 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Projection Algorithm for the Unitary Weights
Feb 19, 2021
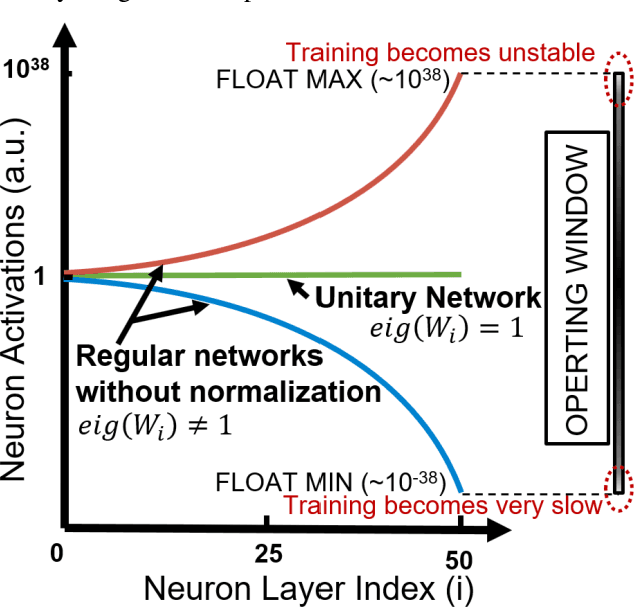
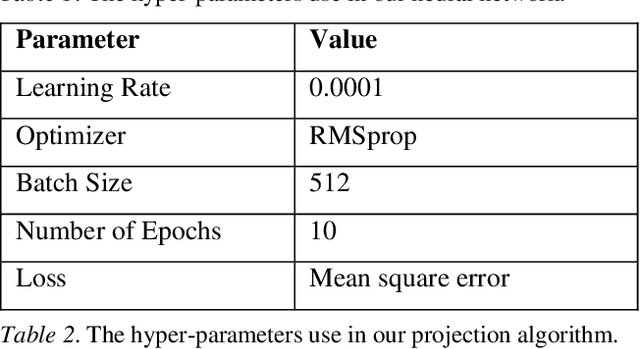
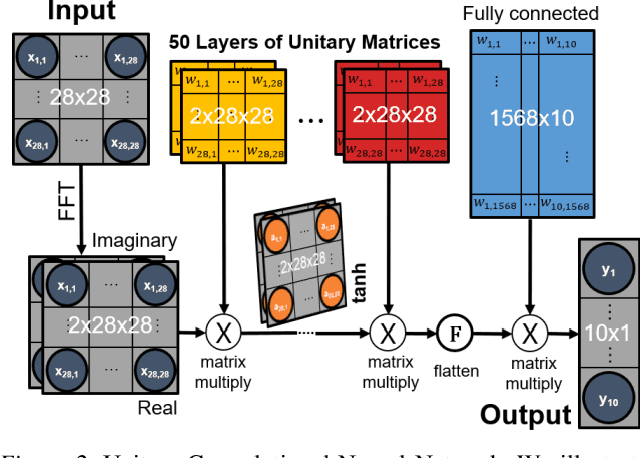
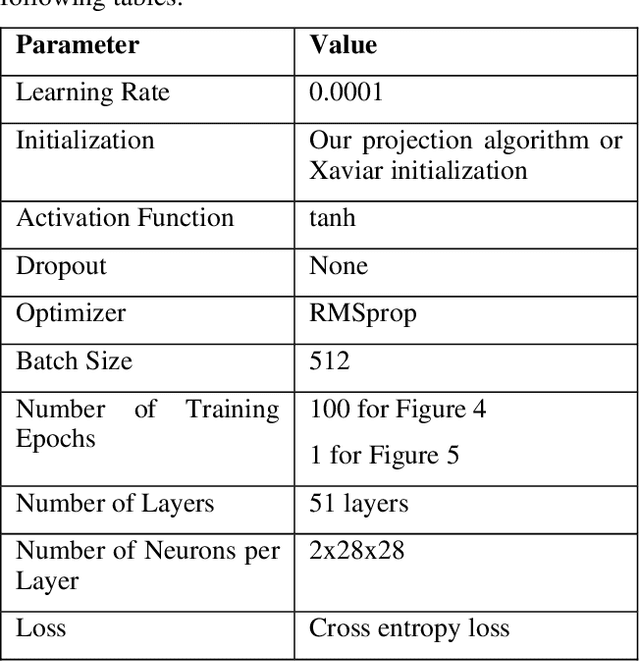
Unitary neural networks are promising alternatives for solving the exploding and vanishing activation/gradient problem without the need for explicit normalization that reduces the inference speed. However, they often require longer training time due to the additional unitary constraints on their weight matrices. Here we show a novel algorithm using a backpropagation technique with Lie algebra for computing approximated unitary weights from their pre-trained, non-unitary counterparts. The unitary networks initialized with these approximations can reach the desired accuracies much faster, mitigating their training time penalties while maintaining inference speedups. Our approach will be instrumental in the adaptation of unitary networks, especially for those neural architectures where pre-trained weights are freely available.
