 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Does Time-Delay Feedback Matter to Small Target Motion Detection Against Complex Dynamic Environments?
Dec 29, 2019

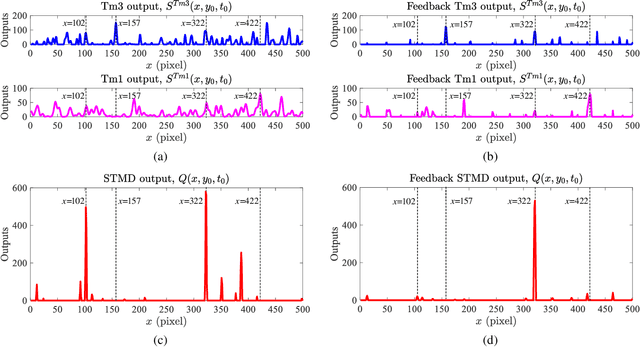
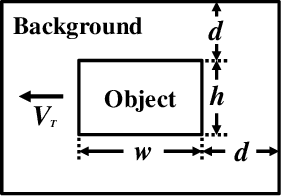
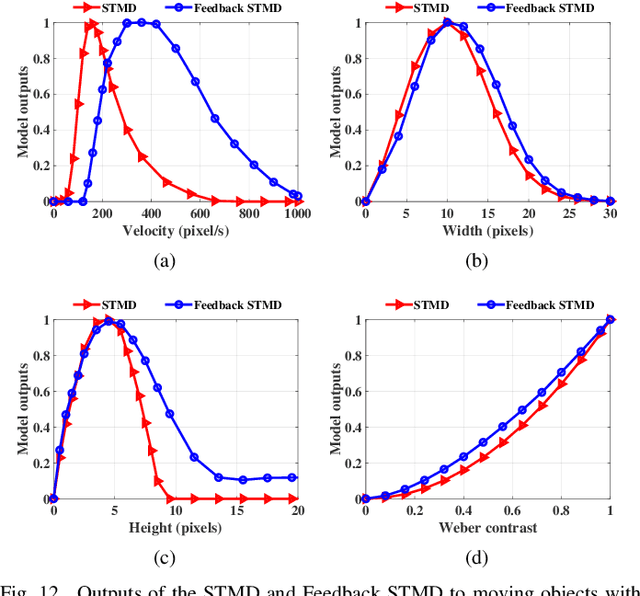
Discriminating small moving objects in complex visual environments is a significant challenge for autonomous micro robots that are generally limited in computational power. Relying on well-evolved visual systems, flying insects can effortlessly detect mates and track prey in rapid pursuits, despite target sizes as small as a few pixels in the visual field. Such exquisite sensitivity for small target motion is known to be supported by a class of specialized neurons named as small target motion detectors (STMDs). The existing STMD-based models normally consist of four sequentially arranged neural layers interconnected through feedforward loops to extract motion information about small targets from raw visual inputs. However, feedback loop, another important regulatory circuit for motion perception, has not been investigated in the STMD pathway and its functional roles for small target motion detection are not clear. In this paper, we assume the existence of the feedback and propose a STMD-based visual system with feedback connection (Feedback STMD), where the system output is temporally delayed, then fed back to lower layers to mediate neural responses. We compare the properties of the visual system with and without the time-delay feedback loop, and discuss its effect on small target motion detection. The experimental results suggest that the Feedback STMD prefers fast-moving small targets, while significantly suppresses those background features moving at lower velocities.
