 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How to Decompose a Tensor with Group Structure
Jun 04, 2021
In this work we study the orbit recovery problem, which is a natural abstraction for the problem of recovering a planted signal from noisy measurements under unknown group actions. Many important inverse problems in statistics, engineering and the sciences fit into this framework. Prior work has studied cases when the group is discrete and/or abelian. However fundamentally new techniques are needed in order to handle more complex group actions. Our main result is a quasi-polynomial time algorithm to solve orbit recovery over $SO(3)$ - i.e. the cryo-electron tomography problem which asks to recover the three-dimensional structure of a molecule from noisy measurements of randomly rotated copies of it. We analyze a variant of the frequency marching heuristic in the framework of smoothed analysis. Our approach exploits the layered structure of the invariant polynomials, and simultaneously yields a new class of tensor decomposition algorithms that work in settings when the tensor is not low-rank but rather where the factors are algebraically related to each other by a group action.
Signal Transformer: Complex-valued Attention and Meta-Learning for Signal Recognition
Jun 12, 2021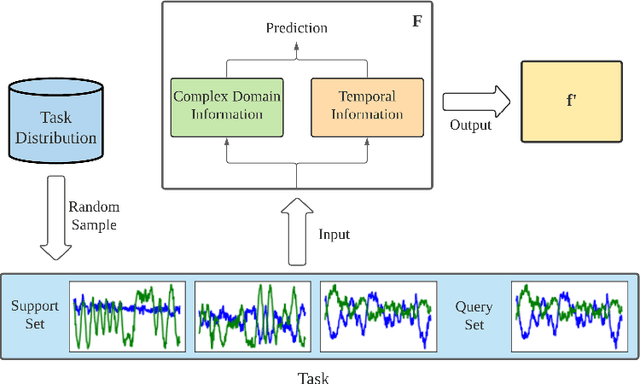
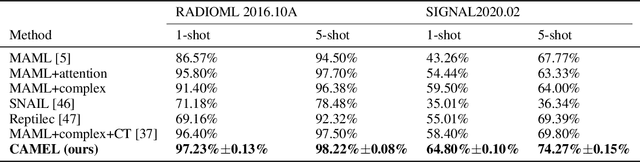

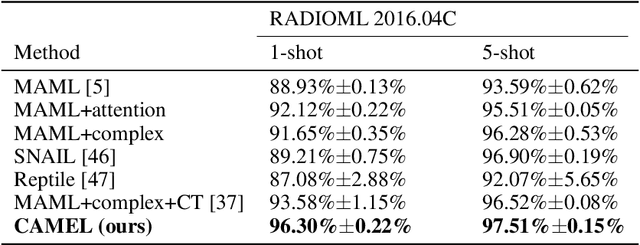
Deep neural networks have been shown as a class of useful tools for addressing signal recognition issues in recent years, especially for identifying the nonlinear feature structures of signals. However, this power of most deep learning techniques heavily relies on an abundant amount of training data, so the performance of classic neural nets decreases sharply when the number of training data samples is small or unseen data are presented in the testing phase. This calls for an advanced strategy, i.e., model-agnostic meta-learning (MAML), which is able to capture the invariant representation of the data samples or signals. In this paper, inspired by the special structure of the signal, i.e., real and imaginary parts consisted in practical time-series signals, we propose a Complex-valued Attentional MEta Learner (CAMEL) for the problem of few-shot signal recognition by leveraging attention and meta-learning in the complex domain. To the best of our knowledge, this is also the first complex-valued MAML that can find the first-order stationary points of general nonconvex problems with theoretical convergence guarantees. Extensive experiments results showcase the superiority of the proposed CAMEL compared with the state-of-the-art methods.
