 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ChronoR: Rotation Based Temporal Knowledge Graph Embedding
Mar 18, 2021

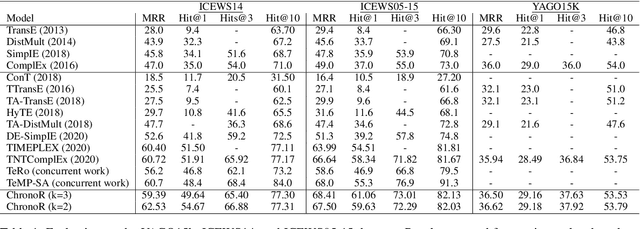

Despite the importance and abundance of temporal knowledge graphs, most of the current research has been focused on reasoning on static graphs. In this paper, we study the challenging problem of inference over temporal knowledge graphs. In particular, the task of temporal link prediction. In general, this is a difficult task due to data non-stationarity, data heterogeneity, and its complex temporal dependencies. We propose Chronological Rotation embedding (ChronoR), a novel model for learning representations for entities, relations, and time. Learning dense representations is frequently used as an efficient and versatile method to perform reasoning on knowledge graphs. The proposed model learns a k-dimensional rotation transformation parametrized by relation and time, such that after each fact's head entity is transformed using the rotation, it falls near its corresponding tail entity. By using high dimensional rotation as its transformation operator, ChronoR captures rich interaction between the temporal and multi-relational characteristics of a Temporal Knowledge Graph. Experimentally, we show that ChronoR is able to outperform many of the state-of-the-art methods on the benchmark datasets for temporal knowledge graph link prediction.
Parameterized and GPU-Parallelized Real-Time Model Predictive Control for High Degree of Freedom Robots
Jan 14, 2020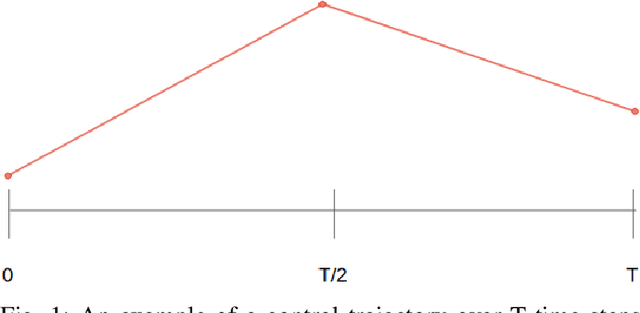
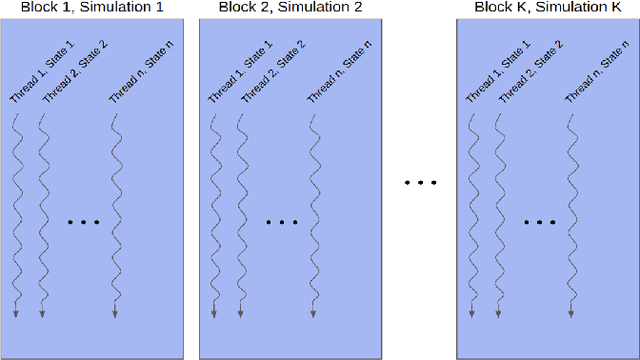
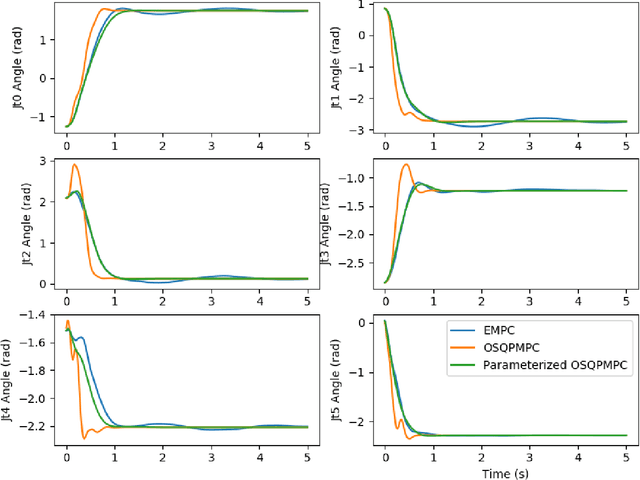
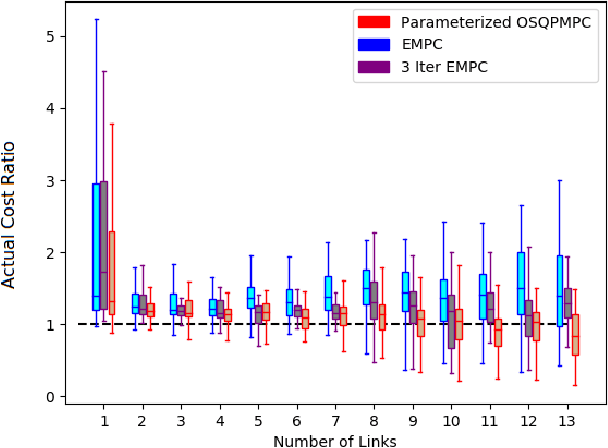
This work presents and evaluates a novel input parameterization method which improves the tractability of model predictive control (MPC) for high degree of freedom (DoF) robots. Experimental results demonstrate that by parameterizing the input trajectory more than three quarters of the optimization variables used in traditional MPC can be eliminated with practically no effect on system performance. This parameterization also leads to trajectories which are more conservative, producing less overshoot in underdamped systems with modeling error. In