 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraging Deep Representations of Radiology Reports in Survival Analysis for Predicting Heart Failure Patient Mortality
May 03, 2021
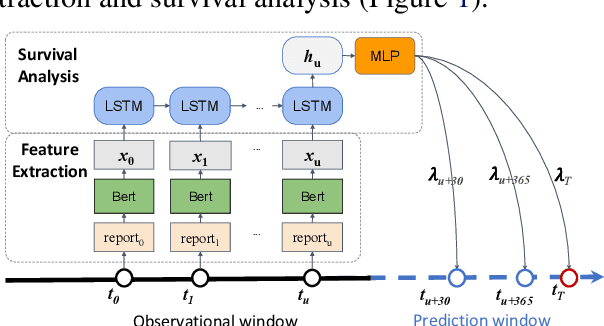
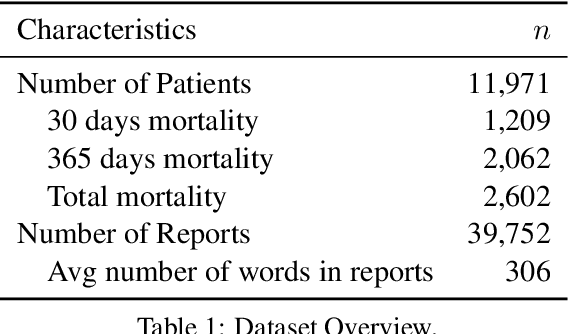
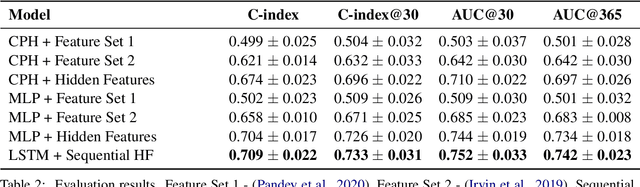
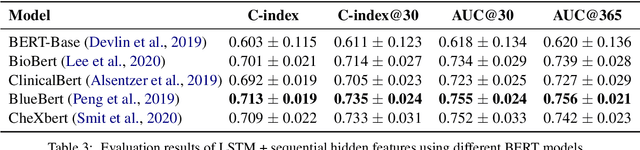
Utilizing clinical texts in survival analysis is difficult because they are largely unstructured. Current automatic extraction models fail to capture textual information comprehensively since their labels are limited in scope. Furthermore, they typically require a large amount of data and high-quality expert annotations for training. In this work, we present a novel method of using BERT-based hidden layer representations of clinical texts as covariates for proportional hazards models to predict patient survival outcomes. We show that hidden layers yield notably more accurate predictions than predefined features, outperforming the previous baseline model by 5.7% on average across C-index and time-dependent AUC. We make our work publicly available at https://github.com/bionlplab/heart_failure_mortality.
Hierarchical Object-oriented Spatio-Temporal Reasoning for Video Question Answering
Jun 25, 2021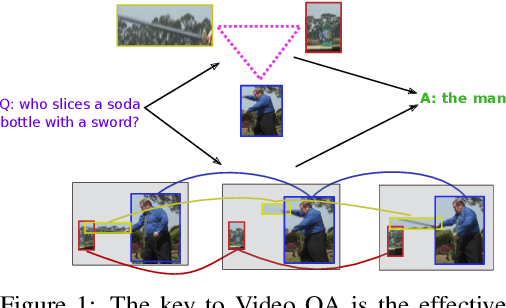
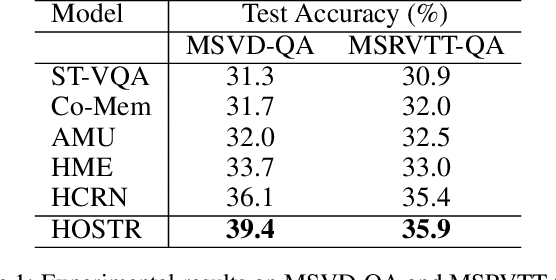
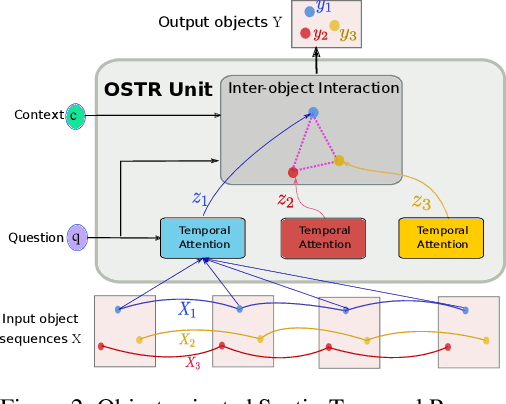
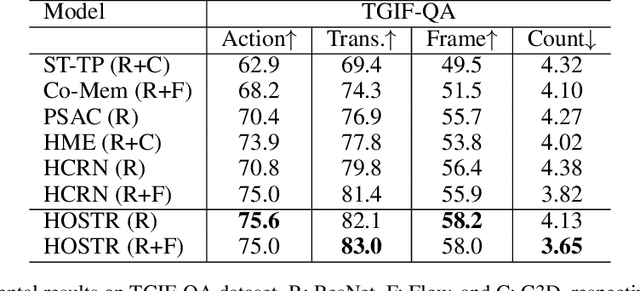
Video Question Answering (Video QA) is a powerful testbed to develop new AI capabilities. This task necessitates learning to reason about objects, relations, and events across visual and linguistic domains in space-time. High-level reasoning demands lifting from associative visual pattern recognition to symbol-like manipulation over objects, their behavior and interactions. Toward reaching this goal we propose an object-oriented reasoning approach in that video is abstracted as a dynamic stream of interacting objects. At each stage of the video event flow, these objects interact with each other, and their interactions are reasoned about with respect to the query and under the overall context of a video. This mechanism is materialized into a family of general-purpose neural