 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Minibatch and Momentum Model-based Methods for Stochastic Non-smooth Non-convex Optimization
Jun 06, 2021

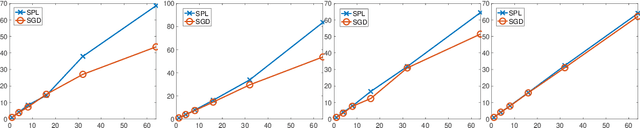
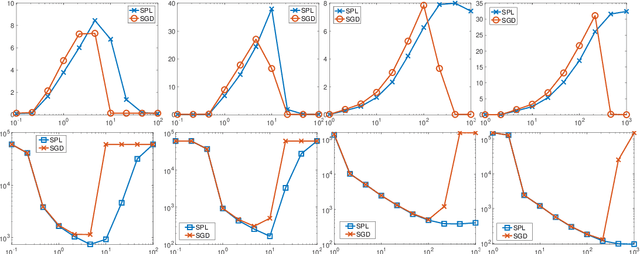

Stochastic model-based methods have received increasing attention lately due to their appealing robustness to the stepsize selection and provable efficiency guarantee for non-smooth non-convex optimization. To further improve the performance of stochastic model-based methods, we make two important extensions. First, we propose a new minibatch algorithm which takes a set of samples to approximate the model function in each iteration. For the first time, we show that stochastic algorithms achieve linear speedup over the batch size even for non-smooth and non-convex problems. To this end, we develop a novel sensitivity analysis of the proximal mapping involved in each algorithm iteration. Our analysis can be of independent interests in more general settings. Second, motivated by the success of momentum techniques for convex optimization, we propose a new stochastic extrapolated model-based method to possibly improve the convergence in the non-smooth and non-convex setting. We obtain complexity guarantees for a fairly flexible range of extrapolation term. In addition, we conduct experiments to show the empirical advantage of our proposed methods.
Grasping force estimation using state-space model and Kalman filter
Jun 26, 2021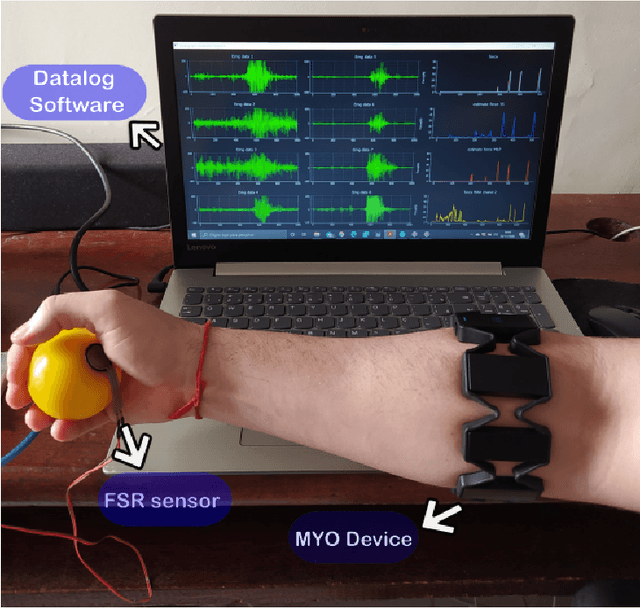
