 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Survey on Deep Learning Methods for Semantic Image Segmentation in Real-Time
Sep 27, 2020

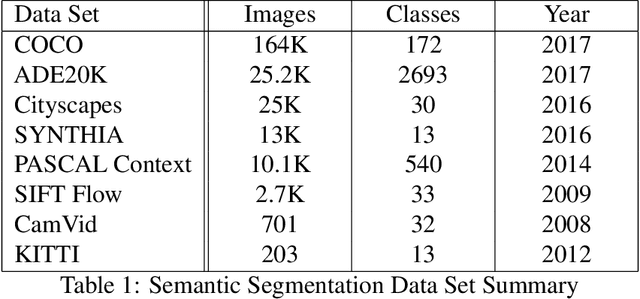
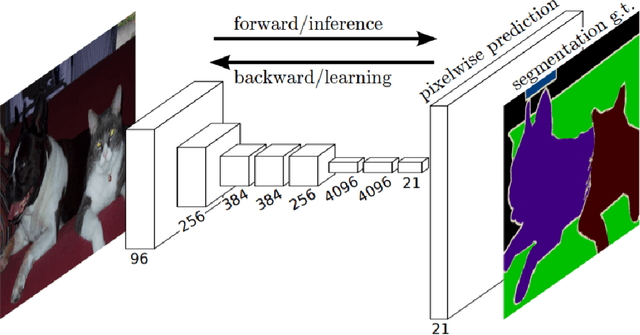
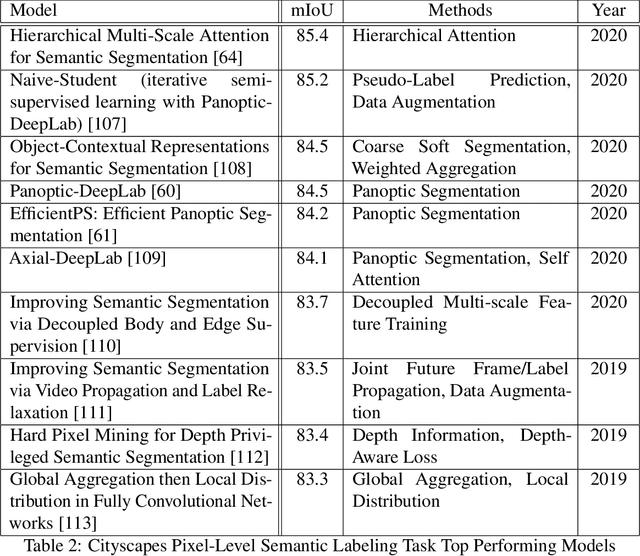
Semantic image segmentation is one of fastest growing areas in computer vision with a variety of applications. In many areas, such as robotics and autonomous vehicles, semantic image segmentation is crucial, since it provides the necessary context for actions to be taken based on a scene understanding at the pixel level. Moreover, the success of medical diagnosis and treatment relies on the extremely accurate understanding of the data under consideration and semantic image segmentation is one of the important tools in many cases. Recent developments in deep learning have provided a host of tools to tackle this problem efficiently and with increased accuracy. This work provides a comprehensive analysis of state-of-the-art deep learning architectures in image segmentation and, more importantly, an extensive list of techniques to achieve fast inference and computational efficiency. The origins of these techniques as well as their strengths and trade-offs are discussed with an in-depth analysis of their impact in the area. The best-performing architectures are summarized with a list of methods used to achieve these state-of-the-art results.