this paper we present two MPC solution methods that make use of this parameterization. The first uses a convex solver, and the second makes use of parallel computing on a graphics processing unit (GPU). We show that both approaches drastically reduce solve times for large DoF, long horizon MPC problems allowing solutions at real-time rates. Through simulation and hardware experiments, we show that the parameterized convex solver MPC has faster solve times than traditional MPC for high DoF cases while still achieving similar performance. For the GPU-based MPC solution method, we use an evolutionary algorithm and that we call Evolutionary MPC (EMPC). EMPC is shown to have even faster solve times for high DoF systems. Solve times for EMPC are shown to decrease even further through the use of a more powerful GPU. This suggests that parallelized MPC methods will become even more advantageous with the improvement and prevalence of GPU technology.
Editing Factual Knowledge in Language Models
Apr 16, 2021
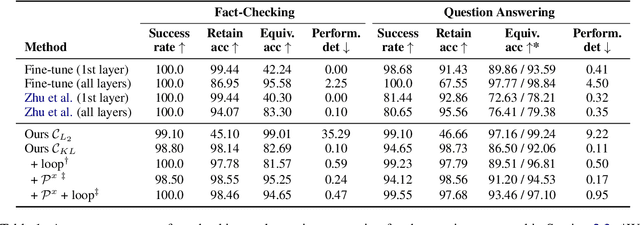

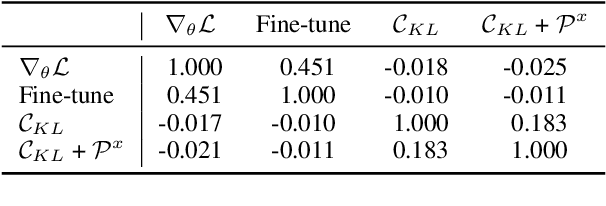
The factual knowledge acquired during pretraining and stored in the parameters of Language Models (LM) can be useful in downstream tasks (e.g., question answering or textual inference). However, some facts can be incorrectly induced or become obsolete over time. We present KnowledgeEditor, a method that can be used to edit this knowledge and, thus, fix 'bugs' or unexpected predictions without the need for expensive re-training or fine-tuning. Besides being computationally efficient, KnowledgeEditor does not require any modifications in LM pre-training (e.g., the use of meta-learning). In our approach, we train a hyper-network with constrained optimization to modify a fact without affecting the rest of the knowledge; the trained hyper-network is then used to predict the weight update at test time. We show KnowledgeEditor's efficacy with two popular architectures and knowledge-intensive tasks: i) a BERT model fine-tuned for fact-checking, and ii) a sequence-to-sequence BART model for question answering. With our method, changing a prediction on the specific wording of a query tends to result in a consistent change in predictions also for its paraphrases. We