Accurate Prediction of Free Solvation Energy of Organic Molecules via Graph Attention Network and Message Passing Neural Network from Pairwise Atomistic Interactions
Apr 15, 2021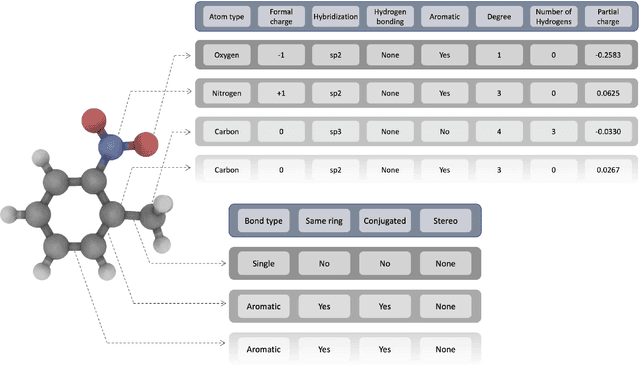
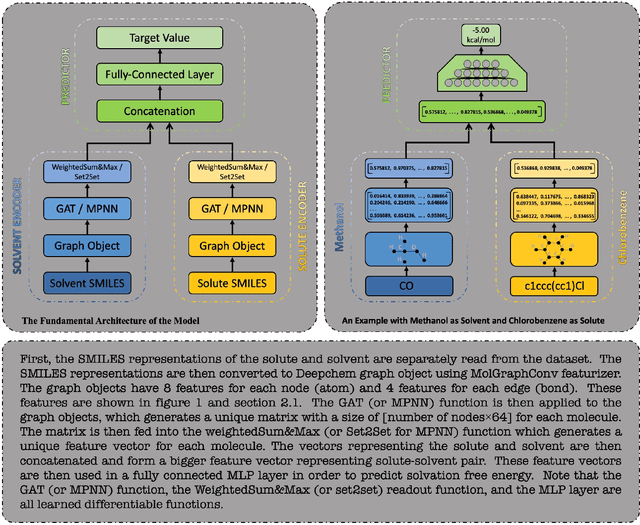
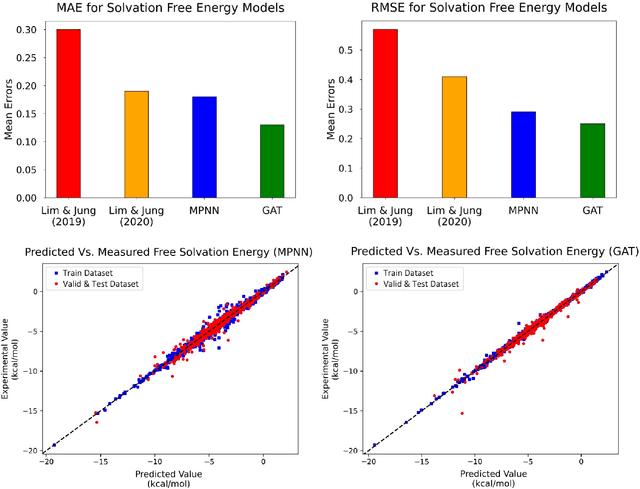
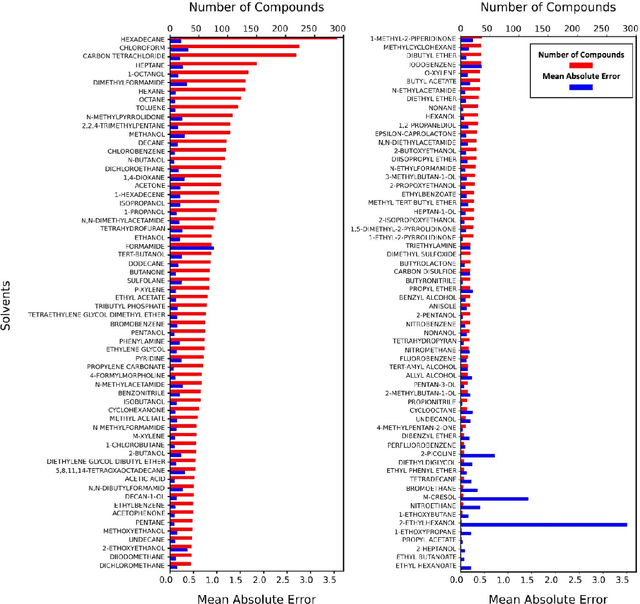
Deep learning based methods have been widely applied to predict various kinds of molecular properties in the pharmaceutical industry with increasingly more success. Solvation free energy is an important index in the field of organic synthesis, medicinal chemistry, drug delivery, and biological processes. However, accurate solvation free energy determination is a time-consuming experimental process. Furthermore, it could be useful to assess solvation free energy in the absence of a physical sample. In this study, we propose two novel models for the problem of free solvation energy predictions, based on the Graph Neural Network (GNN) architectures: Message Passing Neural Network (MPNN) and Graph Attention Network (GAT). GNNs are capable of summarizing the predictive information of a molecule as low-dimensional features directly from its graph structure without relying on an extensive amount of intra-molecular descriptors. As a result, these models are capable of making accurate predictions of the molecular properties without the time consuming process of running an experiment on each molecule. We show that our proposed models outperform all quantum mechanical and molecular dynamics methods in addition to existing alternative machine learning based approaches in the task of solvation free energy prediction. We believe such promising predictive models will be applicable to enhancing the efficiency of the screening of drug molecules and be a useful tool to promote the development of molecular pharmaceutics.
