 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Estimating the Robustness of Public Transport Systems Using Machine Learning
Jun 10, 2021
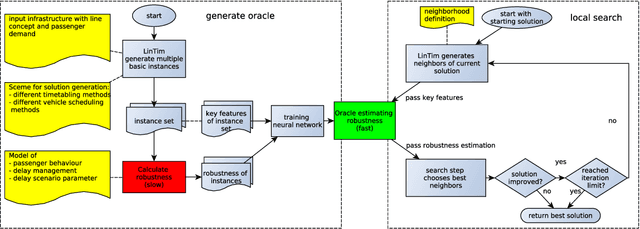
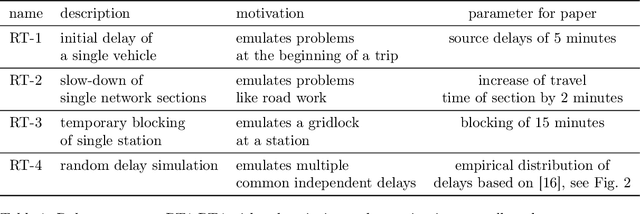
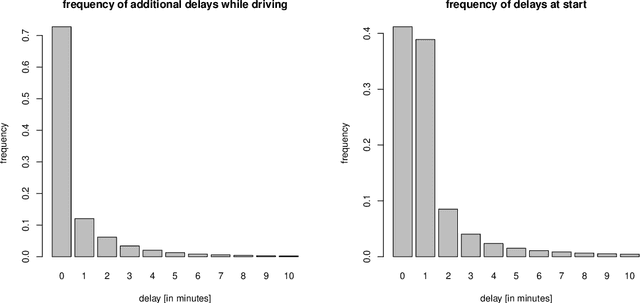
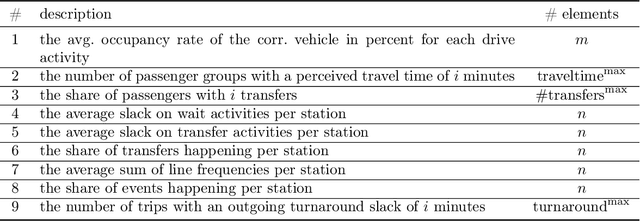
The planning of attractive and cost efficient public transport systems is a highly complex optimization process involving many steps. Integrating robustness from a passenger's point of view makes the task even more challenging. With numerous different definitions of robustness in literature, a real-world acceptable evaluation of the robustness of a public transport system is to simulate its performance under a large number of possible scenarios. Unfortunately, this is computationally very expensive. In this paper, we therefore explore a new way of such a scenario-based robustness approximation by using methods from machine learning. We achieve a fast approach with a very high accuracy by gathering a subset of key features of a public transport system and its passenger demand and training an artificial neural network to learn the outcome of a given set of robustness tests. The network is then able to predict the robustness of untrained instances with high accuracy using only its key features, allowing for a robustness oracle for transport planners that approximates the robustness in constant time. Such an oracle can be used as black box to increase the robustness within a local search framework for integrated public transportation planning. In computational experiments with different benchmark instances we demonstrate an excellent quality of our predictions.
