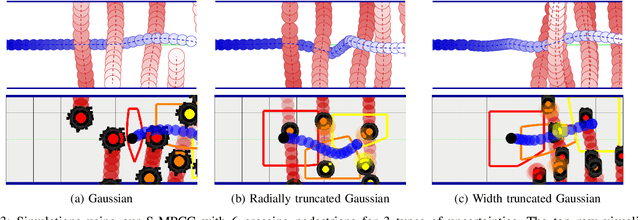
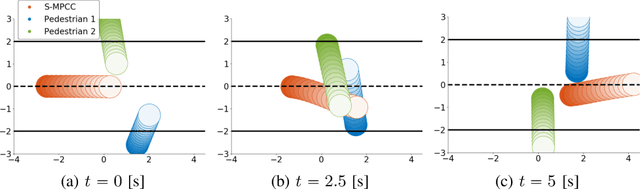
We present an optimization-based method to plan the motion of an autonomous robot under the uncertainties associated with dynamic obstacles, such as humans. Our method bounds the marginal risk of collisions at each point in time by incorporating chance constraints into the planning problem. This problem is not suitable for online optimization outright for arbitrary probability distributions. Hence, we sample from these chance constraints using an uncertainty model, to generate "scenarios", which translate the probabilistic constraints into deterministic ones. In practice, each scenario represents the collision constraint for a dynamic obstacle at the location of the sample. The number of theoretically required scenarios can be very large. Nevertheless, by exploiting the geometry of the workspace, we show how to prune most scenarios before optimization and we demonstrate how the reduced scenarios can still provide probabilistic guarantees on the safety of the motion plan. Since our approach is scenario based, we are able to handle arbitrary uncertainty distributions. We apply our method in a Model Predictive Contouring Control framework and demonstrate its benefits in simulations and experiments with a moving robot platform navigating among pedestrians, running in real-time.
Pseudo-Boolean Functions for Optimal Z-Complementary Code Sets with Flexible Lengths
Apr 20, 2021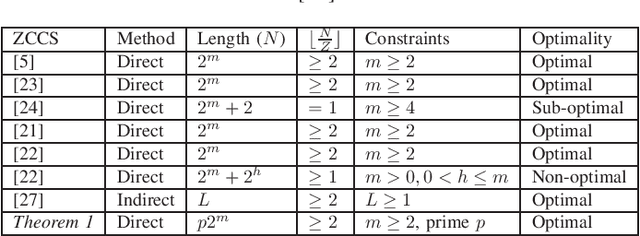
This paper aims to construct optimal Z-complementary code set (ZCCS) with non-power-of-two (NPT) lengths to enable interference-free multicarrier code-division multiple access (MC-CDMA) systems. The existing ZCCSs with NPT lengths, which are constructed from generalized Boolean functions (GBFs), are sub-optimal only with respect to the set size upper bound. For the first time in the literature, we advocate the use of pseudo-Boolean functions (PBFs) (each of which transforms a number of binary variables to a real number as a natural generalization of GBF) for direct constructions of optimal ZCCSs with NPT lengths.