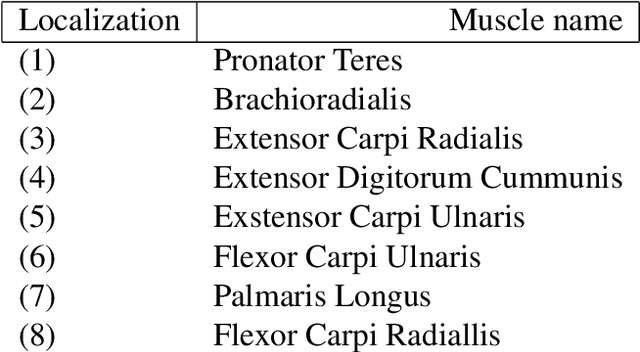
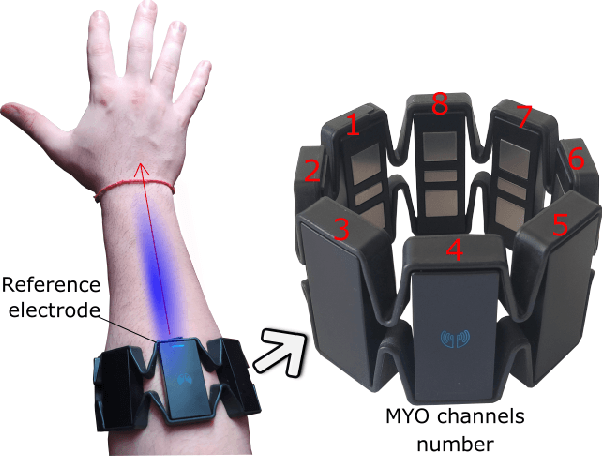
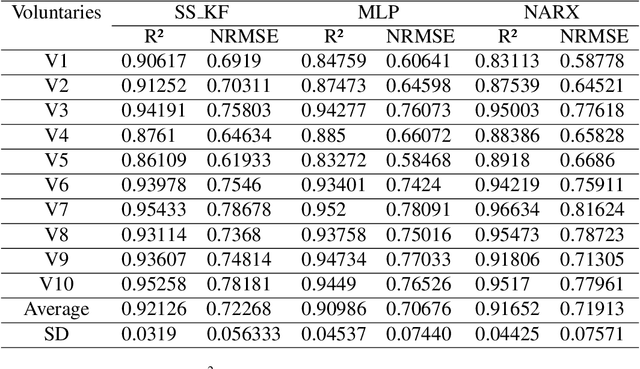
The grip force required to handle an object depends on it mass and the friction between the skin and the object. The control of grip force in myoelectric prosthesis is crucial for handling objects adequately. The current paper proposes a method for improving the estimation of grip force in myoelectric prosthesis based on surface myoelectric (sEMG) recordings. For this purpose, we develop an approach based on multivariable system identification in the state-space (SS) and continuous force estimation with Kalman filter (KF). The sEMG recordings of ten healthy individuals performing a grip task were used as data set for model identification. The root mean square (RMS), the mean absolute value (MAV), and the waveform length (WL) extracted from the sEMG signals were used at the model's input and the measured grasping force was the output. The performance of the proposed method was evaluated using the normalized root-mean-squared-error (NRMSE) and the square of Pearson's correlation coefficient ($ R^2 $). In this study, the CC and NRMSE values were 0.92$ \pm $ 0.0319 and 0.723$ \pm $ 0.0563, respectively. The performance of the system was superior to results obtained with a recurrent nonlinear autoregressive exogenous (NARX)-based neural network and the multi-layer perceptron (MLP) network. The results confirmed that the method is an excellent tool for real-time applications with hand prostheses.
