 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Virtual Sensor for Real-Time Bearing Load Prediction Using Heterogeneous Temporal Graph Neural Networks
Apr 02, 2024
Accurate bearing load monitoring is essential for their Prognostics and Health Management (PHM), enabling damage assessment, wear prediction, and proactive maintenance. While bearing sensors are typically placed on the bearing housing, direct load monitoring requires sensors inside the bearing itself. Recently introduced sensor rollers enable direct bearing load monitoring but are constrained by their battery life. Data-driven virtual sensors can learn from sensor roller data collected during a batterys lifetime to map operating conditions to bearing loads. Although spatially distributed bearing sensors offer insights into load distribution (e.g., correlating temperature with load), traditional machine learning algorithms struggle to fully exploit these spatial-temporal dependencies. To address this gap, we introduce a graph-based virtual sensor that leverages Graph Neural Networks (GNNs) to analyze spatial-temporal dependencies among sensor signals, mapping existing measurements (temperature, vibration) to bearing loads. Since temperature and vibration signals exhibit vastly different dynamics, we propose Heterogeneous Temporal Graph Neural Networks (HTGNN), which explicitly models these signal types and their interactions for effective load prediction. Our results demonstrate that HTGNN outperforms Convolutional Neural Networks (CNNs), which struggle to capture both spatial and heterogeneous signal characteristics. These findings highlight the importance of capturing the complex spatial interactions between temperature, vibration, and load.
Inferring the Phylogeny of Large Language Models and Predicting their Performances in Benchmarks
Apr 06, 2024This paper introduces PhyloLM, a method applying phylogenetic algorithms to Large Language Models to explore their finetuning relationships, and predict their performance characteristics. By leveraging the phylogenetic distance metric, we construct dendrograms, which satisfactorily capture distinct LLM families (across a set of 77 open-source and 22 closed models). Furthermore, phylogenetic distance predicts performances in benchmarks (we test MMLU and ARC), thus enabling a time and cost-effective estimation of LLM capabilities. The approach translates genetic concepts to machine learning, offering tools to infer LLM development, relationships, and capabilities, even in the absence of transparent training information.
Allowing humans to interactively guide machines where to look does not always improve a human-AI team's classification accuracy
Apr 08, 2024Via thousands of papers in Explainable AI (XAI), attention maps \cite{vaswani2017attention} and feature attribution maps \cite{bansal2020sam} have been established as a common means for explaining the input features that are important to AI's decisions. It is an interesting but unexplored question whether allowing users to edit the importance scores of input features at test time would improve the human-AI team's accuracy on downstream tasks. In this paper, we address this question by taking CHM-Corr, a state-of-the-art, ante-hoc explanation method \cite{taesiri2022visual} that first predicts patch-wise correspondences between the input and the training-set images, and then uses them to make classification decisions. We build an interactive interface on top of CHM-Corr, enabling users to directly edit the initial feature attribution map provided by CHM-Corr. Via our CHM-Corr++ interface, users gain insights into if, when, and how the model changes its outputs, enhancing understanding beyond static explanations. Our user study with 18 machine learning researchers who performed $\sim$1,400 decisions shows that our interactive approach does not improve user accuracy on CUB-200 bird image classification over static explanations. This challenges the belief that interactivity inherently boosts XAI effectiveness~\cite{sokol2020one,sun2022exploring,shen2024towards,singh2024rethinking,mindlin2024beyond,lakkaraju2022rethinking,cheng2019explaining,liu2021understanding} and raises needs for future research. Our work contributes to the field by open-sourcing an interactive tool for manipulating model attention, and it lays the groundwork for future research to enable effective human-AI interaction in computer vision. We release code and data on \href{https://anonymous.4open.science/r/CHMCorrPlusPlus/}{github}. Our interface are available \href{http://137.184.82.109:7080/}{here}.
