 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Text Summarization with Latent Queries
May 31, 2021
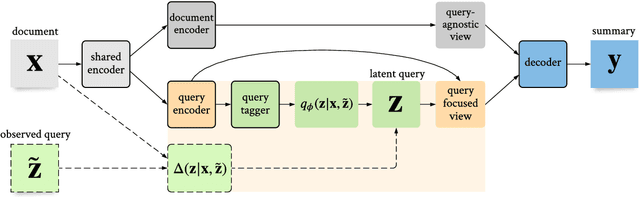


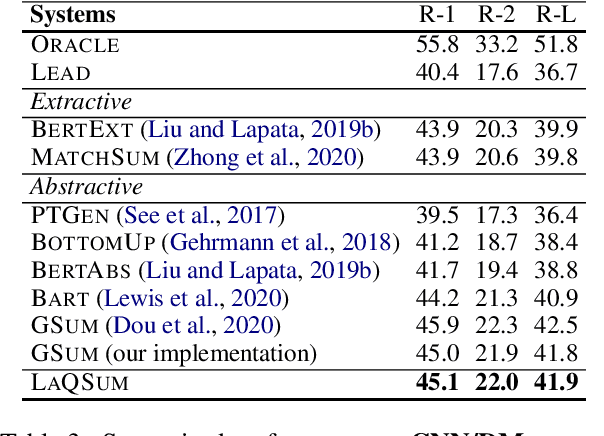
The availability of large-scale datasets has driven the development of neural models that create summaries from single documents, for generic purposes. When using a summarization system, users often have specific intents with various language realizations, which, depending on the information need, can range from a single keyword to a long narrative composed of multiple questions. Existing summarization systems, however, often either fail to support or act robustly on this query focused summarization task. We introduce LaQSum, the first unified text summarization system that learns Latent Queries from documents for abstractive summarization with any existing query forms. Under a deep generative framework, our system jointly optimizes a latent query model and a conditional language model, allowing users to plug-and-play queries of any type at test time. Despite learning from only generic summarization data and requiring no further optimization for downstream summarization tasks, our system robustly outperforms strong comparison systems across summarization benchmarks with different query types, document settings, and target domains.
Retrieval-Free Knowledge-Grounded Dialogue Response Generation with Adapters
May 13, 2021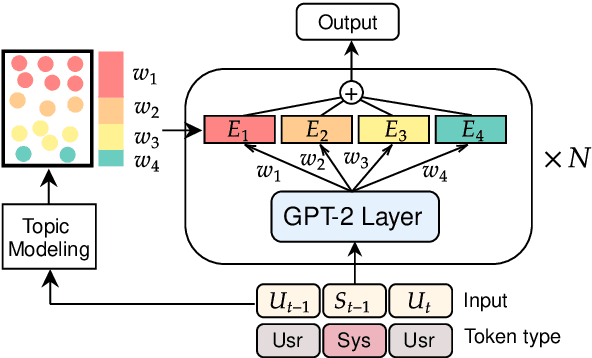
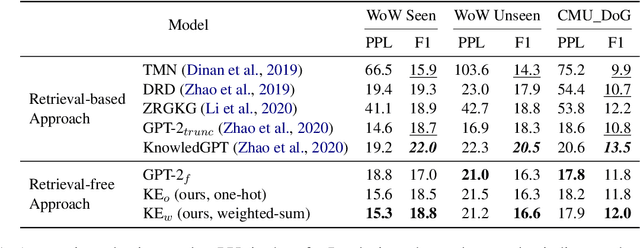
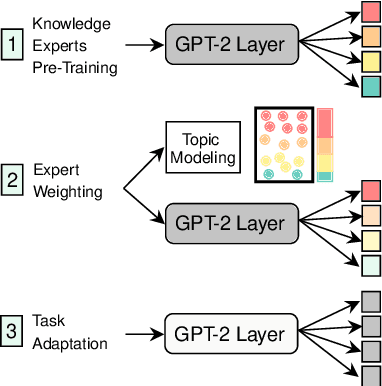

To diversify and enrich generated dialogue responses, knowledge-grounded dialogue has been investigated in recent years. Despite the success of the existing methods, they mainly follow the paradigm of retrieving the relevant sentences over a large corpus and augment the dialogues with explicit extra information, which is time- and resource-consuming. In this paper, we propose KnowExpert, an end-to-end framework to bypass the retrieval process by injecting prior knowledge into the pre-trained language models with lightweight adapters. To the best of our knowledge, this is the first attempt to tackle this task relying solely on a generation-based approach. Experimental results show that KnowExpert performs comparably with the retrieval-based baselines, demonstrating the potential of our proposed direction.