units and their multi-level architecture called Hierarchical Object-oriented Spatio-Temporal Reasoning (HOSTR) networks. This neural model maintains the objects' consistent lifelines in the form of a hierarchically nested spatio-temporal graph. Within this graph, the dynamic interactive object-oriented representations are built up along the video sequence, hierarchically abstracted in a bottom-up manner, and converge toward the key information for the correct answer. The method is evaluated on multiple major Video QA datasets and establishes new state-of-the-arts in these tasks. Analysis into the model's behavior indicates that object-oriented reasoning is a reliable, interpretable and efficient approach to Video QA.
Signal Transformer: Complex-valued Attention and Meta-Learning for Signal Recognition
Jun 12, 2021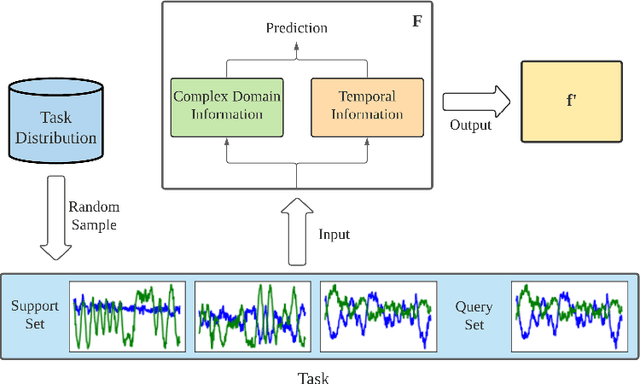
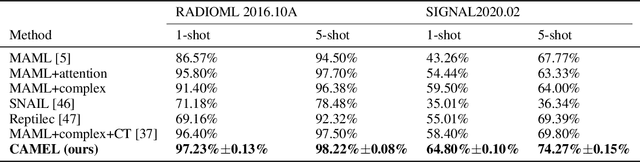

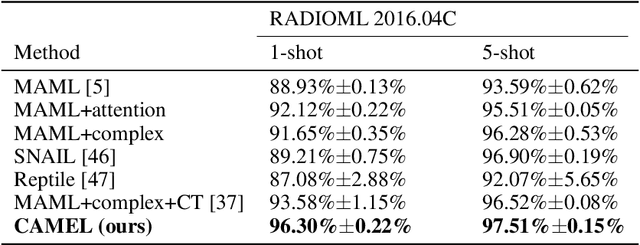
Deep neural networks have been shown as a class of useful tools for addressing signal recognition issues in recent years, especially for identifying the nonlinear feature structures of signals. However, this power of most deep learning techniques heavily relies on an abundant amount of training data, so the performance of classic neural nets decreases sharply when the number of training data samples is small or unseen data are presented in the testing phase. This calls for an advanced strategy, i.e., model-agnostic meta-learning (MAML), which is able to capture the invariant representation of the data samples or signals. In this paper, inspired by the special structure of the signal, i.e., real and imaginary parts consisted in practical time-series signals, we propose a Complex-valued Attentional MEta Learner (CAMEL) for the problem of few-shot signal recognition by leveraging attention and meta-learning in the complex domain. To the best of our knowledge, this is also the first complex-valued MAML that can find the first-order stationary points of general nonconvex problems with theoretical convergence guarantees. Extensive experiments results showcase the superiority of the proposed CAMEL compared with the state-of-the-art methods.
