 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Uncertainty For Safety-Oriented Semantic Segmentation In Autonomous Driving
May 28, 2021
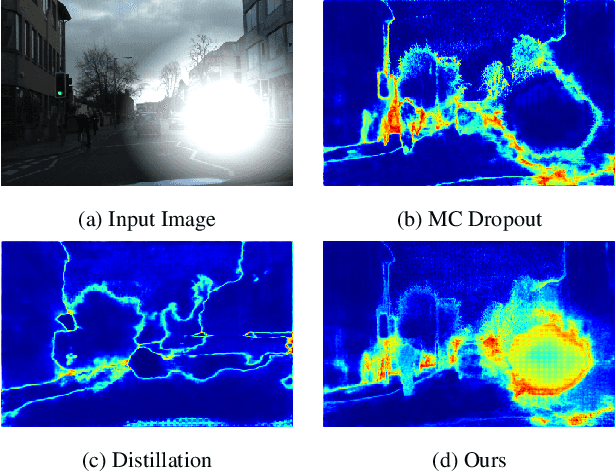
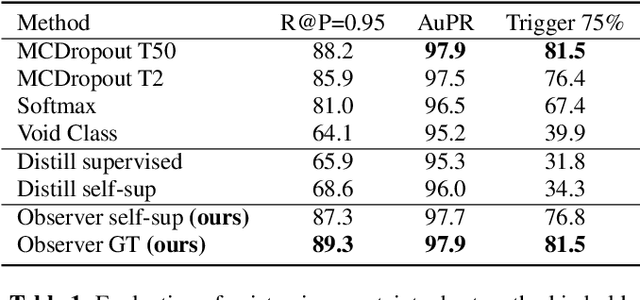
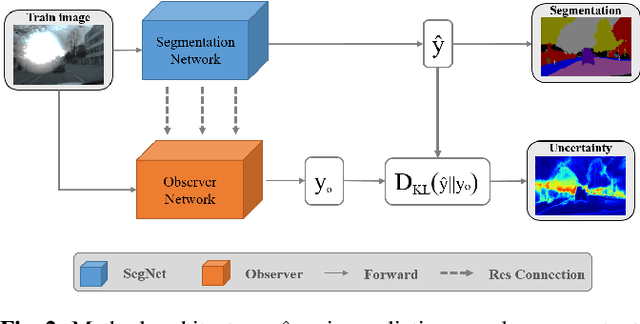
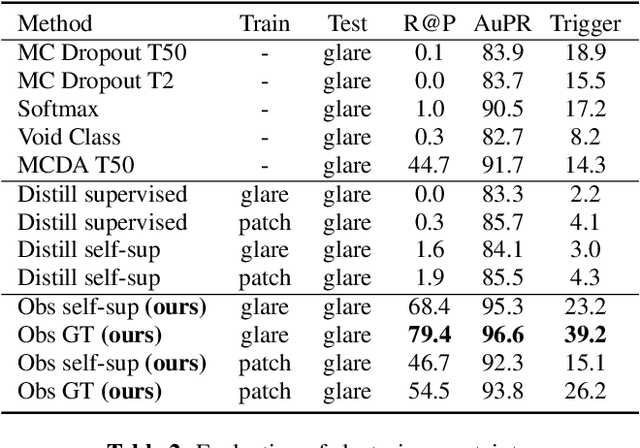
In this paper, we show how uncertainty estimation can be leveraged to enable safety critical image segmentation in autonomous driving, by triggering a fallback behavior if a target accuracy cannot be guaranteed. We introduce a new uncertainty measure based on disagreeing predictions as measured by a dissimilarity function. We propose to estimate this dissimilarity by training a deep neural architecture in parallel to the task-specific network. It allows this observer to be dedicated to the uncertainty estimation, and let the task-specific network make predictions. We propose to use self-supervision to train the observer, which implies that our method does not require additional training data. We show experimentally that our proposed approach is much less computationally intensive at inference time than competing methods (e.g. MCDropout), while delivering better results on safety-oriented evaluation metrics on the CamVid dataset, especially in the case of glare artifacts.
