 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MERMAID: Metaphor Generation with Symbolism and Discriminative Decoding
Mar 11, 2021

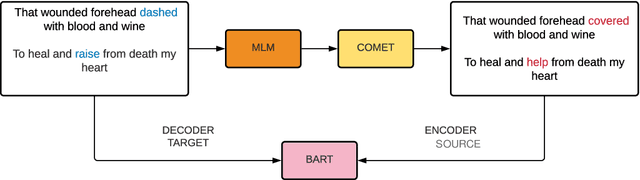
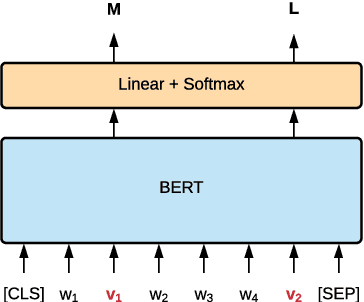

Generating metaphors is a challenging task as it requires a proper understanding of abstract concepts, making connections between unrelated concepts, and deviating from the literal meaning. Based on a theoretically-grounded connection between metaphors and symbols, we propose a method to automatically construct a parallel corpus by transforming a large number of metaphorical sentences from the Gutenberg Poetry corpus (Jacobs, 2018) to their literal counterpart using recent advances in masked language modeling coupled with commonsense inference. For the generation task, we incorporate a metaphor discriminator to guide the decoding of a sequence to sequence model fine-tuned on our parallel data to generate high-quality metaphors. Human evaluation on an independent test set of literal statements shows that our best model generates metaphors better than three well-crafted baselines 66% of the time on average. A task-based evaluation shows that human-written poems enhanced with metaphors proposed by our model are preferred 68% of the time compared to poems without metaphors.
An Empirical Survey of Data Augmentation for Limited Data Learning in NLP
Jun 14, 2021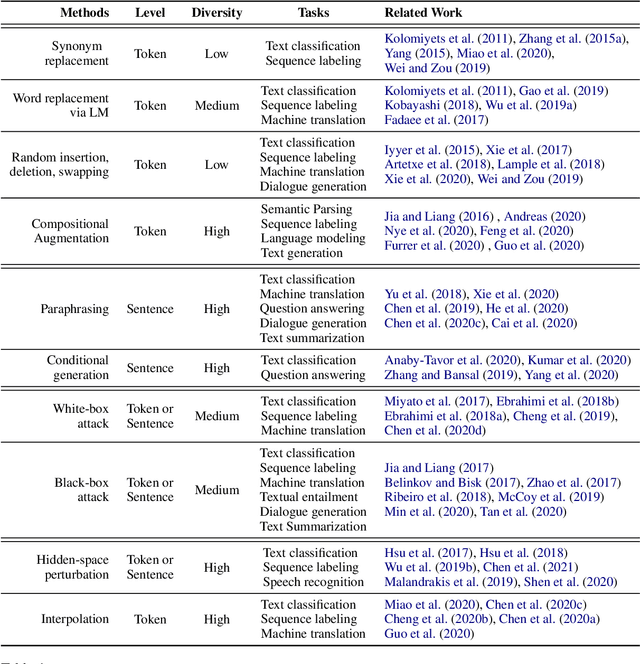
