 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reliable Prediction Errors for Deep Neural Networks Using Test-Time Dropout
Apr 12, 2019
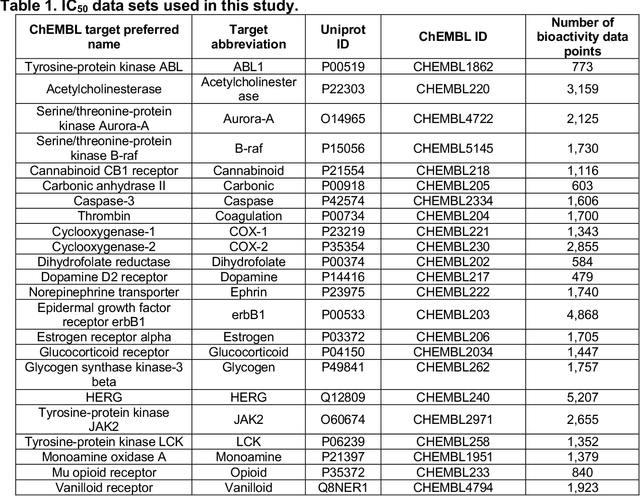
While the use of deep learning in drug discovery is gaining increasing attention, the lack of methods to compute reliable errors in prediction for Neural Networks prevents their application to guide decision making in domains where identifying unreliable predictions is essential, e.g. precision medicine. Here, we present a framework to compute reliable errors in prediction for Neural Networks using Test-Time Dropout and Conformal Prediction. Specifically, the algorithm consists of training a single Neural Network using dropout, and then applying it N times to both the validation and test sets, also employing dropout in this step. Therefore, for each instance in the validation and test sets an ensemble of predictions were generated. The residuals and absolute errors in prediction for the validation set were then used to compute prediction errors for test set instances using Conformal Prediction. We show using 24 bioactivity data sets from ChEMBL 23 that dropout Conformal Predictors are valid (i.e., the fraction of instances whose true value lies within the predicted interval strongly correlates with the confidence level) and efficient, as the predicted confidence intervals span a narrower set of values than those computed with Conformal Predictors generated using Random Forest (RF) models. Lastly, we show in retrospective virtual screening experiments that dropout and RF-based Conformal Predictors lead to comparable retrieval rates of active compounds. Overall, we propose a computationally efficient framework (as only N extra forward passes are required in addition to training a single network) to harness Test-Time Dropout and the Conformal Prediction framework, and to thereby generate reliable prediction errors for deep Neural Networks.
Deep Inertial Poser: Learning to Reconstruct Human Pose from Sparse Inertial Measurements in Real Time
Oct 10, 2018

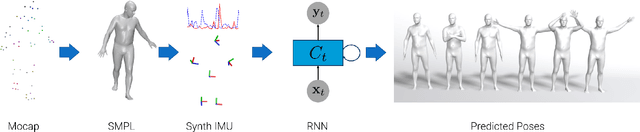
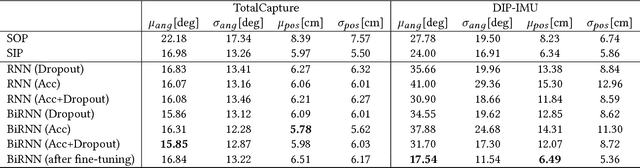
We demonstrate a novel deep neural network capable of reconstructing human full body pose in real-time from 6 Inertial Measurement Units (IMUs) worn on the user's body. In doing so, we address several difficult challenges. First, the problem is severely under-constrained as multiple pose parameters produce the same IMU orientations. Second, capturing IMU data in conjunction with ground-truth poses is expensive and difficult to do in many target application scenarios (e.g., outdoors). Third, modeling temporal dependencies through non-linear optimization has proven effective in prior work but makes real-time prediction infeasible. To address this important limitation, we learn the temporal pose priors using deep learning. To learn from sufficient data, we synthesize IMU data from motion capture datasets. A bi-directional RNN architecture leverages past and future information that is available at training time. At test time, we deploy the network in a sliding window fashion, retaining real time capabilities. To evaluate our method, we recorded DIP-IMU, a dataset consisting of $10$ subjects wearing 17 IMUs for validation in $64$ sequences with $330\,000$ time instants; this constitutes the largest IMU dataset publicly available. We quantitatively evaluate our approach on multiple datasets and show results from a real-time implementation. DIP-IMU and the code are available for research purposes.
