 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Parsimony-Enhanced Sparse Bayesian Learning for Robust Discovery of Partial Differential Equations
Jul 08, 2021
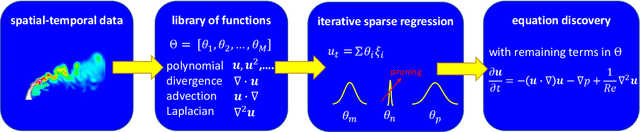
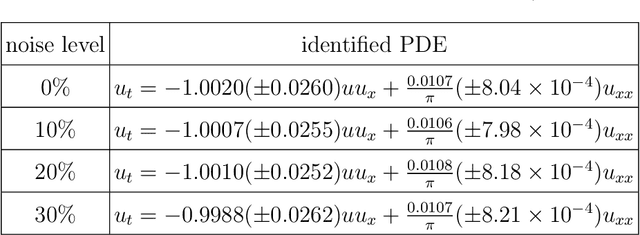
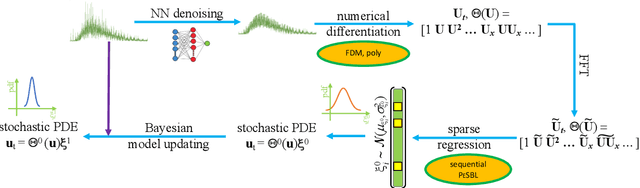
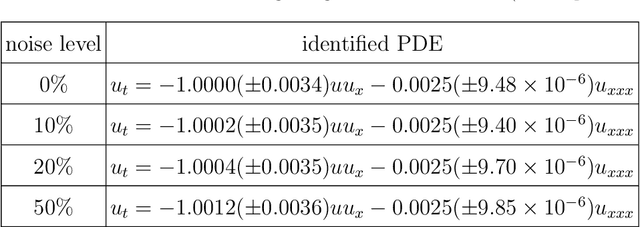
Robust physics discovery is of great interest for many scientific and engineering fields. Inspired by the principle that a representative model is the one simplest possible, a new model selection criteria considering both model's Parsimony and Sparsity is proposed. A Parsimony Enhanced Sparse Bayesian Learning (PeSBL) method is developed for discovering the governing Partial Differential Equations (PDEs) of nonlinear dynamical systems. Compared with the conventional Sparse Bayesian Learning (SBL) method, the PeSBL method promotes parsimony of the learned model in addition to its sparsity. In this method, the parsimony of model terms is evaluated using their locations in the prescribed candidate library, for the first time, considering the increased complexity with the power of polynomials and the order of spatial derivatives. Subsequently, the model parameters are updated through Bayesian inference with the raw data. This procedure aims to reduce the error associated with the possible loss of information in data preprocessing and numerical differentiation prior to sparse regression. Results of numerical case studies indicate that the governing PDEs of many canonical dynamical systems can be correctly identified using the proposed PeSBL method from highly noisy data (up to 50% in the current study). Next, the proposed methodology is extended for stochastic PDE learning where all parameters and modeling error are considered as random variables. Hierarchical Bayesian Inference (HBI) is integrated with the proposed framework for stochastic PDE learning from a population of observations. Finally, the proposed PeSBL is demonstrated for system response prediction with uncertainties and anomaly diagnosis. Codes of all demonstrated examples in this study are available on the website: https://github.com/ymlasu.
MODETR: Moving Object Detection with Transformers
Jun 21, 2021
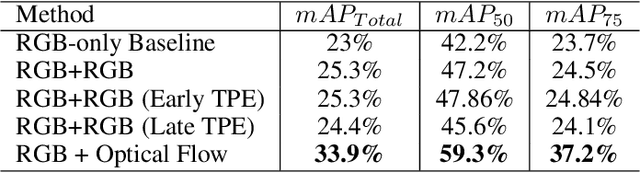

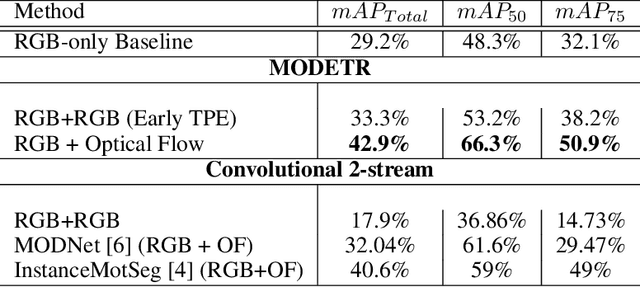
Moving Object Detection (MOD) is a crucial task for the Autonomous Driving pipeline. MOD is usually handled via 2-stream convolutional architectures that incorporates both appearance and motion cues, without considering the inter-relations between the spatial or motion features. In this paper, we tackle this problem through multi-head attention mechanisms, both across the spatial and motion streams. We propose MODETR; a Moving Object DEtection TRansformer network, comprised of multi-stream transformer encoders for both spatial and motion modalities, and an object transformer decoder that produces the moving objects bounding boxes using set predictions. The whole architecture is trained end-to-end using bi-partite loss. Several methods of incorporating motion cues with the Transformer model are explored, including two-stream RGB and Optical Flow (OF) methods, and multi-stream architectures that take advantage of sequence information. To incorporate the temporal information, we propose a new Temporal Positional Encoding (TPE) approach to extend the Spatial Positional Encoding(SPE) in DETR. We explore two architectural choices for that, balancing between speed and time. To evaluate the our network, we perform the MOD task on the KITTI MOD [6] data set. Results show significant 5% mAP of the Transformer network for MOD over the state-of-the art methods. Moreover, the proposed TPE encoding provides 10% mAP improvement over the SPE baseline.
