 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Toward Robotic Weed Control: Detection of Nutsedge Weed in Bermudagrass Turf Using Inaccurate and Insufficient Training Data
Jun 16, 2021
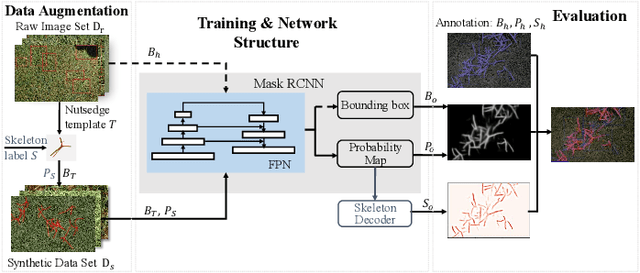
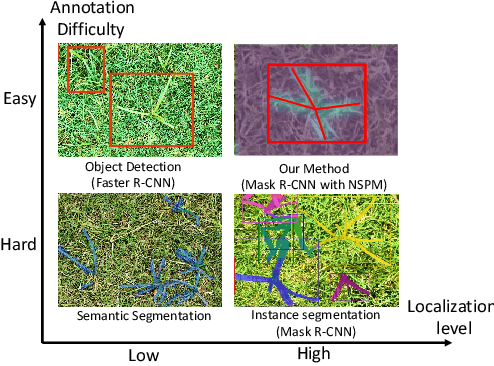
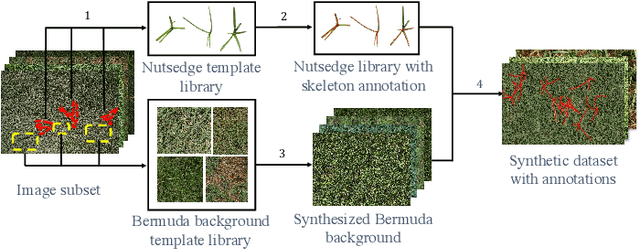

To enable robotic weed control, we develop algorithms to detect nutsedge weed from bermudagrass turf. Due to the similarity between the weed and the background turf, manual data labeling is expensive and error-prone. Consequently, directly applying deep learning methods for object detection cannot generate satisfactory results. Building on an instance detection approach (i.e. Mask R-CNN), we combine synthetic data with raw data to train the network. We propose an algorithm to generate high fidelity synthetic data, adopting different levels of annotations to reduce labeling cost. Moreover, we construct a nutsedge skeleton-based probabilistic map (NSPM) as the neural network input to reduce the reliance on pixel-wise precise labeling. We also modify loss function from cross entropy to Kullback-Leibler divergence which accommodates uncertainty in the labeling process. We implement the proposed algorithm and compare it with both Faster R-CNN and Mask R-CNN. The results show that our design can effectively overcome the impact of imprecise and insufficient training sample issues and significantly outperform the Faster R-CNN counterpart with a false negative rate of only 0.4%. In particular, our approach also reduces labeling time by 95% while achieving better performance if comparing with the original Mask R-CNN approach.