Attribute-aware Explainable Complementary Clothing Recommendation
Jul 04, 2021
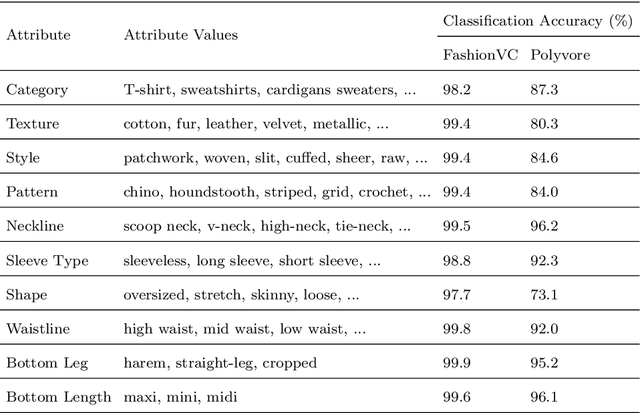
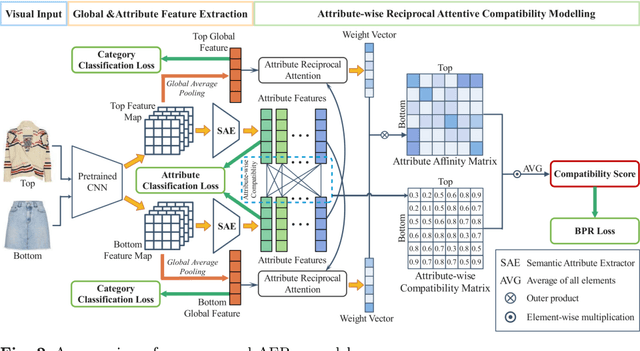
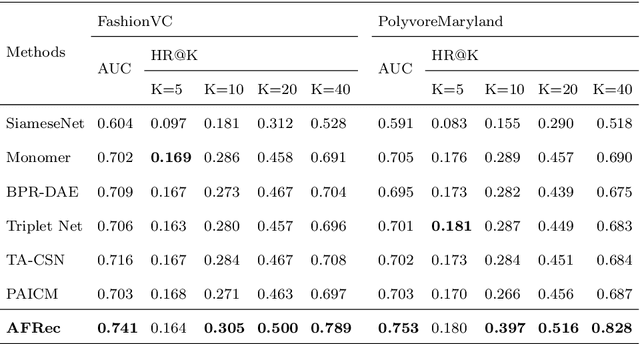
Modelling mix-and-match relationships among fashion items has become increasingly demanding yet challenging for modern E-commerce recommender systems. When performing clothes matching, most existing approaches leverage the latent visual features extracted from fashion item images for compatibility modelling, which lacks explainability of generated matching results and can hardly convince users of the recommendations. Though recent methods start to incorporate pre-defined attribute information (e.g., colour, style, length, etc.) for learning item representations and improving the model interpretability, their utilisation of attribute information is still mainly reserved for enhancing the learned item representations and generating explanations via post-processing. As a result, this creates a severe bottleneck when we are trying to advance the recommendation accuracy and generating fine-grained explanations since the explicit attributes have only loose connections to the actual recommendation process. This work aims to tackle the explainability challenge in fashion recommendation tasks by proposing a novel Attribute-aware Fashion Recommender (AFRec). Specifically, AFRec recommender assesses the outfit compatibility by explicitly leveraging the extracted attribute-level representations from each item's visual feature. The attributes serve as the bridge between two fashion items, where we quantify the affinity of a pair of items through the learned compatibility between their attributes. Extensive experiments have demonstrated that, by making full use of the explicit attributes in the recommendation process, AFRec is able to achieve state-of-the-art recommendation accuracy and generate intuitive explanations at the same time.