Minibatch and Momentum Model-based Methods for Stochastic Non-smooth Non-convex Optimization
Jun 06, 2021
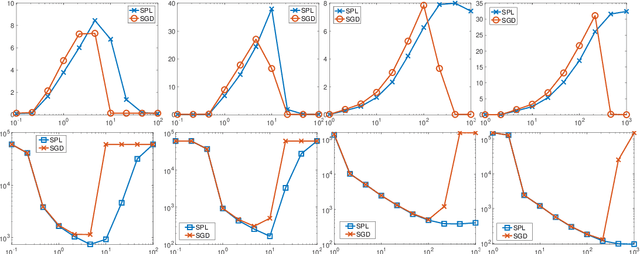

Stochastic model-based methods have received increasing attention lately due to their appealing robustness to the stepsize selection and provable efficiency guarantee for non-smooth non-convex optimization. To further improve the performance of stochastic model-based methods, we make two important extensions. First, we propose a new minibatch algorithm which takes a set of samples to approximate the model function in each iteration. For the first time, we show that stochastic algorithms achieve linear speedup over the batch size even for non-smooth and non-convex problems. To this end, we develop a novel sensitivity analysis of the proximal mapping involved in each algorithm iteration. Our analysis can be of independent interests in more general settings. Second, motivated by the success of momentum techniques for convex optimization, we propose a new stochastic extrapolated model-based method to possibly improve the convergence in the non-smooth and non-convex setting. We obtain complexity guarantees for a fairly flexible range of extrapolation term. In addition, we conduct experiments to show the empirical advantage of our proposed methods.
A linear phase evolution model for reduction of temporal unwrapping and field estimation errors in multi-echo GRE
Jun 26, 2021



This article aims at developing a model based optimization for reduction of temporal unwrapping and field estimation errors in multi-echo acquisition of Gradient Echo sequence. Using the assumption that the phase is linear along the temporal dimension, the field estimation is performed by application of unity rank approximation to the Hankel matrix formed using the complex exponential of the channel combined phase at each echo time. For the purpose of maintaining consistency with the observed complex data, the linear phase evolution model is formulated as an optimization problem with a cost function that involves a fidelity term and a unity rank prior, implemented using alternating minimization. Itoh s algorithm applied to the multi-echo phase estimated from this linear phase evolution model is able to reduce the unwrapping errors as compared to the unwrapping when directly applied to the measured phase. Secondly, the improved accuracy of the frequency fit in comparison to estimation using weighted least-square regression and penalized maximum likelihood is demonstrated using numerical simulation of field perturbation due to magnetic susceptibility effect. It is shown that the field can be estimated with 80 percent reduction in mean absolute error in comparison to wLSR and 66 percent reduction with respect to penalized maximum likelihood. The improvement in performance becomes more pronounced with increasing strengths of field gradient magnitudes and echo spacing.