Egocentric Videoconferencing
Jul 07, 2021

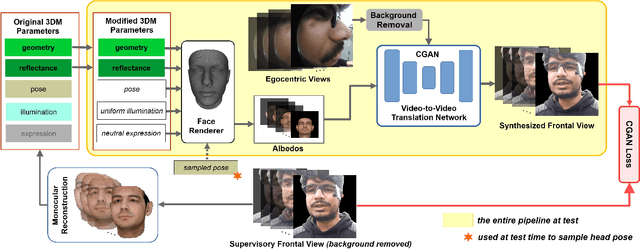

We introduce a method for egocentric videoconferencing that enables hands-free video calls, for instance by people wearing smart glasses or other mixed-reality devices. Videoconferencing portrays valuable non-verbal communication and face expression cues, but usually requires a front-facing camera. Using a frontal camera in a hands-free setting when a person is on the move is impractical. Even holding a mobile phone camera in the front of the face while sitting for a long duration is not convenient. To overcome these issues, we propose a low-cost wearable egocentric camera setup that can be integrated into smart glasses. Our goal is to mimic a classical video call, and therefore, we transform the egocentric perspective of this camera into a front facing video. To this end, we employ a conditional generative adversarial neural network that learns a transition from the highly distorted egocentric views to frontal views common in videoconferencing. Our approach learns to transfer expression details directly from the egocentric view without using a complex intermediate parametric expressions model, as it is used by related face reenactment methods. We successfully handle subtle expressions, not easily captured by parametric blendshape-based solutions, e.g., tongue movement, eye movements, eye blinking, strong expressions and depth varying movements. To get control over the rigid head movements in the target view, we condition the generator on synthetic renderings of a moving neutral face. This allows us to synthesis results at different head poses. Our technique produces temporally smooth video-realistic renderings in real-time using a video-to-video translation network in conjunction with a temporal discriminator. We demonstrate the improved capabilities of our technique by comparing against related state-of-the art approaches.
* Mohamed Elgharib and Mohit Mendiratta contributed equally to this work. http://gvv.mpi-inf.mpg.de/projects/EgoChat/
Incremental Learning for Multi-organ Segmentation with Partially Labeled Datasets
Mar 08, 2021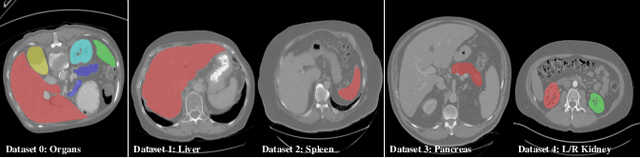
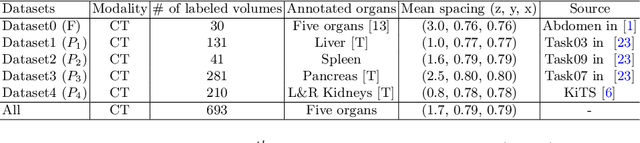
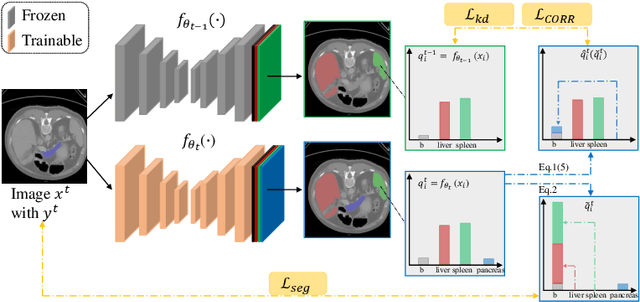
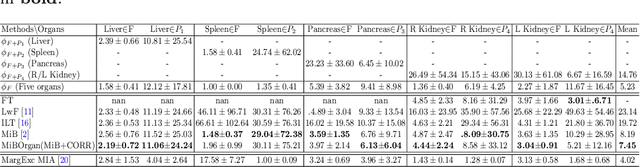
There exists a large number of datasets for organ segmentation, which are partially annotated, and sequentially constructed. A typical dataset is constructed at a certain time by curating medical images and annotating the organs of interest. In other words, new datasets with annotations of new organ categories are built over time. To unleash the potential behind these partially labeled, sequentially-constructed datasets, we propose to learn a multi-organ segmentation model through incremental learning (IL). In each IL stage, we lose access to the previous annotations, whose knowledge is assumingly captured by the current model, and gain the access to a new dataset with annotations of new organ categories, from which we learn to update the organ segmentation model to include the new organs. We give the first attempt to conjecture that the different distribution is the key reason for 'catastrophic forgetting' that commonly exists in IL methods, and verify that IL has the natural adaptability to medical image scenarios. Extensive experiments on five open-sourced datasets are conducted to prove the effectiveness of our method and the conjecture mentioned above.