Phase retrieval from 4-dimensional electron diffraction datasets
Jun 15, 2021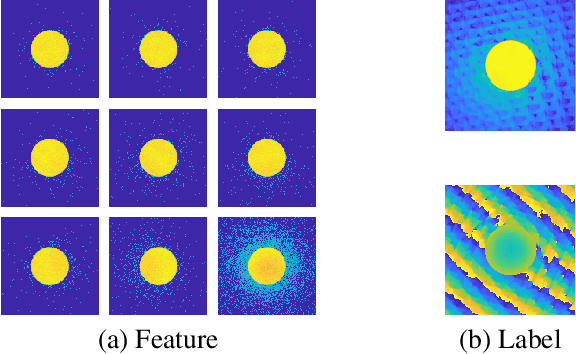
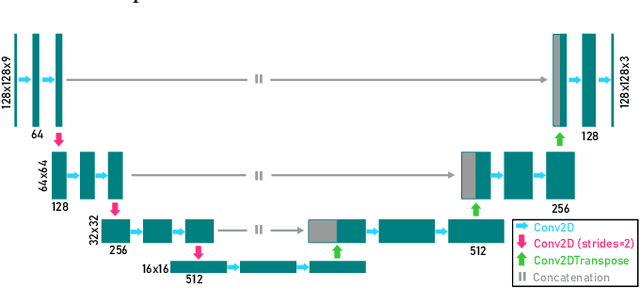
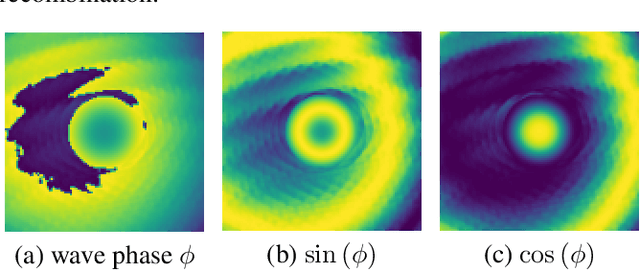
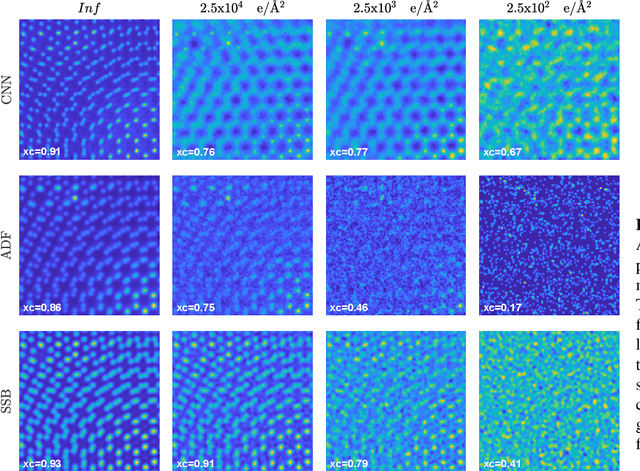
We present a computational imaging mode for large scale electron microscopy data, which retrieves a complex wave from noisy/sparse intensity recordings using a deep learning approach and subsequently reconstructs an image of the specimen from the Convolutional Neural Network (CNN) predicted exit waves. We demonstrate that an appropriate forward model in combination with open data frameworks can be used to generate large synthetic datasets for training. In combination with augmenting the data with Poisson noise corresponding to varying dose-values, we effectively eliminate overfitting issues. The U-NET based architecture of the CNN is adapted to the task at hand and performs well while maintaining a relatively small size and fast performance. The validity of the approach is confirmed by comparing the reconstruction to well-established methods using simulated, as well as real electron microscopy data. The proposed method is shown to be effective particularly in the low dose range, evident by strong suppression of noise, good spatial resolution, and sensitivity to different atom types, enabling the simultaneous visualisation of light and heavy elements and making different atomic species distinguishable. Since the method acts on a very local scale and is comparatively fast it bears the potential to be used for near-real-time reconstruction during data acquisition.
