 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning neural network potentials from experimental data via Differentiable Trajectory Reweighting
Jun 02, 2021
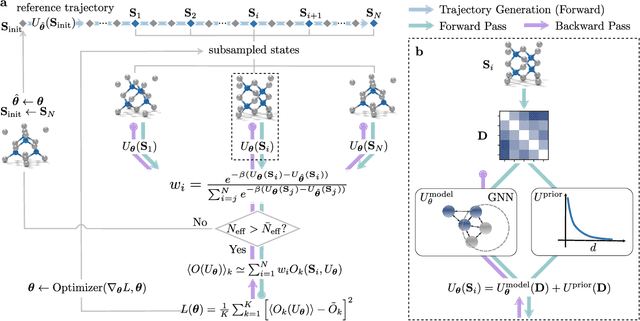
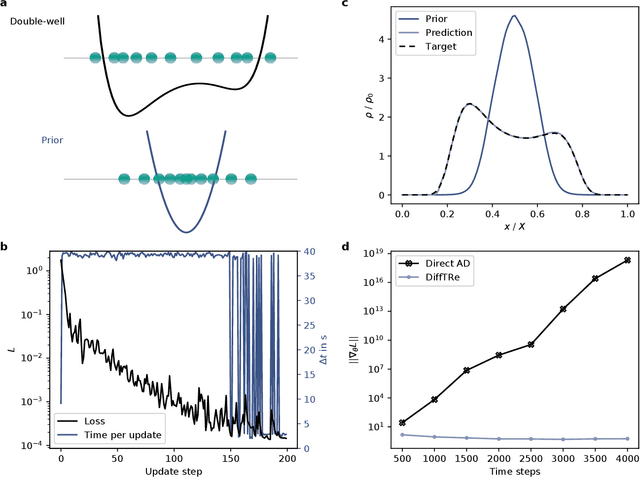
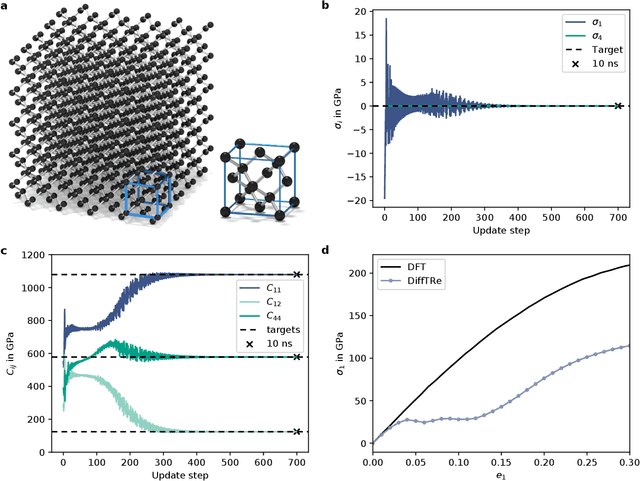
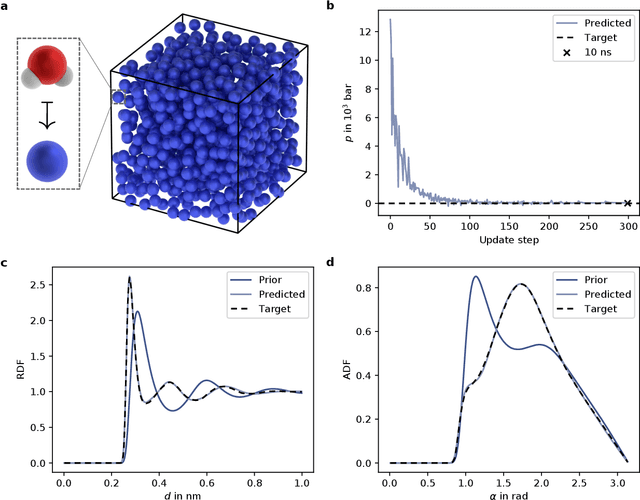
In molecular dynamics (MD), neural network (NN) potentials trained bottom-up on quantum mechanical data have seen tremendous success recently. Top-down approaches that learn NN potentials directly from experimental data have received less attention, typically facing numerical and computational challenges when backpropagating through MD simulations. We present the Differentiable Trajectory Reweighting (DiffTRe) method, which bypasses differentiation through the MD simulation for time-independent observables. Leveraging thermodynamic perturbation theory, we avoid exploding gradients and achieve around 2 orders of magnitude speed-up in gradient computation for top-down learning. We show effectiveness of DiffTRe in learning NN potentials for an atomistic model of diamond and a coarse-grained model of water based on diverse experimental observables including thermodynamic, structural and mechanical properties. Importantly, DiffTRe also generalizes bottom-up structural coarse-graining methods such as iterative Boltzmann inversion to arbitrary potentials. The presented method constitutes an important milestone towards enriching NN potentials with experimental data, particularly when accurate bottom-up data is unavailable.