BayesCard: Revitilizing Bayesian Frameworks for Cardinality Estimation
Feb 02, 2021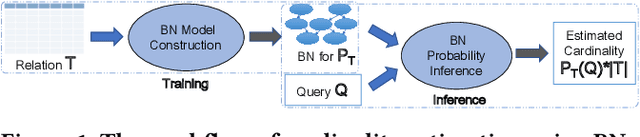
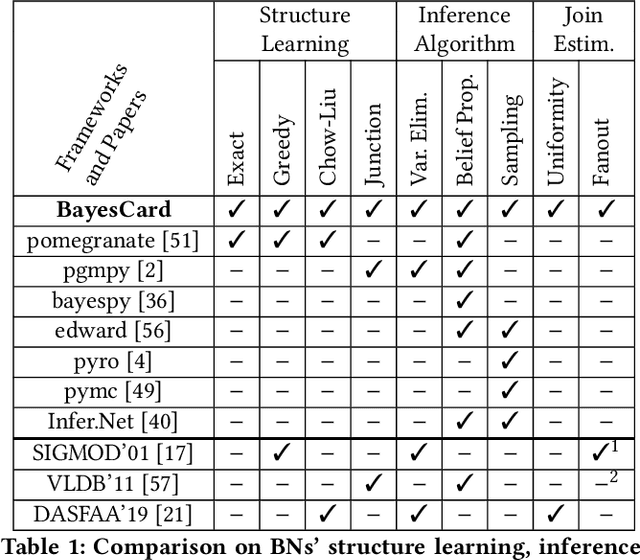
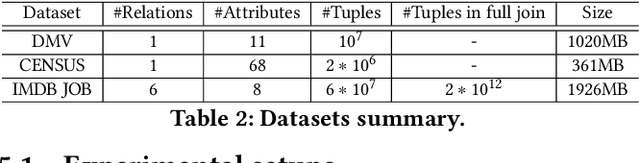
Cardinality estimation (CardEst) is an essential component in query optimizers and a fundamental problem in DBMS. A desired CardEst method should attain good algorithm performance, be stable to varied data settings, and be friendly to system deployment. However, no existing CardEst method can fulfill the three criteria at the same time. Traditional methods often have significant algorithm drawbacks such as large estimation errors. Recently proposed deep learning based methods largely improve the estimation accuracy but their performance can be greatly affected by data and often difficult for system deployment. In this paper, we revitalize the Bayesian networks (BN) for CardEst by incorporating the techniques of probabilistic programming languages. We present BayesCard, the first framework that inherits the advantages of BNs, i.e., high estimation accuracy and interpretability, while overcomes their drawbacks, i.e. low structure learning and inference efficiency. This makes BayesCard a perfect candidate for commercial DBMS deployment. Our experimental results on several single-table and multi-table benchmarks indicate BayesCard's superiority over existing state-of-the-art CardEst methods: BayesCard achieves comparable or better accuracy, 1-2 orders of magnitude faster inference time, 1-3 orders faster training time, 1-3 orders smaller model size, and 1-2 orders faster updates. Meanwhile, BayesCard keeps stable performance when varying data with different settings. We also deploy BayesCard into PostgreSQL. On the IMDB benchmark workload, it improves the end-to-end query time by 13.3%, which is very close to the optimal result of 14.2% using an oracle of true cardinality.