Class Means as an Early Exit Decision Mechanism
Mar 01, 2021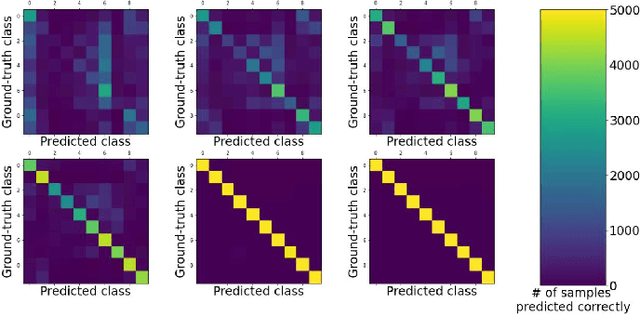
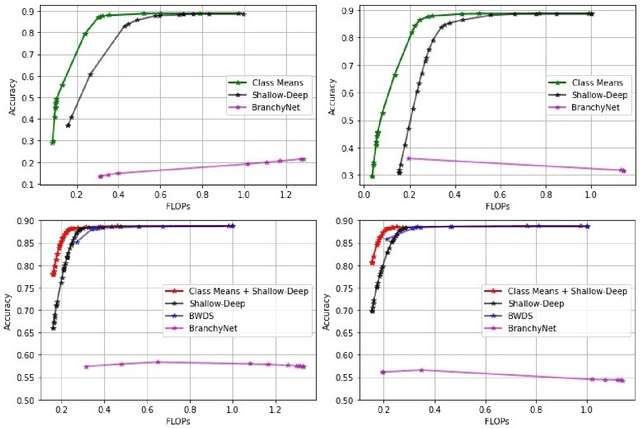
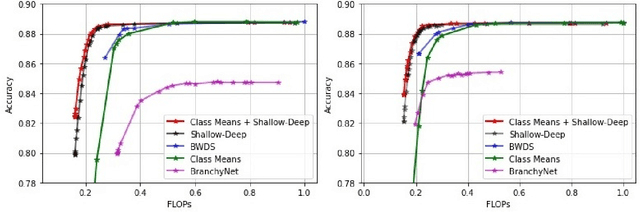
State-of-the-art neural networks with early exit mechanisms often need considerable amount of training and fine-tuning to achieve good performance with low computational cost. We propose a novel early exit technique based on the class means of samples. Unlike most existing schemes, our method does not require gradient-based training of internal classifiers. This makes our method particularly useful for neural network training in low-power devices, as in wireless edge networks. In particular, given a fixed training time budget, our scheme achieves higher accuracy as compared to existing early exit mechanisms. Moreover, if there are no limitations on the training time budget, our method can be combined with an existing early exit scheme to boost its performance, achieving a better trade-off between computational cost and network accuracy.
