 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Adiabatic Theorem for Policy Tracking with TD-learning
Oct 30, 2020
We evaluate the ability of temporal difference learning to track the reward function of a policy as it changes over time. Our results apply a new adiabatic theorem that bounds the mixing time of time-inhomogeneous Markov chains. We derive finite-time bounds for tabular temporal difference learning and $Q$-learning when the policy used for training changes in time. To achieve this, we develop bounds for stochastic approximation under asynchronous adiabatic updates.
Bilateral Grid Learning for Stereo Matching Network
Jan 01, 2021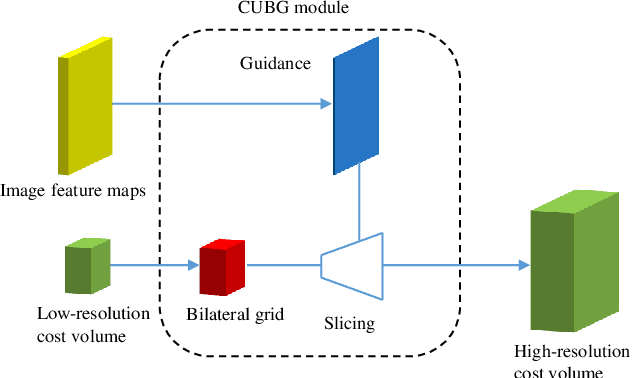
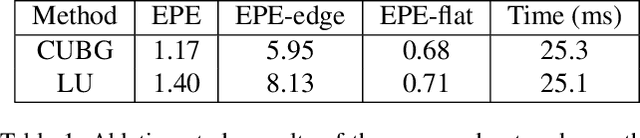
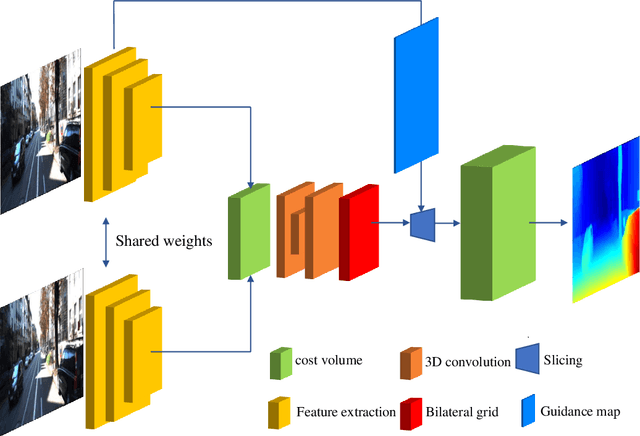
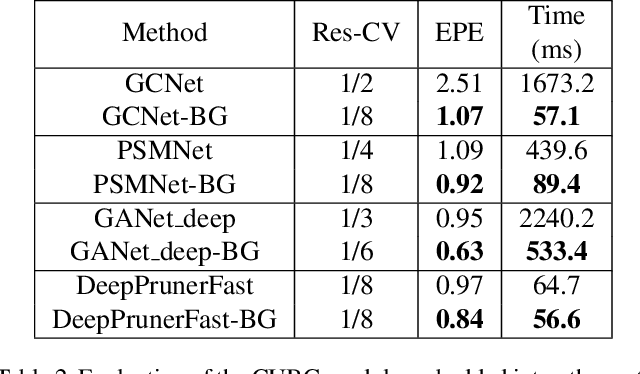
The real-time performance of the stereo matching network is important for many applications, such as automatic driving, robot navigation and augmented reality (AR). Although significant progress has been made in stereo matching networks in recent years, it is still challenging to balance real-time performance and accuracy. In this paper, we present a novel edge-preserving cost volume upsampling module based on the slicing operation in the learned bilateral grid. The slicing layer is parameter-free, which allows us to obtain a high quality cost volume of high resolution from a low resolution cost volume under the guide of the learned guidance map efficiently. The proposed cost volume upsampling module can be seamlessly embedded into many existing stereo matching networks, such as GCNet, PSMNet, and GANet. The resulting networks are accelerated several times while maintaining comparable accuracy. Furthermore, based on this module we design a real-time network (named BGNet), which outperforms the existing published real-time deep stereo matching networks, as well as some complex networks on KITTI stereo datasets. The code of the proposed method will be available.
