 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scaling-up Diverse Orthogonal Convolutional Networks with a Paraunitary Framework
Jun 16, 2021

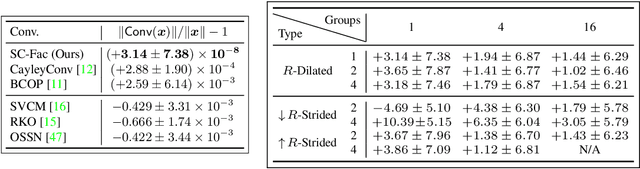
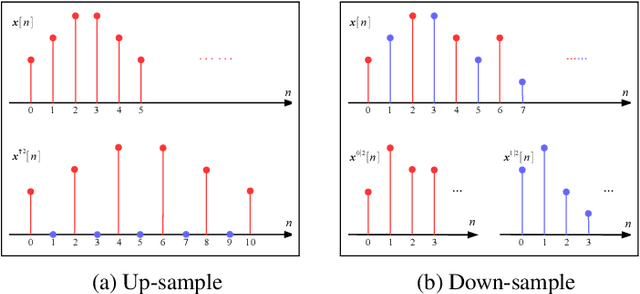
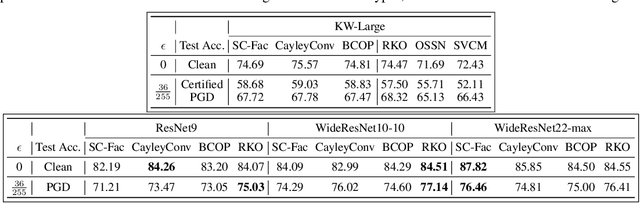
Enforcing orthogonality in neural networks is an antidote for gradient vanishing/exploding problems, sensitivity by adversarial perturbation, and bounding generalization errors. However, many previous approaches are heuristic, and the orthogonality of convolutional layers is not systematically studied: some of these designs are not exactly orthogonal, while others only consider standard convolutional layers and propose specific classes of their realizations. To address this problem, we propose a theoretical framework for orthogonal convolutional layers, which establishes the equivalence between various orthogonal convolutional layers in the spatial domain and the paraunitary systems in the spectral domain. Since there exists a complete spectral factorization of paraunitary systems, any orthogonal convolution layer can be parameterized as convolutions of spatial filters. Our framework endows high expressive power to various convolutional layers while maintaining their exact orthogonality. Furthermore, our layers are memory and computationally efficient for deep networks compared to previous designs. Our versatile framework, for the first time, enables the study of architecture designs for deep orthogonal networks, such as choices of skip connection, initialization, stride, and dilation. Consequently, we scale up orthogonal networks to deep architectures, including ResNet, WideResNet, and ShuffleNet, substantially increasing the performance over the traditional shallow orthogonal networks.
MODISSA: a multipurpose platform for the prototypical realization of vehicle-related applications using optical sensors
May 28, 2021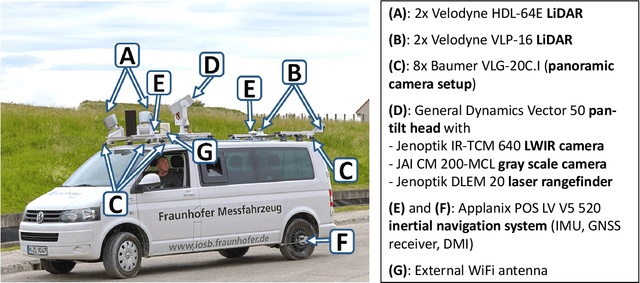

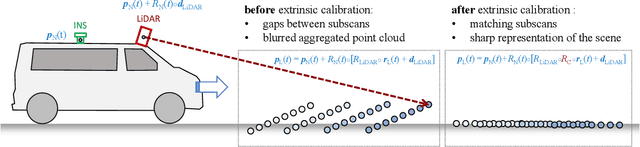

We present the current state of development of the sensor-equipped car MODISSA, with which Fraunhofer IOSB realizes a configurable experimental platform for hardware evaluation and software development in the context of mobile mapping and vehicle-related safety and protection. MODISSA is based on a van that has successively been equipped with a variety of optical sensors over the past few years, and contains hardware for complete raw data acquisition, georeferencing, real-time data analysis, and immediate visualization on in-car displays. We demonstrate the capabilities of MODISSA by giving a deeper insight into experiments with its specific configuration in the scope of three different applications. Other research groups can benefit from these experiences when setting up their own mobile sensor system, especially regarding the selection of hardware and software, the knowledge of possible sources of error, and the handling of the acquired sensor data.