Automatic CT Segmentation from Bounding Box Annotations using Convolutional Neural Networks
Jun 09, 2021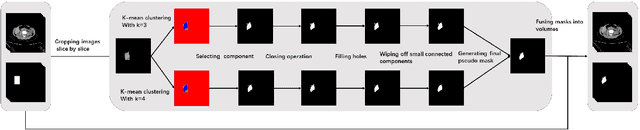
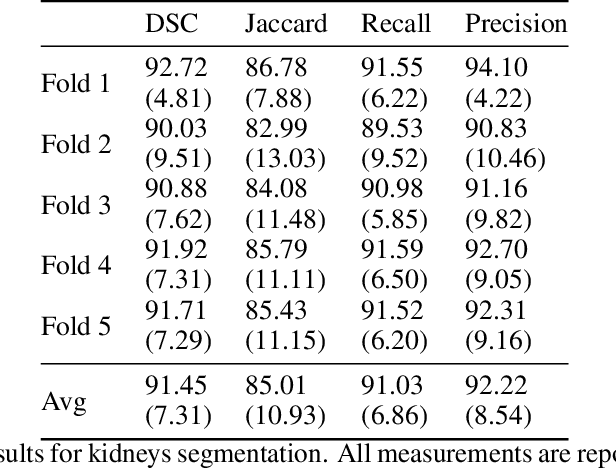
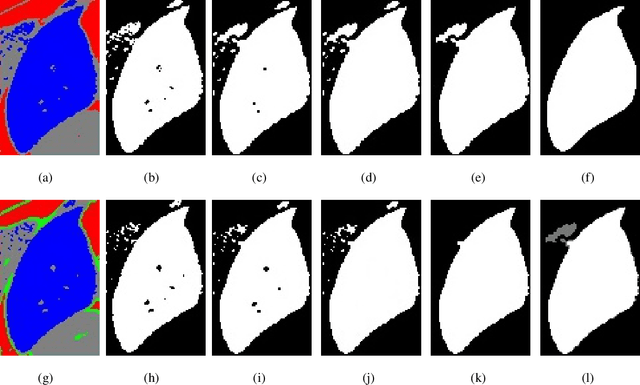
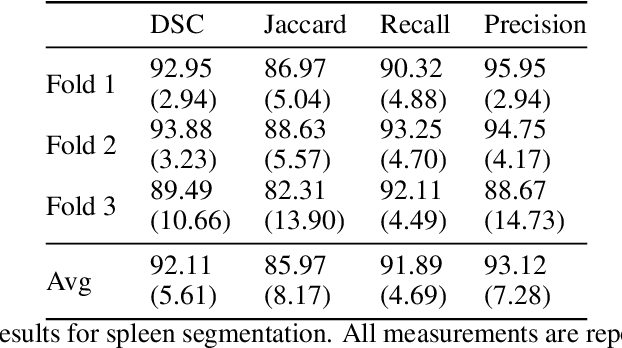
Accurate segmentation for medical images is important for clinical diagnosis. Existing automatic segmentation methods are mainly based on fully supervised learning and have an extremely high demand for precise annotations, which are very costly and time-consuming to obtain. To address this problem, we proposed an automatic CT segmentation method based on weakly supervised learning, by which one could train an accurate segmentation model only with weak annotations in the form of bounding boxes. The proposed method is composed of two steps: 1) generating pseudo masks with bounding box annotations by k-means clustering, and 2) iteratively training a 3D U-Net convolutional neural network as a segmentation model. Some data pre-processing methods are used to improve performance. The method was validated on four datasets containing three types of organs with a total of 627 CT volumes. For liver, spleen and kidney segmentation, it achieved an accuracy of 95.19%, 92.11%, and 91.45%, respectively. Experimental results demonstrate that our method is accurate, efficient, and suitable for clinical use.
DeepWalk: Omnidirectional Bipedal Gait by Deep Reinforcement Learning
Jun 01, 2021
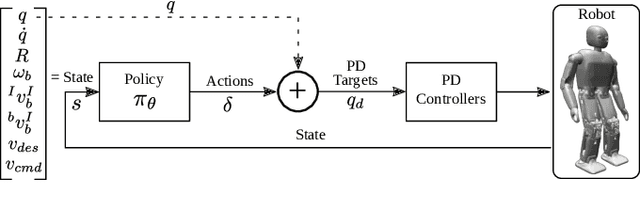
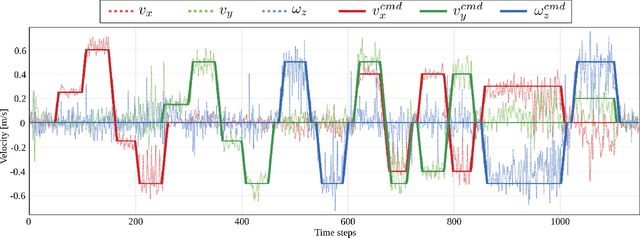
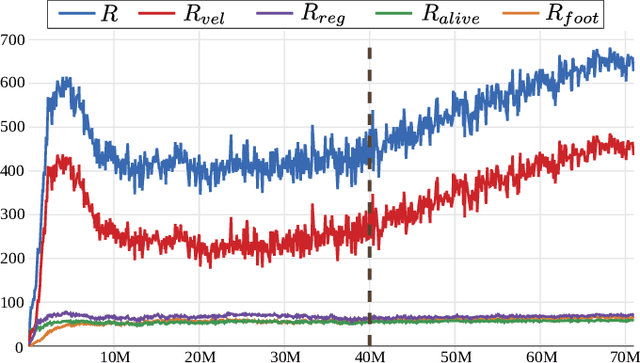
Bipedal walking is one of the most difficult but exciting challenges in robotics. The difficulties arise from the complexity of high-dimensional dynamics, sensing and actuation limitations combined with real-time and computational constraints. Deep Reinforcement Learning (DRL) holds the promise to address these issues by fully