MODISSA: a multipurpose platform for the prototypical realization of vehicle-related applications using optical sensors
May 28, 2021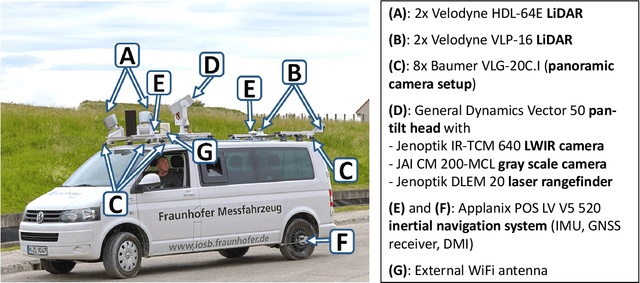

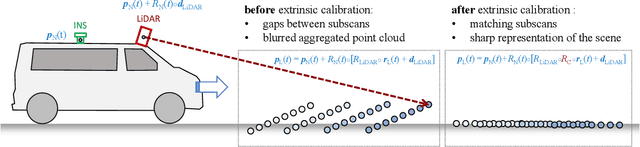

We present the current state of development of the sensor-equipped car MODISSA, with which Fraunhofer IOSB realizes a configurable experimental platform for hardware evaluation and software development in the context of mobile mapping and vehicle-related safety and protection. MODISSA is based on a van that has successively been equipped with a variety of optical sensors over the past few years, and contains hardware for complete raw data acquisition, georeferencing, real-time data analysis, and immediate visualization on in-car displays. We demonstrate the capabilities of MODISSA by giving a deeper insight into experiments with its specific configuration in the scope of three different applications. Other research groups can benefit from these experiences when setting up their own mobile sensor system, especially regarding the selection of hardware and software, the knowledge of possible sources of error, and the handling of the acquired sensor data.