Medical Image Analysis on Left Atrial LGE MRI for Atrial Fibrillation Studies: A Review
Jun 25, 2021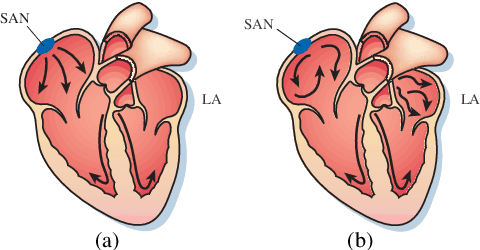
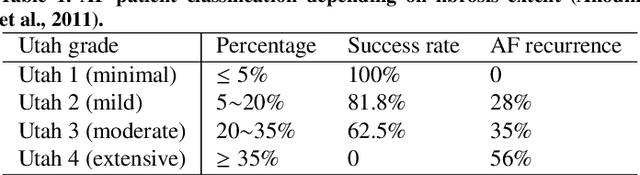
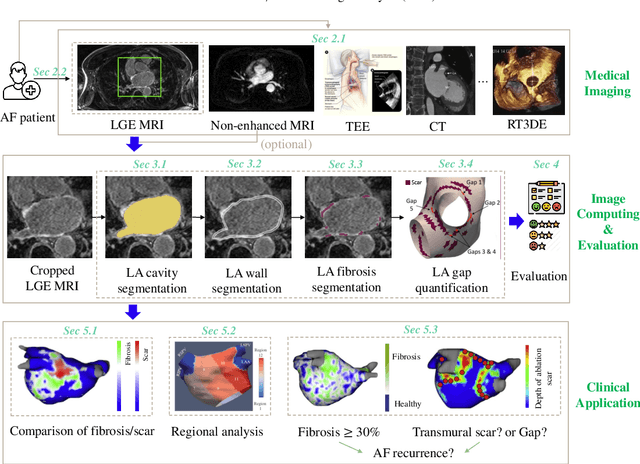

Late gadolinium enhancement magnetic resonance imaging (LGE MRI) is commonly used to visualize and quantify left atrial (LA) scars. The position and extent of scars provide important information of the pathophysiology and progression of atrial fibrillation (AF). Hence, LA scar segmentation and quantification from LGE MRI can be useful in computer-assisted diagnosis and treatment stratification of AF patients. Since manual delineation can be time-consuming and subject to intra- and inter-expert variability, automating this computing is highly desired, which nevertheless is still challenging and under-researched. This paper aims to provide a systematic review on computing methods for LA cavity, wall, scar and ablation gap segmentation and quantification from LGE MRI, and the related literature for AF studies. Specifically, we first summarize AF-related imaging techniques, particularly LGE MRI. Then, we review the methodologies of the four computing tasks in detail, and summarize the validation strategies applied in each task. Finally, the possible future developments are outlined, with a brief survey on the potential clinical applications of the aforementioned methods. The review shows that the research into this topic is still in early stages. Although several methods have been proposed, especially for LA segmentation, there is still large scope for further algorithmic developments due to performance issues related to the high variability of enhancement appearance and differences in image acquisition.
