 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Quantum Hopfield Associative Memory Implemented on an Actual Quantum Processor
May 25, 2021
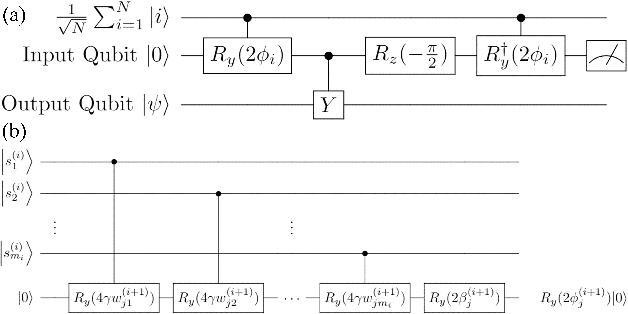

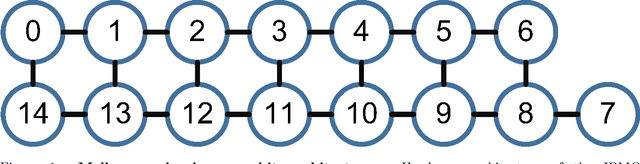
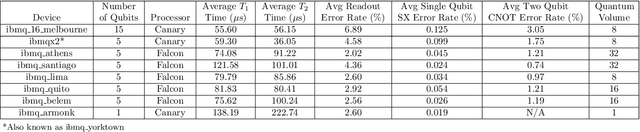
In this work, we present a Quantum Hopfield Associative Memory (QHAM) and demonstrate its capabilities in simulation and hardware using IBM Quantum Experience. The QHAM is based on a quantum neuron design which can be utilized for many different machine learning applications and can be implemented on real quantum hardware without requiring mid-circuit measurement or reset operations. We analyze the accuracy of the neuron and the full QHAM considering hardware errors via simulation with hardware noise models as well as with implementation on the 15-qubit ibmq_16_melbourne device. The quantum neuron and the QHAM are shown to be resilient to noise and require low qubit and time overhead. We benchmark the QHAM by testing its effective memory capacity against qubit- and circuit-level errors and demonstrate its capabilities in the NISQ-era of quantum hardware. This demonstration of the first functional QHAM to be implemented in NISQ-era quantum hardware is a significant step in machine learning at the leading edge of quantum computing.
Finding a latent k-simplex in O(k . nnz(data)) time via Subset Smoothing
Apr 19, 2019The core problem in many Latent Variable Models, widely used in Unsupervised Learning is to find a latent k-simplex K in Rd given perturbed points from it, many of which lie far outside the simplex. This problem was stated in [2] as an open problem. We address this problem under two deterministic assumptions which replace varied stochastic assumptions specific to relevant individual models. Our first contribution is to show that the convex hull K' of the averages of all delta n sized subsets of data points is close to K. We call this subset-smoothing. While K' can have exponentially many vertices, it is easily seen to have a polynomial time Optimization Oracle which in fact runs in time O(nnz(data)). This is the starting point for our algorithm. The algorithm is simple: it has k stages in each of which we use the oracle to find maximum of a carefully chosen linear function over K'; the optimal x is an approximation to a new vertex of K. The simplicity does not carry over to the proof of correctness. The proof is involved and uses existing and new tools from Numerical Analysis, especially angles between singular spaces of close-by matrices. However, the simplicity of the algorithm, especially the fact the only way we use the data is to do matrix-vector products leads to the claimed time bound. This matches the best known algorithms in the special cases and is better when the input is sparse as indeed is the case in many applications. Our algorithm applies to many special cases, including Topic Models, Approximate Non-negative Matrix factorization, Overlapping community Detection and Clustering.