Feedback-based Digital Higher-order Terminal Sliding Mode for 6-DOF Industrial Manipulators
Feb 06, 2021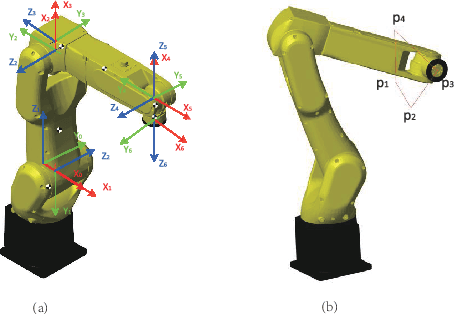
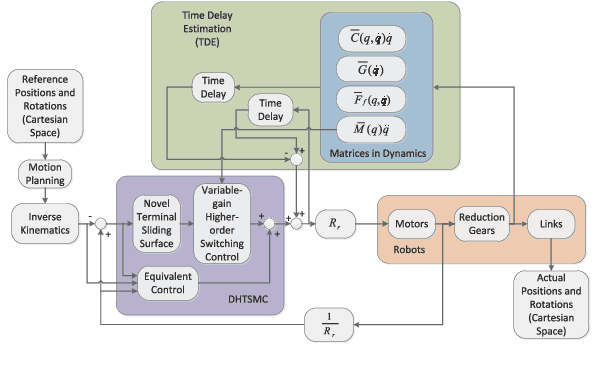
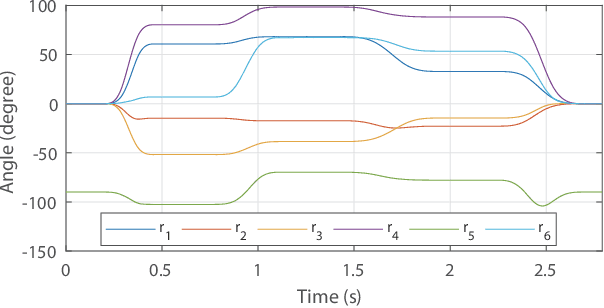
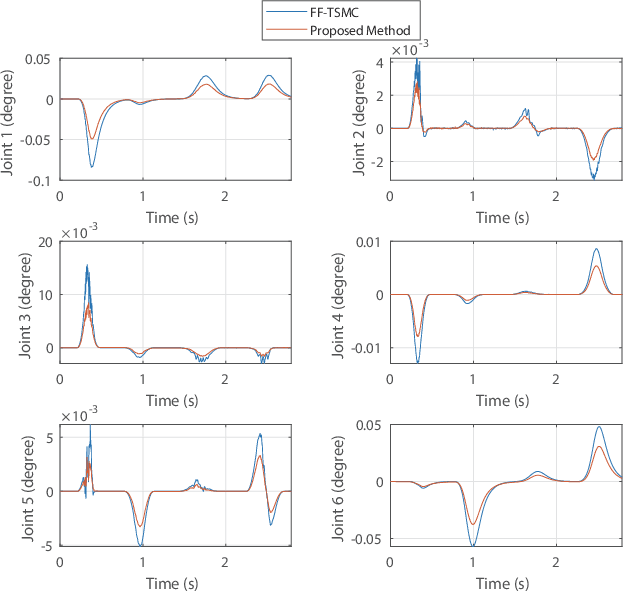
The precise motion control of a multi-degree of freedom~(DOF) robot manipulator is always challenging due to its nonlinear dynamics, disturbances, and uncertainties. Because most manipulators are controlled by digital signals, a novel higher-order sliding mode controller in the discrete-time form with time delay estimation is proposed in this paper. The dynamic model of the manipulator used in the design allows proper handling of nonlinearities, uncertainties and disturbances involved in the problem. Specifically, parametric uncertainties and disturbances are handled by the time delay estimation and the nonlinearity of the manipulator is addressed by the feedback structure of the controller. The combination of terminal sliding mode surface and higher-order control scheme in the controller guarantees a fast response with a small chattering amplitude. Moreover, the controller is designed with a modified sliding mode surface and variable-gain structure, so that the performance of the controller is further enhanced. We also analyze the condition to guarantee the stability of the closed-loop system in this paper. Finally, the simulation and experimental results prove that the proposed control scheme has a precise performance in a robot manipulator system.
Pseudo-Boolean Functions for Optimal Z-Complementary Code Sets with Flexible Lengths
Apr 20, 2021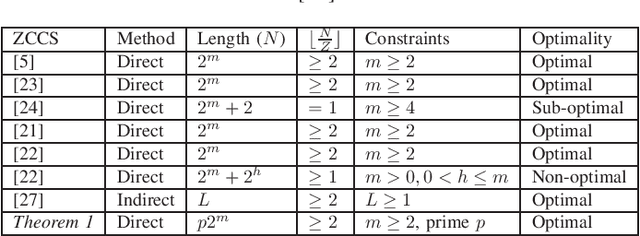
This paper aims to construct optimal Z-complementary code set (ZCCS) with non-power-of-two (NPT) lengths to enable interference-free multicarrier code-division multiple access (MC-CDMA) systems. The existing ZCCSs with NPT lengths, which are constructed from generalized Boolean functions (GBFs), are sub-optimal only with respect to the set size upper bound. For the first time in the literature, we advocate the use of pseudo-Boolean functions (PBFs) (each of which transforms a number of binary variables to a real number as a natural generalization of GBF) for direct constructions of optimal ZCCSs with NPT lengths.