DCCRN+: Channel-wise Subband DCCRN with SNR Estimation for Speech Enhancement
Jun 16, 2021
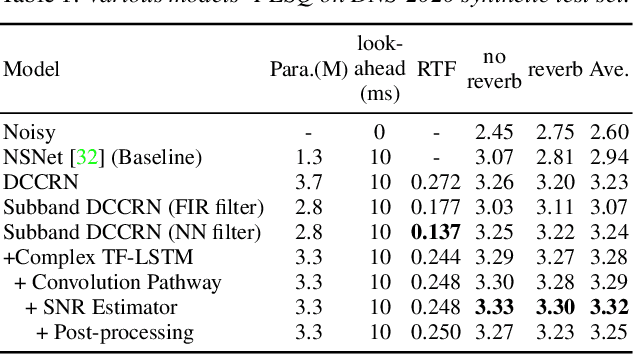
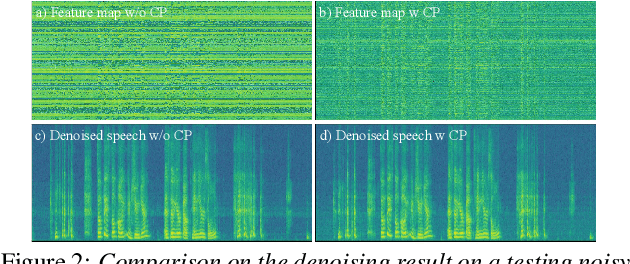

Deep complex convolution recurrent network (DCCRN), which extends CRN with complex structure, has achieved superior performance in MOS evaluation in Interspeech 2020 deep noise suppression challenge (DNS2020). This paper further extends DCCRN with the following significant revisions. We first extend the model to sub-band processing where the bands are split and merged by learnable neural network filters instead of engineered FIR filters, leading to a faster noise suppressor trained in an end-to-end manner. Then the LSTM is further substituted with a complex TF-LSTM to better model temporal dependencies along both time and frequency axes. Moreover, instead of simply concatenating the output of each encoder layer to the input of the corresponding decoder layer, we use convolution blocks to first aggregate essential information from the encoder output before feeding it to the decoder layers. We specifically formulate the decoder with an extra a priori SNR estimation module to maintain good speech quality while removing noise. Finally a post-processing module is adopted to further suppress the unnatural residual noise. The new model, named DCCRN+, has surpassed the original DCCRN as well as several competitive models in terms of PESQ and DNSMOS, and has achieved superior performance in the new Interspeech 2021 DNS challenge
Scaling Up Graph Neural Networks Via Graph Coarsening
Jun 09, 2021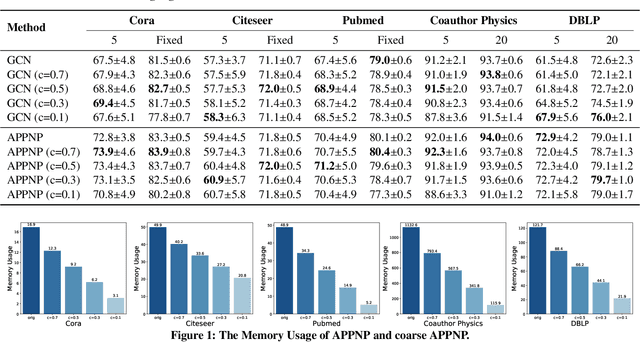
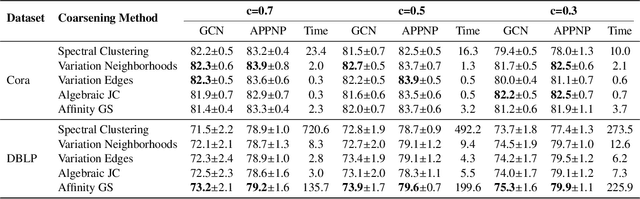
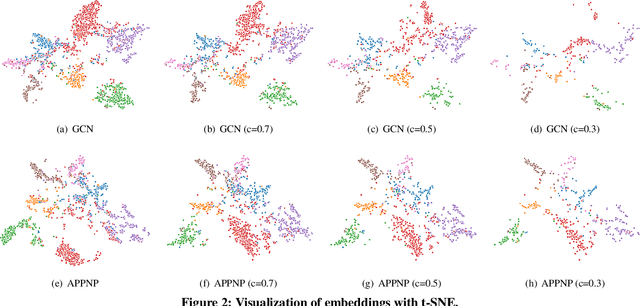
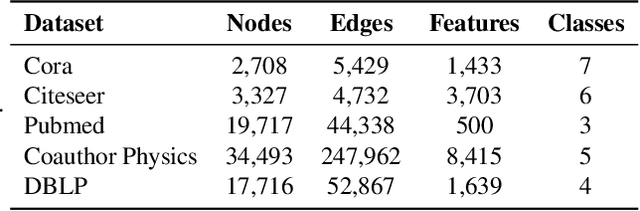
Scalability of graph neural networks remains one of the major challenges in graph machine learning. Since the representation of a node is computed by recursively aggregating and transforming representation vectors of its neighboring nodes from previous layers, the receptive fields grow exponentially, which makes standard stochastic optimization techniques ineffective. Various approaches have been proposed to alleviate this issue, e.g., sampling-based methods and techniques based on pre-computation of graph filters. In this paper, we take a different approach and propose to use graph coarsening for scalable training of GNNs, which is generic, extremely simple and has sublinear memory and time costs during training. We present extensive theoretical analysis on the effect of using coarsening operations and provides useful guidance on the choice of coarsening methods. Interestingly, our theoretical analysis shows that coarsening can also be considered as a type of regularization and may improve the generalization. Finally, empirical results on real world datasets show that, simply applying off-the-shelf coarsening methods, we can reduce the number of nodes by up to a factor of ten without causing a noticeable downgrade in classification accuracy.
