 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semi-Supervised Training with Pseudo-Labeling for End-to-End Neural Diarization
Jun 09, 2021
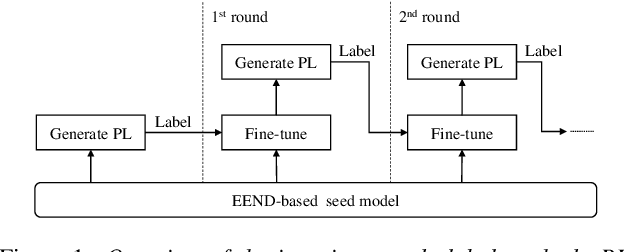
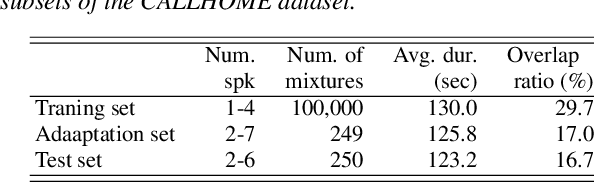
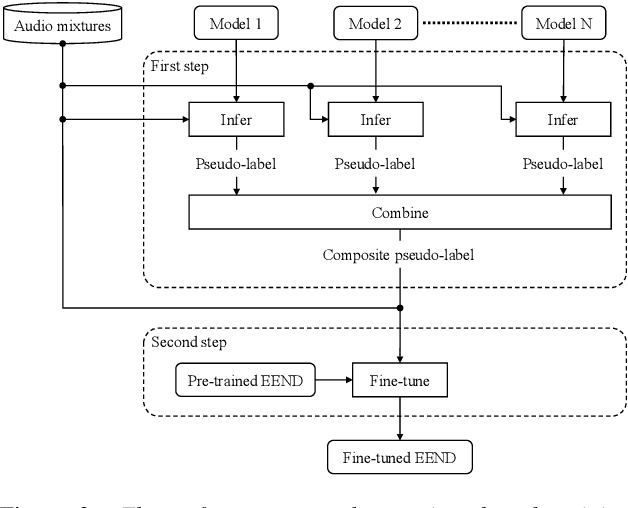
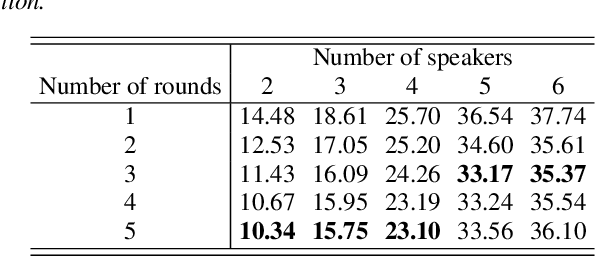
In this paper, we present a semi-supervised training technique using pseudo-labeling for end-to-end neural diarization (EEND). The EEND system has shown promising performance compared with traditional clustering-based methods, especially in the case of overlapping speech. However, to get a well-tuned model, EEND requires labeled data for all the joint speech activities of every speaker at each time frame in a recording. In this paper, we explore a pseudo-labeling approach that employs unlabeled data. First, we propose an iterative pseudo-label method for EEND, which trains the model using unlabeled data of a target condition. Then, we also propose a committee-based training method to improve the performance of EEND. To evaluate our proposed method, we conduct the experiments of model adaptation using labeled and unlabeled data. Experimental results on the CALLHOME dataset show that our proposed pseudo-label achieved a 37.4% relative diarization error rate reduction compared to a seed model. Moreover, we analyzed the results of semi-supervised adaptation with pseudo-labeling. We also show the effectiveness of our approach on the third DIHARD dataset.
Discovering the Information that is lost in our Databases -- Why bother storing data if you can't find the information?