* Authors' version of an article accepted for publication in Applied Optics, 9 May 2021
Hierarchical Learning Framework for UAV Detection and Identification
Jul 10, 2021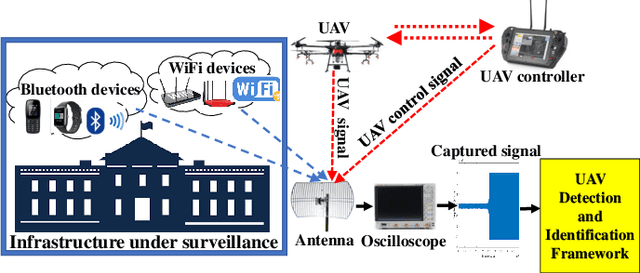
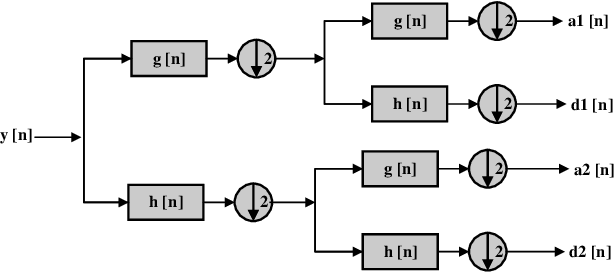
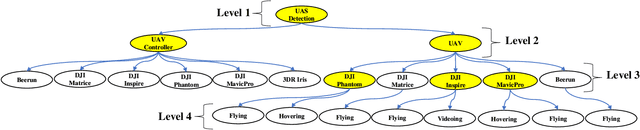
The ubiquity of unmanned aerial vehicles (UAVs) or drones is posing both security and safety risks to the public as UAVs are now used for cybercrimes. To mitigate these risks, it is important to have a system that can detect or identify the presence of an intruding UAV in a restricted environment. In this work, we propose a radio frequency (RF) based UAV detection and identification system by exploiting signals emanating from both the UAV and its flight controller, respectively. While several RF devices (i.e., Bluetooth and WiFi devices) operate in the same frequency band as UAVs, the proposed framework utilizes a semi-supervised learning approach for the detection of UAV or UAV's control signals in the presence of other wireless signals such as Bluetooth and WiFi. The semi-supervised learning approach uses stacked denoising autoencoder and local outlier factor algorithms. After the detection of UAV or UAV's control signals, the signal is decomposed by using Hilbert-Huang transform and wavelet packet transform to extract features from the time-frequency-energy domain of the signal. The extracted feature sets are used to train a three-level hierarchical classifier for identifying the type of signals (i.e., UAV or UAV control signal), UAV models, and flight mode of UAV. To demonstrate the feasibility of the proposed framework, we carried out an outdoor experiment for data collection using six UAVs, five Bluetooth devices, and two WiFi devices. The acquired data is called Cardinal RF (CardRF) dataset, and it is available for public use to foster UAV detection and identification research.