show that this can be further encouraged by exploiting (e.g., automatically-generated) paraphrases during training. Interestingly, our hyper-network can be regarded as a 'probe' revealing which components of a model need to be changed to manipulate factual knowledge; our analysis shows that the updates tend to be concentrated on a small subset of components. Code at https://github.com/nicola-decao/KnowledgeEditor
A PAC-Bayes Analysis of Adversarial Robustness
Feb 19, 2021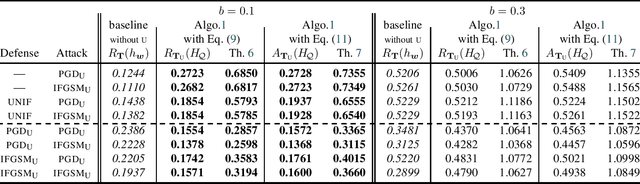
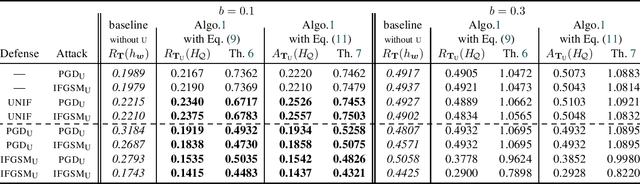
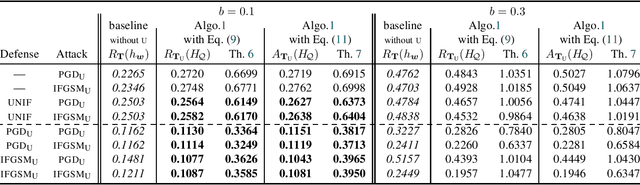
We propose the first general PAC-Bayesian generalization bounds for adversarial robustness, that estimate, at test time, how much a model will be invariant to imperceptible perturbations in the input. Instead of deriving a worst-case analysis of the risk of a hypothesis over all the possible perturbations, we leverage the PAC-Bayesian framework to bound the averaged risk on the perturbations for majority votes (over the whole class of hypotheses). Our theoretically founded analysis has the advantage to provide general bounds (i) independent from the type of perturbations (i.e., the adversarial attacks), (ii) that are tight thanks to the PAC-Bayesian framework, (iii) that can be directly minimized during the learning phase to obtain a robust model on different attacks at test time.
Prediction of Blood Lactate Values in Critically Ill Patients: A Retrospective Multi-center Cohort Study
Jul 07, 2021
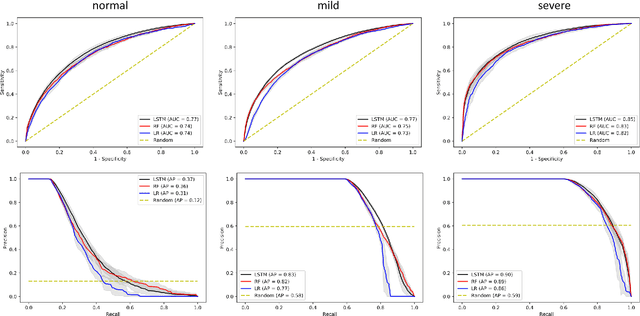
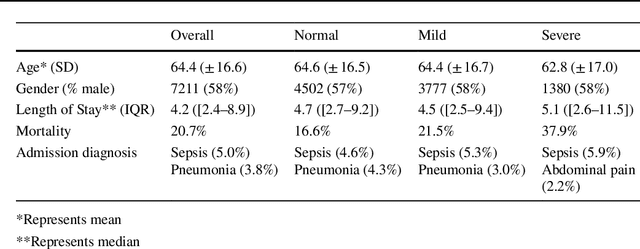
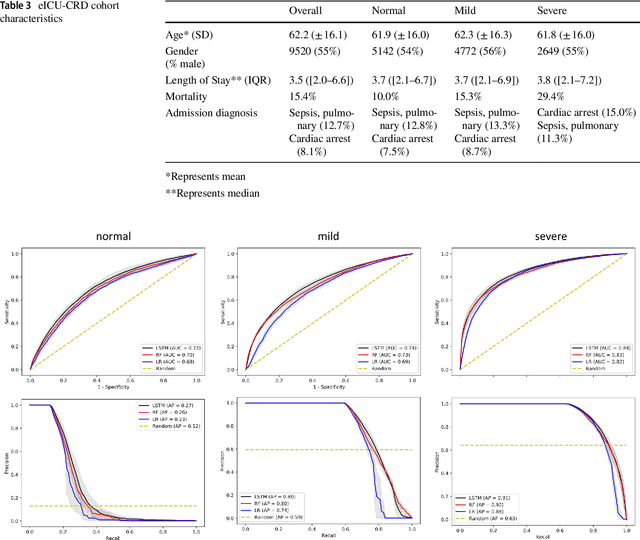
Purpose. Elevations in initially obtained serum lactate levels are strong predictors of mortality in critically ill patients. Identifying patients whose serum lactate levels are more likely to increase can alert physicians to intensify care and guide them in the frequency of tending the blood test. We investigate whether machine learning models can predict subsequent serum lactate changes. Methods. We investigated serum lactate change prediction using the MIMIC-III and eICU-CRD datasets in internal as well as external validation of the eICU cohort on the MIMIC-III cohort. Three subgroups were defined based on the