 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatial resolution of late reverberation in virtual acoustic environments
Jun 30, 2021
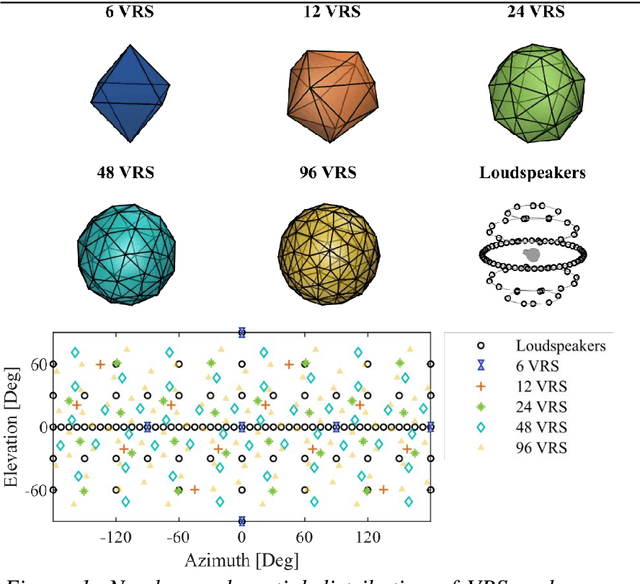
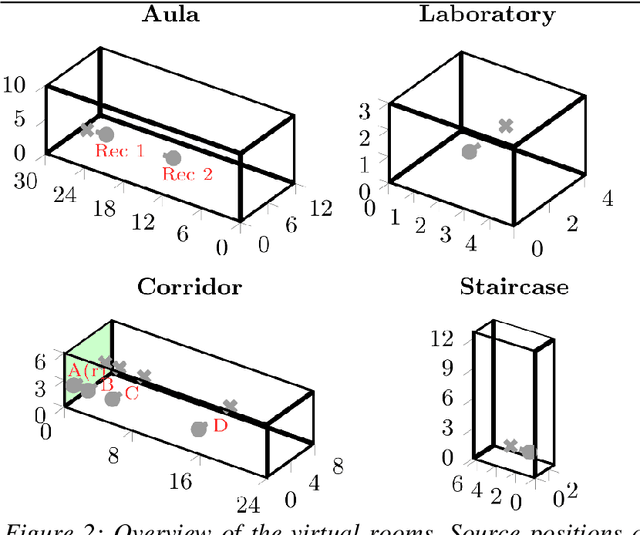
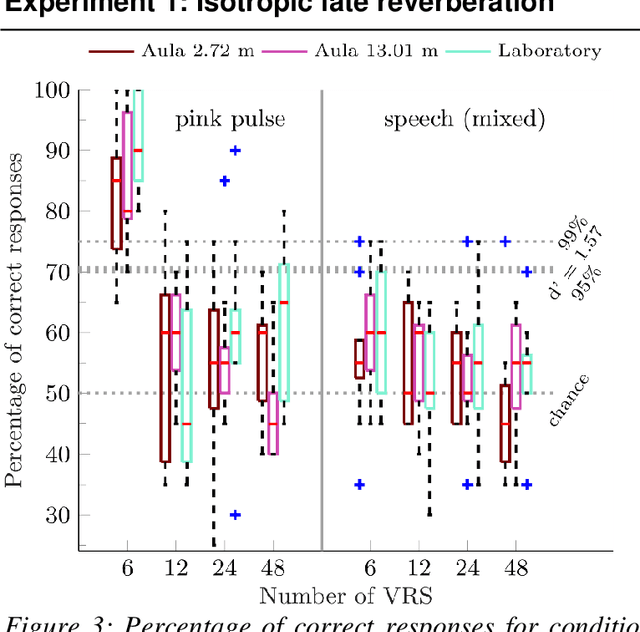
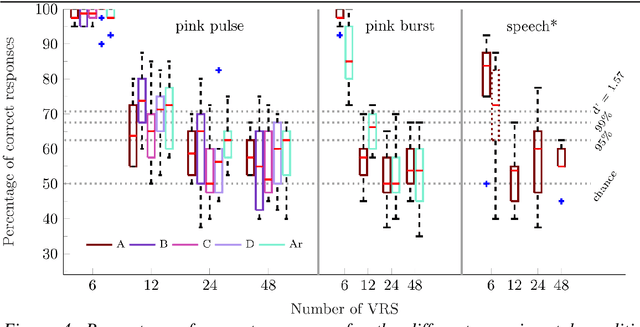
Late reverberation involves the superposition of many sound reflections resulting in a diffuse sound field. Since the spatially resolved perception of individual diffuse reflections is impossible, simplifications can potentially be made for modelling late reverberation in room acoustics simulations with reduced spatial resolution. Such simplifications are desired for interactive, real-time virtual acoustic environments with applications in hearing research and for the evaluation of hearing supportive devices. In this context, the number and spatial arrangement of loudspeakers used for playback additionally affect spatial resolution. The current study assessed the minimum number of spatially evenly distributed virtual late reverberation sources required to perceptually approximate spatially highly resolved isotropic and anisotropic late reverberation and to technically approximate a spherically isotropic diffuse sound field. The spatial resolution of the rendering was systematically reduced by using subsets of the loudspeakers of an 86-channel spherical loudspeaker array in an anechoic chamber. It was tested whether listeners can distinguish lower spatial resolutions for the rendering of late reverberation from the highest achievable spatial resolution in different simulated rooms. Rendering of early reflections was kept fixed. The coherence of the sound field across a pair of microphones at ear and behind-the-ear hearing device distance was assessed to separate the effects of number of virtual sources and loudspeaker array geometry. Results show that between 12 and 24 reverberation sources are required.
Simultaneous Transmission and Reflection Reconfigurable Intelligent Surface Assisted MIMO Systems
Jun 17, 2021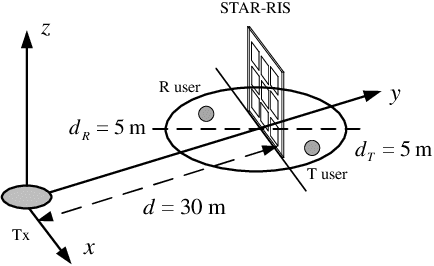
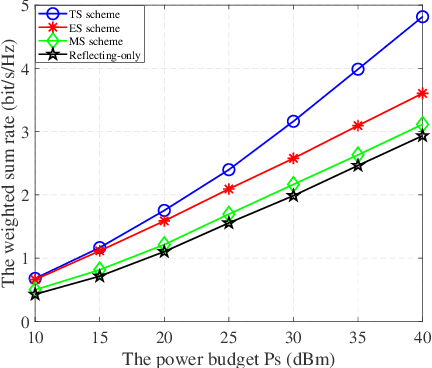
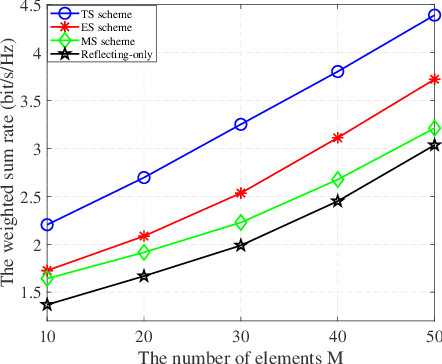
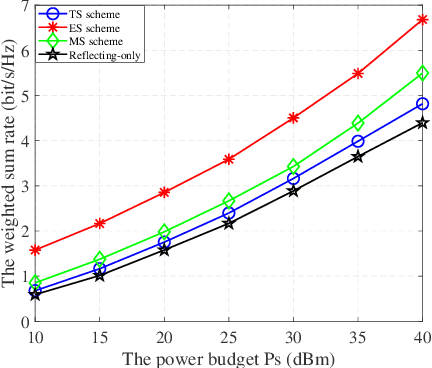
