 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Experimental Comparison of Visual and Single-Receiver GPS Odometry
Jun 08, 2021
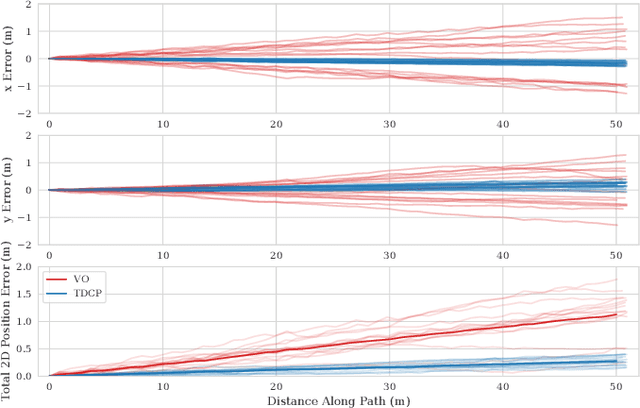
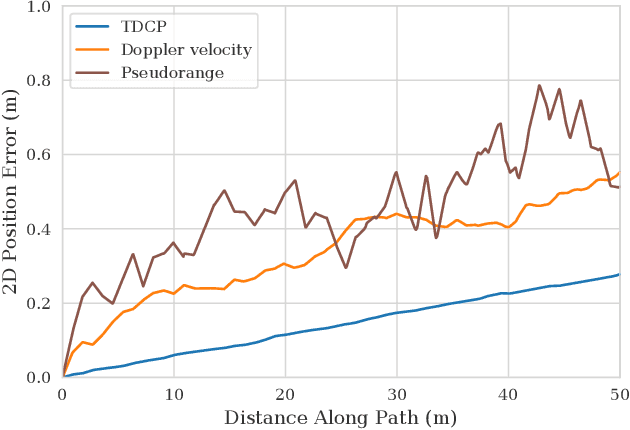
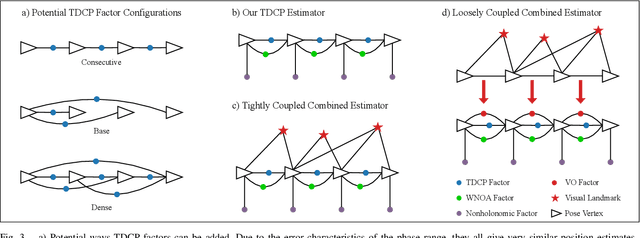
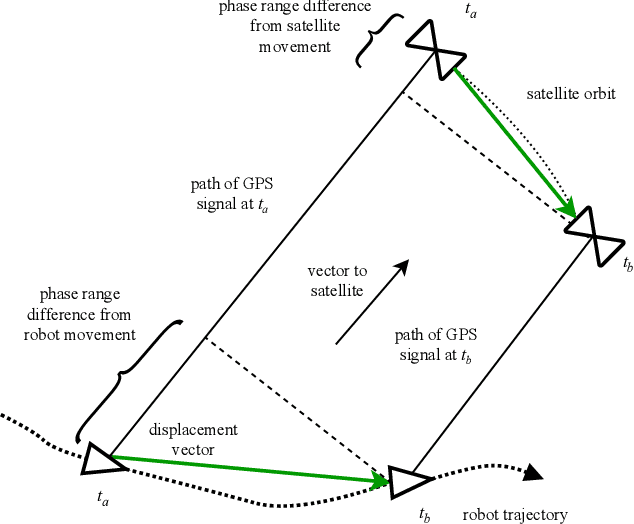
Mobile robots rely on odometry to navigate through areas where localization fails. Visual odometry (VO) is a common solution for obtaining robust and consistent relative motion estimates of the vehicle frame. Contrarily, Global Positioning System (GPS) measurements are typically used for absolute positioning and localization. However, when the constraint on absolute accuracy is relaxed, time-differenced carrier phase (TDCP) measurements can be used to find accurate relative position estimates with one single-frequency GPS receiver. This suggests practitioners may want to consider GPS odometry as an alternative or in combination with VO. We describe a robust method for single-receiver GPS odometry on an unmanned ground vehicle (UGV). We then present an experimental comparison of the two strategies on the same test trajectories. After 1.8km of testing, the results show our GPS odometry method has a 75% lower drift rate than a proven stereo VO method while maintaining a smooth error signal despite varying satellite availability.