initial lactate levels: i) normal group (<2 mmol/L), ii) mild group (2-4 mmol/L), and iii) severe group (>4 mmol/L). Outcomes were defined based on increase or decrease of serum lactate levels between the groups. We also performed sensitivity analysis by defining the outcome as lactate change of >10% and furthermore investigated the influence of the time interval between subsequent lactate measurements on predictive performance. Results. The LSTM models were able to predict deterioration of serum lactate values of MIMIC-III patients with an AUC of 0.77 (95% CI 0.762-0.771) for the normal group, 0.77 (95% CI 0.768-0.772) for the mild group, and 0.85 (95% CI 0.840-0.851) for the severe group, with a slightly lower performance in the external validation. Conclusion. The LSTM demonstrated good discrimination of patients who had deterioration in serum lactate levels. Clinical studies are needed to evaluate whether utilization of a clinical decision support tool based on these results could positively impact decision-making and patient outcomes.
* 15 pages, 6 Appendices
Controllable Abstractive Dialogue Summarization with Sketch Supervision
May 28, 2021
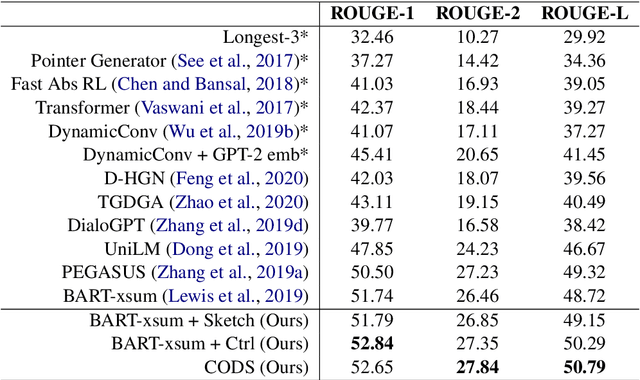
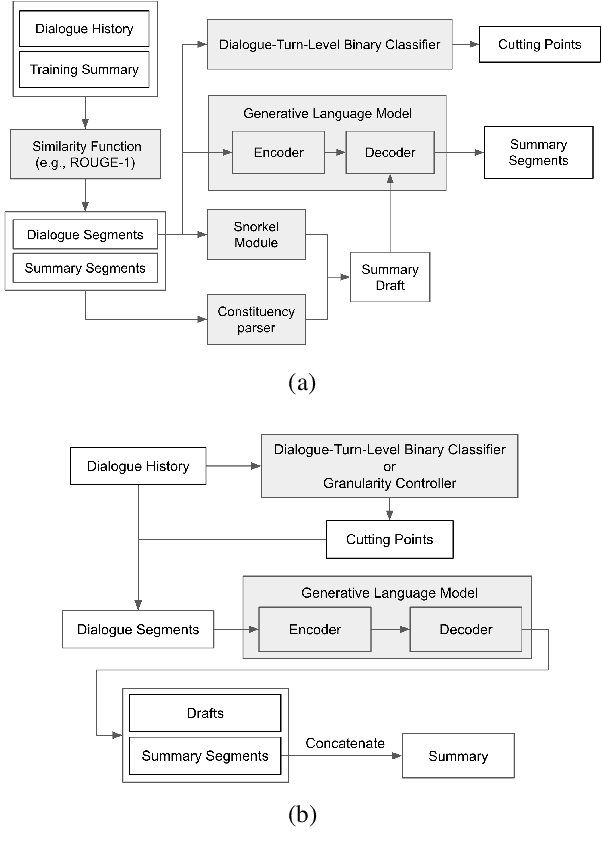

In this paper, we aim to improve abstractive dialogue summarization quality and, at the same time, enable granularity control. Our model has two primary components and stages: 1) a two-stage generation strategy that generates a preliminary summary sketch serving as the basis for the final summary. This summary sketch provides a weakly supervised signal in the form of pseudo-labeled interrogative pronoun categories and key phrases extracted using a constituency parser. 2) A simple strategy to control the granularity of the final summary, in that our model can automatically determine or control the number of generated summary sentences for a given dialogue by predicting and highlighting different text spans from the source text. Our model achieves state-of-the-art performance on the largest dialogue summarization corpus SAMSum, with as high as 50.79 in ROUGE-L score. In addition, we conduct a case study and show competitive human evaluation results and controllability to human-annotated summaries.