Context-aware Ensemble of Multifaceted Factorization Models for Recommendation Prediction in Social Networks
May 03, 2021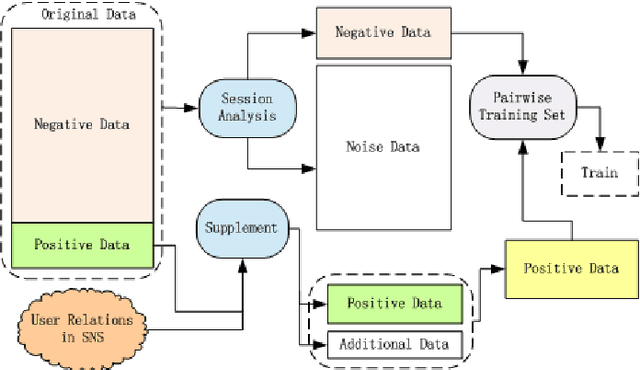
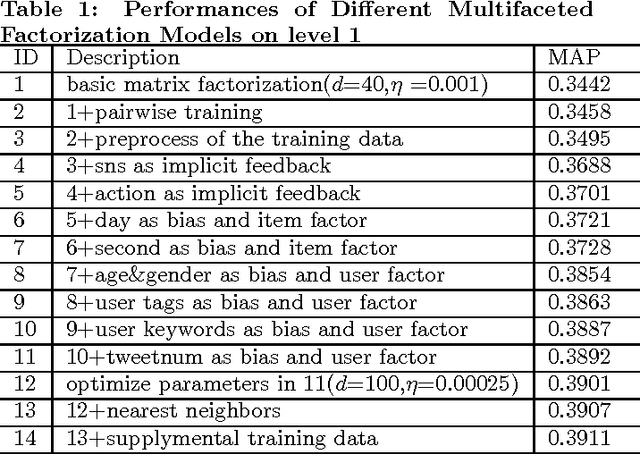
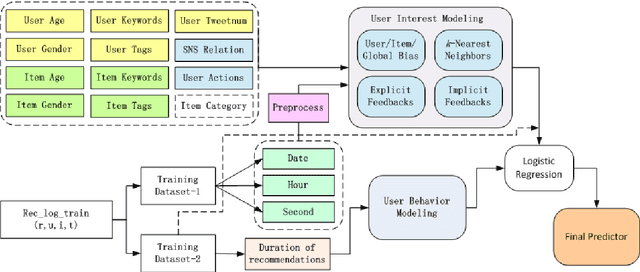

This paper describes the solution of Shanda Innovations team to Task 1 of KDD-Cup 2012. A novel approach called Multifaceted Factorization Models is proposed to incorporate a great variety of features in social networks. Social relationships and actions between users are integrated as implicit feedbacks to improve the recommendation accuracy. Keywords, tags, profiles, time and some other features are also utilized for modeling user interests. In addition, user behaviors are modeled from the durations of recommendation records. A context-aware ensemble framework is then applied to combine multiple predictors and produce final recommendation results. The proposed approach obtained 0.43959 (public score) / 0.41874 (private score) on the testing dataset, which achieved the 2nd place in the KDD-Cup competition.