Sparse Spiking Gradient Descent
May 18, 2021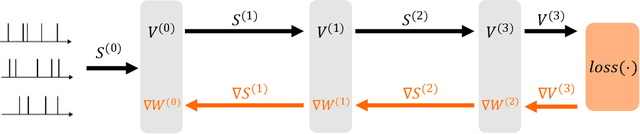
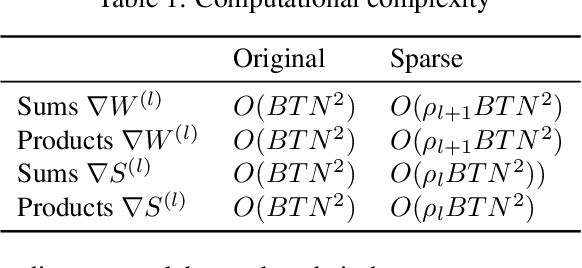
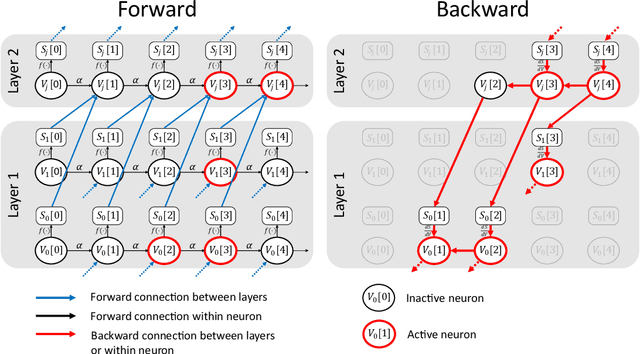

There is an increasing interest in emulating Spiking Neural Networks (SNNs) on neuromorphic computing devices due to their low energy consumption. Recent advances have allowed training SNNs to a point where they start to compete with traditional Artificial Neural Networks (ANNs) in terms of accuracy, while at the same time being energy efficient when run on neuromorphic hardware. However, the process of training SNNs is still based on dense tensor operations originally developed for ANNs which do not leverage the spatiotemporally sparse nature of SNNs. We present here the first sparse SNN backpropagation algorithm which achieves the same or better accuracy as current state of the art methods while being significantly faster and more memory efficient. We show the effectiveness of our method on real datasets of varying complexity (Fashion-MNIST, Neuromophic-MNIST and Spiking Heidelberg Digits) achieving a speedup in the backward pass of up to 70x, and 40% more memory efficient, without losing accuracy.
Hyperspace Neighbor Penetration Approach to Dynamic Programming for Model-Based Reinforcement Learning Problems with Slowly Changing Variables in A Continuous State Space
Jun 10, 2021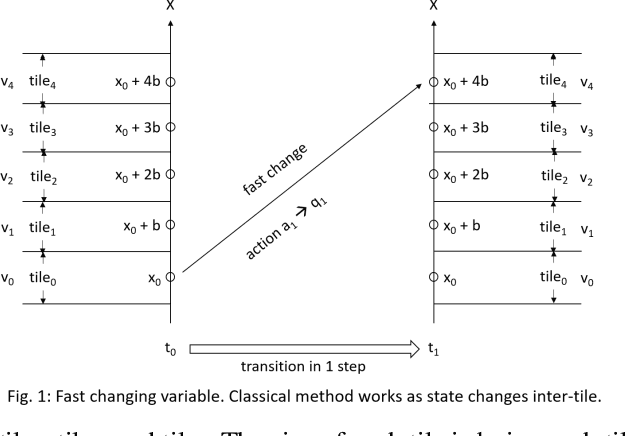
Slowly changing variables in a continuous state space constitute an important category of reinforcement learning and see its application in many domains, such as modeling a climate control system where temperature, humidity, etc. change slowly over time. However, this subject is less addressed in recent studies. Classical methods with certain variants, such as Dynamic Programming with Tile Coding which discretizes the state space, fail to handle slowly changing variables because those methods cannot capture the tiny changes in each transition step, as it is computationally expensive or impossible to establish an extremely granular grid system. In this paper, we introduce a Hyperspace Neighbor Penetration (HNP) approach that solves the problem. HNP captures in each transition step the state's partial "penetration" into its neighboring hyper-tiles in the gridded hyperspace, thus does not require the transition to be inter-tile in order for the change to be captured. Therefore, HNP allows for a very coarse grid system, which makes the computation feasible. HNP assumes near linearity of the transition function in a local space, which is commonly satisfied. In summary, HNP can be orders of magnitude more efficient than classical method in handling slowly changing variables in reinforcement learning. We have made an industrial implementation of NHP with a great success.
