 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Fully Spiking Hybrid Neural Network for Energy-Efficient Object Detection
Apr 21, 2021
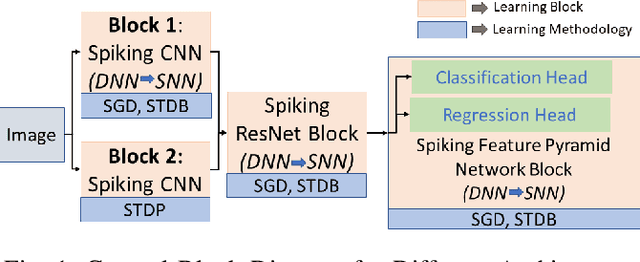
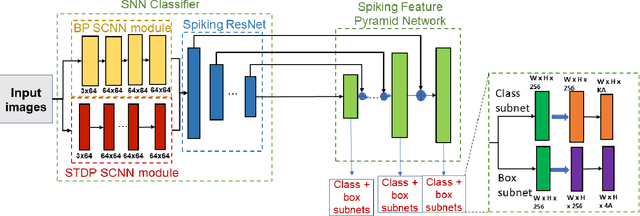
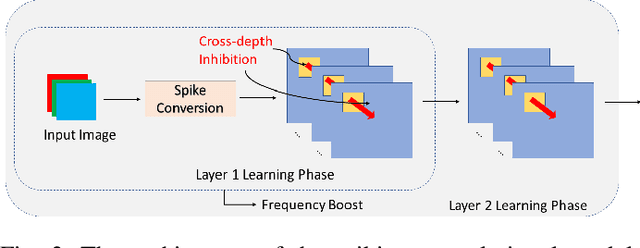
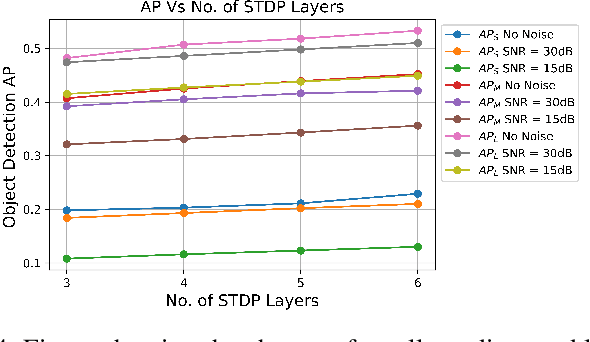
This paper proposes a Fully Spiking Hybrid Neural Network (FSHNN) for energy-efficient and robust object detection in resource-constrained platforms. The network architecture is based on Convolutional SNN using leaky-integrate-fire neuron models. The model combines unsupervised Spike Time-Dependent Plasticity (STDP) learning with back-propagation (STBP) learning methods and also uses Monte Carlo Dropout to get an estimate of the uncertainty error. FSHNN provides better accuracy compared to DNN based object detectors while being 150X energy-efficient. It also outperforms these object detectors, when subjected to noisy input data and less labeled training data with a lower uncertainty error.
A Classical Search Game in Discrete Locations
Mar 08, 2021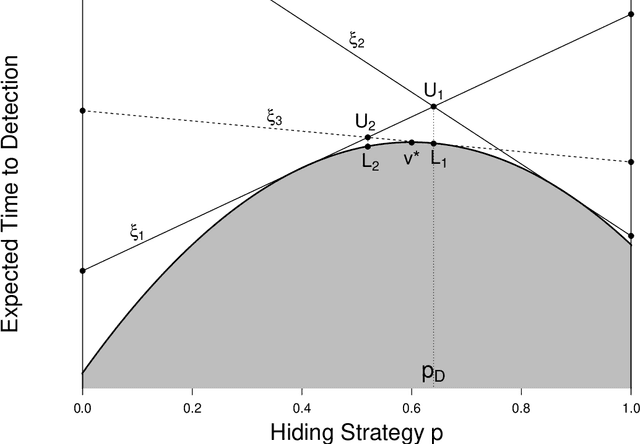
Consider a two-person zero-sum search game between a hider and a searcher. The hider hides among $n$ discrete locations, and the searcher successively visits individual locations until finding the hider. Known to both players, a search at location $i$ takes $t_i$ time units and detects the hider -- if hidden there -- independently with probability $q_i$, for $i=1,\ldots,n$. The hider aims to maximize the expected time until detection, while the searcher aims to minimize it. We prove the existence of an optimal strategy for each player. In particular, the hider's optimal mixed strategy hides in each location with a nonzero probability, and the searcher's optimal mixed strategy can be constructed with up to $n$ simple search sequences. We develop an algorithm to compute an optimal strategy for each player, and compare the optimal hiding strategy with the simple hiding strategy which gives the searcher no location preference at the beginning of the search.