May 18, 2021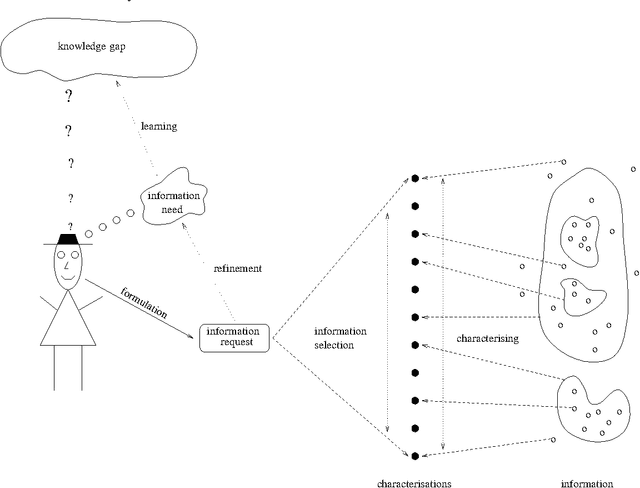
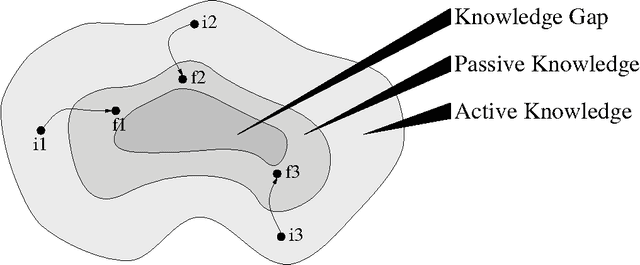
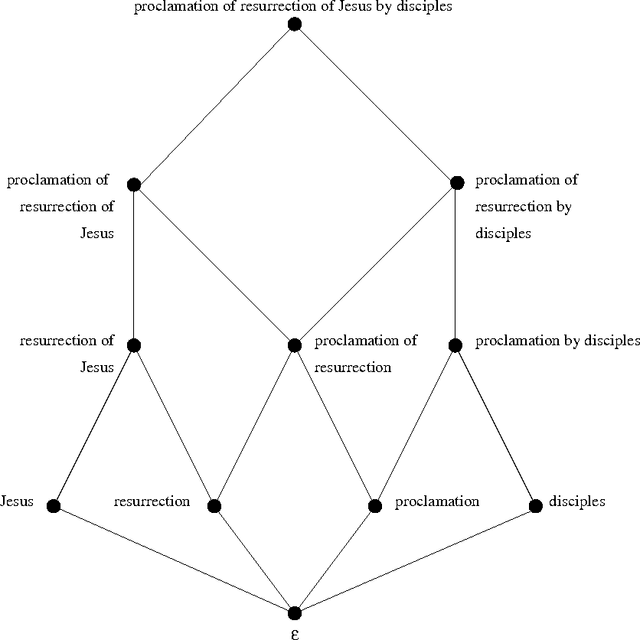
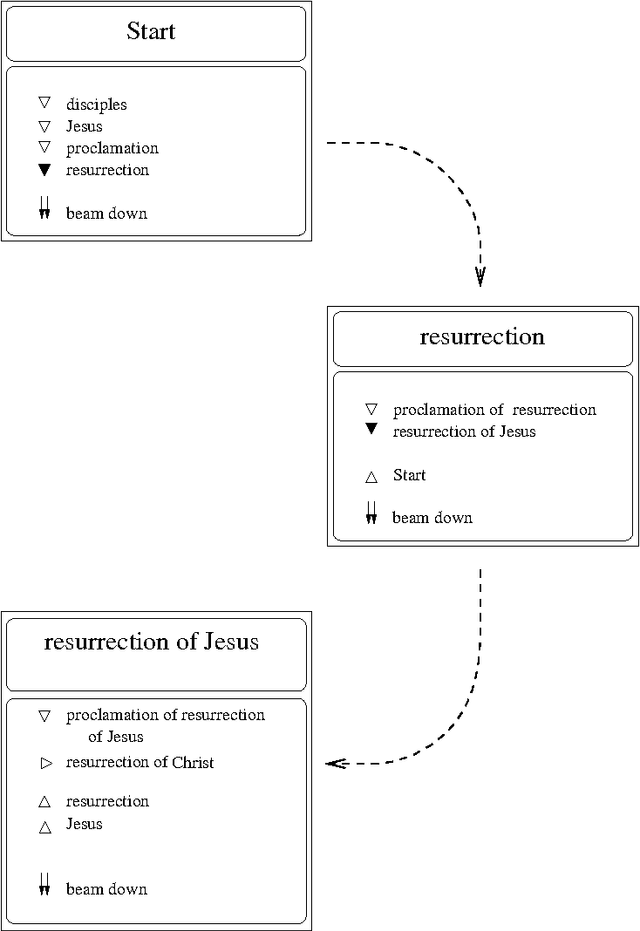
We are surrounded by an ever increasing amount of data that is stored in a variety of databases. In this article we will use a very liberal definition of \EM{database}. Basically any collection of data can be regarded as a database, ranging from the files in a directory on a disk, to ftp and web servers, through to relational or object-oriented databases. The sole reason for storing data in databases is that there is an anticipated need for the stored data at some time in the future. This means that providing smooth access paths by which stored information can be retrieved is at least as important as ensuring integrity of the stored information. In practice, however, providing users with adequate avenues by which to access stored information has received far less attention.