Classification of Documents Extracted from Images with Optical Character Recognition Methods
Jun 15, 2021

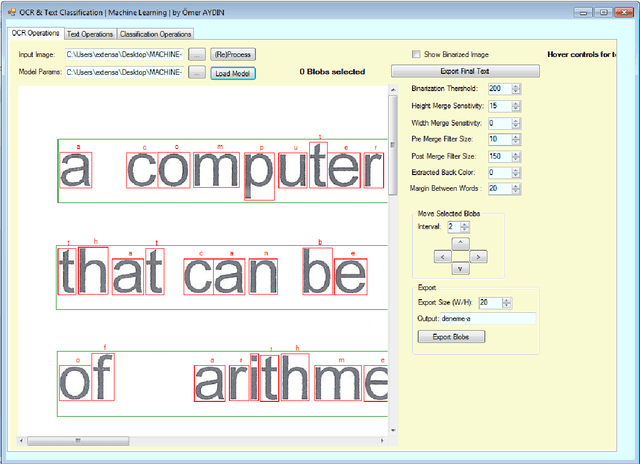

Over the past decade, machine learning methods have given us driverless cars, voice recognition, effective web search, and a much better understanding of the human genome. Machine learning is so common today that it is used dozens of times a day, possibly unknowingly. Trying to teach a machine some processes or some situations can make them predict some results that are difficult to predict by the human brain. These methods also help us do some operations that are often impossible or difficult to do with human activities in a short time. For these reasons, machine learning is so important today. In this study, two different machine learning methods were combined. In order to solve a real-world problem, the manuscript documents were first transferred to the computer and then classified. We used three basic methods to realize the whole process. Handwriting or printed documents have been digitalized by a scanner or digital camera. These documents have been processed with two different Optical Character Recognition (OCR) operation. After that generated texts are classified by using Naive Bayes algorithm. All project was programmed in Microsoft Visual Studio 12 platform on Windows operating system. C# programming language was used for all parts of the study. Also, some prepared codes and DLLs were used.
MLFriend: Interactive Prediction Task Recommendation for Event-Driven Time-Series Data
Jun 28, 2019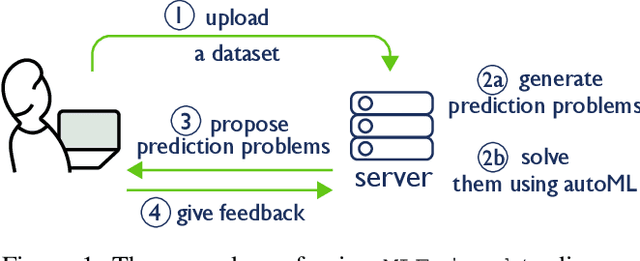

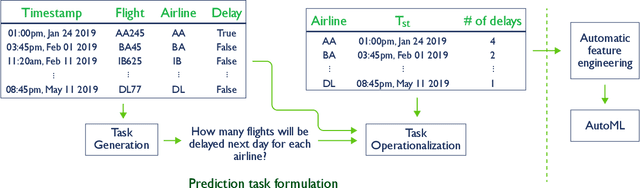

Most automation in machine learning focuses on model selection and hyper parameter tuning, and many overlook the challenge of automatically defining predictive tasks. We still heavily rely on human experts to define prediction tasks, and generate labels by aggregating raw data. In this paper, we tackle the challenge of defining useful prediction problems on event-driven time-series data. We introduce MLFriend to address this challenge. MLFriend first generates all possible prediction tasks under a predefined space, then interacts with a data scientist to learn the context of the data and recommend good prediction tasks from all the tasks in the space. We evaluate our system on three different datasets and generate a total of 2885 prediction tasks and solve them. Out of these 722 were deemed useful by expert data scientists. We also show that an automatic prediction task discovery system is able to identify top 10 tasks that a user may like within a batch of 100 tasks.