Subpixel-Precise Tracking of Rigid Objects in Real-time
Jul 05, 2018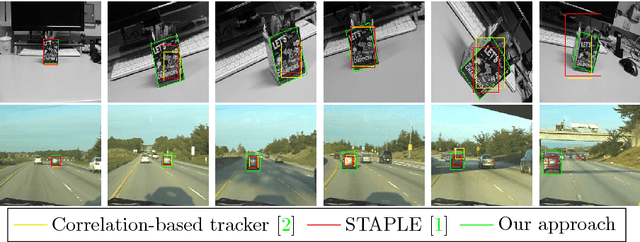

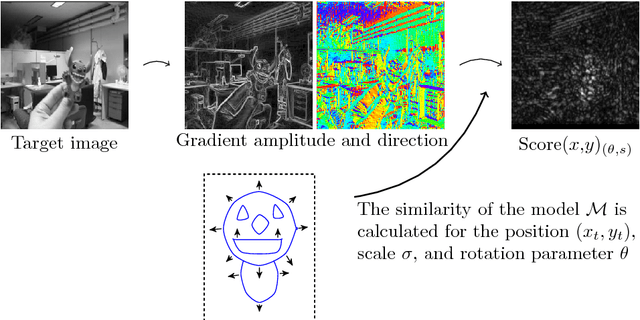
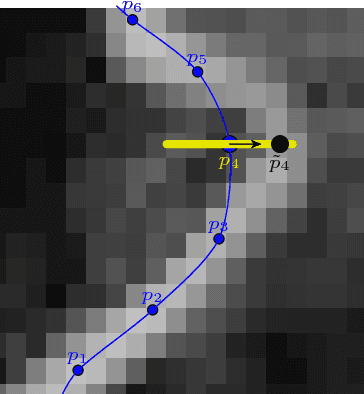
We present a novel object tracking scheme that can track rigid objects in real time. The approach uses subpixel-precise image edges to track objects with high accuracy. It can determine the object position, scale, and rotation with subpixel-precision at around 80fps. The tracker returns a reliable score for each frame and is capable of self diagnosing a tracking failure. Furthermore, the choice of the similarity measure makes the approach inherently robust against occlusion, clutter, and nonlinear illumination changes. We evaluate the method on sequences from rigid objects from the OTB-2015 and VOT2016 dataset and discuss its performance. The evaluation shows that the tracker is more accurate than state-of-the-art real-time trackers while being equally robust.
CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
Mar 27, 2021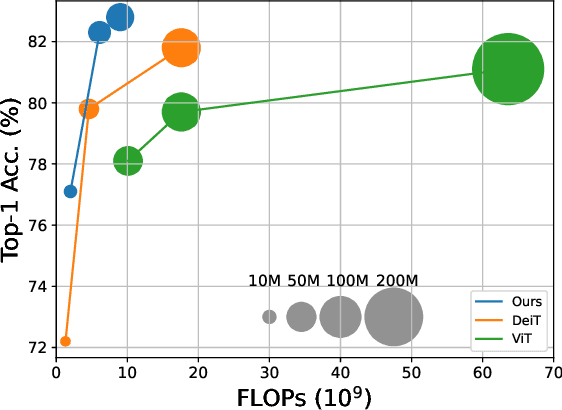
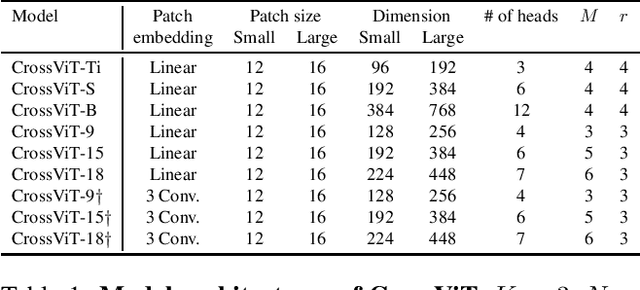
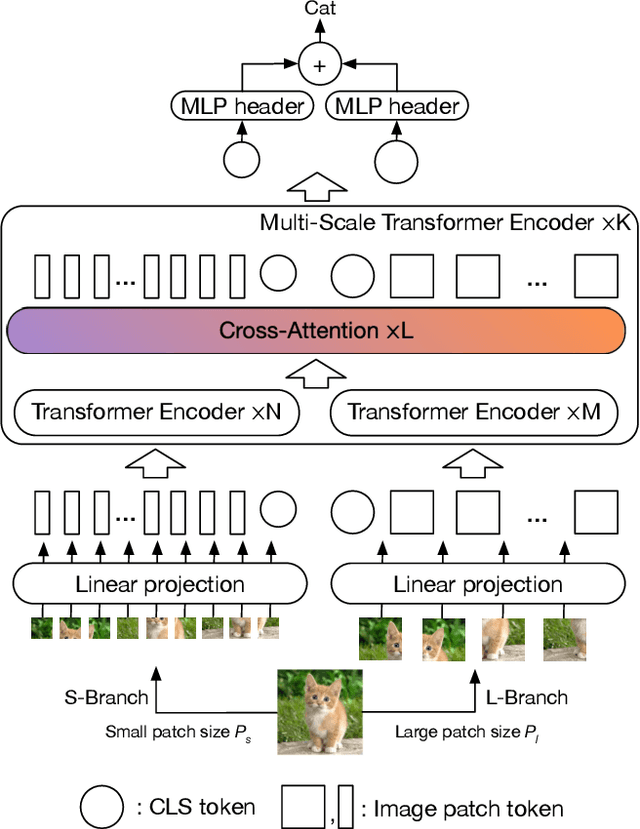
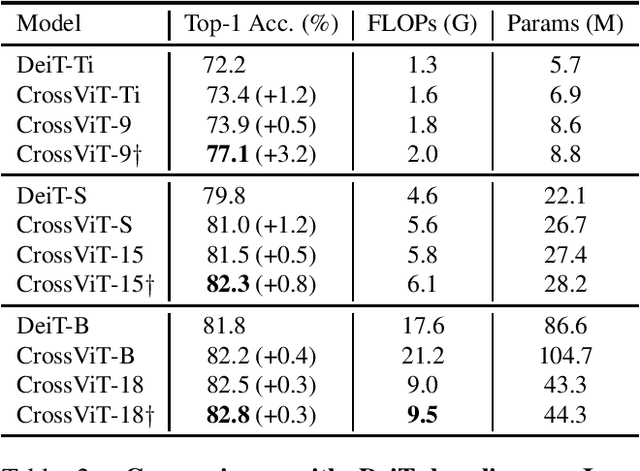
The recently developed vision transformer (ViT) has achieved promising results on image classification compared to convolutional neural networks. Inspired by this, in this paper, we study how to learn multi-scale feature representations in transformer models for image classification. To this end, we propose a dual-branch transformer to combine image patches (i.e., tokens in a transformer) of different sizes to produce