 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cascading Convolutional Temporal Colour Constancy
Jun 15, 2021
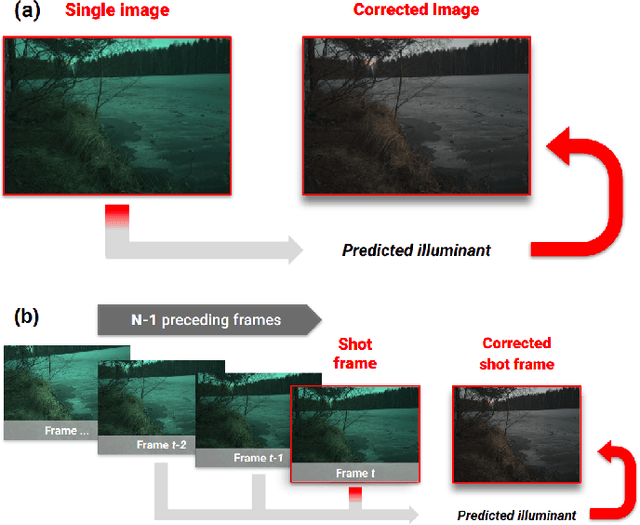
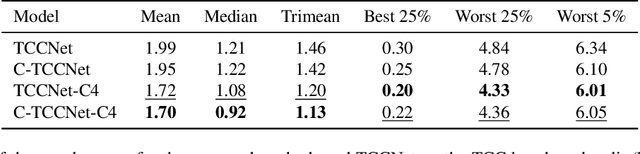
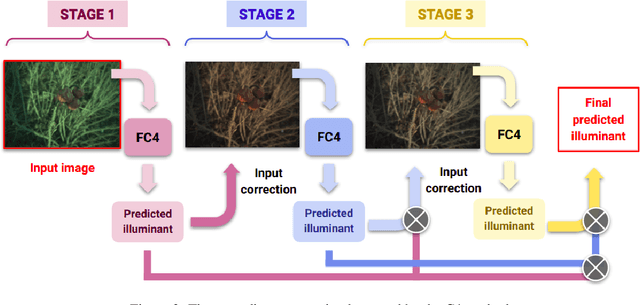
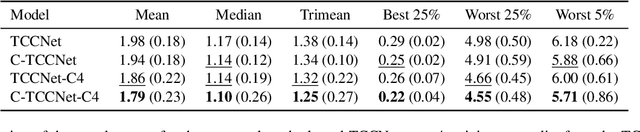
Computational Colour Constancy (CCC) consists of estimating the colour of one or more illuminants in a scene and using them to remove unwanted chromatic distortions. Much research has focused on illuminant estimation for CCC on single images, with few attempts of leveraging the temporal information intrinsic in sequences of correlated images (e.g., the frames in a video), a task known as Temporal Colour Constancy (TCC). The state-of-the-art for TCC is TCCNet, a deep-learning architecture that uses a ConvLSTM for aggregating the encodings produced by CNN submodules for each image in a sequence. We extend this architecture with different models obtained by (i) substituting the TCCNet submodules with C4, the state-of-the-art method for CCC targeting images; (ii) adding a cascading strategy to perform an iterative improvement of the estimate of the illuminant. We tested our models on the recently released TCC benchmark and achieved results that surpass the state-of-the-art. Analyzing the impact of the number of frames involved in illuminant estimation on performance, we show that it is possible to reduce inference time by training the models on few selected frames from the sequences while retaining comparable accuracy.