Compact User-Side Reconfigurable Intelligent Surfaces for Uplink Transmission
Jul 19, 2021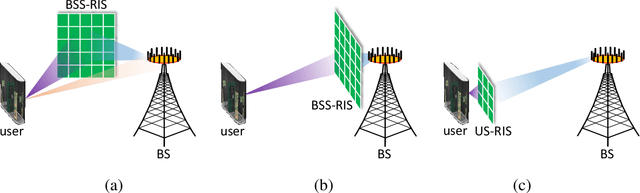
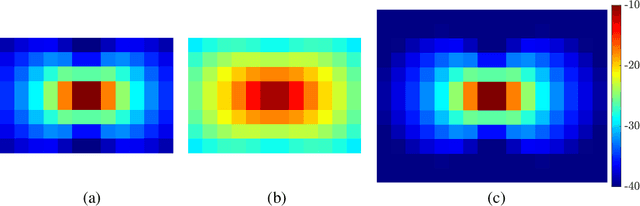
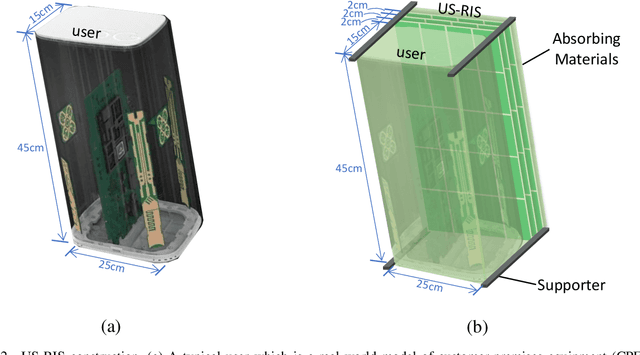
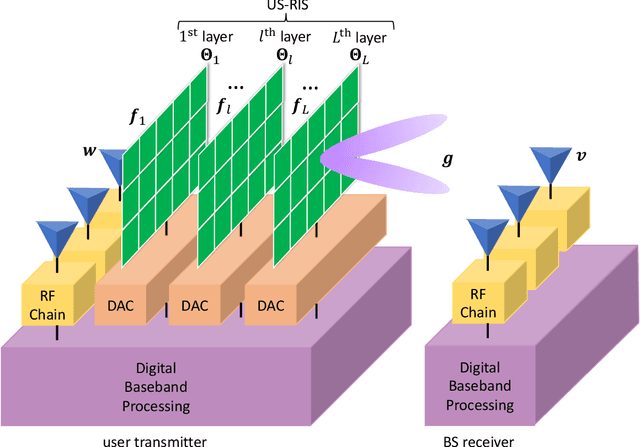
Large-scale antenna arrays employed by the base station (BS) constitute an essential next-generation communications technique. However, due to the constraints of size, cost, and power consumption, it is usually considered unrealistic to use a large-scale antenna array at the user side. Inspired by the emerging technique of reconfigurable intelligent surfaces (RIS), we firstly propose the concept of user-side RIS (US-RIS) for facilitating the employment of a large-scale antenna array at the user side in a cost- and energy-efficient way. In contrast to the existing employments of RIS, which belong to the family of base-station-side RISs (BSS-RISs), the US-RIS concept by definition facilitates the employment of RIS at the user side for the first time. This is achieved by conceiving a multi-layer structure to realize a compact form-factor. Furthermore, our theoretical results demonstrate that, in contrast to the existing single-layer structure, where only the phase of the signal reflected from RIS can be adjusted, the amplitude of the signal penetrating multi-layer US-RIS can also be partially controlled, which brings about a new degree of freedom (DoF) for beamformer design that can be beneficially exploited for performance enhancement. In addition, based on the proposed multi-layer US-RIS, we formulate the signal-to-noise ratio (SNR) maximization problem of US-RIS-aided communications. Due to the non-convexity of the problem introduced by this multi-layer structure, we propose a multi-layer transmit beamformer design relying on an iterative algorithm for finding the optimal solution by alternately updating each variable. Finally, our simulation results verify the superiority of the proposed multi-layer US-RIS as a compact realization of a large-scale antenna array at the user side for uplink transmission.