Wave based damage detection in solid structures using artificial neural networks
Mar 30, 2021


The identification of structural damages takes a more and more important role within the modern economy, where often the monitoring of an infrastructure is the last approach to keep it under public use. Conventional monitoring methods require specialized engineers and are mainly time consuming. This research paper considers the ability of neural networks to recognize the initial or alteration of structural properties based on the training processes. The presented work here is based on Convolutional Neural Networks (CNN) for wave field pattern recognition, or more specifically the wave field change recognition. The CNN model is used to identify the change within propagating wave fields after a crack initiation within the structure. The paper describes the implemented method and the required training procedure to get a successful crack detection accuracy, where the training data are based on the dynamic lattice model. Although the training of the model is still time consuming, the proposed new method has an enormous potential to become a new crack detection or structural health monitoring approach within the conventional monitoring methods.
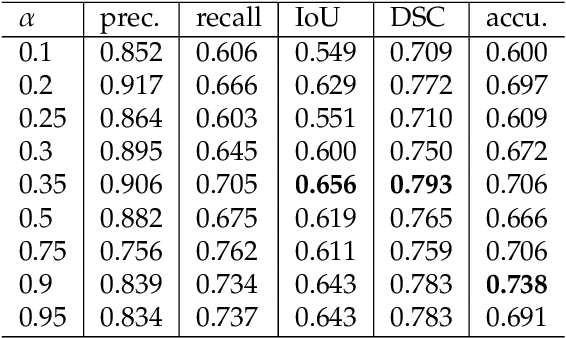
Process Outcome Prediction: CNN vs. LSTM (with Attention)
Apr 14, 2021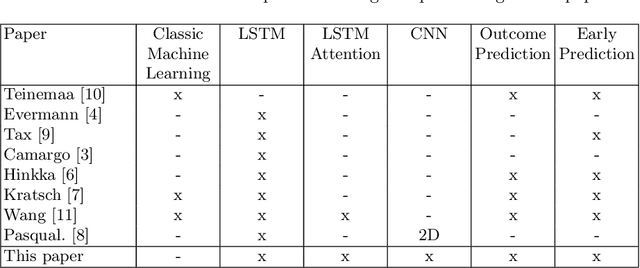
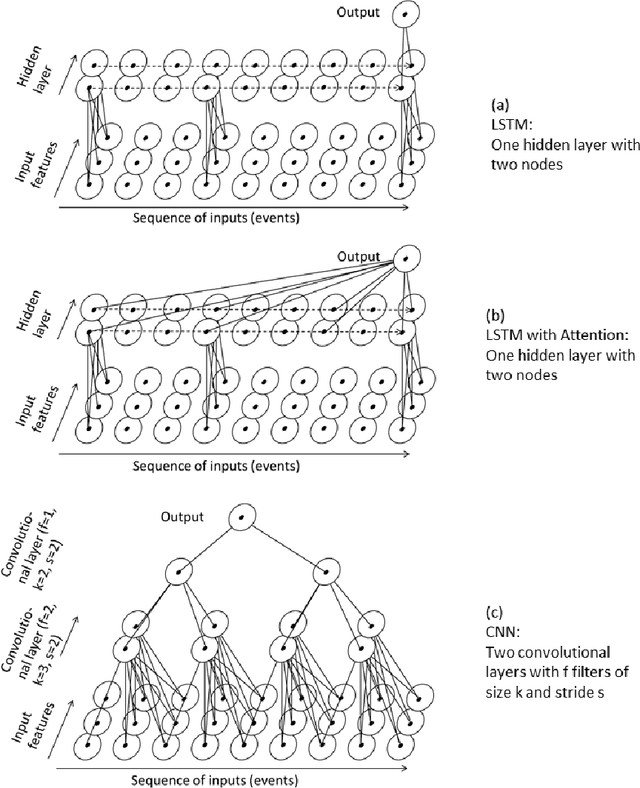

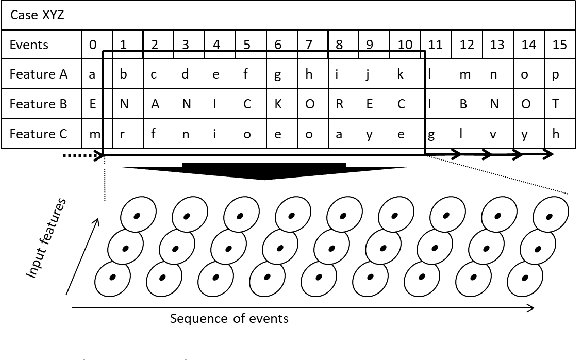
The early outcome prediction of ongoing or completed processes confers competitive advantage to organizations. The performance of classic machine learning and, more recently, deep learning techniques such as Long Short-Term Memory (LSTM) on this type of classification problem has been thorougly investigated. Recently, much research focused on applying Convolutional Neural