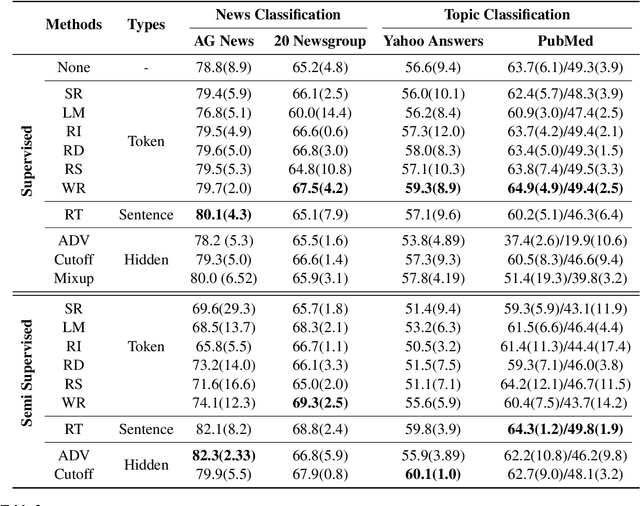
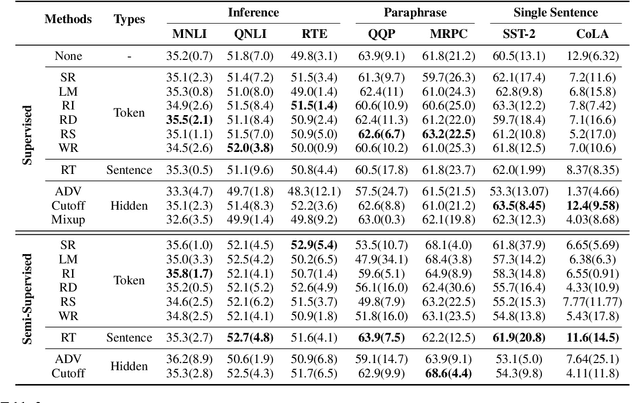
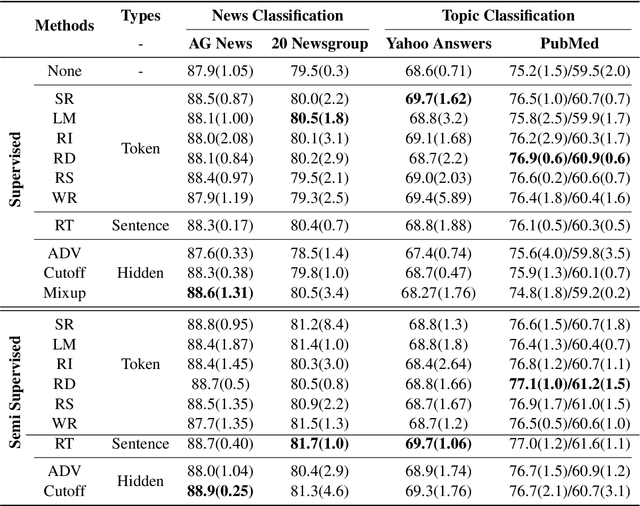
NLP has achieved great progress in the past decade through the use of neural models and large labeled datasets. The dependence on abundant data prevents NLP models from being applied to low-resource settings or novel tasks where significant time, money, or expertise is required to label massive amounts of textual data. Recently, data augmentation methods have been explored as a means of improving data efficiency in NLP. To date, there has been no systematic empirical overview of data augmentation for NLP in the limited labeled data setting, making it difficult to understand which methods work in which settings. In this paper, we provide an empirical survey of recent progress on data augmentation for NLP in the limited labeled data setting, summarizing the landscape of methods (including token-level augmentations, sentence-level augmentations, adversarial augmentations, and hidden-space augmentations) and carrying out experiments on 11 datasets covering topics/news classification, inference tasks, paraphrasing tasks, and single-sentence tasks. Based on the results, we draw several conclusions to help practitioners choose appropriate augmentations in different settings and discuss the current challenges and future directions for limited data learning in NLP.