Physical Activity Recognition Based on a Parallel Approach for an Ensemble of Machine Learning and Deep Learning Classifiers
Mar 02, 2021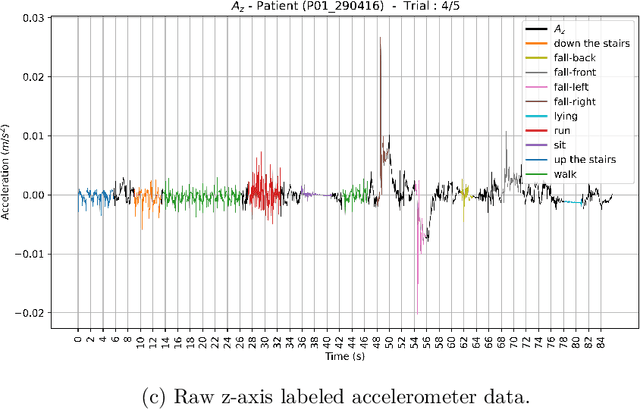
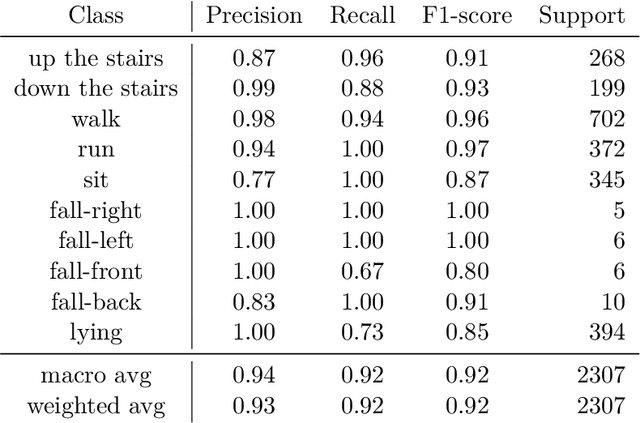
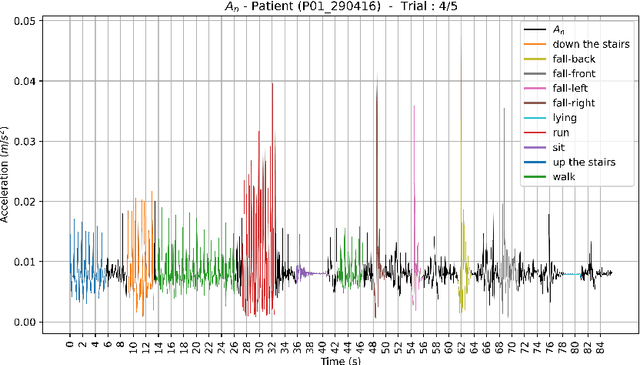
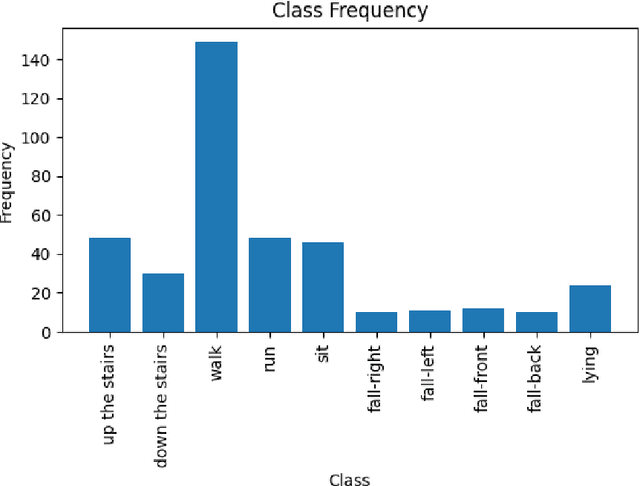
Human activity recognition (HAR) by wearable sensor devices embedded in the Internet of things (IOT) can play a significant role in remote health monitoring and emergency notification, to provide healthcare of higher standards. The purpose of this study is to investigate a human activity recognition method of accrued decision accuracy and speed of execution to be applicable in healthcare. This method classifies wearable sensor acceleration time series data of human movement using efficient classifier combination of feature engineering-based and feature learning-based data representation. Leave-one-subject-out cross-validation of the method with data acquired from 44 subjects wearing a single waist-worn accelerometer on a smart textile, and engaged in a variety of 10 activities, yields an average recognition rate of 90%, performing significantly better than individual classifiers. The method easily accommodates functional and computational parallelization to bring execution time significantly down.