Generator Surgery for Compressed Sensing
Mar 01, 2021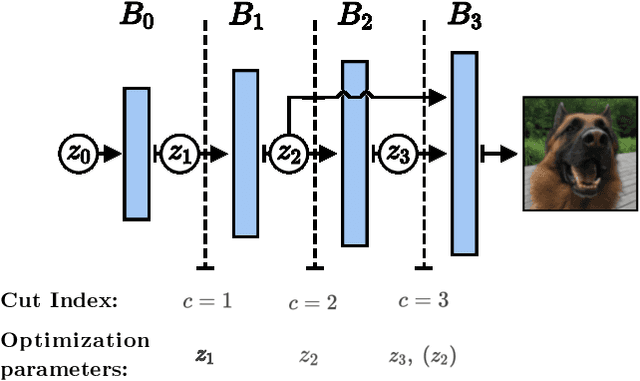
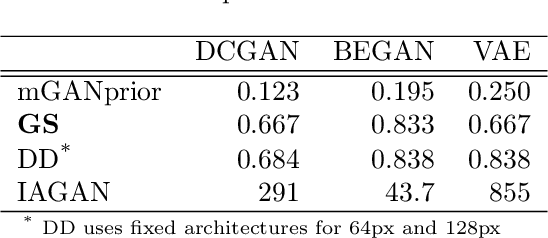
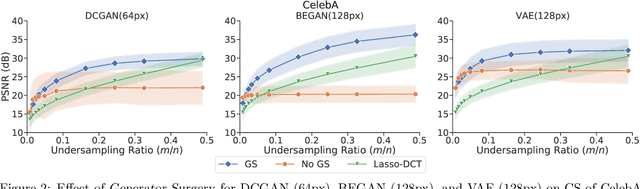
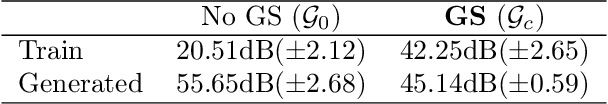
Image recovery from compressive measurements requires a signal prior for the images being reconstructed. Recent work has explored the use of deep generative models with low latent dimension as signal priors for such problems. However, their recovery performance is limited by high representation error. We introduce a method for achieving low representation error using generators as signal priors. Using a pre-trained generator, we remove one or more initial blocks at test time and optimize over the new, higher-dimensional latent space to recover a target image. Experiments demonstrate significantly improved reconstruction quality for a variety of network architectures. This approach also works well for out-of-training-distribution images and is competitive with other state-of-the-art methods. Our experiments show that test-time architectural modifications can greatly improve the recovery quality of generator signal priors for compressed sensing.