On the adoption of abductive reasoning for time series interpretation
Jun 25, 2018


Time series interpretation aims to provide an explanation of what is observed in terms of its underlying processes. The present work is based on the assumption that the common classification-based approaches to time series interpretation suffer from a set of inherent weaknesses, whose ultimate cause lies in the monotonic nature of the deductive reasoning paradigm. In this document we propose a new approach to this problem, based on the initial hypothesis that abductive reasoning properly accounts for the human ability to identify and characterize the patterns appearing in a time series. The result of this interpretation is a set of conjectures in the form of observations, organized into an abstraction hierarchy and explaining what has been observed. A knowledge-based framework and a set of algorithms for the interpretation task are provided, implementing a hypothesize-and-test cycle guided by an attentional mechanism. As a representative application domain, interpretation of the electrocardiogram allows us to highlight the strengths of the proposed approach in comparison with traditional classification-based approaches.
* 44 pages, 9 figures
Atlas-Based Segmentation of Intracochlear Anatomy in Metal Artifact Affected CT Images of the Ear with Co-trained Deep Neural Networks
Jul 08, 2021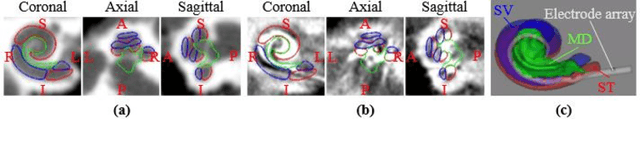
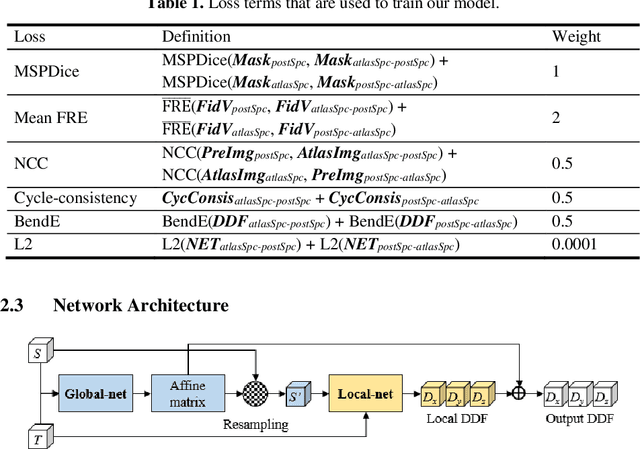
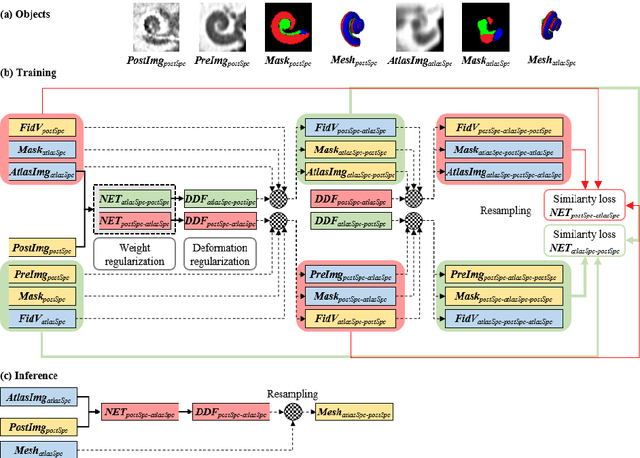
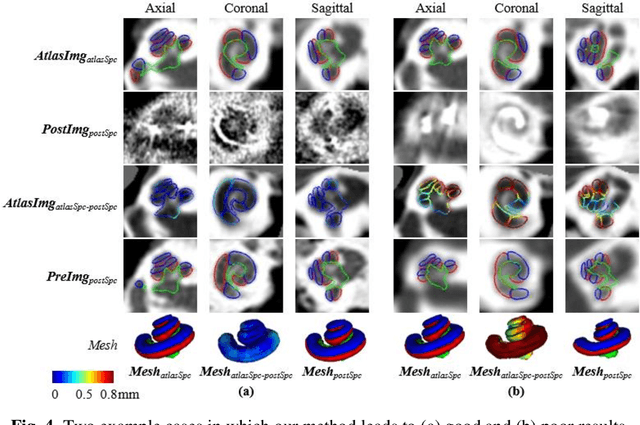
We propose an atlas-based method to segment the intracochlear anatomy (ICA) in the post-implantation CT (Post-CT) images of cochlear implant (CI) recipients that preserves the point-to-point correspondence between the meshes in the atlas and the segmented volumes. To solve this problem, which is challenging because of the strong artifacts produced by the implant, we use a pair of co-trained deep networks that generate dense deformation fields (DDFs) in opposite directions. One network is tasked with registering an atlas image to the Post-CT images and the other network is tasked with registering the Post-CT images to the atlas image. The networks are trained using loss functions based on voxel-wise labels, image content, fiducial registration error, and cycle-consistency constraint. The segmentation of the ICA in the Post-CT images is subsequently obtained by transferring the predefined segmentation meshes of the ICA in the atlas image to the Post-CT images using the corresponding DDFs generated by the trained registration networks. Our model can learn the underlying geometric features of the ICA even though they are obscured by the metal artifacts. We show that our end-to-end network produces results that are comparable to the current state of the art (SOTA) that relies on a two-steps approach that first uses conditional generative adversarial networks to synthesize artifact-free images from the Post-CT images and then uses an active shape model-based method to segment the ICA in the synthetic images. Our method requires a fraction of the time needed by the SOTA, which is important for end-user acceptance.