Super-resolution of Time-series Labels for Bootstrapped Event Detection
Jun 01, 2019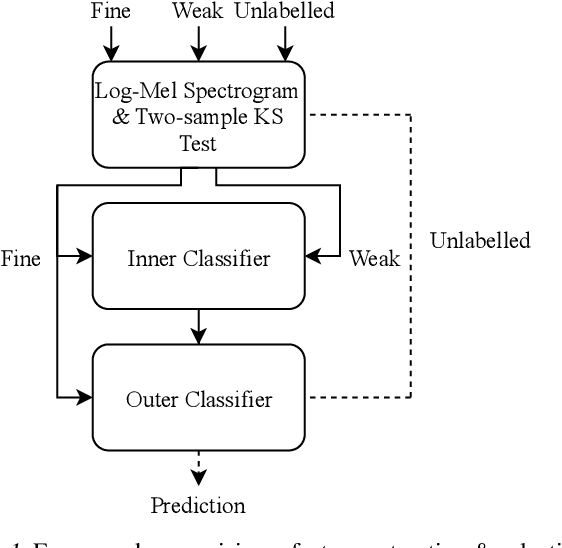
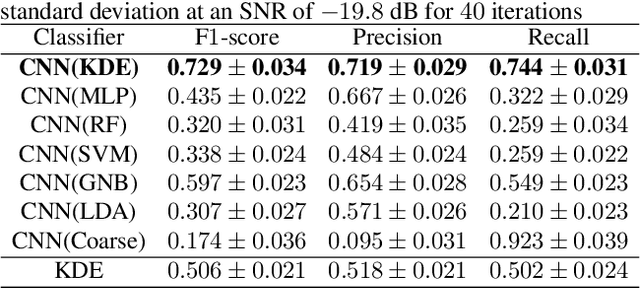
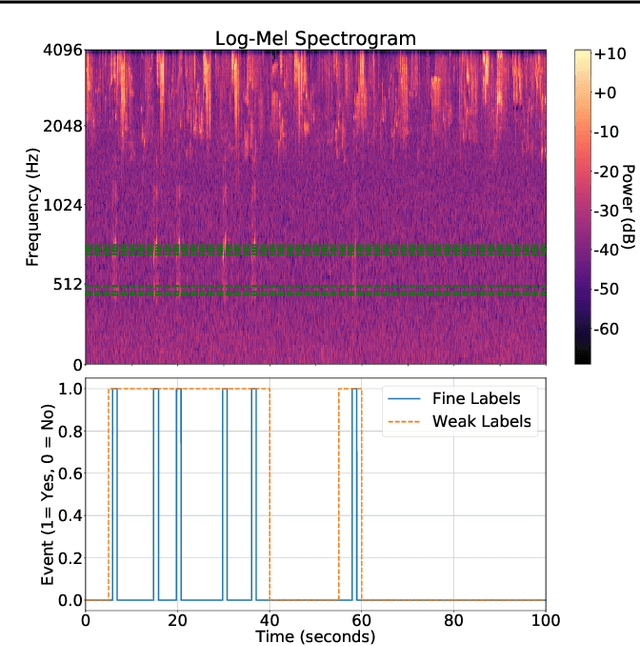

Solving real-world problems, particularly with deep learning, relies on the availability of abundant, quality data. In this paper we develop a novel framework that maximises the utility of time-series datasets that contain only small quantities of expertly-labelled data, larger quantities of weakly (or coarsely) labelled data and a large volume of unlabelled data. This represents scenarios commonly encountered in the real world, such as in crowd-sourcing applications. In our work, we use a nested loop using a Kernel Density Estimator (KDE) to super-resolve the abundant low-quality data labels, thereby enabling effective training of a Convolutional Neural Network (CNN). We demonstrate two key results: a) The KDE is able to super-resolve labels more accurately, and with better calibrated probabilities, than well-established classifiers acting as baselines; b) Our CNN, trained on super-resolved labels from the KDE, achieves an improvement in F1 score of 22.1% over the next best baseline system in our candidate problem domain.