Generative Self-training for Cross-domain Unsupervised Tagged-to-Cine MRI Synthesis
Jun 23, 2021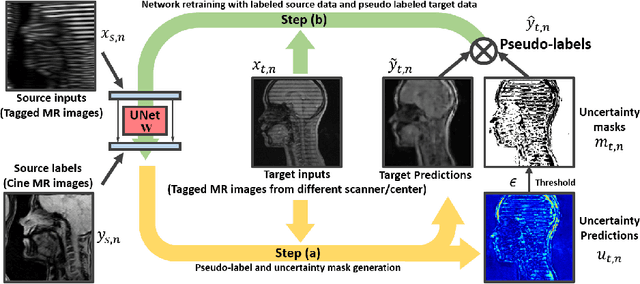
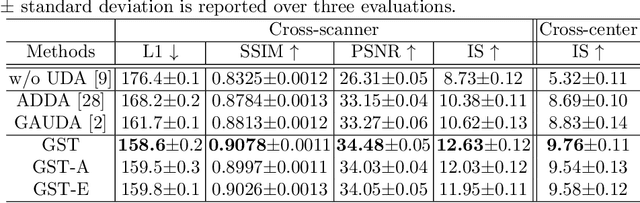
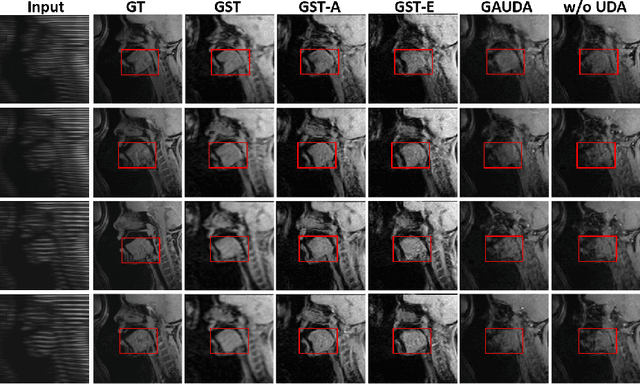
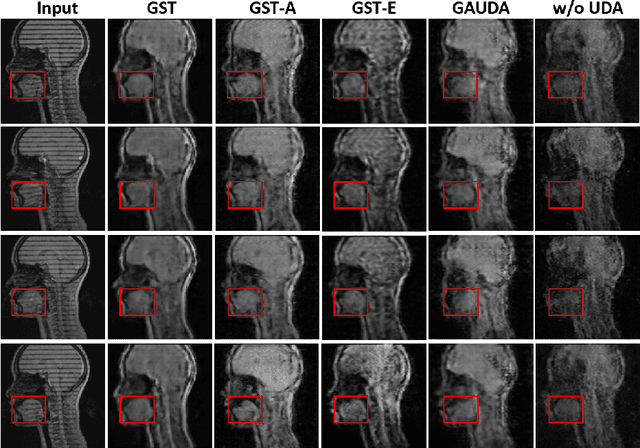
Self-training based unsupervised domain adaptation (UDA) has shown great potential to address the problem of domain shift, when applying a trained deep learning model in a source domain to unlabeled target domains. However, while the self-training UDA has demonstrated its effectiveness on discriminative tasks, such as classification and segmentation, via the reliable pseudo-label selection based on the softmax discrete histogram, the self-training UDA for generative tasks, such as image synthesis, is not fully investigated. In this work, we propose a novel generative self-training (GST) UDA framework with continuous value prediction and regression objective for cross-domain image synthesis. Specifically, we propose to filter the pseudo-label with an uncertainty mask, and quantify the predictive confidence of generated images with practical variational Bayes learning. The fast test-time adaptation is achieved by a round-based alternative optimization scheme. We validated our framework on the tagged-to-cine magnetic resonance imaging (MRI) synthesis problem, where datasets in the source and target domains were acquired from different scanners or centers. Extensive validations were carried out to verify our framework against popular adversarial training UDA methods. Results show that our GST, with tagged MRI of test subjects in new target domains, improved the synthesis quality by a large margin, compared with the adversarial training UDA methods.