Imputation of Clinical Covariates in Time Series
Dec 02, 2018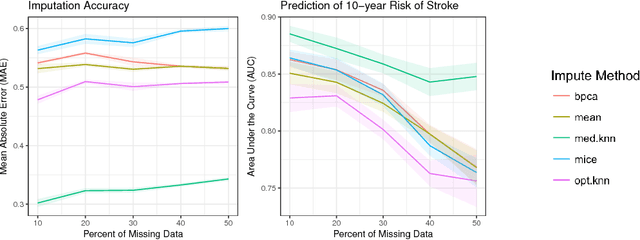
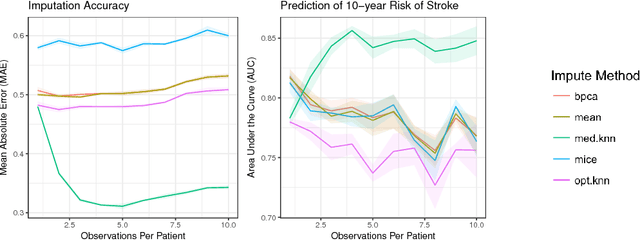
Missing data is a common problem in real-world settings and particularly relevant in healthcare applications where researchers use Electronic Health Records (EHR) and results of observational studies to apply analytics methods. This issue becomes even more prominent for longitudinal data sets, where multiple instances of the same individual correspond to different observations in time. Standard imputation methods do not take into account patient specific information incorporated in multivariate panel data. We introduce the novel imputation algorithm MedImpute that addresses this problem, extending the flexible framework of OptImpute suggested by Bertsimas et al. (2018). Our algorithm provides imputations for data sets with missing continuous and categorical features, and we present the formulation and implement scalable first-order methods for a $K$-NN model. We test the performance of our algorithm on longitudinal data from the Framingham Heart Study when data are missing completely at random (MCAR). We demonstrate that MedImpute leads to significant improvements in both imputation accuracy and downstream model AUC compared to state-of-the-art methods.