Energy Efficient Federated Learning in Integrated Fog-Cloud Computing Enabled Internet-of-Things Networks
Jul 07, 2021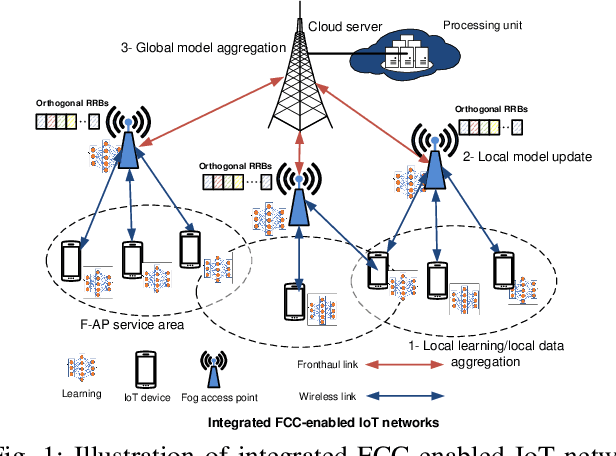
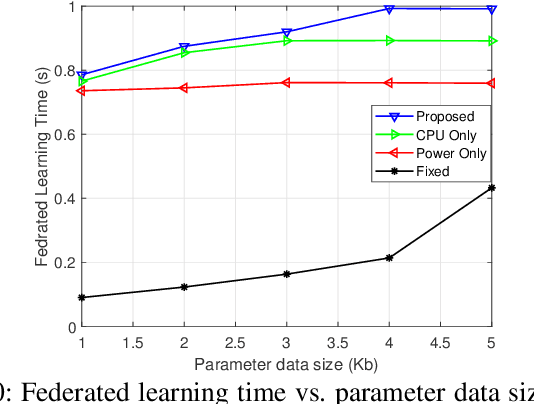
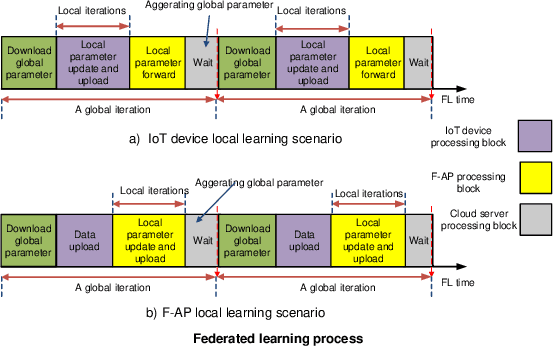
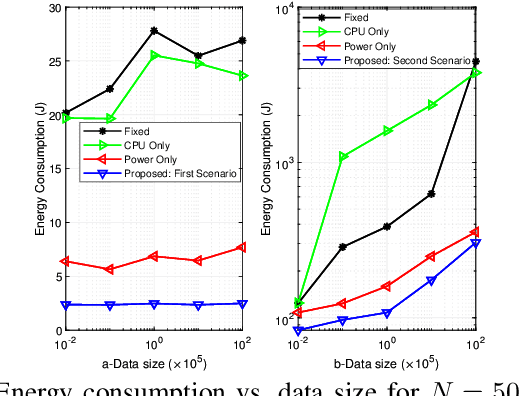
We investigate resource allocation scheme to reduce the energy consumption of federated learning (FL) in the integrated fog-cloud computing enabled Internet-of-things (IoT) networks. In the envisioned system, IoT devices are connected with the centralized cloud server (CS) via multiple fog access points (F-APs). We consider two different scenarios for training the local models. In the first scenario, local models are trained at the IoT devices and the F-APs upload the local model parameters to the CS. In the second scenario, local models are trained at the F-APs based on the collected data from the IoT devices and the F-APs collaborate with the CS for updating the model parameters. Our objective is to minimize the overall energy-consumption of both scenarios subject to FL time constraint. Towards this goal, we devise a joint optimization of scheduling of IoT devices with the F-APs, transmit power allocation, computation frequency allocation at the devices and F-APs and decouple it into two subproblems. In the first subproblem, we optimize the IoT device scheduling and power allocation, while in the second subproblem, we optimize the computation frequency allocation. For each scenario, we develop a conflict graph based solution to iteratively solve the two subproblems. Simulation results show that the proposed two schemes achieve a considerable performance gain in terms of the energy consumption minimization. The presented simulation results interestingly reveal that for a large number of IoT devices and large data sizes, it is more energy efficient to train the local models at the IoT devices instead of the F-APs.