* Authors' version of an article accepted for publication in Applied Optics, 9 May 2021
TENSILE: A Tensor granularity dynamic GPU memory scheduler method towards multiple dynamic workloads system
May 28, 2021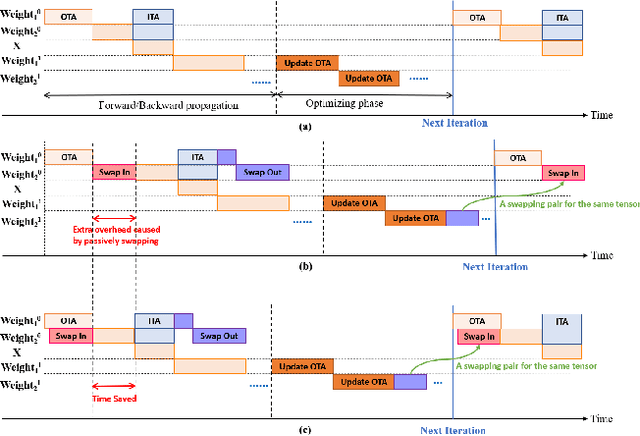
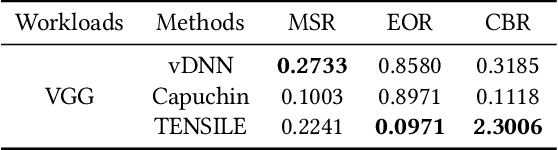
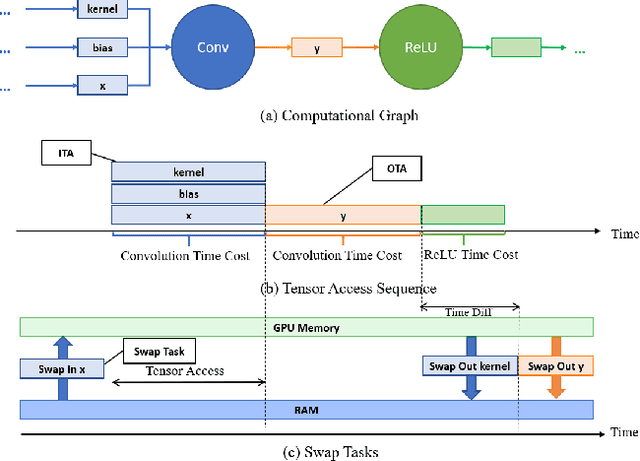
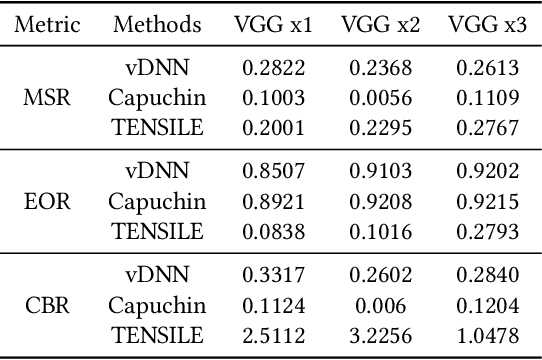
Recently, deep learning has been an area of intense researching. However, as a kind of computing intensive task, deep learning highly relies on the the scale of the GPU memory, which is usually expensive and scarce. Although there are some extensive works have been proposed for dynamic GPU memory management, they are hard to be applied to systems with multitasking dynamic workloads, such as in-database machine learning system. In this paper, we demonstrated TENSILE, a method of managing GPU memory in tensor granularity to reduce the GPU memory peak, with taking the multitasking dynamic workloads into consideration. As far as we know, TENSILE is the first method which is designed to manage multiple workloads' GPU memory using. We implement TENSILE on our own deep learning framework, and evaluated its performance. The experiment results shows that our method can achieve less time overhead than prior works with more GPU memory saved.
Reinforcement Learning for Markovian Bandits: Is Posterior Sampling more Scalable than Optimism?
Jun 16, 2021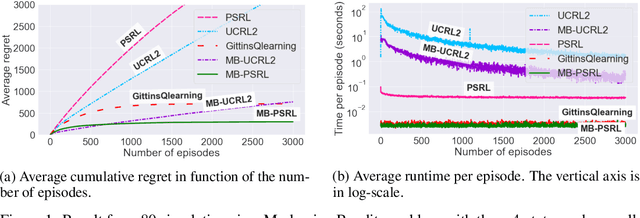


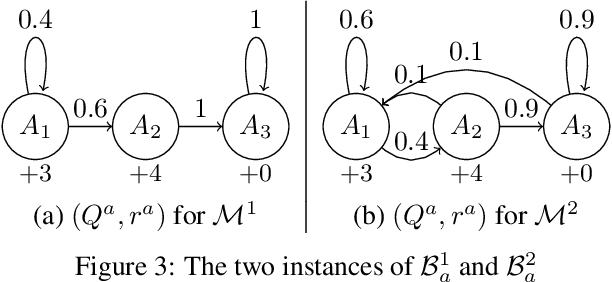
We study learning algorithms for the classical Markovian bandit problem with discount. We explain how to adapt PSRL [24] and UCRL2 [2] to exploit the problem structure. These variants are called MB-PSRL and MB-UCRL2. While the regret bound and runtime of vanilla implementations of PSRL and UCRL2 are exponential in the number of bandits, we show that the episodic regret of MB-PSRL and MB-UCRL2 is $\tilde O(S\sqrt{nK})$ where $K$ is the number of episodes, n is the number of bandits and S is the number of states of each bandit (the exact bound in $S$, $n$ and $K$ is given in the paper). Up to a factor $\sqrt S$, this matches the lower bound of $\Omega(\sqrt{SnK}$) that we also derive in the paper. MB-PSRL is also computationally efficient: its runtime is linear in the number of bandits. We further show that this linear runtime cannot be achieved by adapting classical non-Bayesian algorithms such as UCRL2 or UCBVI to Markovian bandit problems. Finally, we perform numerical experiments that confirm that MB-PSRL outperforms other existing algorithms in practice, both in terms of regret and of computation time.
