 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Video Class Agnostic Segmentation Benchmark for Autonomous Driving
Mar 19, 2021

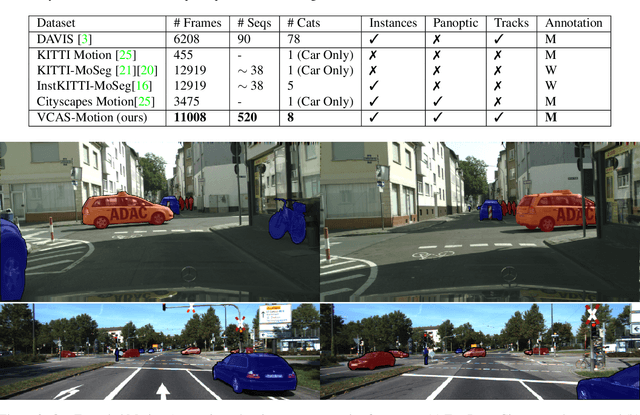

Semantic segmentation approaches are typically trained on large-scale data with a closed finite set of known classes without considering unknown objects. In certain safety-critical robotics applications, especially autonomous driving, it is important to segment all objects, including those unknown at training time. We formalize the task of video class agnostic segmentation from monocular video sequences in autonomous driving to account for unknown objects. Video class agnostic segmentation can be formulated as an open-set or a motion segmentation problem. We discuss both formulations and provide datasets and benchmark different baseline approaches for both tracks. In the motion-segmentation track we benchmark real-time joint panoptic and motion instance segmentation, and evaluate the effect of ego-flow suppression. In the open-set segmentation track we evaluate baseline methods that combine appearance, and geometry to learn prototypes per semantic class. We then compare it to a model that uses an auxiliary contrastive loss to improve the discrimination between known and unknown objects. All datasets and models are publicly released at https://msiam.github.io/vca/.
Temporal Predictive Coding For Model-Based Planning In Latent Space
Jun 14, 2021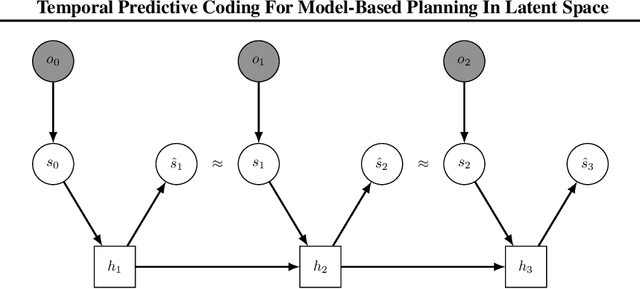
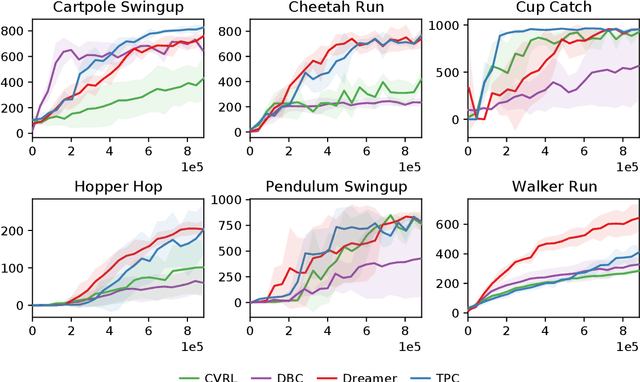
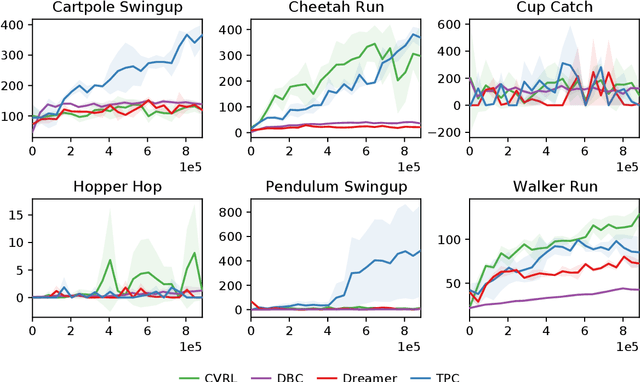
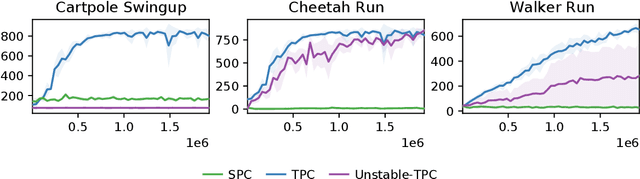
High-dimensional observations are a major challenge in the application of model-based reinforcement learning (MBRL) to real-world environments. To handle high-dimensional sensory inputs, existing approaches use representation learning to map high-dimensional observations into a lower-dimensional latent space that is more amenable to dynamics estimation and planning. In this work, we present an information-theoretic approach that employs temporal predictive coding to encode elements in the environment that can be predicted across time. Since this approach focuses on encoding temporally-predictable information, we implicitly prioritize the encoding of task-relevant components over nuisance information within the environment that are provably task-irrelevant. By learning this representation in conjunction with a recurrent state space model, we can then perform planning in latent space. We evaluate our model on a challenging modification of standard DMControl tasks where the background is replaced with natural videos that contain complex but irrelevant information to the planning task. Our experiments show that our model is superior to existing methods in the challenging complex-background setting while remaining competitive with current state-of-the-art models in the standard setting.