Modelling Urban Dynamics with Multi-Modal Graph Convolutional Networks
Apr 29, 2021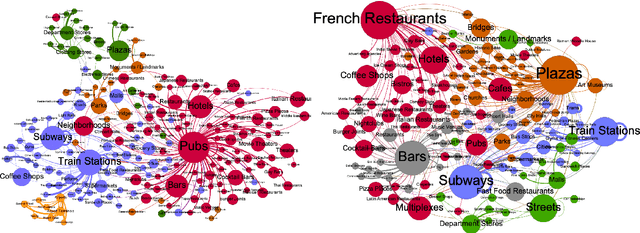
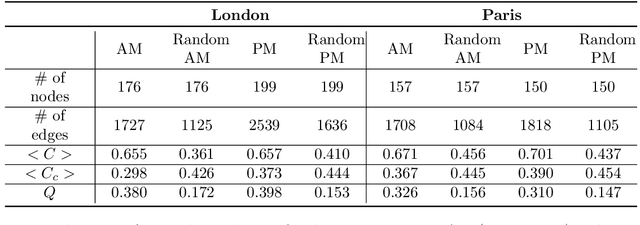
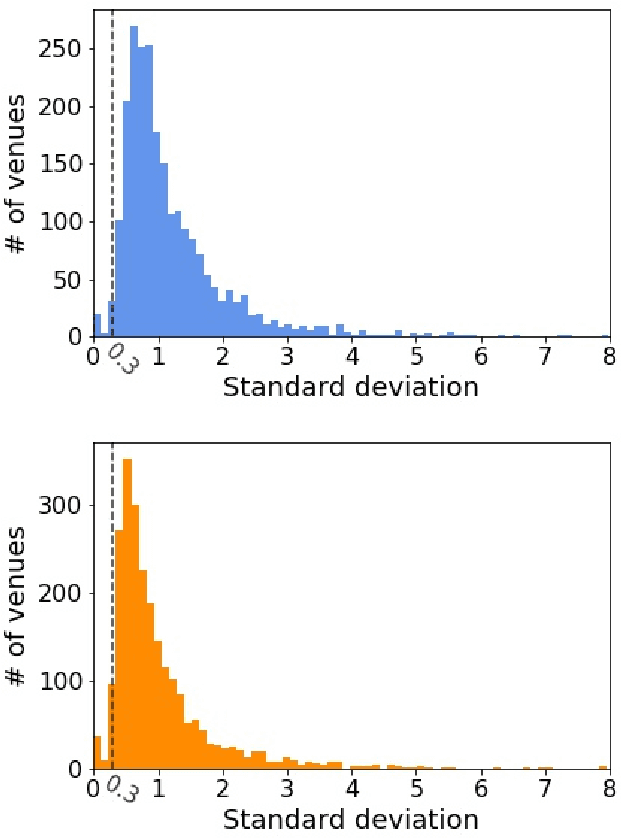
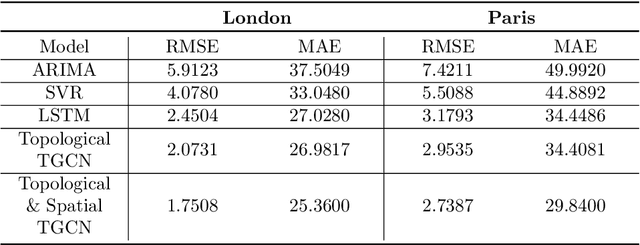
Modelling the dynamics of urban venues is a challenging task as it is multifaceted in nature. Demand is a function of many complex and nonlinear features such as neighborhood composition, real-time events, and seasonality. Recent advances in Graph Convolutional Networks (GCNs) have had promising results as they build a graphical representation of a system and harness the potential of deep learning architectures. However, there has been limited work using GCNs in a temporal setting to model dynamic dependencies of the network. Further, within the context of urban environments, there has been no prior work using dynamic GCNs to support venue demand analysis and prediction. In this paper, we propose a novel deep learning framework which aims to better model the popularity and growth of urban venues. Using a longitudinal dataset from location technology platform Foursquare, we model individual venues and venue types across London and Paris. First, representing cities as connected networks of venues, we quantify their structure and note a strong community structure in these retail networks, an observation that highlights the interplay of cooperative and competitive forces that emerge in local ecosystems of retail businesses. Next, we present our deep learning architecture which integrates both spatial and topological features into a temporal model which predicts the demand of a venue at the subsequent time-step. Our experiments demonstrate that our model can learn spatio-temporal trends of venue demand and consistently outperform baseline models. Relative to state-of-the-art deep learning models, our model reduces the RSME by ~ 28% in London and ~ 13% in Paris. Our approach highlights the power of complex network measures and GCNs in building prediction models for urban environments. The model could have numerous applications within the retail sector to better model venue demand and growth.