In this work, we investigate a novel simultaneous transmission and reflection reconfigurable intelligent surface (RIS)-assisted multiple-input multiple-output downlink system, where three practical transmission protocols, namely, energy splitting (ES), mode selection (MS), and time splitting (TS), are studied. For the system under consideration, we maximize the weighted sum rate with multiple coupled variables. To solve this optimization problem, a block coordinate descent algorithm is proposed to reformulate this problem and design the precoding matrices and the transmitting and reflecting coefficients (TARCs) in an alternate manner. Specifically, for the ES scheme, the precoding matrices are solved using the Lagrange dual method, while the TARCs are obtained using the penalty concave-convex method. Additionally, the proposed method is extended to the MS scheme by solving a mixed-integer problem. Moreover, we solve the formulated problem for the TS scheme using a one-dimensional search and the Majorization-Minimization technique. Our simulation results reveal that: 1) Simultaneous transmission and reflection RIS (STAR-RIS) can achieve better performance than reflecting-only RIS; 2) In unicast communication, TS scheme outperforms the ES and MS schemes, while in broadcast communication, ES scheme outperforms the TS and MS schemes.
Genre determining prediction: Non-standard TAM marking in football language
Jun 30, 2021German and French football language display tense-aspect-mood (TAM) forms which differ from the TAM use in other genres. In German football talk, the present indicative may replace the pluperfect subjunctive. In French reports of football matches, the imperfective past may occur instead of a perfective past tense-aspect form. We argue that the two phenomena share a functional core and are licensed in the same way, which is a direct result of the genre they occur in. More precisely, football match reports adhere to a precise script and specific events are temporally determined in terms of objective time. This allows speakers to exploit a secondary function of TAM forms, namely, they shift the temporal perspective. We argue that it is on the grounds