A Rule Mining-Based Advanced Persistent Threats Detection System
May 20, 2021
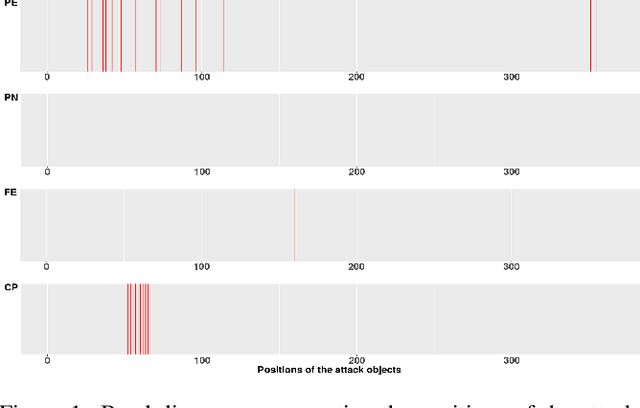

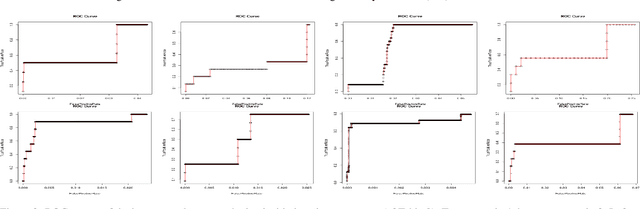
Advanced persistent threats (APT) are stealthy cyber-attacks that are aimed at stealing valuable information from target organizations and tend to extend in time. Blocking all APTs is impossible, security experts caution, hence the importance of research on early detection and damage limitation. Whole-system provenance-tracking and provenance trace mining are considered promising as they can help find causal relationships between activities and flag suspicious event sequences as they occur. We introduce an unsupervised method that exploits OS-independent features reflecting process activity to detect realistic APT-like attacks from provenance traces. Anomalous processes are ranked using both frequent and rare event associations learned from traces. Results are then presented as implications which, since interpretable, help leverage causality in explaining the detected anomalies. When evaluated on Transparent Computing program datasets (DARPA), our method outperformed competing approaches.
Relation-Based Associative Joint Location for Human Pose Estimation in Videos
Jul 08, 2021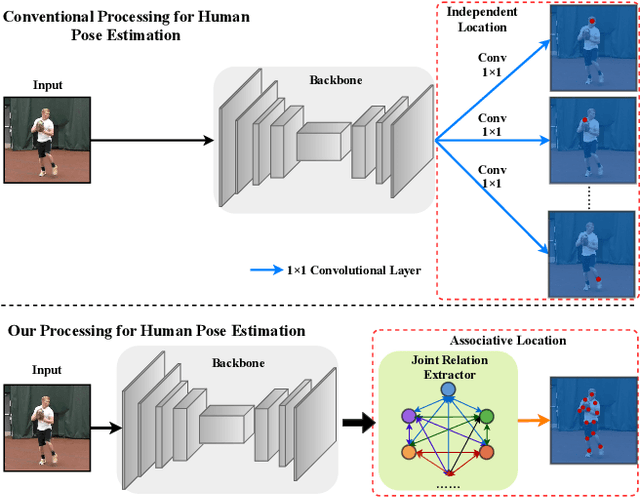
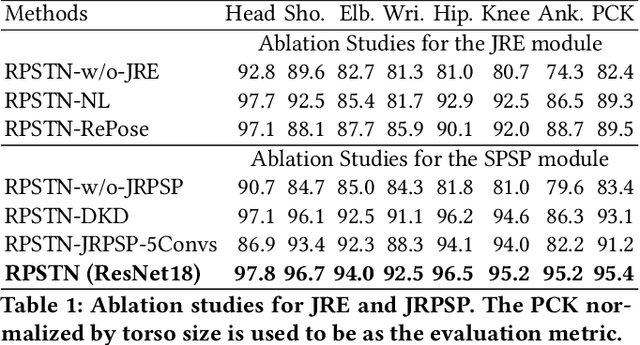
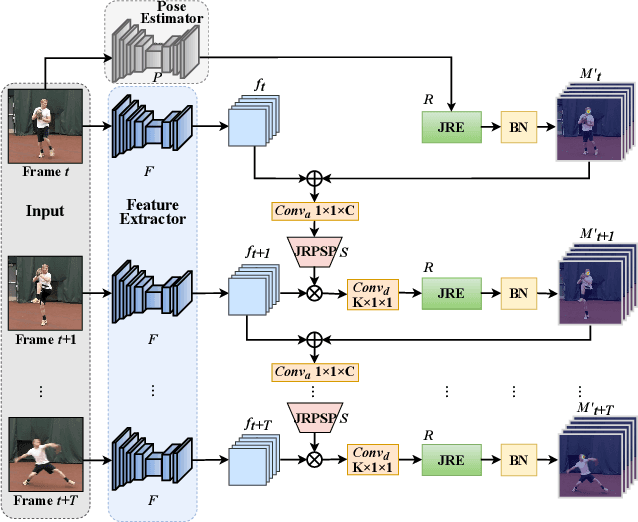
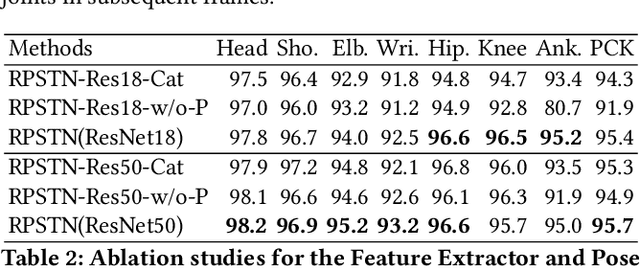
Video-based human pose estimation (HPE) is a vital yet challenging task. While deep learning methods have made significant progress for the HPE, most approaches to this task detect each joint independently, damaging the pose structural information. In this paper, unlike the prior methods, we propose a Relation-based Pose Semantics Transfer Network (RPSTN) to locate joints associatively. Specifically, we design a lightweight joint relation