A Hierarchical State-Machine-Based Framework for Platoon Manoeuvre Descriptions
Apr 12, 2021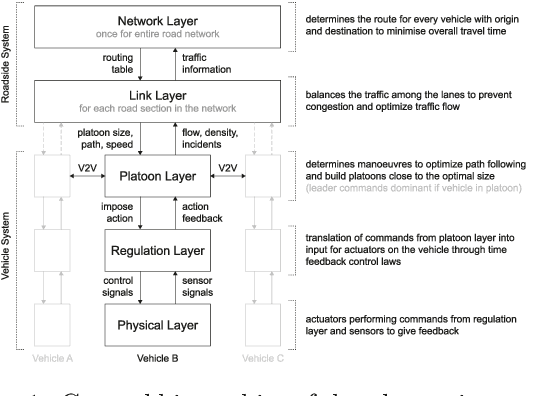
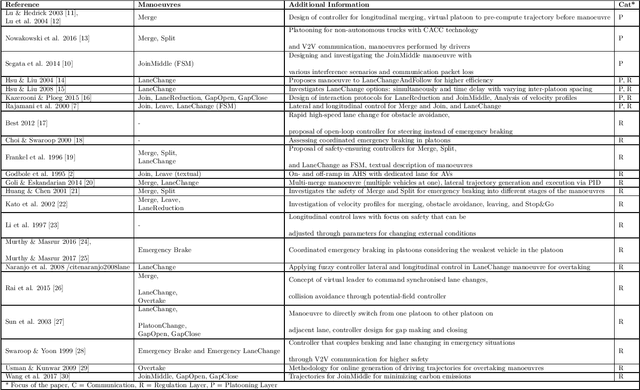
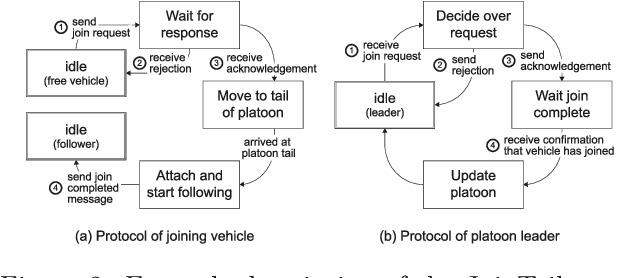
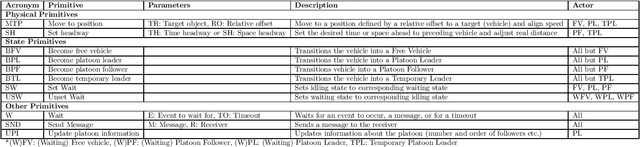
This paper introduces the SEAD framework that simplifies the process of designing and describing autonomous vehicle platooning manoeuvres. Although a large body of research has been formulating platooning manoeuvres, it is still challenging to design, describe, read, and understand them. This difficulty largely arises from missing formalisation. To fill this gap, we analysed existing ways of describing manoeuvres, derived the causes of difficulty, and designed a framework that simplifies the manoeuvre design process. Alongside, a Manoeuvre Design Language was developed to structurally describe manoeuvres in a machine-readable format. Unlike state-of-the-art manoeuvre descriptions that require one state machine for every participating vehicle, the SEAD framework allows describing any manoeuvre from the single perspective of the platoon leader. %As a proof of concept, the proposed framework was implemented in the mixed traffic simulation environment BEHAVE for an autonomous highway scenario. Using this framework, we implemented several manoeuvres as they were described in literature. To demonstrate the applicability of the framework, an experiment was performed to evaluate the execution time performance of multiple alternatives of the Join-Middle manoeuvre. This proof-of-concept experiment revealed that the manoeuvre execution time can be reduced by 28 \% through parallelising various steps without considerable secondary effects. We hope that the SEAD framework will pave the way for further research in the area of new manoeuvre design and optimisation by largely simplifying and unifying platooning manoeuvre representation.
Concave Utility Reinforcement Learning: the Mean-field Game viewpoint
Jun 09, 2021
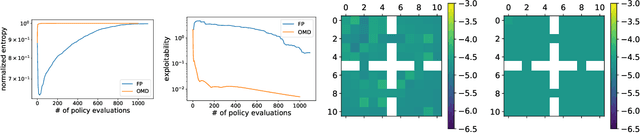
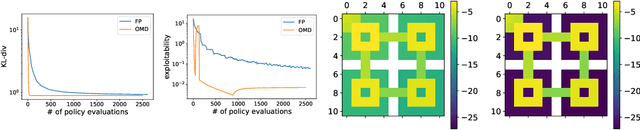

Concave Utility Reinforcement Learning (CURL) extends RL from linear to concave utilities in the occupancy measure induced by the agent's policy. This encompasses not only RL but also imitation learning and exploration, among others. Yet, this more general paradigm invalidates the classical Bellman equations, and calls for new algorithms. Mean-field Games (MFGs) are a continuous approximation of many-agent RL. They consider the limit case of a continuous distribution of identical agents, anonymous with symmetric interests, and reduce the problem to the study of a single representative agent in interaction with the full population. Our core contribution consists in showing that CURL is a subclass of MFGs. We think this important to bridge together both communities. It also allows to shed light on aspects of both fields: we show the equivalence between concavity in CURL and monotonicity in the associated MFG, between optimality conditions in CURL and Nash equilibrium in MFG, or that Fictitious Play (FP) for this class of MFGs is simply Frank-Wolfe, bringing the first convergence rate for discrete-time FP for MFGs. We also experimentally demonstrate that, using algorithms recently introduced for solving MFGs, we can address the CURL problem more efficiently.