GPU-Accelerated Optimizer-Aware Evaluation of Submodular Exemplar Clustering
Jan 21, 2021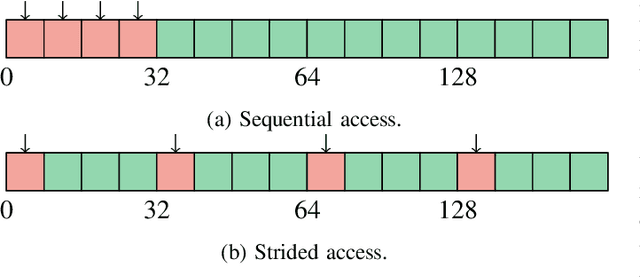
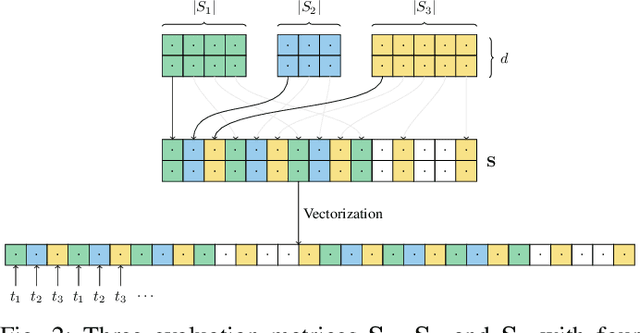
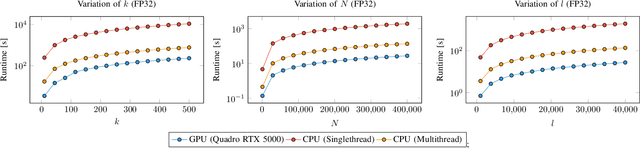
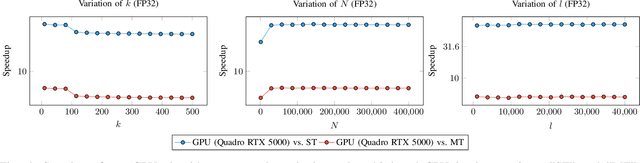
The optimization of submodular functions constitutes a viable way to perform clustering. Strong approximation guarantees and feasible optimization w.r.t. streaming data make this clustering approach favorable. Technically, submodular functions map subsets of data to real values, which indicate how "representative" a specific subset is. Optimal sets might then be used to partition the data space and to infer clusters. Exemplar-based clustering is one of the possible submodular functions, but suffers from high computational complexity. However, for practical applications, the particular real-time or wall-clock run-time is decisive. In this work, we present a novel way to evaluate this particular function on GPUs, which keeps the necessities of optimizers in mind and reduces wall-clock run-time. To discuss our GPU algorithm, we investigated both the impact of different run-time critical problem properties, like data dimensionality and the number of data points in a subset, and the influence of required floating-point precision. In reproducible experiments, our GPU algorithm was able to achieve competitive speedups of up to 72x depending on whether multi-threaded computation on CPUs was used for comparison and the type of floating-point precision required. Half-precision GPU computation led to large speedups of up to 452x compared to single-precision, single-thread CPU computations.