extractor (JRE) to model the pose structural features and associatively generate heatmaps for joints by modeling the relation between any two joints heuristically instead of building each joint heatmap independently. Actually, the proposed JRE module models the spatial configuration of human poses through the relationship between any two joints. Moreover, considering the temporal semantic continuity of videos, the pose semantic information in the current frame is beneficial for guiding the location of joints in the next frame. Therefore, we use the idea of knowledge reuse to propagate the pose semantic information between consecutive frames. In this way, the proposed RPSTN captures temporal dynamics of poses. On the one hand, the JRE module can infer invisible joints according to the relationship between the invisible joints and other visible joints in space. On the other hand, in the time, the propose model can transfer the pose semantic features from the non-occluded frame to the occluded frame to locate occluded joints. Therefore, our method is robust to the occlusion and achieves state-of-the-art results on the two challenging datasets, which demonstrates its effectiveness for video-based human pose estimation. We will release the code and models publicly.
Solving Machine Learning Problems
Jul 02, 2021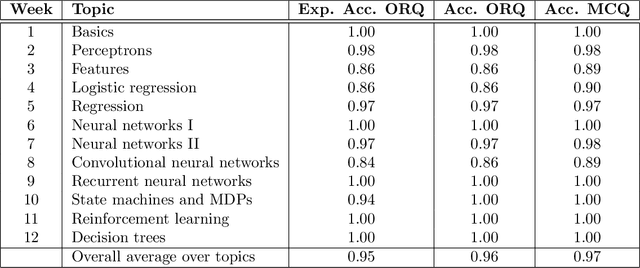
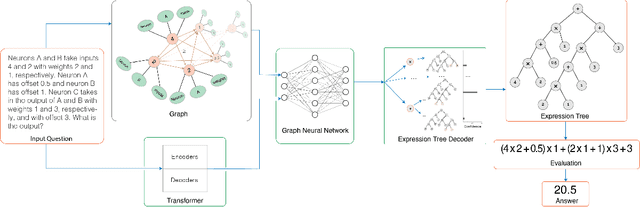
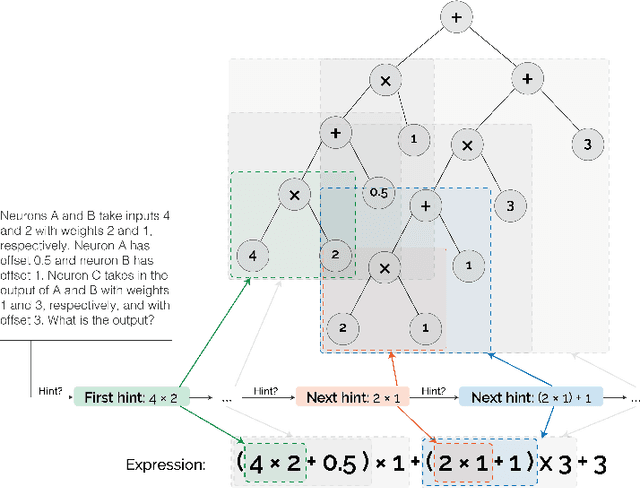
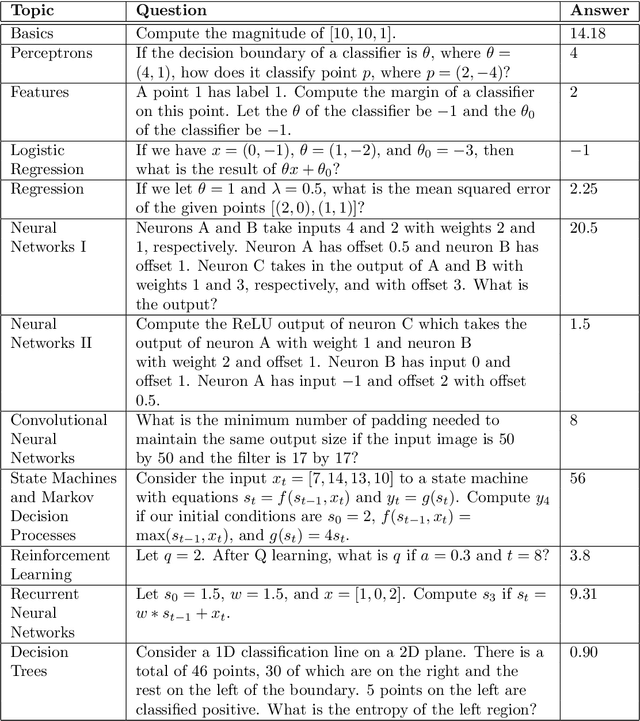
Can a machine learn Machine Learning? This work trains a machine learning model to solve machine learning problems from a University undergraduate level course. We generate a new training set of questions and answers consisting of course exercises, homework, and quiz questions from MIT's 6.036 Introduction to Machine Learning course and train a machine learning model