TIMEDIAL: Temporal Commonsense Reasoning in Dialog
Jun 08, 2021
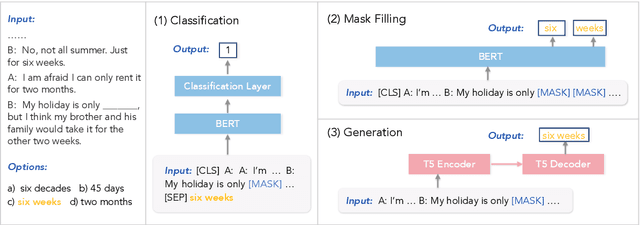

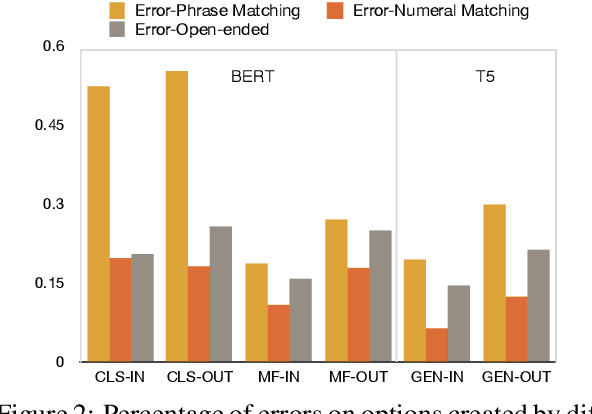
Everyday conversations require understanding everyday events, which in turn, requires understanding temporal commonsense concepts interwoven with those events. Despite recent progress with massive pre-trained language models (LMs) such as T5 and GPT-3, their capability of temporal reasoning in dialogs remains largely under-explored. In this paper, we present the first study to investigate pre-trained LMs for their temporal reasoning capabilities in dialogs by introducing a new task and a crowd-sourced English challenge set, TIMEDIAL. We formulate TIME-DIAL as a multiple-choice cloze task with over 1.1K carefully curated dialogs. Empirical results demonstrate that even the best performing models struggle on this task compared to humans, with 23 absolute points of gap in accuracy. Furthermore, our analysis reveals that the models fail to reason about dialog context correctly; instead, they rely on shallow cues based on existing temporal patterns in context, motivating future research for modeling temporal concepts in text and robust contextual reasoning about them. The dataset is publicly available at: https://github.com/google-research-datasets/timedial.