exploiting the robot dynamics with minimal craftsmanship. In this paper, we propose a novel DRL approach that enables an agent to learn omnidirectional locomotion for humanoid (bipedal) robots. Notably, the locomotion behaviors are accomplished by a single control policy (a single neural network). We achieve this by introducing a new curriculum learning method that gradually increases the task difficulty by scheduling target velocities. In addition, our method does not require reference motions which facilities its application to robots with different kinematics, and reduces the overall complexity. Finally, different strategies for sim-to-real transfer are presented which allow us to transfer the learned policy to a real humanoid robot.
SeaNet -- Towards A Knowledge Graph Based Autonomic Management of Software Defined Networks
Jul 05, 2021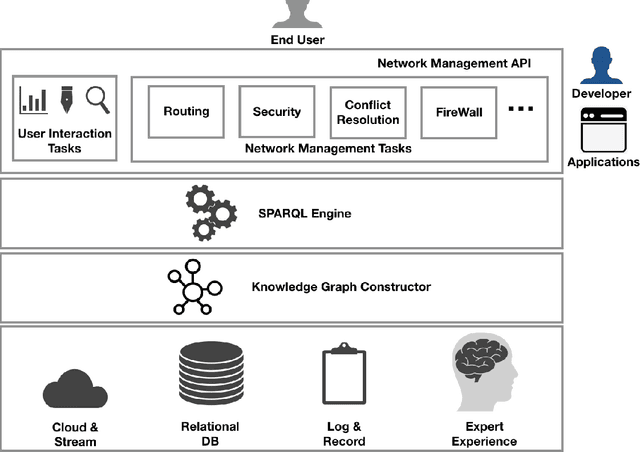
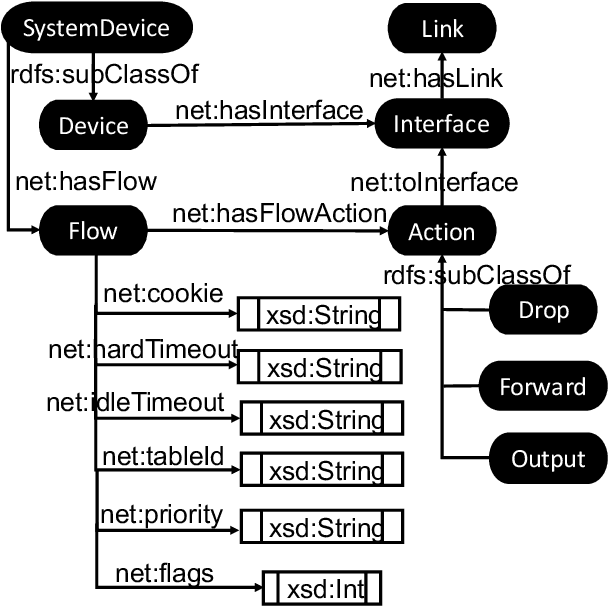
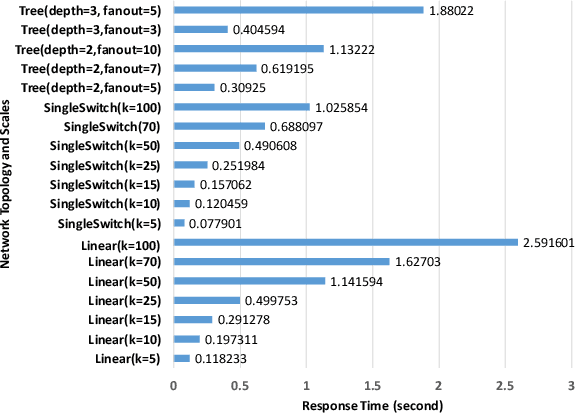
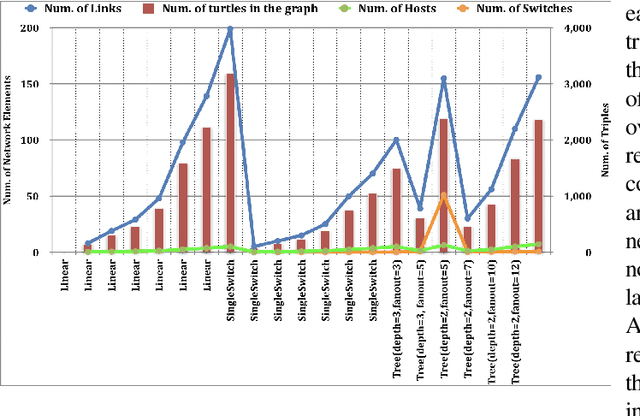
Automatic network management driven by Artificial Intelligent technologies has been heatedly discussed over decades. However, current reports mainly focus on theoretic proposals and architecture designs, works on practical implementations on real-life networks are yet to appear. This paper proposes our effort toward the implementation of knowledge graph driven approach for autonomic network management in software defined networks (SDNs), termed as SeaNet. Driven by the ToCo ontology, SeaNet is reprogrammed based on Mininet (a SDN emulator). It consists three core components, a knowledge graph generator, a SPARQL engine, and a network management API. The knowledge graph generator represents the knowledge in the telecommunication network management tasks into formally represented ontology driven model. Expert experience and network management rules can be formalized into knowledge graph and by