 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Facial emotion expressions in human-robot interaction: A survey
Mar 12, 2021
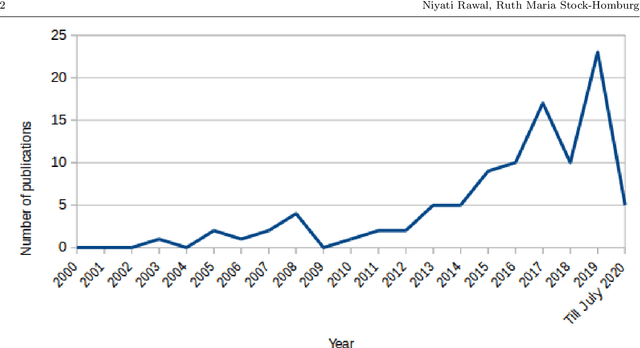
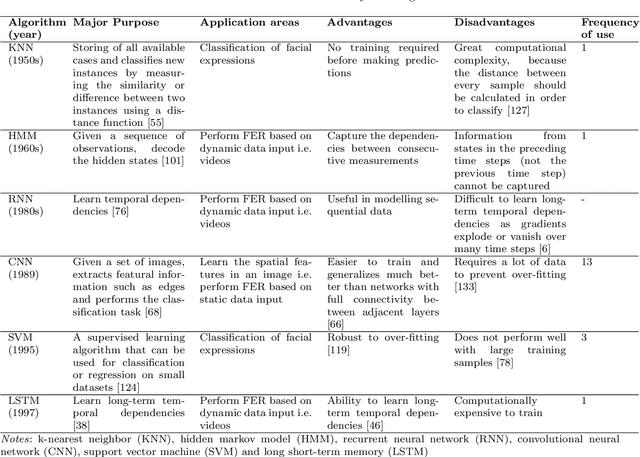
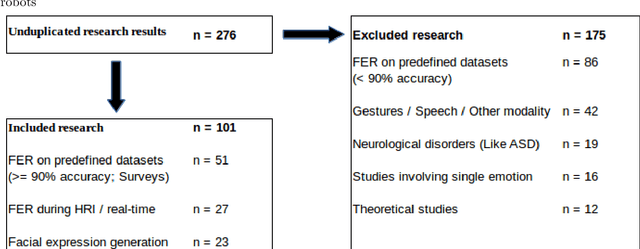
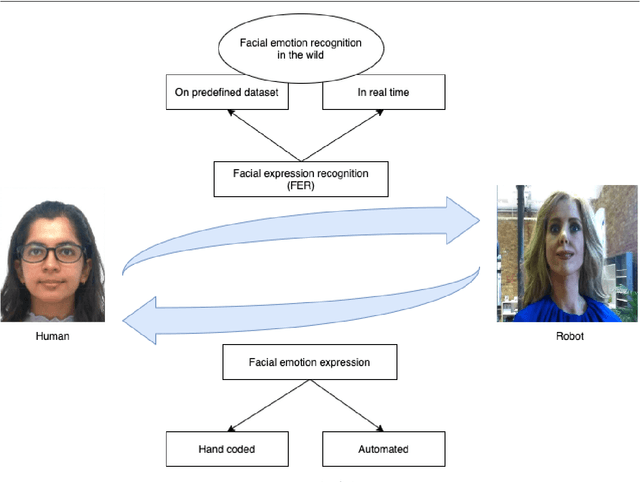
Facial expressions are an ideal means of communicating one's emotions or intentions to others. This overview will focus on human facial expression recognition as well as robotic facial expression generation. In case of human facial expression recognition, both facial expression recognition on predefined datasets as well as in real time will be covered. For robotic facial expression generation, hand coded and automated methods i.e., facial expressions of a robot are generated by moving the features (eyes, mouth) of the robot by hand coding or automatically using machine learning techniques, will also be covered. There are already plenty of studies that achieve high accuracy for emotion expression recognition on predefined datasets, but the accuracy for facial expression recognition in real time is comparatively lower. In case of expression generation in robots, while most of the robots are capable of making basic facial expressions, there are not many studies that enable robots to do so automatically.