GPU-Accelerated Optimizer-Aware Evaluation of Submodular Exemplar Clustering
Jan 21, 2021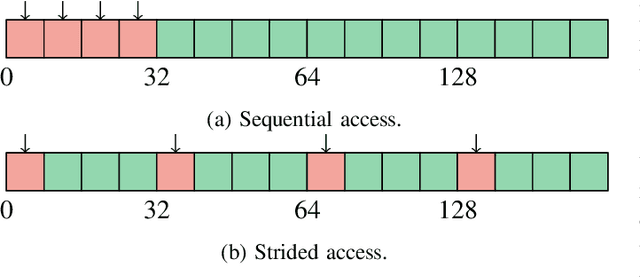
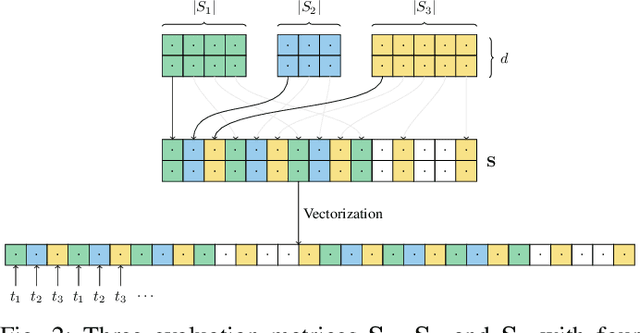
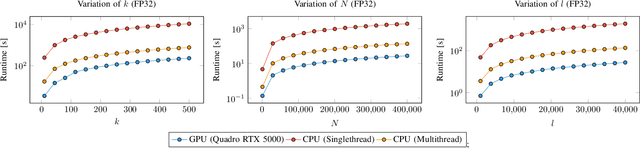
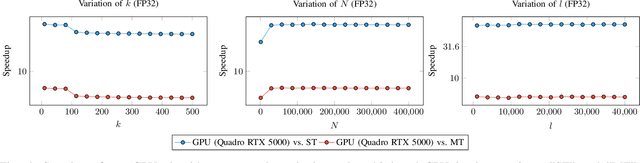
The optimization of submodular functions constitutes a viable way to perform clustering. Strong approximation guarantees and feasible optimization w.r.t. streaming data make this clustering approach favorable. Technically, submodular functions map subsets of data to real values, which indicate how "representative" a specific subset is. Optimal sets might then be used to partition the data space and to infer clusters. Exemplar-based clustering is one of the possible submodular functions, but suffers from high computational complexity. However, for practical applications, the particular real-time or wall-clock run-time is decisive. In this work, we present a novel way to evaluate this particular function on GPUs, which keeps the necessities of optimizers in mind and reduces wall-clock run-time. To discuss our GPU algorithm, we investigated both the impact of different run-time critical problem properties, like data dimensionality and the number of data points in a subset, and the influence of required floating-point precision. In reproducible experiments, our GPU algorithm was able to achieve competitive speedups of up to 72x depending on whether multi-threaded computation on CPUs was used for comparison and the type of floating-point precision required. Half-precision GPU computation led to large speedups of up to 452x compared to single-precision, single-thread CPU computations.