automatically inferenced by SPARQL engine, Network management API is able to packet technology-specific details and expose technology-independent interfaces to users. The Experiments are carried out to evaluate proposed work by comparing with a commercial SDN controller Ryu implemented by the same language Python. The evaluation results show that SeaNet is considerably faster in most circumstances than Ryu and the SeaNet code is significantly more compact. Benefit from RDF reasoning, SeaNet is able to achieve O(1) time complexity on different scales of the knowledge graph while the traditional database can achieve O(nlogn) at its best. With the developed network management API, SeaNet enables researchers to develop semantic-intelligent applications on their own SDNs.
THG: Transformer with Hyperbolic Geometry
Jun 01, 2021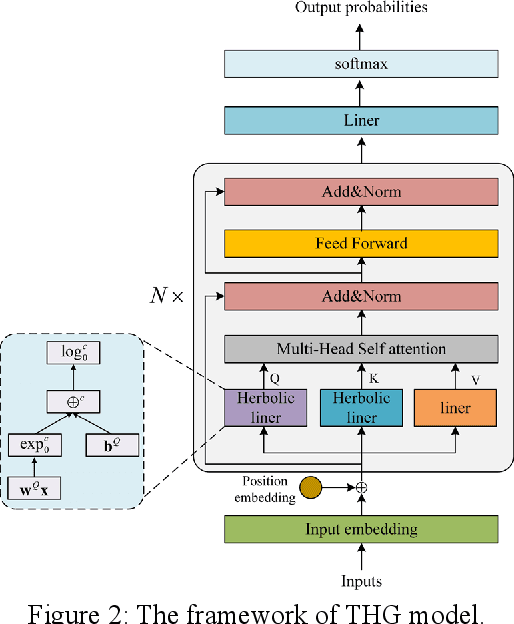
Transformer model architectures have become an indispensable staple in deep learning lately for their effectiveness across a range of tasks. Recently, a surge of "X-former" models have been proposed which improve upon the original Transformer architecture. However, most of these variants make changes only around the quadratic time and memory complexity of self-attention, i.e. the dot product between the query and the key. What's more, they are calculate solely in Euclidean space. In this work, we propose a novel Transformer with Hyperbolic Geometry (THG) model, which take the advantage of both Euclidean space and Hyperbolic space. THG makes improvements in linear transformations of self-attention, which are applied on the input sequence to get the query and the key, with the proposed hyperbolic linear. Extensive experiments on sequence labeling task, machine reading comprehension task and classification task demonstrate the effectiveness and generalizability of our model. It also demonstrates THG could alleviate overfitting.