EarlyBERT: Efficient BERT Training via Early-bird Lottery Tickets
Dec 31, 2020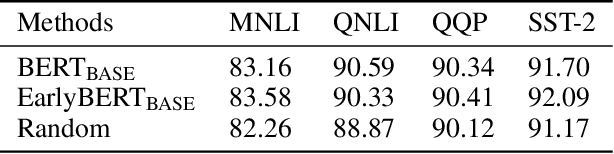
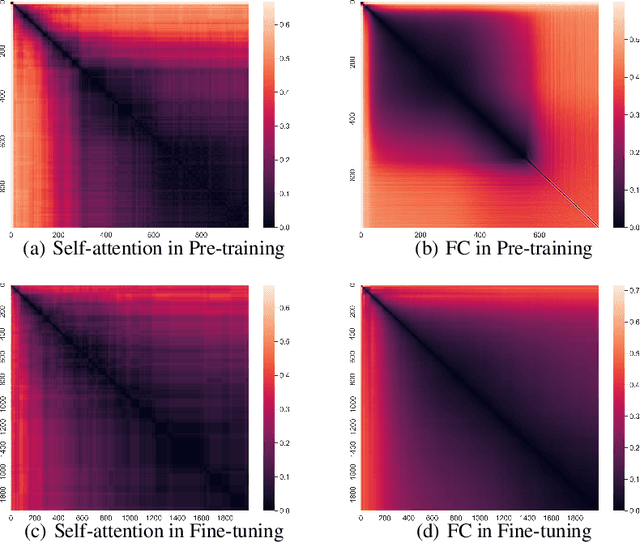
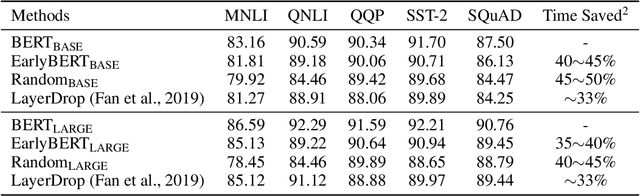
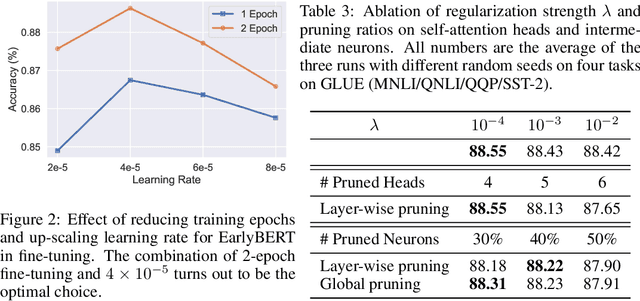
Deep, heavily overparameterized language models such as BERT, XLNet and T5 have achieved impressive success in many NLP tasks. However, their high model complexity requires enormous computation resources and extremely long training time for both pre-training and fine-tuning. Many works have studied model compression on large NLP models, but only focus on reducing inference cost/time, while still requiring expensive training process. Other works use extremely large batch sizes to shorten the pre-training time at the expense of high demand for computation resources. In this paper, inspired by the Early-Bird Lottery Tickets studied for computer vision tasks, we propose EarlyBERT, a general computationally-efficient training algorithm applicable to both pre-training and fine-tuning of large-scale language models. We are the first to identify structured winning tickets in the early stage of BERT training, and use them for efficient training. Comprehensive pre-training and fine-tuning experiments on GLUE and SQuAD downstream tasks show that EarlyBERT easily achieves comparable performance to standard BERT with 35~45% less training time.