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
Apr 08, 2024Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
Ethos and Pathos in Online Group Discussions: Corpora for Polarisation Issues in Social Media
Apr 07, 2024Growing polarisation in society caught the attention of the scientific community as well as news media, which devote special issues to this phenomenon. At the same time, digitalisation of social interactions requires to revise concepts from social science regarding establishment of trust, which is a key feature of all human interactions, and group polarisation, as well as new computational tools to process large quantities of available data. Existing methods seem insufficient to tackle the problem fully, thus, we propose to approach the problem by investigating rhetorical strategies employed by individuals in polarising discussions online. To this end, we develop multi-topic and multi-platform corpora with manual annotation of appeals to ethos and pathos, two modes of persuasion in Aristotelian rhetoric. It can be employed for training language models to advance the study of communication strategies online on a large scale. With the use of computational methods, our corpora allows an investigation of recurring patterns in polarising exchanges across topics of discussion and media platforms, and conduct both quantitative and qualitative analyses of language structures leading to and engaged in polarisation.
AlphaCrystal-II: Distance matrix based crystal structure prediction using deep learning
Apr 07, 2024Computational prediction of stable crystal structures has a profound impact on the large-scale discovery of novel functional materials. However, predicting the crystal structure solely from a material's composition or formula is a promising yet challenging task, as traditional ab initio crystal structure prediction (CSP) methods rely on time-consuming global searches and first-principles free energy calculations. Inspired by the recent success of deep learning approaches in protein structure prediction, which utilize pairwise amino acid interactions to describe 3D structures, we present AlphaCrystal-II, a novel knowledge-based solution that exploits the abundant inter-atomic interaction patterns found in existing known crystal structures. AlphaCrystal-II predicts the atomic distance matrix of a target crystal material and employs this matrix to reconstruct its 3D crystal structure. By leveraging the wealth of inter-atomic relationships of known crystal structures, our approach demonstrates remarkable effectiveness and reliability in structure prediction through comprehensive experiments. This work highlights the potential of data-driven methods in accelerating the discovery and design of new materials with tailored properties.
Adaptive Anchor Pairs Selection in a TDOA-based System Through Robot Localization Error Minimization
Apr 07, 2024The following paper presents an adaptive anchor pairs selection method for ultra-wideband (UWB) Time Difference of Arrival (TDOA) based positioning systems. The method divides the area covered by the system into several zones and assigns them anchor pair sets. The pair sets are determined during calibration based on localization root mean square error (RMSE). The calibration assumes driving a mobile platform equipped with a LiDAR sensor and a UWB tag through the specified zones. The robot is localized separately based on a large set of different TDOA pairs and using a LiDAR, which acts as the reference. For each zone, the TDOA pairs set for which the registered RMSE is lowest is selected and used for localization in the routine system work. The proposed method has been tested with simulations and experiments. The results for both simulated static and experimental dynamic scenarios have proven that the adaptive selection of the anchor nodes leads to an increase in localization accuracy. In the experiment, the median trajectory error for a moving person localization was at a level of 25 cm.
Bayesian Additive Regression Networks
Apr 05, 2024We apply Bayesian Additive Regression Tree (BART) principles to training an ensemble of small neural networks for regression tasks. Using Markov Chain Monte Carlo, we sample from the posterior distribution of neural networks that have a single hidden layer. To create an ensemble of these, we apply Gibbs sampling to update each network against the residual target value (i.e. subtracting the effect of the other networks). We demonstrate the effectiveness of this technique on several benchmark regression problems, comparing it to equivalent shallow neural networks, BART, and ordinary least squares. Our Bayesian Additive Regression Networks (BARN) provide more consistent and often more accurate results. On test data benchmarks, BARN averaged between 5 to 20 percent lower root mean square error. This error performance does come at the cost, however, of greater computation time. BARN sometimes takes on the order of a minute where competing methods take a second or less. But, BARN without cross-validated hyperparameter tuning takes about the same amount of computation time as tuned other methods. Yet BARN is still typically more accurate.