Sublinear Least-Squares Value Iteration via Locality Sensitive Hashing
Jun 08, 2021
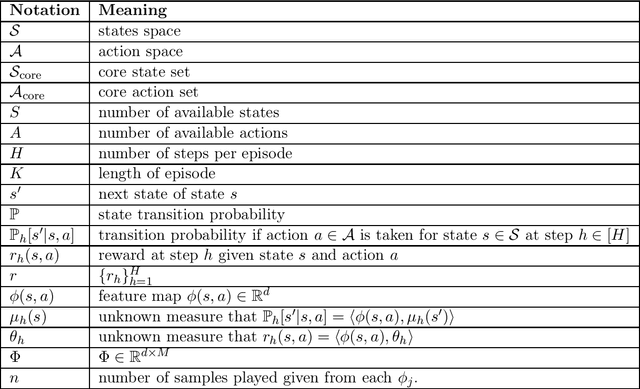
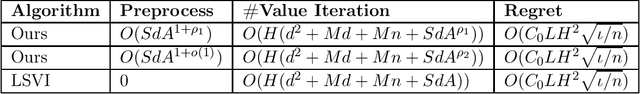

We present the first provable Least-Squares Value Iteration (LSVI) algorithms that have runtime complexity sublinear in the number of actions. We formulate the value function estimation procedure in value iteration as an approximate maximum inner product search problem and propose a locality sensitive hashing (LSH) [Indyk and Motwani STOC'98, Andoni and Razenshteyn STOC'15, Andoni, Laarhoven, Razenshteyn and Waingarten SODA'17] type data structure to solve this problem with sublinear time complexity. Moreover, we build the connections between the theory of approximate maximum inner product search and the regret analysis of reinforcement learning. We prove that, with our choice of approximation factor, our Sublinear LSVI algorithms maintain the same regret as the original LSVI algorithms while reducing the runtime complexity to sublinear in the number of actions. To the best of our knowledge, this is the first work that combines LSH with reinforcement learning resulting in provable improvements. We hope that our novel way of combining data-structures and iterative algorithm will open the door for further study into cost reduction in optimization.
FONTNET: On-Device Font Understanding and Prediction Pipeline
Mar 30, 2021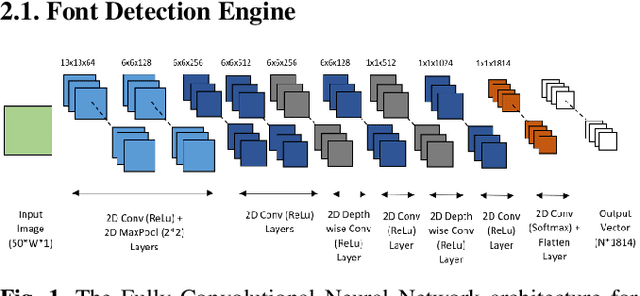
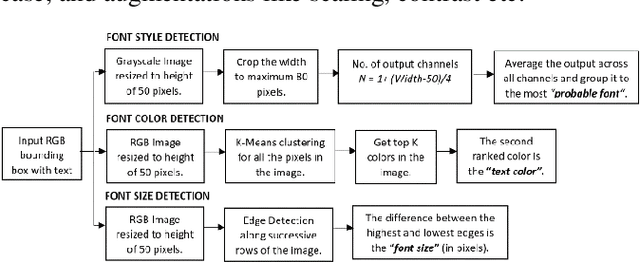
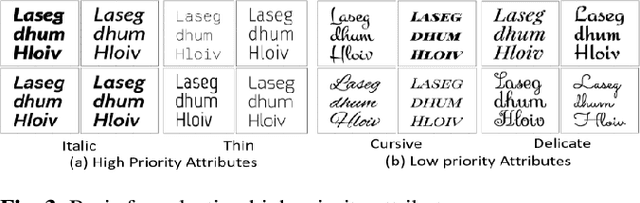
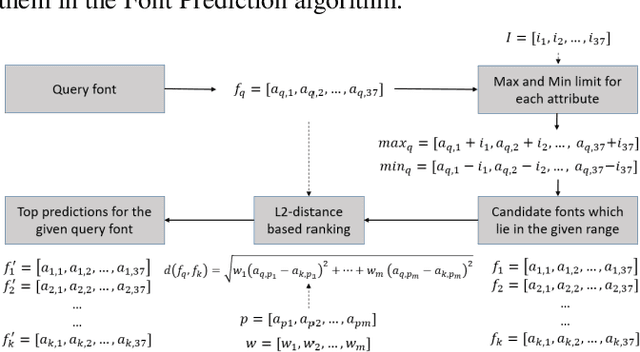
Fonts are one of the most basic and core design concepts. Numerous use cases can benefit from an in depth understanding of Fonts such as Text Customization which can change text in an image while maintaining the Font attributes like style, color, size. Currently, Text recognition solutions can group recognized text based on line breaks or paragraph breaks, if the Font attributes are known multiple text blocks can be combined based on context in a meaningful manner. In this paper, we propose two engines: Font Detection Engine, which identifies the font style, color and size attributes of text in an image and a Font Prediction Engine, which predicts similar fonts for a query font. Major contributions of this paper are three-fold: First, we developed a novel CNN architecture for identifying font style of text in images. Second, we designed a novel algorithm for predicting similar fonts for a given query font. Third, we have optimized and deployed the entire engine On-Device which ensures privacy and improves latency in real time applications such as instant messaging. We achieve a worst case On-Device inference time of 30ms and a model size of 4.5MB for both the engines.