to answer these questions. Our system demonstrates an overall accuracy of 96% for open-response questions and 97% for multiple-choice questions, compared with MIT students' average of 93%, achieving grade A performance in the course, all in real-time. Questions cover all 12 topics taught in the course, excluding coding questions or questions with images. Topics include: (i) basic machine learning principles; (ii) perceptrons; (iii) feature extraction and selection; (iv) logistic regression; (v) regression; (vi) neural networks; (vii) advanced neural networks; (viii) convolutional neural networks; (ix) recurrent neural networks; (x) state machines and MDPs; (xi) reinforcement learning; and (xii) decision trees. Our system uses Transformer models within an encoder-decoder architecture with graph and tree representations. An important aspect of our approach is a data-augmentation scheme for generating new example problems. We also train a machine learning model to generate problem hints. Thus, our system automatically generates new questions across topics, answers both open-response questions and multiple-choice questions, classifies problems, and generates problem hints, pushing the envelope of AI for STEM education.
CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
Mar 27, 2021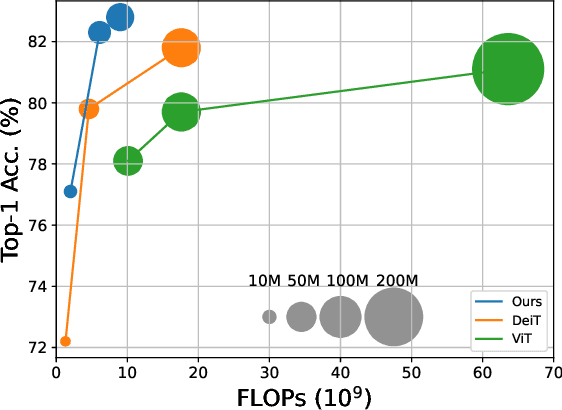
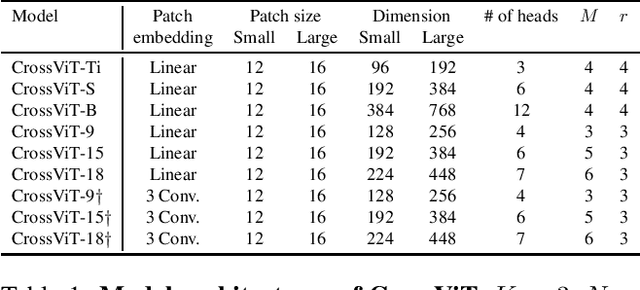
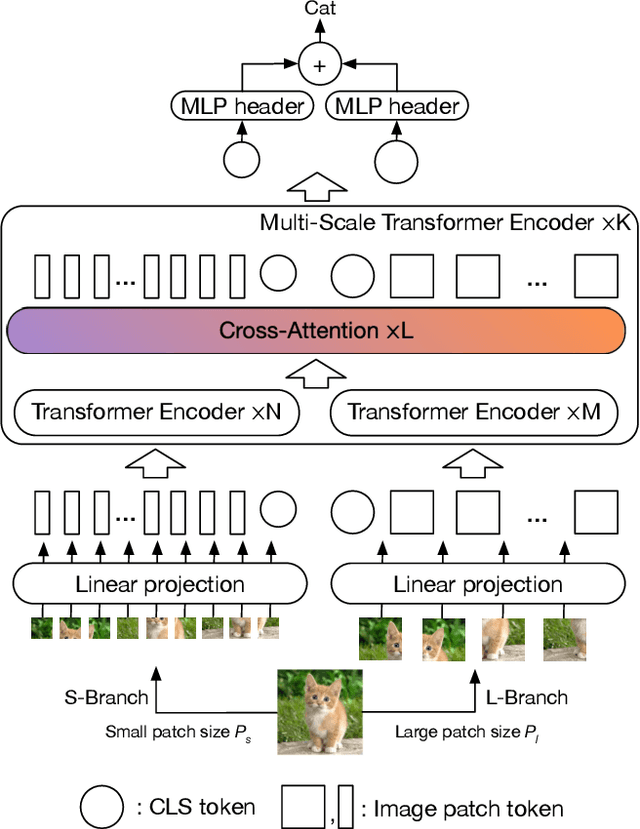
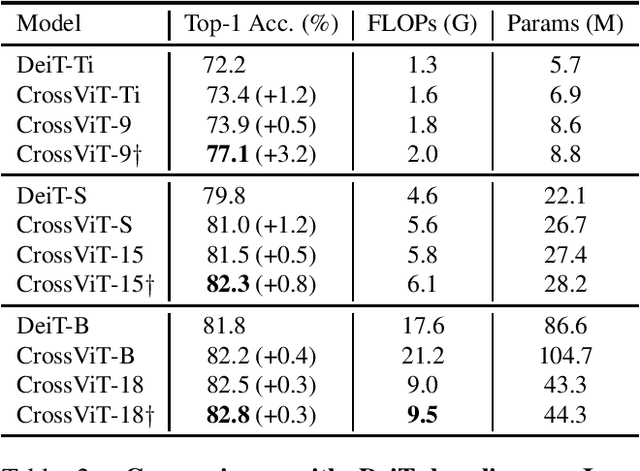
The recently developed vision transformer (ViT) has achieved promising results on image classification compared to convolutional neural networks. Inspired by this, in this paper, we study how to learn multi-scale feature representations in transformer models for image classification. To this end, we propose a dual-branch transformer to combine image patches (i.e., tokens in a transformer) of