ClickBAIT-v2: Training an Object Detector in Real-Time
Mar 27, 2018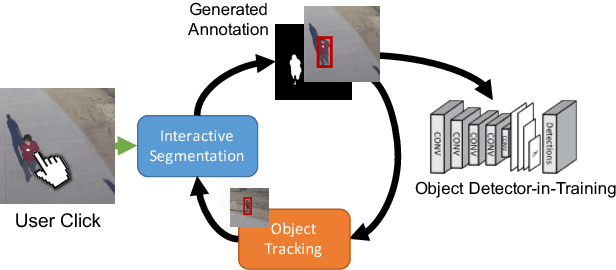

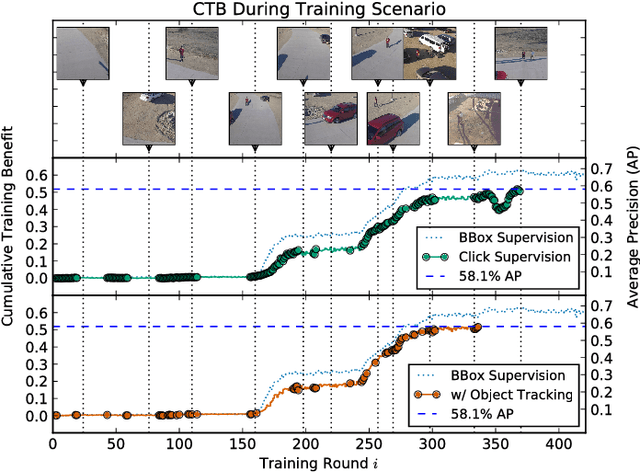
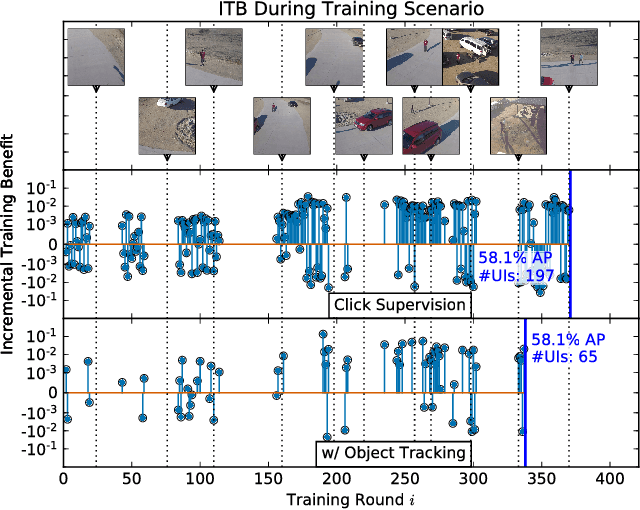
Modern deep convolutional neural networks (CNNs) for image classification and object detection are often trained offline on large static datasets. Some applications, however, will require training in real-time on live video streams with a human-in-the-loop. We refer to this class of problem as time-ordered online training (ToOT). These problems will require a consideration of not only the quantity of incoming training data, but the human effort required to annotate and use it. We demonstrate and evaluate a system tailored to training an object detector on a live video stream with minimal input from a human operator. We show that we can obtain bounding box annotation from weakly-supervised single-point clicks through interactive segmentation. Furthermore, by exploiting the time-ordered nature of the video stream through object tracking, we can increase the average training benefit of human interactions by 3-4 times.