MoCo-Flow: Neural Motion Consensus Flow for Dynamic Humans in Stationary Monocular Cameras
Jun 08, 2021

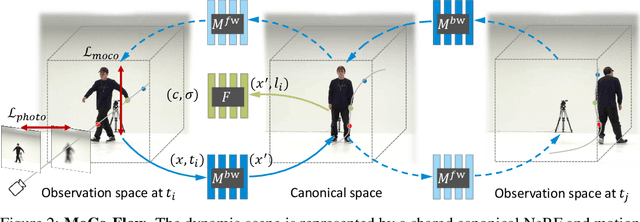

Synthesizing novel views of dynamic humans from stationary monocular cameras is a popular scenario. This is particularly attractive as it does not require static scenes, controlled environments, or specialized hardware. In contrast to techniques that exploit multi-view observations to constrain the modeling, given a single fixed viewpoint only, the problem of modeling the dynamic scene is significantly more under-constrained and ill-posed. In this paper, we introduce Neural Motion Consensus Flow (MoCo-Flow), a representation that models the dynamic scene using a 4D continuous time-variant function. The proposed representation is learned by an optimization which models a dynamic scene that minimizes the error of rendering all observation images. At the heart of our work lies a novel optimization formulation, which is constrained by a motion consensus regularization on the motion flow. We extensively evaluate MoCo-Flow on several datasets that contain human motions of varying complexity, and compare, both qualitatively and quantitatively, to several baseline methods and variants of our methods. Pretrained model, code, and data will be released for research purposes upon paper acceptance.
Factorising Meaning and Form for Intent-Preserving Paraphrasing
May 31, 2021
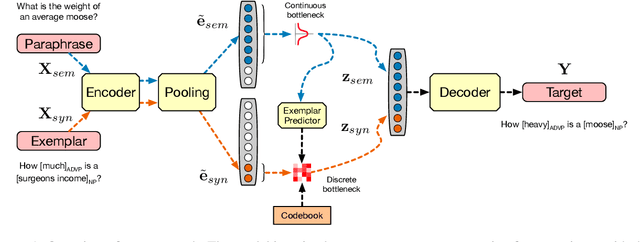

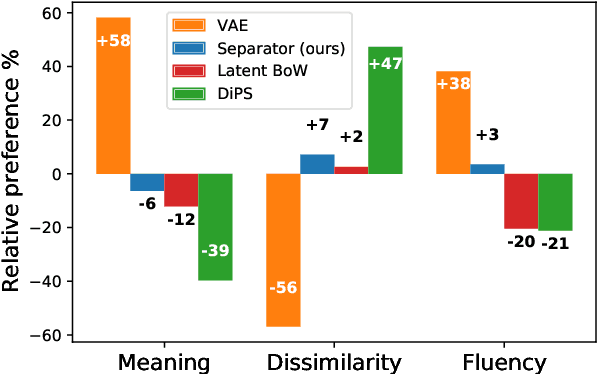
We propose a method for generating paraphrases of English questions that retain the original intent but use a different surface form. Our model combines a careful choice of training objective with a principled information bottleneck, to induce a latent encoding space that disentangles meaning and form. We train an encoder-decoder model to reconstruct a question from a paraphrase with the same meaning and an exemplar with the same surface form, leading to separated encoding spaces. We use a Vector-Quantized Variational Autoencoder to represent the surface form as a set of discrete latent variables, allowing us to use a classifier to select a different surface form at test time. Crucially, our method does not require access to an external source of target exemplars. Extensive experiments and a human evaluation show that we are able to generate paraphrases with a better tradeoff between semantic preservation and syntactic novelty compared to previous methods.
