 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Memorization and Generalization in Neural Code Intelligence Models
Jun 16, 2021

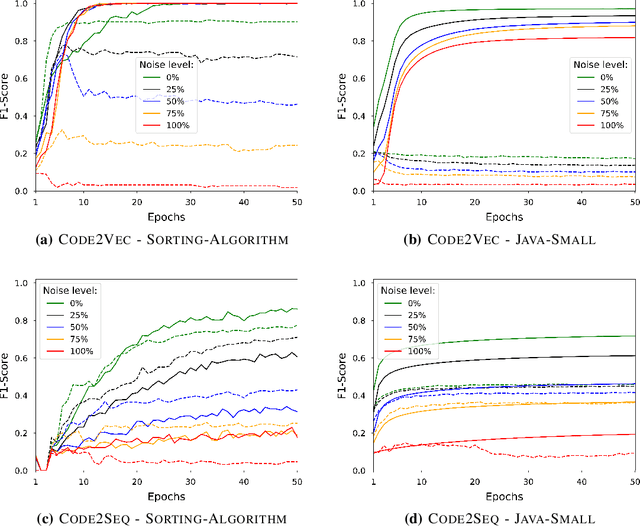
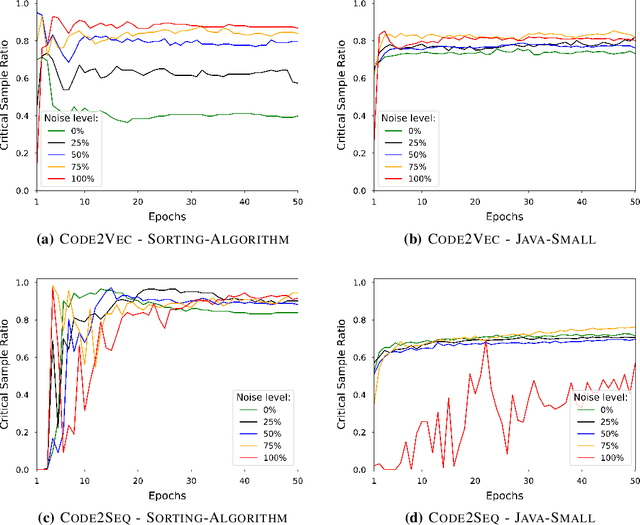
Deep Neural Networks (DNN) are increasingly commonly used in software engineering and code intelligence tasks. These are powerful tools that are capable of learning highly generalizable patterns from large datasets through millions of parameters. At the same time, training DNNs means walking a knife's edges, because their large capacity also renders them prone to memorizing data points. While traditionally thought of as an aspect of over-training, recent work suggests that the memorization risk manifests especially strongly when the training datasets are noisy and memorization is the only recourse. Unfortunately, most code intelligence tasks rely on rather noise-prone and repetitive data sources, such as GitHub, which, due to their sheer size, cannot be manually inspected and evaluated. We evaluate the memorization and generalization tendencies in neural code intelligence models through a case study across several benchmarks and model families by leveraging established approaches from other fields that use DNNs, such as introducing targeted noise into the training dataset. In addition to reinforcing prior general findings about the extent of memorization in DNNs, our results shed light on the impact of noisy dataset in training.