CT Image Synthesis Using Weakly Supervised Segmentation and Geometric Inter-Label Relations For COVID Image Analysis
Jun 15, 2021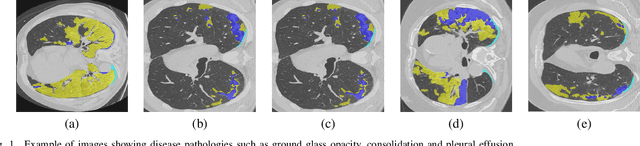
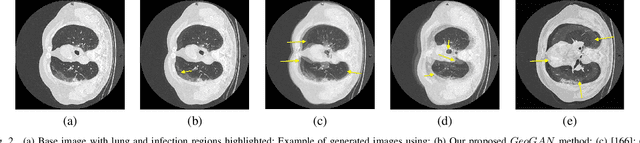
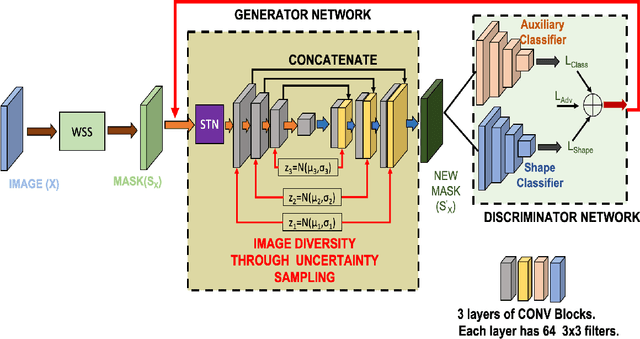
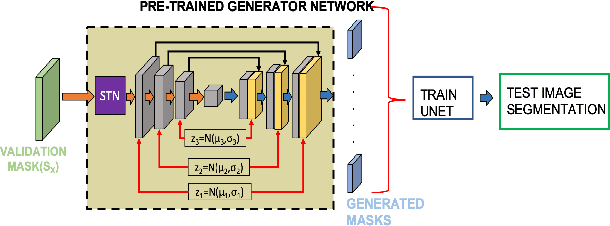
While medical image segmentation is an important task for computer aided diagnosis, the high expertise requirement for pixelwise manual annotations makes it a challenging and time consuming task. Since conventional data augmentations do not fully represent the underlying distribution of the training set, the trained models have varying performance when tested on images captured from different sources. Most prior work on image synthesis for data augmentation ignore the interleaved geometric relationship between different anatomical labels. We propose improvements over previous GAN-based medical image synthesis methods by learning the relationship between different anatomical labels. We use a weakly supervised segmentation method to obtain pixel level semantic label map of images which is used learn the intrinsic relationship of geometry and shape across semantic labels. Latent space variable sampling results in diverse generated images from a base image and improves robustness. We use the synthetic images from our method to train networks for segmenting COVID-19 infected areas from lung CT images. The proposed method outperforms state-of-the-art segmentation methods on a public dataset. Ablation studies also demonstrate benefits of integrating geometry and diversity.
Directional GAN: A Novel Conditioning Strategy for Generative Networks
May 12, 2021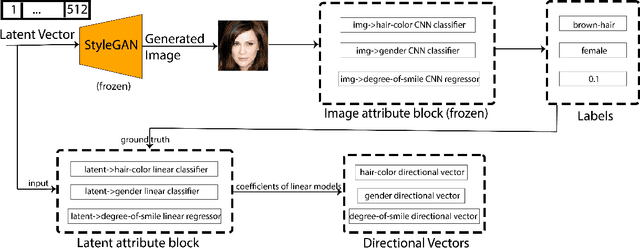

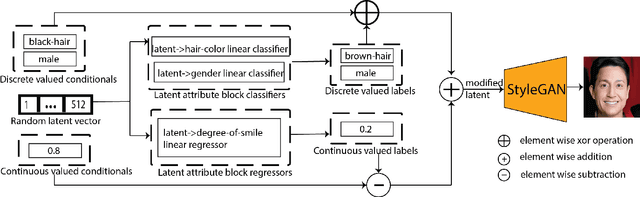
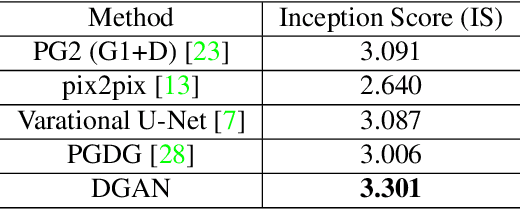
Image content is a predominant factor in marketing campaigns, websites and banners. Today, marketers and designers spend considerable time and money in generating such professional quality content. We take a step towards simplifying this process using Generative Adversarial Networks (GANs). We propose a simple and novel conditioning strategy which allows generation of images conditioned on given semantic attributes using a generator trained for an unconditional image generation task. Our approach is based on modifying latent vectors, using directional vectors of relevant semantic attributes in latent space. Our method is designed to work with both discrete (binary and multi-class) and continuous image attributes. We show the applicability of our proposed approach, named Directional GAN, on multiple public datasets, with an average accuracy of 86.4% across different attributes.
UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation
Jun 15, 2021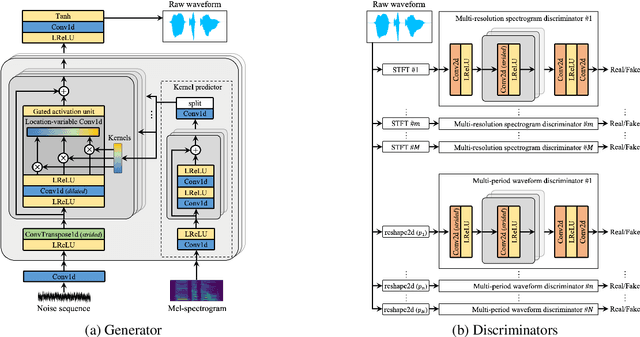
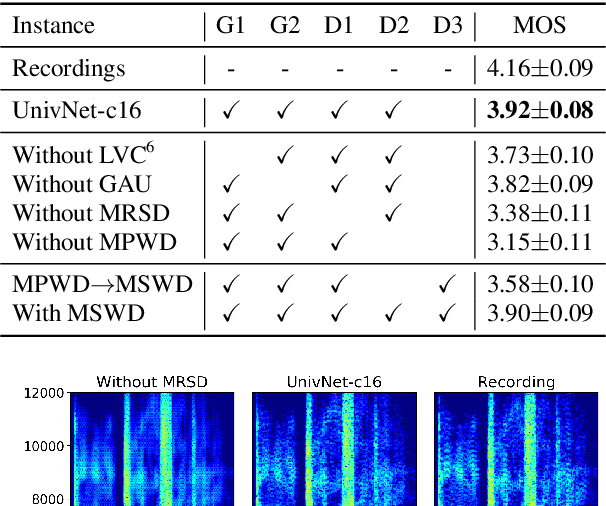
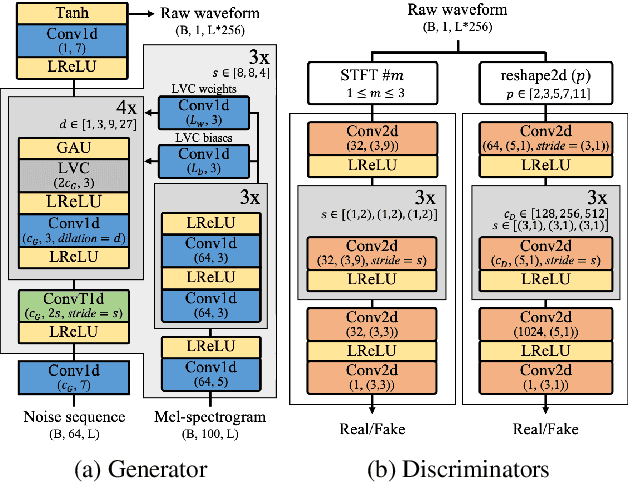
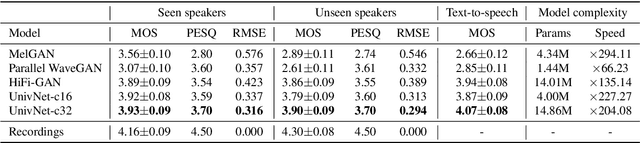
Most neural vocoders employ band-limited mel-spectrograms to generate waveforms. If full-band spectral features are used as the input, the vocoder can be provided with as much acoustic information as possible. However, in some models employing full-band mel-spectrograms, an over-smoothing problem occurs as part of which non-sharp spectrograms are generated. To address this problem, we propose UnivNet, a neural vocoder that synthesizes high-fidelity waveforms in real time. Inspired by works in the field of voice activity detection, we added a multi-resolution spectrogram discriminator that employs multiple linear spectrogram magnitudes computed using various parameter sets. Using full-band mel-spectrograms as input, we expect to generate high-resolution signals by adding a discriminator that employs spectrograms of multiple resolutions as the input. In an evaluation on a dataset containing information on hundreds of speakers, UnivNet obtained the best objective and subjective results among competing models for both seen and unseen speakers. These results, including the best subjective score for text-to-speech, demonstrate the potential for fast adaptation to new speakers without a need for training from scratch.