OneLog: Towards End-to-End Training in Software Log Anomaly Detection
Apr 15, 2021
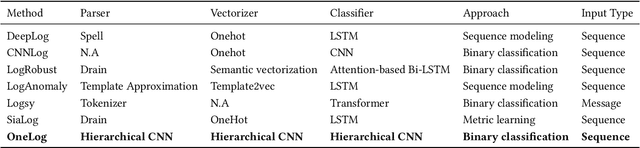


In recent years, with the growth of online services and IoT devices, software log anomaly detection has become a significant concern for both academia and industry. However, at the time of writing this paper, almost all contributions to the log anomaly detection task, follow the same traditional architecture based on parsing, vectorizing, and classifying. This paper proposes OneLog, a new approach that uses a large deep model based on instead of multiple small components. OneLog utilizes a character-based convolutional neural network (CNN) originating from traditional NLP tasks. This allows the model to take advantage of multiple datasets at once and take advantage of numbers and punctuations, which were removed in previous architectures. We evaluate OneLog using four open data sets Hadoop Distributed File System (HDFS), BlueGene/L (BGL), Hadoop, and OpenStack. We evaluate our model with single and multi-project datasets. Additionally, we evaluate robustness with synthetically evolved datasets and ahead-of-time anomaly detection test that indicates capabilities to predict anomalies before occurring. To the best of our knowledge, our multi-project model outperforms state-of-the-art methods in HDFS, Hadoop, and BGL datasets, respectively setting getting F1 scores of 99.99, 99.99, and 99.98. However, OneLog's performance on the Openstack is unsatisfying with F1 score of only 21.18. Furthermore, Onelogs performance suffers very little from noise showing F1 scores of 99.95, 99.92, and 99.98 in HDFS, Hadoop, and BGL.
How to Decompose a Tensor with Group Structure
Jun 04, 2021In this work we study the orbit recovery problem, which is a natural abstraction for the problem of recovering a planted signal from noisy measurements under unknown group actions. Many important inverse problems in statistics, engineering and the sciences fit into this framework. Prior work has studied cases when the group is discrete and/or abelian. However fundamentally new techniques are needed in order to handle more complex group actions. Our main result is a quasi-polynomial time algorithm to solve orbit recovery over $SO(3)$ - i.e. the cryo-electron tomography problem which asks to recover the three-dimensional structure of a molecule from noisy measurements of randomly rotated copies of it. We analyze a variant of the frequency marching heuristic in the framework of smoothed analysis. Our approach exploits the layered structure of the invariant polynomials, and simultaneously yields a new class of tensor decomposition algorithms that work in settings when the tensor is not low-rank but rather where the factors are algebraically related to each other by a group action.
Fast and Effective Biomedical Entity Linking Using a Dual Encoder
Mar 08, 2021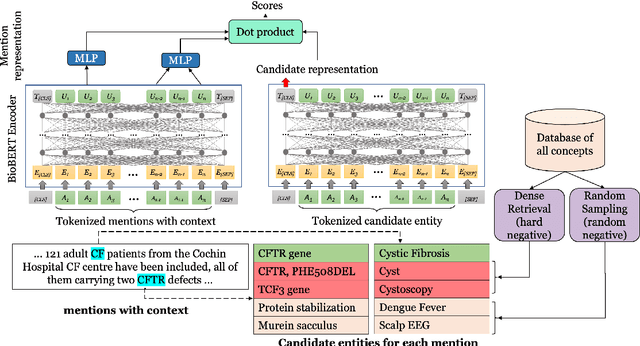

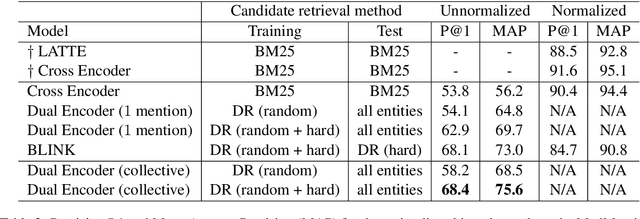
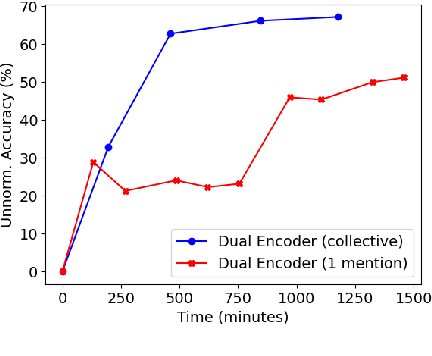
Biomedical entity linking is the task of identifying mentions of biomedical concepts in text documents and mapping them to canonical entities in a target thesaurus. Recent advancements in entity linking using BERT-based models follow a retrieve and rerank paradigm, where the candidate entities are first selected using a retriever model, and then the retrieved candidates are ranked by a reranker model. While this paradigm produces state-of-the-art results, they are slow both at training and test time as they can process only one mention at a time. To mitigate these issues, we propose a BERT-based dual encoder model that resolves multiple mentions in a document in one shot. We show that our proposed model is multiple times faster than existing BERT-based models while being competitive in accuracy for biomedical entity linking. Additionally, we modify our dual encoder model for end-to-end biomedical entity linking that performs both mention span detection and entity disambiguation and out-performs two recently proposed models.