Real Time Elbow Angle Estimation Using Single RGB Camera
Aug 21, 2018The use of motion capture has increased from last decade in a varied spectrum of applications like film special effects, controlling games and robots, rehabilitation system, animations etc. The current human motion capture techniques use markers, structured environment, and high resolution cameras in a dedicated environment. Because of rapid movement, elbow angle estimation is observed as the most difficult problem in human motion capture system. In this paper, we take elbow angle estimation as our research subject and propose a novel, markerless and cost-effective solution that uses RGB camera for estimating elbow angle in real time using part affinity field. We have recruited five (5) participants to perform cup to mouth movement and at the same time measured the angle by both RGB camera and Microsoft Kinect. The experimental results illustrate that markerless and cost-effective RGB camera has a median RMS errors of 3.06{\deg} and 0.95{\deg} in sagittal and coronal plane respectively as compared to Microsoft Kinect.
Wallpaper Texture Generation and Style Transfer Based on Multi-label Semantics
Jun 22, 2021


Textures contain a wealth of image information and are widely used in various fields such as computer graphics and computer vision. With the development of machine learning, the texture synthesis and generation have been greatly improved. As a very common element in everyday life, wallpapers contain a wealth of texture information, making it difficult to annotate with a simple single label. Moreover, wallpaper designers spend significant time to create different styles of wallpaper. For this purpose, this paper proposes to describe wallpaper texture images by using multi-label semantics. Based on these labels and generative adversarial networks, we present a framework for perception driven wallpaper texture generation and style transfer. In this framework, a perceptual model is trained to recognize whether the wallpapers produced by the generator network are sufficiently realistic and have the attribute designated by given perceptual description; these multi-label semantic attributes are treated as condition variables to generate wallpaper images. The generated wallpaper images can be converted to those with well-known artist styles using CycleGAN. Finally, using the aesthetic evaluation method, the generated wallpaper images are quantitatively measured. The experimental results demonstrate that the proposed method can generate wallpaper textures conforming to human aesthetics and have artistic characteristics.
"Train one, Classify one, Teach one" -- Cross-surgery transfer learning for surgical step recognition
Feb 24, 2021
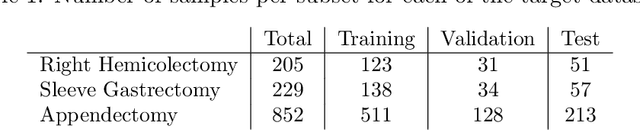

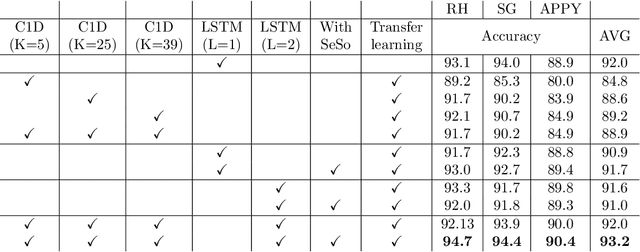
Prior work demonstrated the ability of machine learning to automatically recognize surgical workflow steps from videos. However, these studies focused on only a single type of procedure. In this work, we analyze, for the first time, surgical step recognition on four different laparoscopic surgeries: Cholecystectomy, Right Hemicolectomy, Sleeve Gastrectomy, and Appendectomy. Inspired by the traditional apprenticeship model, in which surgical training is based on the Halstedian method, we paraphrase the "see one, do one, teach one" approach for the surgical intelligence domain as "train one, classify one, teach one". In machine learning, this approach is often referred to as transfer learning. To analyze the impact of transfer learning across different laparoscopic procedures, we explore various time-series architectures and examine their performance on each target domain. We introduce a new architecture, the Time-Series Adaptation Network (TSAN), an architecture optimized for transfer learning of surgical step recognition, and we show how TSAN can be pre-trained using self-supervised learning on a Sequence Sorting task. Such pre-training enables TSAN to learn workflow steps of a new laparoscopic procedure type from only a small number of labeled samples from the target procedure. Our proposed architecture leads to better performance compared to other possible architectures, reaching over 90% accuracy when transferring from laparoscopic Cholecystectomy to the other three procedure types.