SIMLR: Machine Learning inside the SIR model for COVID-19 Forecasting
Jun 03, 2021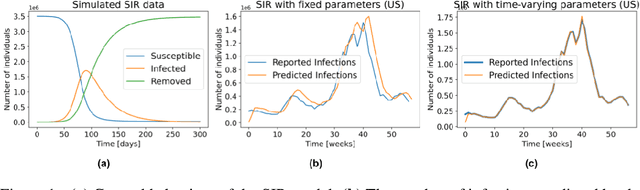
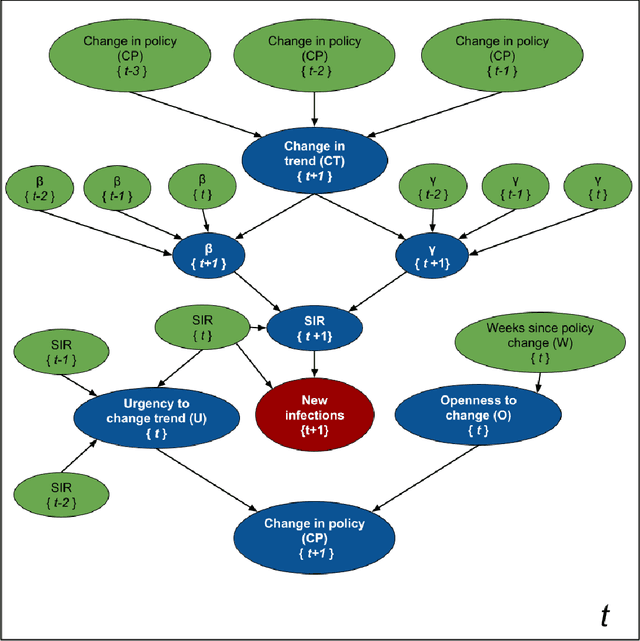
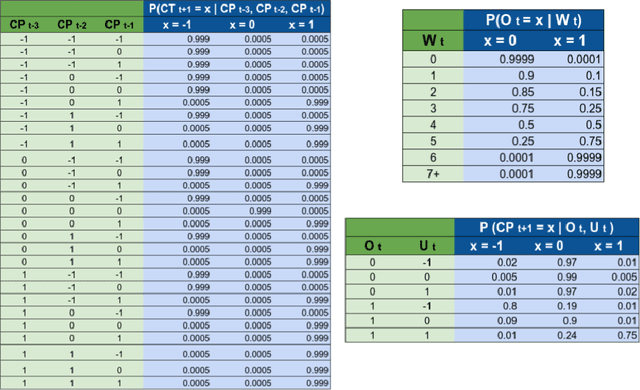
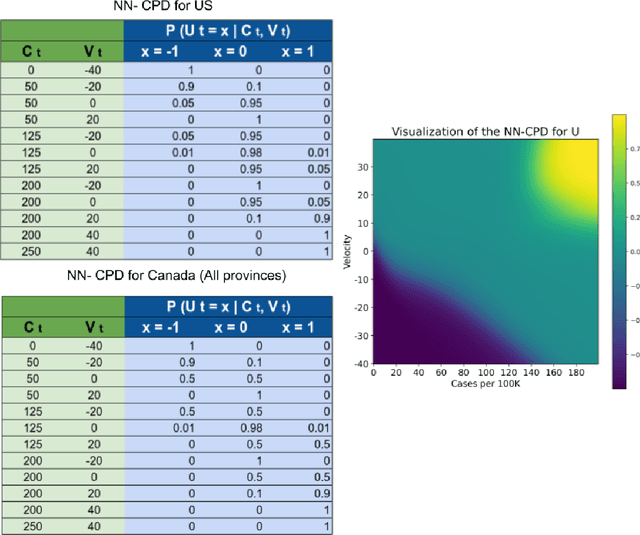
Accurate forecasts of the number of newly infected people during an epidemic are critical for making effective timely decisions. This paper addresses this challenge using the SIMLR model, which incorporates machine learning (ML) into the epidemiological SIR model. For each region, SIMLR tracks the changes in the policies implemented at the government level, which it uses to estimate the time-varying parameters of an SIR model for forecasting the number of new infections 1- to 4-weeks in advance.It also forecasts the probability of changes in those government policies at each of these future times, which is essential for the longer-range forecasts. We applied SIMLR to data from regions in Canada and in the United States,and show that its MAPE (mean average percentage error) performance is as good as SOTA forecasting models, with the added advantage of being an interpretable model. We expect that this approach will be useful not only for forecasting COVID-19 infections, but also in predicting the evolution of other infectious diseases.