Auto-COP: Adaptation Generation in Context-Oriented Programming using Reinforcement Learning Options
Mar 11, 2021
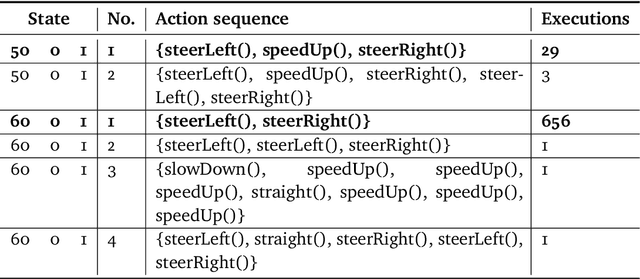
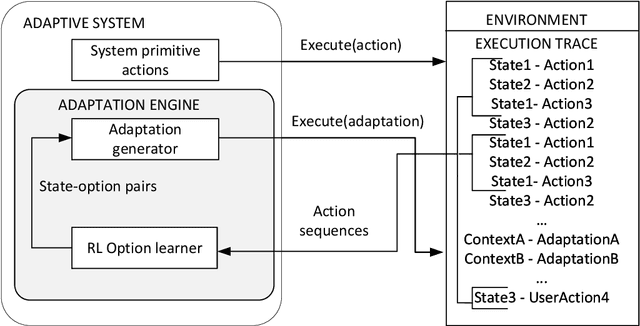
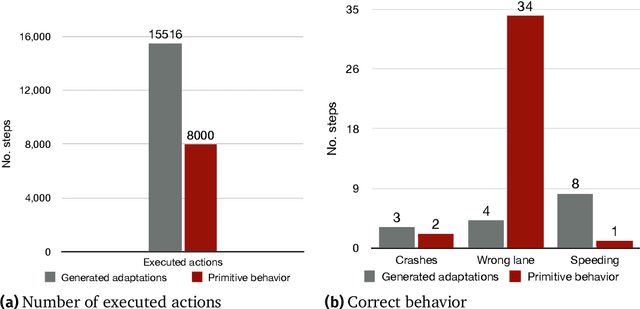
Self-adaptive software systems continuously adapt in response to internal and external changes in their execution environment, captured as contexts. The COP paradigm posits a technique for the development of self-adaptive systems, capturing their main characteristics with specialized programming language constructs. COP adaptations are specified as independent modules composed in and out of the base system as contexts are activated and deactivated in response to sensed circumstances from the surrounding environment. However, the definition of adaptations, their contexts and associated specialized behavior, need to be specified at design time. In complex CPS this is intractable due to new unpredicted operating conditions. We propose Auto-COP, a new technique to enable generation of adaptations at run time. Auto-COP uses RL options to build action sequences, based on the previous instances of the system execution. Options are explored in interaction with the environment, and the most suitable options for each context are used to generate adaptations exploiting COP. To validate Auto-COP, we present two case studies exhibiting different system characteristics and application domains: a driving assistant and a robot delivery system. We present examples of Auto-COP code generated at run time, to illustrate the types of circumstances (contexts) requiring adaptation, and the corresponding generated adaptations for each context. We confirm that the generated adaptations exhibit correct system behavior measured by domain-specific performance metrics, while reducing the number of required execution/actuation steps by a factor of two showing that the adaptations are regularly selected by the running system as adaptive behavior is more appropriate than the execution of primitive actions.