OSTSC: Over Sampling for Time Series Classification in R
Nov 27, 2017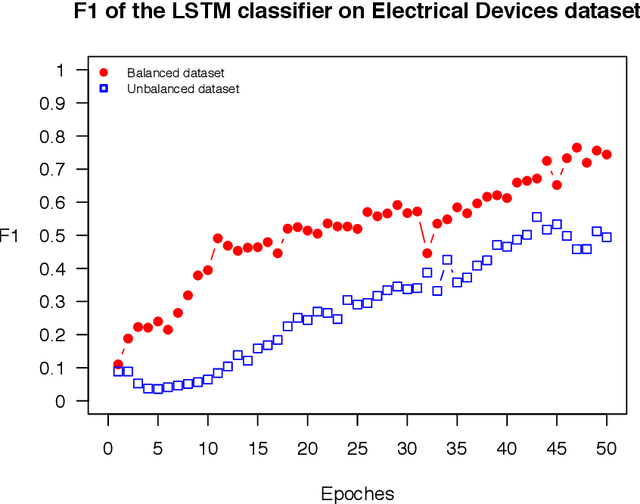
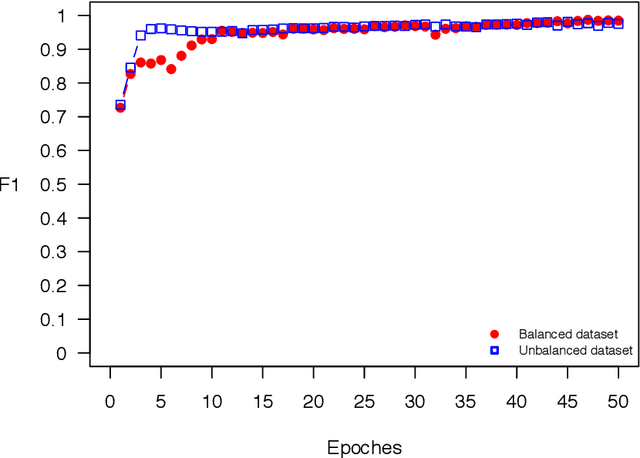

The OSTSC package is a powerful oversampling approach for classifying univariant, but multinomial time series data in R. This article provides a brief overview of the oversampling methodology implemented by the package. A tutorial of the OSTSC package is provided. We begin by providing three test cases for the user to quickly validate the functionality in the package. To demonstrate the performance impact of OSTSC, we then provide two medium size imbalanced time series datasets. Each example applies a TensorFlow implementation of a Long Short-Term Memory (LSTM) classifier - a type of a Recurrent Neural Network (RNN) classifier - to imbalanced time series. The classifier performance is compared with and without oversampling. Finally, larger versions of these two datasets are evaluated to demonstrate the scalability of the package. The examples demonstrate that the OSTSC package improves the performance of RNN classifiers applied to highly imbalanced time series data. In particular, OSTSC is observed to increase the AUC of LSTM from 0.543 to 0.784 on a high frequency trading dataset consisting of 30,000 time series observations.
An improved LogNNet classifier for IoT application
May 30, 2021
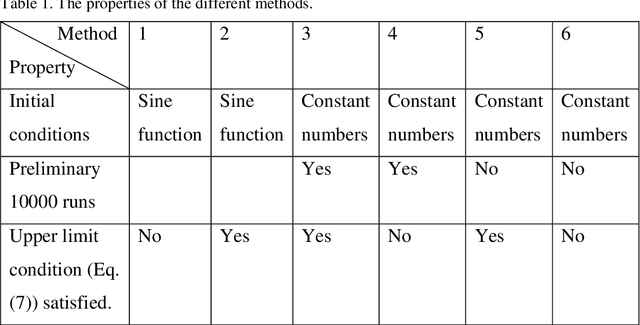
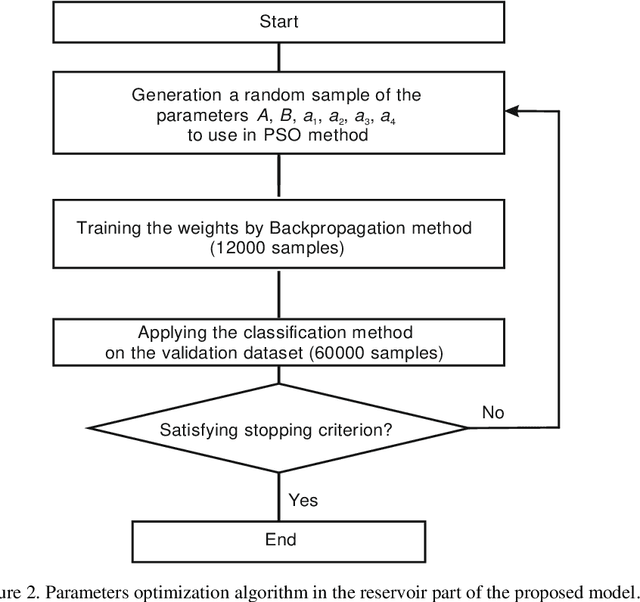
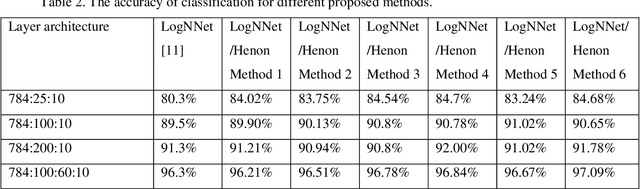
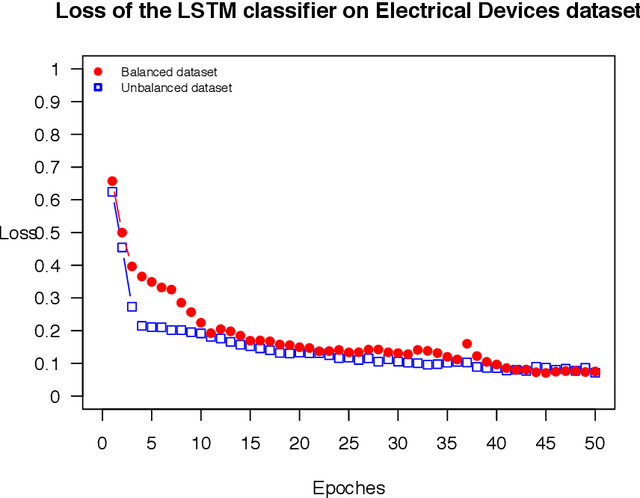
The internet of things devices suffer of low memory while good accuracy is needed. Designing suitable algorithms is vital in this subject. This paper proposes a feed forward LogNNet neural network which uses a semi-linear Henon type discrete chaotic map to classify MNIST-10 dataset. The model is composed of reservoir part and trainable classifier. The aim of reservoir part is transforming the inputs to maximize the classification accuracy using a special matrix filing method and a time series generated by the chaotic map. The parameters of the chaotic map are optimized using particle swarm optimization with random