stronger image features. Our approach processes small-patch and large-patch tokens with two separate branches of different computational complexity and these tokens are then fused purely by attention multiple times to complement each other. Furthermore, to reduce computation, we develop a simple yet effective token fusion module based on cross attention, which uses a single token for each branch as a query to exchange information with other branches. Our proposed cross-attention only requires linear time for both computational and memory complexity instead of quadratic time otherwise. Extensive experiments demonstrate that the proposed approach performs better than or on par with several concurrent works on vision transformer, in addition to efficient CNN models. For example, on the ImageNet1K dataset, with some architectural changes, our approach outperforms the recent DeiT by a large margin of 2\%
Prediction of Blood Lactate Values in Critically Ill Patients: A Retrospective Multi-center Cohort Study
Jul 07, 2021
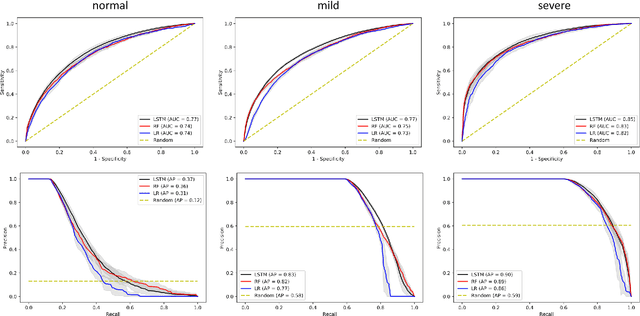
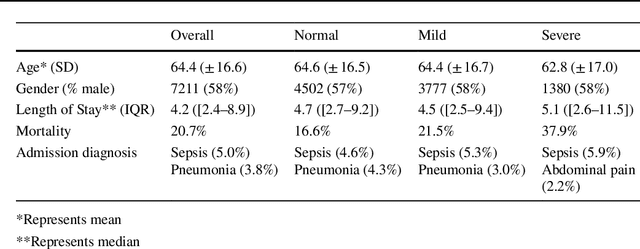
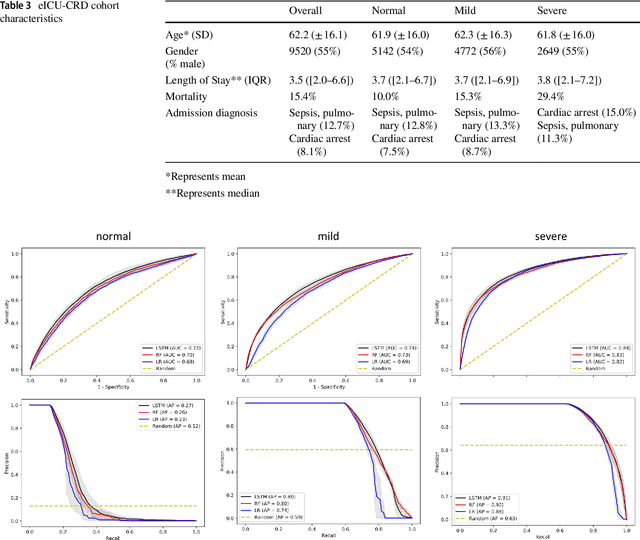
Purpose. Elevations in initially obtained serum lactate levels are strong predictors of mortality in critically ill patients. Identifying patients whose serum lactate levels are more likely to increase can alert physicians to intensify care and guide them in the frequency of tending the blood test. We investigate whether machine learning models can predict subsequent serum lactate changes. Methods. We investigated serum lactate change prediction using the