Embedded Vision for Self-Driving on Forest Roads
May 27, 2021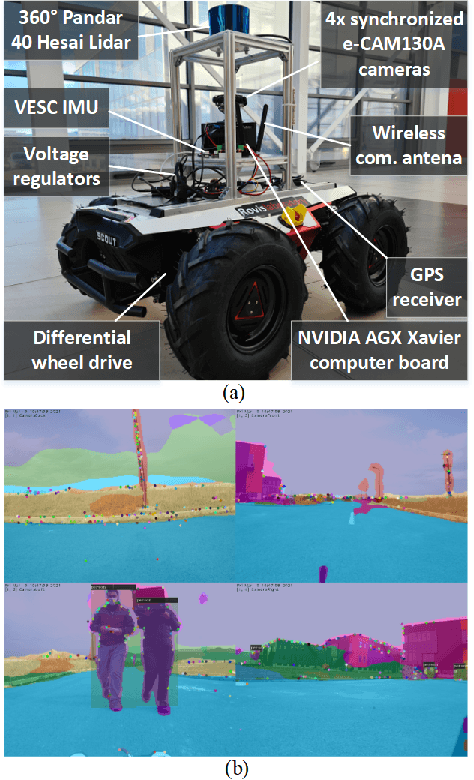
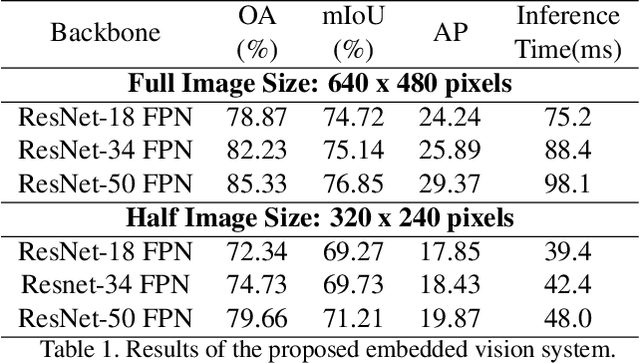
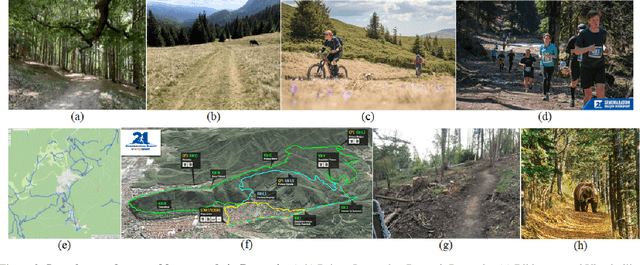
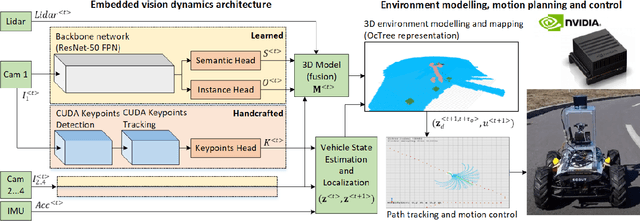
Forest roads in Romania are unique natural wildlife sites used for recreation by countless tourists. In order to protect and maintain these roads, we propose RovisLab AMTU (Autonomous Mobile Test Unit), which is a robotic system designed to autonomously navigate off-road terrain and inspect if any deforestation or damage occurred along tracked route. AMTU's core component is its embedded vision module, optimized for real-time environment perception. For achieving a high computation speed, we use a learning system to train a multi-task Deep Neural Network (DNN) for scene and instance segmentation of objects, while the keypoints required for simultaneous localization and mapping are calculated using a handcrafted FAST feature detector and the Lucas-Kanade tracking algorithm. Both the DNN and the handcrafted backbone are run in parallel on the GPU of an NVIDIA AGX Xavier board. We show experimental results on the test track of our research facility.