Stochastic Whitening Batch Normalization
Jun 03, 2021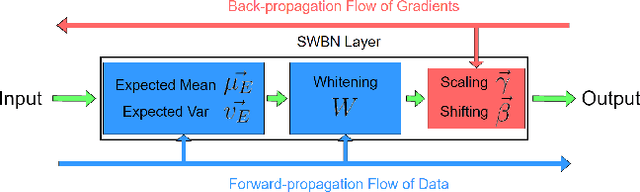
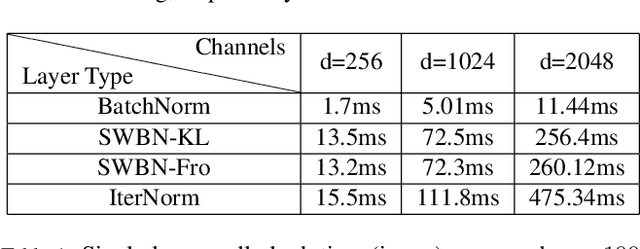
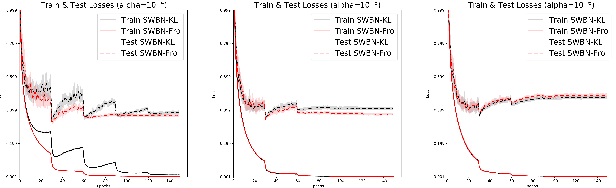
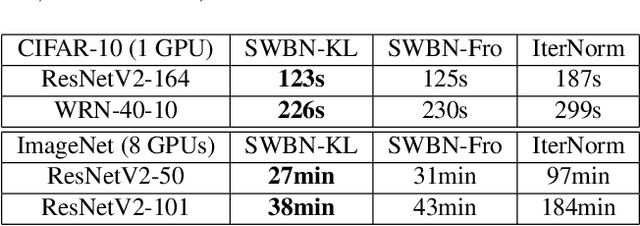
Batch Normalization (BN) is a popular technique for training Deep Neural Networks (DNNs). BN uses scaling and shifting to normalize activations of mini-batches to accelerate convergence and improve generalization. The recently proposed Iterative Normalization (IterNorm) method improves these properties by whitening the activations iteratively using Newton's method. However, since Newton's method initializes the whitening matrix independently at each training step, no information is shared between consecutive steps. In this work, instead of exact computation of whitening matrix at each time step, we estimate it gradually during training in an online fashion, using our proposed Stochastic Whitening Batch Normalization (SWBN) algorithm. We show that while SWBN improves the convergence rate and generalization of DNNs, its computational overhead is less than that of IterNorm. Due to the high efficiency of the proposed method, it can be easily employed in most DNN architectures with a large number of layers. We provide comprehensive experiments and comparisons between BN, IterNorm, and SWBN layers to demonstrate the effectiveness of the proposed technique in conventional (many-shot) image classification and few-shot classification tasks.
Neural Feature Selection for Learning to Rank
Feb 22, 2021
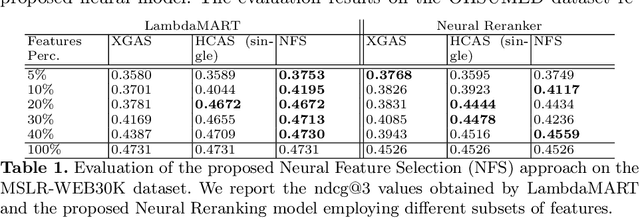
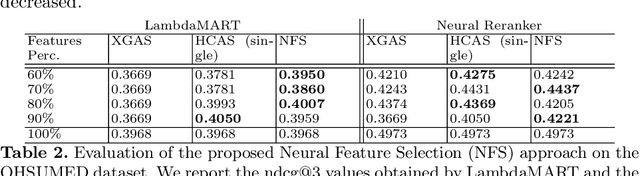
LEarning TO Rank (LETOR) is a research area in the field of Information Retrieval (IR) where machine learning models are employed to rank a set of items. In the past few years, neural LETOR approaches have become a competitive alternative to traditional ones like LambdaMART. However, neural architectures performance grew proportionally to their complexity and size. This can be an obstacle for their adoption in large-scale search systems where a model size impacts latency and update time. For this reason, we propose an architecture-agnostic approach based on a neural LETOR model to reduce the size of its input by up to 60% without affecting the system performance. This approach also allows to reduce a LETOR model complexity and, therefore, its training and inference time up to 50%.