immigrants. The results show that the proposed LogNNet/Henon classifier has higher accuracy and same RAM saving comparable to the original version of LogNNet and has broad prospects for implementation in IoT devices. In addition, the relation between the entropy and accuracy of the classification is investigated. It is shown that there exists a direct relation between the value of entropy and accuracy of the classification.
Sequential Recommendation with Graph Neural Networks
Jun 27, 2021

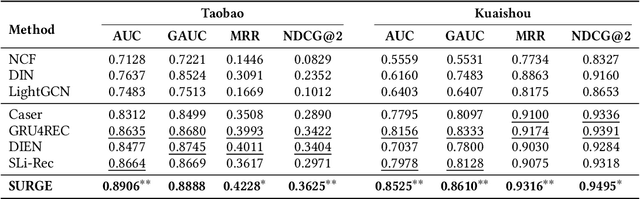
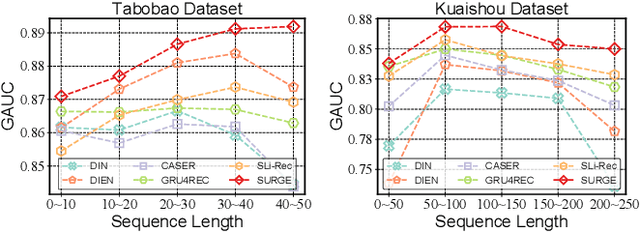
Sequential recommendation aims to leverage users' historical behaviors to predict their next interaction. Existing works have not yet addressed two main challenges in sequential recommendation. First, user behaviors in their rich historical sequences are often implicit and noisy preference signals, they cannot sufficiently reflect users' actual preferences. In addition, users' dynamic preferences often change rapidly over time, and hence it is difficult to capture user patterns in their historical sequences. In this work, we propose a graph neural network model called SURGE (short for SeqUential Recommendation with Graph neural nEtworks) to address these two issues. Specifically, SURGE integrates different types of preferences in long-term user behaviors into clusters in the graph by re-constructing loose item sequences into tight item-item interest graphs based on metric learning. This helps explicitly distinguish users' core interests, by forming dense clusters in the interest graph. Then, we perform cluster-aware and query-aware graph convolutional propagation and graph pooling on the constructed graph. It dynamically fuses and extracts users' current activated core interests from noisy user behavior sequences. We conduct extensive experiments on both public and proprietary industrial datasets. Experimental results demonstrate significant performance gains of our proposed method compared to state-of-the-art methods. Further studies on sequence length confirm that our method can model long behavioral sequences effectively and efficiently.