Towards Fast Region Adaptive Ultrasound Beamformer for Plane Wave Imaging Using Convolutional Neural Networks
Jun 13, 2021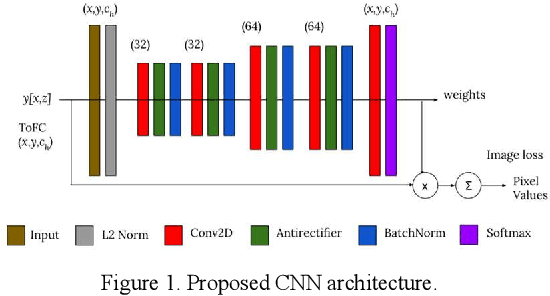

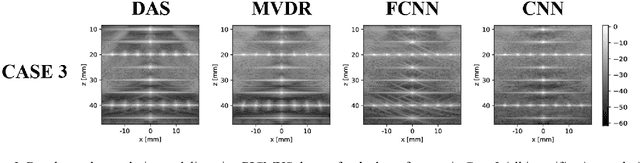
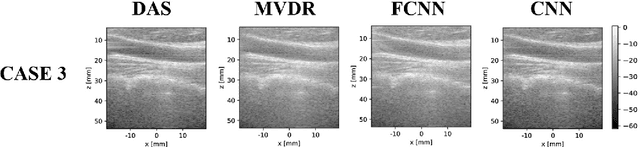
Automatic learning algorithms for improving the image quality of diagnostic B-mode ultrasound (US) images have been gaining popularity in the recent past. In this work, a novel convolutional neural network (CNN) is trained using time of flight corrected in-vivo receiver data of plane wave transmit to produce corresponding high-quality minimum variance distortion less response (MVDR) beamformed image. A comprehensive performance comparison in terms of qualitative and quantitative measures for fully connected neural network (FCNN), the proposed CNN architecture, MVDR and Delay and Sum (DAS) using the dataset from Plane wave Imaging Challenge in Ultrasound (PICMUS) is also reported in this work. The CNN architecture could leverage the spatial information and will be more region adaptive during the beamforming process. This is evident from the improvement seen over the baseline FCNN approach and conventional MVDR beamformer, both in resolution and contrast with an improvement of 6 dB in CNR using only zero-angle transmission over the baseline. With the observed reduction in the requirement of number of angles to produce similar image metrics would prove advantageous in providing a possibility for higher frame rates.
Parameterized and GPU-Parallelized Real-Time Model Predictive Control for High Degree of Freedom Robots
Jan 14, 2020
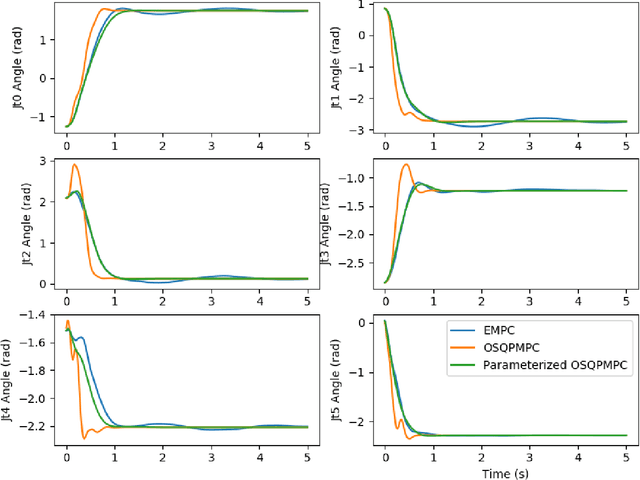
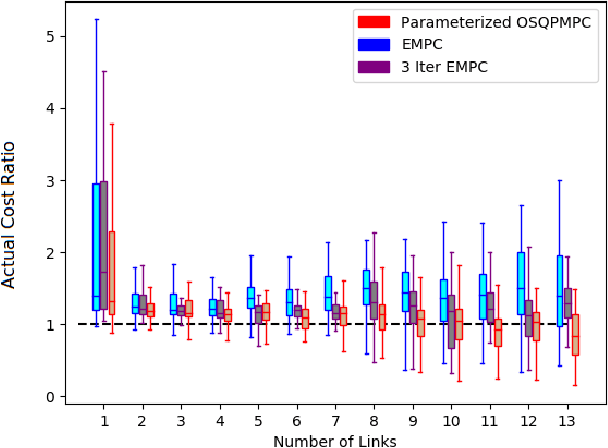
This work presents and evaluates a novel input parameterization method which improves the tractability of model predictive control (MPC) for high degree of freedom (DoF) robots. Experimental results demonstrate that by parameterizing the input trajectory more than three quarters of the optimization variables used in traditional MPC can be eliminated with practically no effect on system performance. This parameterization also leads to trajectories which are more conservative, producing less overshoot in underdamped systems with modeling error. In this paper we present two MPC solution methods that make use of this parameterization. The first uses a convex solver, and the second makes use of parallel computing on a graphics processing unit (GPU). We show that both approaches drastically reduce solve times for large DoF, long horizon MPC problems allowing solutions at real-time rates. Through simulation and hardware experiments, we show that the parameterized convex solver MPC has faster solve times than traditional MPC for high DoF cases while still achieving similar performance. For the GPU-based MPC solution method, we use an evolutionary algorithm and that we call Evolutionary MPC (EMPC). EMPC is shown to have even faster solve times for high DoF systems. Solve times for EMPC are shown to decrease even further through the use of a more powerful GPU. This suggests that parallelized MPC methods will become even more advantageous with the improvement and prevalence of GPU technology.