TENSILE: A Tensor granularity dynamic GPU memory scheduler method towards multiple dynamic workloads system
May 28, 2021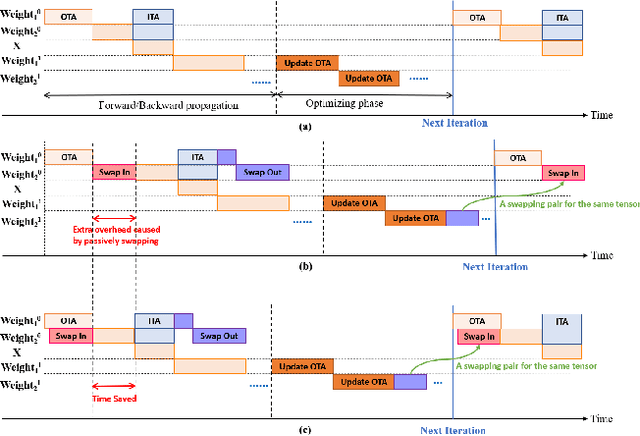
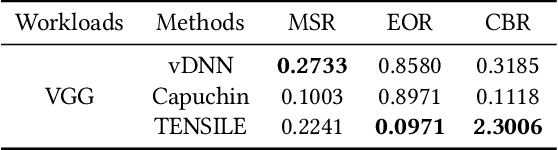
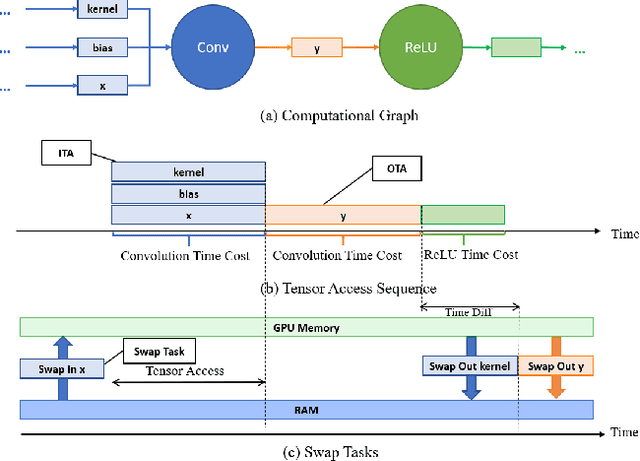
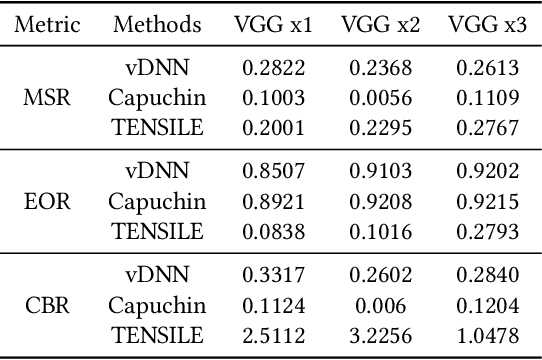
Recently, deep learning has been an area of intense researching. However, as a kind of computing intensive task, deep learning highly relies on the the scale of the GPU memory, which is usually expensive and scarce. Although there are some extensive works have been proposed for dynamic GPU memory management, they are hard to be applied to systems with multitasking dynamic workloads, such as in-database machine learning system. In this paper, we demonstrated TENSILE, a method of managing GPU memory in tensor granularity to reduce the GPU memory peak, with taking the multitasking dynamic workloads into consideration. As far as we know, TENSILE is the first method which is designed to manage multiple workloads' GPU memory using. We implement TENSILE on our own deep learning framework, and evaluated its performance. The experiment results shows that our method can achieve less time overhead than prior works with more GPU memory saved.
Structure-aware reinforcement learning for node-overload protection in mobile edge computing
Jun 29, 2021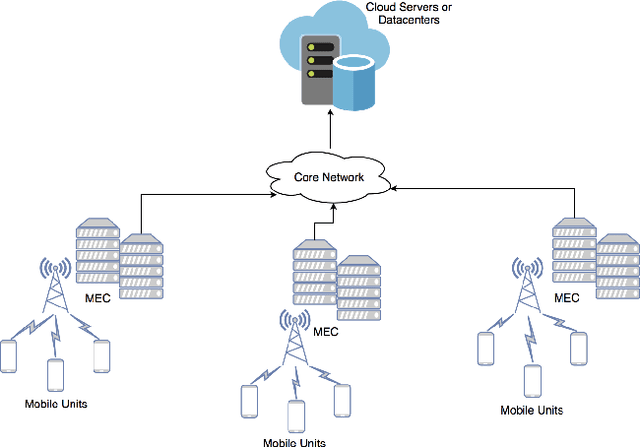
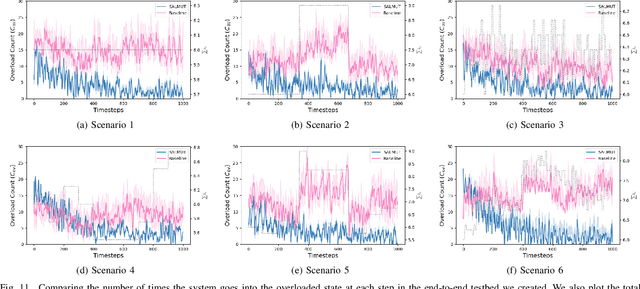
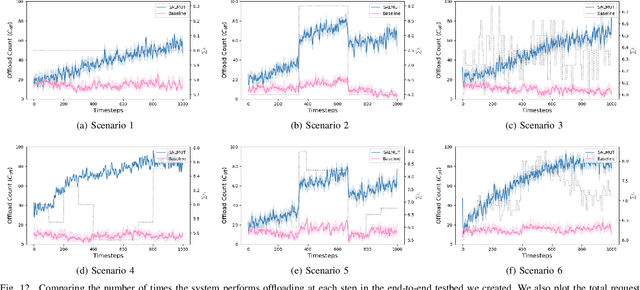
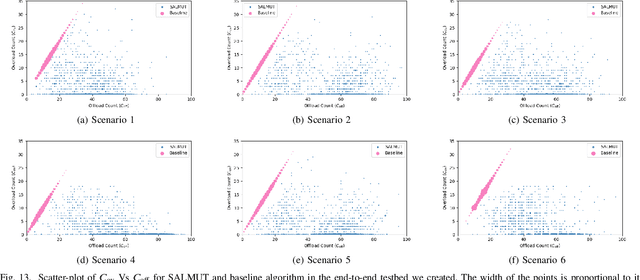