Fair Visual Recognition in Limited Data Regime using Self-Supervision and Self-Distillation
Jun 30, 2021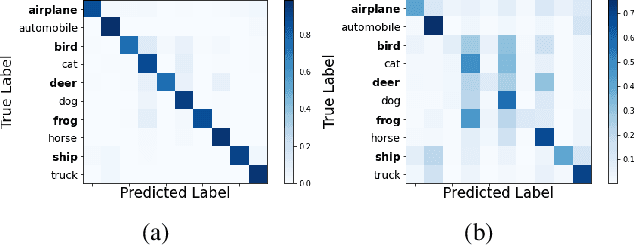
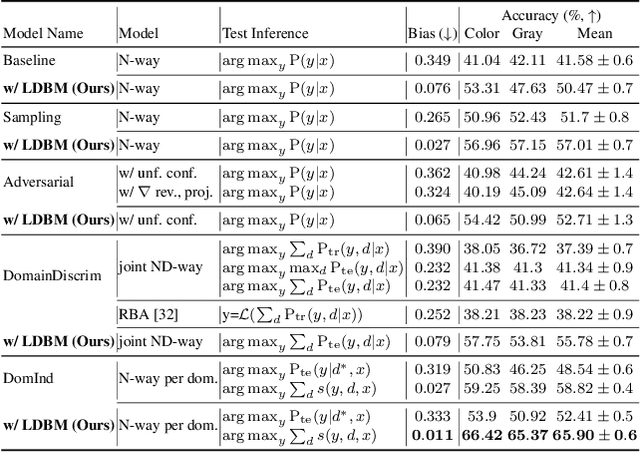
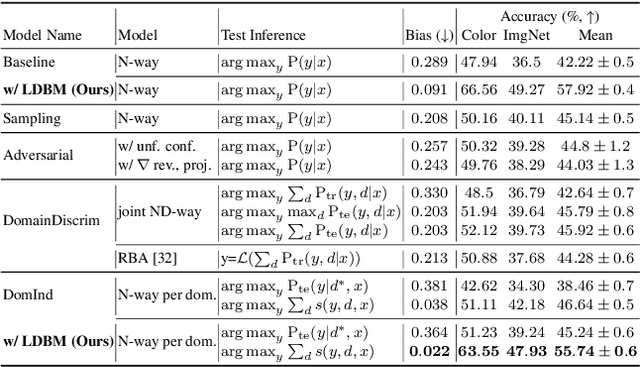
Deep learning models generally learn the biases present in the training data. Researchers have proposed several approaches to mitigate such biases and make the model fair. Bias mitigation techniques assume that a sufficiently large number of training examples are present. However, we observe that if the training data is limited, then the effectiveness of bias mitigation methods is severely degraded. In this paper, we propose a novel approach to address this problem. Specifically, we adapt self-supervision and self-distillation to reduce the impact of biases on the model in this setting. Self-supervision and self-distillation are not used for bias mitigation. However, through this work, we demonstrate for the first time that these techniques are very effective in bias mitigation. We empirically show that our approach can significantly reduce the biases learned by the model. Further, we experimentally demonstrate that our approach is complementary to other bias mitigation strategies. Our approach significantly improves their performance and further reduces the model biases in the limited data regime. Specifically, on the L-CIFAR-10S skewed dataset, our approach significantly reduces the bias score of the baseline model by 78.22% and outperforms it in terms of accuracy by a significant absolute margin of 8.89%. It also significantly reduces the bias score for the state-of-the-art domain independent bias mitigation method by 59.26% and improves its performance by a significant absolute margin of 7.08%.