Simulated annealing from continuum to discretization: a convergence analysis via the Eyring--Kramers law
Feb 09, 2021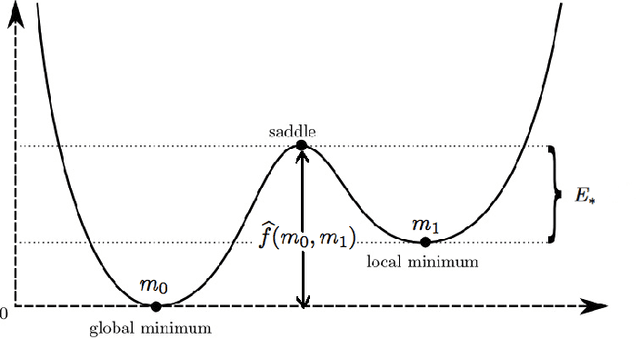
We study the convergence rate of continuous-time simulated annealing $(X_t; \, t \ge 0)$ and its discretization $(x_k; \, k =0,1, \ldots)$ for approximating the global optimum of a given function $f$. We prove that the tail probability $\mathbb{P}(f(X_t) > \min f +\delta)$ (resp. $\mathbb{P}(f(x_k) > \min f +\delta)$) decays polynomial in time (resp. in cumulative step size), and provide an explicit rate as a function of the model parameters. Our argument applies the recent development on functional inequalities for the Gibbs measure at low temperatures -- the Eyring-Kramers law. In the discrete setting, we obtain a condition on the step size to ensure the convergence.
Super-convergence and Differential Privacy: Training faster with better privacy guarantees
Mar 18, 2021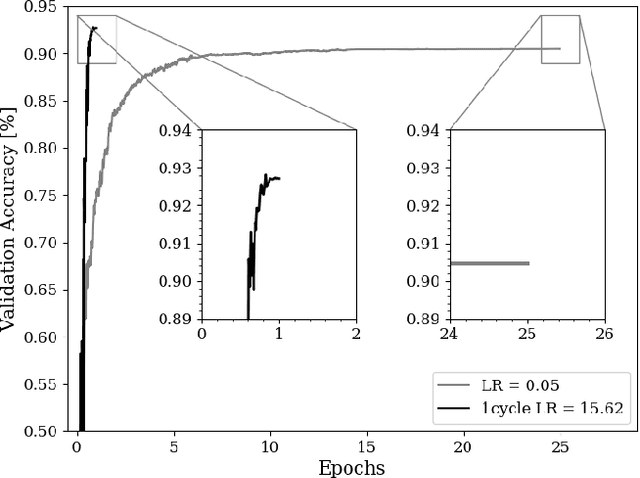
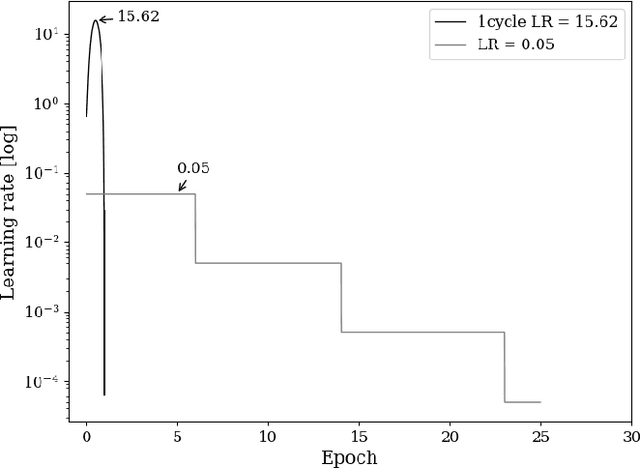
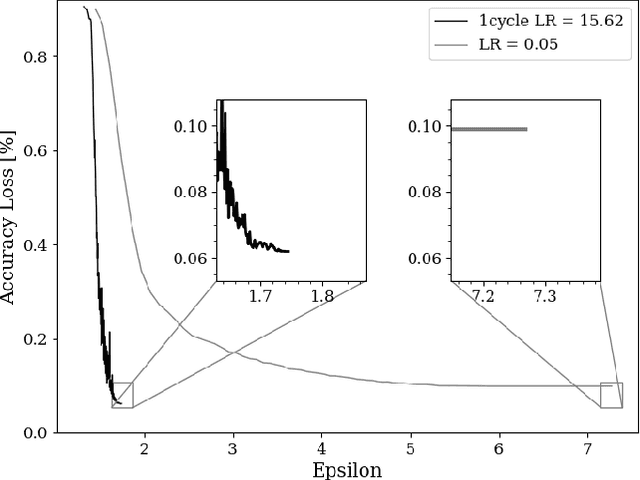
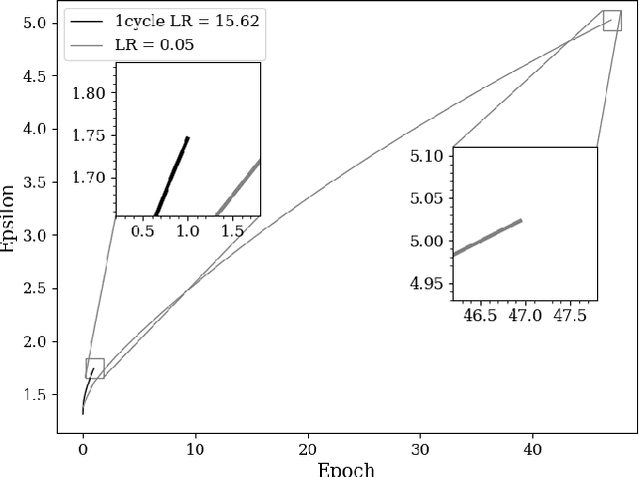
The combination of deep neural networks and Differential Privacy has been of increasing interest in recent years, as it offers important data protection guarantees to the individuals of the training datasets used. However, using Differential Privacy in the training of neural networks comes with a set of shortcomings, like a decrease in validation accuracy and a significant increase in the use of resources and time in training. In this paper, we examine super-convergence as a way of greatly increasing training speed of differentially private neural networks, addressing the shortcoming of high training time and resource use. Super-convergence allows for acceleration in network training using very high learning rates, and has been shown to achieve models with high utility in orders of magnitude less training iterations than conventional ways. Experiments in this paper show that this order-of-magnitude speedup can also be seen when combining it with Differential Privacy, allowing for higher validation accuracies in much fewer training iterations compared to non-private, non-super convergent baseline models. Furthermore, super-convergence is shown to improve the privacy guarantees of private models.