Gradient-based Label Binning in Multi-label Classification
Jun 22, 2021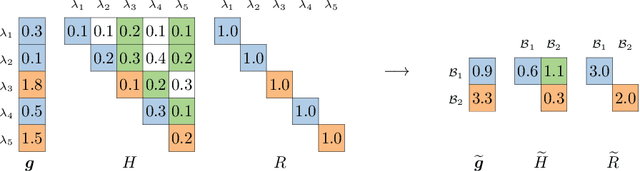
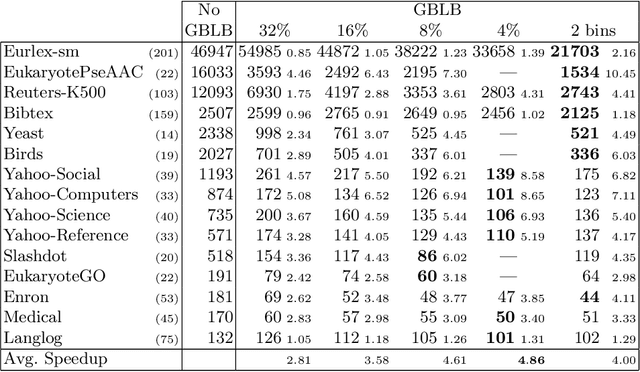
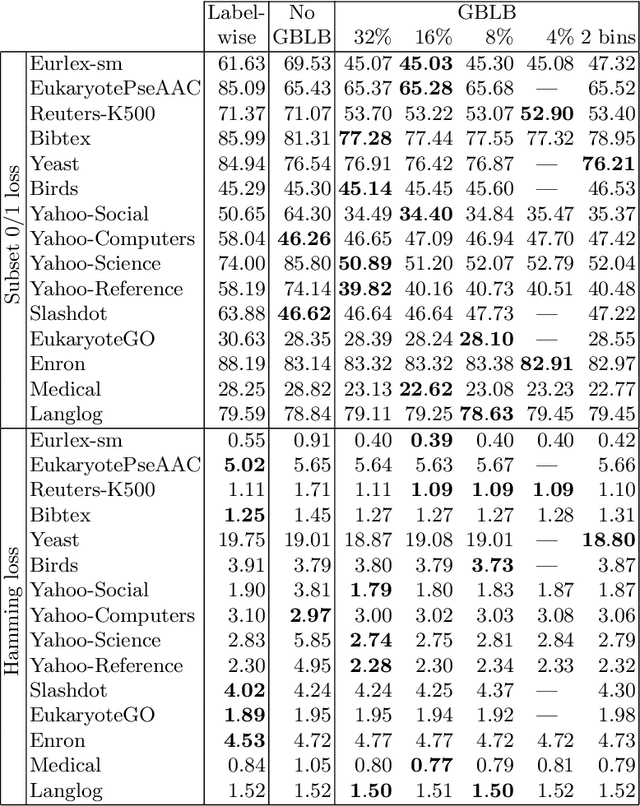
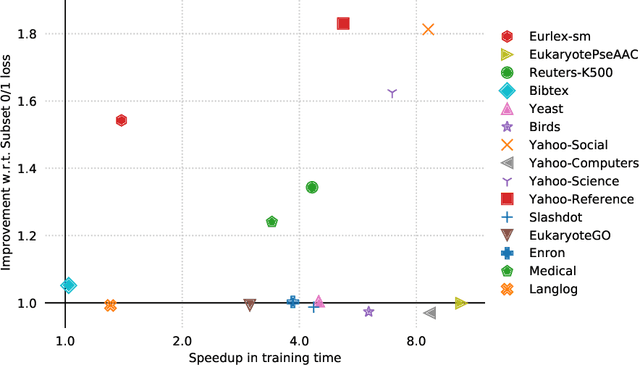
In multi-label classification, where a single example may be associated with several class labels at the same time, the ability to model dependencies between labels is considered crucial to effectively optimize non-decomposable evaluation measures, such as the Subset 0/1 loss. The gradient boosting framework provides a well-studied foundation for learning models that are specifically tailored to such a loss function and recent research attests the ability to achieve high predictive accuracy in the multi-label setting. The utilization of second-order derivatives, as used by many recent boosting approaches, helps to guide the minimization of non-decomposable losses, due to the information about pairs of labels it incorporates into the optimization process. On the downside, this comes with high computational costs, even if the number of labels is small. In this work, we address the computational bottleneck of such approach -- the need to solve a system of linear equations -- by integrating a novel approximation technique into the boosting procedure. Based on the derivatives computed during training, we dynamically group the labels into a predefined number of bins to impose an upper bound on the dimensionality of the linear system. Our experiments, using an existing rule-based algorithm, suggest that this may boost the speed of training, without any significant loss in predictive performance.