Gradient-based Label Binning in Multi-label Classification
Jun 22, 2021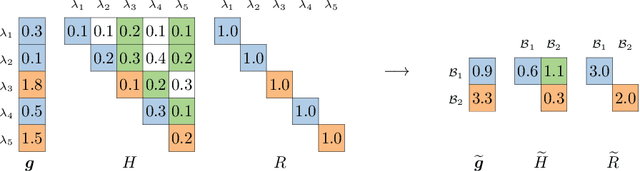
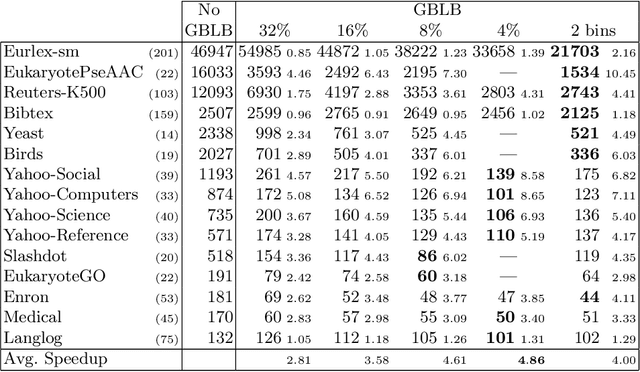
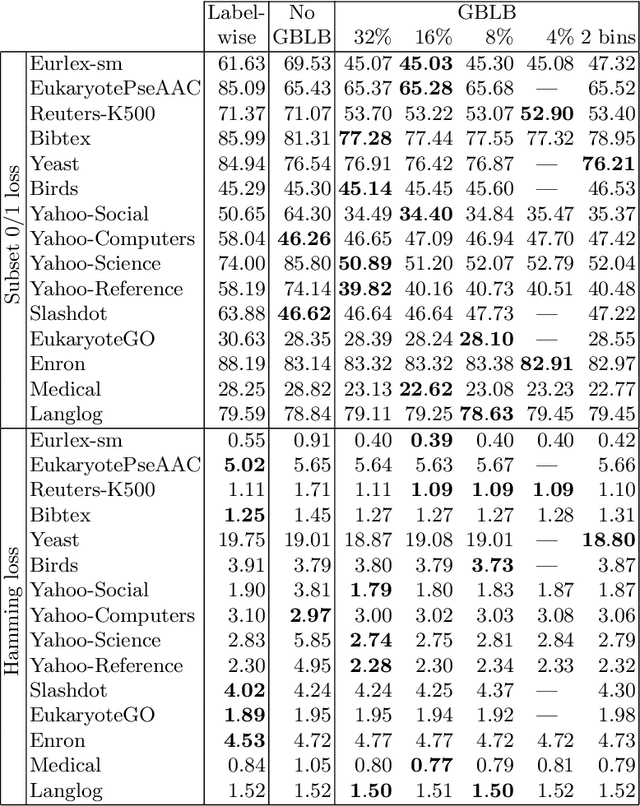
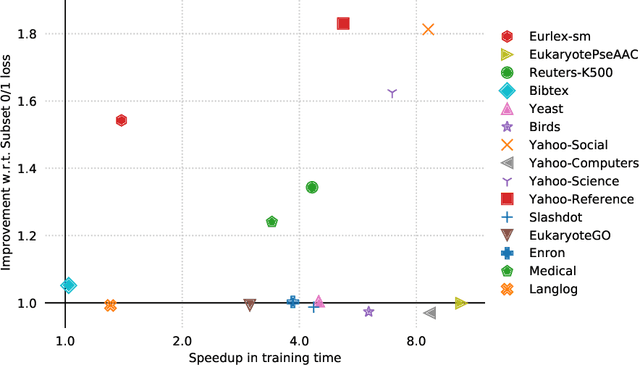
In multi-label classification, where a single example may be associated with several class labels at the same time, the ability to model dependencies between labels is considered crucial to effectively optimize non-decomposable evaluation measures, such as the Subset 0/1 loss. The gradient boosting framework provides a well-studied foundation for learning models that are specifically tailored to such a loss function and recent research attests the ability to achieve high predictive accuracy in the multi-label setting. The utilization of second-order derivatives, as used by many recent boosting approaches, helps to guide the minimization of non-decomposable losses, due to the information about pairs of labels it incorporates into the optimization process. On the downside, this comes with high computational costs, even if the number of labels is small. In this work, we address the computational bottleneck of such approach -- the need to solve a system of linear equations -- by integrating a novel approximation technique