MIMIC-III and eICU-CRD datasets in internal as well as external validation of the eICU cohort on the MIMIC-III cohort. Three subgroups were defined based on the initial lactate levels: i) normal group (<2 mmol/L), ii) mild group (2-4 mmol/L), and iii) severe group (>4 mmol/L). Outcomes were defined based on increase or decrease of serum lactate levels between the groups. We also performed sensitivity analysis by defining the outcome as lactate change of >10% and furthermore investigated the influence of the time interval between subsequent lactate measurements on predictive performance. Results. The LSTM models were able to predict deterioration of serum lactate values of MIMIC-III patients with an AUC of 0.77 (95% CI 0.762-0.771) for the normal group, 0.77 (95% CI 0.768-0.772) for the mild group, and 0.85 (95% CI 0.840-0.851) for the severe group, with a slightly lower performance in the external validation. Conclusion. The LSTM demonstrated good discrimination of patients who had deterioration in serum lactate levels. Clinical studies are needed to evaluate whether utilization of a clinical decision support tool based on these results could positively impact decision-making and patient outcomes.
* 15 pages, 6 Appendices
Real-Time Sleep Staging using Deep Learning on a Smartphone for a Wearable EEG
Nov 28, 2018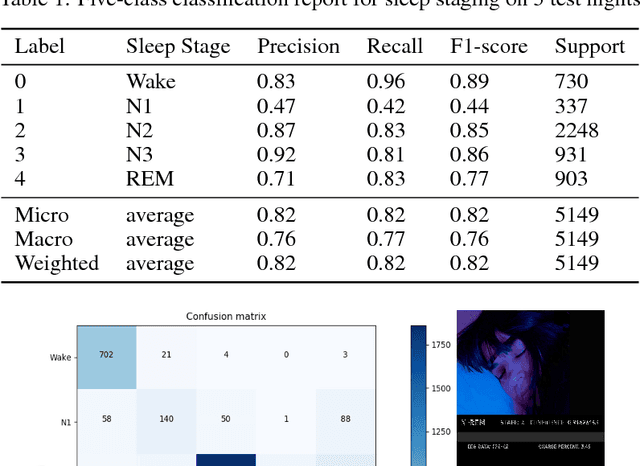

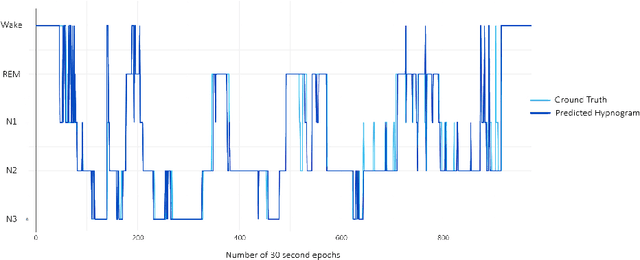
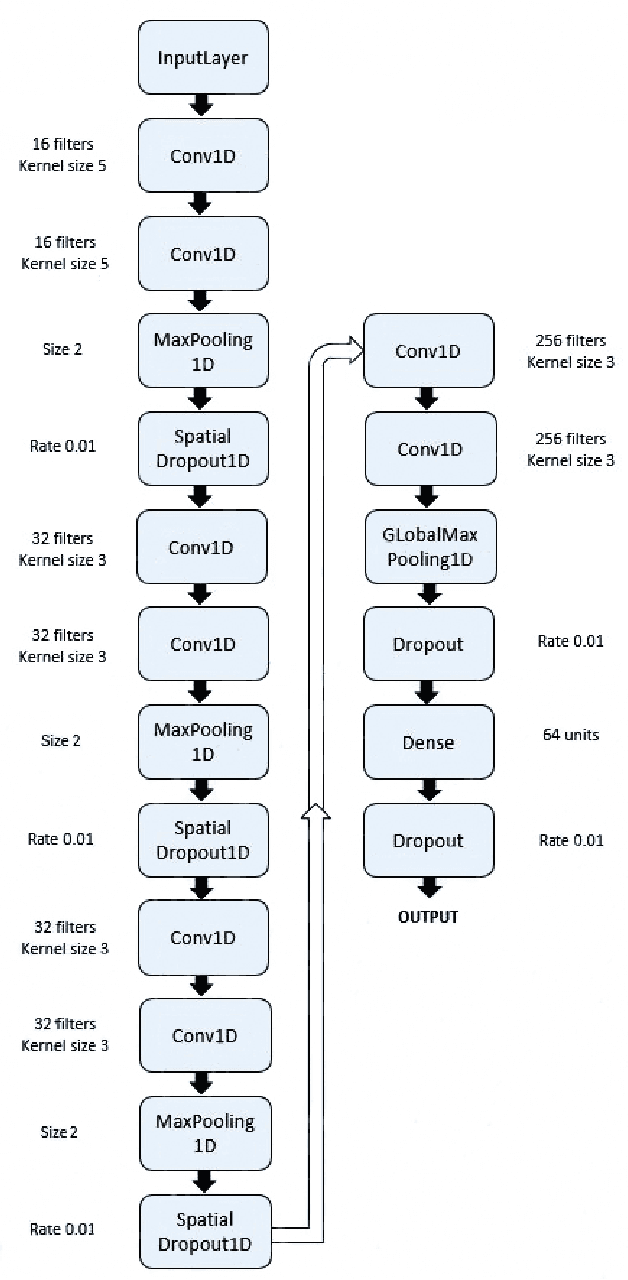