Real-time 3D Face-Eye Performance Capture of a Person Wearing VR Headset
Jan 21, 2019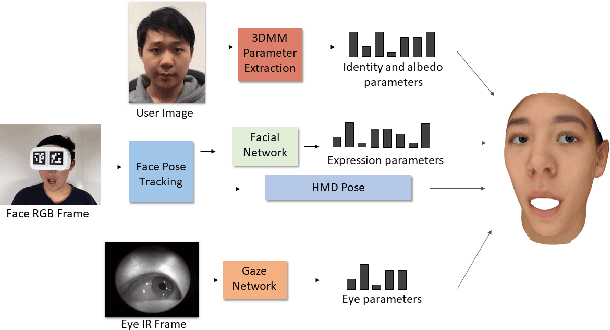
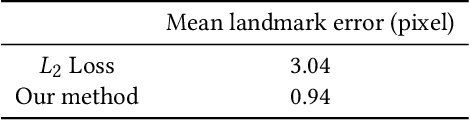

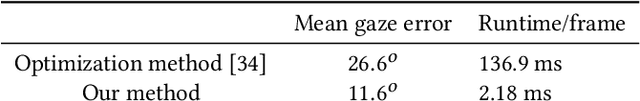
Teleconference or telepresence based on virtual reality (VR) headmount display (HMD) device is a very interesting and promising application since HMD can provide immersive feelings for users. However, in order to facilitate face-to-face communications for HMD users, real-time 3D facial performance capture of a person wearing HMD is needed, which is a very challenging task due to the large occlusion caused by HMD. The existing limited solutions are very complex either in setting or in approach as well as lacking the performance capture of 3D eye gaze movement. In this paper, we propose a convolutional neural network (CNN) based solution for real-time 3D face-eye performance capture of HMD users without complex modification to devices. To address the issue of lacking training data, we generate massive pairs of HMD face-label dataset by data synthesis as well as collecting VR-IR eye dataset from multiple subjects. Then, we train a dense-fitting network for facial region and an eye gaze network to regress 3D eye model parameters. Extensive experimental results demonstrate that our system can efficiently and effectively produce in real time a vivid personalized 3D avatar with the correct identity, pose, expression and eye motion corresponding to the HMD user.
Research on Mosaic Image Data Enhancement for Overlapping Ship Targets
May 11, 2021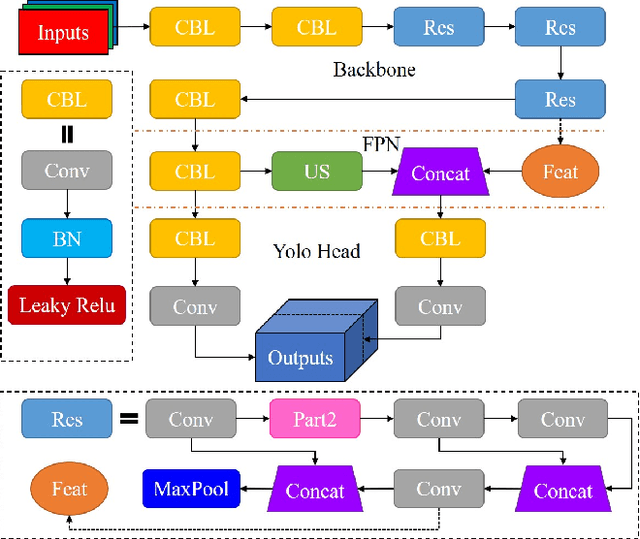

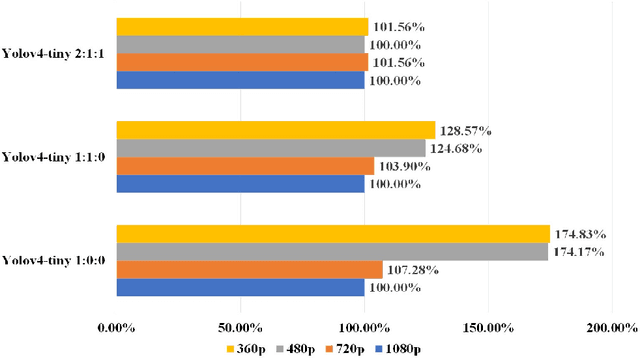
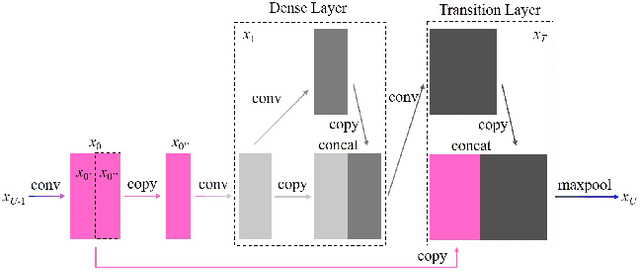
The problem of overlapping occlusion in target recognition has been a difficult research problem, and the situation of mutual occlusion of ship targets in narrow waters still exists. In this paper, an improved mosaic data enhancement method is proposed, which optimizes the reading method of the data set, strengthens the learning ability of the detection algorithm for local features, improves the recognition accuracy of overlapping targets while keeping the test speed unchanged, reduces the decay rate of recognition ability under different resolutions, and strengthens the robustness of the algorithm. The real test experiments prove that, relative to the original algorithm, the improved algorithm improves the recognition accuracy of overlapping targets by 2.5%, reduces the target loss time by 17%, and improves the recognition stability under different video resolutions by 27.01%.