into the boosting procedure. Based on the derivatives computed during training, we dynamically group the labels into a predefined number of bins to impose an upper bound on the dimensionality of the linear system. Our experiments, using an existing rule-based algorithm, suggest that this may boost the speed of training, without any significant loss in predictive performance.
Progressive Encoding for Neural Optimization
Apr 19, 2021
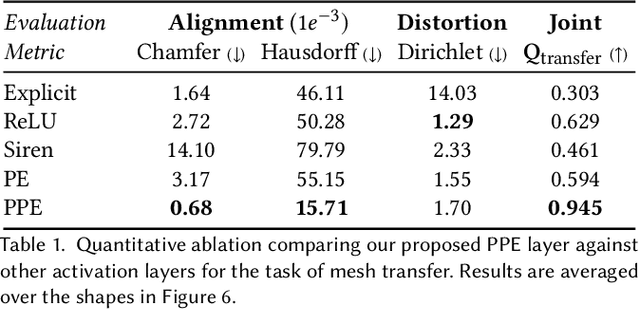
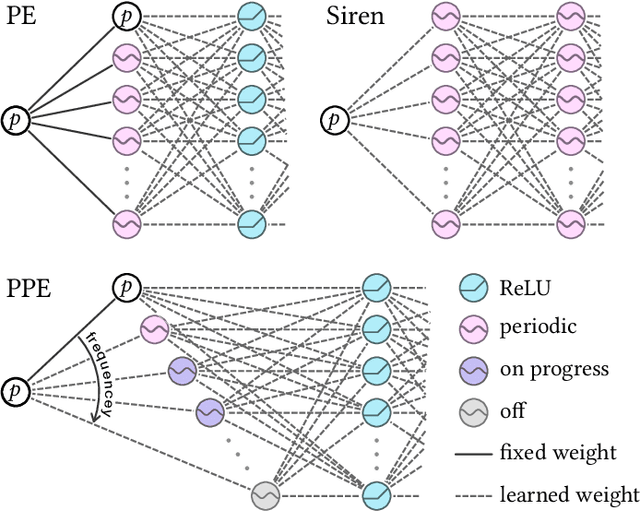
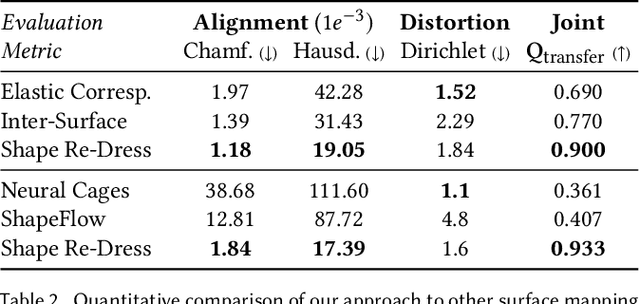
We introduce a Progressive Positional Encoding (PPE) layer, which gradually exposes signals with increasing frequencies throughout the neural optimization. In this paper, we show the competence of the PPE layer for mesh transfer and its advantages compared to contemporary surface mapping techniques. Our approach is simple and requires little user guidance. Most importantly, our technique is a parameterization-free method, and thus applicable to a variety of target shape representations, including point clouds, polygon soups, and non-manifold meshes. We demonstrate that the transferred meshing remains faithful to the source mesh design characteristics, and at the same time fits the target geometry well.