Superiorities of Deep Extreme Learning Machines against Convolutional Neural Networks
Jan 21, 2021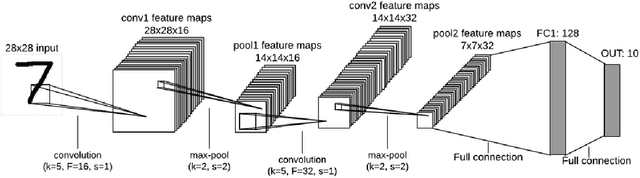
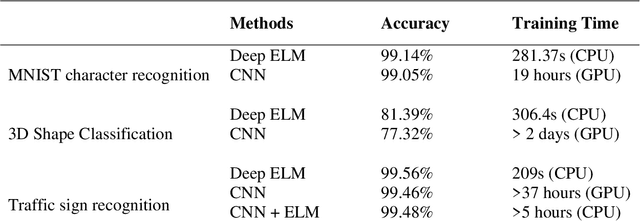
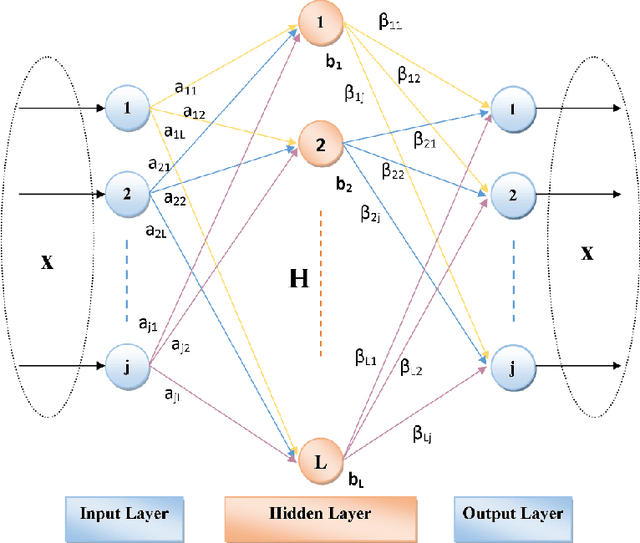
Deep Learning (DL) is a machine learning procedure for artificial intelligence that analyzes the input data in detail by increasing neuron sizes and number of the hidden layers. DL has a popularity with the common improvements on the graphical processing unit capabilities. Increasing number of the neuron sizes at each layer and hidden layers is directly related to the computation time and training speed of the classifier models. The classification parameters including neuron weights, output weights, and biases need to be optimized for obtaining an optimum model. Most of the popular DL algorithms require long training times for optimization of the parameters with feature learning progresses and back-propagated training procedures. Reducing the training time and providing a real-time decision system are the basic focus points of the novel approaches. Deep Extreme Learning machines (Deep ELM) classifier model is one of the fastest and effective way to meet fast classification problems. In this study, Deep ELM model, its superiorities and weaknesses are discussed, the problems that are more suitable for the classifiers against Convolutional neural network based DL algorithms.