CT Image Synthesis Using Weakly Supervised Segmentation and Geometric Inter-Label Relations For COVID Image Analysis
Jun 15, 2021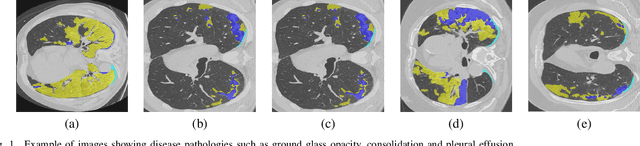
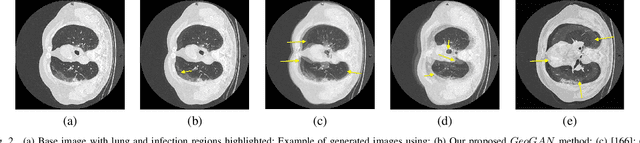
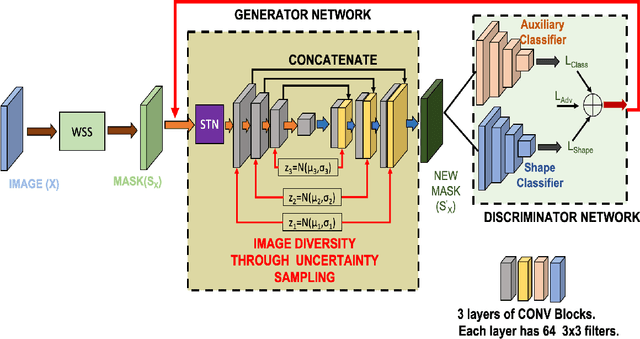
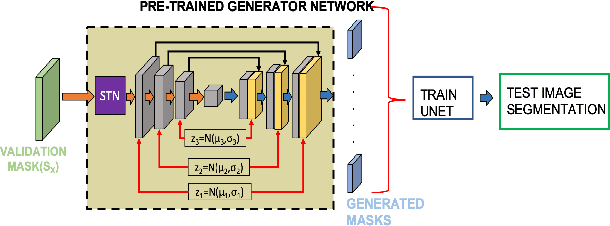
While medical image segmentation is an important task for computer aided diagnosis, the high expertise requirement for pixelwise manual annotations makes it a challenging and time consuming task. Since conventional data augmentations do not fully represent the underlying distribution of the training set, the trained models have varying performance when tested on images captured from different sources. Most prior work on image synthesis for data augmentation ignore the interleaved geometric relationship between different anatomical labels. We propose improvements over previous GAN-based medical image synthesis methods by learning the relationship between different anatomical labels. We use a weakly supervised segmentation method to obtain pixel level semantic label map of images which is used learn the intrinsic relationship of geometry and shape across semantic labels. Latent space variable sampling results in diverse generated images from a base image and improves robustness. We use the synthetic images from our method to train networks for segmenting COVID-19 infected areas from lung CT images. The proposed method outperforms state-of-the-art segmentation methods on a public dataset. Ablation studies also demonstrate benefits of integrating geometry and diversity.
