 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Coarse-to-Fine Imitation Learning: Robot Manipulation from a Single Demonstration
Jun 10, 2021
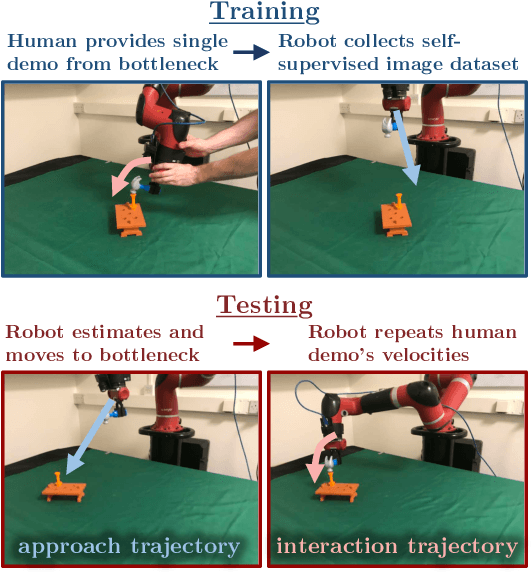


We introduce a simple new method for visual imitation learning, which allows a novel robot manipulation task to be learned from a single human demonstration, without requiring any prior knowledge of the object being interacted with. Our method models imitation learning as a state estimation problem, with the state defined as the end-effector's pose at the point where object interaction begins, as observed from the demonstration. By then modelling a manipulation task as a coarse, approach trajectory followed by a fine, interaction trajectory, this state estimator can be trained in a self-supervised manner, by automatically moving the end-effector's camera around the object. At test time, the end-effector moves to the estimated state through a linear path, at which point the original demonstration's end-effector velocities are simply replayed. This enables convenient acquisition of a complex interaction trajectory, without actually needing to explicitly learn a policy. Real-world experiments on 8 everyday tasks show that our method can learn a diverse range of skills from a single human demonstration, whilst also yielding a stable and interpretable controller.
DEALIO: Data-Efficient Adversarial Learning for Imitation from Observation
Mar 31, 2021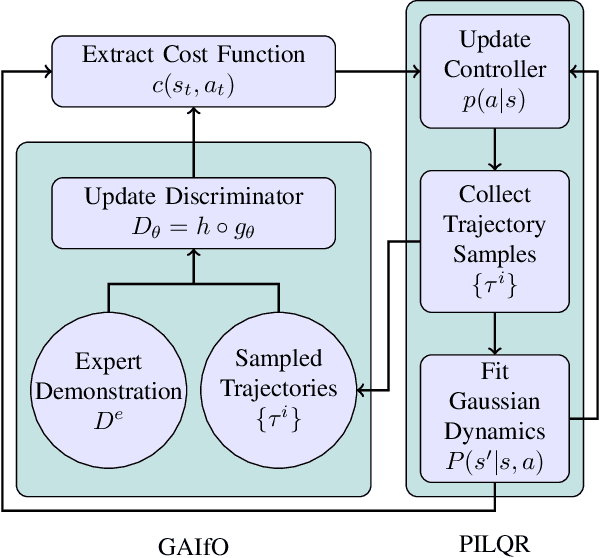
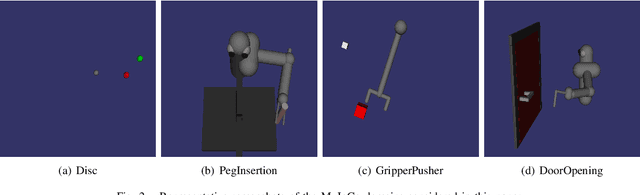
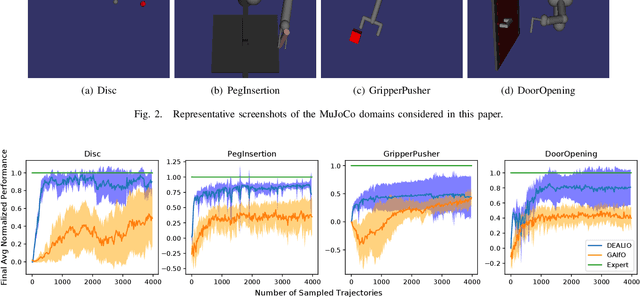
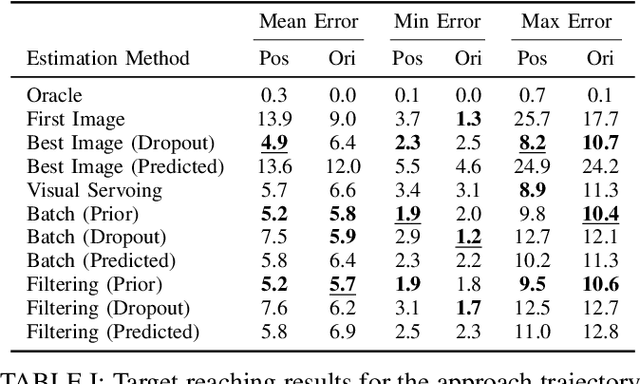
In imitation learning from observation IfO, a learning agent seeks to imitate a demonstrating agent using only observations of the demonstrated behavior without access to the control signals generated by the demonstrator. Recent methods based on adversarial imitation learning have led to state-of-the-art performance on IfO problems, but they typically suffer from high sample complexity due to a reliance on data-inefficient, model-free reinforcement learning algorithms. This issue makes them impractical to deploy in real-world settings, where gathering samples can incur high costs in terms of time, energy, and risk. In this work, we hypothesize that we can incorporate ideas from model-based reinforcement learning with adversarial methods for IfO in order to increase the data efficiency of these methods without sacrificing performance. Specifically, we