An Efficient Batch Constrained Bayesian Optimization Approach for Analog Circuit Synthesis via Multi-objective Acquisition Ensemble
Jun 28, 2021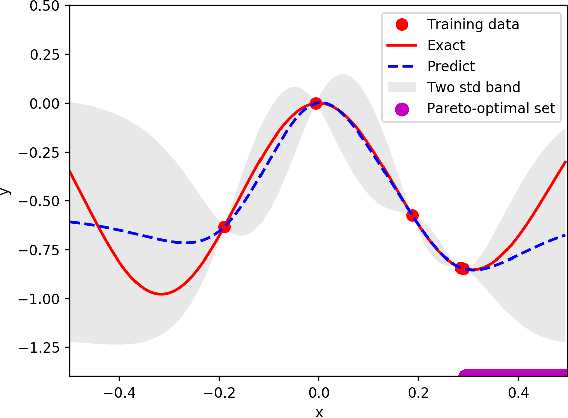
Bayesian optimization is a promising methodology for analog circuit synthesis. However, the sequential nature of the Bayesian optimization framework significantly limits its ability to fully utilize real-world computational resources. In this paper, we propose an efficient parallelizable Bayesian optimization algorithm via Multi-objective ACquisition function Ensemble (MACE) to further accelerate the optimization procedure. By sampling query points from the Pareto front of the probability of improvement (PI), expected improvement (EI) and lower confidence bound (LCB), we combine the benefits of state-of-the-art acquisition functions to achieve a delicate tradeoff between exploration and exploitation for the unconstrained optimization problem. Based on this batch design, we further adjust the algorithm for the constrained optimization problem. By dividing the optimization procedure into two stages and first focusing on finding an initial feasible point, we manage to gain more information about the valid region and can better avoid sampling around the infeasible area. After achieving the first feasible point, we favor the feasible region by adopting a specially designed penalization term to the acquisition function ensemble. The experimental results quantitatively demonstrate that our proposed algorithm can reduce the overall simulation time by up to 74 times compared to differential evolution (DE) for the unconstrained optimization problem when the batch size is 15. For the constrained optimization problem, our proposed algorithm can speed up the optimization process by up to 15 times compared to the weighted expected improvement based Bayesian optimization (WEIBO) approach, when the batch size is 15.
Recent Advances on Sub-Nyquist Sampling-Based Wideband Spectrum Sensing
May 07, 2021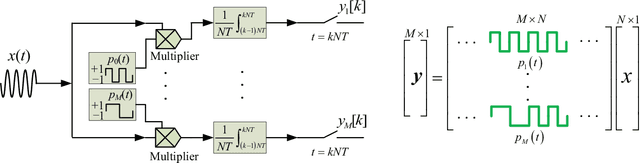
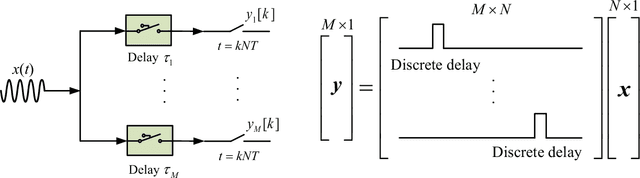
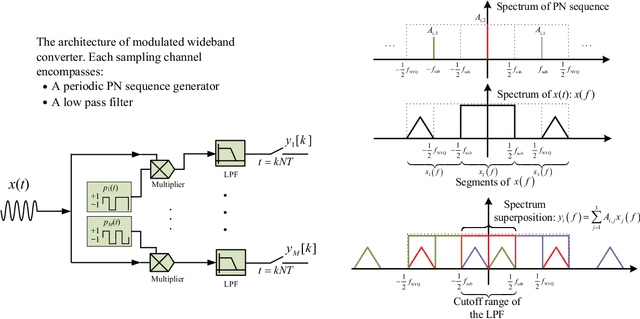
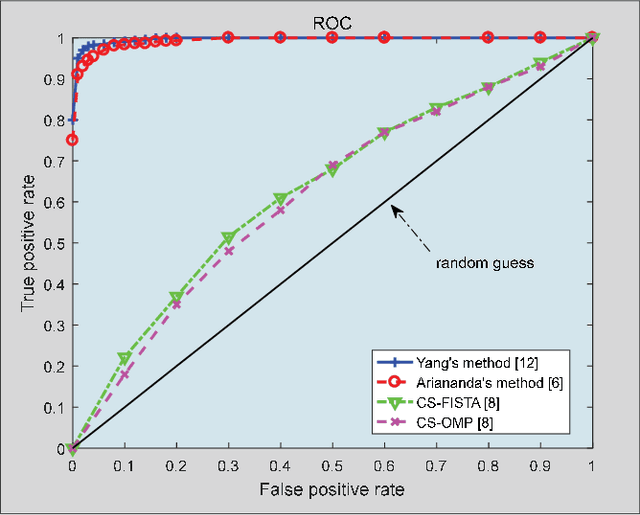