Quantifying and Avoiding Unfair Qualification Labour in Crowdsourcing
May 26, 2021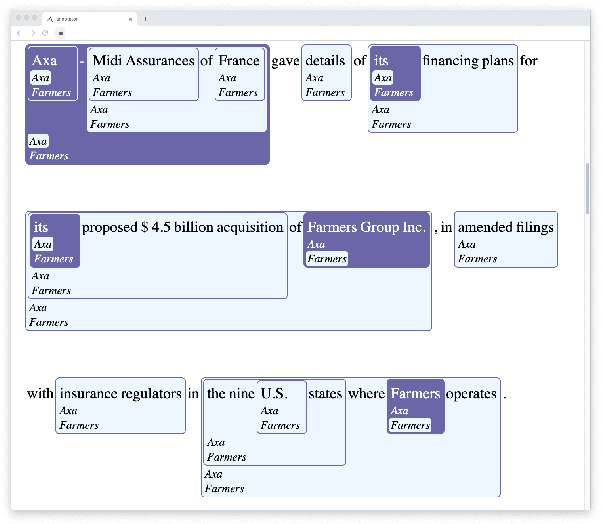
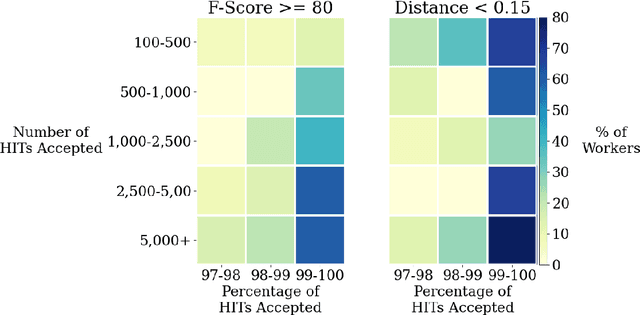
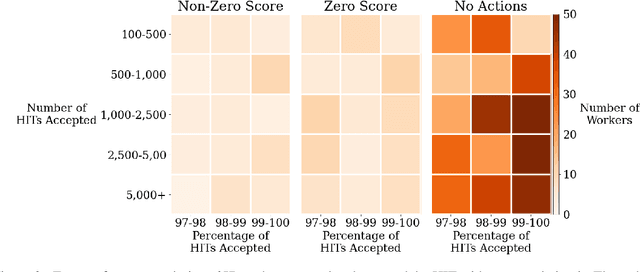
Extensive work has argued in favour of paying crowd workers a wage that is at least equivalent to the U.S. federal minimum wage. Meanwhile, research on collecting high quality annotations suggests using a qualification that requires workers to have previously completed a certain number of tasks. If most requesters who pay fairly require workers to have completed a large number of tasks already then workers need to complete a substantial amount of poorly paid work before they can earn a fair wage. Through analysis of worker discussions and guidance for researchers, we estimate that workers spend approximately 2.25 months of full time effort on poorly paid tasks in order to get the qualifications needed for better paid tasks. We discuss alternatives to this qualification and conduct a study of the correlation between qualifications and work quality on two NLP tasks. We find that it is possible to reduce the burden on workers while still collecting high quality data.