consider time-varying linear Gaussian policies, and propose a method that integrates the linear-quadratic regulator with path integral policy improvement into an existing adversarial IfO framework. The result is a more data-efficient IfO algorithm with better performance, which we show empirically in four simulation domains: using far fewer interactions with the environment, the proposed method exhibits similar or better performance than the existing technique.
Unsupervised learning of MRI tissue properties using MRI physics models
Jul 06, 2021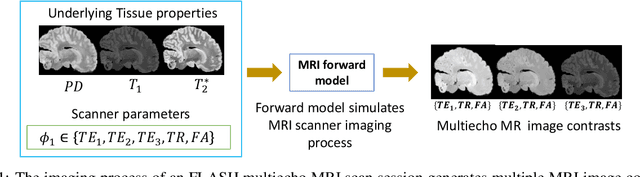

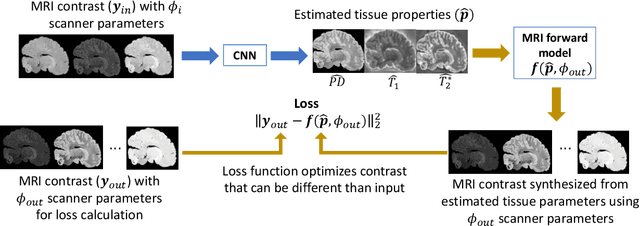
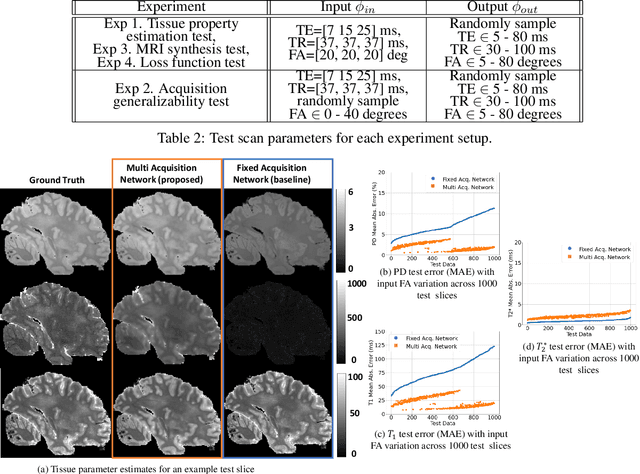
In neuroimaging, MRI tissue properties characterize underlying neurobiology, provide quantitative biomarkers for neurological disease detection and analysis, and can be used to synthesize arbitrary MRI contrasts. Estimating tissue properties from a single scan session using a protocol available on all clinical scanners promises to reduce scan time and cost, enable quantitative analysis in routine clinical scans and provide scan-independent biomarkers of disease. However, existing tissue properties estimation methods - most often $\mathbf{T_1}$ relaxation, $\mathbf{T_2^*}$ relaxation, and proton density ($\mathbf{PD}$) - require data from multiple scan sessions and cannot estimate all properties from a single clinically available MRI protocol such as the multiecho MRI scan. In addition, the widespread use of non-standard acquisition parameters across clinical imaging sites require estimation methods that can generalize across varying scanner parameters. However, existing learning methods are acquisition protocol specific and cannot estimate from heterogenous clinical data from different imaging sites. In this work we propose an unsupervised deep-learning strategy that employs MRI physics to estimate all three tissue properties from a single multiecho MRI scan session, and generalizes across varying acquisition parameters. The proposed strategy optimizes accurate synthesis of new MRI contrasts from estimated latent tissue properties, enabling unsupervised training, we also employ random acquisition parameters during training to achieve acquisition generalization. We provide the first demonstration of estimating all tissue properties from a single multiecho scan session. We demonstrate improved accuracy and generalizability for tissue property estimation and MRI synthesis.