different sizes to produce stronger image features. Our approach processes small-patch and large-patch tokens with two separate branches of different computational complexity and these tokens are then fused purely by attention multiple times to complement each other. Furthermore, to reduce computation, we develop a simple yet effective token fusion module based on cross attention, which uses a single token for each branch as a query to exchange information with other branches. Our proposed cross-attention only requires linear time for both computational and memory complexity instead of quadratic time otherwise. Extensive experiments demonstrate that the proposed approach performs better than or on par with several concurrent works on vision transformer, in addition to efficient CNN models. For example, on the ImageNet1K dataset, with some architectural changes, our approach outperforms the recent DeiT by a large margin of 2\%
On training targets for noise-robust voice activity detection
Feb 15, 2021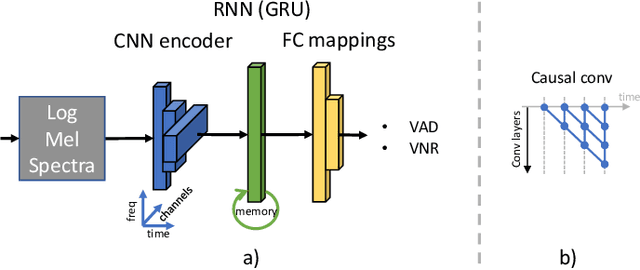
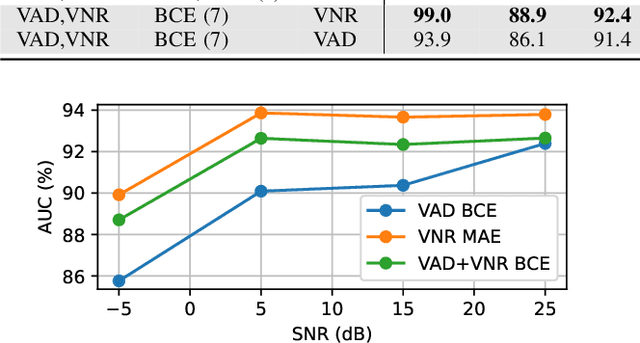
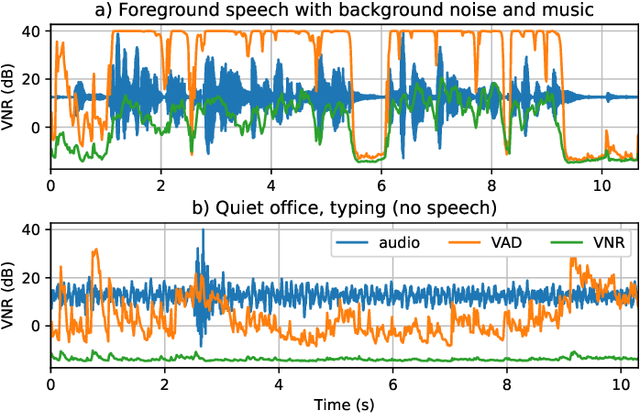

The task of voice activity detection (VAD) is an often required module in various speech processing, analysis and classification tasks. While state-of-the-art neural network based VADs can achieve great results, they often exceed computational budgets and real-time operating requirements. In this work, we propose a computationally efficient real-time VAD network that achieves state-of-the-art results on several public real recording datasets. We investigate different training targets for the VAD and show that using the segmental voice-to-noise ratio (VNR) is a better and more noise-robust training target than the clean speech level based VAD. We also show that multi-target training improves the performance further.