Terahertz Wireless Communications with Flexible Index Modulation Aided Pilot Design
Jun 23, 2021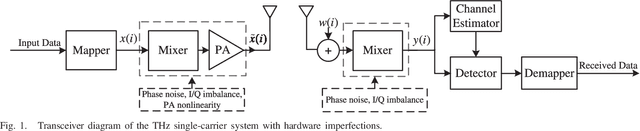
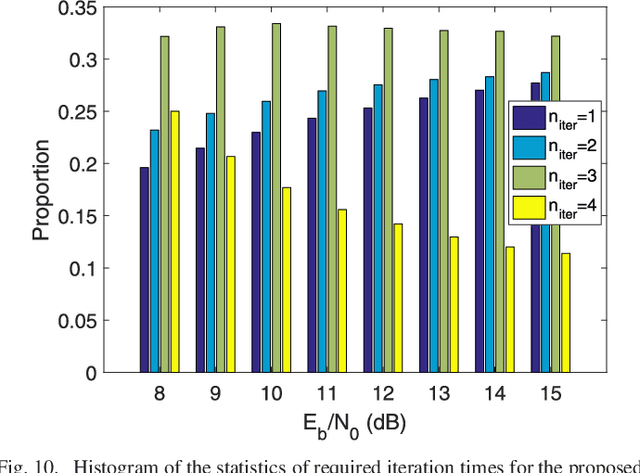
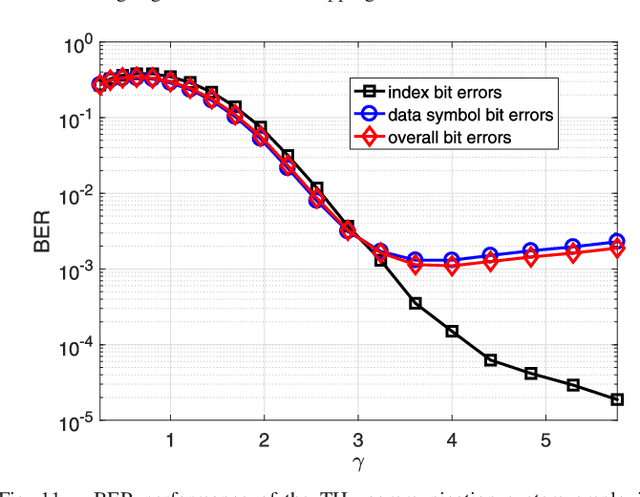
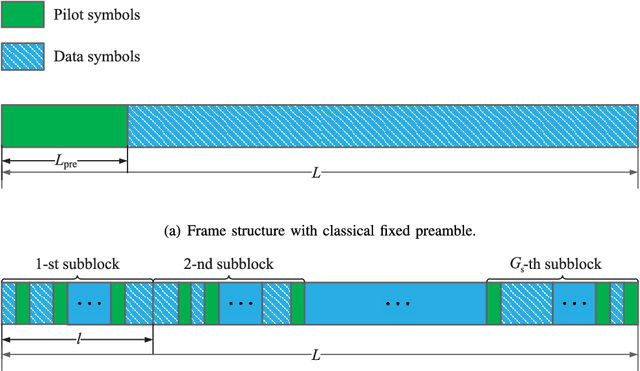
Terahertz (THz) wireless communication is envisioned as a promising technology, which is capable of providing ultra-high-rate transmission up to Terabit per second. However, some hardware imperfections, which are generally neglected in the existing literature concerning lower data rates and traditional operating frequencies, cannot be overlooked in the THz systems. Hardware imperfections usually consist of phase noise, in-phase/quadrature imbalance, and nonlinearity of power amplifier. Due to the time-variant characteristic of phase noise, frequent pilot insertion is required, leading to decreased spectral efficiency. In this paper, to address this issue, a novel pilot design strategy is proposed based on index modulation (IM), where the positions of pilots are flexibly changed in the data frame, and additional information bits can be conveyed by indices of pilots. Furthermore, a turbo receiving algorithm is developed, which jointly performs the detection of pilot indices and channel estimation in an iterative manner. It is shown that the proposed turbo receiver works well even under the situation where the prior knowledge of channel state information is outdated. Analytical and simulation results validate that the proposed schemes achieve significant enhancement of bit-error rate performance and channel estimation accuracy, whilst attaining higher spectral efficiency in comparison with its classical counterpart.