Mobile Edge Computing (MEC) refers to the concept of placing computational capability and applications at the edge of the network, providing benefits such as reduced latency in handling client requests, reduced network congestion, and improved performance of applications. The performance and reliability of MEC are degraded significantly when one or several edge servers in the cluster are overloaded. Especially when a server crashes due to the overload, it causes service failures in MEC. In this work, an adaptive admission control policy to prevent edge node from getting overloaded is presented. This approach is based on a recently-proposed low complexity RL (Reinforcement Learning) algorithm called SALMUT (Structure-Aware Learning for Multiple Thresholds), which exploits the structure of the optimal admission control policy in multi-class queues for an average-cost setting. We extend the framework to work for node overload-protection problem in a discounted-cost setting. The proposed solution is validated using several scenarios mimicking real-world deployments in two different settings - computer simulations and a docker testbed. Our empirical evaluations show that the total discounted cost incurred by SALMUT is similar to state-of-the-art deep RL algorithms such as PPO (Proximal Policy Optimization) and A2C (Advantage Actor Critic) but requires an order of magnitude less time to train, outputs easily interpretable policy, and can be deployed in an online manner.
Real-Time Sleep Staging using Deep Learning on a Smartphone for a Wearable EEG
Nov 28, 2018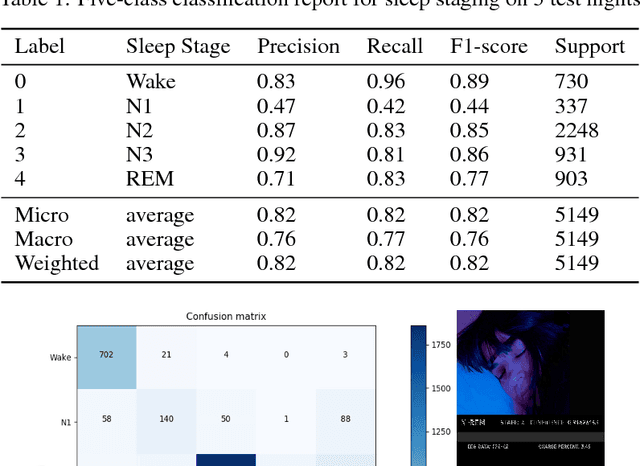

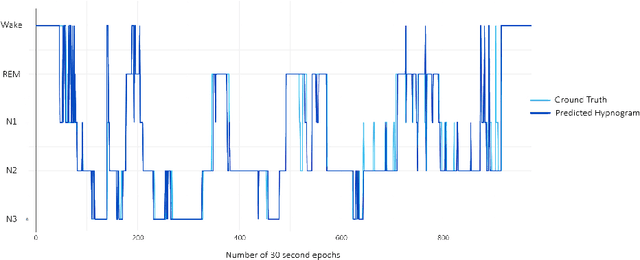
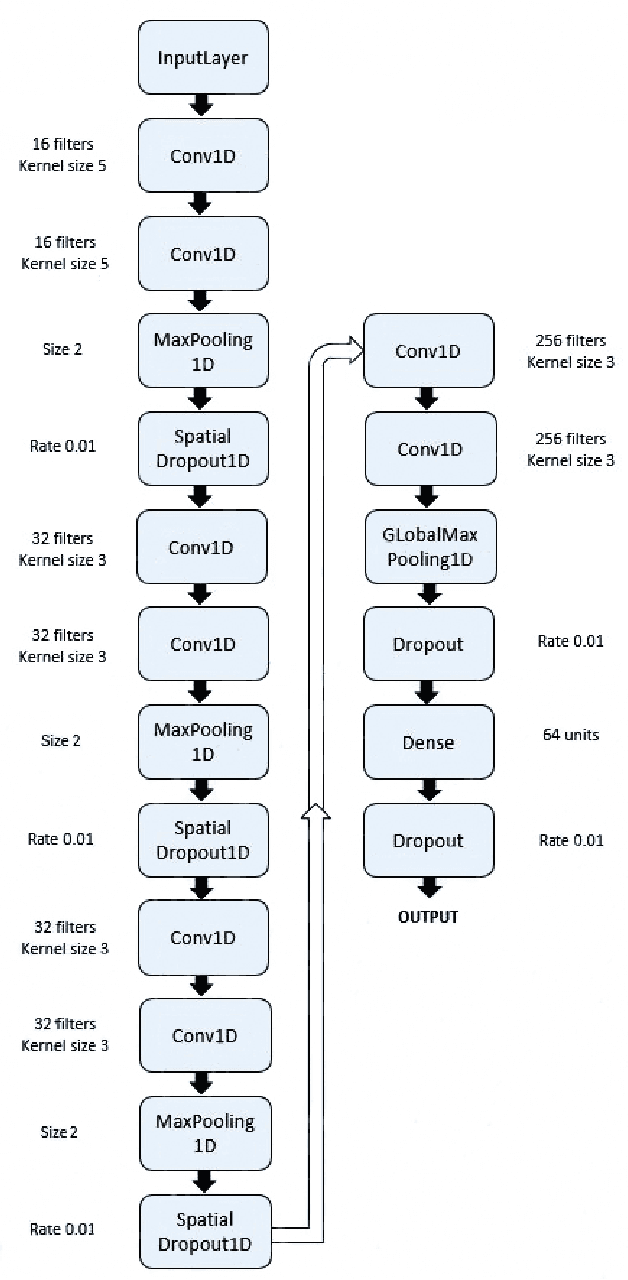