SHAFF: Fast and consistent SHApley eFfect estimates via random Forests
May 25, 2021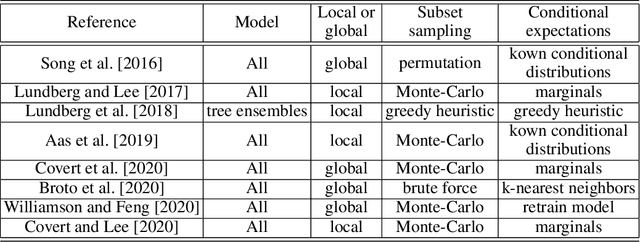
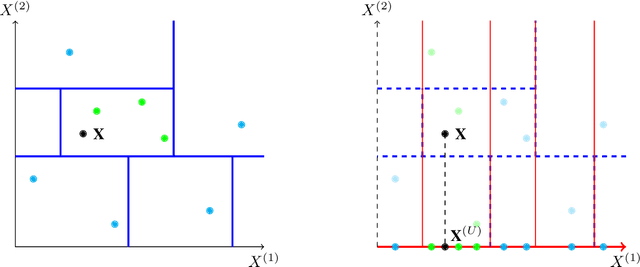
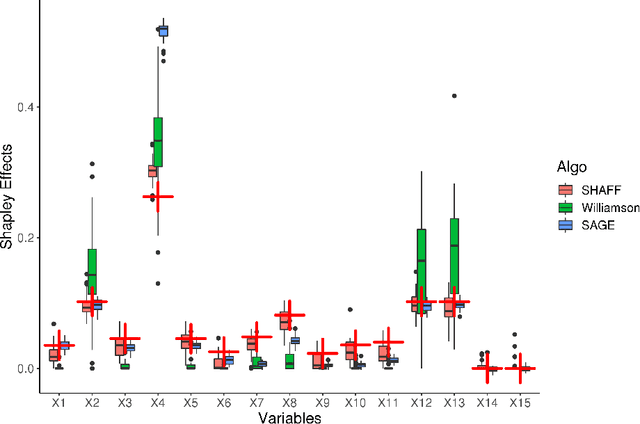
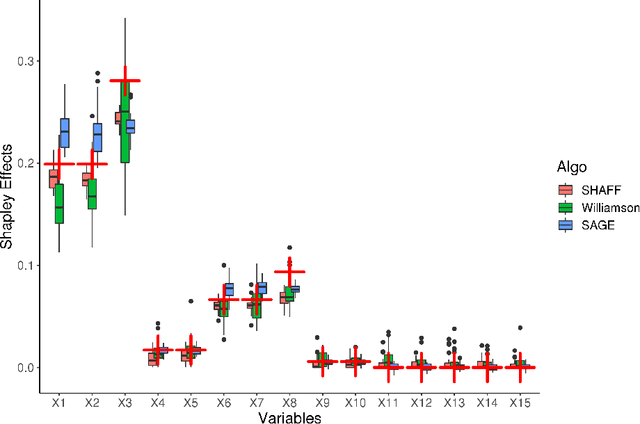
Interpretability of learning algorithms is crucial for applications involving critical decisions, and variable importance is one of the main interpretation tools. Shapley effects are now widely used to interpret both tree ensembles and neural networks, as they can efficiently handle dependence and interactions in the data, as opposed to most other variable importance measures. However, estimating Shapley effects is a challenging task, because of the computational complexity and the conditional expectation estimates. Accordingly, existing Shapley algorithms have flaws: a costly running time, or a bias when input variables are dependent. Therefore, we introduce SHAFF, SHApley eFfects via random Forests, a fast and accurate Shapley effect estimate, even when input variables are dependent. We show SHAFF efficiency through both a theoretical analysis of its consistency, and the practical performance improvements over competitors with extensive experiments. An implementation of SHAFF in C++ and R is available online.