Networks (CNN) to time series problems including classification, however not yet to outcome prediction. The purpose of this paper is to close this gap and compare CNNs to LSTMs. Attention is another technique that, in combination with LSTMs, has found application in time series classification and was included in our research. Our findings show that all these neural networks achieve satisfactory to high predictive power provided sufficiently large datasets. CNNs perfom on par with LSTMs; the Attention mechanism adds no value to the latter. Since CNNs run one order of magnitude faster than both types of LSTM, their use is preferable. All models are robust with respect to their hyperparameters and achieve their maximal predictive power early on in the cases, usually after only a few events, making them highly suitable for runtime predictions. We argue that CNNs' speed, early predictive power and robustness should pave the way for their application in process outcome prediction.
SMART tracking: Simultaneous anatomical imaging and real-time passive device tracking for MR-guided interventions
Aug 28, 2019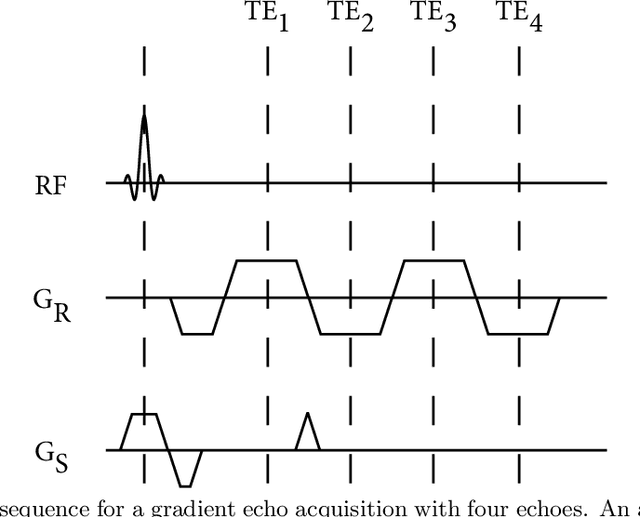
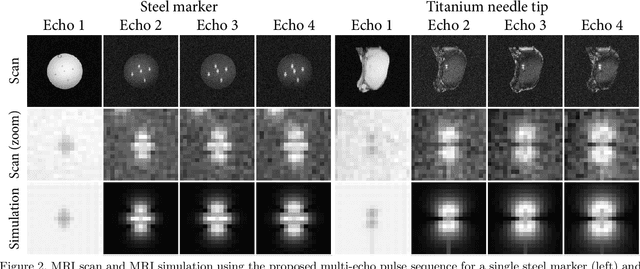
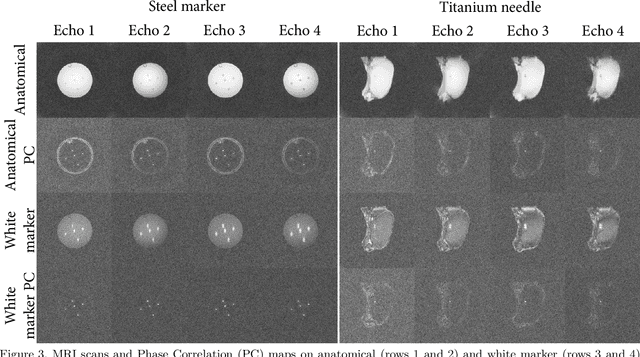

Purpose: This study demonstrates a proof of concept of a method for simultaneous anatomical imaging and real-time (SMART) passive device tracking for MR-guided interventions. Methods: Phase Correlation template matching was combined with a fast undersampled radial multi-echo acquisition using the white marker phenomenon after the first echo. In this way, the first echo provides anatomical contrast, whereas the other echoes provide white marker contrast to allow accurate device localization using fast simulations and template matching. This approach was tested on tracking of five 0.5 mm steel markers in an agarose phantom