Neural Feature Selection for Learning to Rank
Feb 22, 2021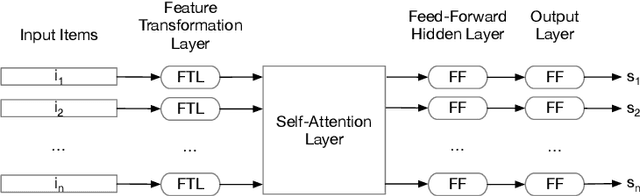
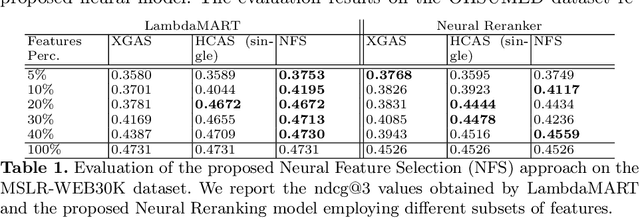
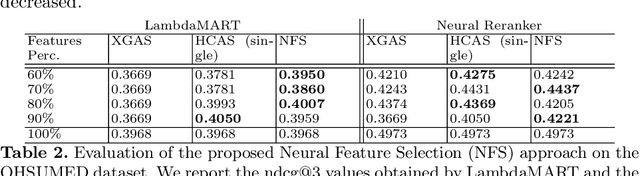
LEarning TO Rank (LETOR) is a research area in the field of Information Retrieval (IR) where machine learning models are employed to rank a set of items. In the past few years, neural LETOR approaches have become a competitive alternative to traditional ones like LambdaMART. However, neural architectures performance grew proportionally to their complexity and size. This can be an obstacle for their adoption in large-scale search systems where a model size impacts latency and update time. For this reason, we propose an architecture-agnostic approach based on a neural LETOR model to reduce the size of its input by up to 60% without affecting the system performance. This approach also allows to reduce a LETOR model complexity and, therefore, its training and inference time up to 50%.
Real-time Data Driven Precision Estimator for RAVEN-II Surgical Robot End Effector Position
Oct 14, 2019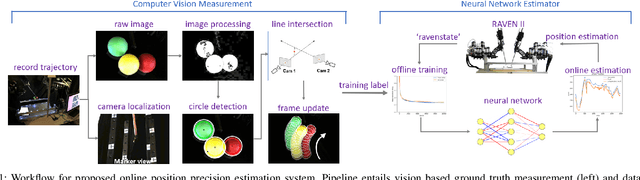
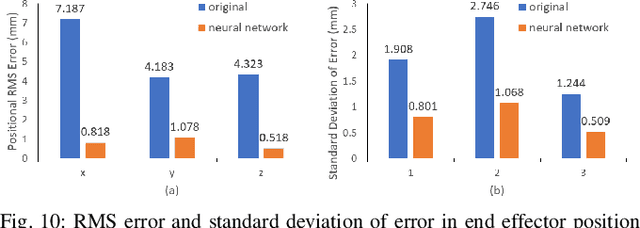
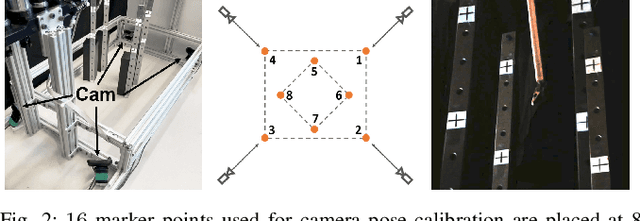

Surgical robots have been introduced to operating rooms over the past few decades due to their high sensitivity, small size, and remote controllability. The cable-driven nature of many surgical robots allows the systems to be dexterous and lightweight, with diameters as low as 5mm. However, due to the slack and stretch of the cables and the backlash of the gears, inevitable uncertainties are brought into the kinematics calculation. Since the reported end effector position of surgical robots like RAVEN-II is directly calculated using the motor encoder measurements and forward kinematics, it may contain relatively large error up to 10mm, whereas semi-autonomous functions being introduced into abdominal surgeries require position inaccuracy of at most 1mm. To resolve the problem, a cost-effective, real-time and data-driven pipeline for robot end effector position precision estimation is proposed and tested on RAVEN-II. Analysis shows an improved end effector position error of around 1mm RMS traversing through the entire robot workspace without high-resolution motion tracker.