Action Shuffle Alternating Learning for Unsupervised Action Segmentation
Apr 05, 2021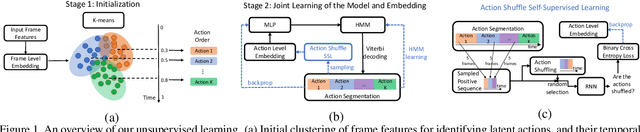
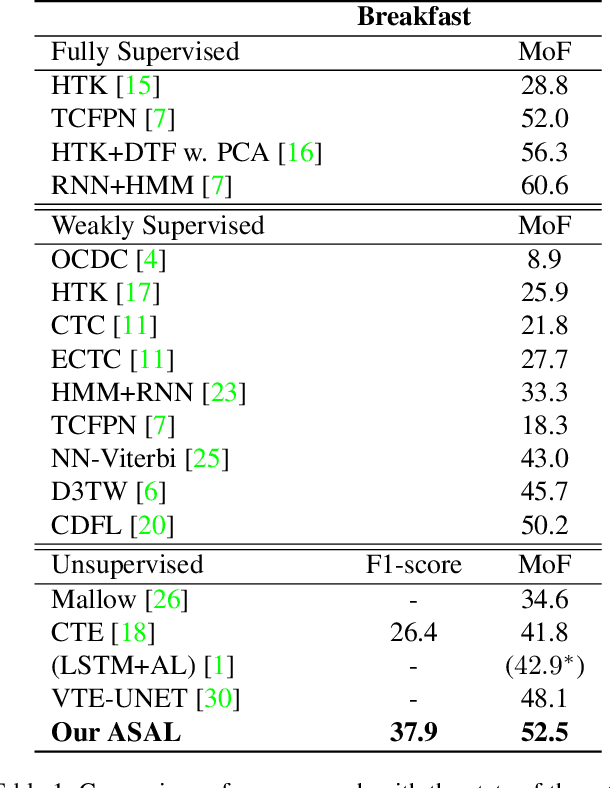
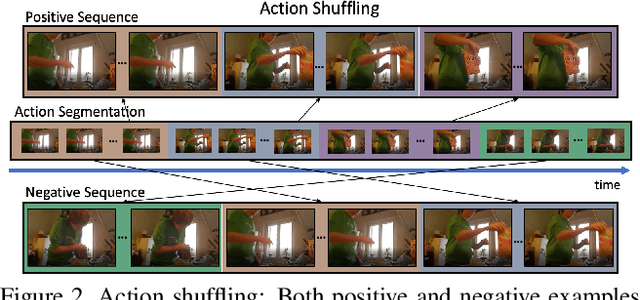
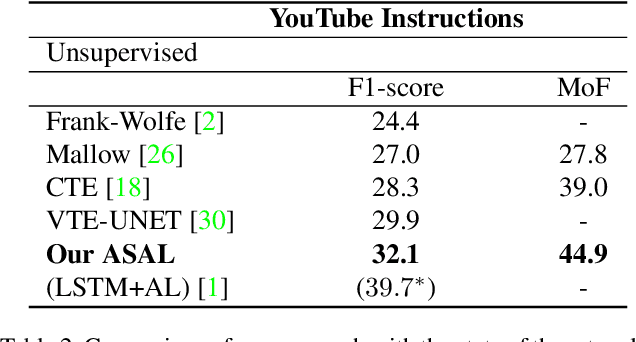
This paper addresses unsupervised action segmentation. Prior work captures the frame-level temporal structure of videos by a feature embedding that encodes time locations of frames in the video. We advance prior work with a new self-supervised learning (SSL) of a feature embedding that accounts for both frame- and action-level structure of videos. Our SSL trains an RNN to recognize positive and negative action sequences, and the RNN's hidden layer is taken as our new action-level feature embedding. The positive and negative sequences consist of action segments sampled from videos, where in the former the sampled action segments respect their time ordering in the video, and in the latter they are shuffled. As supervision of actions is not available and our SSL requires access to action segments, we specify an HMM that explicitly models action lengths, and infer a MAP action segmentation with the Viterbi algorithm. The resulting action segmentation is used as pseudo-ground truth for estimating our action-level feature embedding and updating the HMM. We alternate the above steps within the Generalized EM framework, which ensures convergence. Our evaluation on the Breakfast, YouTube Instructions, and 50Salads datasets gives superior results to those of the state of the art.