SQRP: Sensing Quality-aware Robot Programming System for Non-expert Programmers
Jun 30, 2021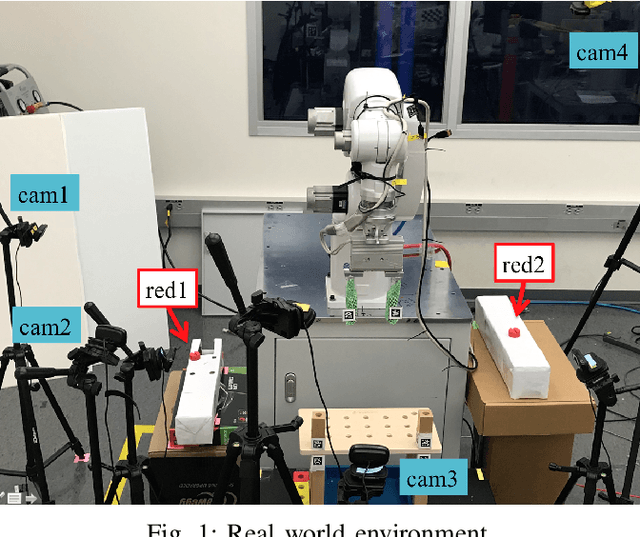
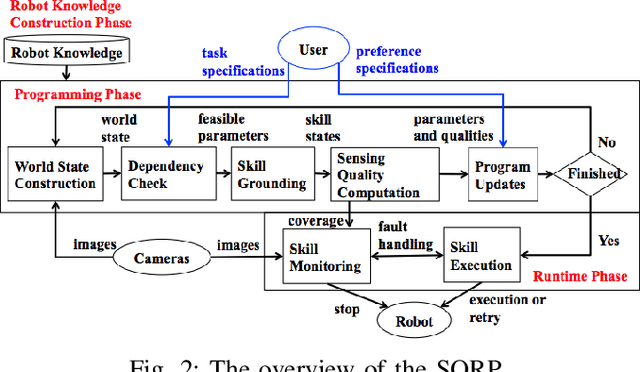
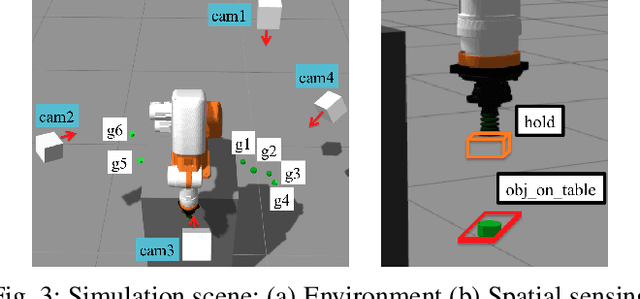
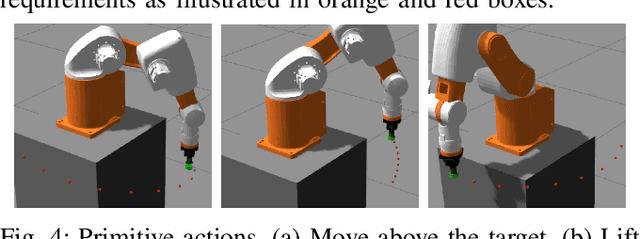
Robot programming typically makes use of a set of mechanical skills that is acquired by machine learning. Because there is in general no guarantee that machine learning produces robot programs that are free of surprising behavior, the safe execution of a robot program must utilize monitoring modules that take sensor data as inputs in real time to ensure the correctness of the skill execution. Owing to the fact that sensors and monitoring algorithms are usually subject to physical restrictions and that effective robot programming is sensitive to the selection of skill parameters, these considerations may lead to different sensor input qualities such as the view coverage of a vision system that determines whether a skill can be successfully deployed in performing a task. Choosing improper skill parameters may cause the monitoring modules to delay or miss the detection of important events such as a mechanical failure. These failures may reduce the throughput in robotic manufacturing and could even cause a destructive system crash. To address above issues, we propose a sensing quality-aware robot programming system that automatically computes the sensing qualities as a function of the robot's environment and uses the information to guide non-expert users to select proper skill parameters in the programming phase. We demonstrate our system framework on a 6DOF robot arm for an object pick-up task.