On Maximum Likelihood Training of Score-Based Generative Models
Jan 22, 2021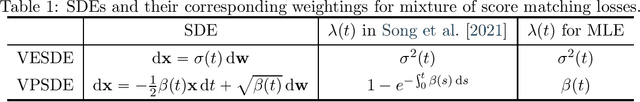
Score-based generative modeling has recently emerged as a promising alternative to traditional likelihood-based or implicit approaches. Learning in score-based models involves first perturbing data with a continuous-time stochastic process, and then matching the time-dependent gradient of the logarithm of the noisy data density - or score function - using a continuous mixture of score matching losses. In this note, we show that such an objective is equivalent to maximum likelihood for certain choices of mixture weighting. This connection provides a principled way to weight the objective function, and justifies its use for comparing different score-based generative models. Taken together with previous work, our result reveals that both maximum likelihood training and test-time log-likelihood evaluation can be achieved through parameterization of the score function alone, without the need to explicitly parameterize a density function.
A Variational Time Series Feature Extractor for Action Prediction
Sep 26, 2018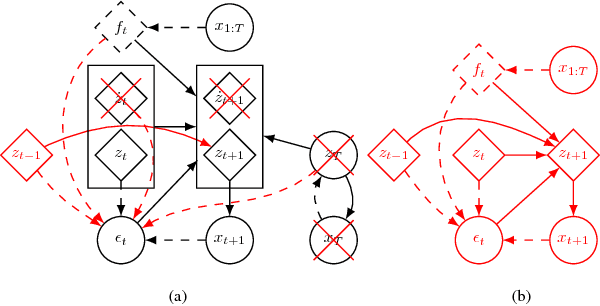

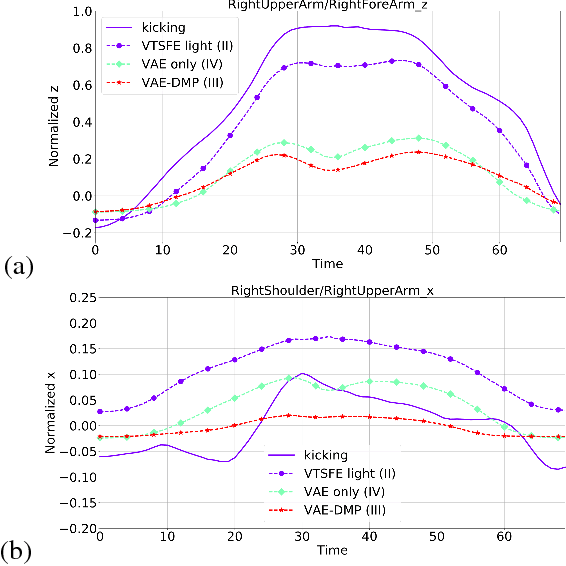
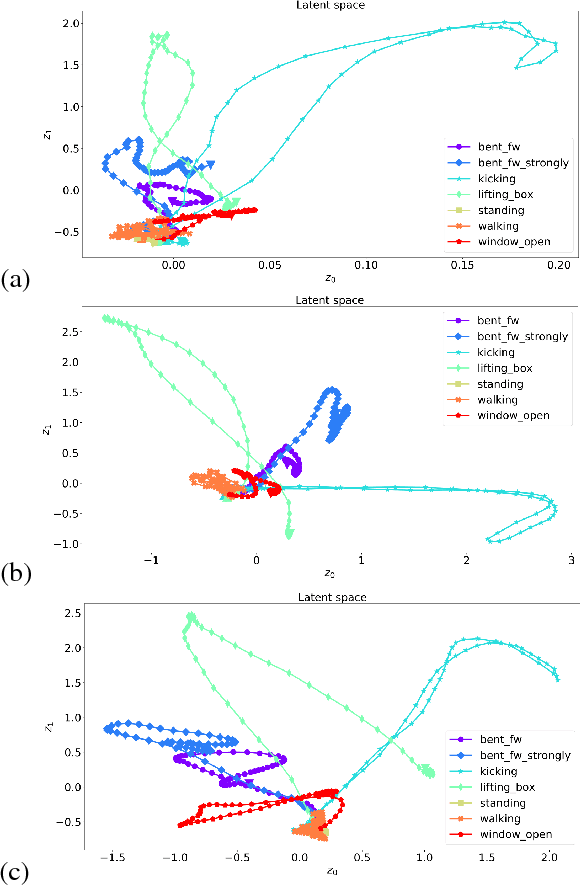
We propose a Variational Time Series Feature Extractor (VTSFE), inspired by the VAE-DMP model of Chen et al., to be used for action recognition and prediction. Our method is based on variational autoencoders. It improves VAE-DMP in that it has a better noise inference model, a simpler transition model constraining the acceleration in the trajectories of the latent space, and a tighter lower bound for the variational inference. We