FONTNET: On-Device Font Understanding and Prediction Pipeline
Mar 30, 2021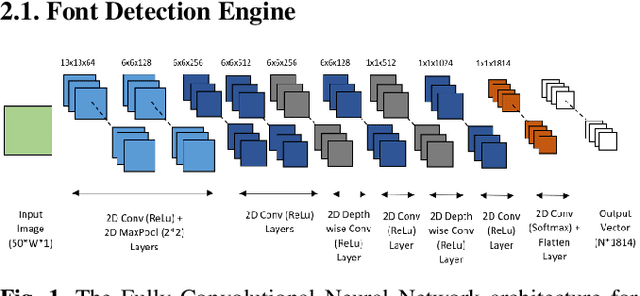
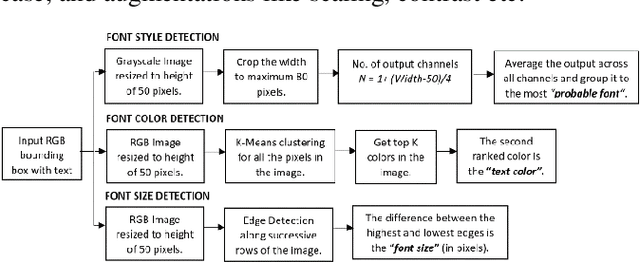
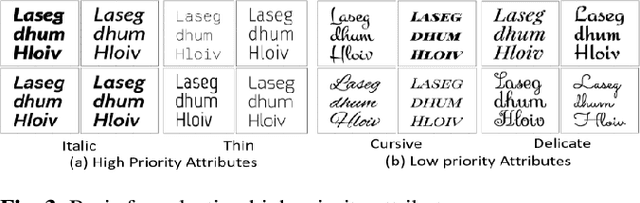
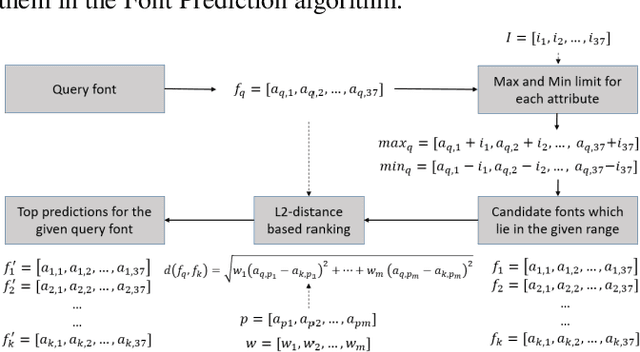
Fonts are one of the most basic and core design concepts. Numerous use cases can benefit from an in depth understanding of Fonts such as Text Customization which can change text in an image while maintaining the Font attributes like style, color, size. Currently, Text recognition solutions can group recognized text based on line breaks or paragraph breaks, if the Font attributes are known multiple text blocks can be combined based on context in a meaningful manner. In this paper, we propose two engines: Font Detection Engine, which identifies the font style, color and size attributes of text in an image and a Font Prediction Engine, which predicts similar fonts for a query font. Major contributions of this paper are three-fold: First, we developed a novel CNN architecture for identifying font style of text in images. Second, we designed a novel algorithm for predicting similar fonts for a given query font. Third, we have optimized and deployed the entire engine On-Device which ensures privacy and improves latency in real time applications such as instant messaging. We achieve a worst case On-Device inference time of 30ms and a model size of 4.5MB for both the engines.
Proving Equivalence Between Complex Expressions Using Graph-to-Sequence Neural Models
Jun 09, 2021
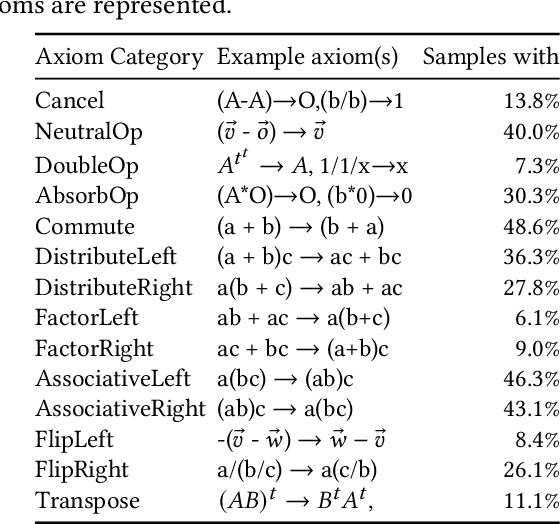
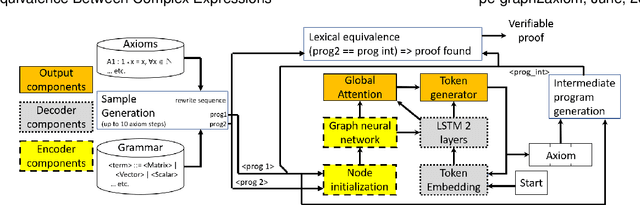

We target the problem of provably computing the equivalence between two complex expression trees. To this end, we formalize the problem of equivalence between two such programs as finding a set of semantics-preserving rewrite rules from one into the other, such that after the rewrite the two programs are structurally identical, and therefore trivially equivalent.We then develop a graph-to-sequence neural network system for program equivalence, trained to produce such rewrite sequences from a carefully crafted automatic example generation algorithm. We extensively evaluate our system on a rich multi-type linear algebra expression language, using arbitrary combinations of 100+ graph-rewriting axioms of equivalence. Our machine learning system guarantees correctness for all true negatives, and ensures 0 false positive by design. It outputs via inference a valid proof of equivalence for 93% of the 10,000 equivalent expression pairs isolated for testing, using up to 50-term expressions. In all cases, the validity of the sequence produced and therefore the provable assertion of program equivalence is always computable, in negligible time.