* 7 pages, 2 figures, Natural and Engineering Sciences
Acoustic Scene Classification Using Multichannel Observation with Partially Missing Channels
May 05, 2021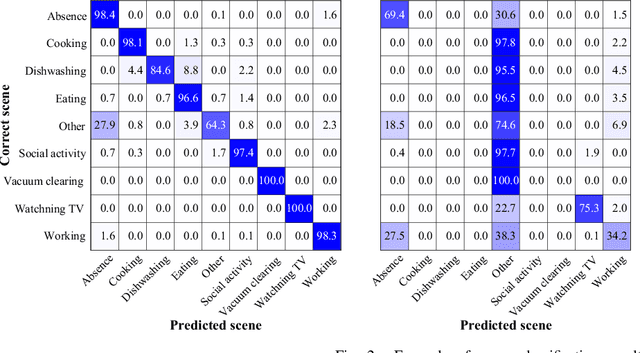
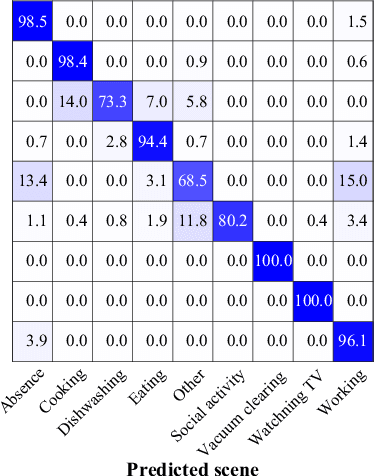
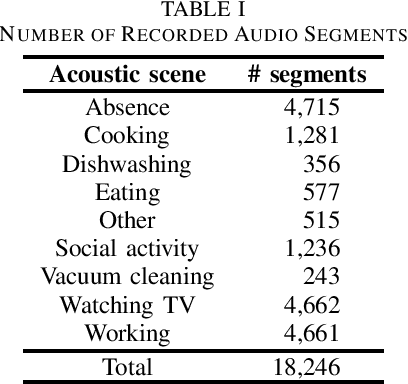

Sounds recorded with smartphones or IoT devices often have partially unreliable observations caused by clipping, wind noise, and completely missing parts due to microphone failure and packet loss in data transmission over the network. In this paper, we investigate the impact of the partially missing channels on the performance of acoustic scene classification using multichannel audio recordings, especially for a distributed microphone array. Missing observations cause not only losses of time-frequency and spatial information on sound sources but also a mismatch between a trained model and evaluation data. We thus investigate how a missing channel affects the performance of acoustic scene classification in detail. We also propose simple data augmentation methods for scene classification using multichannel observations with partially missing channels and evaluate the scene classification performance using the data augmentation methods.
Learning-based Optoelectronically Innervated Tactile Finger for Rigid-Soft Interactive Grasping
Jan 29, 2021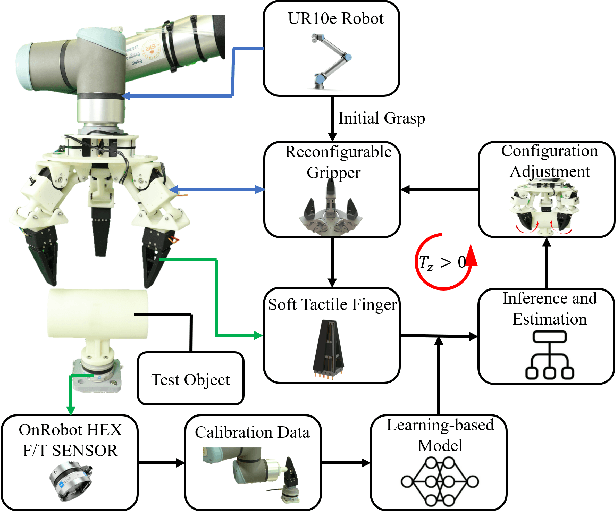
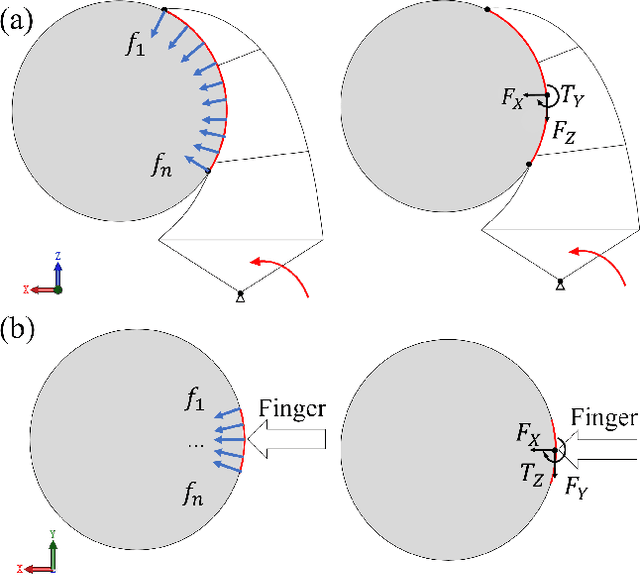
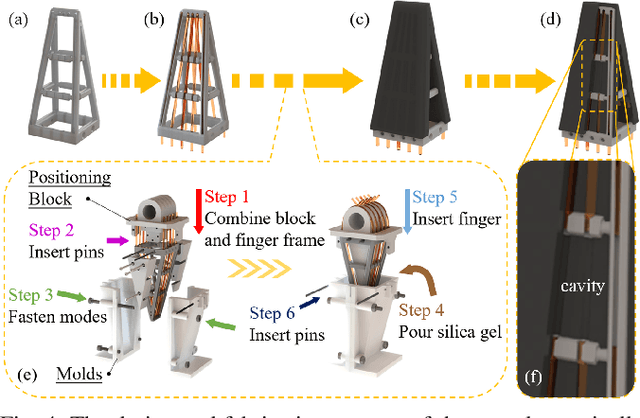
