 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TBC-Net: A real-time detector for infrared small target detection using semantic constraint
Dec 27, 2019

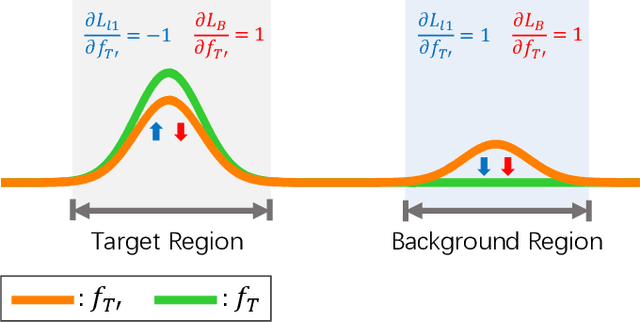
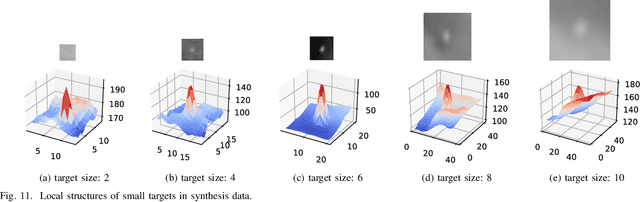
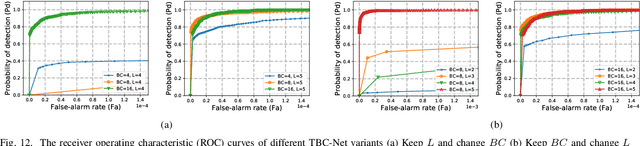
Infrared small target detection is a key technique in infrared search and tracking (IRST) systems. Although deep learning has been widely used in the vision tasks of visible light images recently, it is rarely used in infrared small target detection due to the difficulty in learning small target features. In this paper, we propose a novel lightweight convolutional neural network TBC-Net for infrared small target detection. The TBCNet consists of a target extraction module (TEM) and a semantic constraint module (SCM), which are used to extract small targets from infrared images and to classify the extracted target images during the training, respectively. Meanwhile, we propose a joint loss function and a training method. The SCM imposes a semantic constraint on TEM by combining the high-level classification task and solve the problem of the difficulty to learn features caused by class imbalance problem. During the training, the targets are extracted from the input image and then be classified by SCM. During the inference, only the TEM is used to detect the small targets. We also propose a data synthesis method to generate training data. The experimental results show that compared with the traditional methods, TBC-Net can better reduce the false alarm caused by complicated background, the proposed network structure and joint loss have a significant improvement on small target feature learning. Besides, TBC-Net can achieve real-time detection on the NVIDIA Jetson AGX Xavier development board, which is suitable for applications such as field research with drones equipped with infrared sensors.