Collision Recovery Control of a Foldable Quadrotor
May 28, 2021
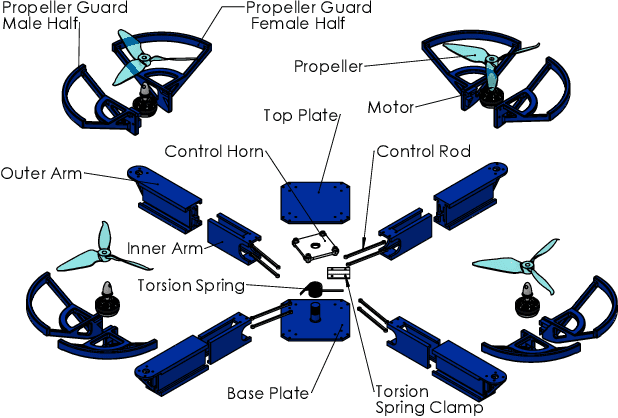
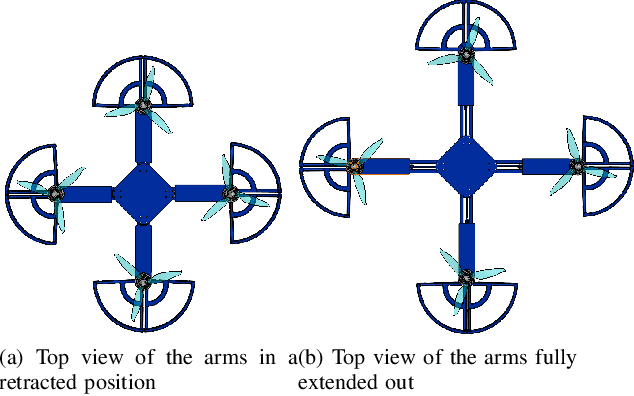
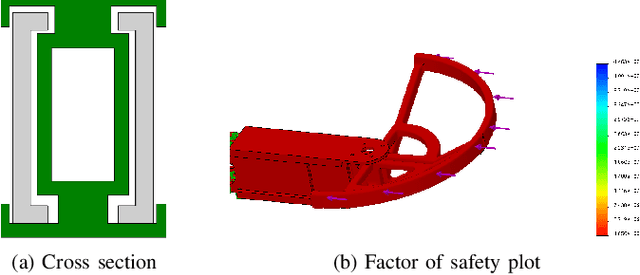
Autonomous missions of small unmanned aerial vehicles (UAVs) are prone to collisions owing to environmental disturbances and localization errors. Consequently, a UAV that can endure collisions and perform recovery control in critical aerial missions is desirable to prevent loss of the vehicle and/or payload. We address this problem by proposing a novel foldable quadrotor system which can sustain collisions and recover safely. The quadrotor is designed with integrated mechanical compliance using a torsional spring such that the impact time is increased and the net impact force on the main body is decreased. The post-collision dynamics is analysed and a recovery controller is proposed which stabilizes the system to a hovering location without additional collisions. Flight test results on the proposed and a conventional quadrotor demonstrate that for the former, integrated spring-damper characteristics reduce the rebound velocity and lead to simple recovery control algorithms in the event of unintended collisions as compared to a rigid quadrotor of the same dimension.
Switching Variational Auto-Encoders for Noise-Agnostic Audio-visual Speech Enhancement
Feb 08, 2021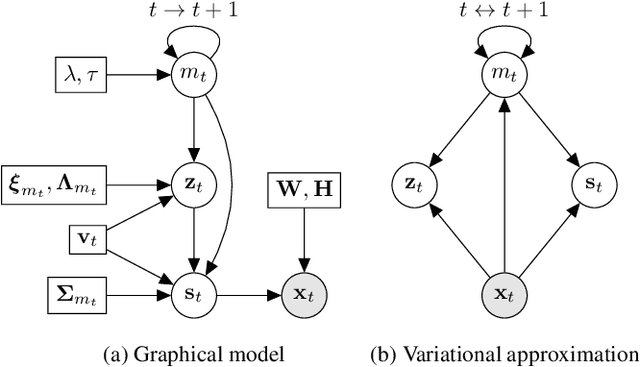

Recently, audio-visual speech enhancement has been tackled in the unsupervised settings based on variational auto-encoders (VAEs), where during training only clean data is used to train a generative model for speech, which at test time is combined with a noise model, e.g. nonnegative matrix factorization (NMF), whose parameters are learned without supervision. Consequently, the proposed model is agnostic to the noise type. When visual data are clean, audio-visual VAE-based architectures usually outperform the audio-only counterpart. The opposite happens when the visual data are corrupted by clutter, e.g. the speaker not facing the camera. In this paper, we propose to find the optimal combination of these two architectures through time. More precisely, we introduce the use of a latent sequential variable with Markovian dependencies to switch between different VAE architectures through time in an unsupervised manner: leading to switching variational auto-encoder (SwVAE). We propose a variational factorization to approximate the computationally intractable posterior distribution. We also derive the corresponding variational expectation-maximization algorithm to estimate the parameters of the model and enhance the speech signal. Our experiments demonstrate the promising performance of SwVAE.