We present the first real-time sleep staging system that uses deep learning without the need for servers in a smartphone application for a wearable EEG. We employ real-time adaptation of a single channel Electroencephalography (EEG) to infer from a Time-Distributed 1-D Deep Convolutional Neural Network. Polysomnography (PSG)-the gold standard for sleep staging, requires a human scorer and is both complex and resource-intensive. Our work demonstrates an end-to-end on-smartphone pipeline that can infer sleep stages in just single 30-second epochs, with an overall accuracy of 83.5% on 20-fold cross validation for five-class classification of sleep stages using the open Sleep-EDF dataset.
Directional GAN: A Novel Conditioning Strategy for Generative Networks
May 13, 2021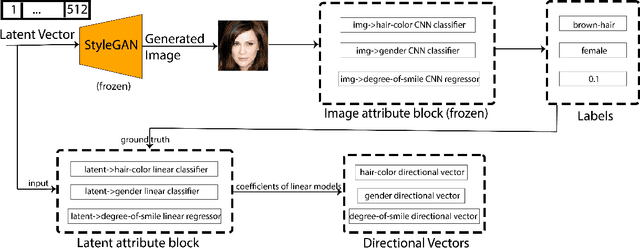

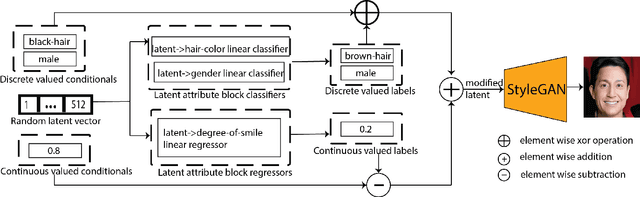
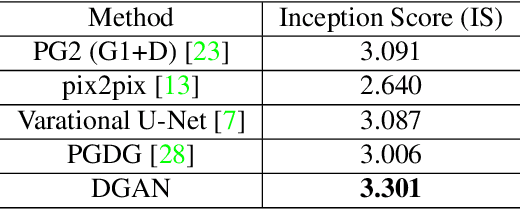
Image content is a predominant factor in marketing campaigns, websites and banners. Today, marketers and designers spend considerable time and money in generating such professional quality content. We take a step towards simplifying this process using Generative Adversarial Networks (GANs). We propose a simple and novel conditioning strategy which allows generation of images conditioned on given semantic attributes using a generator trained for an unconditional image generation task. Our approach is based on modifying latent vectors, using directional vectors of relevant semantic attributes in latent space. Our method is designed to work with both discrete (binary and multi-class) and continuous image attributes. We show the applicability of our proposed approach, named Directional GAN, on multiple public datasets, with an average accuracy of 86.4% across different attributes.