Synthesizing Adversarial Negative Responses for Robust Response Ranking and Evaluation
Jun 10, 2021
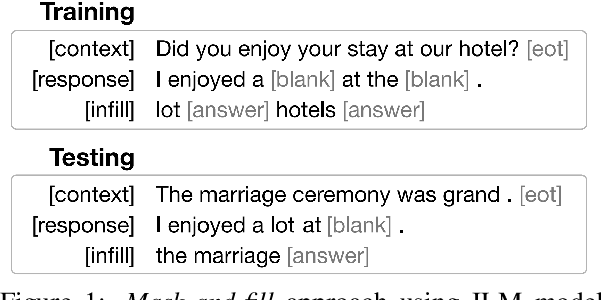

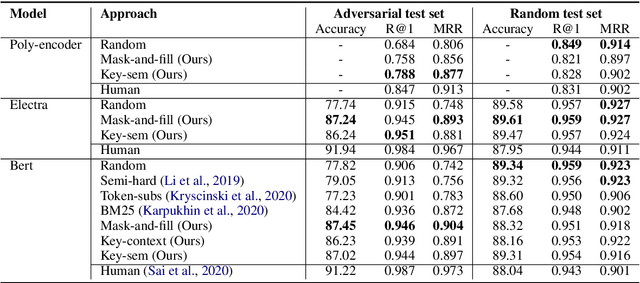
Open-domain neural dialogue models have achieved high performance in response ranking and evaluation tasks. These tasks are formulated as a binary classification of responses given in a dialogue context, and models generally learn to make predictions based on context-response content similarity. However, over-reliance on content similarity makes the models less sensitive to the presence of inconsistencies, incorrect time expressions and other factors important for response appropriateness and coherence. We propose approaches for automatically creating adversarial negative training data to help ranking and evaluation models learn features beyond content similarity. We propose mask-and-fill and keyword-guided approaches that generate negative examples for training more robust dialogue systems. These generated adversarial responses have high content similarity with the contexts but are either incoherent, inappropriate or not fluent. Our approaches are fully data-driven and can be easily incorporated in existing models and datasets. Experiments on classification, ranking and evaluation tasks across multiple datasets demonstrate that our approaches outperform strong baselines in providing informative negative examples for training dialogue systems.
A Variational Time Series Feature Extractor for Action Prediction
Sep 26, 2018

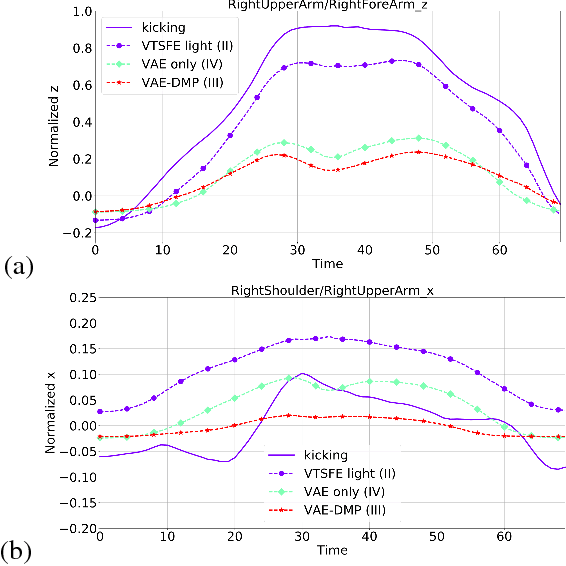
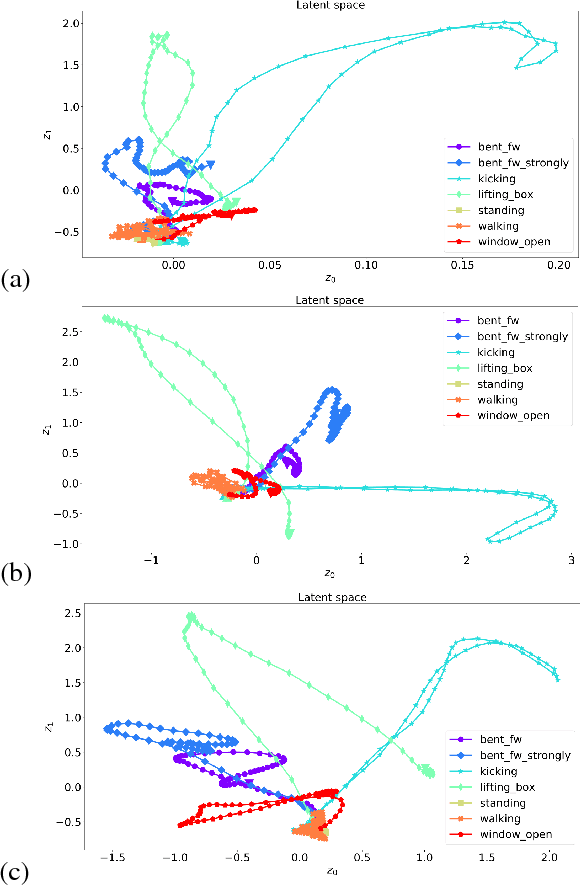
We propose a Variational Time Series Feature Extractor (VTSFE), inspired by the VAE-DMP model of Chen et al., to be used for action recognition and prediction. Our method is based on variational autoencoders. It improves VAE-DMP in that it has a better noise inference model, a simpler transition model constraining the acceleration in the trajectories of the latent space, and a tighter lower bound for the variational inference. We apply the method for