RoFL: Attestable Robustness for Secure Federated Learning
Jul 07, 2021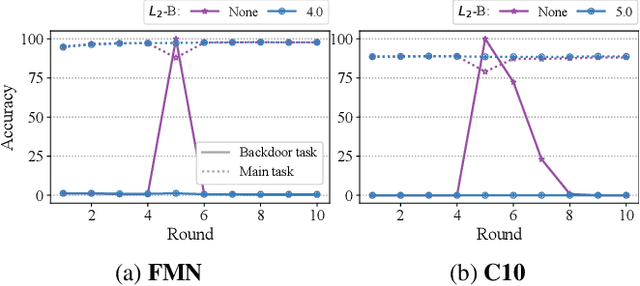
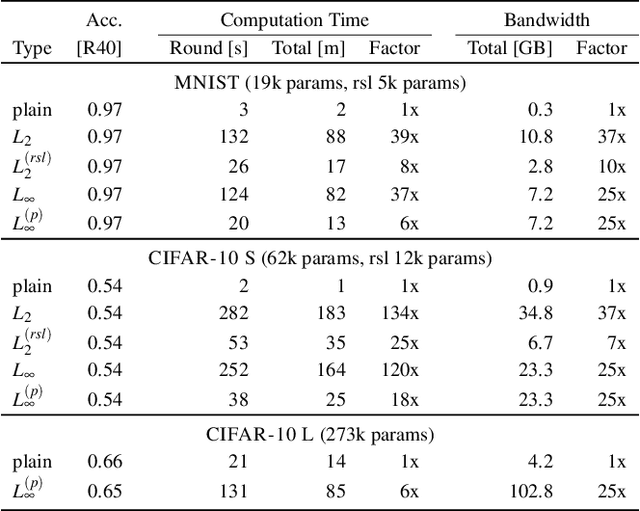
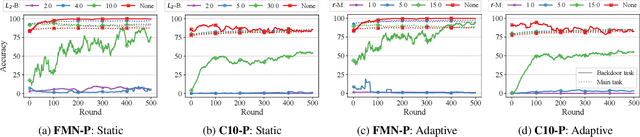
Federated Learning is an emerging decentralized machine learning paradigm that allows a large number of clients to train a joint model without the need to share their private data. Participants instead only share ephemeral updates necessary to train the model. To ensure the confidentiality of the client updates, Federated Learning systems employ secure aggregation; clients encrypt their gradient updates, and only the aggregated model is revealed to the server. Achieving this level of data protection, however, presents new challenges to the robustness of Federated Learning, i.e., the ability to tolerate failures and attacks. Unfortunately, in this setting, a malicious client can now easily exert influence on the model behavior without being detected. As Federated Learning is being deployed in practice in a range of sensitive applications, its robustness is growing in importance. In this paper, we take a step towards understanding and improving the robustness of secure Federated Learning. We start this paper with a systematic study that evaluates and analyzes existing attack vectors and discusses potential defenses and assesses their effectiveness. We then present RoFL, a secure Federated Learning system that improves robustness against malicious clients through input checks on the encrypted model updates. RoFL extends Federated Learning's secure aggregation protocol to allow expressing a variety of properties and constraints on model updates using zero-knowledge proofs. To enable RoFL to scale to typical Federated Learning settings, we introduce several ML and cryptographic optimizations specific to Federated Learning. We implement and evaluate a prototype of RoFL and show that realistic ML models can be trained in a reasonable time while improving robustness.
Denoising User-aware Memory Network for Recommendation
Jul 12, 2021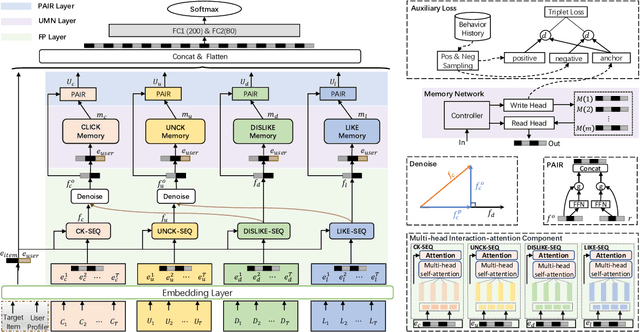
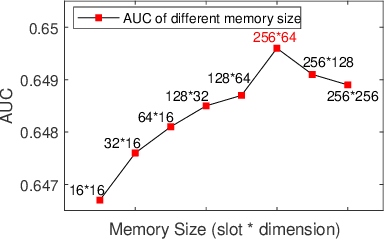
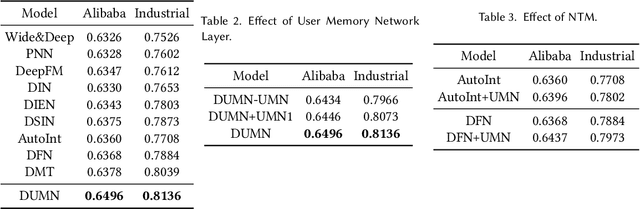

For better user satisfaction and business effectiveness, more and more attention has been paid to the sequence-based recommendation system, which is used to infer the evolution of users' dynamic preferences, and recent studies have noticed that the evolution of users' preferences can be better understood from the implicit and explicit feedback sequences. However, most of the existing recommendation techniques do not consider the noise contained in implicit feedback, which will lead to the biased representation of user interest and a suboptimal recommendation