DDGC: Generative Deep Dexterous Grasping in Clutter
Mar 08, 2021
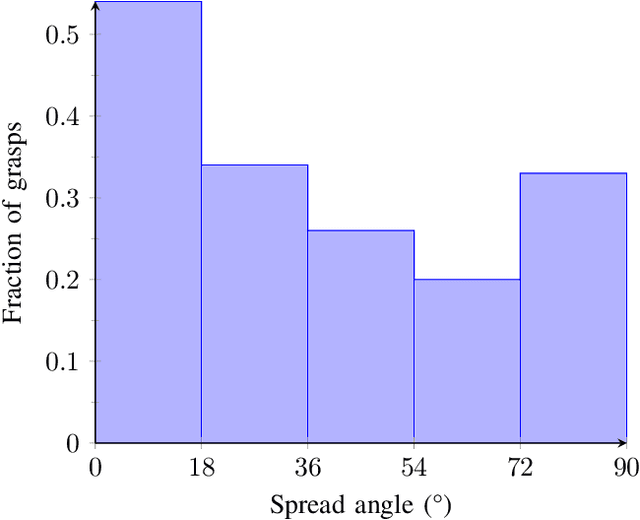
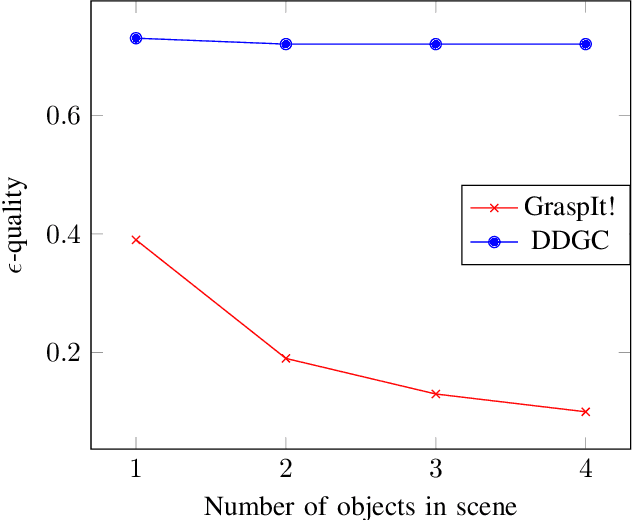

Recent advances in multi-fingered robotic grasping have enabled fast 6-Degrees-Of-Freedom (DOF) single object grasping. Multi-finger grasping in cluttered scenes, on the other hand, remains mostly unexplored due to the added difficulty of reasoning over obstacles which greatly increases the computational time to generate high-quality collision-free grasps. In this work we address such limitations by introducing DDGC, a fast generative multi-finger grasp sampling method that can generate high quality grasps in cluttered scenes from a single RGB-D image. DDGC is built as a network that encodes scene information to produce coarse-to-fine collision-free grasp poses and configurations. We experimentally benchmark DDGC against the simulated-annealing planner in GraspIt! on 1200 simulated cluttered scenes and 7 real world scenes. The results show that DDGC outperforms the baseline on synthesizing high-quality grasps and removing clutter while being 5 times faster. This, in turn, opens up the door for using multi-finger grasps in practical applications which has so far been limited due to the excessive computation time needed by other methods.
Dynamic Graph-Based Anomaly Detection in the Electrical Grid
Dec 30, 2020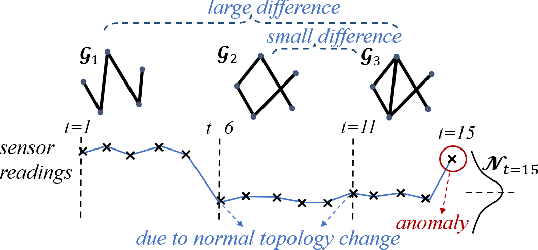
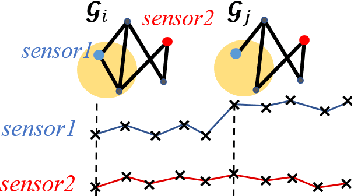
Given sensor readings over time from a power grid, how can we accurately detect when an anomaly occurs? A key part of achieving this goal is to use the network of power grid sensors to quickly detect, in real-time, when any unusual events, whether natural faults or malicious, occur on the power grid. Existing bad-data detectors in the industry lack the sophistication to robustly detect broad types of anomalies, especially those due to emerging cyber-attacks, since they operate on a single measurement snapshot of the grid at a time. New ML methods are more widely applicable, but generally do not consider the impact of topology change on sensor measurements and thus cannot accommodate regular topology adjustments in historical data. Hence, we propose DYNWATCH, a domain knowledge based and topology-aware algorithm for anomaly detection using sensors placed on a dynamic grid. Our approach is accurate, outperforming existing approaches by 20% or more (F-measure) in experiments; and fast, running in less than 1.7ms on average per time tick per sensor on a 60K+ branch case using a laptop computer, and scaling linearly in the size of the graph.