Terahertz Wireless Communications with Flexible Index Modulation Aided Pilot Design
Jun 23, 2021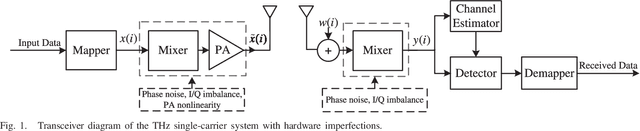
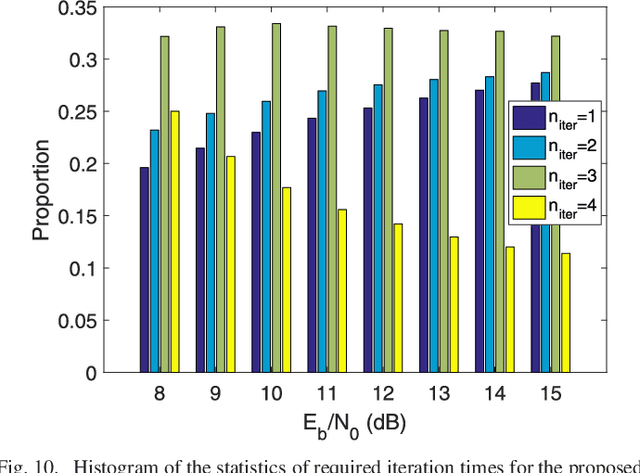
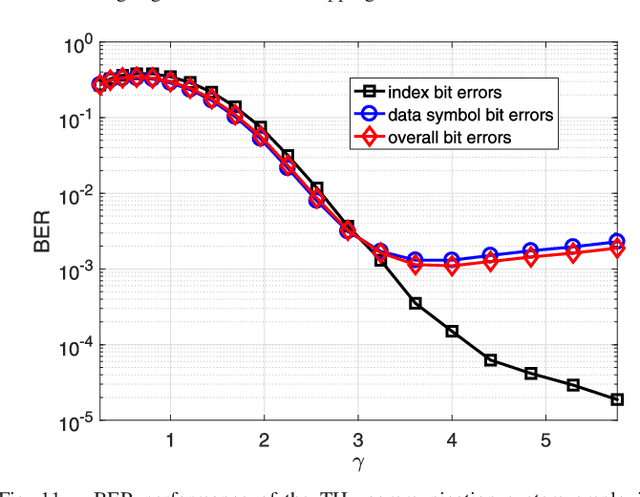
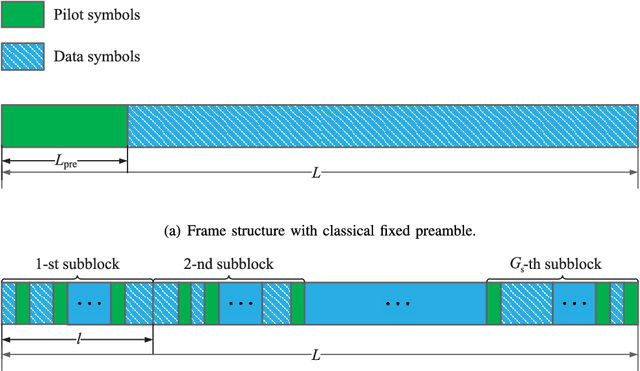
Terahertz (THz) wireless communication is envisioned as a promising technology, which is capable of providing ultra-high-rate transmission up to Terabit per second. However, some hardware imperfections, which are generally neglected in the existing literature concerning lower data rates and traditional operating frequencies, cannot be overlooked in the THz systems. Hardware imperfections usually consist of phase noise, in-phase/quadrature imbalance, and nonlinearity of power amplifier. Due to the time-variant characteristic of phase noise, frequent pilot insertion is required, leading to decreased spectral efficiency. In this paper, to address this issue, a novel pilot design strategy is proposed based on index modulation (IM), where the positions of pilots are flexibly changed in the data frame, and additional information bits can be conveyed by indices of pilots. Furthermore, a turbo receiving algorithm is developed, which jointly performs the detection of pilot indices and channel estimation in an iterative manner. It is shown that the proposed turbo receiver works well even under the situation where the prior knowledge of channel state information is outdated. Analytical and simulation results validate that the proposed schemes achieve significant enhancement of bit-error rate performance and channel estimation accuracy, whilst attaining higher spectral efficiency in comparison with its classical counterpart.