Efficient Matrix-Free Approximations of Second-Order Information, with Applications to Pruning and Optimization
Jul 09, 2021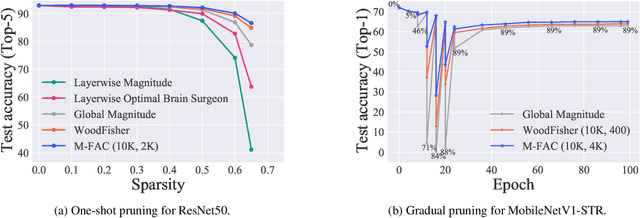
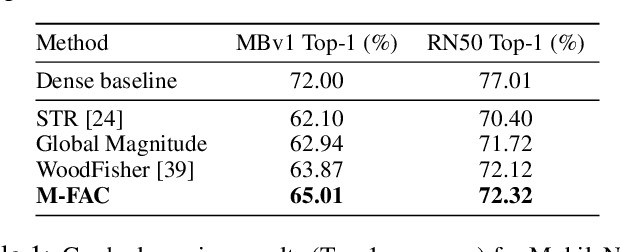
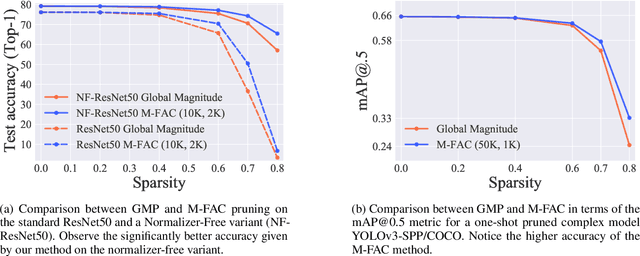
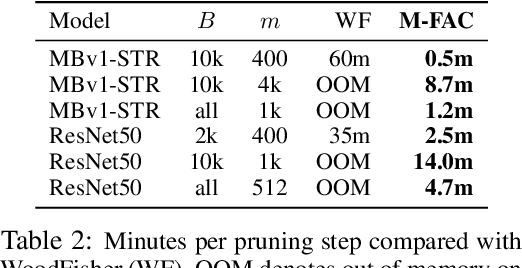
Efficiently approximating local curvature information of the loss function is a key tool for optimization and compression of deep neural networks. Yet, most existing methods to approximate second-order information have high computational or storage costs, which can limit their practicality. In this work, we investigate matrix-free, linear-time approaches for estimating Inverse-Hessian Vector Products (IHVPs) for the case when the Hessian can be approximated as a sum of rank-one matrices, as in the classic approximation of the Hessian by the empirical Fisher matrix. We propose two new algorithms as part of a framework called M-FAC: the first algorithm is tailored towards network compression and can compute the IHVP for dimension $d$, if the Hessian is given as a sum of $m$ rank-one matrices, using $O(dm^2)$ precomputation, $O(dm)$ cost for computing the IHVP, and query cost $O(m)$ for any single element of the inverse Hessian. The second algorithm targets an optimization setting, where we wish to compute the product between the inverse Hessian, estimated over a sliding window of optimization steps, and a given gradient direction, as required for preconditioned SGD. We give an algorithm with cost $O(dm + m^2)$ for computing the IHVP and $O(dm + m^3)$ for adding or removing any gradient from the sliding window. These two algorithms yield state-of-the-art results for network pruning and optimization with lower computational overhead relative to existing second-order methods. Implementations are available at [10] and [18].
Initializing LSTM internal states via manifold learning
May 12, 2021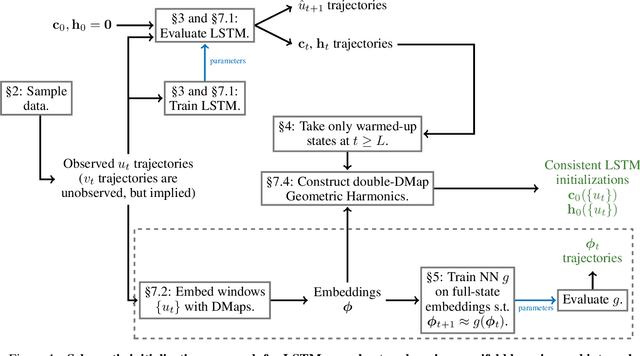
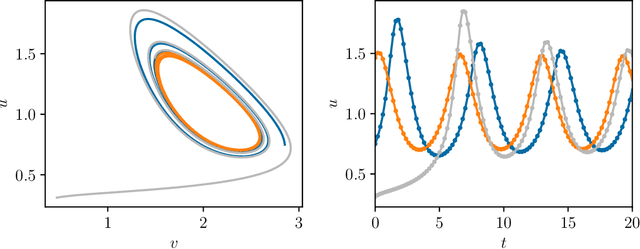
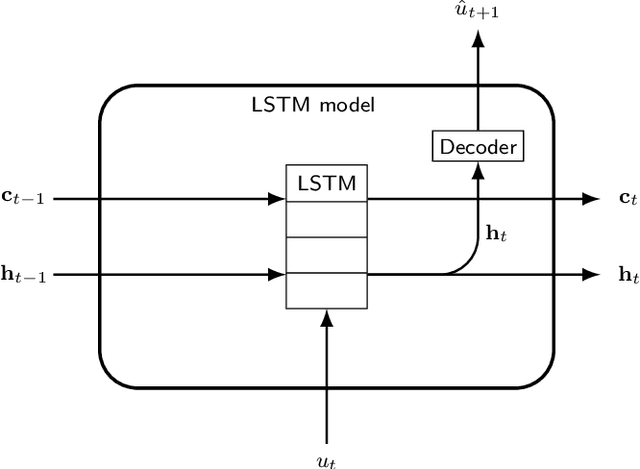
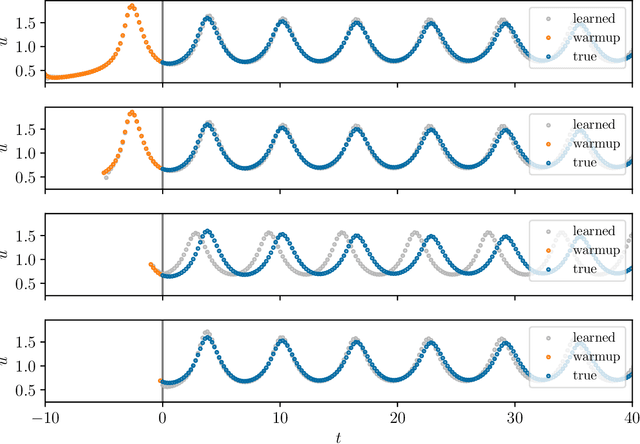