We present the first real-time sleep staging system that uses deep learning without the need for servers in a smartphone application for a wearable EEG. We employ real-time adaptation of a single channel Electroencephalography (EEG) to infer from a Time-Distributed 1-D Deep Convolutional Neural Network. Polysomnography (PSG)-the gold standard for sleep staging, requires a human scorer and is both complex and resource-intensive. Our work demonstrates an end-to-end on-smartphone pipeline that can infer sleep stages in just single 30-second epochs, with an overall accuracy of 83.5% on 20-fold cross validation for five-class classification of sleep stages using the open Sleep-EDF dataset.
Temporal Knowledge Graph Forecasting with Neural ODE
Jan 13, 2021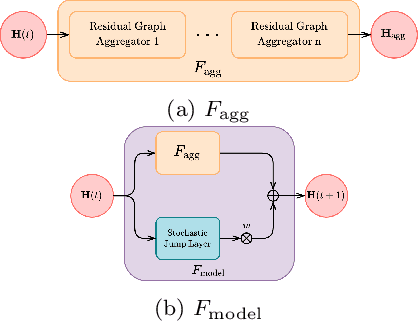

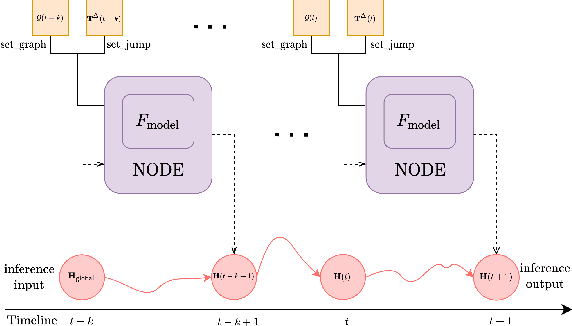

Learning node representation on dynamically-evolving, multi-relational graph data has gained great research interest. However, most of the existing models for temporal knowledge graph forecasting use Recurrent Neural Network (RNN) with discrete depth to capture temporal information, while time is a continuous variable. Inspired by Neural Ordinary Differential Equation (NODE), we extend the idea of continuum-depth models to time-evolving multi-relational graph data, and propose a novel Temporal Knowledge Graph Forecasting model with NODE. Our model captures temporal information through NODE and structural information through a Graph Neural Network (GNN). Thus, our graph ODE model achieves a continuous model in time and efficiently learns node representation for future prediction. We evaluate our model on six temporal knowledge graph datasets by performing link forecasting. Experiment results show the superiority of our model.