TeCANet: Temporal-Contextual Attention Network for Environment-Aware Speech Dereverberation
Mar 31, 2021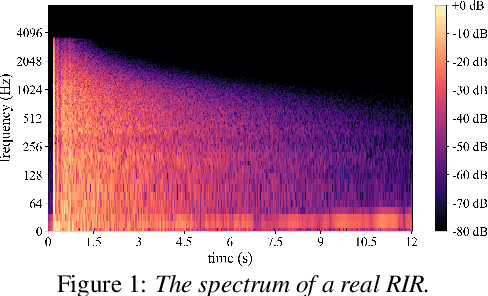
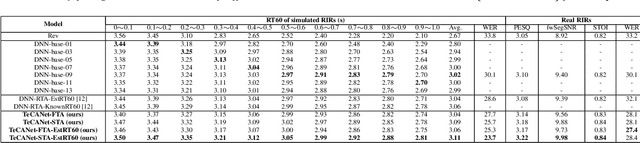
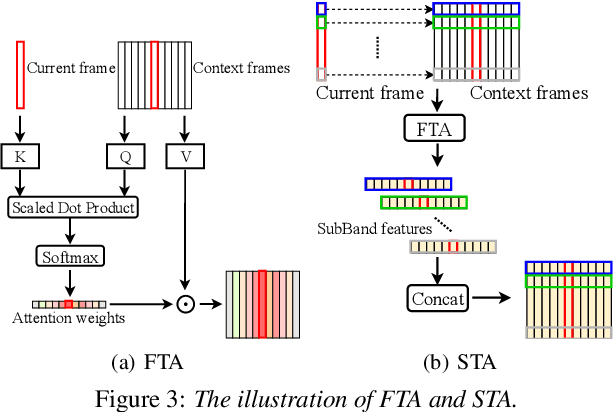
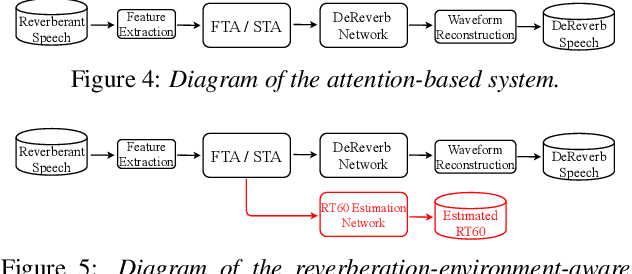
In this paper, we exploit the effective way to leverage contextual information to improve the speech dereverberation performance in real-world reverberant environments. We propose a temporal-contextual attention approach on the deep neural network (DNN) for environment-aware speech dereverberation, which can adaptively attend to the contextual information. More specifically, a FullBand based Temporal Attention approach (FTA) is proposed, which models the correlations between the fullband information of the context frames. In addition, considering the difference between the attenuation of high frequency bands and low frequency bands (high frequency bands attenuate faster than low frequency bands) in the room impulse response (RIR), we also propose a SubBand based Temporal Attention approach (STA). In order to guide the network to be more aware of the reverberant environments, we jointly optimize the dereverberation network and the reverberation time (RT60) estimator in a multi-task manner. Our experimental results indicate that the proposed method outperforms our previously proposed reverberation-time-aware DNN and the learned attention weights are fully physical consistent. We also report a preliminary yet promising dereverberation and recognition experiment on real test data.