On the Evaluation of Commit Message Generation Models: An Experimental Study
Jul 13, 2021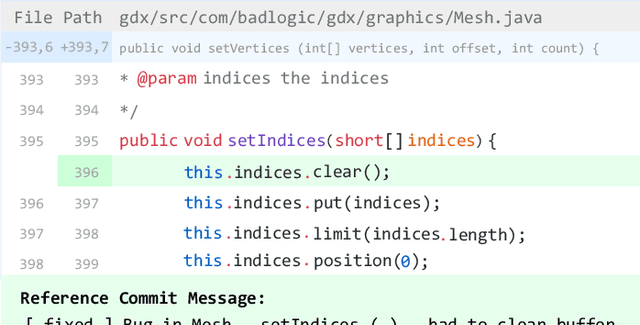
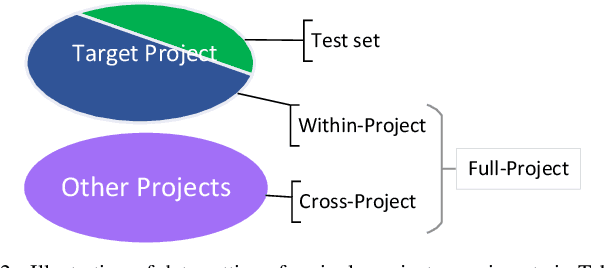
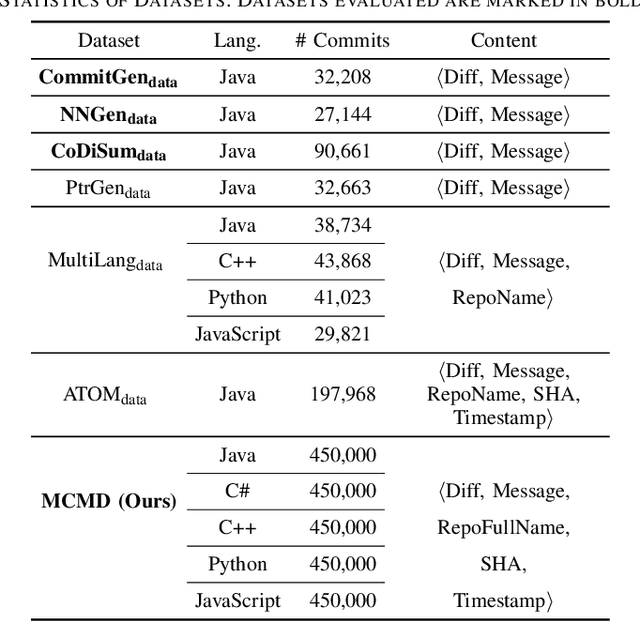
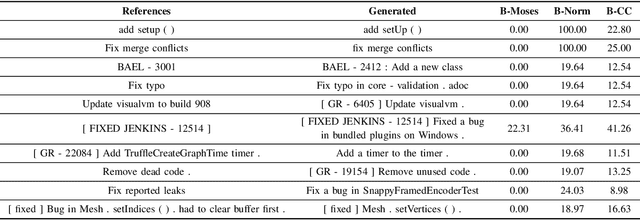
Commit messages are natural language descriptions of code changes, which are important for program understanding and maintenance. However, writing commit messages manually is time-consuming and laborious, especially when the code is updated frequently. Various approaches utilizing generation or retrieval techniques have been proposed to automatically generate commit messages. To achieve a better understanding of how the existing approaches perform in solving this problem, this paper conducts a systematic and in-depth analysis of the state-of-the-art models and datasets. We find that: (1) Different variants of the BLEU metric are used in previous works, which affects the evaluation and understanding of existing methods. (2) Most existing datasets are crawled only from Java repositories while repositories in other programming languages are not sufficiently explored. (3) Dataset splitting strategies can influence the performance of existing models by a large margin. Some models show better performance when the datasets are split by commit, while other models perform better when the datasets are split by timestamp or by project. Based on our findings, we conduct a human evaluation and find the BLEU metric that best correlates with the human scores for the task. We also collect a large-scale, information-rich, and multi-language commit message dataset MCMD and evaluate existing models on this dataset. Furthermore, we conduct extensive experiments under different dataset splitting strategies and suggest the suitable models under different scenarios. Based on the experimental results and findings, we provide feasible suggestions for comprehensively evaluating commit message generation models and discuss possible future research directions. We believe this work can help practitioners and researchers better evaluate and select models for automatic commit message generation.