Federated Graph Classification over Non-IID Graphs
Jun 25, 2021
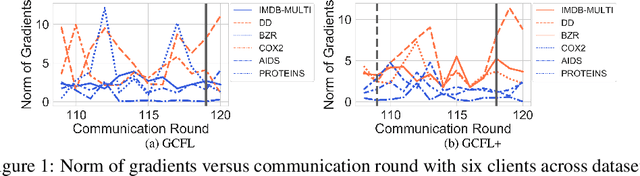

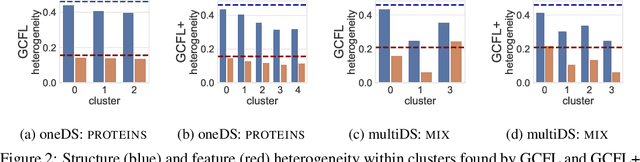
Federated learning has emerged as an important paradigm for training machine learning models in different domains. For graph-level tasks such as graph classification, graphs can also be regarded as a special type of data samples, which can be collected and stored in separate local systems. Similar to other domains, multiple local systems, each holding a small set of graphs, may benefit from collaboratively training a powerful graph mining model, such as the popular graph neural networks (GNNs). To provide more motivation towards such endeavors, we analyze real-world graphs from different domains to confirm that they indeed share certain graph properties that are statistically significant compared with random graphs. However, we also find that different sets of graphs, even from the same domain or same dataset, are non-IID regarding both graph structures and node features. To handle this, we propose a graph clustering federated learning (GCFL) framework that dynamically finds clusters of local systems based on the gradients of GNNs, and theoretically justify that such clusters can reduce the structure and feature heterogeneity among graphs owned by the local systems. Moreover, we observe the gradients of GNNs to be rather fluctuating in GCFL which impedes high-quality clustering, and design a gradient sequence-based clustering mechanism based on dynamic time warping (GCFL+). Extensive experimental results and in-depth analysis demonstrate the effectiveness of our proposed frameworks.
Explicit Basis Function Kernel Methods for Cloud Segmentation in Infrared Sky Images
Feb 12, 2021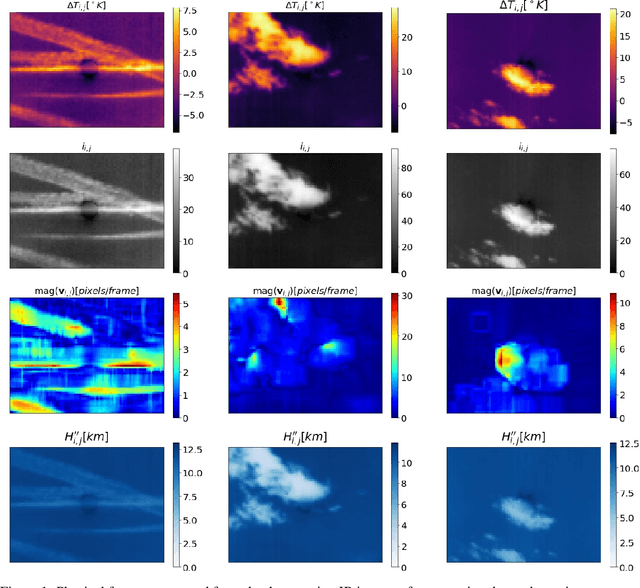
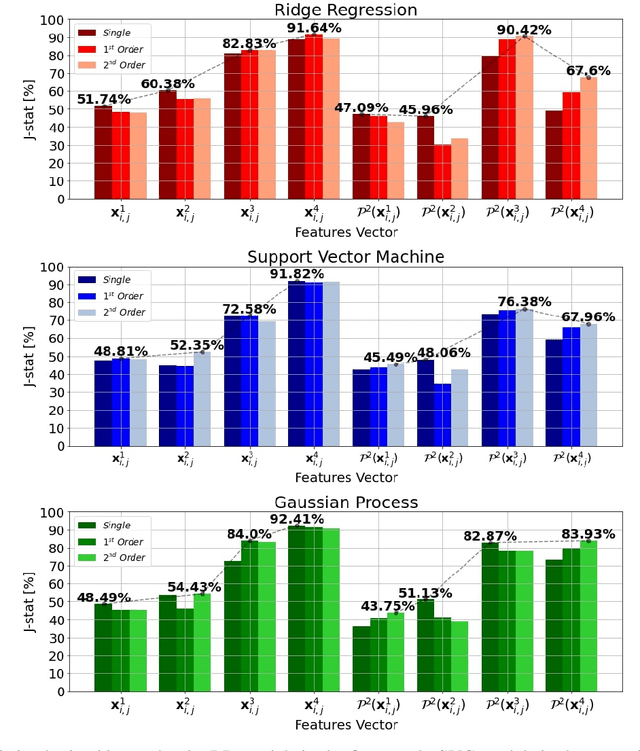

Photovoltaic (PV) systems are sensitive to cloud shadow projection, which needs to be forecasted to reduce the noise impacting the short-term forecast of Global Solar Irradiance (GSI). We present a comparison between different kernel discriminative models for cloud detection. The models are solved in the primal formulation to make them feasible in real-time applications. The performances are compared using the j-statistic. The Infrared (IR) images have been preprocessed to remove debris, which increases the performance of the analyzed methods. The use of the pixels neighboring features also leads to a performance improvement. Discriminative models solved in the primal yield a dramatically lower computing time along with high performance in the segmentation.