Harnessing the power of Topological Data Analysis to detect change points in time series
Oct 28, 2019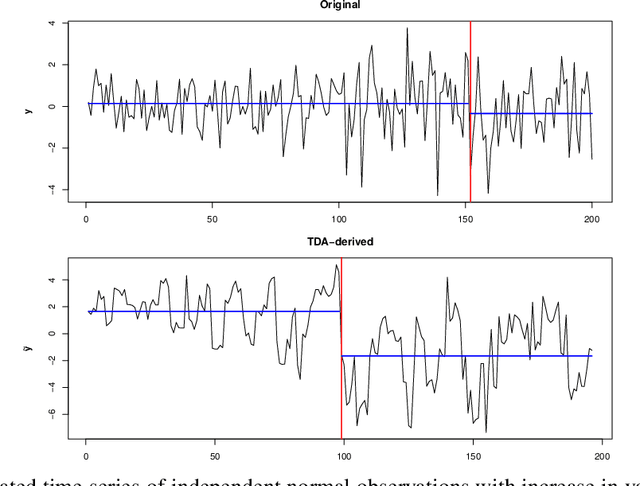
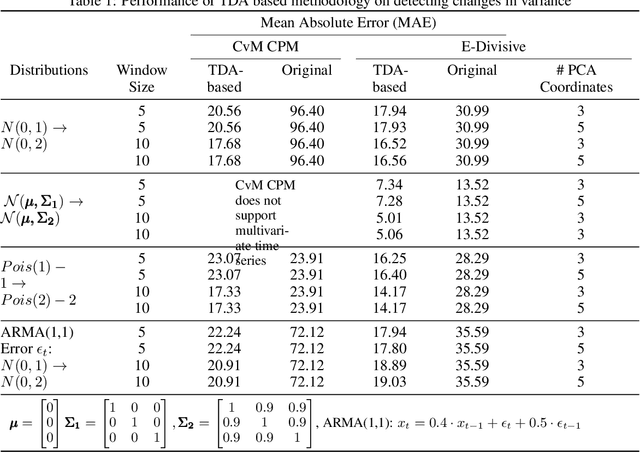
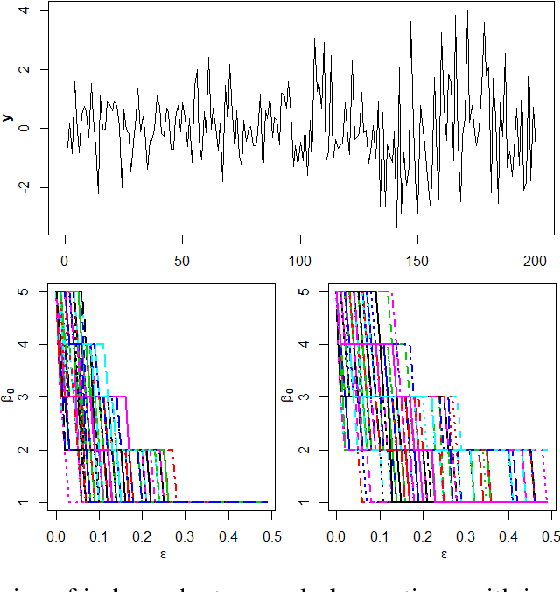
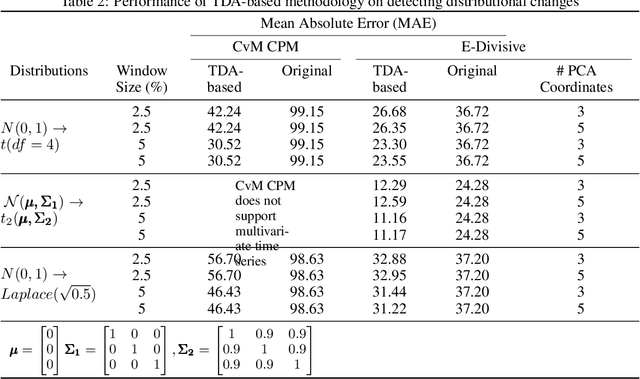
We introduce a novel geometry-oriented methodology, based on the emerging tools of topological data analysis, into the change point detection framework. The key rationale is that change points are likely to be associated with changes in geometry behind the data generating process. While the applications of topological data analysis to change point detection are potentially very broad, in this paper we primarily focus on integrating topological concepts with the existing nonparametric methods for change point detection. In particular, the proposed new geometry-oriented approach aims to enhance detection accuracy of distributional regime shift locations. Our simulation studies suggest that integration of topological data analysis with some existing algorithms for change point detection leads to consistently more accurate detection results. We illustrate our new methodology in application to the two closely related environmental time series datasets -ice phenology of the Lake Baikal and the North Atlantic Oscillation indices, in a research query for a possible association between their estimated regime shift locations.