Memorization and Generalization in Neural Code Intelligence Models
Jun 16, 2021
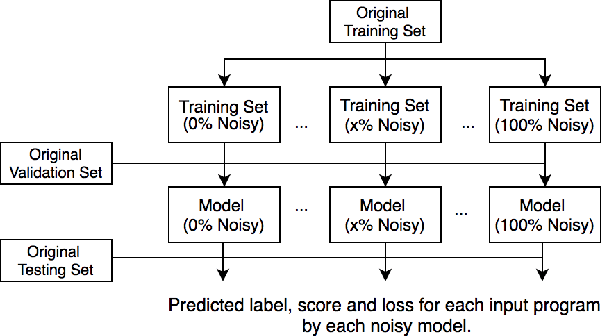
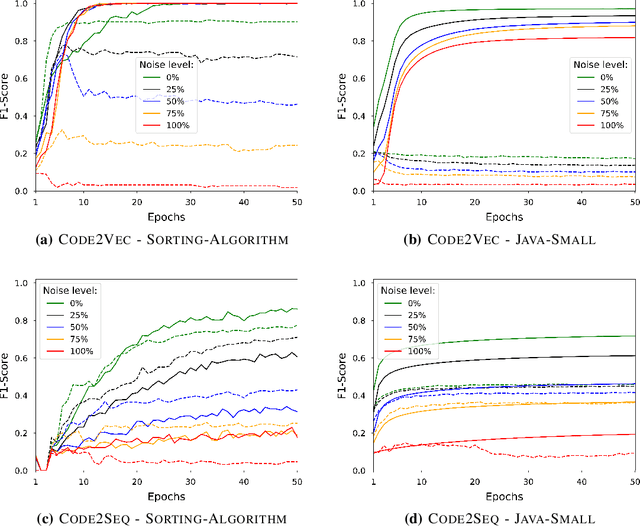
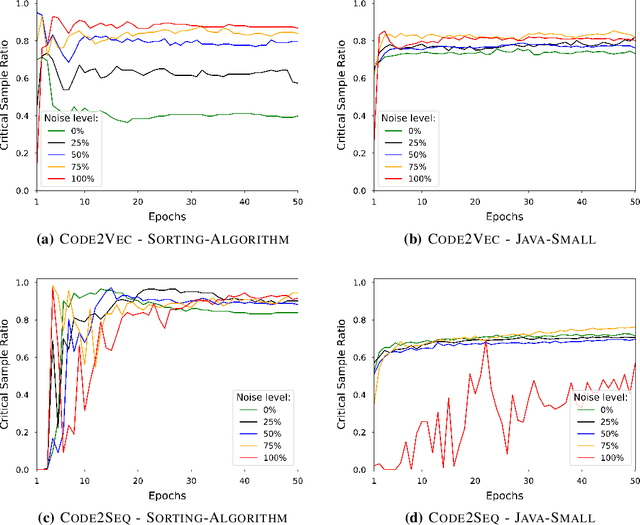
Deep Neural Networks (DNN) are increasingly commonly used in software engineering and code intelligence tasks. These are powerful tools that are capable of learning highly generalizable patterns from large datasets through millions of parameters. At the same time, training DNNs means walking a knife's edges, because their large capacity also renders them prone to memorizing data points. While traditionally thought of as an aspect of over-training, recent work suggests that the memorization risk manifests especially strongly when the training datasets are noisy and memorization is the only recourse. Unfortunately, most code intelligence tasks rely on rather noise-prone and repetitive data sources, such as GitHub, which, due to their sheer size, cannot be manually inspected and evaluated. We evaluate the memorization and generalization tendencies in neural code intelligence models through a case study across several benchmarks and model families by leveraging established approaches from other fields that use DNNs, such as introducing targeted noise into the training dataset. In addition to reinforcing prior general findings about the extent of memorization in DNNs, our results shed light on the impact of noisy dataset in training.