Semantic Communications in Networked Systems
Mar 09, 2021
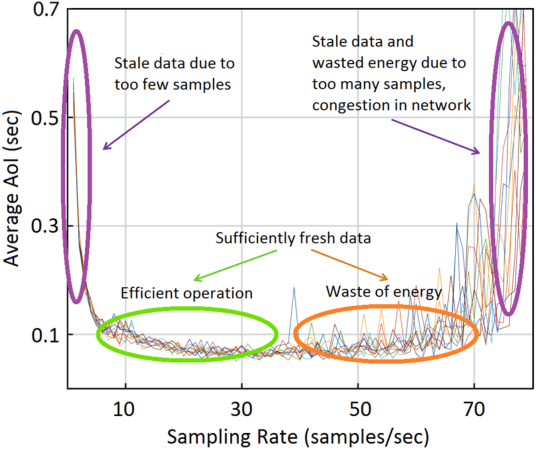
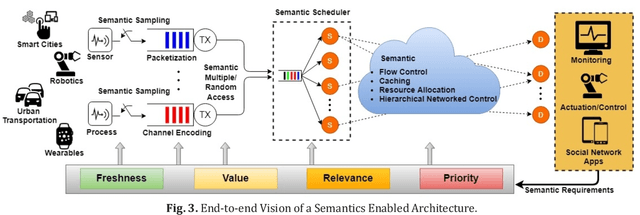
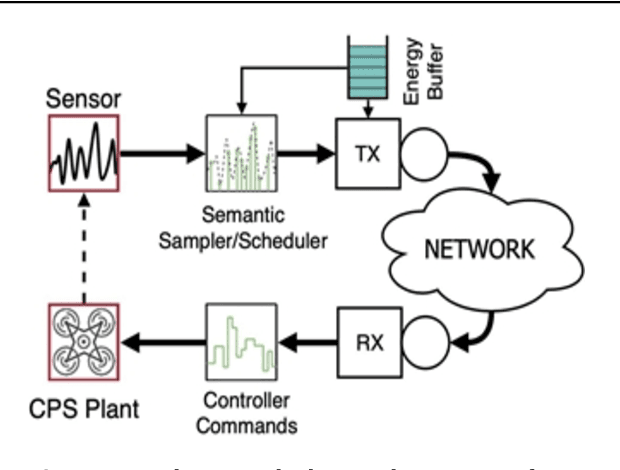
We present our vision for a departure from the established way of architecting and assessing communication networks, by incorporating the semantics of information for communications and control in networked systems. We define semantics of information, not as the meaning of the messages, but as their significance, possibly within a real time constraint, relative to the purpose of the data exchange. We argue that research efforts must focus on laying the theoretical foundations of a redesign of the entire process of information generation, transmission and usage in unison by developing: advanced semantic metrics for communications and control systems; an optimal sampling theory combining signal sparsity and semantics, for real-time prediction, reconstruction and control under communication constraints and delays; semantic compressed sensing techniques for decision making and inference directly in the compressed domain; semantic-aware data generation, channel coding, feedback, multiple and random access schemes that reduce the volume of data and the energy consumption, increasing the number of supportable devices.
Physical Interaction as Communication: Learning Robot Objectives Online from Human Corrections
Jul 06, 2021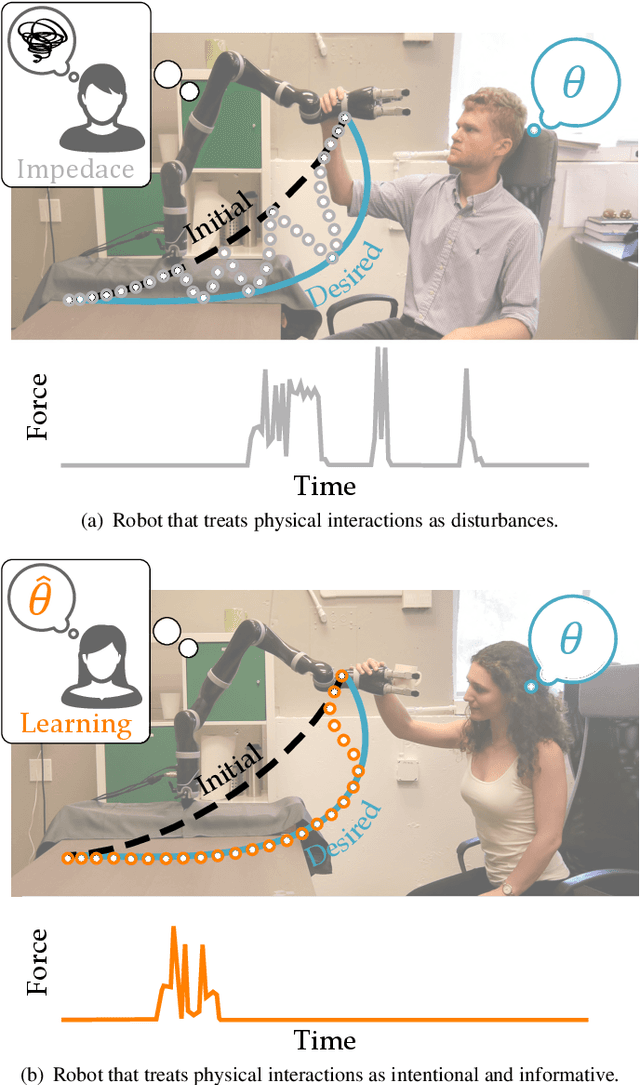
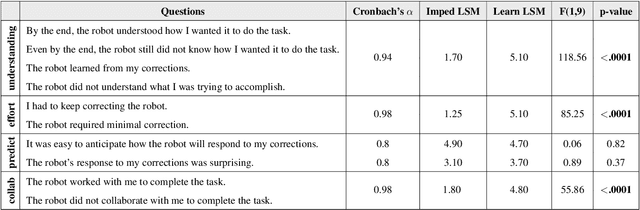
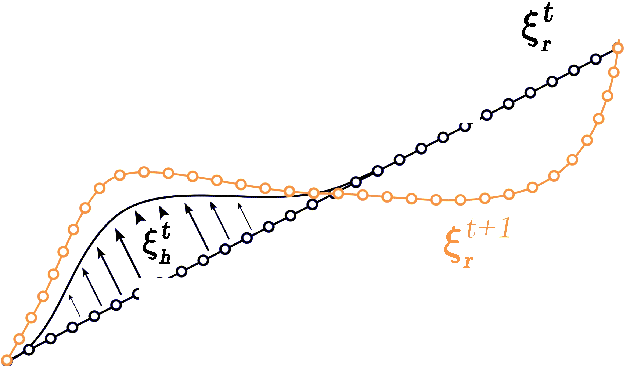