and on insertion of an MRI-compatible 20 Gauge titanium needle in ex vivo porcine tissue. The locations of the steel markers were quantitatively compared to the marker locations as found on a CT scan of the same phantom. Results: The average pairwise error between the MRI and CT locations was 0.30 mm for tracking of stationary steel spheres and 0.29 mm during motion. Qualitative evaluation of the tracking of needle insertions showed that tracked positions were stable throughout needle insertion and retraction. Conclusions: The proposed SMART tracking method provided accurate passive tracking of devices at high framerates, inclusion of real-time anatomical scanning, and the capability of automatic slice positioning. Furthermore, the method does not require specialized hardware and could therefore be applied to track any rigid metal device that causes appreciable magnetic field distortions.
Biologically Inspired Model for Timed Motion in Robotic Systems
Jun 30, 2021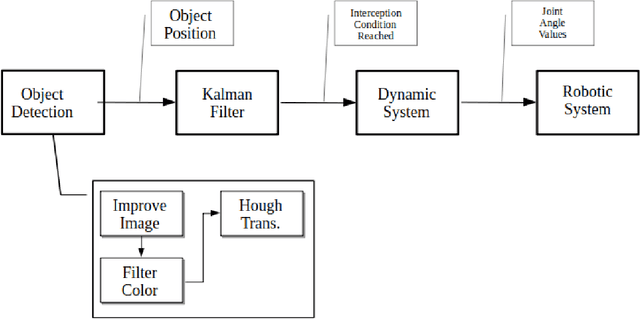
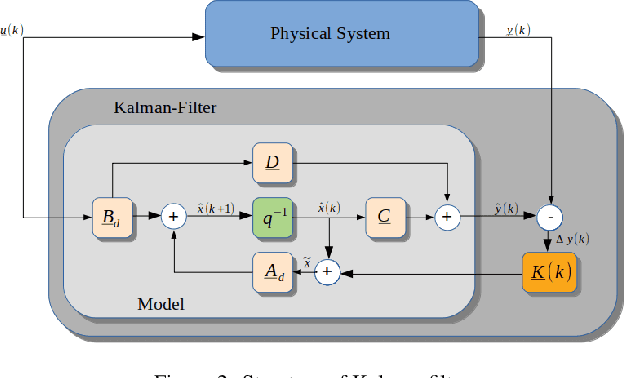
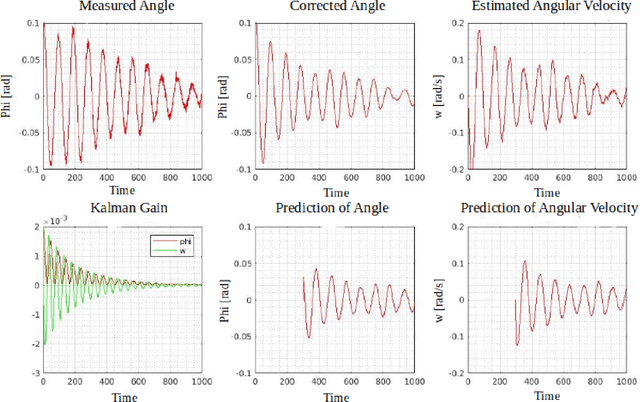

The goal of this work is the development of a motion model for sequentially timed movement actions in robotic systems under specific consideration of temporal stabilization, that is maintaining an approximately constant overall movement time (isochronous behavior). This is demonstrated both in simulation and on a physical robotic system for the task of intercepting a moving target in three-dimensional space. Motivated from humanoid motion, timing plays a vital role to generate a naturalistic behavior in interaction with the dynamic environment as well as adaptively planning and executing action sequences on-line. In biological systems, many of the physiological and anatomical functions follow a particular level of periodicity and stabilization, which