Intrusion Detection System in Smart Home Network Using Bidirectional LSTM and Convolutional Neural Networks Hybrid Model
May 25, 2021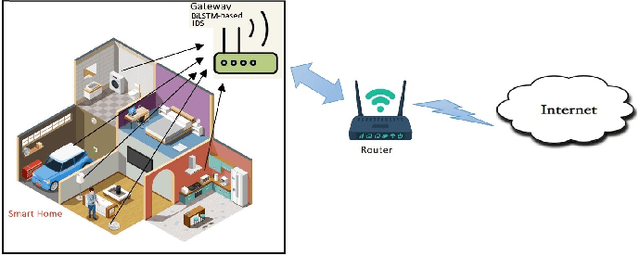
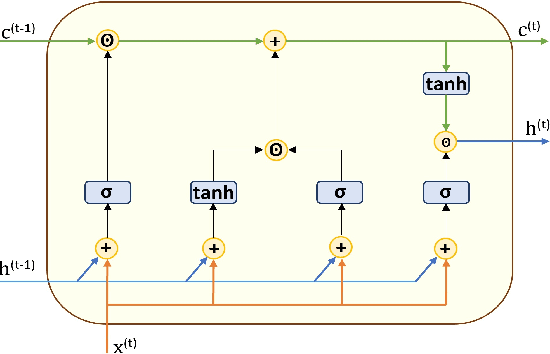
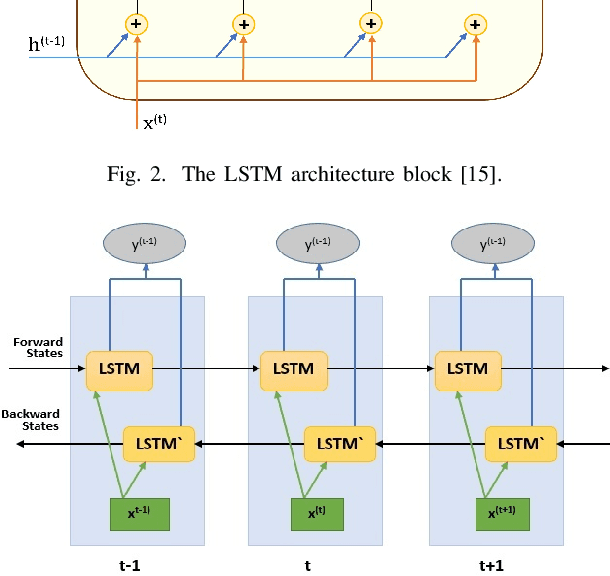
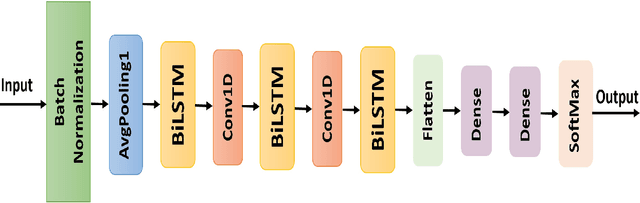
Internet of Things (IoT) allowed smart homes to improve the quality and the comfort of our daily lives. However, these conveniences introduced several security concerns that increase rapidly. IoT devices, smart home hubs, and gateway raise various security risks. The smart home gateways act as a centralized point of communication between the IoT devices, which can create a backdoor into network data for hackers. One of the common and effective ways to detect such attacks is intrusion detection in the network traffic. In this paper, we proposed an intrusion detection system (IDS) to detect anomalies in a smart home network using a bidirectional long short-term memory (BiLSTM) and convolutional neural network (CNN) hybrid model. The BiLSTM recurrent behavior provides the intrusion detection model to preserve the learned information through time, and the CNN extracts perfectly the data features. The proposed model can be applied to any smart home network gateway.