performance. Meanwhile, the existing methods utilize item sequence for capturing the evolution of user interest. The performance of these methods is limited by the length of the sequence, and can not effectively model the long-term interest in a long period of time. Based on this observation, we propose a novel CTR model named denoising user-aware memory network (DUMN). Specifically, the framework: (i) proposes a feature purification module based on orthogonal mapping, which use the representation of explicit feedback to purify the representation of implicit feedback, and effectively denoise the implicit feedback; (ii) designs a user memory network to model the long-term interests in a fine-grained way by improving the memory network, which is ignored by the existing methods; and (iii) develops a preference-aware interactive representation component to fuse the long-term and short-term interests of users based on gating to understand the evolution of unbiased preferences of users. Extensive experiments on two real e-commerce user behavior datasets show that DUMN has a significant improvement over the state-of-the-art baselines. The code of DUMN model has been uploaded as an additional material.
Iris Recognition Performance in Children: A Longitudinal Study
Jan 16, 2021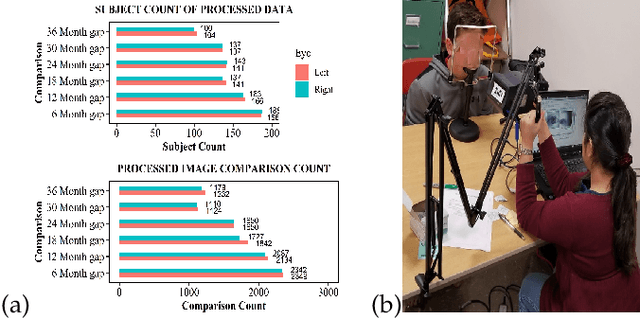
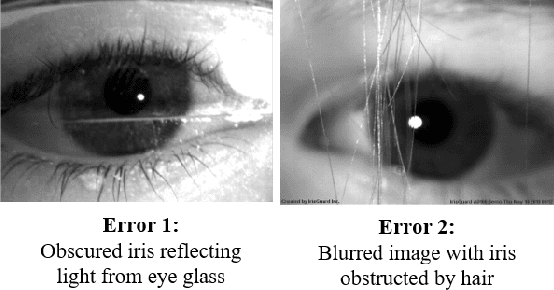
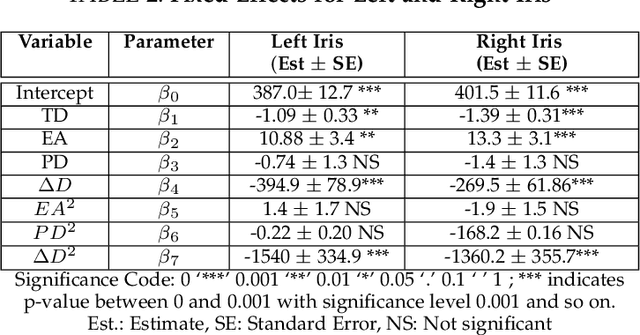
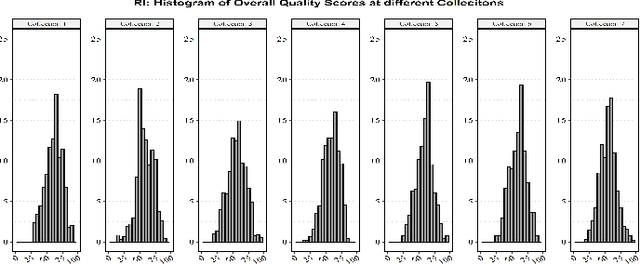
There is uncertainty around the effect of aging of children on biometric characteristics impacting applications relying on biometric recognition, particularly as the time between enrollment and query increases. Though there have been studies of such effects for iris recognition in adults, there have been few studies evaluating impact in children. This paper presents longitudinal analysis from 209 subjects aged 4 to 11 years at enrollment and six additional sessions over a period of 3 years. The influence of time, dilation and enrollment age on iris recognition have been analyzed and their statistical importance has been evaluated. A minor aging effect is noted which is statistically significant, but practically insignificant and is comparatively less important than other variability factors. Practical biometric applications of iris recognition in children are feasible for a time frame of at least 3 years between samples, for ages 4 to 11 years, even in presence of aging, though we note practical difficulties in enrolling young children with cameras not designed for the purpose. To the best of our knowledge, the database used in this study is the only dataset of longitudinal iris images from children for this age group and time period that is available for research.