exhibit a certain extent of resilience against external disturbances. A main aspect thereof is stabilizing movement timing against limited perturbations. Especially human arm movement, namely when it is tasked to reach a certain goal point, pose or configuration, shows a stabilizing behavior. This work incorporates the utilization of an extended Kalman filter (EKF) which was implemented to predict the target position while coping with non-linear system dynamics. The periodicity and temporal stabilization in biological systems was artificially generated by a Hopf oscillator, yielding a sinusoidal velocity profile for smooth and repeatable motion.
Neural Lumigraph Rendering
Mar 22, 2021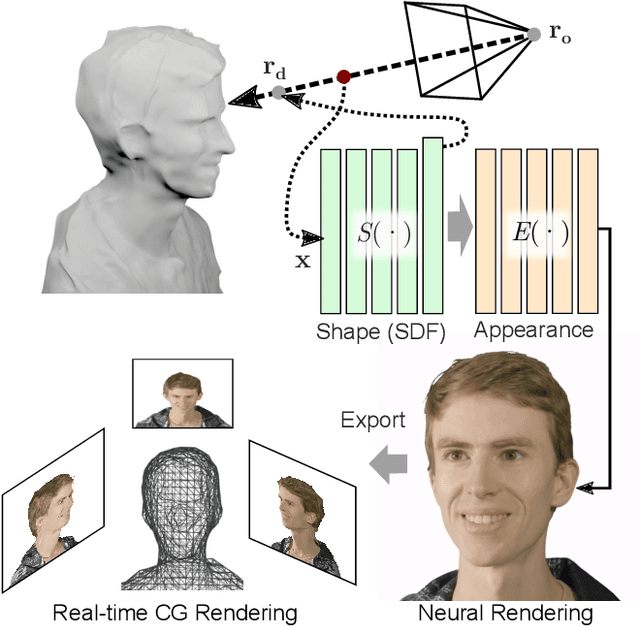


Novel view synthesis is a challenging and ill-posed inverse rendering problem. Neural rendering techniques have recently achieved photorealistic image quality for this task. State-of-the-art (SOTA) neural volume rendering approaches, however, are slow to train and require minutes of inference (i.e., rendering) time for high image resolutions. We adopt high-capacity neural scene representations with periodic activations for jointly optimizing an implicit surface and a radiance field of a scene supervised exclusively with posed 2D images. Our neural rendering pipeline accelerates SOTA neural volume rendering by about two orders of magnitude and our implicit surface representation is unique in allowing us to export a mesh with view-dependent texture information. Thus, like other implicit surface representations, ours is compatible with traditional graphics pipelines, enabling real-time rendering rates, while achieving unprecedented image quality compared to other surface methods. We assess the quality of our approach using existing datasets as well as high-quality 3D face data captured with a custom multi-camera rig.