Explicit Basis Function Kernel Methods for Cloud Segmentation in Infrared Sky Images
Feb 12, 2021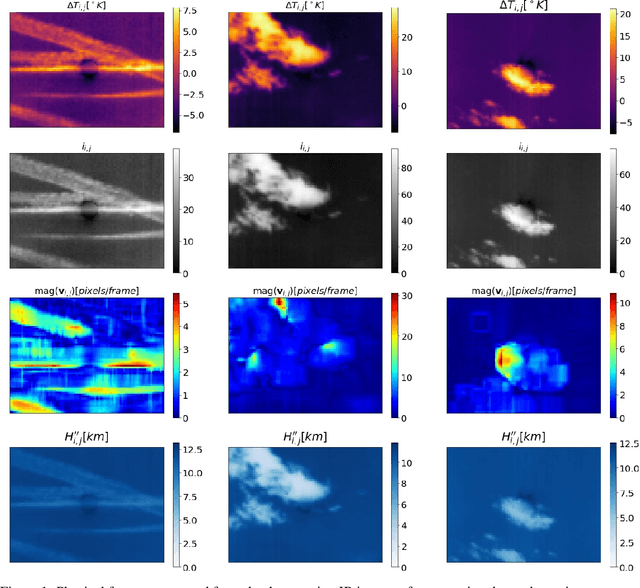
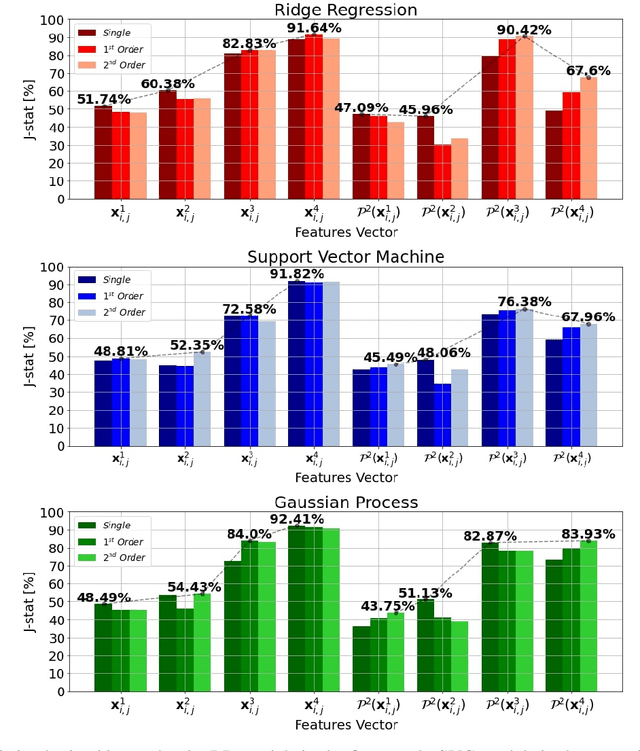

Photovoltaic (PV) systems are sensitive to cloud shadow projection, which needs to be forecasted to reduce the noise impacting the short-term forecast of Global Solar Irradiance (GSI). We present a comparison between different kernel discriminative models for cloud detection. The models are solved in the primal formulation to make them feasible in real-time applications. The performances are compared using the j-statistic. The Infrared (IR) images have been preprocessed to remove debris, which increases the performance of the analyzed methods. The use of the pixels neighboring features also leads to a performance improvement. Discriminative models solved in the primal yield a dramatically lower computing time along with high performance in the segmentation.
Bilateral Grid Learning for Stereo Matching Network
Jan 01, 2021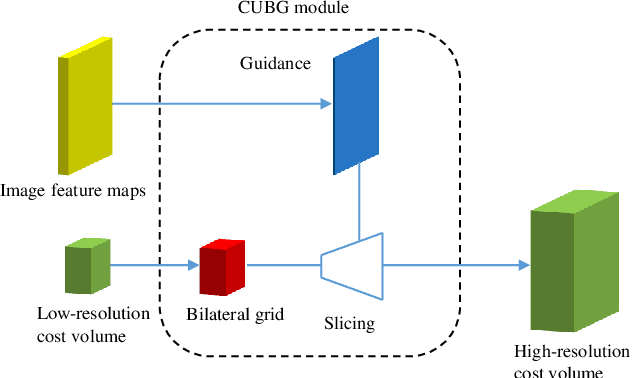
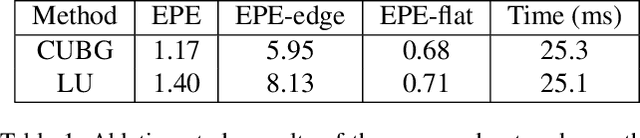
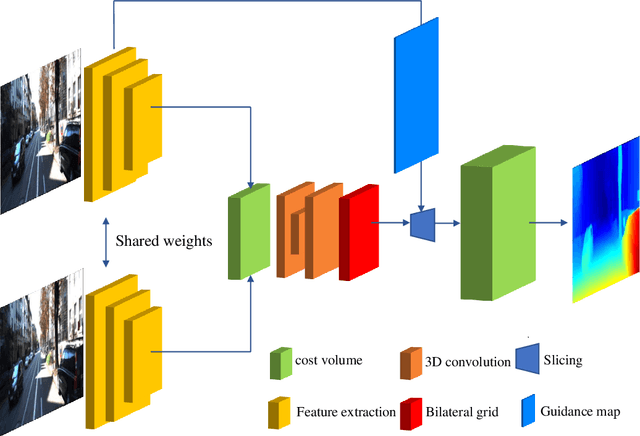
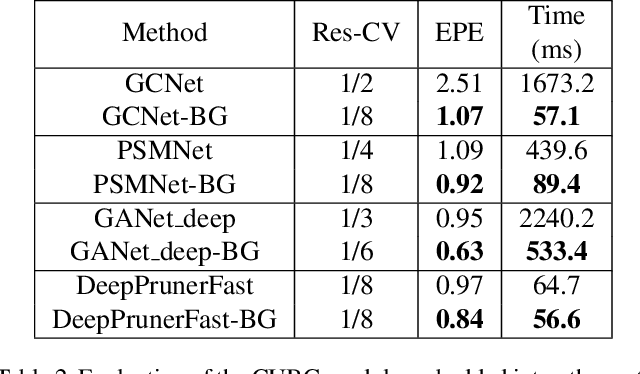
The real-time performance of the stereo matching network is important for many applications, such as automatic driving, robot navigation and augmented reality (AR). Although significant progress has been made in stereo matching networks in recent years, it is still challenging to balance real-time performance and accuracy. In this paper, we present a novel edge-preserving cost volume upsampling module based on the slicing operation in the learned bilateral grid. The slicing layer is parameter-free, which allows us to obtain a high quality cost volume of high resolution from a low resolution cost volume under the