An Online Riemannian PCA for Stochastic Canonical Correlation Analysis
Jun 08, 2021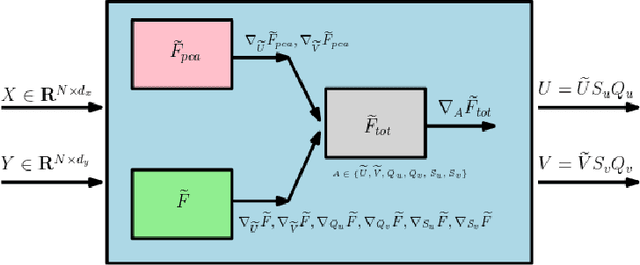
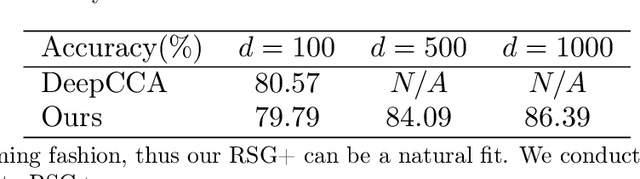
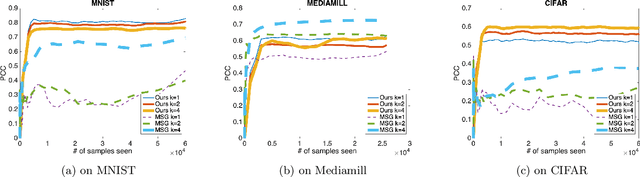
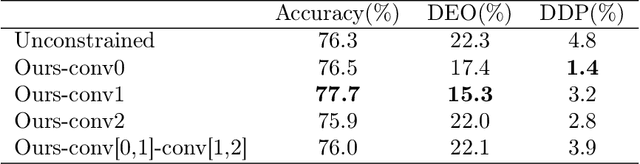
We present an efficient stochastic algorithm (RSG+) for canonical correlation analysis (CCA) using a reparametrization of the projection matrices. We show how this reparametrization (into structured matrices), simple in hindsight, directly presents an opportunity to repurpose/adjust mature techniques for numerical optimization on Riemannian manifolds. Our developments nicely complement existing methods for this problem which either require $O(d^3)$ time complexity per iteration with $O(\frac{1}{\sqrt{t}})$ convergence rate (where $d$ is the dimensionality) or only extract the top $1$ component with $O(\frac{1}{t})$ convergence rate. In contrast, our algorithm offers a strict improvement for this classical problem: it achieves $O(d^2k)$ runtime complexity per iteration for extracting the top $k$ canonical components with $O(\frac{1}{t})$ convergence rate. While the paper primarily focuses on the formulation and technical analysis of its properties, our experiments show that the empirical behavior on common datasets is quite promising. We also explore a potential application in training fair models where the label of protected attribute is missing or otherwise unavailable.
Mining Interpretable Spatio-temporal Logic Properties for Spatially Distributed Systems
Jun 16, 2021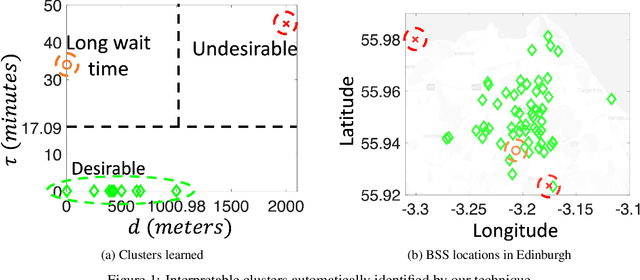

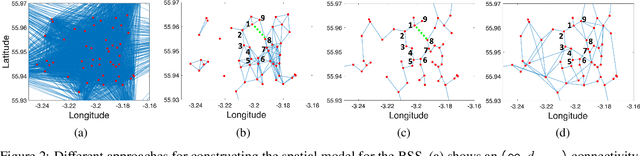

The Internet-of-Things, complex sensor networks, multi-agent cyber-physical systems are all examples of spatially distributed systems that continuously evolve in time. Such systems generate huge amounts of spatio-temporal data, and system designers are often interested in analyzing and discovering structure within the data. There has been considerable interest in learning causal and logical properties of temporal data using logics such as Signal Temporal Logic (STL); however, there is limited work on discovering such relations on spatio-temporal data. We propose the first set of algorithms for unsupervised learning for spatio-temporal data. Our method does automatic feature extraction from the spatio-temporal data by projecting it onto the parameter space of a parametric spatio-temporal reach and escape logic (PSTREL). We propose an agglomerative hierarchical clustering technique that guarantees that each cluster satisfies a distinct STREL formula. We show that our method generates STREL formulas of bounded description complexity using a novel decision-tree approach which generalizes previous unsupervised learning techniques for Signal Temporal Logic. We demonstrate the effectiveness of our approach on case studies from diverse domains such as urban transportation, epidemiology, green infrastructure, and air quality monitoring.