An Explainable Probabilistic Classifier for Categorical Data Inspired to Quantum Physics
May 26, 2021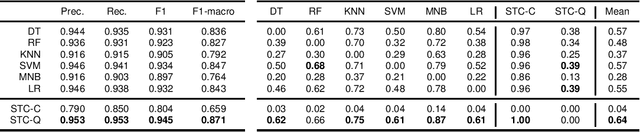

This paper presents Sparse Tensor Classifier (STC), a supervised classification algorithm for categorical data inspired by the notion of superposition of states in quantum physics. By regarding an observation as a superposition of features, we introduce the concept of wave-particle duality in machine learning and propose a generalized framework that unifies the classical and the quantum probability. We show that STC possesses a wide range of desirable properties not available in most other machine learning methods but it is at the same time exceptionally easy to comprehend and use. Empirical evaluation of STC on structured data and text classification demonstrates that our methodology achieves state-of-the-art performances compared to both standard classifiers and deep learning, at the additional benefit of requiring minimal data pre-processing and hyper-parameter tuning. Moreover, STC provides a native explanation of its predictions both for single instances and for each target label globally.
Directed percolation and numerical stability of simulations of digital memcomputing machines
Feb 06, 2021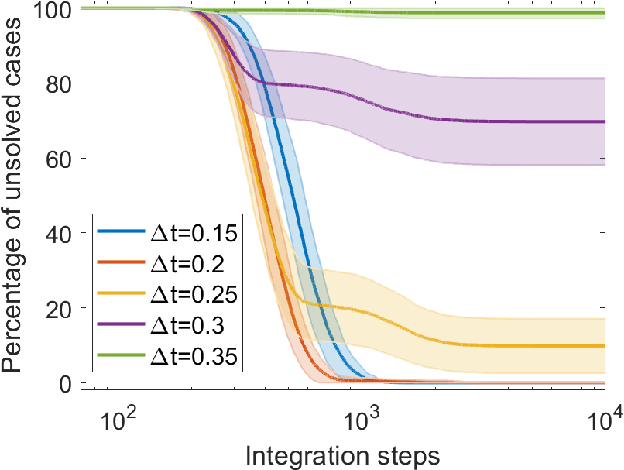
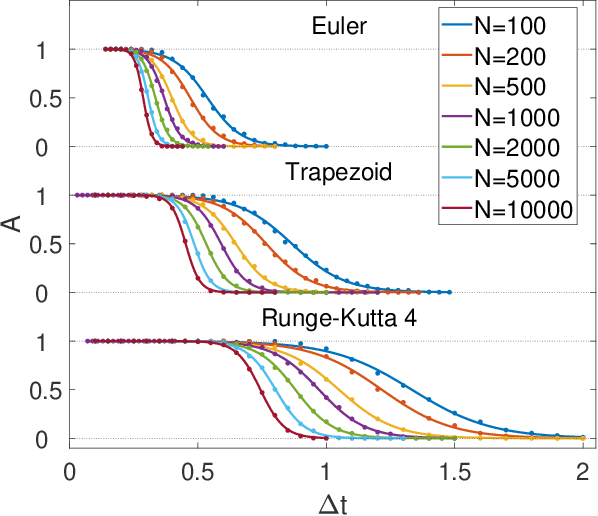
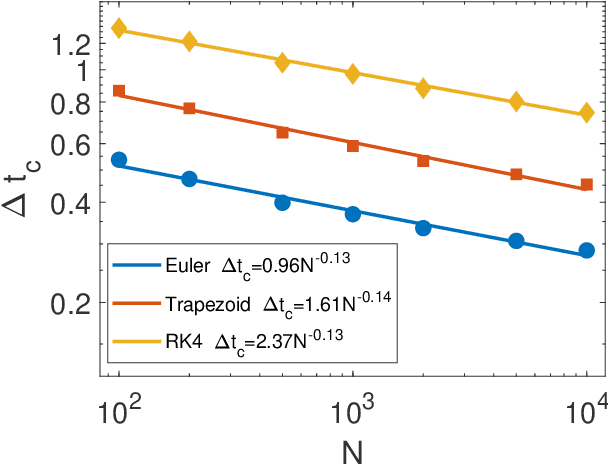
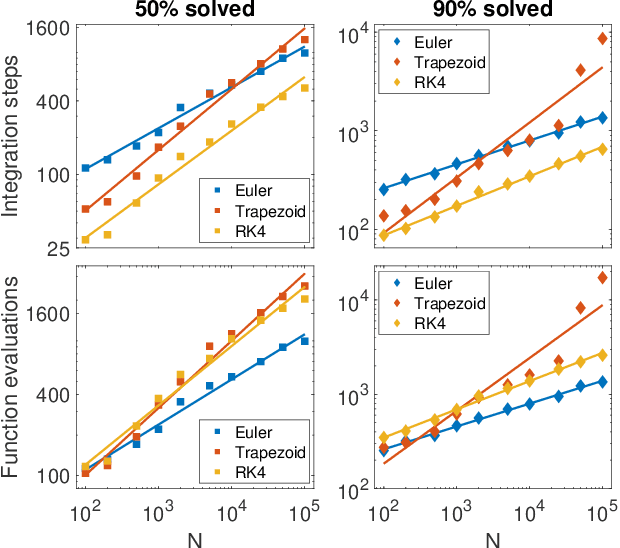
Digital memcomputing machines (DMMs) are a novel, non-Turing class of machines designed to solve combinatorial optimization problems. They can be physically realized with continuous-time, non-quantum dynamical systems with memory (time non-locality), whose ordinary differential equations (ODEs) can be numerically integrated on modern computers. Solutions of many hard problems have been reported by numerically integrating the ODEs of DMMs, showing substantial advantages over state-of-the-art solvers. To investigate the reasons behind the robustness and effectiveness of this method, we employ three explicit integration schemes (forward Euler, trapezoid and Runge-Kutta 4th order) with a constant time step, to solve 3-SAT instances with planted solutions. We