Efficient Large-Scale Face Clustering Using an Online Mixture of Gaussians
Mar 31, 2021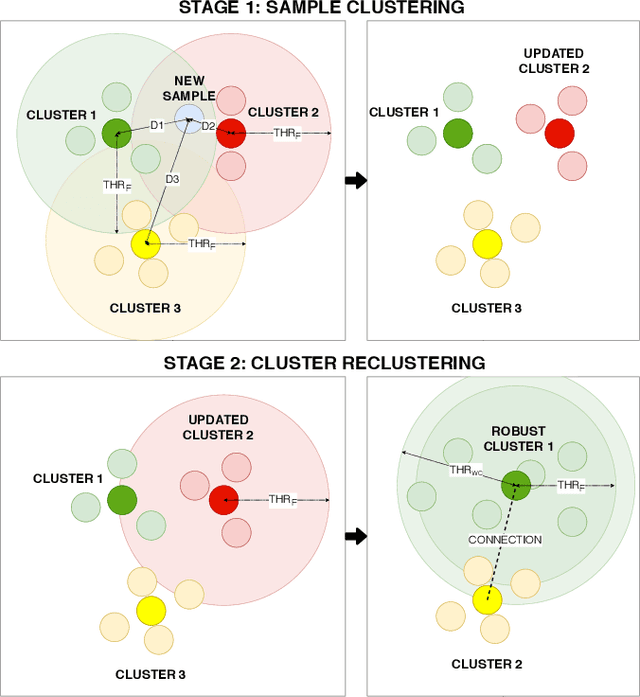
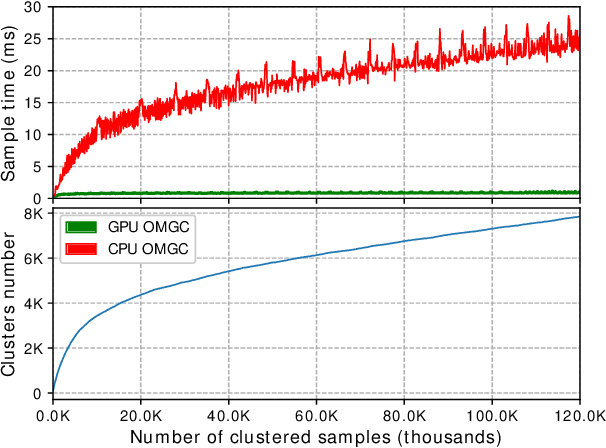

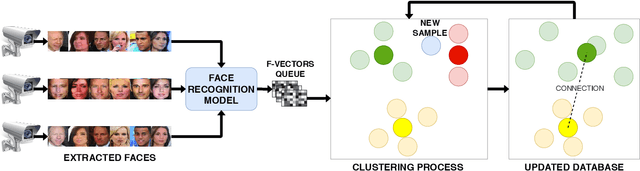
In this work, we address the problem of large-scale online face clustering: given a continuous stream of unknown faces, create a database grouping the incoming faces by their identity. The database must be updated every time a new face arrives. In addition, the solution must be efficient, accurate and scalable. For this purpose, we present an online gaussian mixture-based clustering method (OGMC). The key idea of this method is the proposal that an identity can be represented by more than just one distribution or cluster. Using feature vectors (f-vectors) extracted from the incoming faces, OGMC generates clusters that may be connected to others depending on their proximity and their robustness. Every time a cluster is updated with a new sample, its connections are also updated. With this approach, we reduce the dependency of the clustering process on the order and the size of the incoming data and we are able to deal with complex data distributions. Experimental results show that the proposed approach outperforms state-of-the-art clustering methods on large-scale face clustering benchmarks not only in accuracy, but also in efficiency and scalability.
Self-training with noisy student model and semi-supervised loss function for dcase 2021 challenge task 4
Jul 06, 2021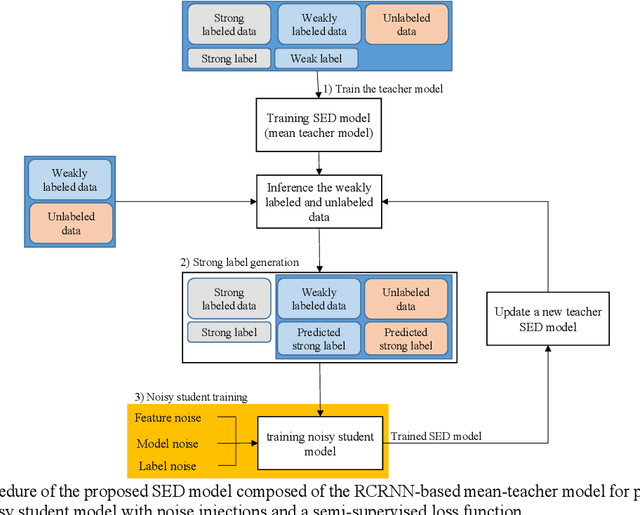
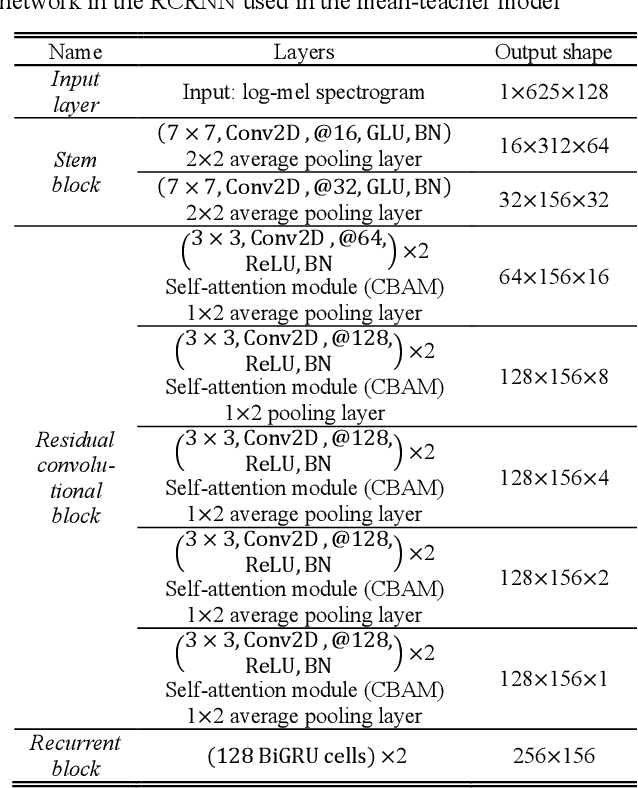
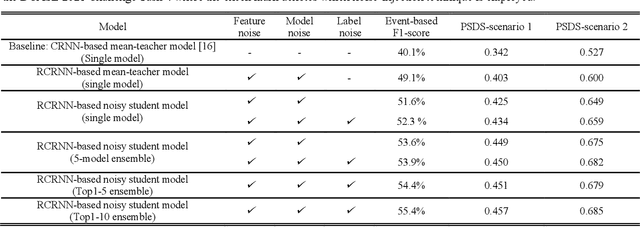
This report proposes a polyphonic sound event detection (SED) method for the DCASE 2021 Challenge Task 4. The proposed SED model consists of two stages: a mean-teacher model for providing target labels regarding weakly labeled or unlabeled data and a self-training-based noisy student model for predicting strong labels for sound events. The mean-teacher model, which is based on the residual convolutional recurrent neural network (RCRNN) for the teacher and student model, is first trained using all the training data from a weakly labeled dataset, an unlabeled