This paper presents a novel design of a soft tactile finger with omni-directional adaptation using multi-channel optical fibers for rigid-soft interactive grasping. Machine learning methods are used to train a model for real-time prediction of force, torque, and contact using the tactile data collected. We further integrated such fingers in a reconfigurable gripper design with three fingers so that the finger arrangement can be actively adjusted in real-time based on the tactile data collected during grasping, achieving the process of rigid-soft interactive grasping. Detailed sensor calibration and experimental results are also included to further validate the proposed design for enhanced grasping robustness.
Sleeping Combinatorial Bandits
Jun 03, 2021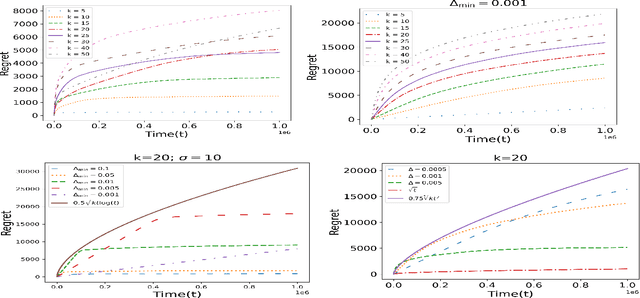
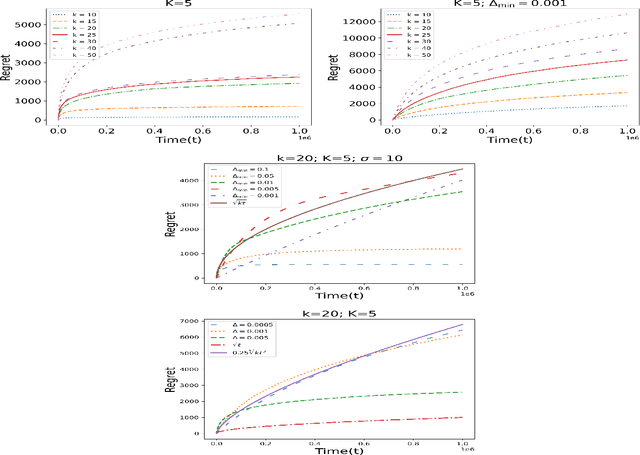
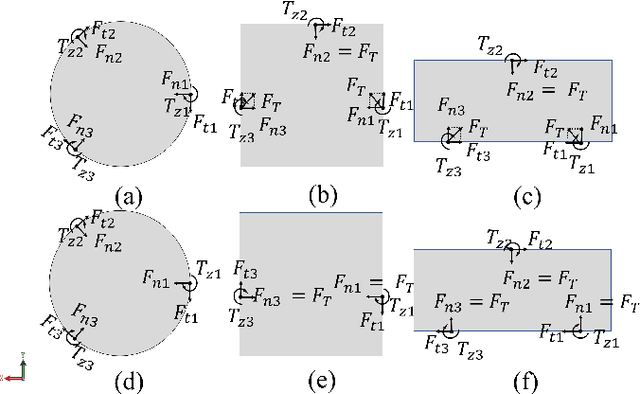
In this paper, we study an interesting combination of sleeping and combinatorial stochastic bandits. In the mixed model studied here, at each discrete time instant, an arbitrary \emph{availability set} is generated from a fixed set of \emph{base} arms. An algorithm can select a subset of arms from the \emph{availability set} (sleeping bandits) and receive the corresponding reward along with semi-bandit feedback (combinatorial bandits). We adapt the well-known CUCB algorithm in the sleeping combinatorial bandits setting and refer to it as \CSUCB. We prove -- under mild smoothness conditions -- that the \CSUCB\ algorithm achieves an $O(\log (T))$ instance-dependent regret guarantee. We further prove that (i) when the range of the rewards is bounded, the regret guarantee of \CSUCB\ algorithm is $O(\sqrt{T \log (T)})$ and (ii) the instance-independent regret is $O(\sqrt[3]{T^2 \log(T)})$ in a general setting. Our results are quite general and hold under general environments -- such as non-additive reward functions, volatile arm availability, a variable number of base-arms to be pulled -- arising in practical applications. We validate the proven theoretical guarantees through experiments.