Explicit Basis Function Kernel Methods for Cloud Segmentation in Infrared Sky Images
Feb 19, 2021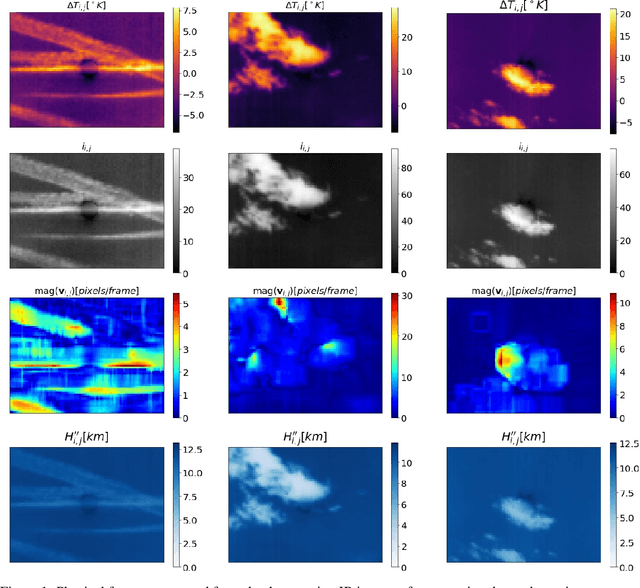
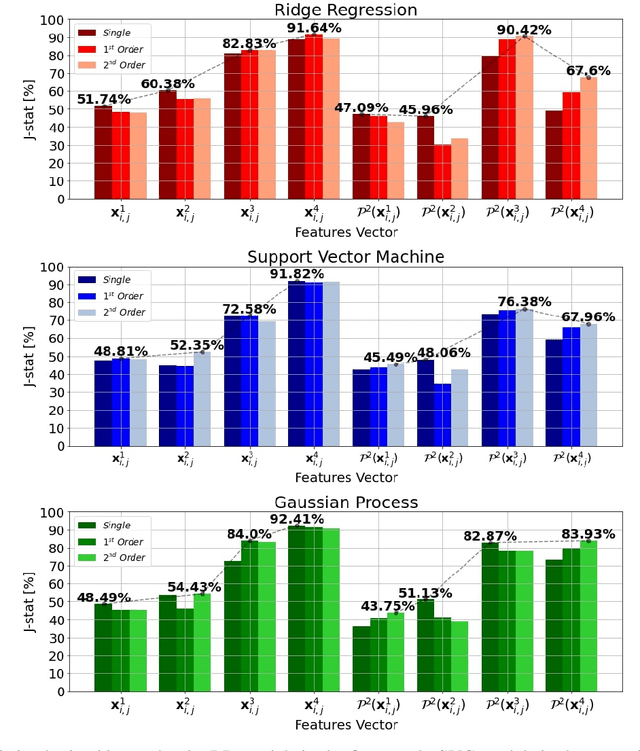

Photovoltaic (PV) systems are sensitive to cloud shadow projection, which needs to be forecasted to reduce the noise impacting the short-term forecast of Global Solar Irradiance (GSI). We present a comparison between different kernel discriminative models for cloud detection. The models are solved in the primal formulation to make them feasible in real-time applications. The performances are compared using the j-statistic. The Infrared (IR) images have been preprocessed to remove debris, which increases the performance of the analyzed methods. The use of the pixels neighboring features also leads to a performance improvement. Discriminative models solved in the primal yield a dramatically lower computing time along with high performance in the segmentation.