of the genre that comprehenders predict the deviating forms and are also able to decode them. We present various corpus studies where we explore the functioning of these phenomena in order to gain insights into their distribution, grammaticalization and their functioning in discourse. Relevant factors are Aktionsart properties, rhetorical relations and their interaction with other TAM forms. This allows us to discuss coping mechanisms on the part of the comprehender. We broaden our understanding of the phenomena, which have only been partly covered for French and up to now seem to have been ignored in German.
Communication-Efficient Split Learning Based on Analog Communication and Over the Air Aggregation
Jun 02, 2021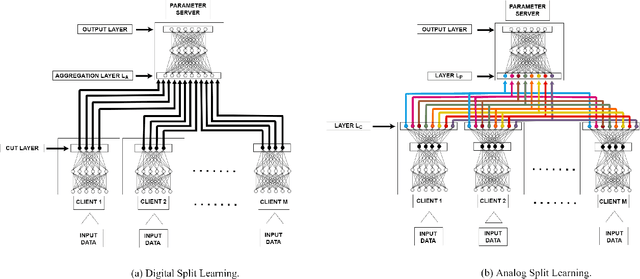
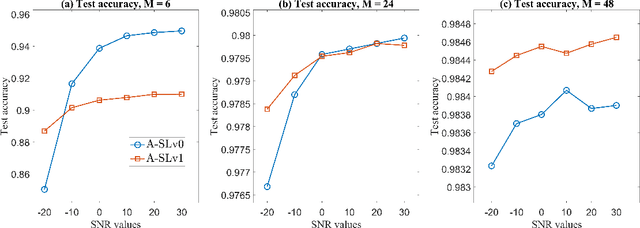
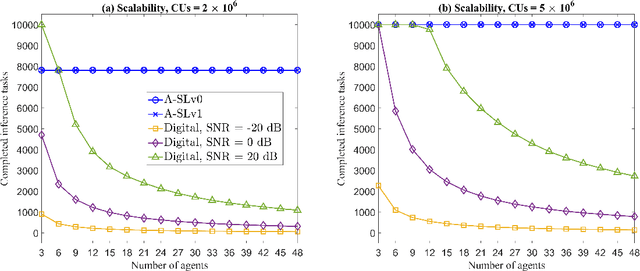
Split-learning (SL) has recently gained popularity due to its inherent privacy-preserving capabilities and ability to enable collaborative inference for devices with limited computational power. Standard SL algorithms assume an ideal underlying digital communication system and ignore the problem of scarce communication bandwidth. However, for a large number of agents, limited bandwidth resources, and time-varying communication channels, the communication bandwidth can become the bottleneck. To address this challenge, in this work, we propose a novel SL framework to solve the remote inference problem that introduces an additional layer at the agent side and constrains the choices of the weights and the biases to ensure over the air aggregation. Hence, the proposed approach maintains constant communication cost with respect to the number of agents enabling remote inference under limited bandwidth. Numerical results show that our proposed algorithm significantly outperforms the digital implementation in terms of communication-efficiency, especially as the number of agents grows large.
Efficient reconstruction of depth three circuits with top fan-in two