classification and prediction of whole-body movements on a dataset with 7 tasks and 10 demonstrations per task, recorded with a wearable motion capture suit. The comparison with VAE and VAE-DMP suggests the better performance of our method for feature extraction. An open-source software implementation of each method with TensorFlow is also provided. In addition, a more detailed version of this work can be found in the indicated code repository. Although it was meant to, the VTSFE hasn't been tested for action prediction, due to a lack of time in the context of Maxime Chaveroche's Master thesis at INRIA.
Improving multi-speaker TTS prosody variance with a residual encoder and normalizing flows
Jun 10, 2021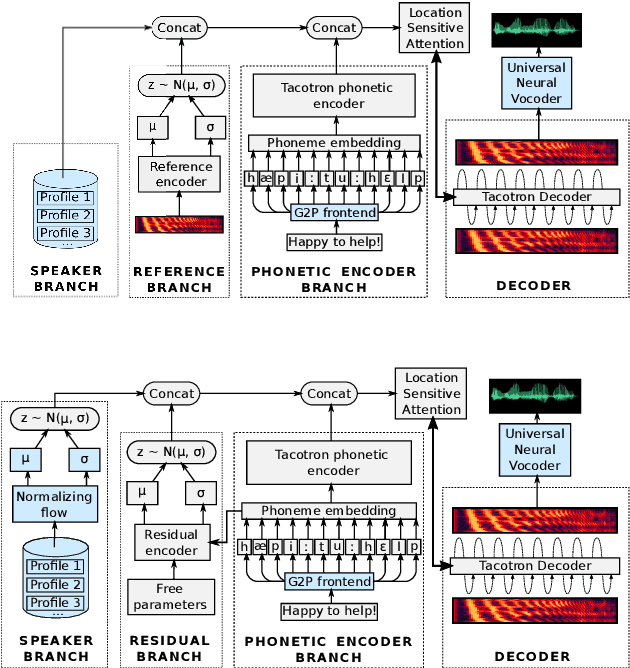

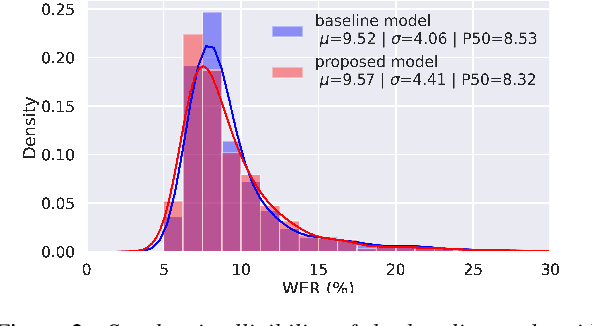

Text-to-speech systems recently achieved almost indistinguishable quality from human speech. However, the prosody of those systems is generally flatter than natural speech, producing samples with low expressiveness. Disentanglement of speaker id and prosody is crucial in text-to-speech systems to improve on naturalness and produce more variable syntheses. This paper proposes a new neural text-to-speech model that approaches the disentanglement problem by conditioning a Tacotron2-like architecture on flow-normalized speaker embeddings, and by substituting the reference encoder with a new learned latent distribution responsible for modeling the intra-sentence variability due to the prosody. By removing the reference encoder dependency, the speaker-leakage problem typically happening in this kind of systems disappears, producing more distinctive syntheses at inference time. The new model achieves significantly higher prosody variance than the baseline in a set of quantitative prosody features, as well as higher speaker distinctiveness, without decreasing the speaker intelligibility. Finally, we observe that the normalized speaker embeddings enable much richer speaker interpolations, substantially improving the distinctiveness of the new interpolated speakers.