A Review-based Taxonomy for Secure Health Care Monitoring: Wireless Smart Cameras
Jul 05, 2021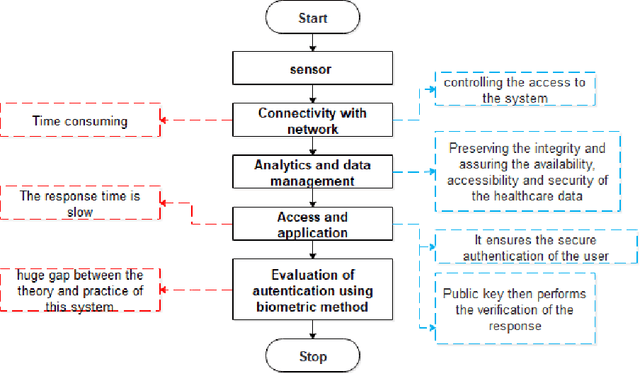
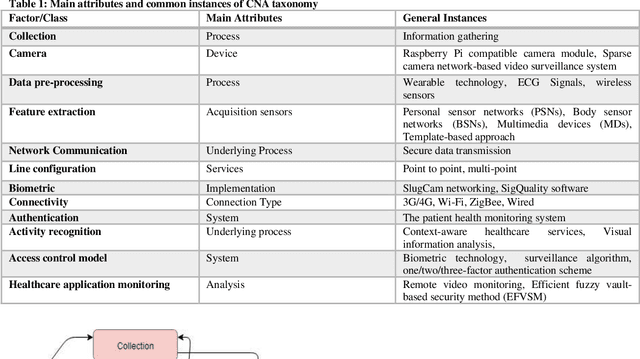
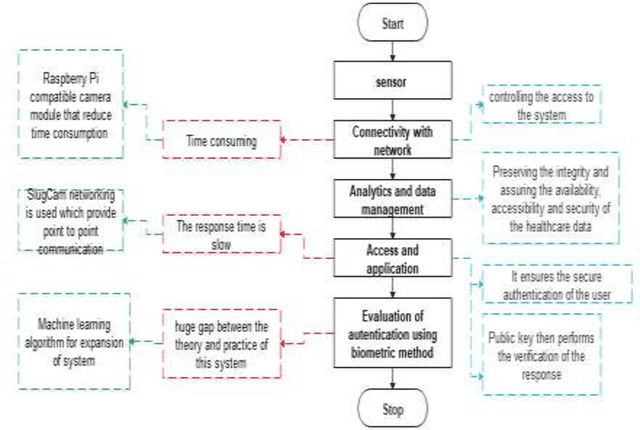
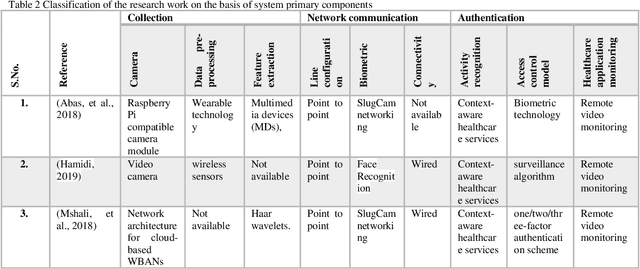
Health records data security is one of the main challenges in e-health systems. Authentication is one of the essential security services to support the stored data confidentiality, integrity, and availability. This research focuses on the secure storage of patient and medical records in the healthcare sector where data security and unauthorized access is an ongoing issue. A potential solution comes from biometrics, although their use may be time-consuming and can slow down data retrieval. This research aims to overcome these challenges and enhance data access control in the healthcare sector through the addition of biometrics in the form of fingerprints. The proposed model for application in the healthcare sector consists of Collection, Network communication, and Authentication (CNA) using biometrics, which replaces an existing password-based access control method. A sensor then collects data and by using a network (wireless or Zig-bee), a connection is established, after connectivity analytics and data management work which processes and aggregate the data. Subsequently, access is granted to authenticated users of the application. This IoT-based biometric authentication system facilitates effective recognition and ensures confidentiality, integrity, and reliability of patients, records and other sensitive data. The proposed solution provides reliable access to healthcare data and enables secure access through the process of user and device authentication. The proposed model has been developed for access control to data through the authentication of users in healthcare to reduce data manipulation or theft.