A Shapelet Transform for Multivariate Time Series Classification
Dec 18, 2017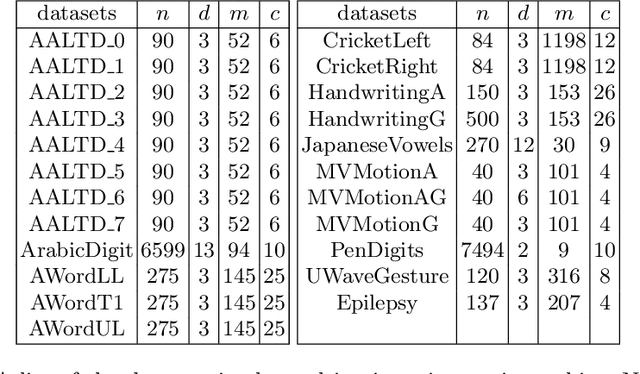
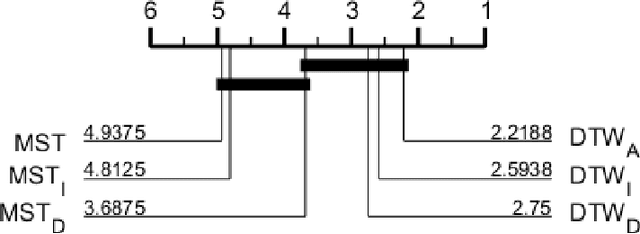
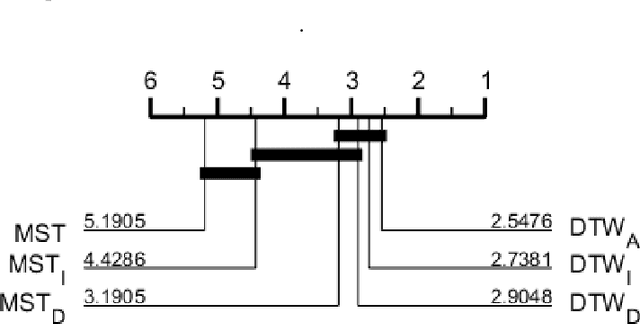
Shapelets are phase independent subsequences designed for time series classification. We propose three adaptations to the Shapelet Transform (ST) to capture multivariate features in multivariate time series classification. We create a unified set of data to benchmark our work on, and compare with three other algorithms. We demonstrate that multivariate shapelets are not significantly worse than other state-of-the-art algorithms.
Monocular Depth Estimation through Virtual-world Supervision and Real-world SfM Self-Supervision
Mar 22, 2021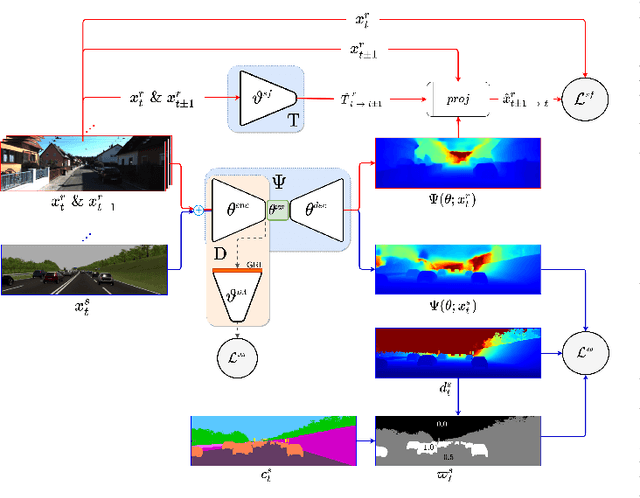
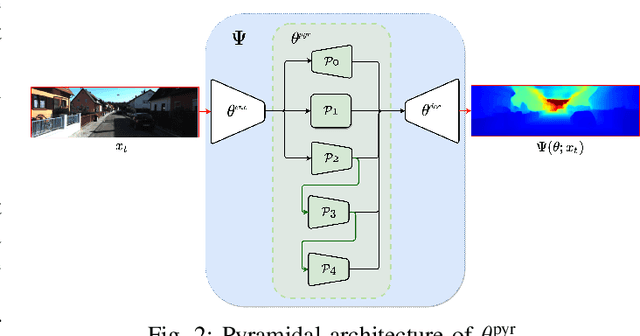
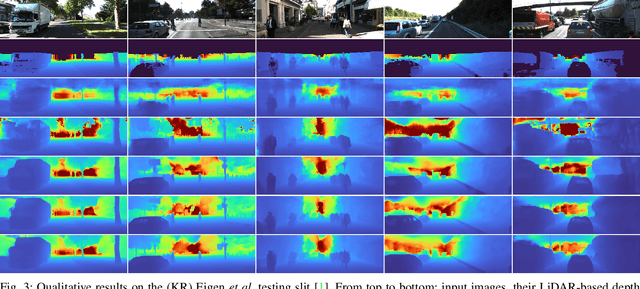
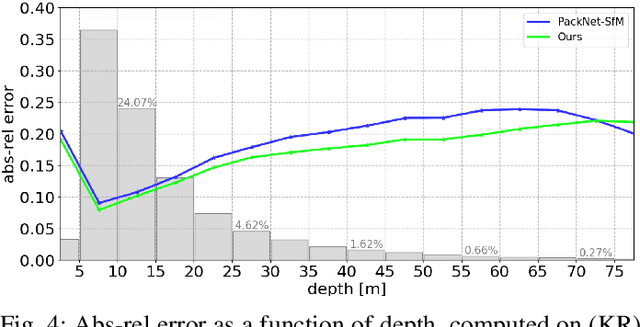
Depth information is essential for on-board perception in autonomous driving and driver assistance. Monocular depth estimation (MDE) is very appealing since it allows for appearance and depth being on direct pixelwise correspondence without further calibration. Best MDE models are based on Convolutional Neural Networks (CNNs) trained in a supervised manner, i.e., assuming pixelwise ground truth (GT). Usually, this GT is acquired at training time through a calibrated multi-modal suite of sensors. However, also using only a monocular system at training time is cheaper and more scalable. This is possible by relying on structure-from-motion (SfM) principles to generate self-supervision. Nevertheless, problems of camouflaged objects, visibility changes, static-camera intervals, textureless areas, and scale ambiguity, diminish the usefulness of such self-supervision. In this paper, we perform monocular depth estimation by virtual-world supervision (MonoDEVS) and real-world SfM self-supervision. We compensate the SfM self-supervision limitations by leveraging virtual-world images with accurate semantic and depth supervision and addressing the virtual-to-real domain gap. Our MonoDEVSNet outperforms previous MDE CNNs trained on monocular and even stereo sequences.