Detecting Anomalous User Behavior in Remote Patient Monitoring
Jun 22, 2021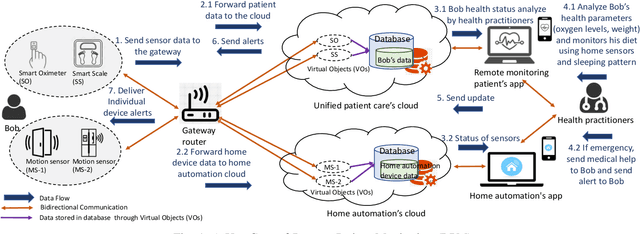
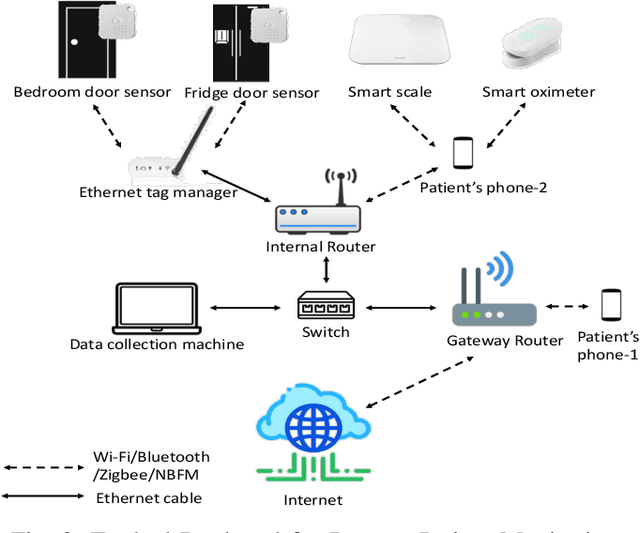


The growth in Remote Patient Monitoring (RPM) services using wearable and non-wearable Internet of Medical Things (IoMT) promises to improve the quality of diagnosis and facilitate timely treatment for a gamut of medical conditions. At the same time, the proliferation of IoMT devices increases the potential for malicious activities that can lead to catastrophic results including theft of personal information, data breach, and compromised medical devices, putting human lives at risk. IoMT devices generate tremendous amount of data that reflect user behavior patterns including both personal and day-to-day social activities along with daily routine health monitoring. In this context, there are possibilities of anomalies generated due to various reasons including unexpected user behavior, faulty sensor, or abnormal values from malicious/compromised devices. To address this problem, there is an imminent need to develop a framework for securing the smart health care infrastructure to identify and mitigate anomalies. In this paper, we present an anomaly detection model for RPM utilizing IoMT and smart home devices. We propose Hidden Markov Model (HMM) based anomaly detection that analyzes normal user behavior in the context of RPM comprising both smart home and smart health devices, and identifies anomalous user behavior. We design a testbed with multiple IoMT devices and home sensors to collect data and use the HMM model to train using network and user behavioral data. Proposed HMM based anomaly detection model achieved over 98% accuracy in identifying the anomalies in the context of RPM.
Content-Based Detection of Temporal Metadata Manipulation
Mar 08, 2021
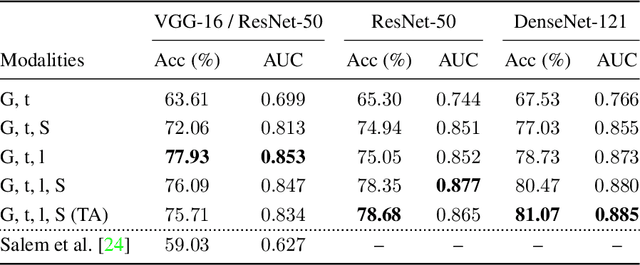


Most pictures shared online are accompanied by a temporal context (i.e., the moment they were taken) that aids their understanding and the history behind them. Claiming that these images were captured in a different moment can be misleading and help to convey a distorted version of reality. In this work, we present the nascent problem of detecting timestamp manipulation. We propose an end-to-end approach to verify whether the purported time of capture of an image is consistent with its content and geographic location. The central idea is the use of supervised consistency verification, in which we predict the probability that the image content, capture time, and geographical location are consistent. We also include a pair of auxiliary tasks, which can be used to explain the network decision. Our approach improves upon previous work on a large benchmark dataset, increasing the classification accuracy from 59.03% to 81.07%. Finally, an ablation study highlights the importance of various components of the method, showing what types of tampering are detectable using our approach.