Cognitive radio (CR) is a promising technology enabling efficient utilization of the spectrum resource for future wireless systems. As future CR networks are envisioned to operate over a wide frequency range, advanced wideband spectrum sensing (WBSS) capable of quickly and reliably detecting idle spectrum bands across a wide frequency span is essential. In this article, we provide an overview of recent advances on sub-Nyquist sampling-based WBSS techniques, including compressed sensing-based methods and compressive covariance sensing-based methods. An elaborate discussion of the pros and cons of each approach is presented, along with some challenging issues for future research. A comparative study suggests that the compressive covariance sensing-based approach offers a more competitive solution for reliable real-time WBSS.
Atlas-Based Segmentation of Intracochlear Anatomy in Metal Artifact Affected CT Images of the Ear with Co-trained Deep Neural Networks
Jul 08, 2021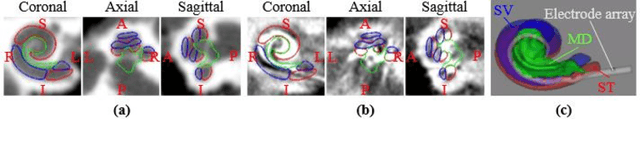
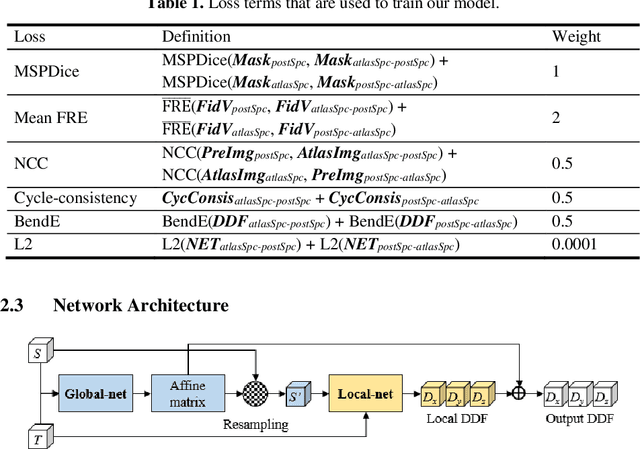
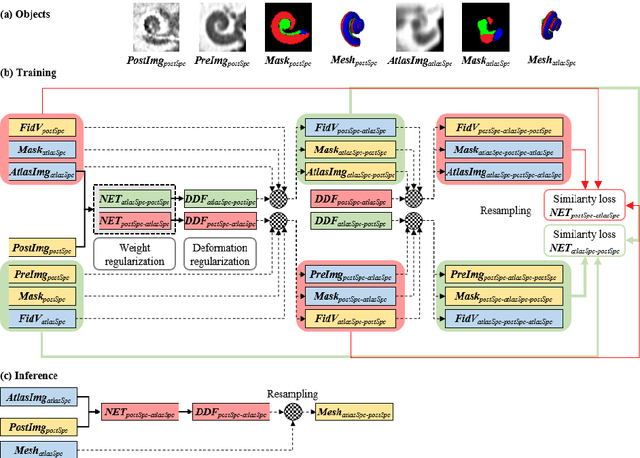
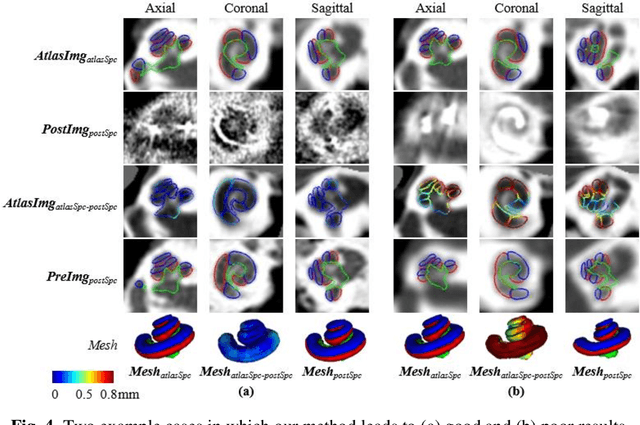
We propose an atlas-based method to segment the intracochlear anatomy (ICA) in the post-implantation CT (Post-CT) images of cochlear implant (CI) recipients that preserves the point-to-point correspondence between the meshes in the atlas and the segmented volumes. To solve this problem, which is challenging because of the strong artifacts produced by the implant, we use a pair of co-trained deep networks that generate dense deformation fields (DDFs) in opposite directions. One network is tasked with registering an atlas image to the Post-CT images and the other network is tasked with registering the Post-CT images to the atlas image. The networks are trained using loss functions based on voxel-wise labels, image content, fiducial registration error, and cycle-consistency constraint. The segmentation of the ICA in the Post-CT images is subsequently obtained by transferring the predefined segmentation meshes of the ICA in the atlas image to the Post-CT images using the corresponding DDFs generated by the trained registration networks. Our model can learn the underlying geometric features