We present an approach, based on learning an intrinsic data manifold, for the initialization of the internal state values of LSTM recurrent neural networks, ensuring consistency with the initial observed input data. Exploiting the generalized synchronization concept, we argue that the converged, "mature" internal states constitute a function on this learned manifold. The dimension of this manifold then dictates the length of observed input time series data required for consistent initialization. We illustrate our approach through a partially observed chemical model system, where initializing the internal LSTM states in this fashion yields visibly improved performance. Finally, we show that learning this data manifold enables the transformation of partially observed dynamics into fully observed ones, facilitating alternative identification paths for nonlinear dynamical systems.
Capturing the temporal constraints of gradual patterns
Jun 28, 2021



Gradual pattern mining allows for extraction of attribute correlations through gradual rules such as: "the more X, the more Y". Such correlations are useful in identifying and isolating relationships among the attributes that may not be obvious through quick scans on a data set. For instance, a researcher may apply gradual pattern mining to determine which attributes of a data set exhibit unfamiliar correlations in order to isolate them for deeper exploration or analysis. In this work, we propose an ant colony optimization technique which uses a popular probabilistic approach that mimics the behavior biological ants as they search for the shortest path to find food in order to solve combinatorial problems. In our second contribution, we extend an existing gradual pattern mining technique to allow for extraction of gradual patterns together with an approximated temporal lag between the affected gradual item sets. Such a pattern is referred to as a fuzzy-temporal gradual pattern and it may take the form: "the more X, the more Y, almost 3 months later". In our third contribution, we propose a data crossing model that allows for integration of mostly gradual pattern mining algorithm implementations into a Cloud platform. This contribution is motivated by the proliferation of IoT applications in almost every area of our society and this comes with provision of large-scale time-series data from different sources.