Collision Replay: What Does Bumping Into Things Tell You About Scene Geometry?
May 03, 2021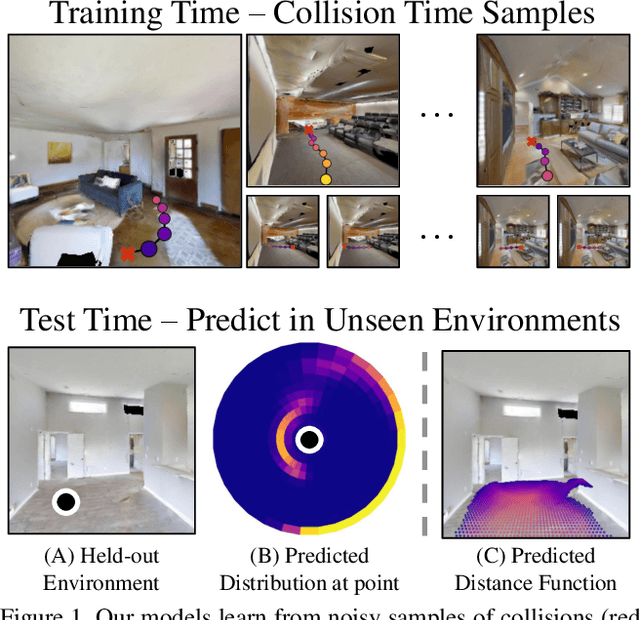
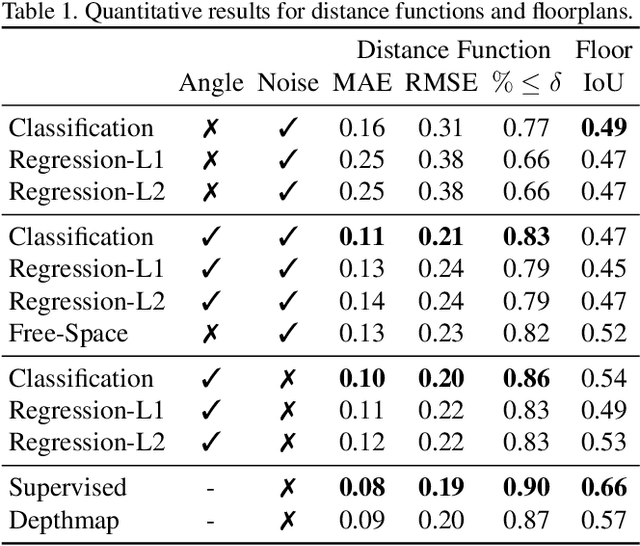
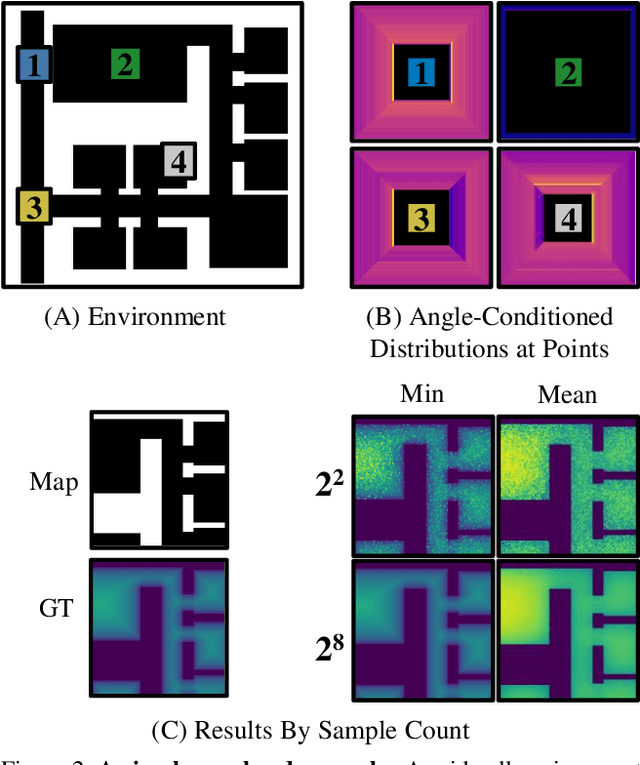
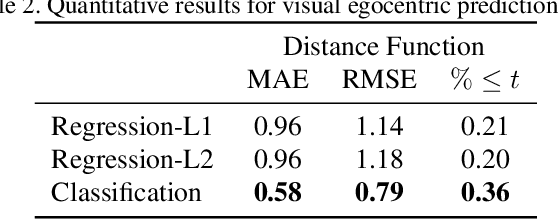
What does bumping into things in a scene tell you about scene geometry? In this paper, we investigate the idea of learning from collisions. At the heart of our approach is the idea of collision replay, where we use examples of a collision to provide supervision for observations at a past frame. We use collision replay to train convolutional neural networks to predict a distribution over collision time from new images. This distribution conveys information about the navigational affordances (e.g., corridors vs open spaces) and, as we show, can be converted into the distance function for the scene geometry. We analyze this approach with an agent that has noisy actuation in a photorealistic simulator.
Hierarchical Object-oriented Spatio-Temporal Reasoning for Video Question Answering
Jun 25, 2021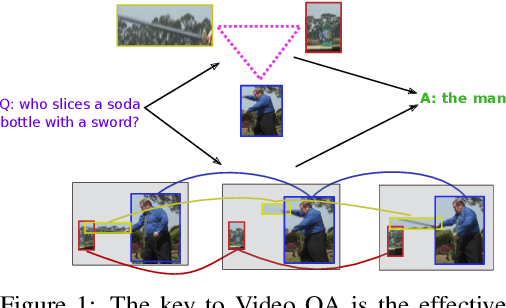
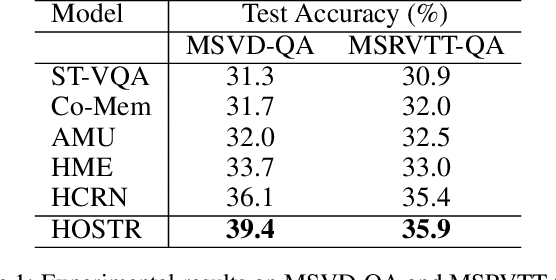
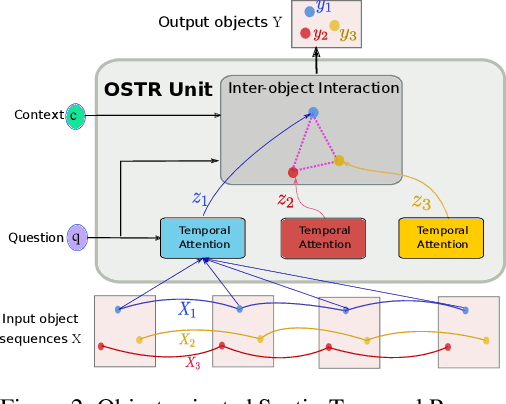
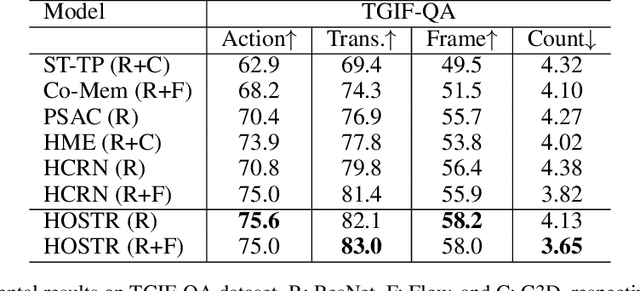