Online Cognitive Data Sensing and Processing Optimization in Energy-harvesting Edge Computing Systems
Jun 27, 2021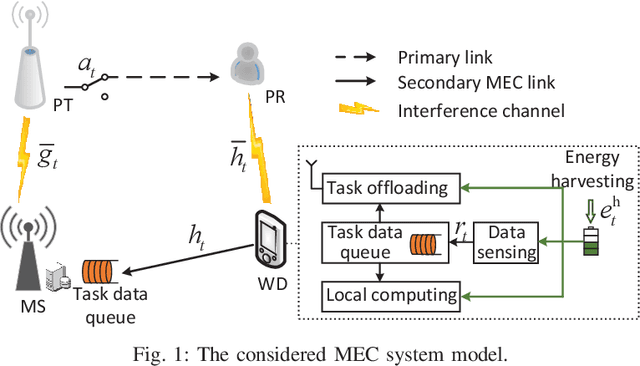
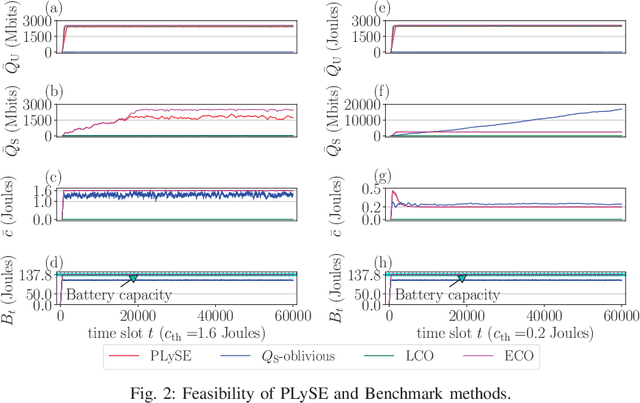
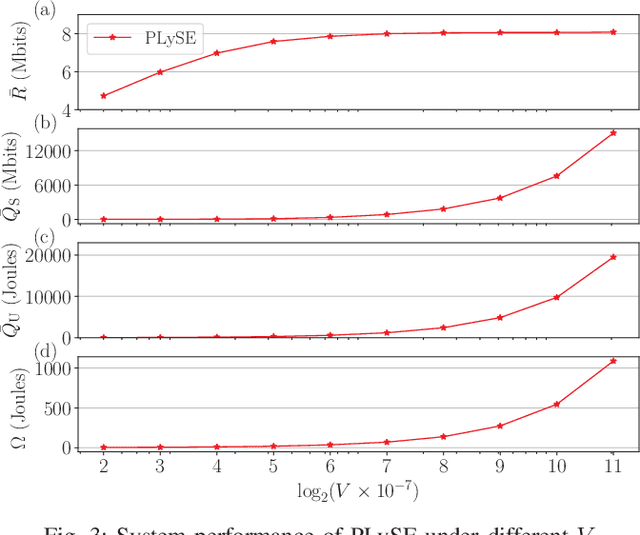
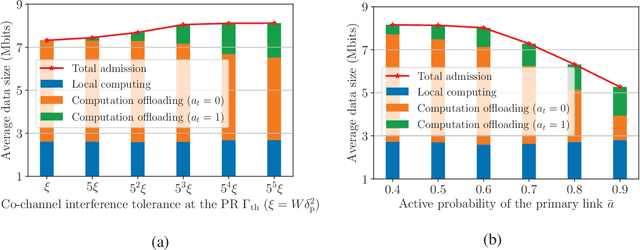
Mobile edge computing (MEC) has recently become a prevailing technique to alleviate the intensive computation burden in Internet of Things (IoT) networks. However, the limited device battery capacity and stringent spectrum resource significantly restrict the data processing performance of MEC-enabled IoT networks. To address the two performance limitations, we consider in this paper an MEC-enabled IoT system with an energy harvesting (EH) wireless device (WD) which opportunistically accesses the licensed spectrum of an overlaid primary communication link for task offloading. We aim to maximize the long-term average sensing rate of the WD subject to quality of service (QoS) requirement of primary link, average power constraint of MEC server (MS) and data queue stability of both MS and WD. We formulate the problem as a multi-stage stochastic optimization and propose an online algorithm named PLySE that applies the perturbed Lyapunov optimization technique to decompose the original problem into per-slot deterministic optimization problems. For each per-slot problem, we derive the closed-form optimal solution of data sensing and processing control to facilitate low-complexity real-time implementation. Interestingly, our analysis finds that the optimal solution exhibits an threshold-based structure. Simulation results collaborate with our analysis and demonstrate more than 46.7\% data sensing rate improvement of the proposed PLySE over representative benchmark methods.