Mar 12, 2021We develop efficient randomized algorithms to solve the black-box reconstruction problem for polynomials over finite fields, computable by depth three arithmetic circuits with alternating addition/multiplication gates, such that output gate is an addition gate with in-degree two. These circuits compute polynomials of form $G\times(T_1 + T_2)$, where $G,T_1,T_2$ are product of affine forms, and polynomials $T_1,T_2$ have no common factors. Rank of such a circuit is defined as dimension of vector space spanned by all affine factors of $T_1$ and $T_2$. For any polynomial $f$ computable by such a circuit, $rank(f)$ is defined to be the minimum rank of any such circuit computing it. Our work develops randomized reconstruction algorithms which take as input black-box access to a polynomial $f$ (over finite field $\mathbb{F}$), computable by such a circuit. Here are the results. 1 [Low rank]: When $5\leq rank(f) = O(\log^3 d)$, it runs in time $(nd^{\log^3d}\log |\mathbb{F}|)^{O(1)}$, and, with high probability, outputs a depth three circuit computing $f$, with top addition gate having in-degree $\leq d^{rank(f)}$. 2 [High rank]: When $rank(f) = \Omega(\log^3 d)$, it runs in time $(nd\log |\mathbb{F}|)^{O(1)}$, and, with high probability, outputs a depth three circuit computing $f$, with top addition gate having in-degree two. Ours is the first blackbox reconstruction algorithm for this circuit class, that runs in time polynomial in $\log |\mathbb{F}|$. This problem has been mentioned as an open problem in [GKL12] (STOC 2012)
Delay Analysis of Wireless Federated Learning Based on Saddle Point Approximation and Large Deviation Theory
Apr 01, 2021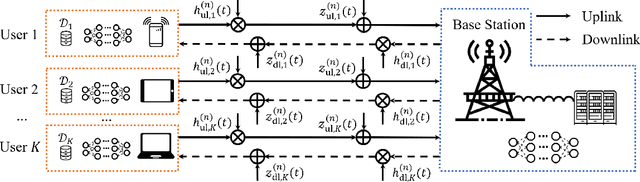
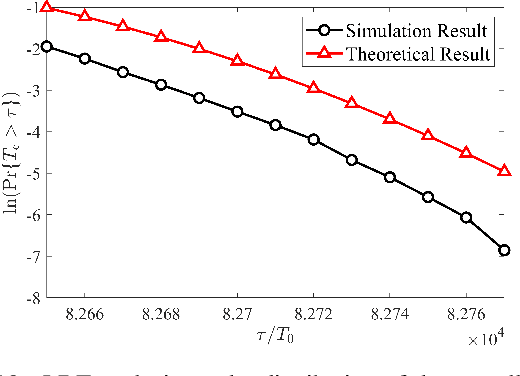

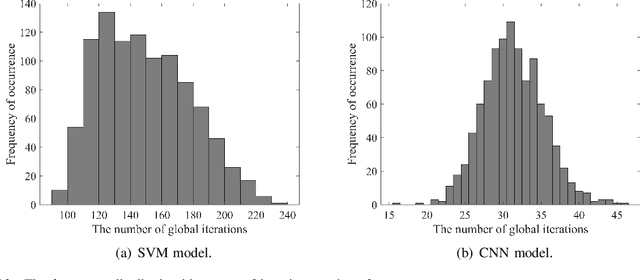
Federated learning (FL) is a collaborative machine learning paradigm, which enables deep learning model training over a large volume of decentralized data residing in mobile devices without accessing clients' private data. Driven by the ever increasing demand for model training of mobile applications or devices, a vast majority of FL tasks are implemented over wireless fading channels. Due to the time-varying nature of wireless channels, however, random delay occurs in both the uplink and downlink transmissions of FL. How to analyze the overall time consumption of a wireless