PPDM: Parallel Point Detection and Matching for Real-time Human-Object Interaction Detection
Dec 30, 2019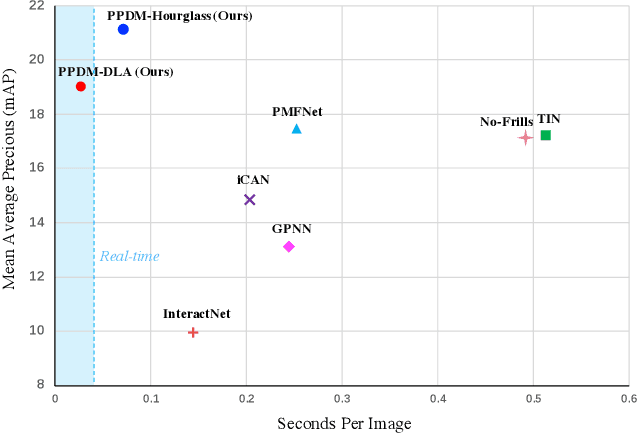
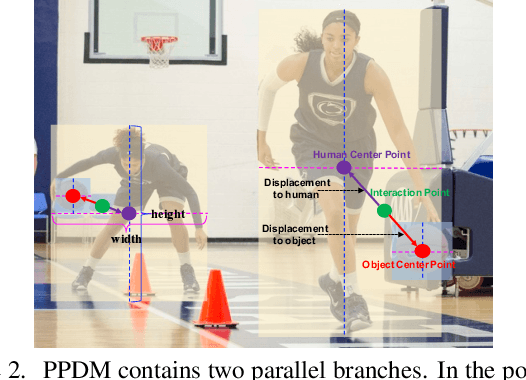
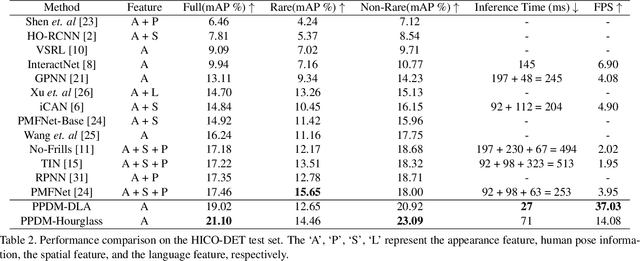
We propose a single-stage Human-Object Interaction (HOI) detection method that has outperformed all existing methods on HICO-DET dataset at 37 fps on a single Titan XP GPU. It is the first real-time HOI detection method. Conventional HOI detection methods are composed of two stages, i.e., human-object proposals generation, and proposals classification. Their effectiveness and efficiency are limited by the sequential and separate architecture. In this paper, we propose a Parallel Point Detection and Matching (PPDM) HOI detection framework. In PPDM, an HOI is defined as a point triplet < human point, interaction point, object point>. Human and object points are the center of the detection boxes, and the interaction point is the midpoint of the human and object points. PPDM contains two parallel branches, namely point detection branch and point matching branch. The point detection branch predicts three points. Simultaneously, the point matching branch predicts two displacements from the interaction point to its corresponding human and object points. The human point and the object point originated from the same interaction point are considered as matched pairs. In our novel parallel architecture, the interaction points implicitly provide context and regularization for human and object detection. The isolated detection boxes are unlikely to form meaning HOI triplets are suppressed, which increases the precision of HOI detection. Moreover, the matching between human and object detection boxes is only applied around limited numbers of filtered candidate interaction points, which saves much computational cost. Additionally, we build a new applicationoriented database named HOI-A, which severs as a good supplement to the existing datasets. The source code and the dataset will be made publicly available to facilitate the development of HOI detection.