Video Class Agnostic Segmentation Benchmark for Autonomous Driving
Mar 19, 2021
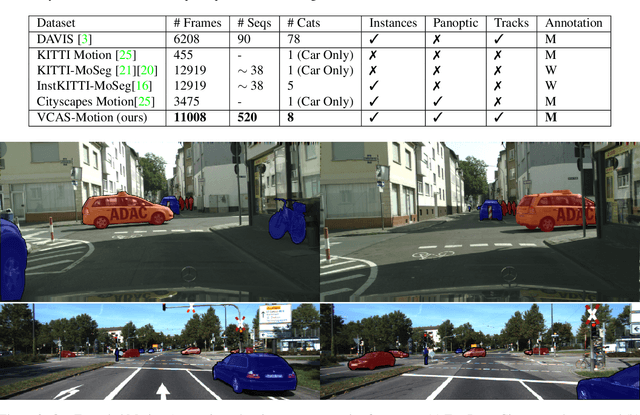

Semantic segmentation approaches are typically trained on large-scale data with a closed finite set of known classes without considering unknown objects. In certain safety-critical robotics applications, especially autonomous driving, it is important to segment all objects, including those unknown at training time. We formalize the task of video class agnostic segmentation from monocular video sequences in autonomous driving to account for unknown objects. Video class agnostic segmentation can be formulated as an open-set or a motion segmentation problem. We discuss both formulations and provide datasets and benchmark different baseline approaches for both tracks. In the motion-segmentation track we benchmark real-time joint panoptic and motion instance segmentation, and evaluate the effect of ego-flow suppression. In the open-set segmentation track we evaluate baseline methods that combine appearance, and geometry to learn prototypes per semantic class. We then compare it to a model that uses an auxiliary contrastive loss to improve the discrimination between known and unknown objects. All datasets and models are publicly released at https://msiam.github.io/vca/.
Data-driven 6D Pose Tracking by Calibrating Image Residuals in Synthetic Domains
May 29, 2021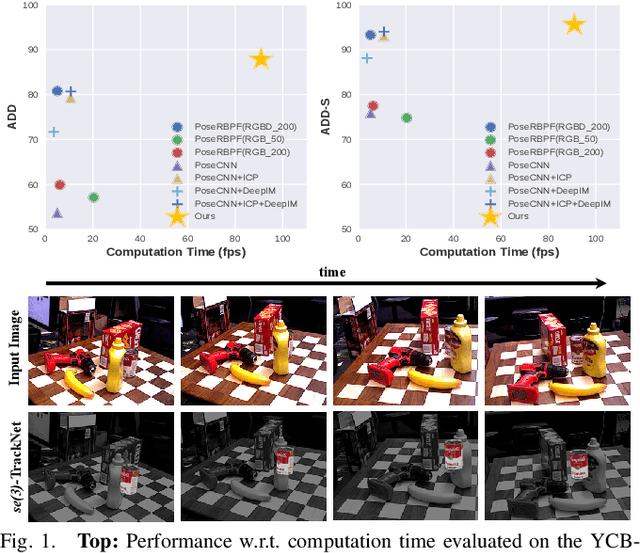
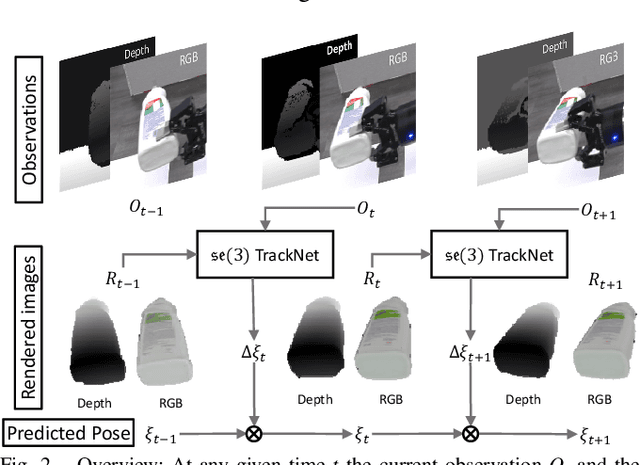
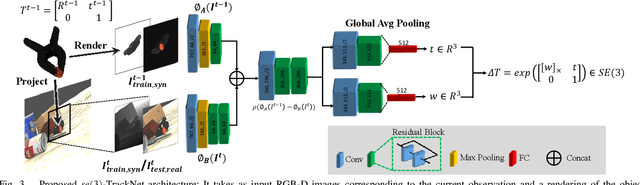