apply the method for classification and prediction of whole-body movements on a dataset with 7 tasks and 10 demonstrations per task, recorded with a wearable motion capture suit. The comparison with VAE and VAE-DMP suggests the better performance of our method for feature extraction. An open-source software implementation of each method with TensorFlow is also provided. In addition, a more detailed version of this work can be found in the indicated code repository. Although it was meant to, the VTSFE hasn't been tested for action prediction, due to a lack of time in the context of Maxime Chaveroche's Master thesis at INRIA.
Bi-objective Search with Bi-directional A*
May 25, 2021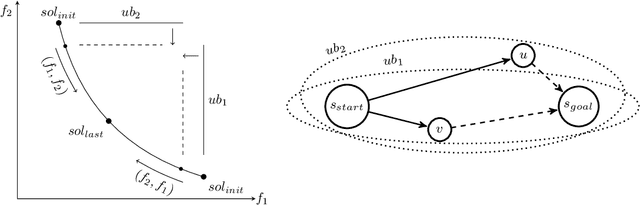
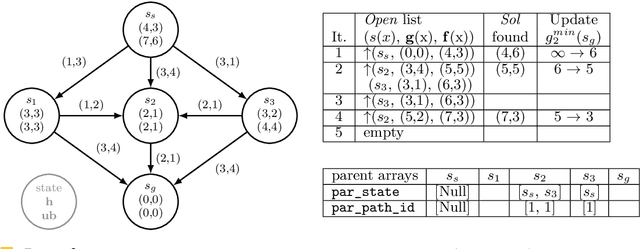
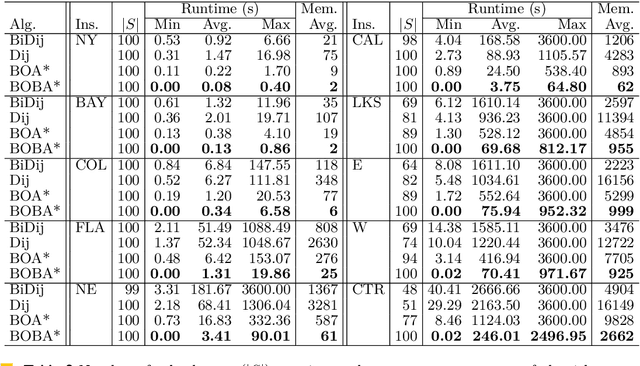
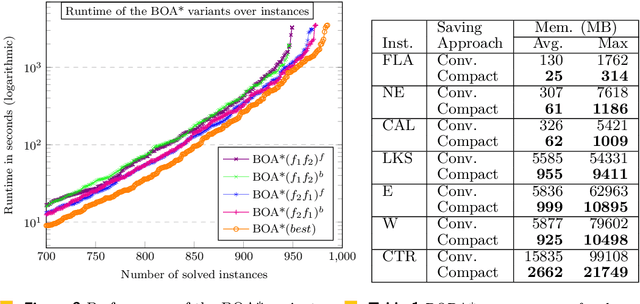
Bi-objective search is a well-known algorithmic problem, concerned with finding a set of optimal solutions in a two-dimensional domain. This problem has a wide variety of applications such as planning in transport systems or optimal control in energy systems. Recently, bi-objective A*-based search (BOA*) has shown state-of-the-art performance in large networks. This paper develops a bi-directional variant of BOA*, enriched with several speed-up heuristics. Our experimental results on 1,000 benchmark cases show that our bi-directional A* algorithm for bi-objective search (BOBA*) can optimally solve all of the benchmark cases within the time limit, outperforming the state of the art BOA*, bi-objective Dijkstra and bi-directional bi-objective Dijkstra by an average runtime improvement of a factor of five over all of the benchmark instances.