Video Question Answering (Video QA) is a powerful testbed to develop new AI capabilities. This task necessitates learning to reason about objects, relations, and events across visual and linguistic domains in space-time. High-level reasoning demands lifting from associative visual pattern recognition to symbol-like manipulation over objects, their behavior and interactions. Toward reaching this goal we propose an object-oriented reasoning approach in that video is abstracted as a dynamic stream of interacting objects. At each stage of the video event flow, these objects interact with each other, and their interactions are reasoned about with respect to the query and under the overall context of a video. This mechanism is materialized into a family of general-purpose neural units and their multi-level architecture called Hierarchical Object-oriented Spatio-Temporal Reasoning (HOSTR) networks. This neural model maintains the objects' consistent lifelines in the form of a hierarchically nested spatio-temporal graph. Within this graph, the dynamic interactive object-oriented representations are built up along the video sequence, hierarchically abstracted in a bottom-up manner, and converge toward the key information for the correct answer. The method is evaluated on multiple major Video QA datasets and establishes new state-of-the-arts in these tasks. Analysis into the model's behavior indicates that object-oriented reasoning is a reliable, interpretable and efficient approach to Video QA.
Signal Transformer: Complex-valued Attention and Meta-Learning for Signal Recognition
Jun 12, 2021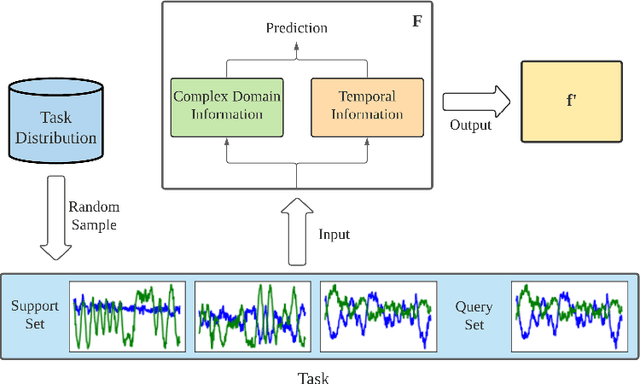
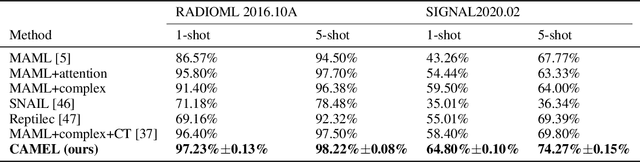

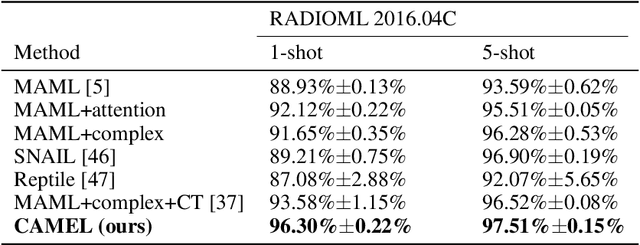
Deep neural networks have been shown as a class of useful tools for addressing signal recognition issues in recent years, especially for identifying the nonlinear feature structures of signals. However, this power of most deep learning techniques heavily relies on an abundant amount of training data, so the performance of classic neural nets decreases sharply when the number of training data samples is small or unseen data are presented in the testing phase. This calls for an advanced strategy, i.e., model-agnostic meta-learning (MAML), which is able to capture the invariant representation of the data samples or signals. In this paper, inspired by the special structure of the signal, i.e., real and imaginary parts consisted in practical time-series signals, we propose a Complex-valued Attentional MEta Learner (CAMEL) for the problem of few-shot signal recognition by leveraging attention and meta-learning in the complex domain. To the best of our knowledge, this is also the first complex-valued MAML that can find the first-order stationary points of general nonconvex problems with theoretical convergence guarantees. Extensive experiments results showcase the superiority of the proposed CAMEL compared with the state-of-the-art methods.