Leveraged Weighted Loss for Partial Label Learning
Jun 10, 2021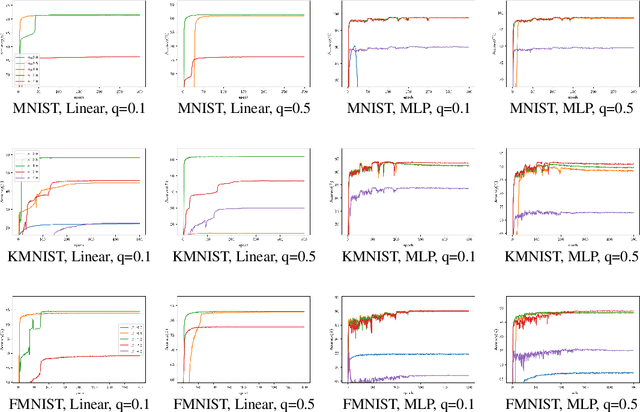
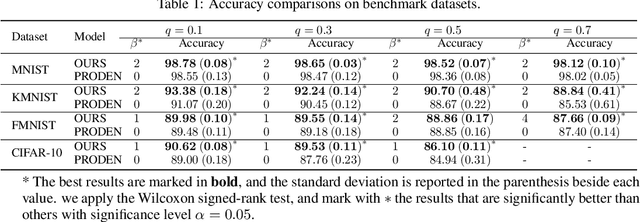
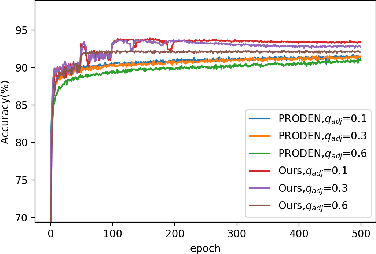
As an important branch of weakly supervised learning, partial label learning deals with data where each instance is assigned with a set of candidate labels, whereas only one of them is true. Despite many methodology studies on learning from partial labels, there still lacks theoretical understandings of their risk consistent properties under relatively weak assumptions, especially on the link between theoretical results and the empirical choice of parameters. In this paper, we propose a family of loss functions named \textit{Leveraged Weighted} (LW) loss, which for the first time introduces the leverage parameter $\beta$ to consider the trade-off between losses on partial labels and non-partial ones. From the theoretical side, we derive a generalized result of risk consistency for the LW loss in learning from partial labels, based on which we provide guidance to the choice of the leverage parameter $\beta$. In experiments, we verify the theoretical guidance, and show the high effectiveness of our proposed LW loss on both benchmark and real datasets compared with other state-of-the-art partial label learning algorithms.