Spectrum Correction: Acoustic Scene Classification with Mismatched Recording Devices
May 25, 2021
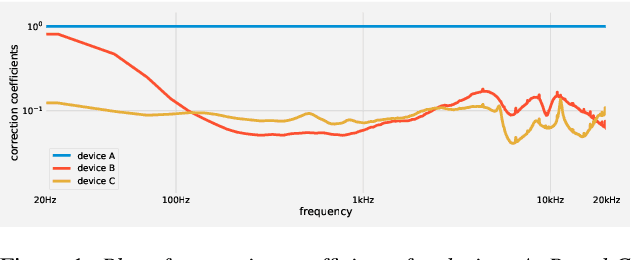
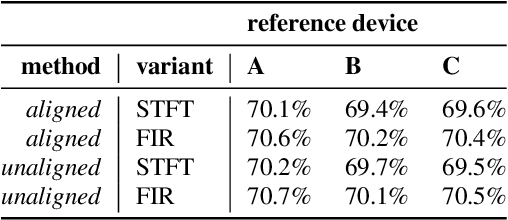
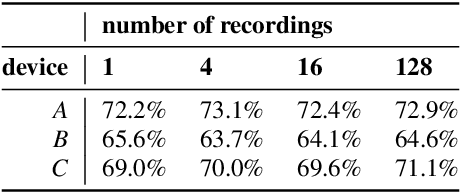
Machine learning algorithms, when trained on audio recordings from a limited set of devices, may not generalize well to samples recorded using other devices with different frequency responses. In this work, a relatively straightforward method is introduced to address this problem. Two variants of the approach are presented. First requires aligned examples from multiple devices, the second approach alleviates this requirement. This method works for both time and frequency domain representations of audio recordings. Further, a relation to standardization and Cepstral Mean Subtraction is analysed. The proposed approach becomes effective even when very few examples are provided. This method was developed during the Detection and Classification of Acoustic Scenes and Events (DCASE) 2019 challenge and won the 1st place in the scenario with mis-matched recording devices with the accuracy of 75%. Source code for the experiments can be found online.
* 5 pages, 1 figure, published at Interspeech 2020, see https://isca-speech.org/archive/Interspeech_2020/abstracts/3088.html
AI Empowered Resource Management for Future Wireless Networks
Jun 11, 2021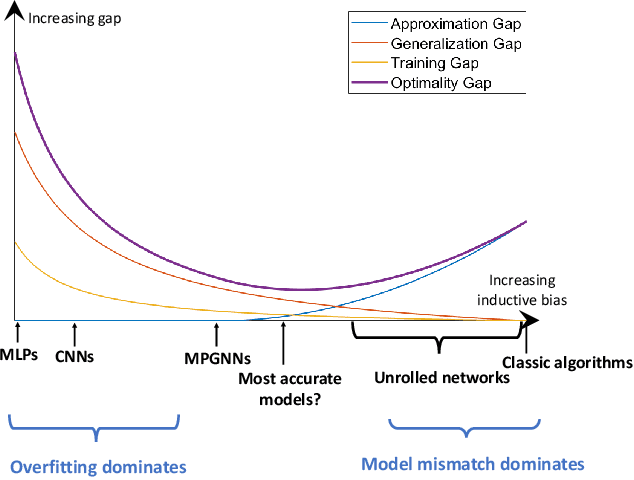
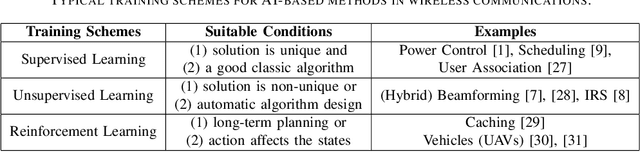
Resource management plays a pivotal role in wireless networks, which, unfortunately, leads to challenging NP-hard problems. Artificial Intelligence (AI), especially deep learning techniques, has recently emerged as a disruptive technology to solve such challenging problems in a real-time manner. However, although promising results have been reported, practical design guidelines and performance guarantees of AI-based approaches are still missing. In this paper, we endeavor to address two fundamental questions: 1) What are the main advantages of AI-based methods compared with classical techniques; and 2) Which neural network should we choose for a given resource management task. For the first question, four advantages are identified and discussed. For the second question, \emph{optimality gap}, i.e., the gap to the optimal performance, is proposed as a measure for selecting model architectures, as well as, for enabling a theoretical comparison between different AI-based approaches. Specifically, for $K$-user interference management problem, we theoretically show that graph neural networks (GNNs) are superior to multi-layer perceptrons (MLPs), and the performance gap between these two methods grows with $\sqrt{K}$.