Multitask Recalibrated Aggregation Network for Medical Code Prediction
Apr 30, 2021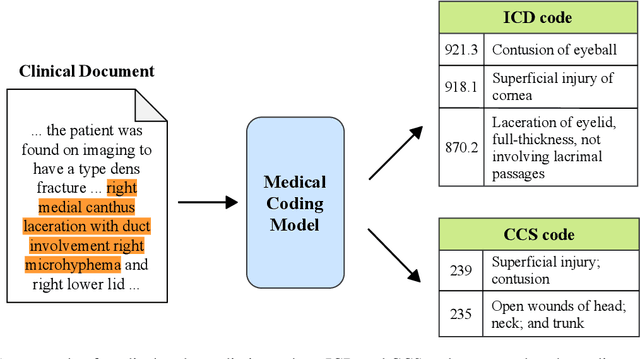
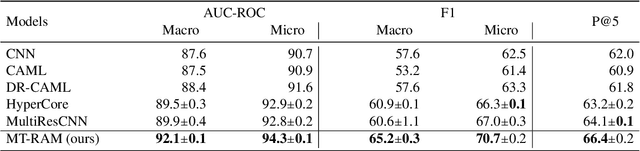
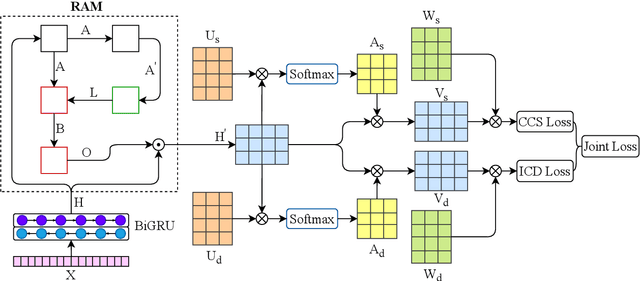
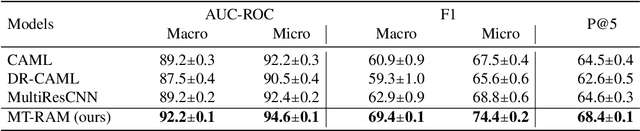
Medical coding translates professionally written medical reports into standardized codes, which is an essential part of medical information systems and health insurance reimbursement. Manual coding by trained human coders is time-consuming and error-prone. Thus, automated coding algorithms have been developed, building especially on the recent advances in machine learning and deep neural networks. To solve the challenges of encoding lengthy and noisy clinical documents and capturing code associations, we propose a multitask recalibrated aggregation network. In particular, multitask learning shares information across different coding schemes and captures the dependencies between different medical codes. Feature recalibration and aggregation in shared modules enhance representation learning for lengthy notes. Experiments with a real-world MIMIC-III dataset show significantly improved predictive performance.