dataset, and a strongly labeled synthetic dataset. Then, the trained mean-teacher model predicts the strong label to each of the weakly labeled and unlabeled datasets, which is brought to the noisy student model in the second stage of the proposed SED model. Here, the structure of the noisy student model is identical to the RCRNN-based student model of the mean-teacher model in the first stage. Then, it is self-trained by adding feature noises, such as time-frequency shift, mixup, SpecAugment, and dropout-based model noise. In addition, a semi-supervised loss function is applied to train the noisy student model, which acts as label noise injection. The performance of the proposed SED model is evaluated on the validation set of the DCASE 2021 Challenge Task 4, and then, several ensemble models that combine five-fold validation models with different hyperparameters of the semi-supervised loss function are finally selected as our final models.
Neural SDEs as Infinite-Dimensional GANs
Feb 06, 2021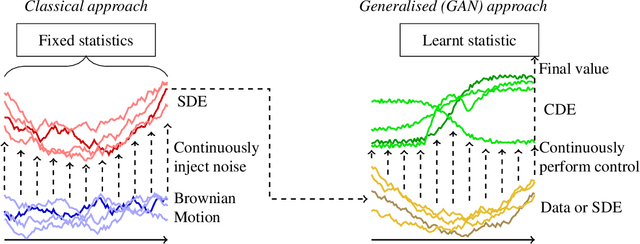

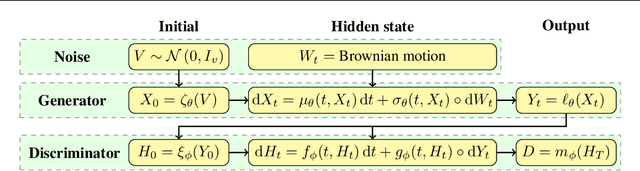

Stochastic differential equations (SDEs) are a staple of mathematical modelling of temporal dynamics. However, a fundamental limitation has been that such models have typically been relatively inflexible, which recent work introducing Neural SDEs has sought to solve. Here, we show that the current classical approach to fitting SDEs may be approached as a special case of (Wasserstein) GANs, and in doing so the neural and classical regimes may be brought together. The input noise is Brownian motion, the output samples are time-evolving paths produced by a numerical solver, and by parameterising a discriminator as a Neural Controlled Differential Equation (CDE), we obtain Neural SDEs as (in modern machine learning parlance) continuous-time generative time series models. Unlike previous work on this problem, this is a direct extension of the classical approach without reference to either prespecified statistics or density functions. Arbitrary drift and diffusions are admissible, so as the Wasserstein loss has a unique global minima, in the infinite data limit \textit{any} SDE may be learnt.