Tracking the 6D pose of objects in video sequences is important for robot manipulation. This work presents se(3)-TrackNet, a data-driven optimization approach for long term, 6D pose tracking. It aims to identify the optimal relative pose given the current RGB-D observation and a synthetic image conditioned on the previous best estimate and the object's model. The key contribution in this context is a novel neural network architecture, which appropriately disentangles the feature encoding to help reduce domain shift, and an effective 3D orientation representation via Lie Algebra. Consequently, even when the network is trained solely with synthetic data can work effectively over real images. Comprehensive experiments over multiple benchmarks show se(3)-TrackNet achieves consistently robust estimates and outperforms alternatives, even though they have been trained with real images. The approach runs in real time at 90.9Hz. Code, data and supplementary video for this project are available at https://github.com/wenbowen123/iros20-6d-pose-tracking
* CVPR 2021 Workshop on 3D Vision and Robotics. arXiv admin note: substantial text overlap with arXiv:2007.13866
SMET: Scenario-based Metamorphic Testing for Autonomous Driving Models
Apr 08, 2021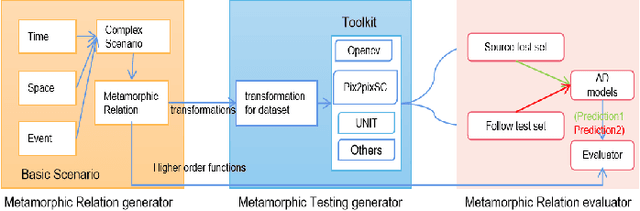
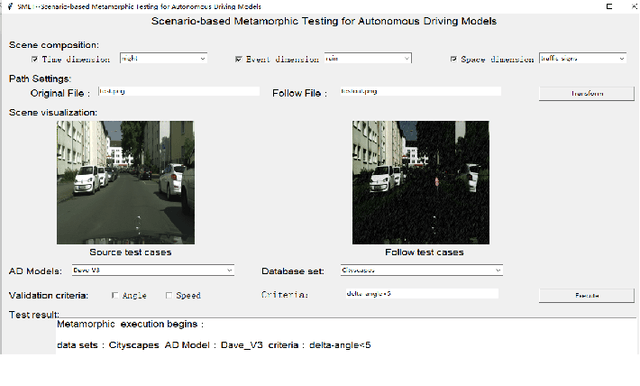
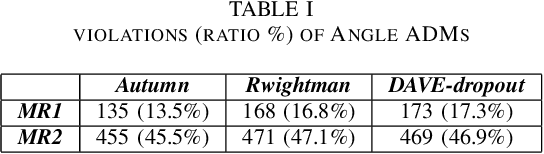
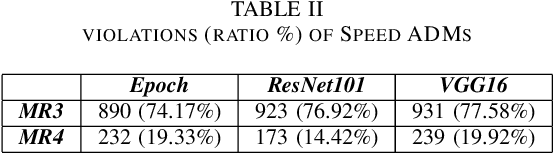
To improve the security and robustness of autonomous driving models, this paper presents SMET, a scenariobased metamorphic testing tool for autonomous driving models. The metamorphic relationship is divided into three dimensions (time, space, and event) and demonstrates its effectiveness through case studies in two types of autonomous driving models with different outputs.Experimental results show that this tool can well detect potential defects of the autonomous driving model, and complex scenes are more effective than simple scenes.