A Raspberry Pi based Traumatic Brain Injury Detection System for Single-Channel Electroencephalogram
Jan 23, 2021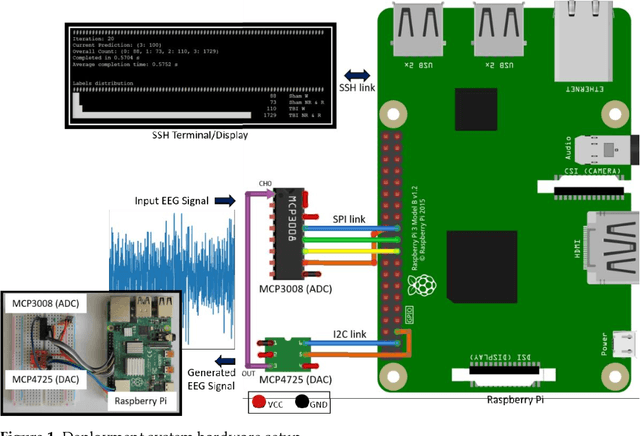
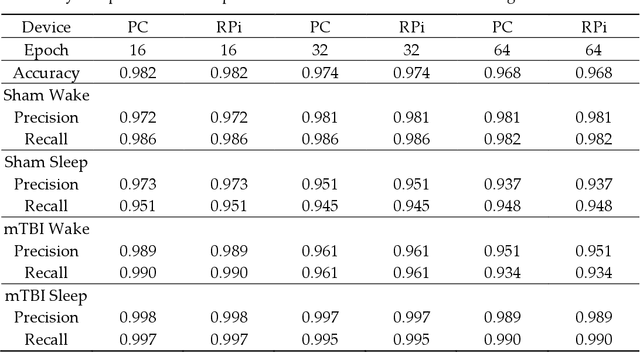
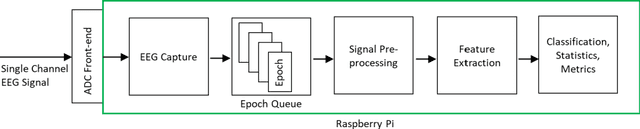
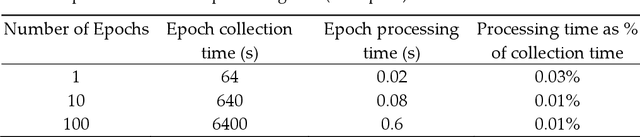
Traumatic Brain Injury (TBI) is a common cause of death and disability. However, existing tools for TBI diagnosis are either subjective or require extensive clinical setup and expertise. The increasing affordability and reduction in size of relatively high-performance computing systems combined with promising results from TBI related machine learning research make it possible to create compact and portable systems for early detection of TBI. This work describes a Raspberry Pi based portable, real-time data acquisition, and automated processing system that uses machine learning to efficiently identify TBI and automatically score sleep stages from a single-channel Electroen-cephalogram (EEG) signal. We discuss the design, implementation, and verification of the system that can digitize EEG signal using an Analog to Digital Converter (ADC) and perform real-time signal classification to detect the presence of mild TBI (mTBI). We utilize Convolutional Neural Networks (CNN) and XGBoost based predictive models to evaluate the performance and demonstrate the versatility of the system to operate with multiple types of predictive models. We achieve a peak classification accuracy of more than 90% with a classification time of less than 1 s across 16 s - 64 s epochs for TBI vs control conditions. This work can enable development of systems suitable for field use without requiring specialized medical equipment for early TBI detection applications and TBI research. Further, this work opens avenues to implement connected, real-time TBI related health and wellness monitoring systems.