Deep learning based electrical noise removal enables high spectral optoacoustic contrast in deep tissue
Feb 24, 2021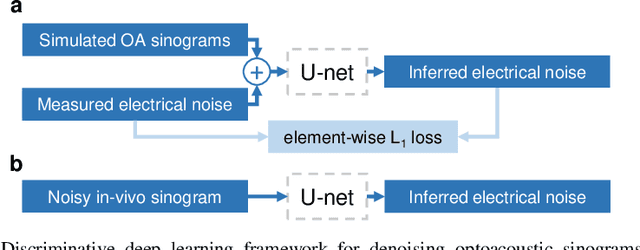
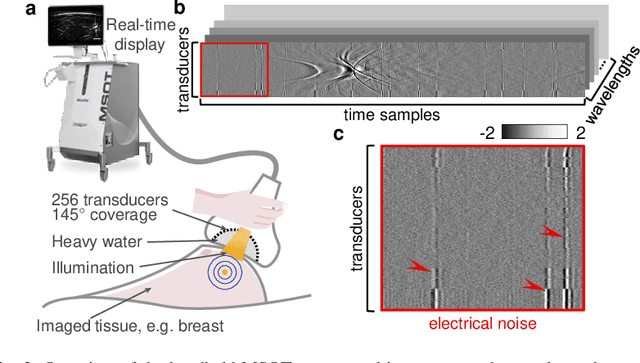
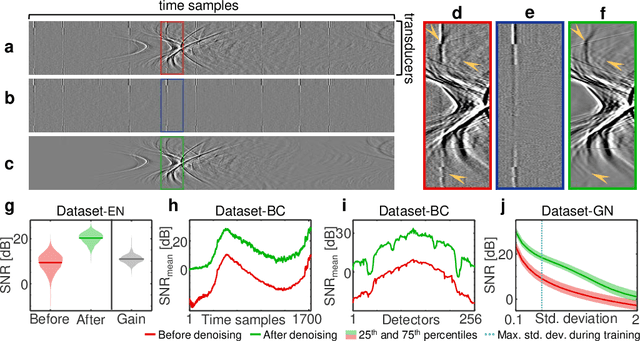
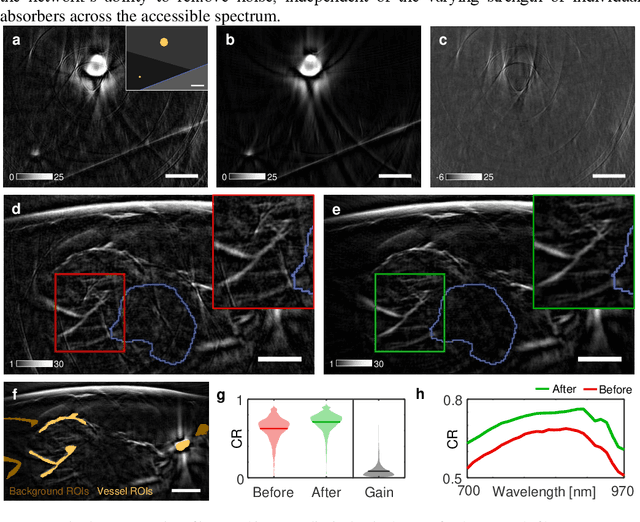
Image contrast in multispectral optoacoustic tomography (MSOT) can be severely reduced by electrical noise and interference in the acquired optoacoustic signals. Signal processing techniques have proven insufficient to remove the effects of electrical noise because they typically rely on simplified models and fail to capture complex characteristics of signal and noise. Moreover, they often involve time-consuming processing steps that are unsuited for real-time imaging applications. In this work, we develop and demonstrate a discriminative deep learning (DL) approach to separate electrical noise from optoacoustic signals prior to image reconstruction. The proposed DL algorithm is based on two key features. First, it learns spatiotemporal correlations in both noise and signal by using the entire optoacoustic sinogram as input. Second, it employs training based on a large dataset of experimentally acquired pure noise and synthetic optoacoustic signals. We validated the ability of the trained model to accurately remove electrical noise on synthetic data and on optoacoustic images of a phantom and the human breast. We demonstrate significant enhancements of morphological and spectral optoacoustic images reaching 19% higher blood vessel contrast and localized spectral contrast at depths of more than 2 cm for images acquired in vivo. We discuss how the proposed denoising framework is applicable to clinical multispectral optoacoustic tomography and suitable for real-time operation.