Unsupervised Object-Based Transition Models for 3D Partially Observable Environments
Mar 08, 2021
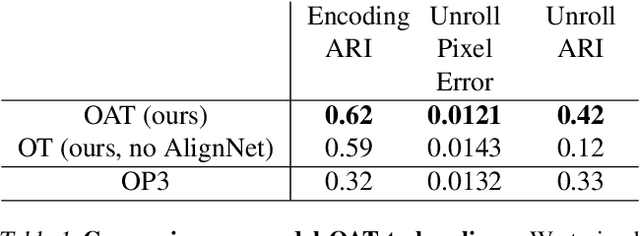
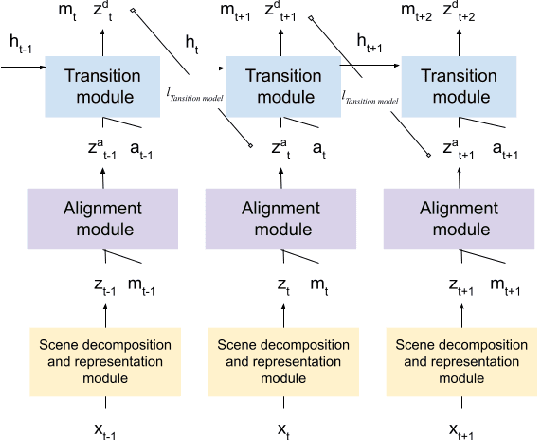

We present a slot-wise, object-based transition model that decomposes a scene into objects, aligns them (with respect to a slot-wise object memory) to maintain a consistent order across time, and predicts how those objects evolve over successive frames. The model is trained end-to-end without supervision using losses at the level of the object-structured representation rather than pixels. Thanks to its alignment module, the model deals properly with two issues that are not handled satisfactorily by other transition models, namely object persistence and object identity. We show that the combination of an object-level loss and correct object alignment over time enables the model to outperform a state-of-the-art baseline, and allows it to deal well with object occlusion and re-appearance in partially observable environments.
Contention-based Grant-free Transmission with Extremely Sparse Orthogonal Pilot Scheme
Jun 08, 2021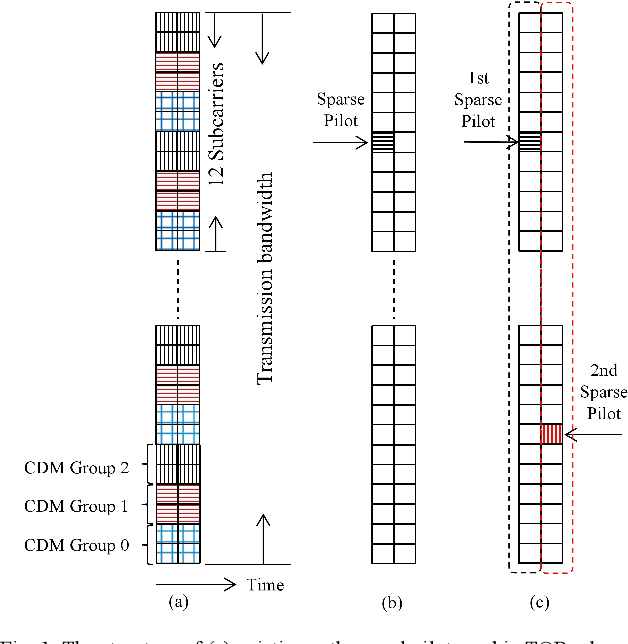
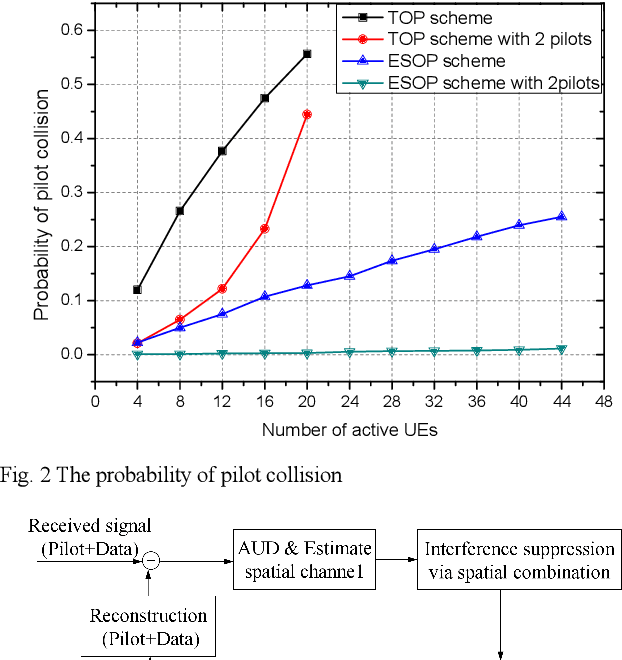
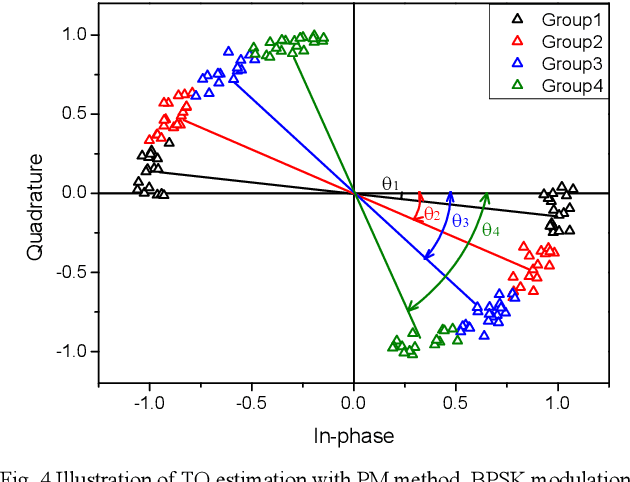