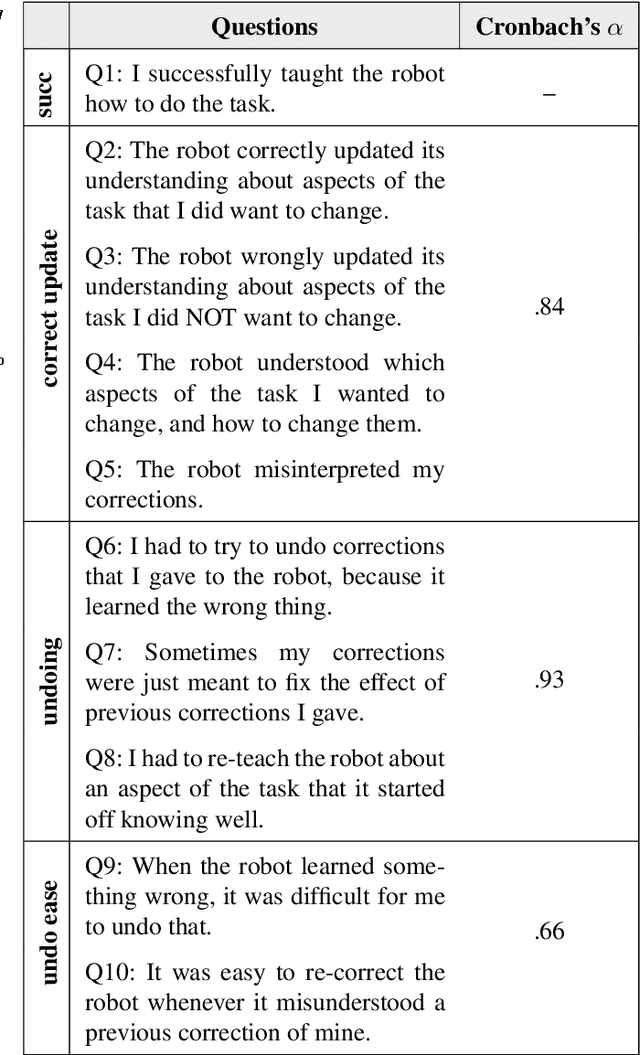
When a robot performs a task next to a human, physical interaction is inevitable: the human might push, pull, twist, or guide the robot. The state-of-the-art treats these interactions as disturbances that the robot should reject or avoid. At best, these robots respond safely while the human interacts; but after the human lets go, these robots simply return to their original behavior. We recognize that physical human-robot interaction (pHRI) is often intentional -- the human intervenes on purpose because the robot is not doing the task correctly. In this paper, we argue that when pHRI is intentional it is also informative: the robot can leverage interactions to learn how it should complete the rest of its current task even after the person lets go. We formalize pHRI as a dynamical system, where the human has in mind an objective function they want the robot to optimize, but the robot does not get direct access to the parameters of this objective -- they are internal to the human. Within our proposed framework human interactions become observations about the true objective. We introduce approximations to learn from and respond to pHRI in real-time. We recognize that not all human corrections are perfect: often users interact with the robot noisily, and so we improve the efficiency of robot learning from pHRI by reducing unintended learning. Finally, we conduct simulations and user studies on a robotic manipulator to compare our proposed approach to the state-of-the-art. Our results indicate that learning from pHRI leads to better task performance and improved human satisfaction.