Reinforcement Learning for Resource Allocation in Steerable Laser-based Optical Wireless Systems
Jun 21, 2021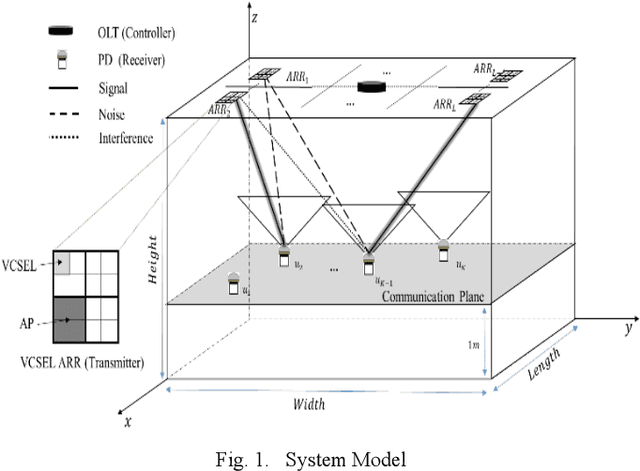
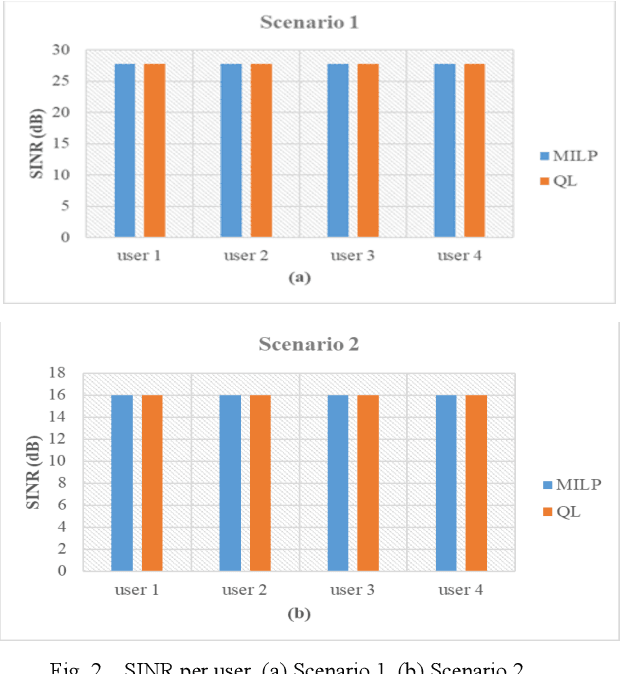
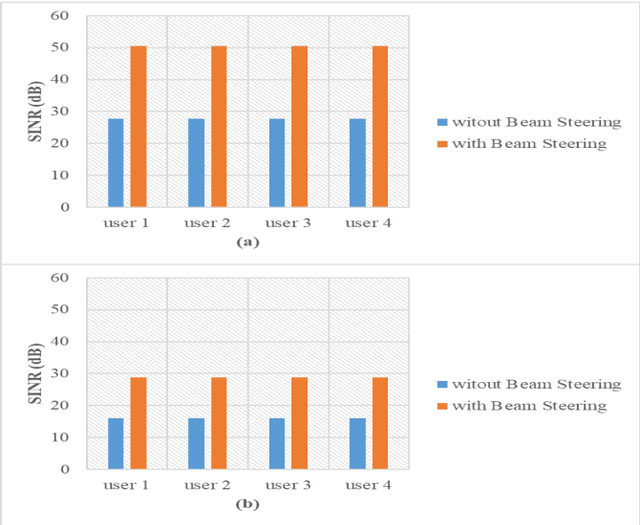
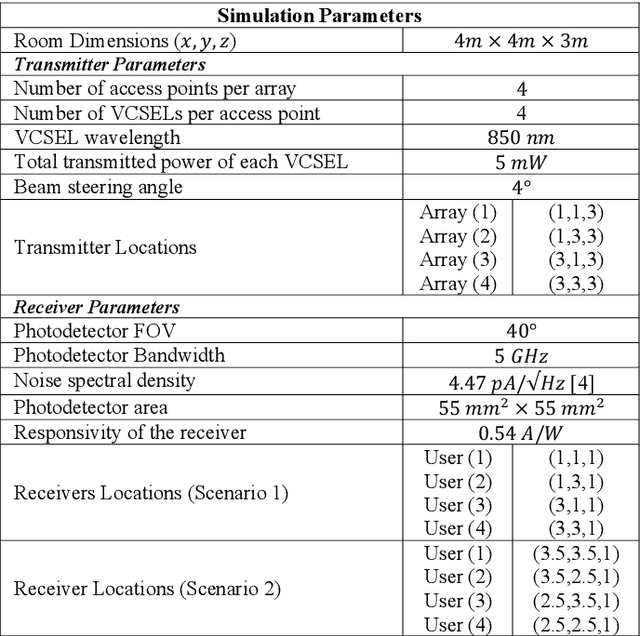
Vertical Cavity Surface Emitting Lasers (VCSELs) have demonstrated suitability for data transmission in indoor optical wireless communication (OWC) systems due to the high modulation bandwidth and low manufacturing cost of these sources. Specifically, resource allocation is one of the major challenges that can affect the performance of multi-user optical wireless systems. In this paper, an optimisation problem is formulated to optimally assign each user to an optical access point (AP) composed of multiple VCSELs within a VCSEL array at a certain time to maximise the signal to interference plus noise ratio (SINR). In this context, a mixed-integer linear programming (MILP) model is introduced to solve this optimisation problem. Despite the optimality of the MILP model, it is considered impractical due to its high complexity, high memory and full system information requirements. Therefore, reinforcement Learning (RL) is considered, which recently has been widely investigated as a practical solution for various optimization problems in cellular networks due to its ability to interact with environments with no previous experience. In particular, a Q-learning (QL) algorithm is investigated to perform resource management in a steerable VCSEL-based OWC systems. The