Variable Weights Neural Network For Diabetes Classification
Feb 22, 2021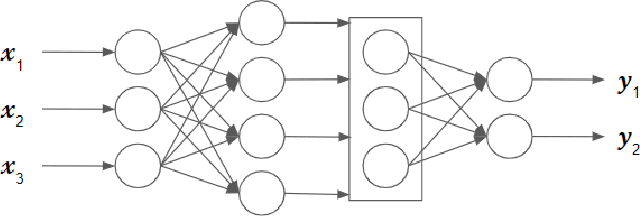
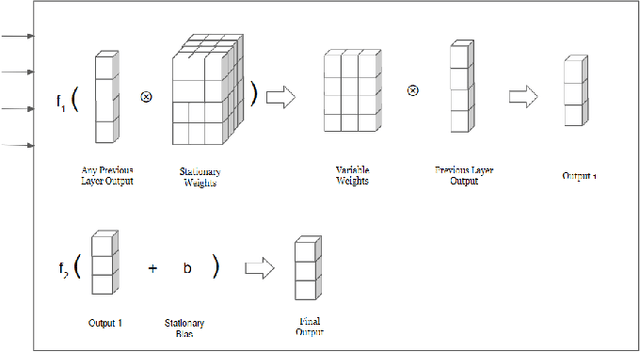

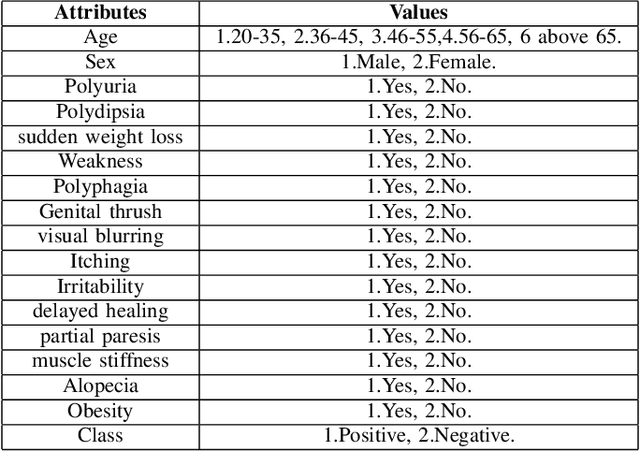
As witnessed in the past year, where the world was brought to the ground by a pandemic, fighting Life-threatening diseases have found greater focus than ever. The first step in fighting a disease is to diagnose it at the right time. Diabetes has been affecting people for a long time and is growing among people faster than ever. The number of people who have Diabetes reached 422 million in 2018, as reported by WHO, and the global prevalence of diabetes among adults above the age of 18 has risen to 8.5%. Now Diabetes is a disease that shows no or very few symptoms among the people affected by it for a long time, and even in some cases, people realize they have it when they have lost any chance of controlling it. So getting Diabetes diagnosed at an early stage can make a huge difference in how one can approach curing it. Moving in this direction in this paper, we have designed a liquid machine learning approach to detect Diabetes with no cost using deep learning. In this work, we have used a dataset of 520 instances. Our approach shows a significant improvement in the previous state-of-the-art results. Its power to generalize well on small dataset deals with the critical problem of lesser data in medical sciences.