Non-stationary Linear Bandits Revisited
Mar 09, 2021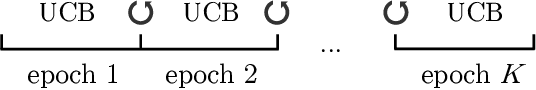
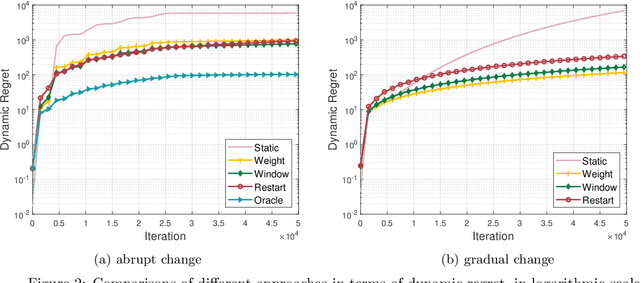
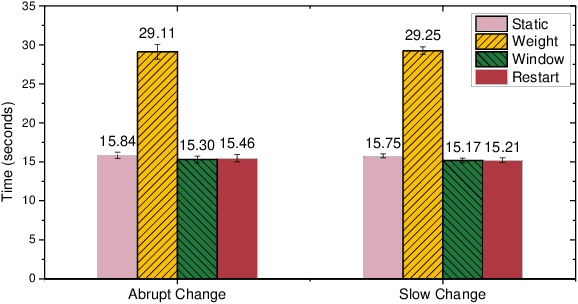
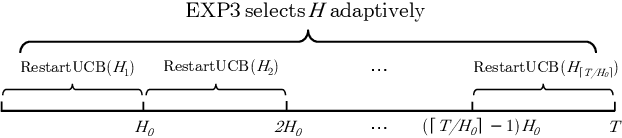
In this note, we revisit non-stationary linear bandits, a variant of stochastic linear bandits with a time-varying underlying regression parameter. Existing studies develop various algorithms and show that they enjoy an $\widetilde{O}(T^{2/3}(1+P_T)^{1/3})$ dynamic regret, where $T$ is the time horizon and $P_T$ is the path-length that measures the fluctuation of the evolving unknown parameter. However, we discover that a serious technical flaw makes the argument ungrounded. We revisit the analysis and present a fix. Without modifying original algorithms, we can prove an $\widetilde{O}(T^{3/4}(1+P_T)^{1/4})$ dynamic regret for these algorithms, slightly worse than the rate as was anticipated. We also show some impossibility results for the key quantity concerned in the regret analysis. Note that the above dynamic regret guarantee requires an oracle knowledge of the path-length $P_T$. Combining the bandit-over-bandit mechanism, we can also achieve the same guarantee in a parameter-free way.