Learning neural network potentials from experimental data via Differentiable Trajectory Reweighting
Jun 02, 2021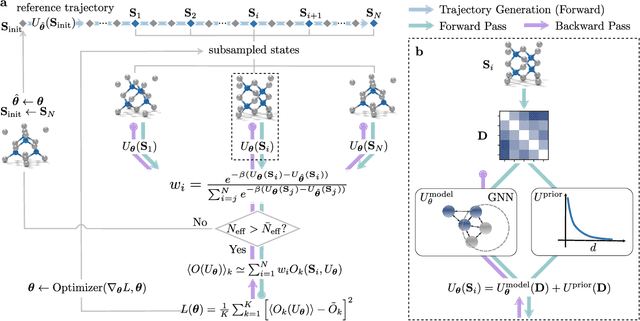
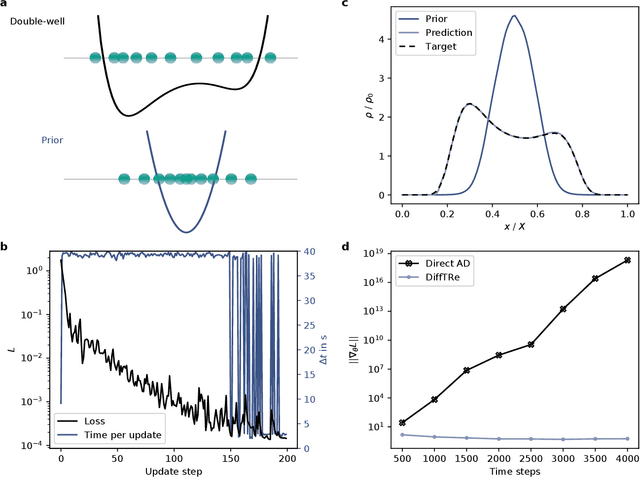
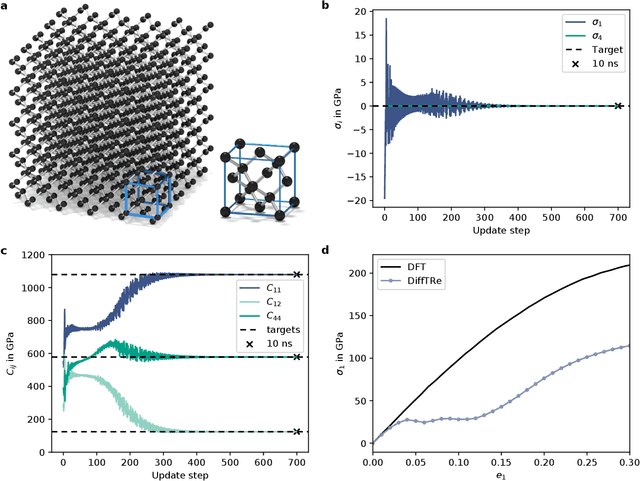
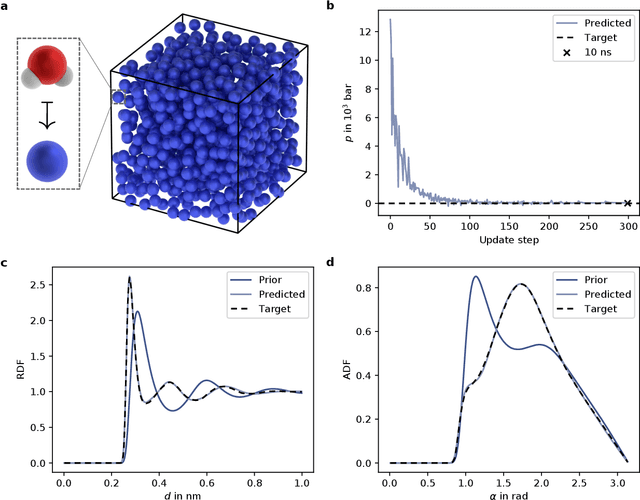
In molecular dynamics (MD), neural network (NN) potentials trained bottom-up on quantum mechanical data have seen tremendous success recently. Top-down approaches that learn NN potentials directly from experimental data have received less attention, typically facing numerical and computational challenges when backpropagating through MD simulations. We present the Differentiable Trajectory Reweighting (DiffTRe) method, which bypasses differentiation through the MD simulation for time-independent observables. Leveraging thermodynamic perturbation theory, we avoid exploding gradients and achieve around 2 orders of magnitude speed-up in gradient computation for top-down learning. We show effectiveness of DiffTRe in learning NN potentials for an atomistic model of diamond and a coarse-grained model of water based on diverse experimental observables including thermodynamic, structural and mechanical properties. Importantly, DiffTRe also generalizes bottom-up structural coarse-graining methods such as iterative Boltzmann inversion to arbitrary potentials. The presented method constitutes an important milestone towards enriching NN potentials with experimental data, particularly when accurate bottom-up data is unavailable.
