 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Go with the Flows: Mixtures of Normalizing Flows for Point Cloud Generation and Reconstruction
Jun 06, 2021
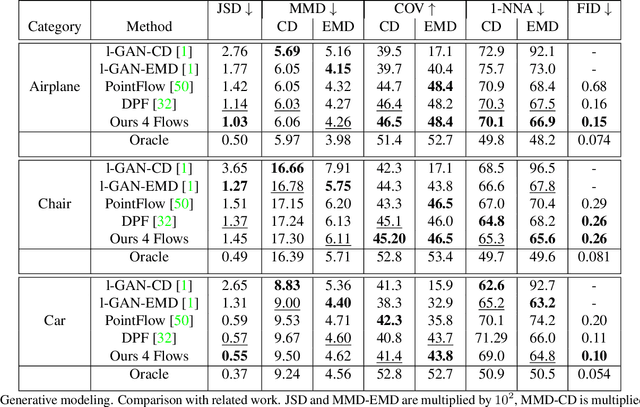
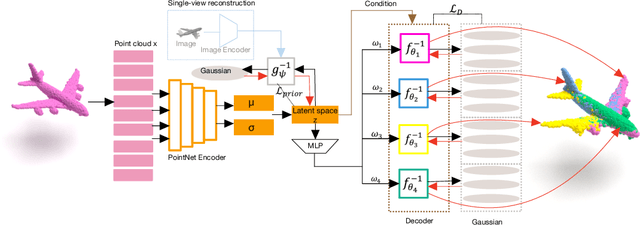
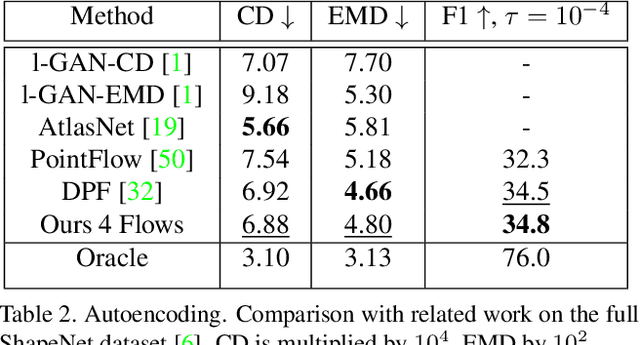
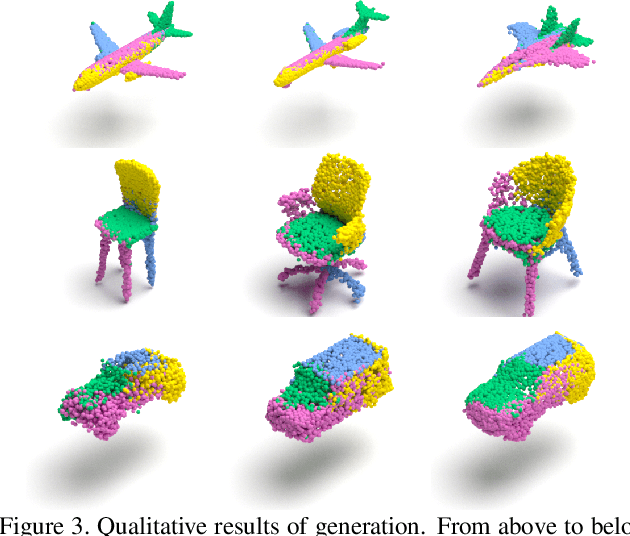
Recently normalizing flows (NFs) have demonstrated state-of-the-art performance on modeling 3D point clouds while allowing sampling with arbitrary resolution at inference time. However, these flow-based models still require long training times and large models for representing complicated geometries. This work enhances their representational power by applying mixtures of NFs to point clouds. We show that in this more general framework each component learns to specialize in a particular subregion of an object in a completely unsupervised fashion. By instantiating each mixture component with a comparatively small NF we generate point clouds with improved details compared to single-flow-based models while using fewer parameters and considerably reducing the inference runtime. We further demonstrate that by adding data augmentation, individual mixture components can learn to specialize in a semantically meaningful manner. We evaluate mixtures of NFs on generation, autoencoding and single-view reconstruction based on the ShapeNet dataset.