guide of the learned guidance map efficiently. The proposed cost volume upsampling module can be seamlessly embedded into many existing stereo matching networks, such as GCNet, PSMNet, and GANet. The resulting networks are accelerated several times while maintaining comparable accuracy. Furthermore, based on this module we design a real-time network (named BGNet), which outperforms the existing published real-time deep stereo matching networks, as well as some complex networks on KITTI stereo datasets. The code of the proposed method will be available.
The Smoothed Satisfaction of Voting Axioms
Jun 03, 2021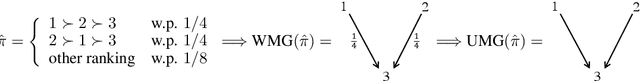


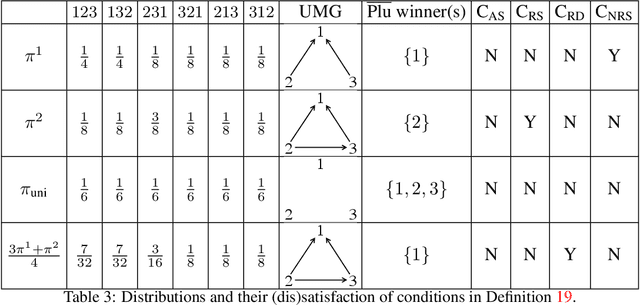
We initiate the work towards a comprehensive picture of the smoothed satisfaction of voting axioms, to provide a finer and more realistic foundation for comparing voting rules. We adopt the smoothed social choice framework, where an adversary chooses arbitrarily correlated "ground truth" preferences for the agents, on top of which random noises are added. We focus on characterizing the smoothed satisfaction of two well-studied voting axioms: Condorcet criterion and participation. We prove that for any fixed number of alternatives, when the number of voters $n$ is sufficiently large, the smoothed satisfaction of the Condorcet criterion under a wide range of voting rules is $1$, $1-\exp(-\Theta(n))$, $\Theta(n^{-0.5})$, $ \exp(-\Theta(n))$, or being $\Theta(1)$ and $1-\Theta(1)$ at the same time; and the smoothed satisfaction of participation is $1-\Theta(n^{-0.5})$. Our results address open questions by Berg and Lepelley in 1994 for these rules, and also confirm the following high-level message: the Condorcet criterion is a bigger concern than participation under realistic models.