* 29 pages
Massive Self-Assembly in Grid Environments
Feb 23, 2021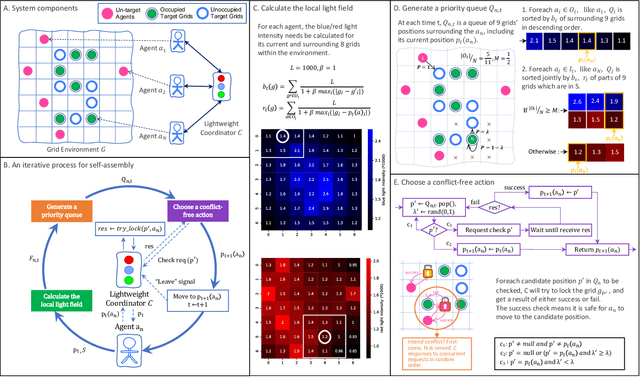
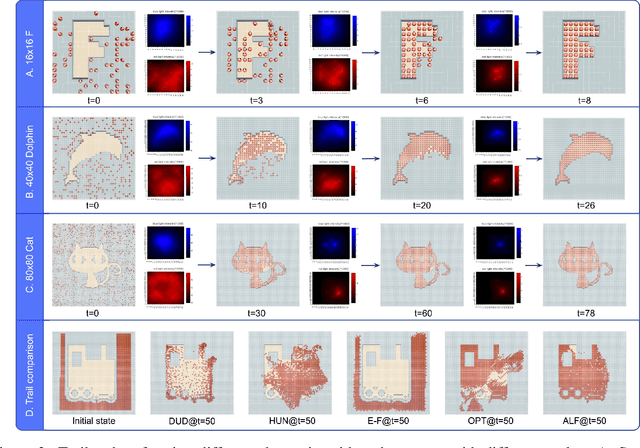
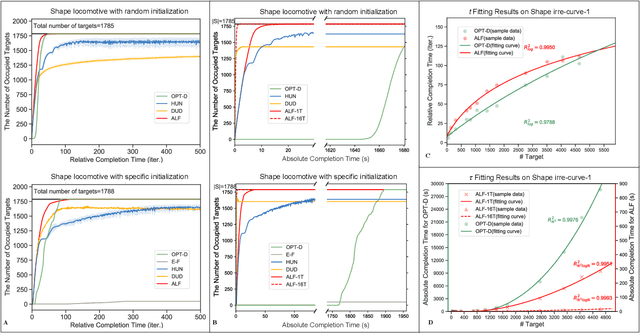
Self-assembly plays an essential role in many natural processes, involving the formation and evolution of living or non-living structures, and shows potential applications in many emerging domains. In existing research and practice, there still lacks an ideal self-assembly mechanism that manifests efficiency, scalability, and stability at the same time. Inspired by phototaxis observed in nature, we propose a computational approach for massive self-assembly of connected shapes in grid environments. The key component of this approach is an artificial light field superimposed on a grid environment, which is determined by the positions of all agents and at the same time drives all agents to change their positions, forming a dynamic mutual feedback process. This work advances the understanding and potential applications of self-assembly.