FL task, or more specifically, a FL's delay distribution, becomes a challenging but important open problem, especially for delay-sensitive model training. In this paper, we present a unified framework to calculate the approximate delay distributions of FL over arbitrary fading channels. Specifically, saddle point approximation, extreme value theory (EVT), and large deviation theory (LDT) are jointly exploited to find the approximate delay distribution along with its tail distribution, which characterizes the quality-of-service of a wireless FL system. Simulation results will demonstrate that our approximation method achieves a small approximation error, which vanishes with the increase of training accuracy.
Edge Proposal Sets for Link Prediction
Jun 30, 2021



Graphs are a common model for complex relational data such as social networks and protein interactions, and such data can evolve over time (e.g., new friendships) and be noisy (e.g., unmeasured interactions). Link prediction aims to predict future edges or infer missing edges in the graph, and has diverse applications in recommender systems, experimental design, and complex systems. Even though link prediction algorithms strongly depend on the set of edges in the graph, existing approaches typically do not modify the graph topology to improve performance. Here, we demonstrate how simply adding a set of edges, which we call a \emph{proposal set}, to the graph as a pre-processing step can improve the performance of several link prediction algorithms. The underlying idea is that if the edges in the proposal set generally align with the structure of the graph, link prediction algorithms are further guided towards predicting the right edges; in other words, adding a proposal set of edges is a signal-boosting pre-processing step. We show how to use existing link prediction algorithms to generate effective proposal sets and evaluate this approach on various synthetic and empirical datasets. We find that proposal sets meaningfully improve the accuracy of link prediction algorithms based on both neighborhood heuristics and graph neural networks. Code is available at \url{https://github.com/CUAI/Edge-Proposal-Sets}.