results demonstrate the ability of the QL algorithm to achieve optimal solutions close to the MILP model. Moreover, the adoption of beam steering, using holograms implemented by exploiting liquid crystal devices, results in further enhancement in the performance of the network considered.
Progressively Normalized Self-Attention Network for Video Polyp Segmentation
May 24, 2021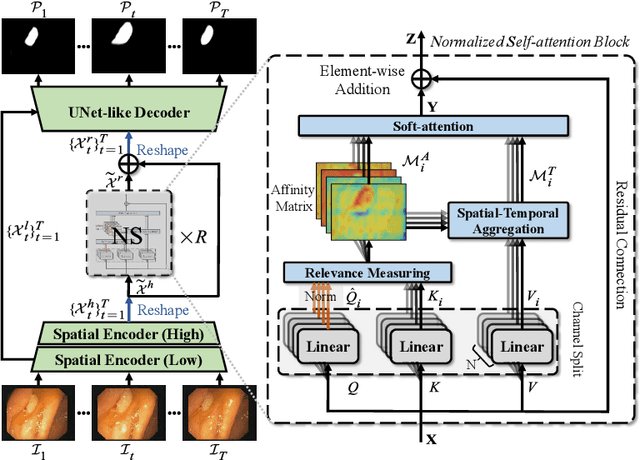
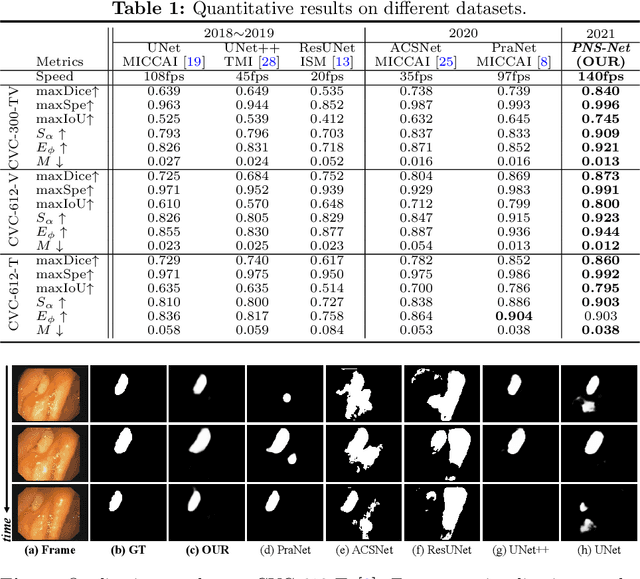
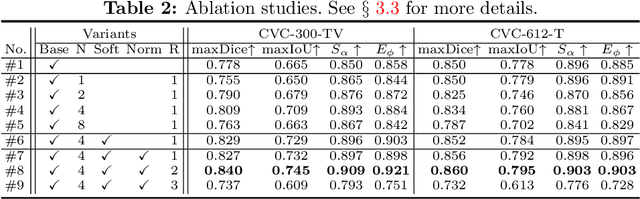
Existing video polyp segmentation (VPS) models typically employ convolutional neural networks (CNNs) to extract features. However, due to their limited receptive fields, CNNs can not fully exploit the global temporal and spatial information in successive video frames, resulting in false-positive segmentation results. In this paper, we propose the novel PNS-Net (Progressively Normalized Self-attention Network), which can efficiently learn representations from polyp videos with real-time speed (~140fps) on a single RTX 2080 GPU and no post-processing. Our PNS-Net is based solely on a basic normalized self-attention block, equipping with recurrence and CNNs entirely. Experiments on challenging VPS datasets demonstrate that the proposed PNS-Net achieves state-of-the-art performance. We also conduct extensive experiments to study the effectiveness of the channel split, soft-attention, and progressive learning strategy. We find that our PNS-Net works well under different settings, making it a promising solution to the VPS task.