Compact User-Side Reconfigurable Intelligent Surfaces for Uplink Transmission
Jul 19, 2021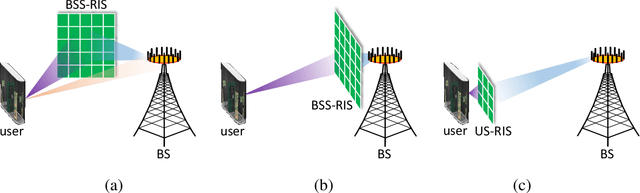
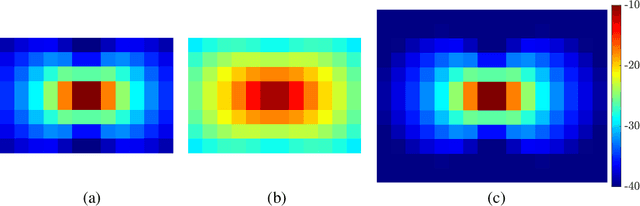
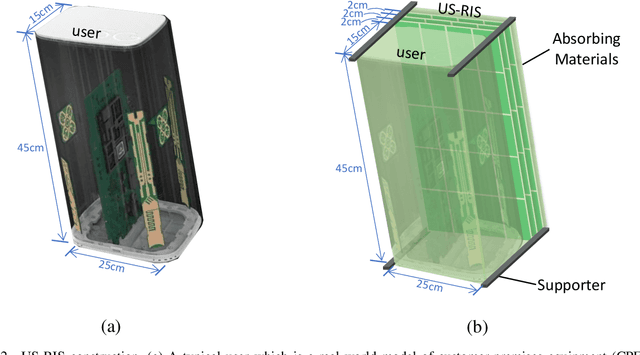
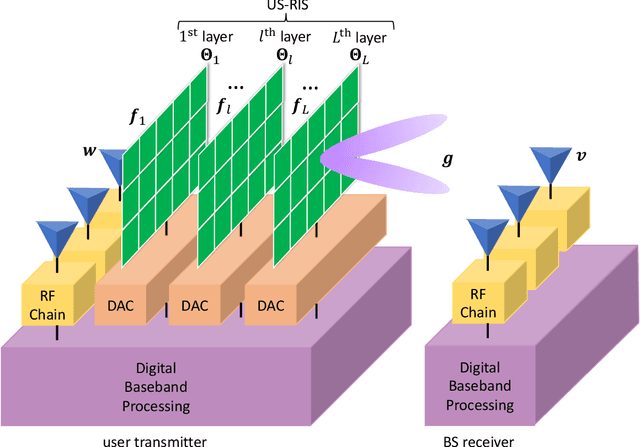
Large-scale antenna arrays employed by the base station (BS) constitute an essential next-generation communications technique. However, due to the constraints of size, cost, and power consumption, it is usually considered unrealistic to use a large-scale antenna array at the user side. Inspired by the emerging technique of reconfigurable intelligent surfaces (RIS), we firstly propose the concept of user-side RIS (US-RIS) for facilitating the employment of a large-scale antenna array at the user side in a cost- and energy-efficient way. In contrast to the existing employments of RIS, which belong to the family of base-station-side RISs (BSS-RISs), the US-RIS concept by definition facilitates the employment of RIS at the user side for the first time. This is achieved by conceiving a multi-layer structure to realize a compact form-factor. Furthermore, our theoretical results demonstrate that, in contrast to the existing single-layer structure, where only the phase of the signal reflected from RIS can be adjusted, the amplitude of the signal penetrating multi-layer US-RIS can also be partially controlled, which brings about a new degree of freedom (DoF) for beamformer design that can be beneficially exploited for performance enhancement. In addition, based on the proposed multi-layer US-RIS, we formulate the signal-to-noise ratio (SNR) maximization problem of US-RIS-aided communications. Due to the non-convexity of the problem introduced by this multi-layer structure, we propose a multi-layer transmit beamformer design relying on an iterative algorithm for finding the optimal solution by alternately updating each variable. Finally, our simulation results verify the superiority of the proposed multi-layer US-RIS as a compact realization of a large-scale antenna array at the user side for uplink transmission.