Hair Segmentation on Time-of-Flight RGBD Images
Mar 11, 2019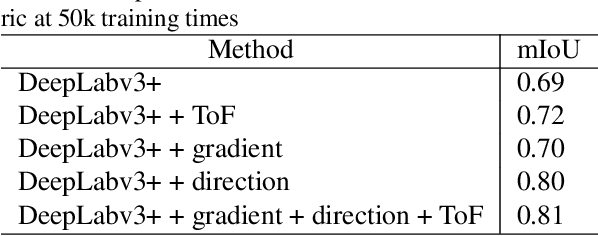
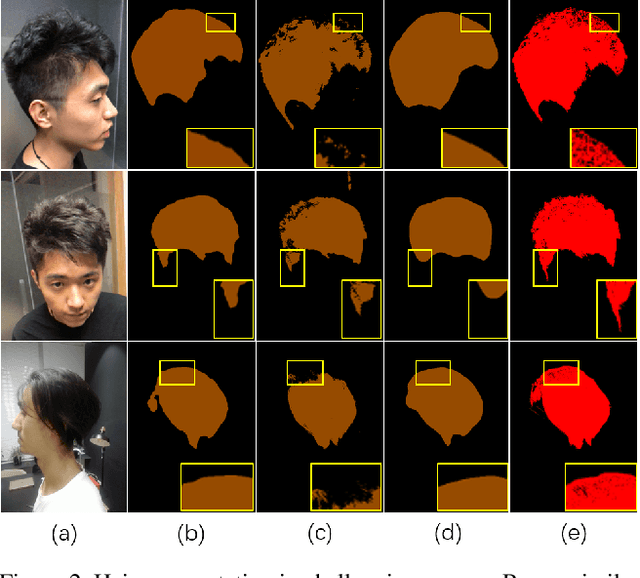
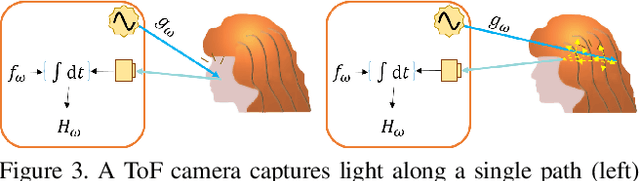
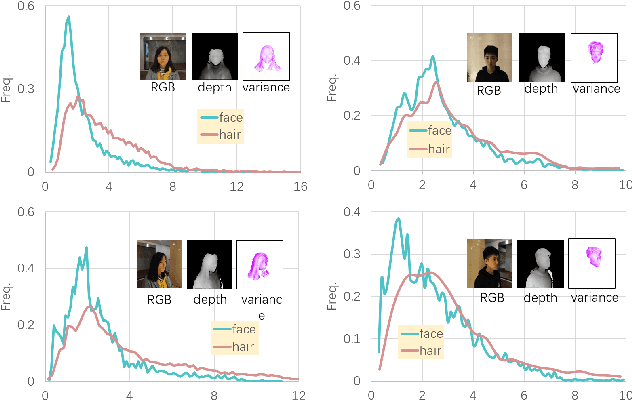
Robust segmentation of hair from portrait images remains challenging: hair does not conform to a uniform shape, style or even color; dark hair in particular lacks features. We present a novel computational imaging solution that tackles the problem from both input and processing fronts. We explore using Time-of-Flight (ToF) RGBD sensors on recent mobile devices. We first conduct a comprehensive analysis to show that scattering and inter-reflection cause different noise patterns on hair vs. non-hair regions on ToF images, by changing the light path and/or combining multiple paths. We then develop a deep network based approach that employs both ToF depth map and the RGB gradient maps to produce an initial hair segmentation with labeled hair components. We then refine the result by imposing ToF noise prior under the conditional random field. We collect the first ToF RGBD hair dataset with 20k+ head images captured on 30 human subjects with a variety of hairstyles at different view angles. Comprehensive experiments show that our approach outperforms the RGB based techniques in accuracy and robustness and can handle traditionally challenging cases such as dark hair, similar hair/background, similar hair/foreground, etc.