IGrow: A Smart Agriculture Solution to Autonomous Greenhouse Control
Jul 06, 2021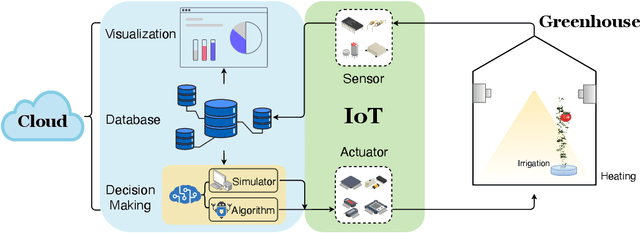
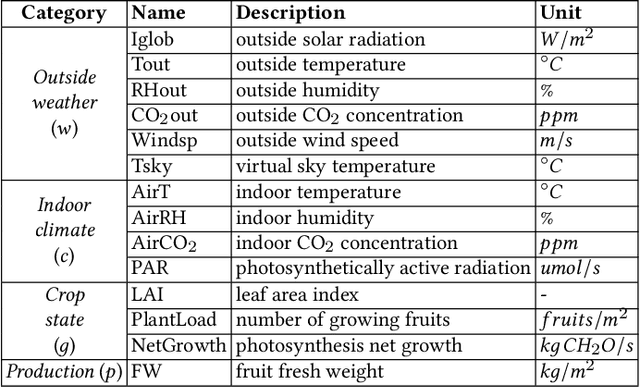
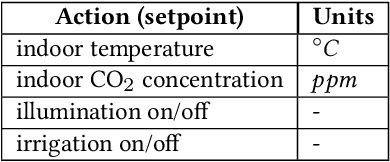
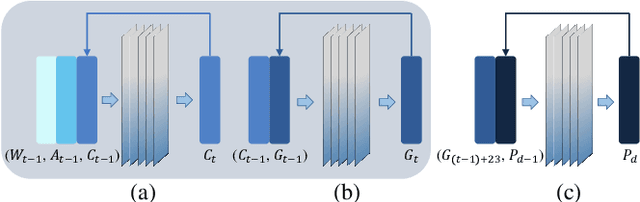
Agriculture is the foundation of human civilization. However, the rapid increase and aging of the global population pose challenges on this cornerstone by demanding more healthy and fresh food. Internet of Things (IoT) technology makes modern autonomous greenhouse a viable and reliable engine of food production. However, the educated and skilled labor capable of overseeing high-tech greenhouses is scarce. Artificial intelligence (AI) and cloud computing technologies are promising solutions for precision control and high-efficiency production in such controlled environments. In this paper, we propose a smart agriculture solution, namely iGrow: (1) we use IoT and cloud computing technologies to measure, collect, and manage growing data, to support iteration of our decision-making AI module, which consists of an incremental model and an optimization algorithm; (2) we propose a three-stage incremental model based on accumulating data, enabling growers/central computers to schedule control strategies conveniently and at low cost; (3) we propose a model-based iterative optimization algorithm, which can dynamically optimize the greenhouse control strategy in real-time production. In the simulated experiment, evaluation results show the accuracy of our incremental model is comparable to an advanced tomato simulator, while our optimization algorithms can beat the champion of the 2nd Autonomous Greenhouse Challenge. Compelling results from the A/B test in real greenhouses demonstrate that our solution significantly increases production (commercially sellable fruits) (+ 10.15%) and net profit (+ 87.07%) with statistical significance compared to planting experts.
LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations
Jun 02, 2021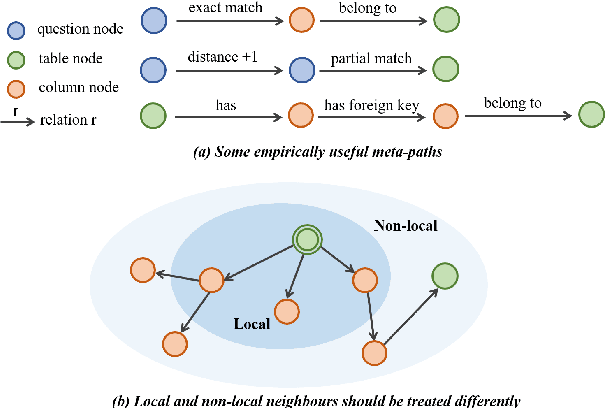
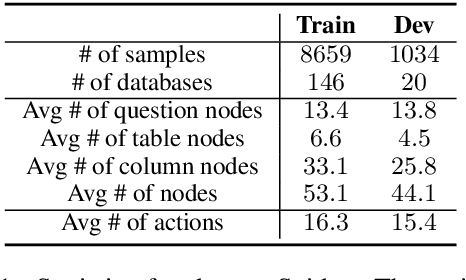
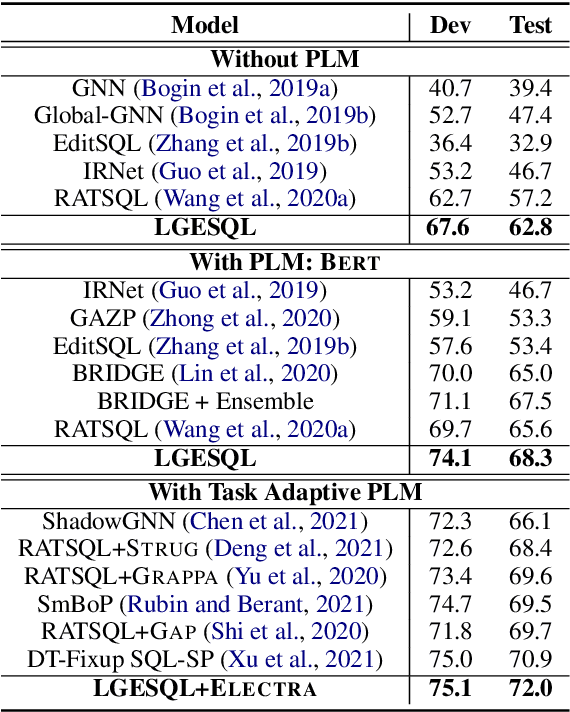
This work aims to tackle the challenging heterogeneous graph encoding problem in the text-to-SQL task. Previous methods are typically node-centric and merely utilize different weight matrices to parameterize edge types, which 1) ignore the rich semantics embedded in the topological structure of edges, and 2) fail to distinguish local and non-local relations for each node. To this end, we propose a Line Graph Enhanced Text-to-SQL (LGESQL) model to mine the underlying relational features without constructing meta-paths. By virtue of the line graph, messages propagate more efficiently through not only connections between nodes, but also the topology of directed edges. Furthermore, both local and non-local relations are integrated distinctively during the graph iteration. We also design an auxiliary task called graph pruning to improve the discriminative capability of the encoder. Our framework achieves state-of-the-art results (62.8% with Glove, 72.0% with Electra) on the cross-domain text-to-SQL benchmark Spider at the time of writing.
Explicit Basis Function Kernel Methods for Cloud Segmentation in Infrared Sky Images
Feb 19, 2021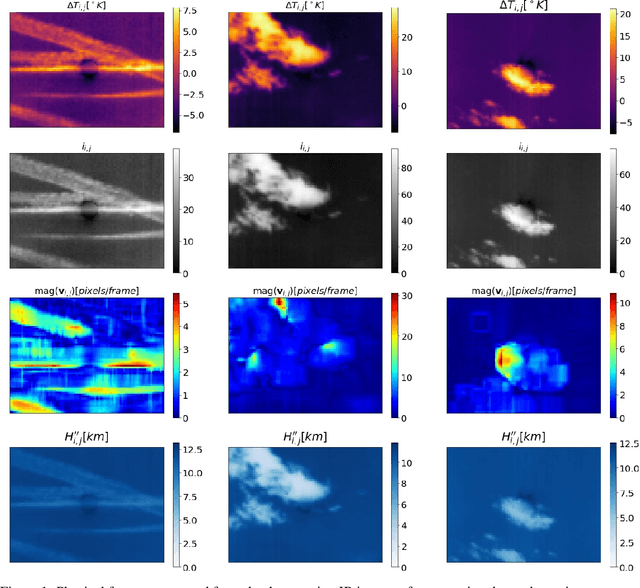
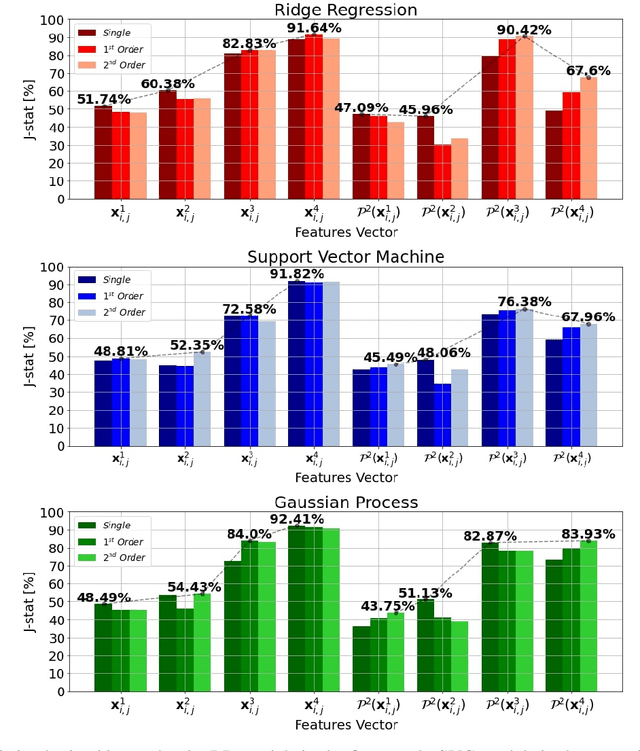