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
Jun 15, 2021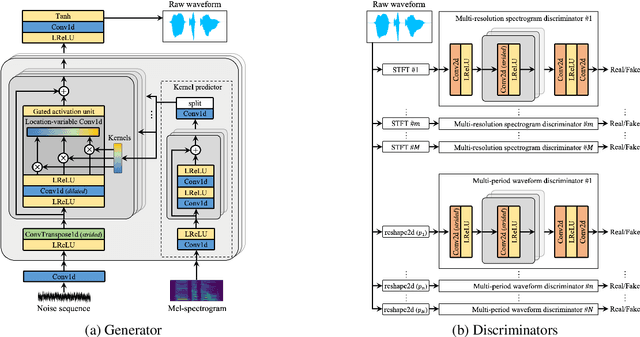
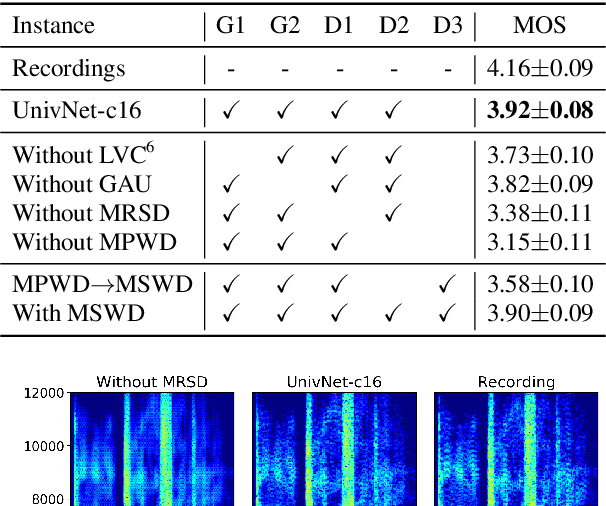
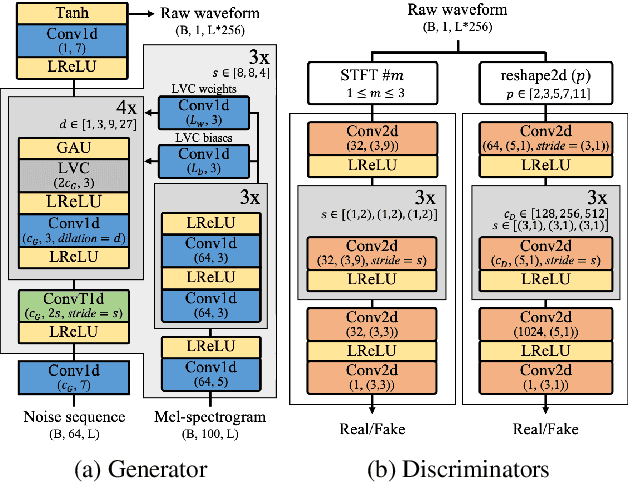
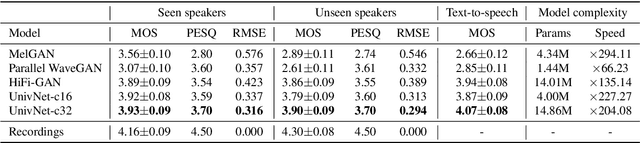
Most neural vocoders employ band-limited mel-spectrograms to generate waveforms. If full-band spectral features are used as the input, the vocoder can be provided with as much acoustic information as possible. However, in some models employing full-band mel-spectrograms, an over-smoothing problem occurs as part of which non-sharp spectrograms are generated. To address this problem, we propose UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multi-resolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input. In an evaluation on a dataset containing information on hundreds of speakers, UnivNet obtained the best objective and subjective results among competing models for both seen and unseen speakers. These results, including the best subjective score for text-to-speech, demonstrate the potential for fast adaptation to new speakers without a need for training from scratch.