PSB2: The Second Program Synthesis Benchmark Suite
Jun 10, 2021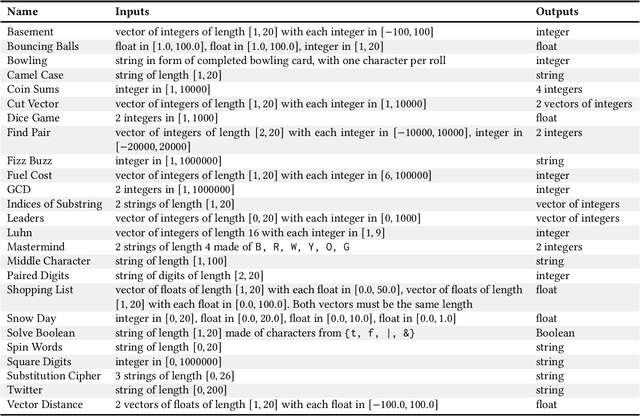
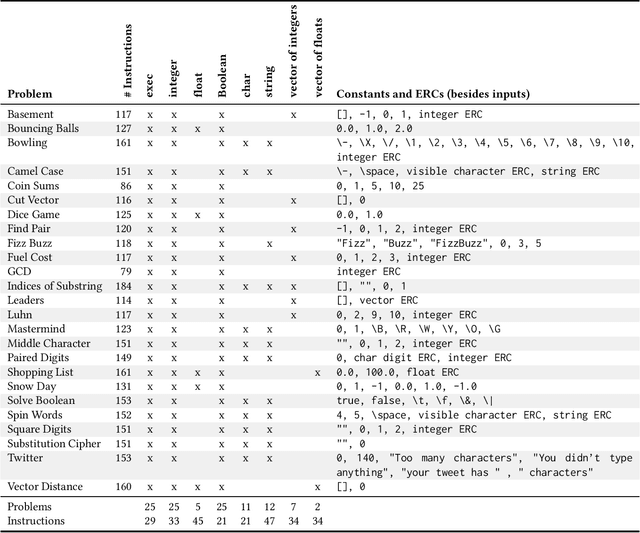
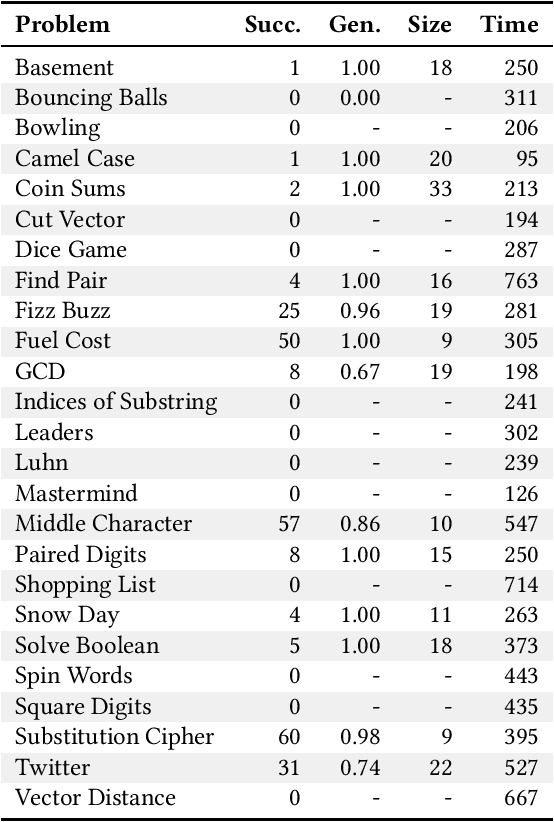
For the past six years, researchers in genetic programming and other program synthesis disciplines have used the General Program Synthesis Benchmark Suite to benchmark many aspects of automatic program synthesis systems. These problems have been used to make notable progress toward the goal of general program synthesis: automatically creating the types of software that human programmers code. Many of the systems that have attempted the problems in the original benchmark suite have used it to demonstrate performance improvements granted through new techniques. Over time, the suite has gradually become outdated, hindering the accurate measurement of further improvements. The field needs a new set of more difficult benchmark problems to move beyond what was previously possible. In this paper, we describe the 25 new general program synthesis benchmark problems that make up PSB2, a new benchmark suite. These problems are curated from a variety of sources, including programming katas and college courses. We selected these problems to be more difficult than those in the original suite, and give results using PushGP showing this increase in difficulty. These new problems give plenty of room for improvement, pointing the way for the next six or more years of general program synthesis research.