Hyperparameter Selection for Imitation Learning
May 25, 2021
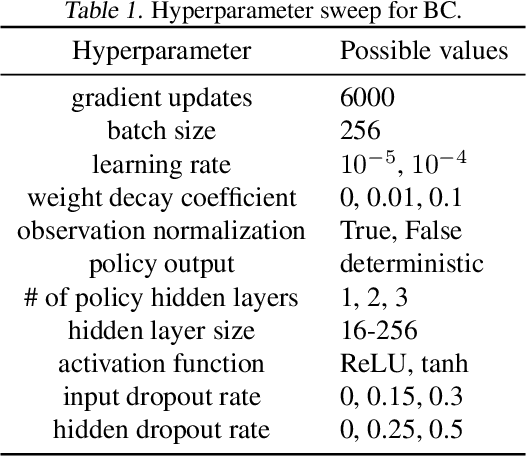
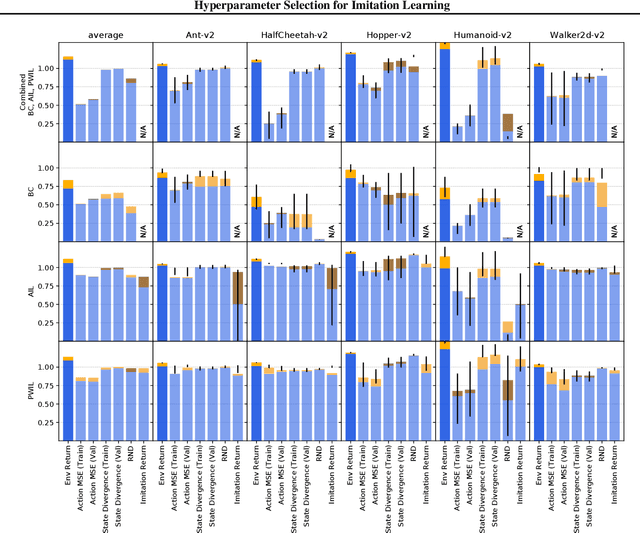
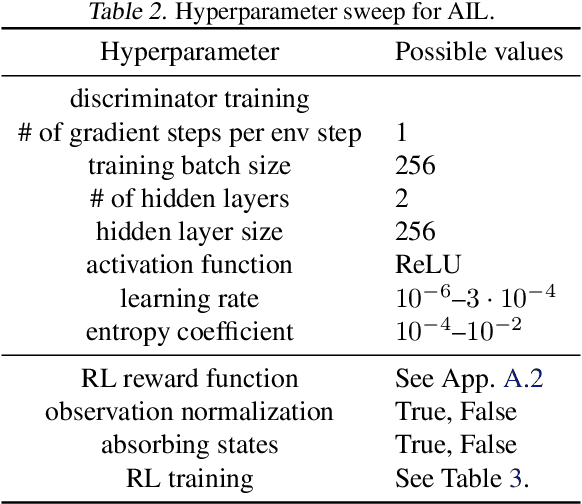
We address the issue of tuning hyperparameters (HPs) for imitation learning algorithms in the context of continuous-control, when the underlying reward function of the demonstrating expert cannot be observed at any time. The vast literature in imitation learning mostly considers this reward function to be available for HP selection, but this is not a realistic setting. Indeed, would this reward function be available, it could then directly be used for policy training and imitation would not be necessary. To tackle this mostly ignored problem, we propose a number of possible proxies to the external reward. We evaluate them in an extensive empirical study (more than 10'000 agents across 9 environments) and make practical recommendations for selecting HPs. Our results show that while imitation learning algorithms are sensitive to HP choices, it is often possible to select good enough HPs through a proxy to the reward function.