show that, (i) even if most of the trajectories in the phase space are destroyed by numerical noise, the solution can still be achieved; (ii) the forward Euler method, although having the largest numerical error, solves the instances in the least amount of function evaluations; and (iii) when increasing the integration time step, the system undergoes a "solvable-unsolvable transition" at a critical threshold, which needs to decay at most as a power law with the problem size, to control the numerical errors. To explain these results, we model the dynamical behavior of DMMs as directed percolation of the state trajectory in the phase space in the presence of noise. This viewpoint clarifies the reasons behind their numerical robustness and provides an analytical understanding of the unsolvable-solvable transition. These results land further support to the usefulness of DMMs in the solution of hard combinatorial optimization problems.
Modular Interactive Video Object Segmentation: Interaction-to-Mask, Propagation and Difference-Aware Fusion
Mar 21, 2021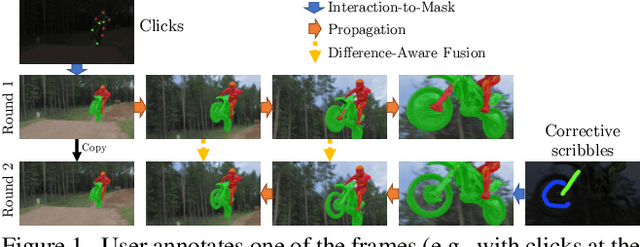
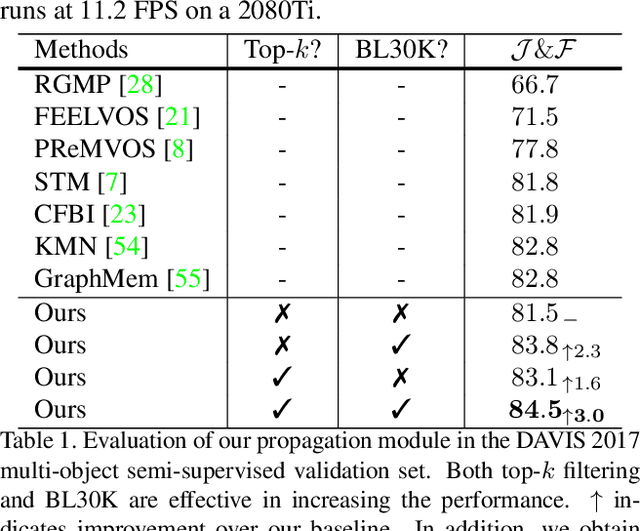
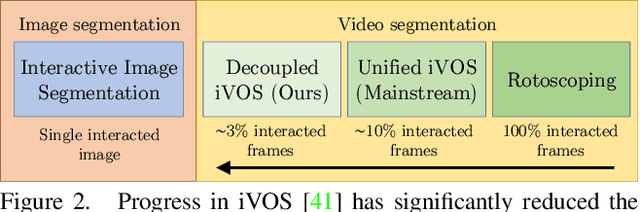
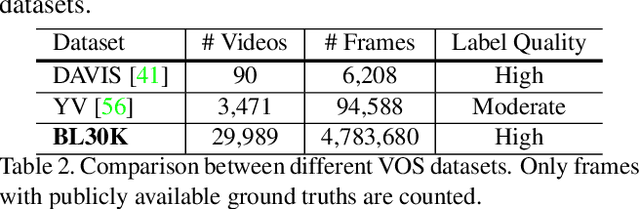
We present Modular interactive VOS (MiVOS) framework which decouples interaction-to-mask and mask propagation, allowing for higher generalizability and better performance. Trained separately, the interaction module converts user interactions to an object mask, which is then temporally propagated by our propagation module using a novel top-$k$ filtering strategy in reading the space-time memory. To effectively take the user's intent into account, a novel difference-aware module is proposed to learn how to properly fuse the masks before and after each interaction, which are aligned with the target frames by employing the space-time memory. We evaluate our method both qualitatively and quantitatively with different forms of user interactions (e.g., scribbles, clicks) on DAVIS to show that our method outperforms current state-of-the-art algorithms while requiring fewer frame interactions, with the additional advantage in generalizing to different types of user interactions. We contribute a large-scale synthetic VOS dataset with pixel-accurate segmentation of 4.8M frames to accompany our source codes to facilitate future research.