Photovoltaic (PV) systems are sensitive to cloud shadow projection, which needs to be forecasted to reduce the noise impacting the short-term forecast of Global Solar Irradiance (GSI). We present a comparison between different kernel discriminative models for cloud detection. The models are solved in the primal formulation to make them feasible in real-time applications. The performances are compared using the j-statistic. The Infrared (IR) images have been preprocessed to remove debris, which increases the performance of the analyzed methods. The use of the pixels neighboring features also leads to a performance improvement. Discriminative models solved in the primal yield a dramatically lower computing time along with high performance in the segmentation.
Applying SVGD to Bayesian Neural Networks for Cyclical Time-Series Prediction and Inference
Jan 17, 2019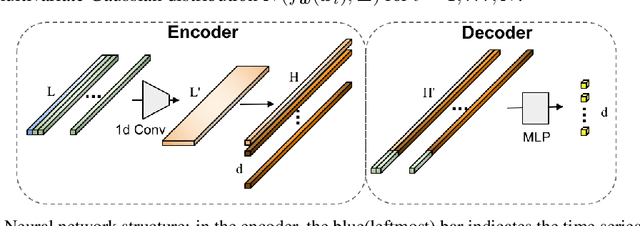
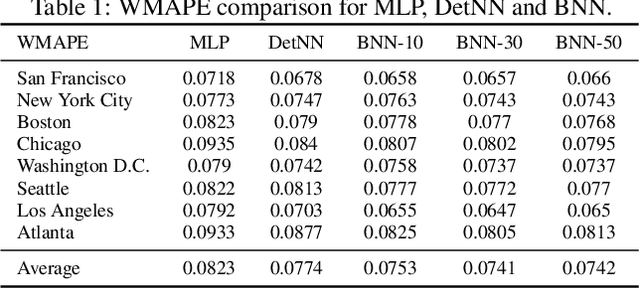
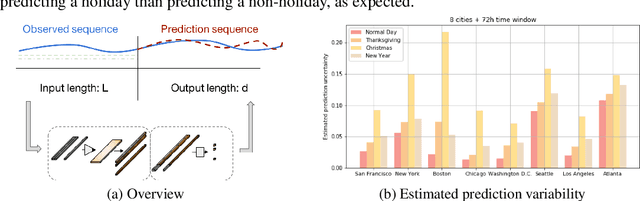
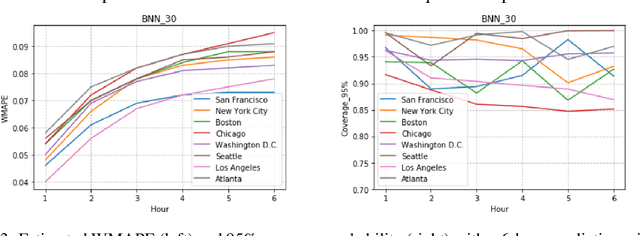
A regression-based BNN model is proposed to predict spatiotemporal quantities like hourly rider demand with calibrated uncertainties. The main contributions of this paper are (i) A feed-forward deterministic neural network (DetNN) architecture that predicts cyclical time series data with sensitivity to anomalous forecasting events; (ii) A Bayesian framework applying SVGD to train large neural networks for such tasks, capable of producing time series predictions as well as measures of uncertainty surrounding the predictions. Experiments show that the proposed BNN reduces average estimation error by 10% across 8 U.S. cities compared to a fine-tuned multilayer perceptron (MLP), and 4% better than the same network architecture trained without SVGD.