Activity-Aware Deep Cognitive Fatigue Assessment using Wearables
May 05, 2021
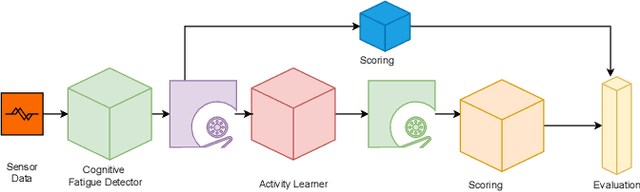
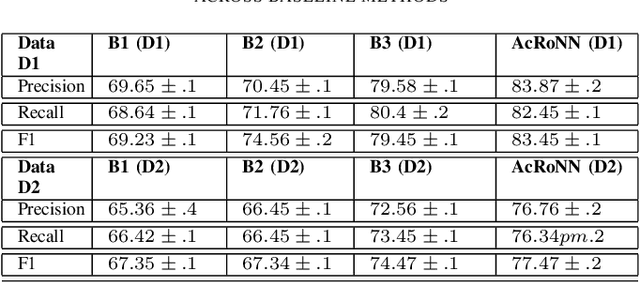
Cognitive fatigue has been a common problem among workers which has become an increasing global problem since the emergence of COVID-19 as a global pandemic. While existing multi-modal wearable sensors-aided automatic cognitive fatigue monitoring tools have focused on physical and physiological sensors (ECG, PPG, Actigraphy) analytic on specific group of people (say gamers, athletes, construction workers), activity-awareness is utmost importance due to its different responses on physiology in different person. In this paper, we propose a novel framework, Activity-Aware Recurrent Neural Network (\emph{AcRoNN}), that can generalize individual activity recognition and improve cognitive fatigue estimation significantly. We evaluate and compare our proposed method with state-of-art methods using one real-time collected dataset from 5 individuals and another publicly available dataset from 27 individuals achieving max. 19% improvement.
Lite-HDSeg: LiDAR Semantic Segmentation Using Lite Harmonic Dense Convolutions
Mar 16, 2021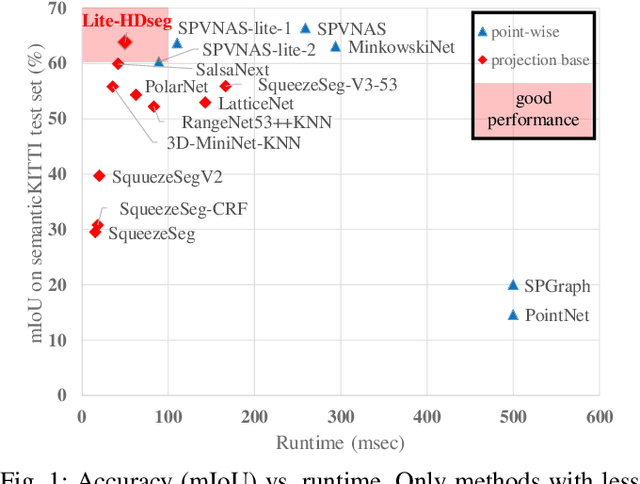
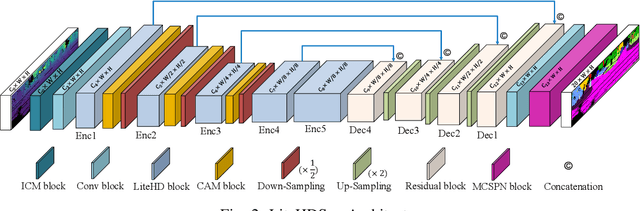
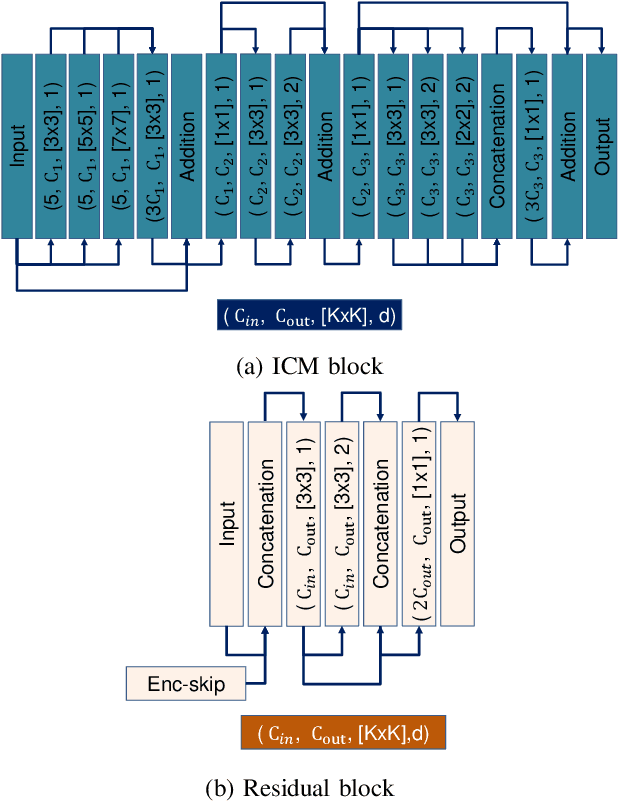
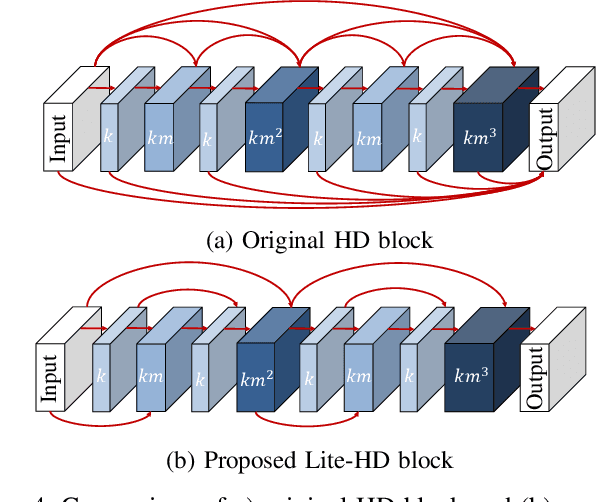
Autonomous driving vehicles and robotic systems rely on accurate perception of their surroundings. Scene understanding is one of the crucial components of perception modules. Among all available sensors, LiDARs are one of the essential sensing modalities of autonomous driving systems due to their active sensing nature with high resolution of sensor readings. Accurate and fast semantic segmentation methods are needed to fully utilize LiDAR sensors for scene understanding. In this paper, we present Lite-HDSeg, a novel real-time convolutional neural network for