Sleep Staging Based on Serialized Dual Attention Network
Jul 18, 2021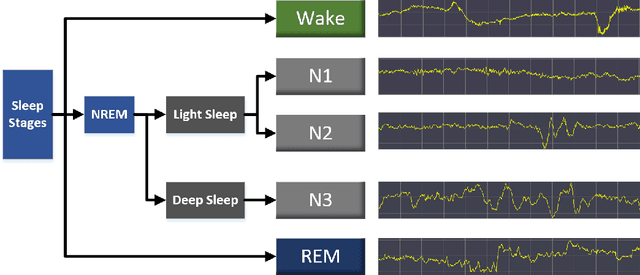

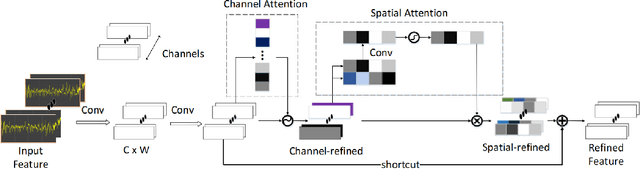

Sleep staging assumes an important role in the diagnosis of sleep disorders. In general, experts classify sleep stages manually based on polysomnography (PSG), which is quite time-consuming. Meanwhile, the acquisition of multiple signals is complex, which can affect the subject's sleep. Therefore, the use of single-channel electroencephalogram (EEG) for automatic sleep staging has become mainstream. In the literature, a large number of sleep staging methods based on single-channel EEG have been proposed with good results and realize the preliminary automation of sleep staging. However, the performance for most of these methods in the N1 stage is generally not high. In this paper, we propose a deep learning model SDAN based on raw EEG. The method utilises a one-dimensional convolutional neural network (CNN) to automatically extract features from raw EEG. It serially combines the channel attention and spatial attention mechanisms to filter and highlight key information and then uses soft threshold to eliminate redundant information. Additionally, we introduce a residual network to avoid degradation problems caused by network deepening. Experiments were conducted using two datasets with 5-fold cross-validation and hold-out validation method. The final average accuracy, overall accuracy, macro F1 score and Cohen's Kappa coefficient of the model reach 96.74%, 91.86%, 82.64% and 0.8742 on the Sleep-EDF dataset, and 95.98%, 89.96%, 79.08% and 0.8216 on the Sleep-EDFx dataset. Significantly, our model performed superiorly in the N1 stage, with F1 scores of 54.08% and 52.49% on the two datasets respectively. The results show the superiority of our network over the best existing methods, reaching a new state-of-the-art. In particular, the present method achieves excellent results in the N1 sleep stage compared to other methods.