Streaming Social Event Detection and Evolution Discovery in Heterogeneous Information Networks
Apr 02, 2021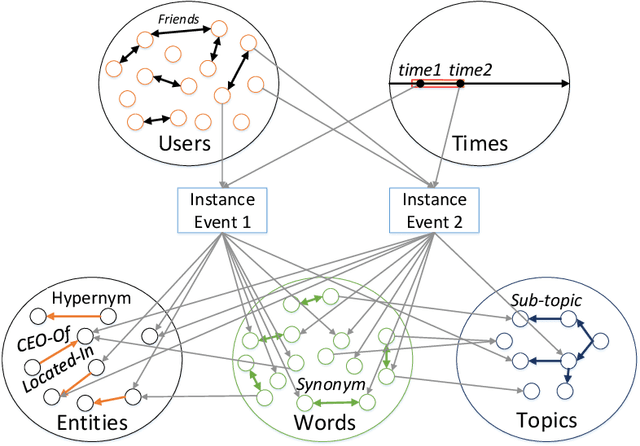
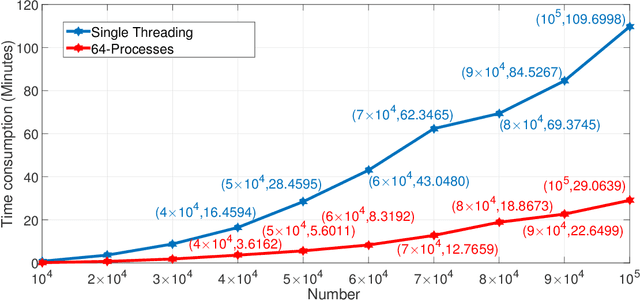
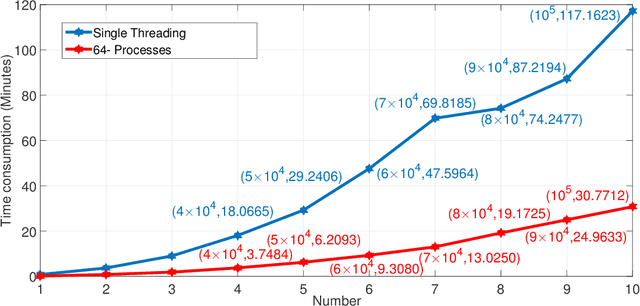
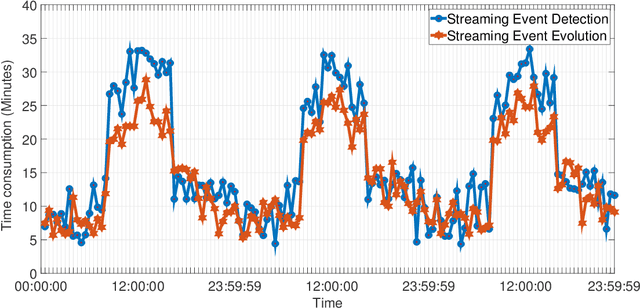
Events are happening in real-world and real-time, which can be planned and organized for occasions, such as social gatherings, festival celebrations, influential meetings or sports activities. Social media platforms generate a lot of real-time text information regarding public events with different topics. However, mining social events is challenging because events typically exhibit heterogeneous texture and metadata are often ambiguous. In this paper, we first design a novel event-based meta-schema to characterize the semantic relatedness of social events and then build an event-based heterogeneous information network (HIN) integrating information from external knowledge base. Second, we propose a novel Pairwise Popularity Graph Convolutional Network, named as PP-GCN, based on weighted meta-path instance similarity and textual semantic representation as inputs, to perform fine-grained social event categorization and learn the optimal weights of meta-paths in different tasks. Third, we propose a streaming social event detection and evolution discovery framework for HINs based on meta-path similarity search, historical information about meta-paths, and heterogeneous DBSCAN clustering method. Comprehensive experiments on real-world streaming social text data are conducted to compare various social event detection and evolution discovery algorithms. Experimental results demonstrate that our proposed framework outperforms other alternative social event detection and evolution discovery techniques.