Full-Body Torque-Level Non-linear Model Predictive Control for Aerial Manipulation
Jul 08, 2021
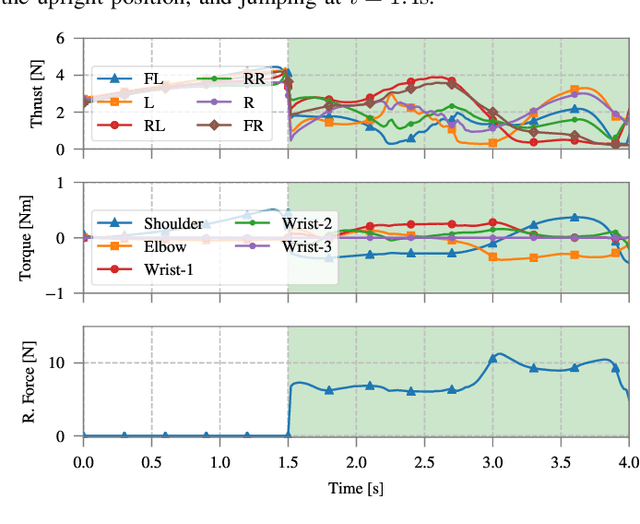
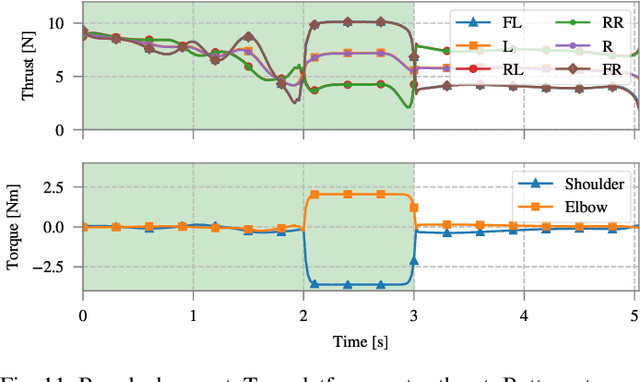
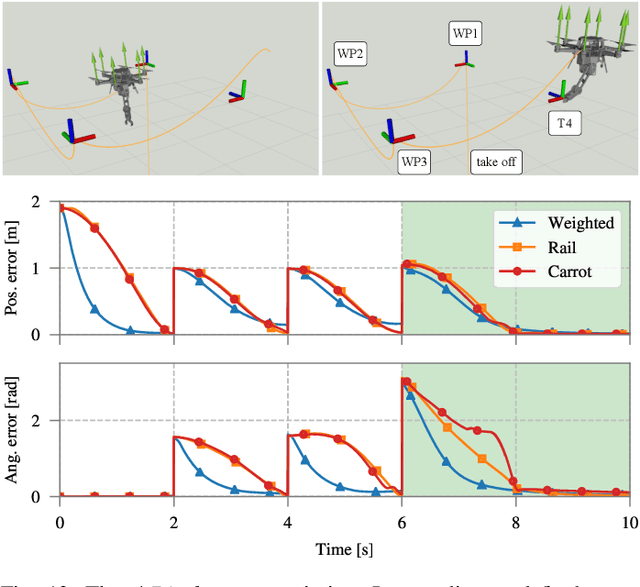
Non-linear model predictive control (nMPC) is a powerful approach to control complex robots (such as humanoids, quadrupeds, or unmanned aerial manipulators (UAMs)) as it brings important advantages over other existing techniques. The full-body dynamics, along with the prediction capability of the optimal control problem (OCP) solved at the core of the controller, allows to actuate the robot in line with its dynamics. This fact enhances the robot capabilities and allows, e.g., to perform intricate maneuvers at high dynamics while optimizing the amount of energy used. Despite the many similarities between humanoids or quadrupeds and UAMs, full-body torque-level nMPC has rarely been applied to UAMs. This paper provides a thorough description of how to use such techniques in the field of aerial manipulation. We give a detailed explanation of the different parts involved in the OCP, from the UAM dynamical model to the residuals in the cost function. We develop and compare three different nMPC controllers: Weighted MPC, Rail MPC, and Carrot MPC, which differ on the structure of their OCPs and on how these are updated at every time step. To validate the proposed framework, we present a wide variety of simulated case studies. First, we evaluate the trajectory generation problem, i.e., optimal control problems solved offline, involving different kinds of motions (e.g., aggressive maneuvers or contact locomotion) for different types of UAMs. Then, we assess the performance of the three nMPC controllers, i.e., closed-loop controllers solved online, through a variety of realistic simulations. For the benefit of the community, we have made available the source code related to this work.