POCFormer: A Lightweight Transformer Architecture for Detection of COVID-19 Using Point of Care Ultrasound
May 20, 2021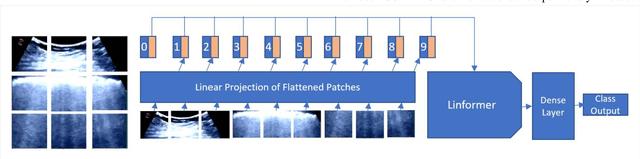
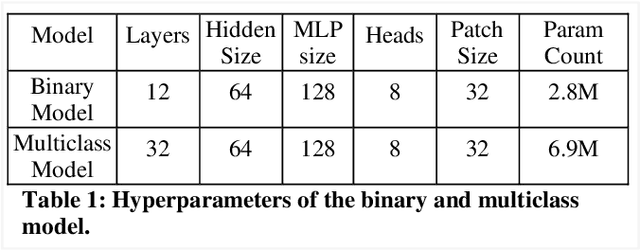
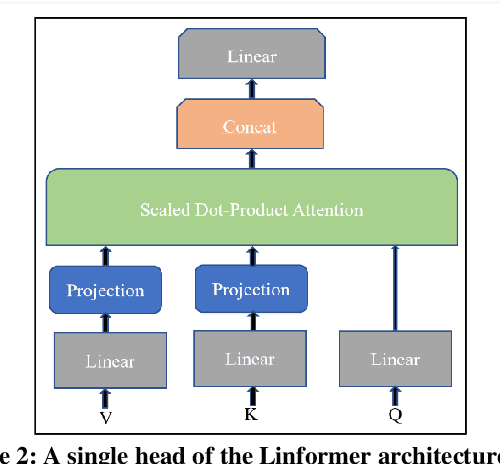
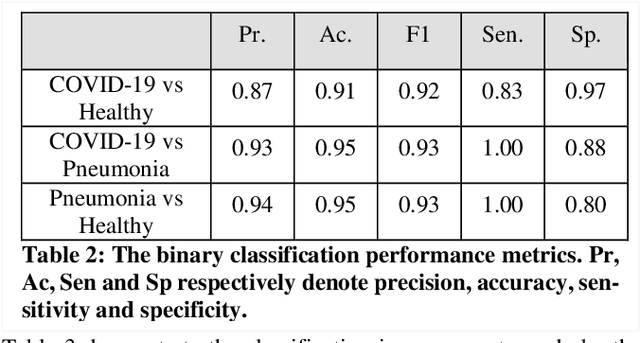
The rapid and seemingly endless expansion of COVID-19 can be traced back to the inefficiency and shortage of testing kits that offer accurate results in a timely manner. An emerging popular technique, which adopts improvements made in mobile ultrasound technology, allows for healthcare professionals to conduct rapid screenings on a large scale. We present an image-based solution that aims at automating the testing process which allows for rapid mass testing to be conducted with or without a trained medical professional that can be applied to rural environments and third world countries. Our contributions towards rapid large-scale testing include a novel deep learning architecture capable of analyzing ultrasound data that can run in real-time and significantly improve the current state-of-the-art detection accuracies using image-based COVID-19 detection.