Semi-Supervised Training with Pseudo-Labeling for End-to-End Neural Diarization
Jun 09, 2021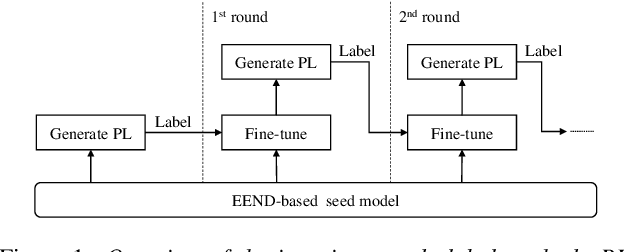
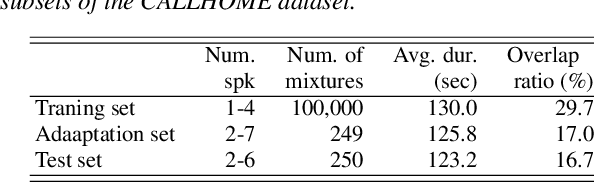
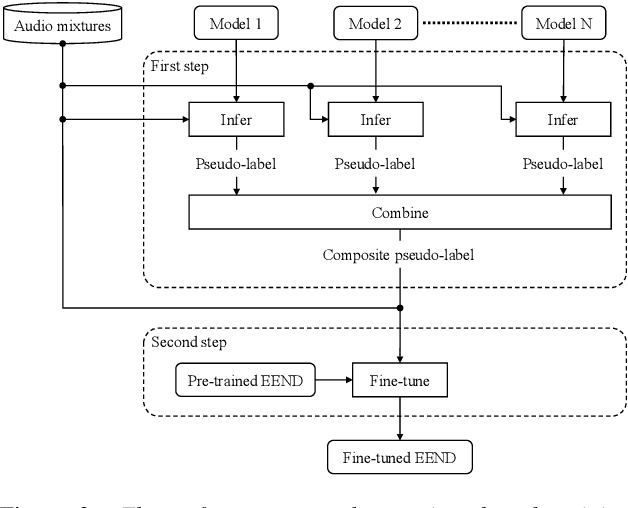
In this paper, we present a semi-supervised training technique using pseudo-labeling for end-to-end neural diarization (EEND). The EEND system has shown promising performance compared with traditional clustering-based methods, especially in the case of overlapping speech. However, to get a well-tuned model, EEND requires labeled data for all the joint speech activities of every speaker at each time frame in a recording. In this paper, we explore a pseudo-labeling approach that employs unlabeled data. First, we propose an iterative pseudo-label method for EEND, which trains the model using unlabeled data of a target condition. Then, we also propose a committee-based training method to improve the performance of EEND. To evaluate our proposed method, we conduct the experiments of model adaptation using labeled and unlabeled data. Experimental results on the CALLHOME dataset show that our proposed pseudo-label achieved a 37.4% relative diarization error rate reduction compared to a seed model. Moreover, we analyzed the results of semi-supervised adaptation with pseudo-labeling. We also show the effectiveness of our approach on the third DIHARD dataset.