semantic segmentation of full $3$D LiDAR point clouds. Lite-HDSeg can achieve the best accuracy vs. computational complexity trade-off in SemanticKitti benchmark and is designed on the basis of a new encoder-decoder architecture with light-weight harmonic dense convolutions as its core. Moreover, we introduce ICM, an improved global contextual module to capture multi-scale contextual features, and MCSPN, a multi-class Spatial Propagation Network to further refine the semantic boundaries. Our experimental results show that the proposed method outperforms state-of-the-art semantic segmentation approaches which can run real-time, thus is suitable for robotic and autonomous driving applications.
Flatland Competition 2020: MAPF and MARL for Efficient Train Coordination on a Grid World
Mar 30, 2021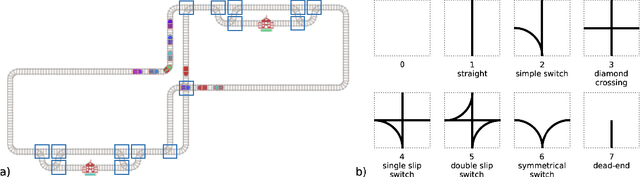
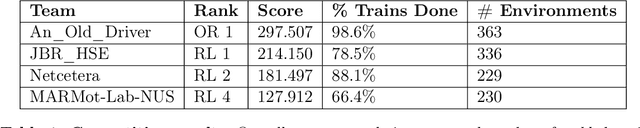
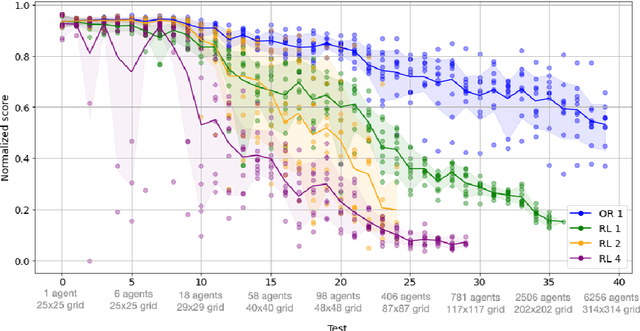
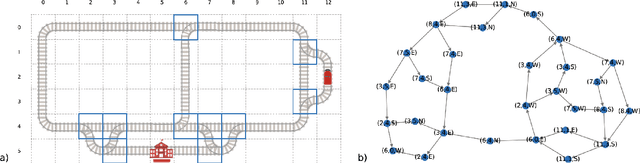
The Flatland competition aimed at finding novel approaches to solve the vehicle re-scheduling problem (VRSP). The VRSP is concerned with scheduling trips in traffic networks and the re-scheduling of vehicles when disruptions occur, for example the breakdown of a vehicle. While solving the VRSP in various settings has been an active area in operations research (OR) for decades, the ever-growing complexity of modern railway networks makes dynamic real-time scheduling of traffic virtually impossible. Recently, multi-agent reinforcement learning (MARL) has successfully tackled challenging tasks where many agents need to be coordinated, such as multiplayer video games. However, the coordination of hundreds of agents in a real-life setting like a railway network remains challenging and the Flatland environment used for the competition models these real-world properties in a simplified manner. Submissions had to bring as many trains (agents) to their