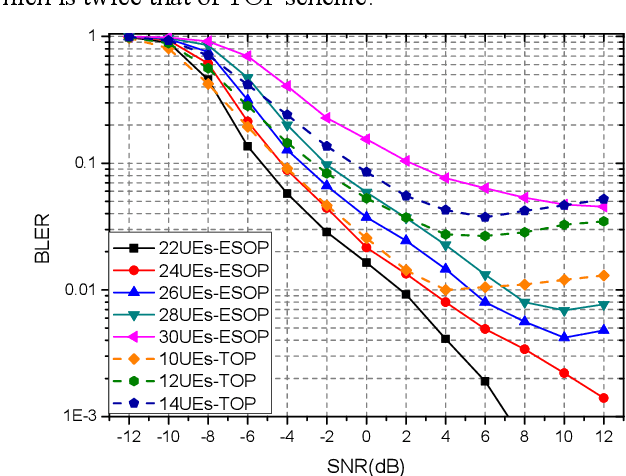
Due to the limited number of traditional orthogonal pilots, pilot collision will severely degrade the performance of contention-based grant-free transmission. To alleviate the pilot collision and exploit the spatial degree of freedom as much as possible, an extremely sparse orthogonal pilot scheme is proposed for uplink grant-free transmission. The proposed sparse pilot is used to perform active user detection and estimate the spatial channel. Then, inter-user interference suppression is performed by spatially combining the received data symbols using the estimated spatial channel. After that, the estimation and compensation of wireless channel and time/frequency offset are performed utilizing the geometric characteristics of combined data symbols. The task of pilot is much lightened, so that the extremely sparse orthogonal pilot can occupy minimized resources, and the number of orthogonal pilots can be increased significantly, which greatly reduces the probability of pilot collision. The numerical results show that the proposed extremely sparse orthogonal pilot scheme significantly improves the performance in high-overloading grant-free scenario.