Time Integrating Articulated Body Dynamics Using Position-Based Collocation Method
Jul 23, 2018
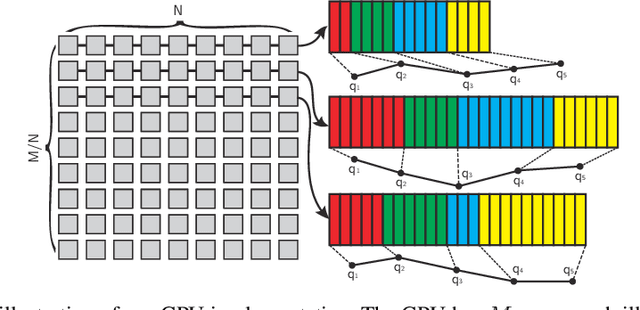
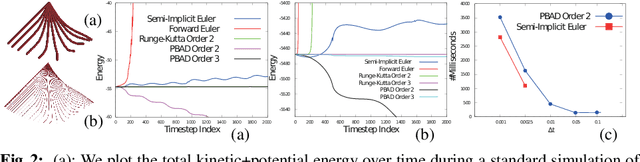
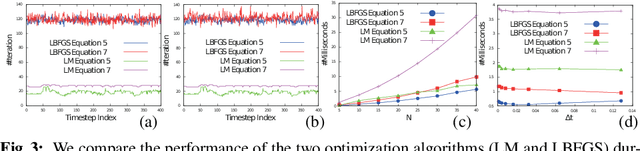
We present a new time integrator for articulated body dynamics. We formulate the governing equations of the dynamics using only the position variables and recast the position-based articulated dynamics as an optimization problem. Our reformulation allows us to integrate the dynamics in a fully implicit manner without computing high-order derivatives. Therefore, under arbitrarily large timestep sizes, the stability of our time integration scheme is guaranteed using an off-the-shelf numerical optimizer. In addition to stability, we show that, similar to the Runge-Kutta method, the accuracy of our time integrator can also be increased arbitrarily by using a high-order collocation method. We provide efficient algorithms to perform time integration using our position-based formulation. We show that each iteration of optimization has a complexity of O(N) using Quasi-Newton method or O(N^2) using Newton's method, where N is the number of links. Finally, our method is highly parallelizable and can be accelerated using a Graphics Processing Unit (GPU). We highlight the efficiency and stability of our method on different benchmarks and compare the performance with prior articulated body dynamics simulation methods based on the Newton-Euler's equation. Our method is stable under a timestep size as large as 0.1s. Using a larger timestep size and less timesteps, our method achieves up to 4 times speedup on a single-core CPU. With GPU acceleration, we observe an additional 3-6 times speedup over a 4-core CPU.
Real-time Neural-based Input Method
Oct 19, 2018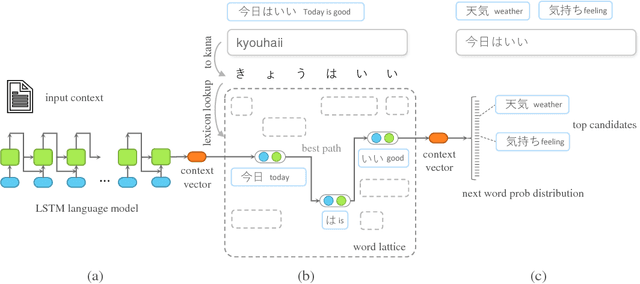
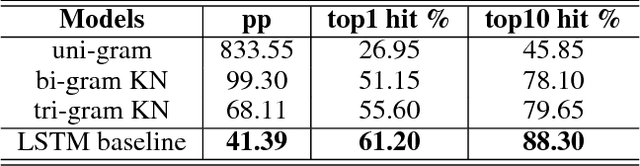
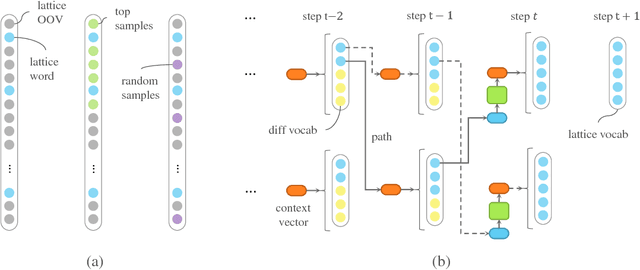
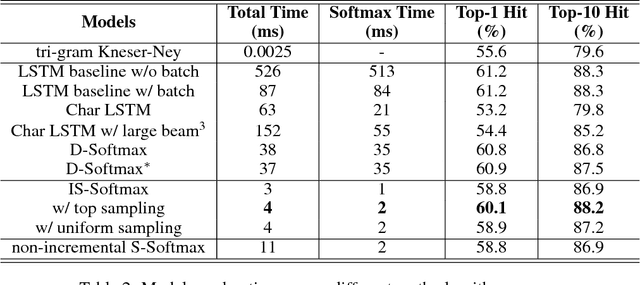
The input method is an essential service on every mobile and desktop devices that provides text suggestions. It converts sequential keyboard inputs to the characters in its target language, which is indispensable for Japanese and Chinese users. Due to critical resource constraints and limited network bandwidth of the target devices, applying neural models to input method is not well explored. In this work, we apply a LSTM-based language model to input method and evaluate its performance for both prediction and conversion tasks with Japanese BCCWJ corpus. We articulate the bottleneck to be the slow softmax computation during conversion. To solve the issue, we propose incremental softmax approximation approach, which computes softmax with a selected subset vocabulary and fix the stale probabilities when the vocabulary is updated in future steps. We refer to this method as incremental selective softmax. The results show a two order speedup for the softmax computation when converting Japanese input sequences with a large vocabulary, reaching real-time speed on commodity CPU. We also exploit the model compressing potential to achieve a 92% model size reduction without losing accuracy.