Attribute-aware Explainable Complementary Clothing Recommendation
Jul 04, 2021
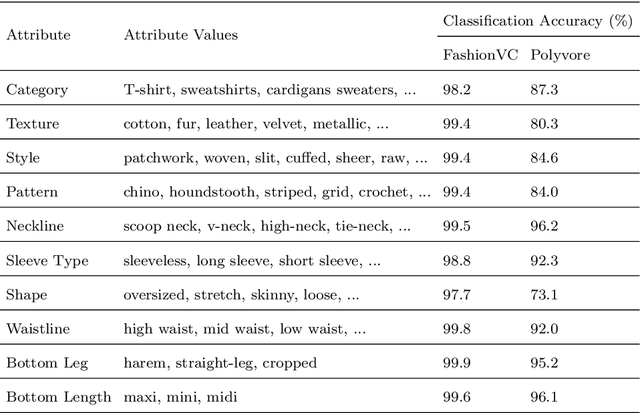
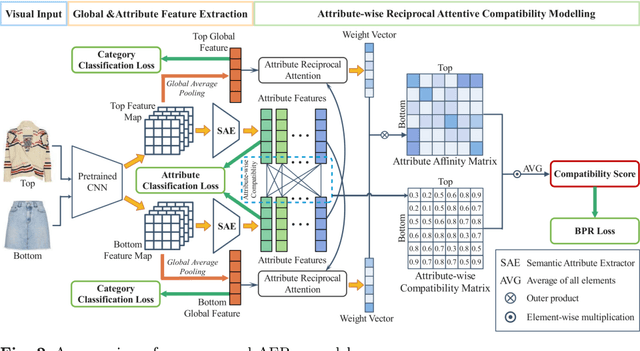
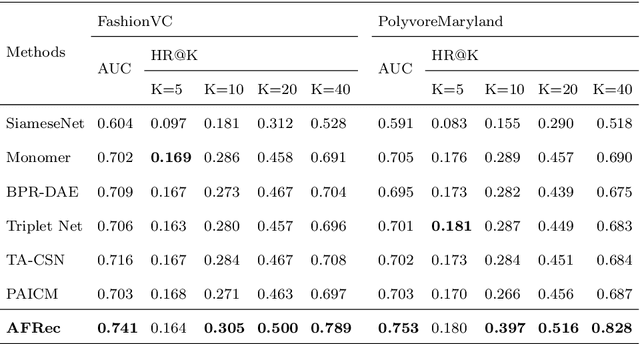
Modelling mix-and-match relationships among fashion items has become increasingly demanding yet challenging for modern E-commerce recommender systems. When performing clothes matching, most existing approaches leverage the latent visual features extracted from fashion item images for compatibility modelling, which lacks explainability of generated matching results and can hardly convince users of the recommendations. Though recent methods start to incorporate pre-defined attribute information (e.g., colour, style, length, etc.) for learning item representations and improving the model interpretability, their utilisation of attribute information is still mainly reserved for enhancing the learned item representations and generating explanations via post-processing. As a result, this creates a severe bottleneck when we are trying to advance the recommendation accuracy and generating fine-grained explanations since the explicit attributes have only loose connections to the actual recommendation process. This work aims to tackle the explainability challenge in fashion recommendation tasks by proposing a novel Attribute-aware Fashion Recommender (AFRec). Specifically, AFRec recommender assesses the outfit compatibility by explicitly leveraging the extracted attribute-level representations from each item's visual feature. The attributes serve as the bridge between two fashion items, where we quantify the affinity of a pair of items through the learned compatibility between their attributes. Extensive experiments have demonstrated that, by making full use of the explicit attributes in the recommendation process, AFRec is able to achieve state-of-the-art recommendation accuracy and generate intuitive explanations at the same time.