target stations in as little time as possible. While the best submissions were in the OR category, participants found many promising MARL approaches. Using both centralized and decentralized learning based approaches, top submissions used graph representations of the environment to construct tree-based observations. Further, different coordination mechanisms were implemented, such as communication and prioritization between agents. This paper presents the competition setup, four outstanding solutions to the competition, and a cross-comparison between them.
Real-world Ride-hailing Vehicle Repositioning using Deep Reinforcement Learning
Mar 08, 2021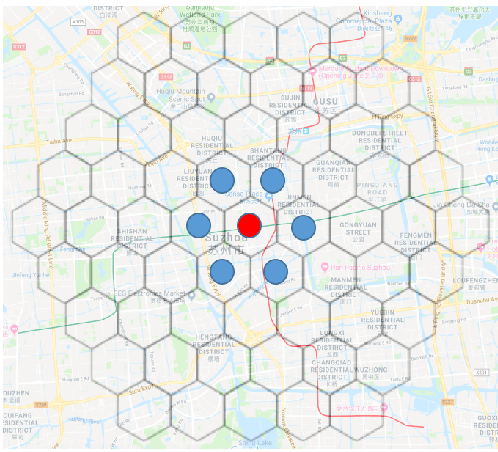
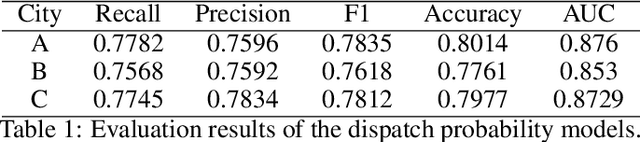
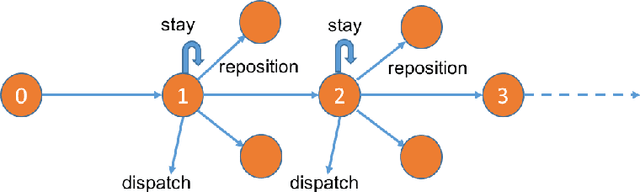

We present a new practical framework based on deep reinforcement learning and decision-time planning for real-world vehicle repositioning on ride-hailing (a type of mobility-on-demand, MoD) platforms. Our approach learns the spatiotemporal state-value function using a batch training algorithm with deep value networks. The optimal repositioning action is generated on-demand through value-based policy search, which combines planning and bootstrapping with the value networks. For the large-fleet problems, we develop several algorithmic features that we incorporate into our framework and that we demonstrate to induce coordination among the algorithmically-guided vehicles. We benchmark our algorithm with baselines in a ride-hailing simulation environment to demonstrate its superiority in improving income efficiency meausred by income-per-hour. We have also designed and run a real-world experiment program with regular drivers on a major ride-hailing platform. We have observed significantly positive results on key metrics comparing our method with experienced drivers who performed idle-time repositioning based on their own expertise.