A Deep Variational Approach to Clustering Survival Data
Jun 10, 2021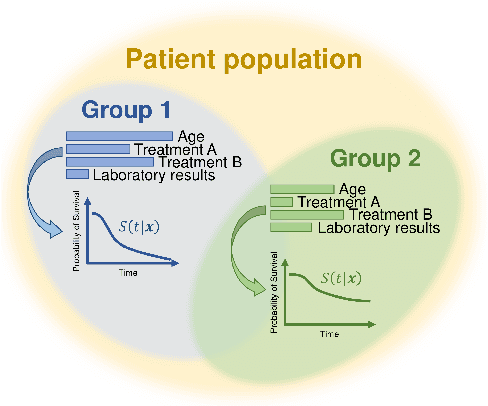
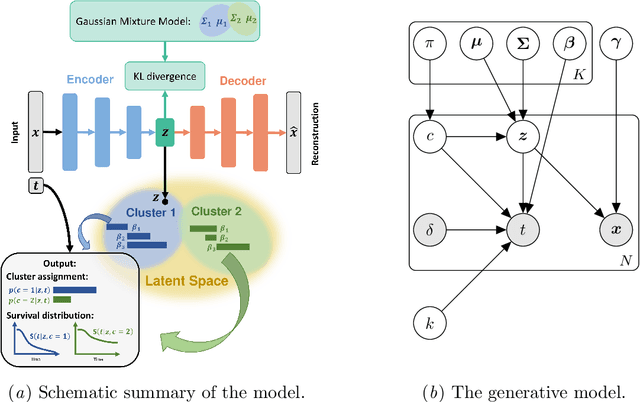
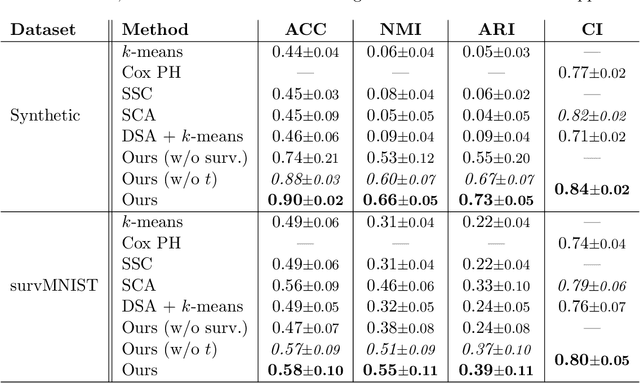
Survival analysis has gained significant attention in the medical domain and has many far-reaching applications. Although a variety of machine learning methods have been introduced for tackling time-to-event prediction in unstructured data with complex dependencies, clustering of survival data remains an under-explored problem. The latter is particularly helpful in discovering patient subpopulations whose survival is regulated by different generative mechanisms, a critical problem in precision medicine. To this end, we introduce a novel probabilistic approach to cluster survival data in a variational deep clustering setting. Our proposed method employs a deep generative model to uncover the underlying distribution of both the explanatory variables and the potentially censored survival times. We compare our model to the related work on survival clustering in comprehensive experiments on a range of synthetic, semi-synthetic, and real-world datasets. Our proposed method performs better at identifying clusters and is competitive at predicting survival times in terms of the concordance index and relative absolute error. To further demonstrate the usefulness of our approach, we show that our method identifies meaningful clusters from an observational cohort of hemodialysis patients that are consistent with previous clinical findings.
Classifying Textual Data with Pre-trained Vision Models through Transfer Learning and Data Transformations
Jun 23, 2021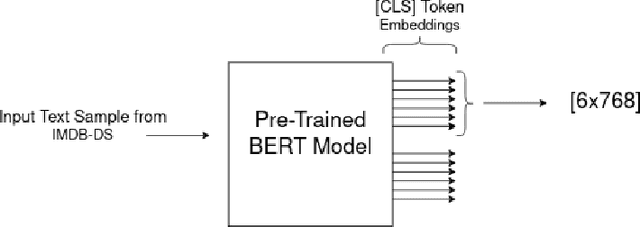


Knowledge is acquired by humans through experience, and no boundary is set between the kinds of knowledge or skill levels we can achieve on different tasks at the same time. When it comes to Neural Networks, that is not the case, the major breakthroughs in the field are extremely task and domain specific. Vision and language are dealt with in separate manners, using separate methods and different datasets. In this work, we propose to use knowledge acquired by benchmark Vision Models which are trained on ImageNet to help a much smaller architecture learn to classify text. After transforming the textual data contained in the IMDB dataset to gray scale images. An analysis of different domains and the Transfer Learning method is carried out. Despite the challenge posed by the very different datasets, promising results are achieved. The main contribution of this work is a novel approach which links large pretrained models on both language and vision to achieve state-of-the-art results in different sub-fields from the original task. Without needing high compute capacity resources. Specifically, Sentiment Analysis is achieved after transferring knowledge between vision and language models. BERT embeddings are transformed into grayscale images, these images are then used as training examples for pretrained vision models such as VGG16 and ResNet Index Terms: Natural language, Vision, BERT, Transfer Learning, CNN, Domain Adaptation.