LaplaceNet: A Hybrid Energy-Neural Model for Deep Semi-Supervised Classification
Jun 08, 2021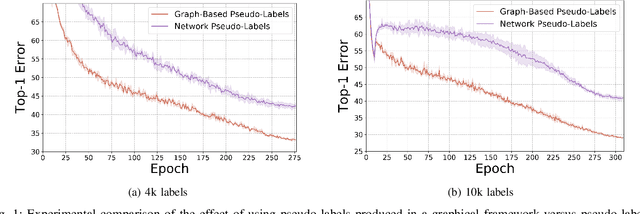
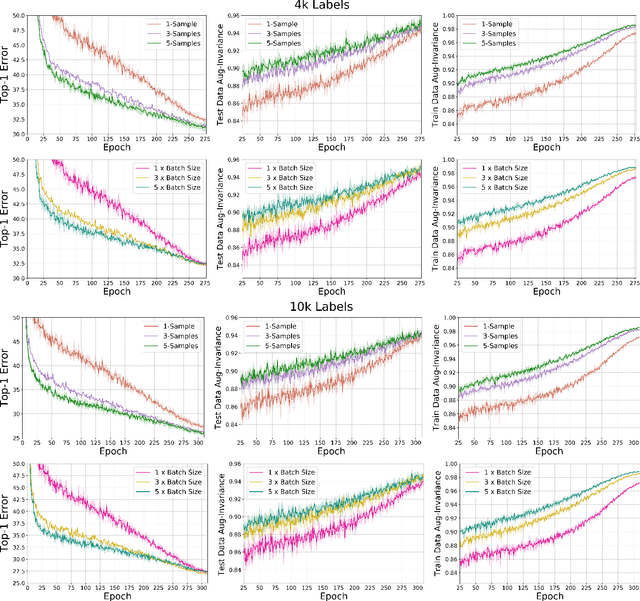

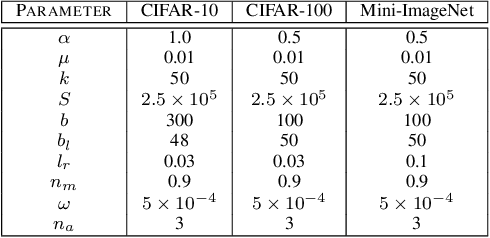
Semi-supervised learning has received a lot of recent attention as it alleviates the need for large amounts of labelled data which can often be expensive, requires expert knowledge and be time consuming to collect. Recent developments in deep semi-supervised classification have reached unprecedented performance and the gap between supervised and semi-supervised learning is ever-decreasing. This improvement in performance has been based on the inclusion of numerous technical tricks, strong augmentation techniques and costly optimisation schemes with multi-term loss functions. We propose a new framework, LaplaceNet, for deep semi-supervised classification that has a greatly reduced model complexity. We utilise a hybrid energy-neural network where graph based pseudo-labels, generated by minimising the graphical Laplacian, are used to iteratively improve a neural-network backbone. Our model outperforms state-of-the-art methods for deep semi-supervised classification, over several benchmark datasets. Furthermore, we consider the application of strong-augmentations to neural networks theoretically and justify the use of a multi-sampling approach for semi-supervised learning. We demonstrate, through rigorous experimentation, that a multi-sampling augmentation approach improves generalisation and reduces the sensitivity of the network to augmentation.