Generation and Simulation of Yeast Microscopy Imagery with Deep Learning
Mar 24, 2021

Time-lapse fluorescence microscopy (TLFM) is an important and powerful tool in synthetic biological research. Modeling TLFM experiments based on real data may enable researchers to repeat certain experiments with minor effort. This thesis is a study towards deep learning-based modeling of TLFM experiments on the image level. The modeling of TLFM experiments, by way of the example of trapped yeast cells, is split into two tasks. The first task is to generate synthetic image data based on real image data. To approach this problem, a novel generative adversarial network, for conditionalized and unconditionalized image generation, is proposed. The second task is the simulation of brightfield microscopy images over multiple discrete time-steps. To tackle this simulation task an advanced future frame prediction model is introduced. The proposed models are trained and tested on a novel dataset that is presented in this thesis. The obtained results showed that the modeling of TLFM experiments, with deep learning, is a proper approach, but requires future research to effectively model real-world experiments.
Controllable Abstractive Dialogue Summarization with Sketch Supervision
Jun 03, 2021
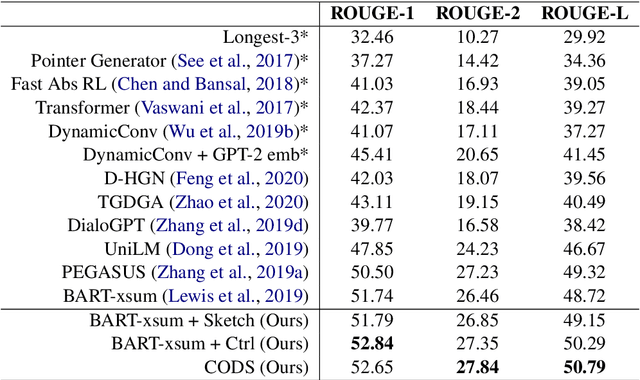
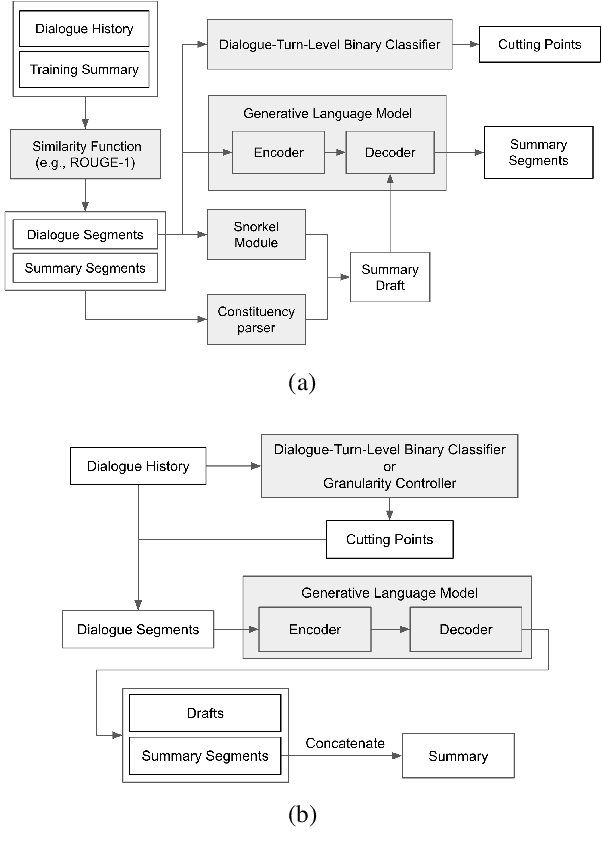

In this paper, we aim to improve abstractive dialogue summarization quality and, at the same time, enable granularity control. Our model has two primary components and stages: 1) a two-stage generation strategy that generates a preliminary summary sketch serving as the basis for the final summary. This summary sketch provides a weakly supervised signal in the form of pseudo-labeled interrogative pronoun categories and key phrases extracted using a constituency parser. 2) A simple strategy to control the granularity of the final summary, in that our model can automatically determine or control the number of generated summary sentences for a given dialogue by predicting and highlighting different text spans from the source text. Our model achieves state-of-the-art performance on the largest dialogue summarization corpus SAMSum, with as high as 50.79 in ROUGE-L score. In addition, we conduct a case study and show competitive human evaluation results and controllability to human-annotated summaries.