of the ICA even though they are obscured by the metal artifacts. We show that our end-to-end network produces results that are comparable to the current state of the art (SOTA) that relies on a two-steps approach that first uses conditional generative adversarial networks to synthesize artifact-free images from the Post-CT images and then uses an active shape model-based method to segment the ICA in the synthetic images. Our method requires a fraction of the time needed by the SOTA, which is important for end-user acceptance.
Towards Biologically Plausible Convolutional Networks
Jun 22, 2021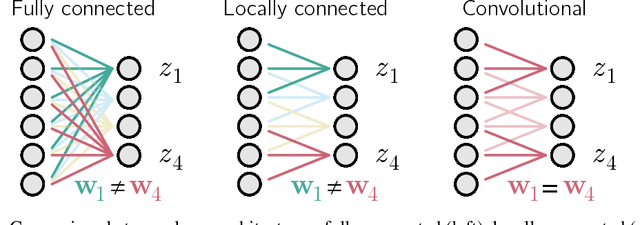
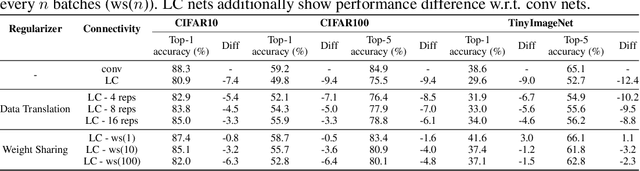
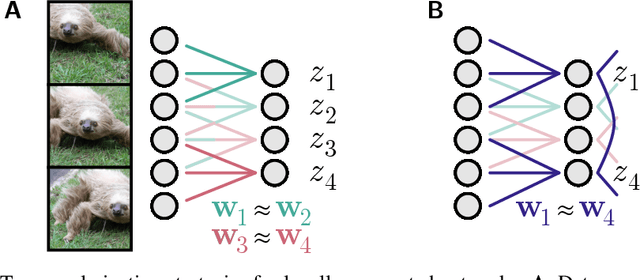

Convolutional networks are ubiquitous in deep learning. They are particularly useful for images, as they reduce the number of parameters, reduce training time, and increase accuracy. However, as a model of the brain they are seriously problematic, since they require weight sharing - something real neurons simply cannot do. Consequently, while neurons in the brain can be locally connected (one of the features of convolutional networks), they cannot be convolutional. Locally connected but non-convolutional networks, however, significantly underperform convolutional ones. This is troublesome for studies that use convolutional networks to explain activity in the visual system. Here we study plausible alternatives to weight sharing that aim at the same regularization principle, which is to make each neuron within a pool react similarly to identical inputs. The most natural way to do that is by showing the network multiple translations of the same image, akin to saccades in animal vision. However, this approach requires many translations, and doesn't remove the performance gap. We propose instead to add lateral connectivity to a locally connected network, and allow learning via Hebbian plasticity. This requires the network to pause occasionally for a sleep-like phase of "weight sharing". This method enables locally connected networks to achieve nearly convolutional performance on ImageNet, thus supporting convolutional networks as a model of the visual stream.