CoMo: A novel co-moving 3D camera system
Jan 26, 2021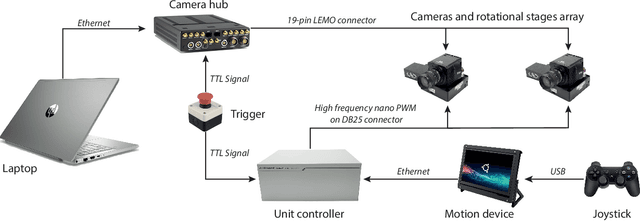
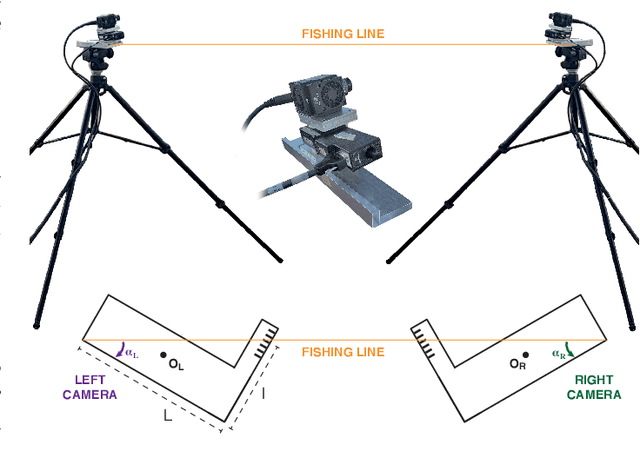
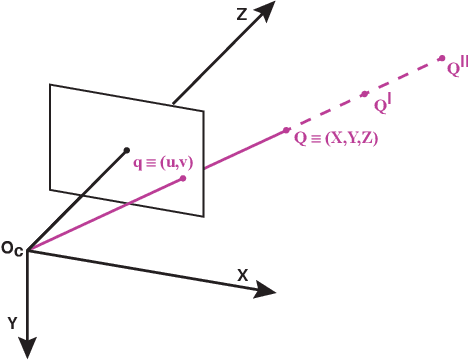
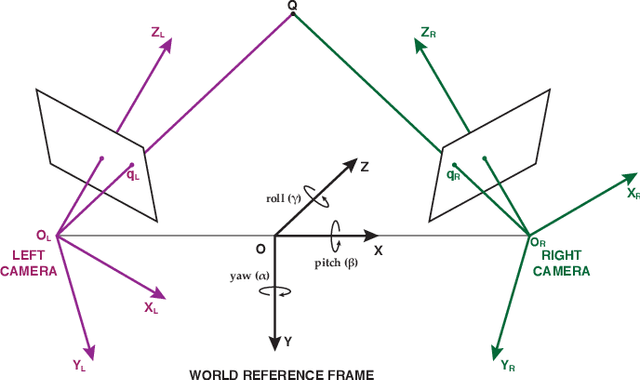
Motivated by the theoretical interest in reconstructing long 3D trajectories of individual birds in large flocks, we developed CoMo, a co-moving camera system of two synchronized high speed cameras coupled with rotational stages, which allow us to dynamically follow the motion of a target flock. With the rotation of the cameras we overcome the limitations of standard static systems that restrict the duration of the collected data to the short interval of time in which targets are in the cameras common field of view, but at the same time we change in time the external parameters of the system, which have then to be calibrated frame-by-frame. We address the calibration of the external parameters measuring the position of the cameras and their three angles of yaw, pitch and roll in the system "home" configuration (rotational stage at an angle equal to 0deg and combining this static information with the time dependent rotation due to the stages. We evaluate the robustness and accuracy of the system by comparing reconstructed and measured 3D distances in what we call 3D tests, which show a relative error of the order of 1%. The novelty of the work presented in this paper is not only on the system itself, but also on the approach we use in the tests, which we show to be a very powerful tool in detecting and fixing calibration inaccuracies and that, for this reason, may be relevant for a broad audience.