A Deep Ensemble-based Wireless Receiver Architecture for Mitigating Adversarial Interference in Automatic Modulation Classification
Apr 08, 2021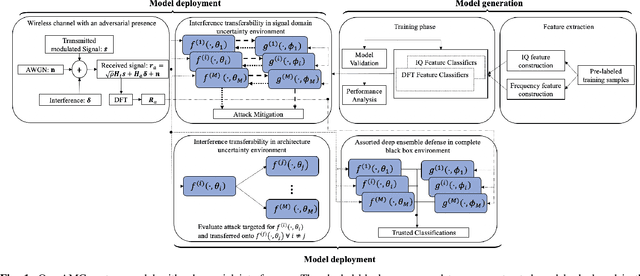
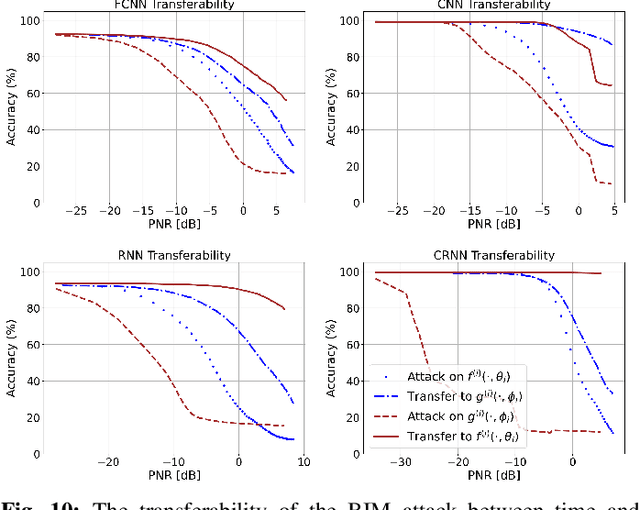
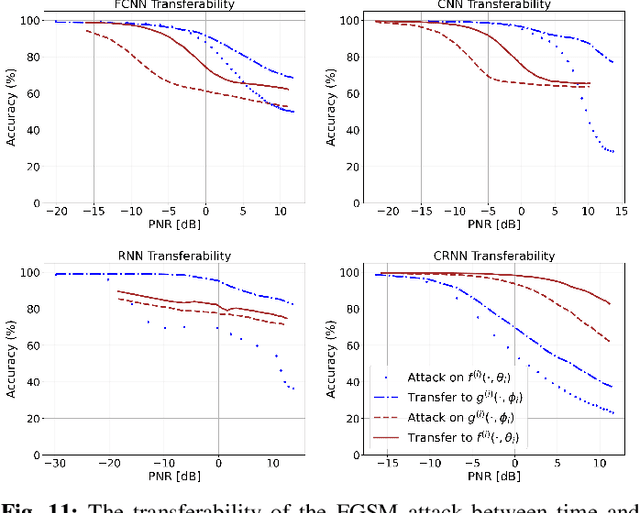
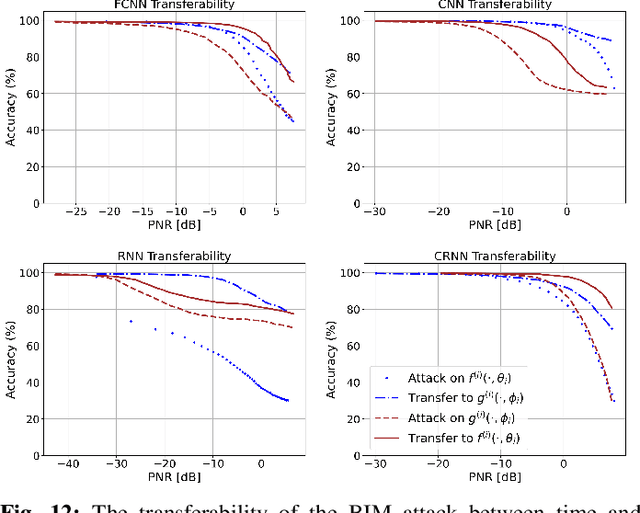
Deep learning-based automatic modulation classification (AMC) models are susceptible to adversarial attacks. Such attacks inject specifically crafted (non-random) wireless interference into transmitted signals to induce erroneous classification predictions. Furthermore, adversarial interference is transferable in black box environments, allowing an adversary to attack multiple deep learning models with a single perturbation crafted for a particular classification model. In this work, we propose a novel wireless receiver architecture to mitigate the effects of adversarial interference in various black box attack environments. We begin by evaluating the architecture uncertainty environment, where we show that adversarial attacks crafted to fool specific AMC DL architectures are not directly transferable to different DL architectures. Next, we consider the domain uncertainty environment, where we show that adversarial attacks crafted on time domain and frequency domain features to not directly transfer to the altering domain. Using these insights, we develop our Assorted Deep Ensemble (ADE) defense, which is an ensemble of deep learning architectures trained on time and frequency domain representations of received signals. Through evaluation on two wireless signal datasets under different sources of uncertainty, we demonstrate that our ADE obtains substantial improvements in AMC classification performance compared with baseline defenses across different adversarial attacks and potencies.