Measuring and Increasing Context Usage in Context-Aware Machine Translation
Jun 02, 2021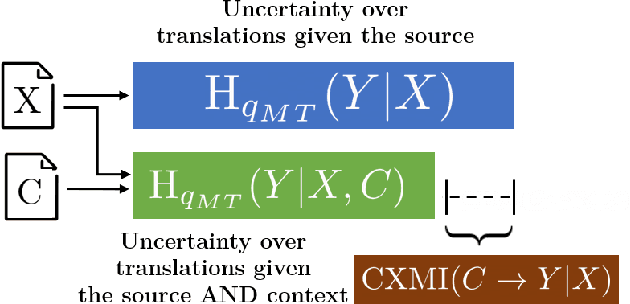

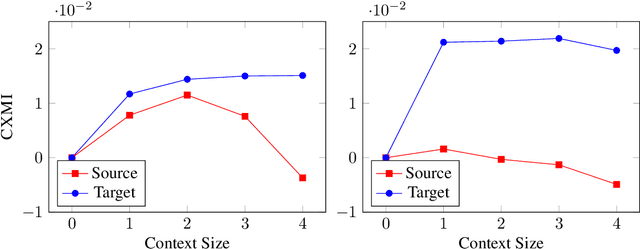
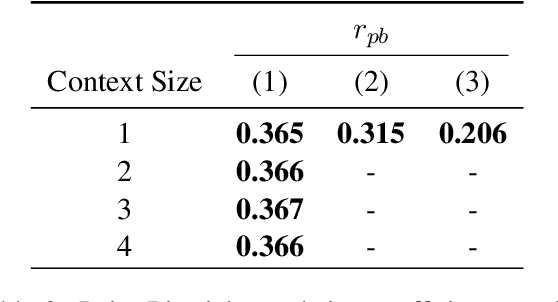
Recent work in neural machine translation has demonstrated both the necessity and feasibility of using inter-sentential context -- context from sentences other than those currently being translated. However, while many current methods present model architectures that theoretically can use this extra context, it is often not clear how much they do actually utilize it at translation time. In this paper, we introduce a new metric, conditional cross-mutual information, to quantify the usage of context by these models. Using this metric, we measure how much document-level machine translation systems use particular varieties of context. We find that target context is referenced more than source context, and that conditioning on a longer context has a diminishing effect on results. We then introduce a new, simple training method, context-aware word dropout, to increase the usage of context by context-aware models. Experiments show that our method increases context usage and that this reflects on the translation quality according to metrics such as BLEU and COMET, as well as performance on anaphoric pronoun resolution and lexical cohesion contrastive datasets.
Real Time Elbow Angle Estimation Using Single RGB Camera
Aug 21, 2018The use of motion capture has increased from last decade in a varied spectrum of applications like film special effects, controlling games and robots, rehabilitation system, animations etc. The current human motion capture techniques use markers, structured environment, and high resolution cameras in a dedicated environment. Because of rapid movement, elbow angle estimation is observed as the most difficult problem in human motion capture system. In this paper, we take elbow angle estimation as our research subject and propose a novel, markerless and cost-effective solution that uses RGB camera for estimating elbow angle in real time using part affinity field. We have recruited five (5) participants to perform cup to mouth movement and at the same time measured the angle by both RGB camera and Microsoft Kinect. The experimental results illustrate that markerless and cost-effective RGB camera has a median RMS errors of 3.06{\deg} and 0.95{\deg} in sagittal and coronal plane respectively as compared to Microsoft Kinect.