BAGUA: Scaling up Distributed Learning with System Relaxations
Jul 06, 2021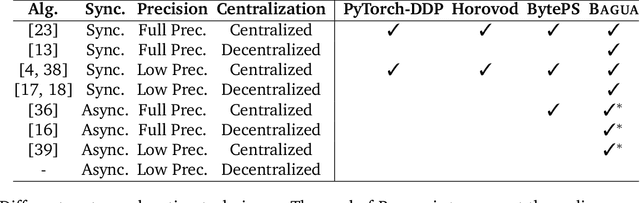
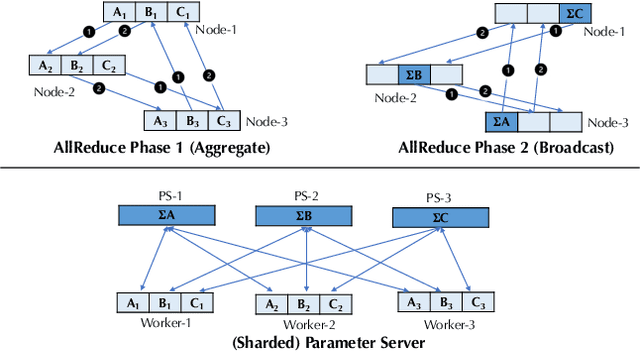
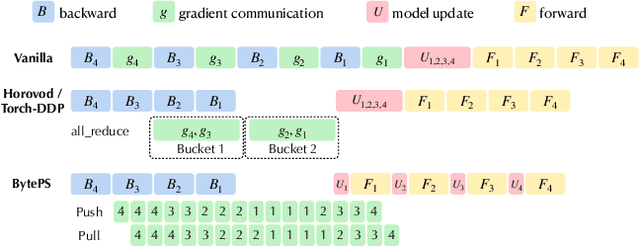

Recent years have witnessed a growing list of systems for distributed data-parallel training. Existing systems largely fit into two paradigms, i.e., parameter server and MPI-style collective operations. On the algorithmic side, researchers have proposed a wide range of techniques to lower the communication via system relaxations: quantization, decentralization, and communication delay. However, most, if not all, existing systems only rely on standard synchronous and asynchronous stochastic gradient (SG) based optimization, therefore, cannot take advantage of all possible optimizations that the machine learning community has been developing recently. Given this emerging gap between the current landscapes of systems and theory, we build BAGUA, a communication framework whose design goal is to provide a system abstraction that is both flexible and modular to support state-of-the-art system relaxation techniques of distributed training. Powered by the new system design, BAGUA has a great ability to implement and extend various state-of-the-art distributed learning algorithms. In a production cluster with up to 16 machines (128 GPUs), BAGUA can outperform PyTorch-DDP, Horovod and BytePS in the end-to-end training time by a significant margin (up to 1.95 times) across a diverse range of tasks. Moreover, we conduct a rigorous tradeoff exploration showing that different algorithms and system relaxations achieve the best performance over different network conditions.
Tetrad: Actively Secure 4PC for Secure Training and Inference
Jun 08, 2021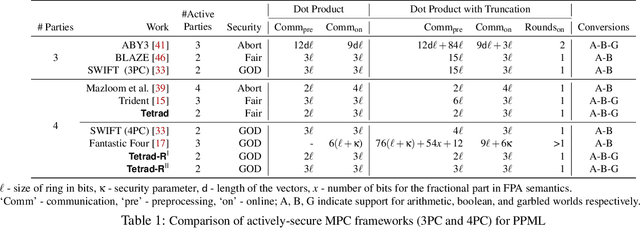



In this work, we design an efficient mixed-protocol framework, Tetrad, with applications to privacy-preserving machine learning. It is designed for the four-party setting with at most one active corruption and supports rings. Our fair multiplication protocol requires communicating only 5 ring elements improving over the state-of-the-art protocol of Trident (Chaudhari et al. NDSS'20). The technical highlights of Tetrad include efficient (a) truncation without any overhead, (b) multi-input multiplication protocols for arithmetic and boolean worlds, (c) garbled-world, tailor-made for the mixed-protocol framework, and (d) conversion mechanisms to switch between the computation styles. The fair framework is also extended to provide robustness without inflating the costs. The competence of Tetrad is tested with benchmarks for deep neural networks such as LeNet and VGG16 and support vector machines. One variant of our framework aims at minimizing the execution time, while the other focuses on the monetary cost. We observe improvements up to 6x over Trident across these parameters.