Neural SDEs as Infinite-Dimensional GANs
Feb 06, 2021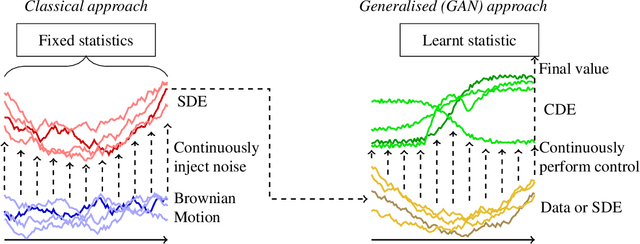

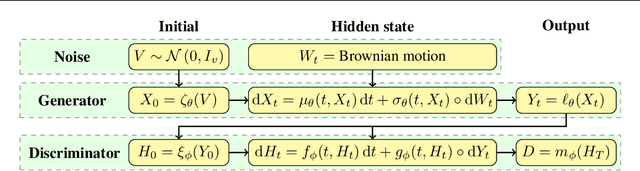

Stochastic differential equations (SDEs) are a staple of mathematical modelling of temporal dynamics. However, a fundamental limitation has been that such models have typically been relatively inflexible, which recent work introducing Neural SDEs has sought to solve. Here, we show that the current classical approach to fitting SDEs may be approached as a special case of (Wasserstein) GANs, and in doing so the neural and classical regimes may be brought together. The input noise is Brownian motion, the output samples are time-evolving paths produced by a numerical solver, and by parameterising a discriminator as a Neural Controlled Differential Equation (CDE), we obtain Neural SDEs as (in modern machine learning parlance) continuous-time generative time series models. Unlike previous work on this problem, this is a direct extension of the classical approach without reference to either prespecified statistics or density functions. Arbitrary drift and diffusions are admissible, so as the Wasserstein loss has a unique global minima, in the infinite data limit \textit{any} SDE may be learnt.
Model-Based Counterfactual Synthesizer for Interpretation
Jun 16, 2021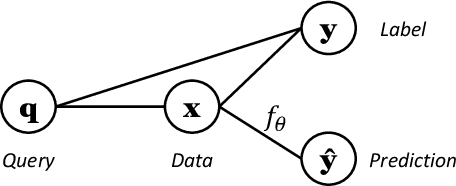
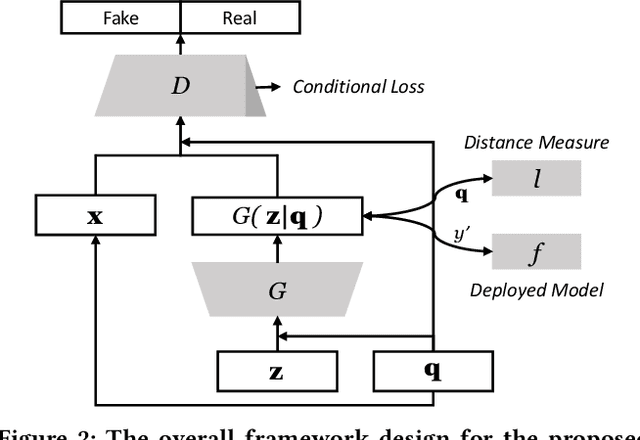
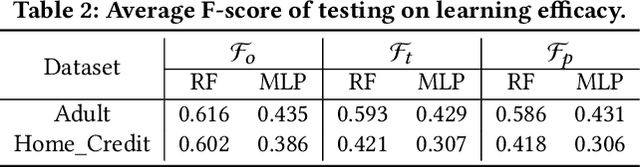
Counterfactuals, serving as one of the emerging type of model interpretations, have recently received attention from both researchers and practitioners. Counterfactual explanations formalize the exploration of ``what-if'' scenarios, and are an instance of example-based reasoning using a set of hypothetical data samples. Counterfactuals essentially show how the model decision alters with input perturbations. Existing methods for generating counterfactuals are mainly algorithm-based, which are time-inefficient and assume the same counterfactual universe for different queries. To address these limitations, we propose a Model-based Counterfactual Synthesizer (MCS) framework for interpreting machine learning models. We first analyze the model-based counterfactual process and construct a base synthesizer using a conditional generative adversarial net (CGAN). To better approximate the counterfactual universe for those rare queries, we novelly employ the umbrella sampling technique to conduct the MCS framework training. Besides, we also enhance the MCS framework by incorporating the causal dependence among attributes with model inductive bias, and validate its design correctness from the causality identification perspective. Experimental results on several datasets demonstrate the effectiveness as well as efficiency of our proposed MCS framework, and verify the advantages compared with other alternatives.