Leveraging Deep Representations of Radiology Reports in Survival Analysis for Predicting Heart Failure Patient Mortality
May 03, 2021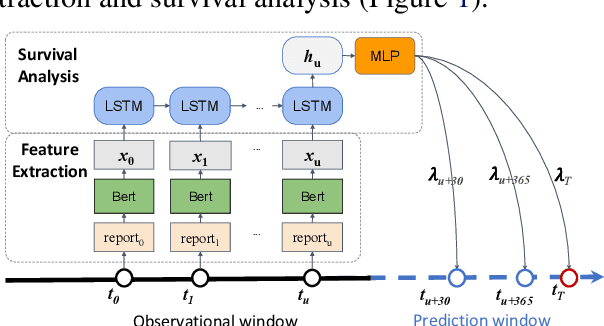
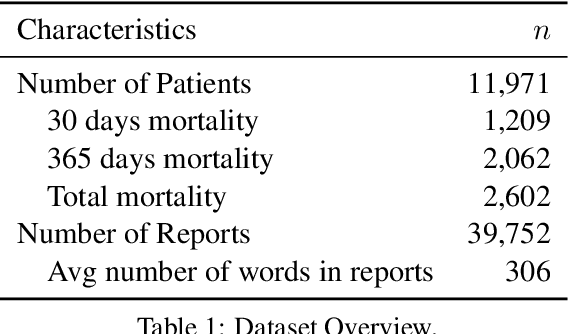
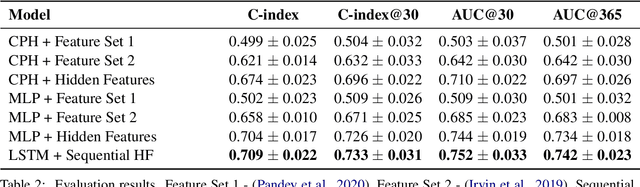
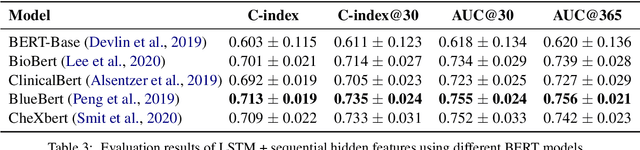
Utilizing clinical texts in survival analysis is difficult because they are largely unstructured. Current automatic extraction models fail to capture textual information comprehensively since their labels are limited in scope. Furthermore, they typically require a large amount of data and high-quality expert annotations for training. In this work, we present a novel method of using BERT-based hidden layer representations of clinical texts as covariates for proportional hazards models to predict patient survival outcomes. We show that hidden layers yield notably more accurate predictions than predefined features, outperforming the previous baseline model by 5.7% on average across C-index and time-dependent AUC. We make our work publicly available at https://github.com/bionlplab/heart_failure_mortality.