A Microarchitecture Implementation Framework for Online Learning with Temporal Neural Networks
May 27, 2021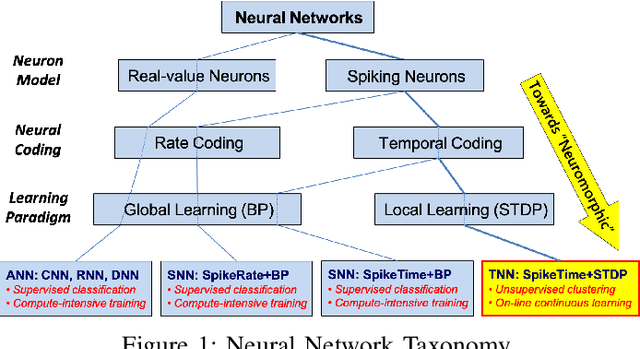

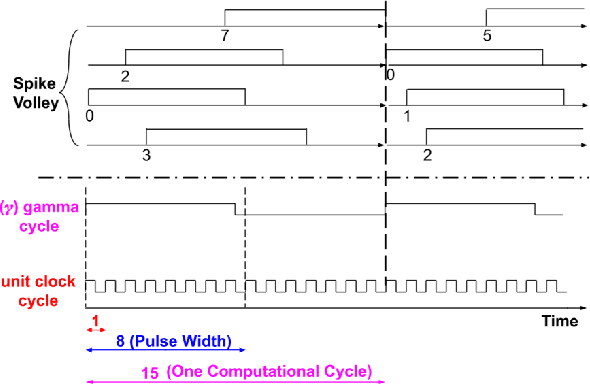
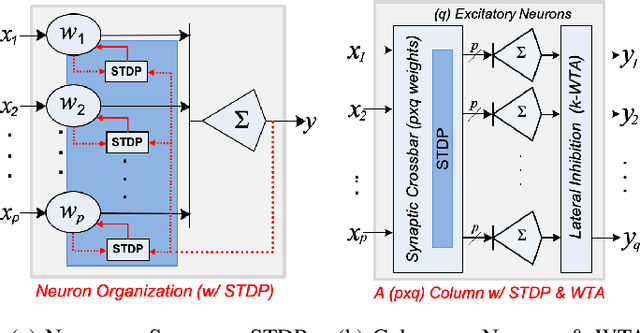
Temporal Neural Networks (TNNs) are spiking neural networks that use time as a resource to represent and process information, similar to the mammalian neocortex. In contrast to compute-intensive Deep Neural Networks that employ separate training and inference phases, TNNs are capable of extremely efficient online incremental/continuous learning and are excellent candidates for building edge-native sensory processing units. This work proposes a microarchitecture framework for implementing TNNs using standard CMOS. Gate-level implementations of three key building blocks are presented: 1) multi-synapse neurons, 2) multi-neuron columns, and 3) unsupervised and supervised online learning algorithms based on Spike Timing Dependent Plasticity (STDP). The TNN microarchitecture is embodied in a set of characteristic scaling equations for assessing the gate count, area, delay and power consumption for any TNN design. Post-synthesis results (in 45nm CMOS) for the proposed designs are presented, and their online incremental learning capability is demonstrated.