DEALIO: Data-Efficient Adversarial Learning for Imitation from Observation
Mar 31, 2021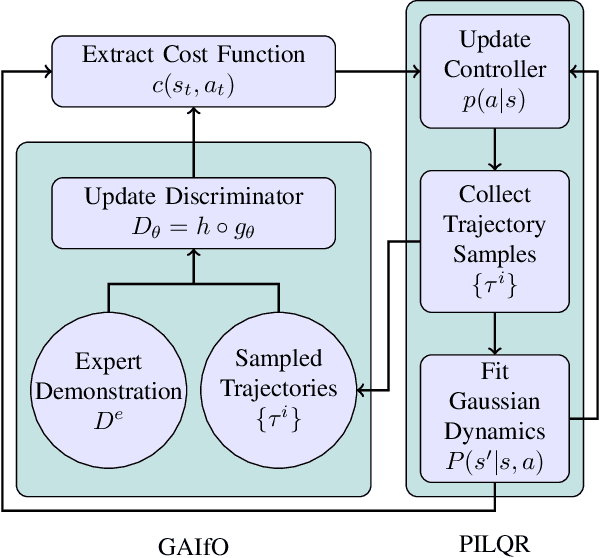
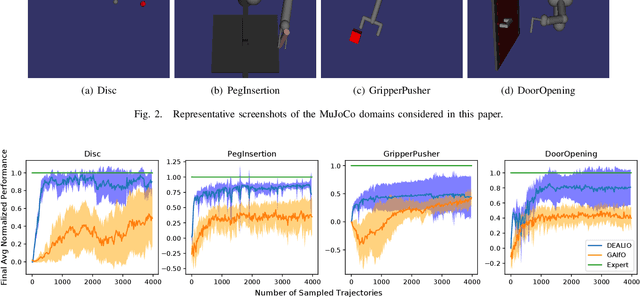
In imitation learning from observation IfO, a learning agent seeks to imitate a demonstrating agent using only observations of the demonstrated behavior without access to the control signals generated by the demonstrator. Recent methods based on adversarial imitation learning have led to state-of-the-art performance on IfO problems, but they typically suffer from high sample complexity due to a reliance on data-inefficient, model-free reinforcement learning algorithms. This issue makes them impractical to deploy in real-world settings, where gathering samples can incur high costs in terms of time, energy, and risk. In this work, we hypothesize that we can incorporate ideas from model-based reinforcement learning with adversarial methods for IfO in order to increase the data efficiency of these methods without sacrificing performance. Specifically, we consider time-varying linear Gaussian policies, and propose a method that integrates the linear-quadratic regulator with path integral policy improvement into an existing adversarial IfO framework. The result is a more data-efficient IfO algorithm with better performance, which we show empirically in four simulation domains: using far fewer interactions with the environment, the proposed method exhibits similar or better performance than the existing technique.