A Classical Search Game in Discrete Locations
Mar 08, 2021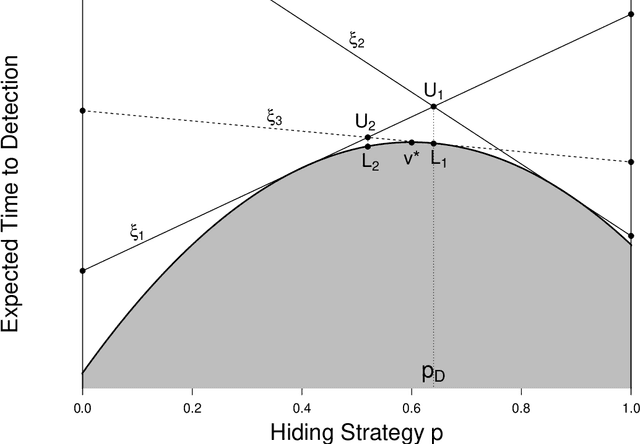
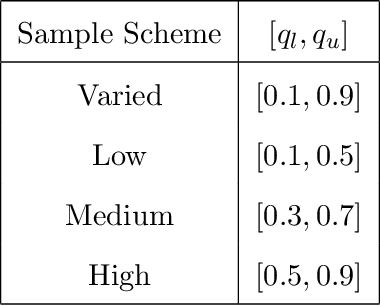
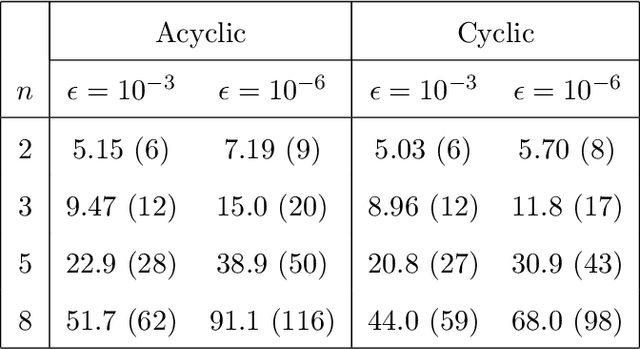
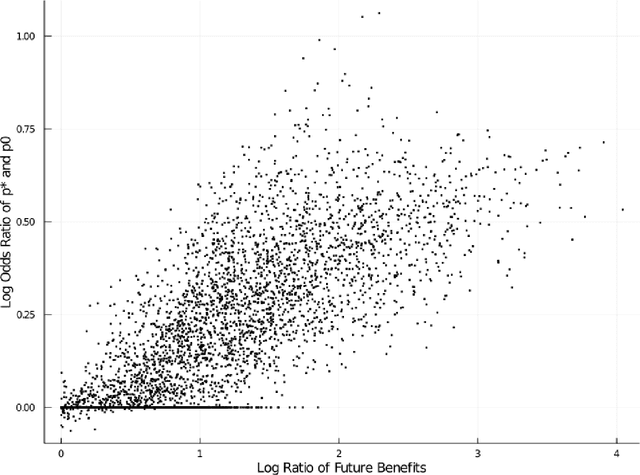
Consider a two-person zero-sum search game between a hider and a searcher. The hider hides among $n$ discrete locations, and the searcher successively visits individual locations until finding the hider. Known to both players, a search at location $i$ takes $t_i$ time units and detects the hider -- if hidden there -- independently with probability $q_i$, for $i=1,\ldots,n$. The hider aims to maximize the expected time until detection, while the searcher aims to minimize it. We prove the existence of an optimal strategy for each player. In particular, the hider's optimal mixed strategy hides in each location with a nonzero probability, and the searcher's optimal mixed strategy can be constructed with up to $n$ simple search sequences. We develop an algorithm to compute an optimal strategy for each player, and compare the optimal hiding strategy with the simple hiding strategy which gives the searcher no location preference at the beginning of the search.