Threshold-Based Data Exclusion Approach for Energy-Efficient Federated Edge Learning
Mar 30, 2021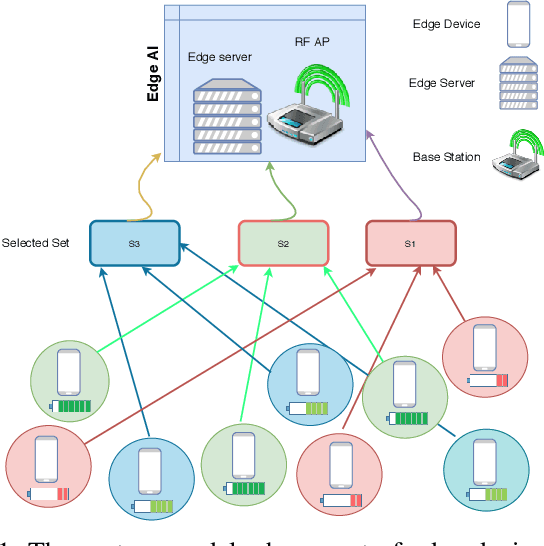
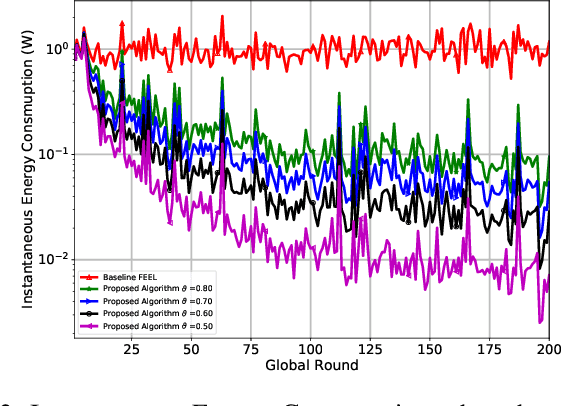
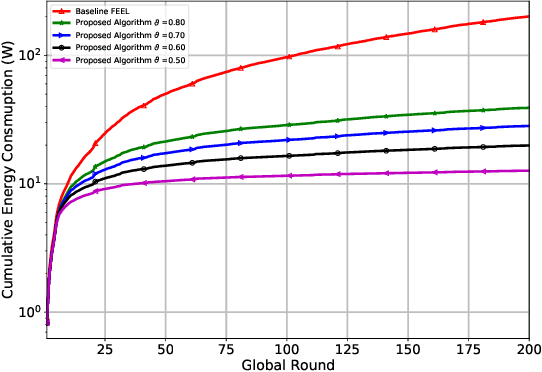
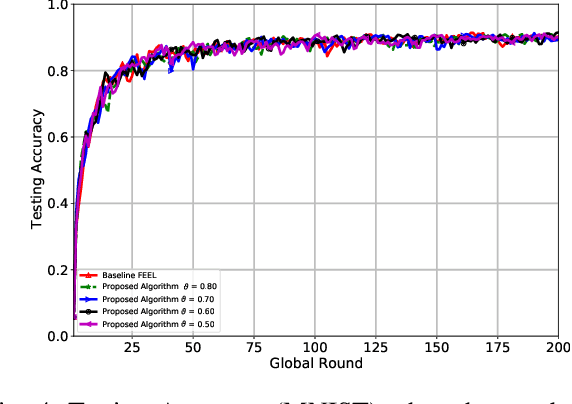
Federated edge learning (FEEL) is a promising distributed learning technique for next-generation wireless networks. FEEL preserves the user's privacy, reduces the communication costs, and exploits the unprecedented capabilities of edge devices to train a shared global model by leveraging a massive amount of data generated at the network edge. However, FEEL might significantly shorten energy-constrained participating devices' lifetime due to the power consumed during the model training round. This paper proposes a novel approach that endeavors to minimize computation and communication energy consumption during FEEL rounds to address this issue. First, we introduce a modified local training algorithm that intelligently selects only the samples that enhance the model's quality based on a predetermined threshold probability. Then, the problem is formulated as joint energy minimization and resource allocation optimization problem to obtain the optimal local computation time and the optimal transmission time that minimize the total energy consumption considering the worker's energy budget, available bandwidth, channel states, beamforming, and local CPU speed. After that, we introduce a tractable solution to the formulated problem that ensures the robustness of FEEL. Our simulation results show that our solution substantially outperforms the baseline FEEL algorithm as it reduces the local consumed energy by up to 79%.