Gaussian Process Model for Estimating Piecewise Continuous Regression Functions
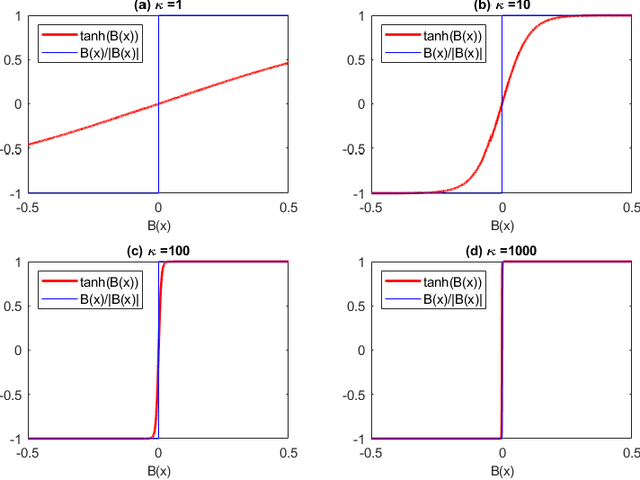
Apr 13, 2021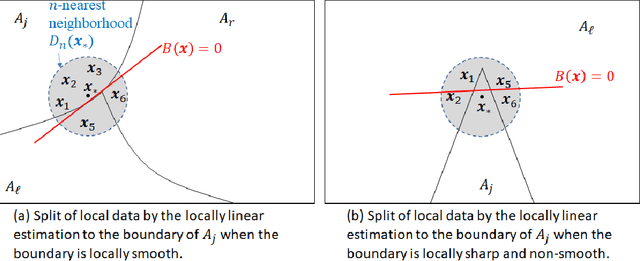
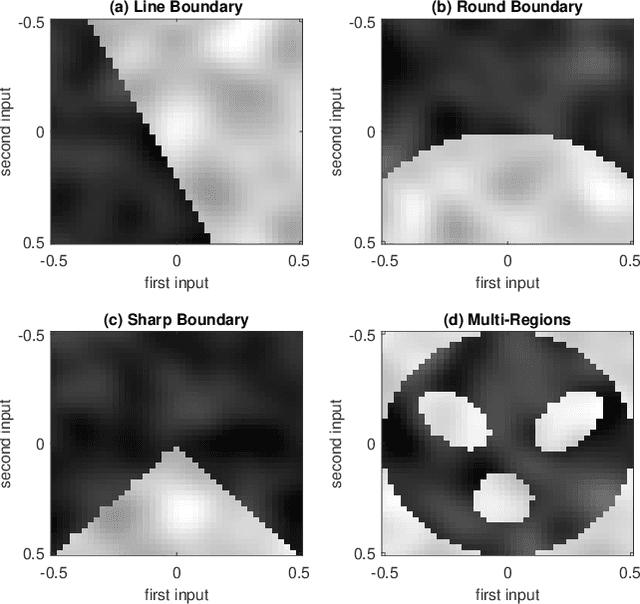
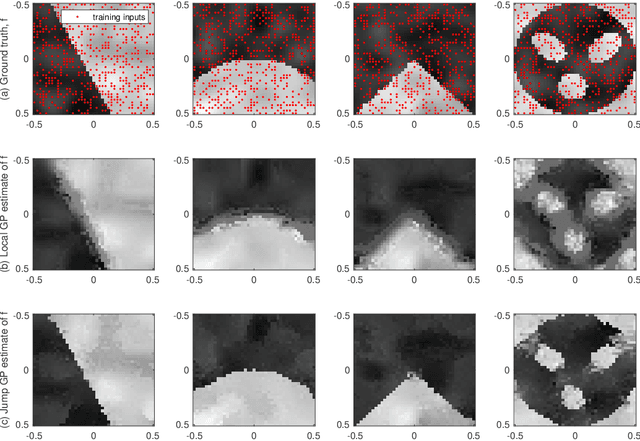
This paper presents a Gaussian process (GP) model for estimating piecewise continuous regression functions. In scientific and engineering applications of regression analysis, the underlying regression functions are piecewise continuous in that data follow different continuous regression models for different regions of the data with possible discontinuities between the regions. However, many conventional GP regression approaches are not designed for piecewise regression analysis. We propose a new GP modeling approach for estimating an unknown piecewise continuous regression function. The new GP model seeks for a local GP estimate of an unknown regression function at each test location, using local data neighboring to the test location. To accommodate the possibilities of the local data from different regions, the local data is partitioned into two sides by a local linear boundary, and only the local data belonging to the same side as the test location is used for the regression estimate. This local split works very well when the input regions are bounded by smooth boundaries, so the local linear approximation of the smooth boundaries works well. We estimate the local linear boundary jointly with the other hyperparameters of the GP model, using the maximum likelihood approach. Its computation time is as low as the local GP's time. The superior numerical performance of the proposed approach over the conventional GP modeling approaches is shown using various simulated piecewise regression functions.