Hierarchical Neural Additive Models for Interpretable Demand Forecasts
Apr 05, 2024Demand forecasts are the crucial basis for numerous business decisions, ranging from inventory management to strategic facility planning. While machine learning (ML) approaches offer accuracy gains, their interpretability and acceptance are notoriously lacking. Addressing this dilemma, we introduce Hierarchical Neural Additive Models for time series (HNAM). HNAM expands upon Neural Additive Models (NAM) by introducing a time-series specific additive model with a level and interacting covariate components. Covariate interactions are only allowed according to a user-specified interaction hierarchy. For example, weekday effects may be estimated independently of other covariates, whereas a holiday effect may depend on the weekday and an additional promotion may depend on both former covariates that are lower in the interaction hierarchy. Thereby, HNAM yields an intuitive forecasting interface in which analysts can observe the contribution for each known covariate. We evaluate the proposed approach and benchmark its performance against other state-of-the-art machine learning and statistical models extensively on real-world retail data. The results reveal that HNAM offers competitive prediction performance whilst providing plausible explanations.
Advancing Time Series Classification with Multimodal Language Modeling
Mar 19, 2024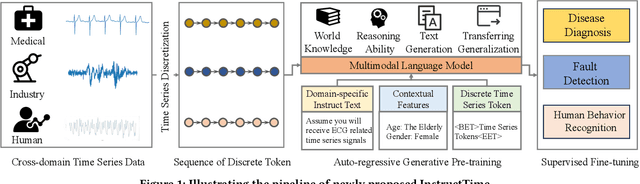
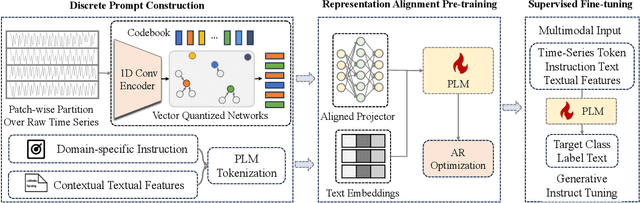
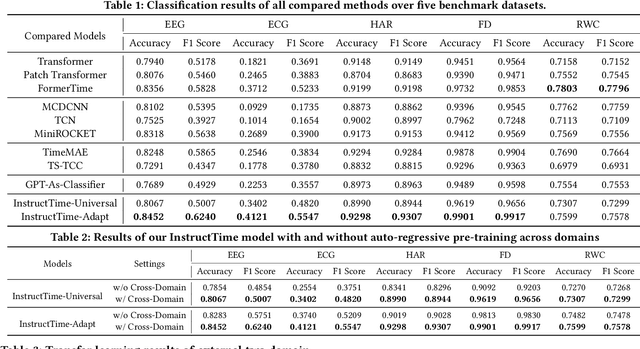

For the advancements of time series classification, scrutinizing previous studies, most existing methods adopt a common learning-to-classify paradigm - a time series classifier model tries to learn the relation between sequence inputs and target label encoded by one-hot distribution. Although effective, this paradigm conceals two inherent limitations: (1) encoding target categories with one-hot distribution fails to reflect the comparability and similarity between labels, and (2) it is very difficult to learn transferable model across domains, which greatly hinder the development of universal serving paradigm. In this work, we propose InstructTime, a novel attempt to reshape time series classification as a learning-to-generate paradigm. Relying on the powerful generative capacity of the pre-trained language model, the core idea is to formulate the classification of time series as a multimodal understanding task, in which both task-specific instructions and raw time series are treated as multimodal inputs while the label information is represented by texts. To accomplish this goal, three distinct designs are developed in the InstructTime. Firstly, a time series discretization module is designed to convert continuous time series into a sequence of hard tokens to solve the inconsistency issue across modal inputs. To solve the modality representation gap issue, for one thing, we introduce an alignment projected layer before feeding the transformed token of time series into language models. For another, we highlight the necessity of auto-regressive pre-training across domains, which can facilitate the transferability of the language model and boost the generalization performance. Extensive experiments are conducted over benchmark datasets, whose results uncover the superior performance of InstructTime and the potential for a universal foundation model in time series classification.