Retrieval-Free Knowledge-Grounded Dialogue Response Generation with Adapters
May 13, 2021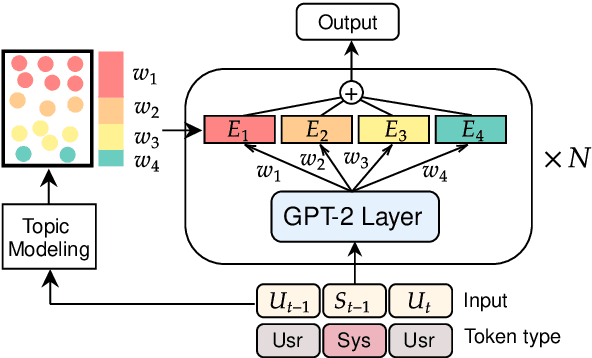
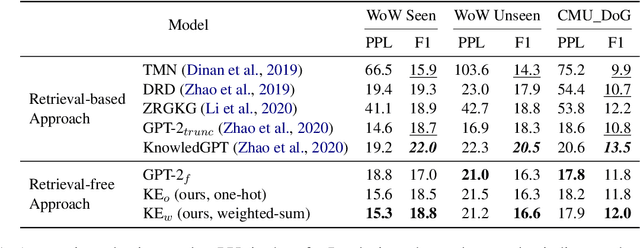
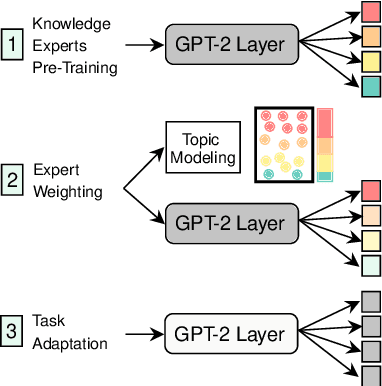

To diversify and enrich generated dialogue responses, knowledge-grounded dialogue has been investigated in recent years. Despite the success of the existing methods, they mainly follow the paradigm of retrieving the relevant sentences over a large corpus and augment the dialogues with explicit extra information, which is time- and resource-consuming. In this paper, we propose KnowExpert, an end-to-end framework to bypass the retrieval process by injecting prior knowledge into the pre-trained language models with lightweight adapters. To the best of our knowledge, this is the first attempt to tackle this task relying solely on a generation-based approach. Experimental results show that KnowExpert performs comparably with the retrieval-based baselines, demonstrating the potential of our proposed direction.
Learning Aberrance Repressed Correlation Filters for Real-Time UAV Tracking
Aug 07, 2019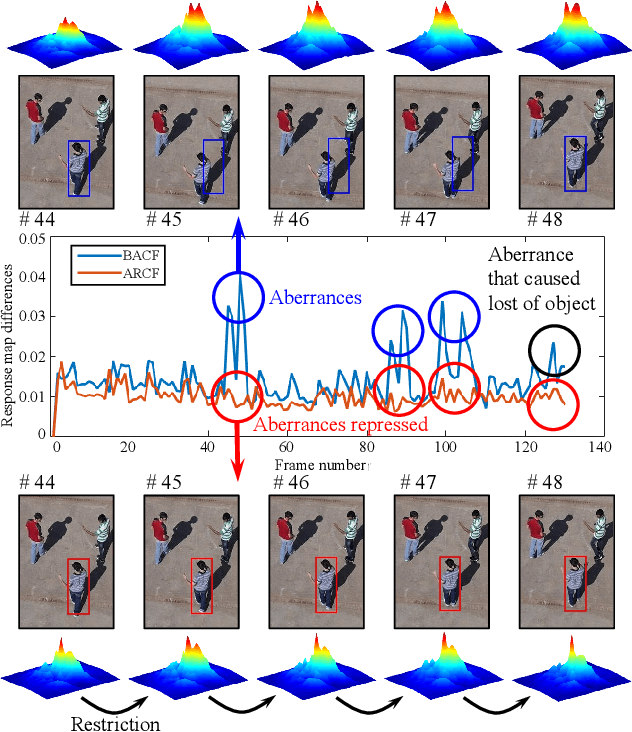
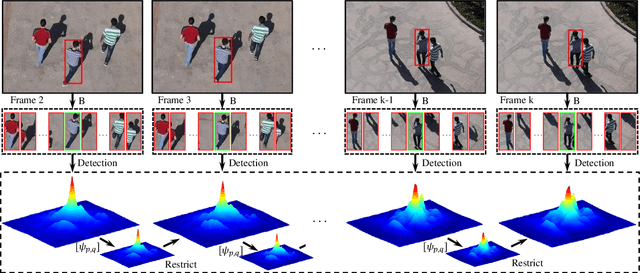
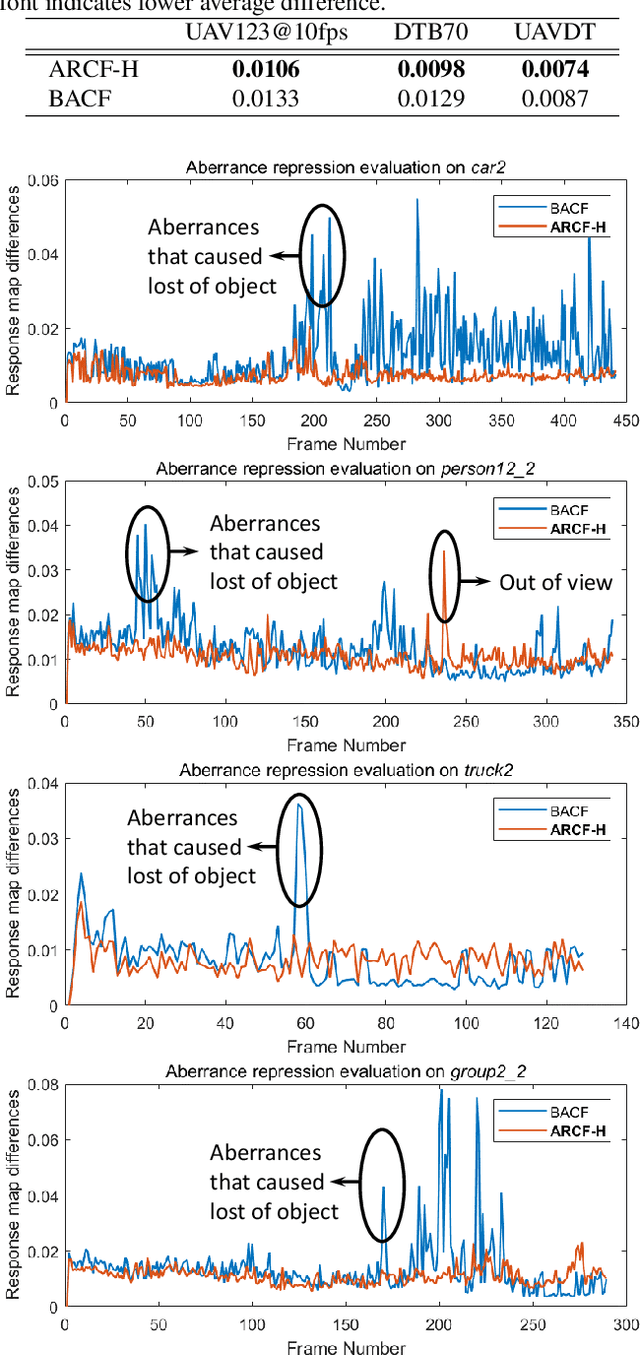
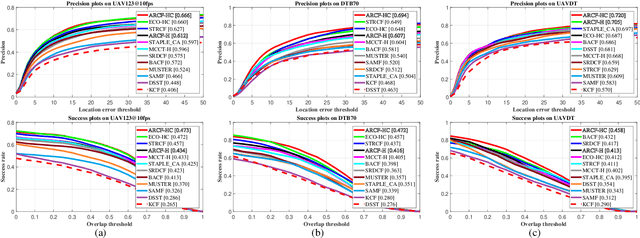
Traditional framework of discriminative correlation filters (DCF) is often subject to undesired boundary effects. Several approaches to enlarge search regions have been already proposed in the past years to make up for this shortcoming. However, with excessive background information, more background noises are also introduced and the discriminative filter is prone to learn from the ambiance rather than the object. This situation, along with appearance changes of objects caused by full/partial occlusion, illumination variation, and other reasons has made it more likely to have aberrances in the detection process, which could substantially degrade the credibility of its result. Therefore, in this work, a novel approach to repress the aberrances happening during the detection process is proposed, i.e., aberrance repressed correlation filter (ARCF). By enforcing restriction to the rate of alteration in response maps generated in the detection phase, the ARCF tracker can evidently suppress aberrances and is thus more robust and accurate to track objects. Considerable experiments are conducted on different UAV datasets to perform object tracking from an aerial view, i.e., UAV123, UAVDT, and DTB70, with 243 challenging image sequences containing over 90K frames to verify the performance of the ARCF tracker and it has proven itself to have outperformed other 20 state-of-the-art trackers based on DCF and deep-based frameworks with sufficient speed for real-time applications.