Fair Exploration via Axiomatic Bargaining
Jun 04, 2021
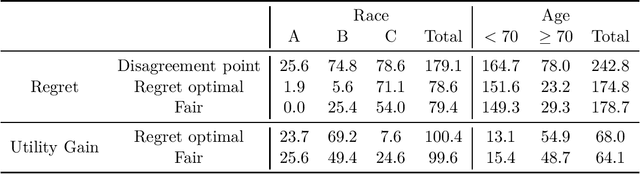
Motivated by the consideration of fairly sharing the cost of exploration between multiple groups in learning problems, we develop the Nash bargaining solution in the context of multi-armed bandits. Specifically, the 'grouped' bandit associated with any multi-armed bandit problem associates, with each time step, a single group from some finite set of groups. The utility gained by a given group under some learning policy is naturally viewed as the reduction in that group's regret relative to the regret that group would have incurred 'on its own'. We derive policies that yield the Nash bargaining solution relative to the set of incremental utilities possible under any policy. We show that on the one hand, the 'price of fairness' under such policies is limited, while on the other hand, regret optimal policies are arbitrarily unfair under generic conditions. Our theoretical development is complemented by a case study on contextual bandits for warfarin dosing where we are concerned with the cost of exploration across multiple races and age groups.
Avoiding Dense and Dynamic Obstacles in Enclosed Spaces: Application to Moving in Crowds
Jun 04, 2021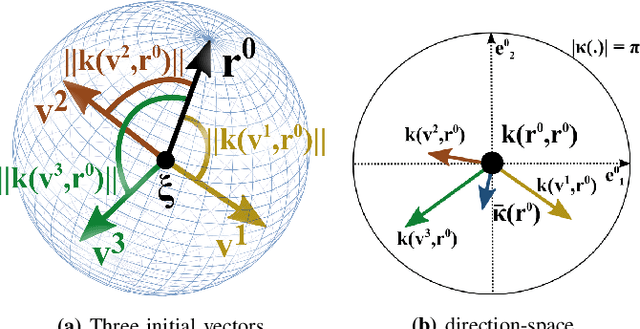
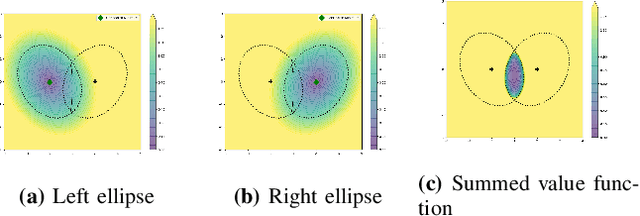

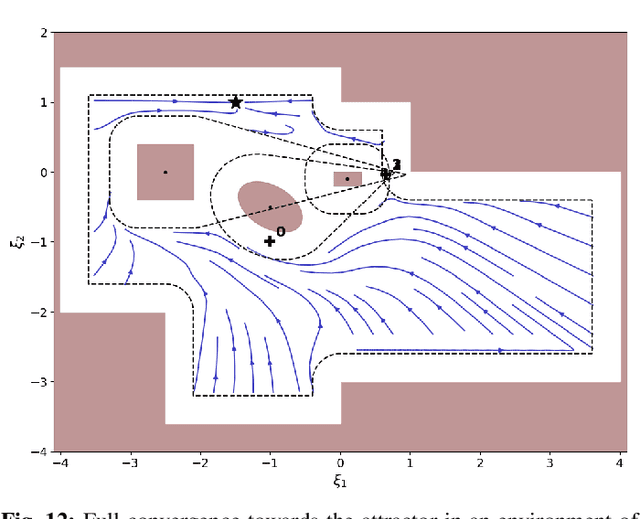
This paper presents a closed-form approach to constrain a flow within a given volume and around objects. The flow is guaranteed to converge and to stop at a single fixed point. We show that the obstacle avoidance problem can be inverted to enforce that the flow remains enclosed within a volume defined by a polygonal surface. We formally guarantee that such a flow will never contact the boundaries of the enclosing volume and obstacles, and will asymptotically converge towards an attractor. We further create smooth motion fields around obstacles with edges (e.g. tables). Both obstacles and enclosures may be time-varying, i.e. moving, expanding and shrinking. The technique enables a robot to navigate within an enclosed corridor while avoiding static and moving obstacles. It was applied on an autonomous robot (QOLO) in a static complex indoor environment, and also tested in simulations with dense crowds. The final proof of concept was performed in an outdoor environment in Lausanne. The QOLO-robot successfully traversed a marketplace in the center of town in presence of a diverse crowd with a non-uniform motion pattern.