A Systematic Literature Review of Automated ICD Coding and Classification Systems using Discharge Summaries
Jul 12, 2021
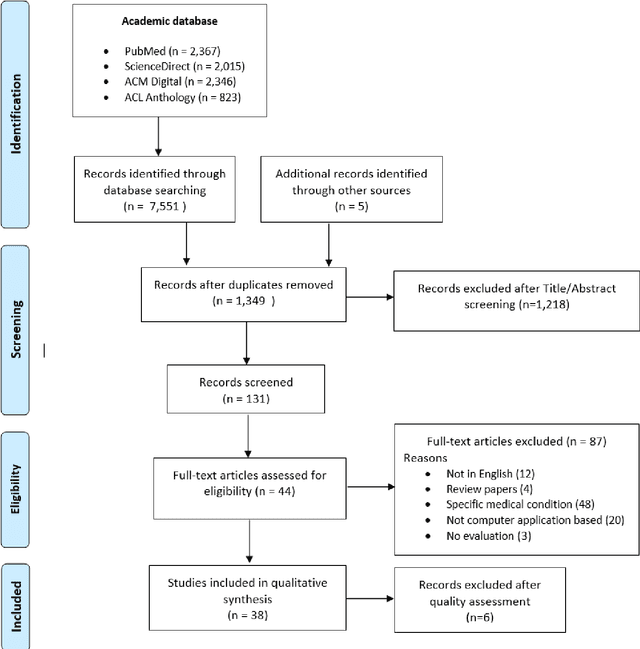
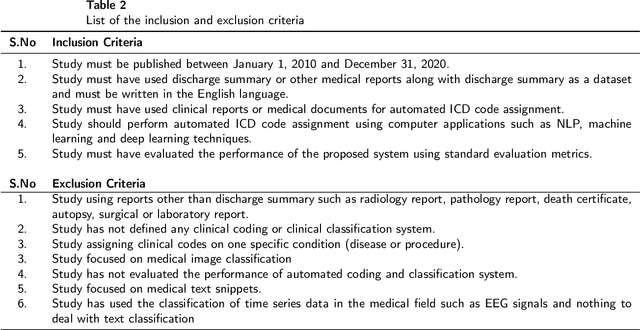

Codification of free-text clinical narratives have long been recognised to be beneficial for secondary uses such as funding, insurance claim processing and research. The current scenario of assigning codes is a manual process which is very expensive, time-consuming and error prone. In recent years, many researchers have studied the use of Natural Language Processing (NLP), related Machine Learning (ML) and Deep Learning (DL) methods and techniques to resolve the problem of manual coding of clinical narratives and to assist human coders to assign clinical codes more accurately and efficiently. This systematic literature review provides a comprehensive overview of automated clinical coding systems that utilises appropriate NLP, ML and DL methods and techniques to assign ICD codes to discharge summaries. We have followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses(PRISMA) guidelines and conducted a comprehensive search of publications from January, 2010 to December 2020 in four academic databases- PubMed, ScienceDirect, Association for Computing Machinery(ACM) Digital Library, and the Association for Computational Linguistics(ACL) Anthology. We reviewed 7,556 publications; 38 met the inclusion criteria. This review identified: datasets having discharge summaries; NLP techniques along with some other data extraction processes, different feature extraction and embedding techniques. To measure the performance of classification methods, different evaluation metrics are used. Lastly, future research directions are provided to scholars who are interested in automated ICD code assignment. Efforts are still required to improve ICD code prediction accuracy, availability of large-scale de-identified clinical corpora with the latest version of the classification system. This can be a platform to guide and share knowledge with the less experienced coders and researchers.