An Online Riemannian PCA for Stochastic Canonical Correlation Analysis
Jun 08, 2021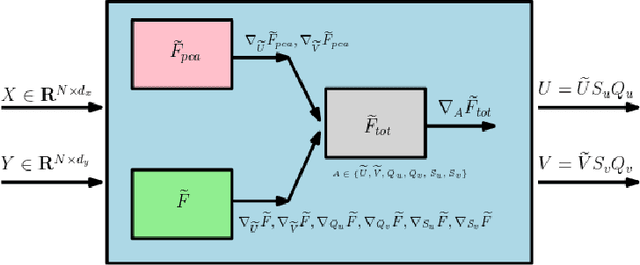
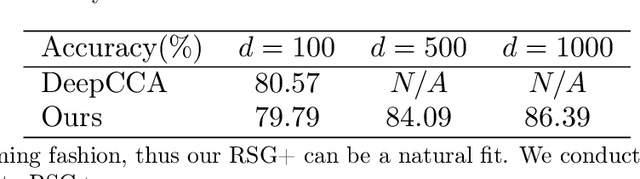
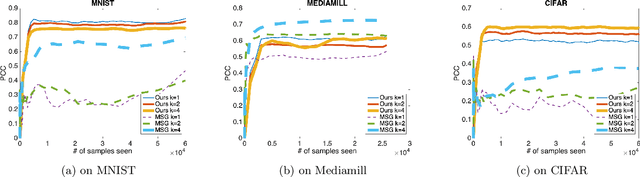
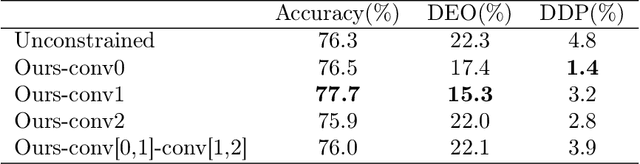
We present an efficient stochastic algorithm (RSG+) for canonical correlation analysis (CCA) using a reparametrization of the projection matrices. We show how this reparametrization (into structured matrices), simple in hindsight, directly presents an opportunity to repurpose/adjust mature techniques for numerical optimization on Riemannian manifolds. Our developments nicely complement existing methods for this problem which either require $O(d^3)$ time complexity per iteration with $O(\frac{1}{\sqrt{t}})$ convergence rate (where $d$ is the dimensionality) or only extract the top $1$ component with $O(\frac{1}{t})$ convergence rate. In contrast, our algorithm offers a strict improvement for this classical problem: it achieves $O(d^2k)$ runtime complexity per iteration for extracting the top $k$ canonical components with $O(\frac{1}{t})$ convergence rate. While the paper primarily focuses on the formulation and technical analysis of its properties, our experiments show that the empirical behavior on common datasets is quite promising. We also explore a potential application in training fair models where the label of protected attribute is missing or otherwise unavailable.