Gaussian Process Model for Estimating Piecewise Continuous Regression Functions
Apr 13, 2021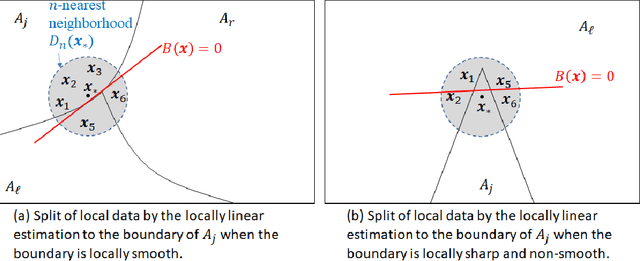
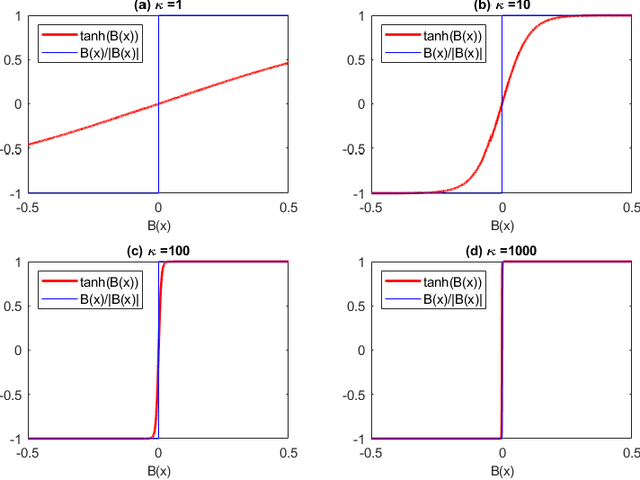
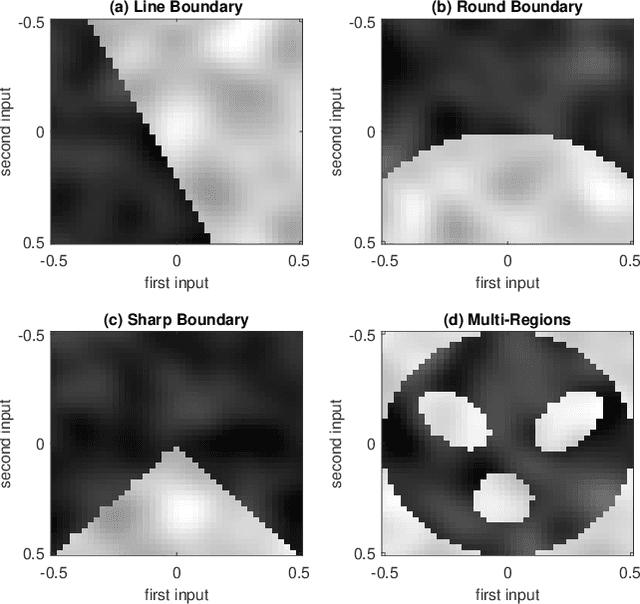
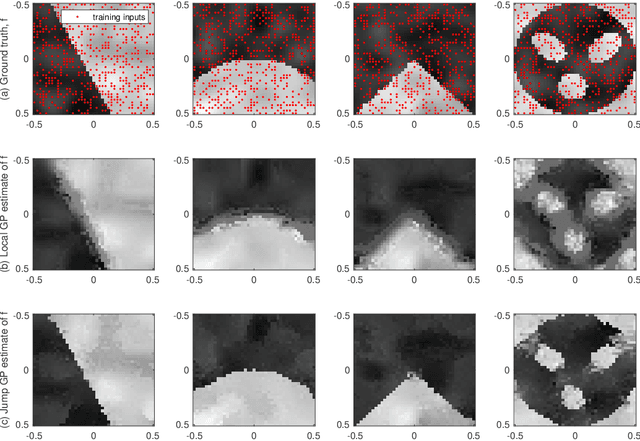
This paper presents a Gaussian process (GP) model for estimating piecewise continuous regression functions. In scientific and engineering applications of regression analysis, the underlying regression functions are piecewise continuous in that data follow different continuous regression models for different regions of the data with possible discontinuities between the regions. However, many conventional GP regression approaches are not designed for piecewise regression analysis. We propose a new GP modeling approach for estimating an unknown piecewise continuous regression function. The new GP model seeks for a local GP estimate of an unknown regression function at each test location, using local data neighboring to the test location. To accommodate the possibilities of the local data from different regions, the local data is partitioned into two sides by a local linear boundary, and only the local data belonging to the same side as the test location is used for the regression estimate. This local split works very well when the input regions are bounded by smooth boundaries, so the local linear approximation of the smooth boundaries works well. We estimate the local linear boundary jointly with the other hyperparameters of the GP model, using the maximum likelihood approach. Its computation time is as low as the local GP's time. The superior numerical performance of the proposed approach over the conventional GP modeling approaches is shown using various simulated piecewise regression functions.