Efficient Deep Learning Pipelines for Accurate Cost Estimations Over Large Scale Query Workload
Mar 23, 2021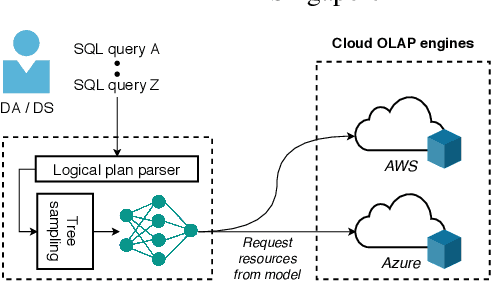
The use of deep learning models for forecasting the resource consumption patterns of SQL queries have recently been a popular area of study. With many companies using cloud platforms to power their data lakes for large scale analytic demands, these models form a critical part of the pipeline in managing cloud resource provisioning. While these models have demonstrated promising accuracy, training them over large scale industry workloads are expensive. Space inefficiencies of encoding techniques over large numbers of queries and excessive padding used to enforce shape consistency across diverse query plans implies 1) longer model training time and 2) the need for expensive, scaled up infrastructure to support batched training. In turn, we developed Prestroid, a tree convolution based data science pipeline that accurately predicts resource consumption patterns of query traces, but at a much lower cost. We evaluated our pipeline over 19K Presto OLAP queries from Grab, on a data lake of more than 20PB of data. Experimental results imply that our pipeline outperforms benchmarks on predictive accuracy, contributing to more precise resource prediction for large-scale workloads, yet also reduces per-batch memory footprint by 13.5x and per-epoch training time by 3.45x. We demonstrate direct cost savings of up to 13.2x for large batched model training over Microsoft Azure VMs.