Directional GAN: A Novel Conditioning Strategy for Generative Networks
May 13, 2021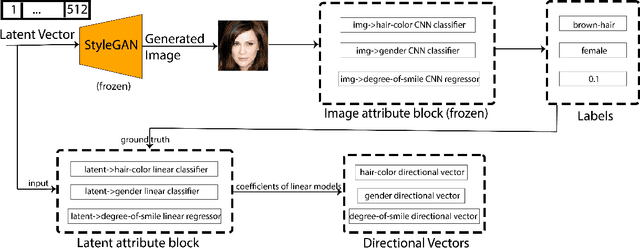

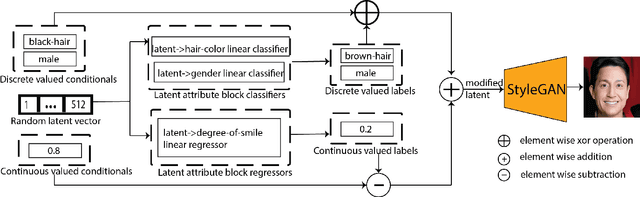
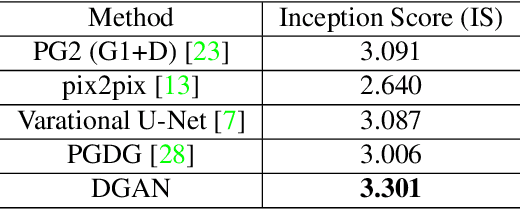
Image content is a predominant factor in marketing campaigns, websites and banners. Today, marketers and designers spend considerable time and money in generating such professional quality content. We take a step towards simplifying this process using Generative Adversarial Networks (GANs). We propose a simple and novel conditioning strategy which allows generation of images conditioned on given semantic attributes using a generator trained for an unconditional image generation task. Our approach is based on modifying latent vectors, using directional vectors of relevant semantic attributes in latent space. Our method is designed to work with both discrete (binary and multi-class) and continuous image attributes. We show the applicability of our proposed approach, named Directional GAN, on multiple public datasets, with an average accuracy of 86.4% across different attributes.
Proving Equivalence Between Complex Expressions Using Graph-to-Sequence Neural Models
Jun 09, 2021
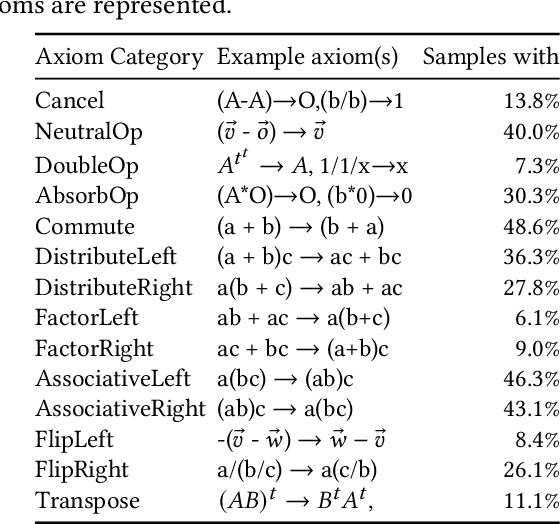
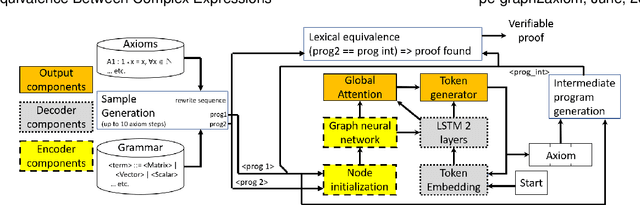

We target the problem of provably computing the equivalence between two complex expression trees. To this end, we formalize the problem of equivalence between two such programs as finding a set of semantics-preserving rewrite rules from one into the other, such that after the rewrite the two programs are structurally identical, and therefore trivially equivalent.We then develop a graph-to-sequence neural network system for program equivalence, trained to produce such rewrite sequences from a carefully crafted automatic example generation algorithm. We extensively evaluate our system on a rich multi-type linear algebra expression language, using arbitrary combinations of 100+ graph-rewriting axioms of equivalence. Our machine learning system guarantees correctness for all true negatives, and ensures 0 false positive by design. It outputs via inference a valid proof of equivalence for 93% of the 10,000 equivalent expression pairs isolated for testing, using up to 50-term expressions. In all cases, the validity of the sequence produced and therefore the provable assertion of program equivalence is always computable, in negligible time.