A Microarchitecture Implementation Framework for Online Learning with Temporal Neural Networks
May 27, 2021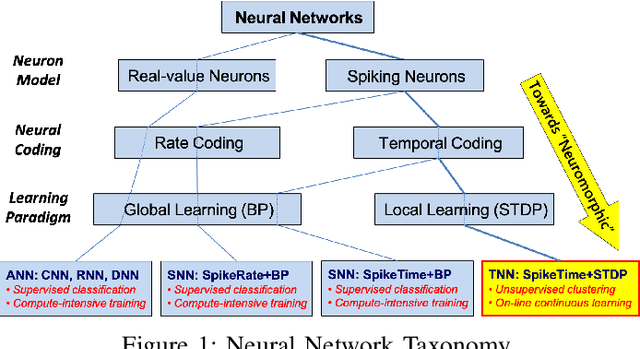

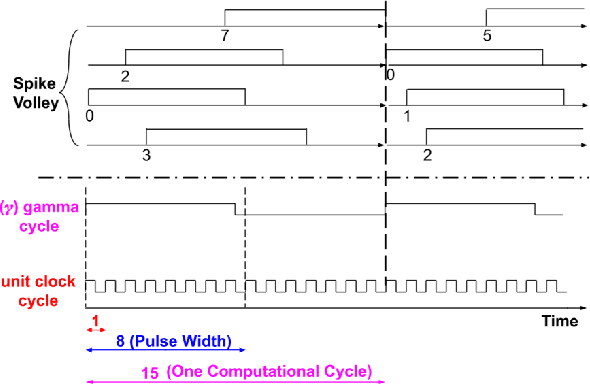
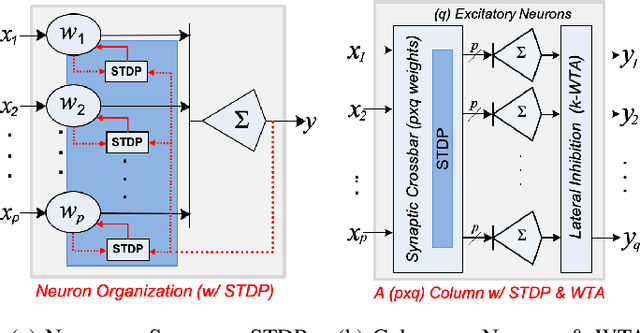
Temporal Neural Networks (TNNs) are spiking neural networks that use time as a resource to represent and process information, similar to the mammalian neocortex. In contrast to compute-intensive Deep Neural Networks that employ separate training and inference phases, TNNs are capable of extremely efficient online incremental/continuous learning and are excellent candidates for building edge-native sensory processing units. This work proposes a microarchitecture framework for implementing TNNs using standard CMOS. Gate-level implementations of three key building blocks are presented: 1) multi-synapse neurons, 2) multi-neuron columns, and 3) unsupervised and supervised online learning algorithms based on Spike Timing Dependent Plasticity (STDP). The TNN microarchitecture is embodied in a set of characteristic scaling equations for assessing the gate count, area, delay and power consumption for any TNN design. Post-synthesis results (in 45nm CMOS) for the proposed designs are presented, and their online incremental learning capability is demonstrated.
Self-Supervised Video Representation Learning with Space-Time Cubic Puzzles
Nov 24, 2018
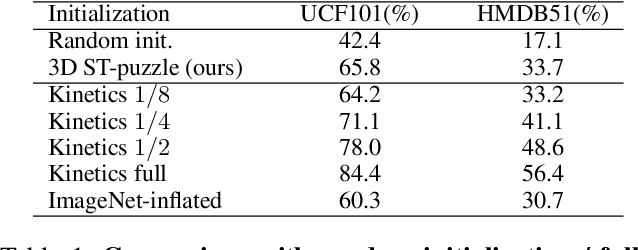
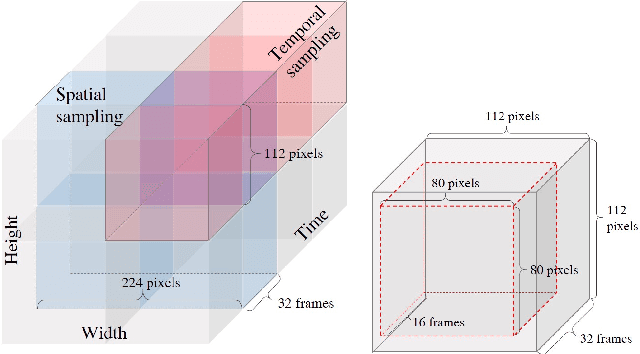

Self-supervised tasks such as colorization, inpainting and zigsaw puzzle have been utilized for visual representation learning for still images, when the number of labeled images is limited or absent at all. Recently, this worthwhile stream of study extends to video domain where the cost of human labeling is even more expensive. However, the most of existing methods are still based on 2D CNN architectures that can not directly capture spatio-temporal information for video applications. In this paper, we introduce a new self-supervised task called as \textit{Space-Time Cubic Puzzles} to train 3D CNNs using large scale video dataset. This task requires a network to arrange permuted 3D spatio-temporal crops. By completing \textit{Space-Time Cubic Puzzles}, the network learns both spatial appearance and temporal relation of video frames, which is our final goal. In experiments, we demonstrate that our learned 3D representation is well transferred to action recognition tasks, and outperforms state-of-the-art 2D CNN-based competitors on UCF101 and HMDB51 datasets.