Bandit based centralized matching in two-sided markets for peer to peer lending
May 06, 2021
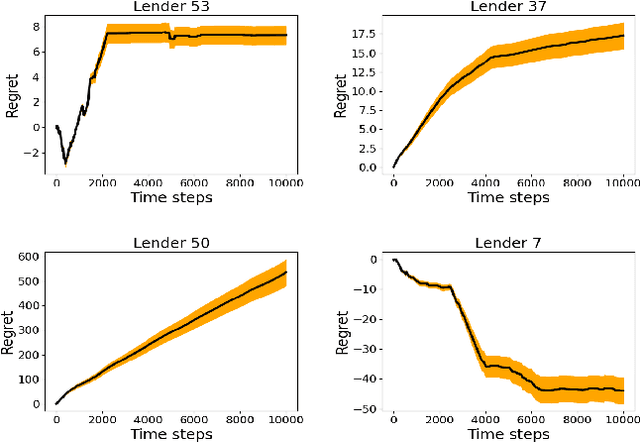
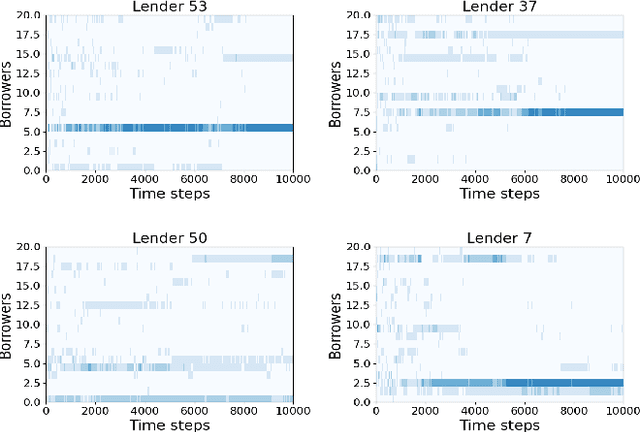
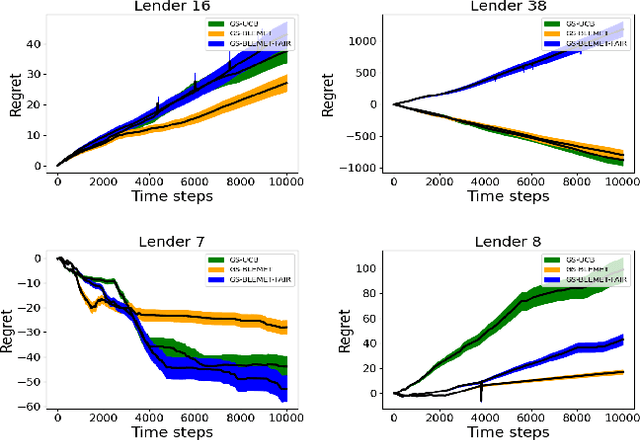
Sequential fundraising in two sided online platforms enable peer to peer lending by sequentially bringing potential contributors, each of whose decisions impact other contributors in the market. However, understanding the dynamics of sequential contributions in online platforms for peer lending has been an open ended research question. The centralized investment mechanism in these platforms makes it difficult to understand the implicit competition that borrowers face from a single lender at any point in time. Matching markets are a model of pairing agents where the preferences of agents from both sides in terms of their preferred pairing for transactions can allow to decentralize the market. We study investment designs in two sided platforms using matching markets when the investors or lenders also face restrictions on the investments based on borrower preferences. This situation creates an implicit competition among the lenders in addition to the existing borrower competition, especially when the lenders are uncertain about their standing in the market and thereby the probability of their investments being accepted or the borrower loan requests for projects reaching the reserve price. We devise a technique based on sequential decision making that allows the lenders to adjust their choices based on the dynamics of uncertainty from competition over time. We simulate two sided market matchings in a sequential decision framework and show the dynamics of the lender regret amassed compared to the optimal borrower-lender matching and find that the lender regret depends on the initial preferences set by the lenders which could affect their learning over decision making steps.
Dynamics-Regulated Kinematic Policy for Egocentric Pose Estimation
Jun 10, 2021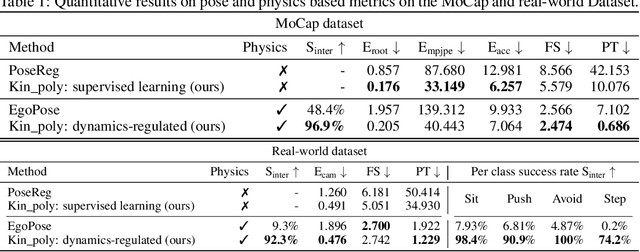
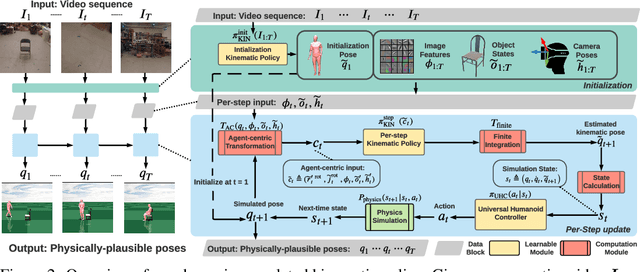
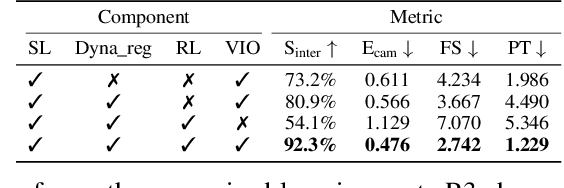
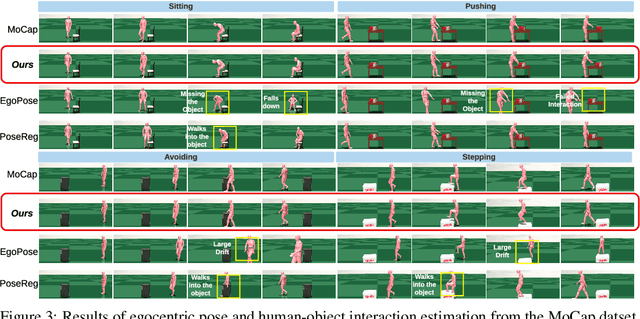
We propose a method for object-aware 3D egocentric pose estimation that tightly integrates kinematics modeling, dynamics modeling, and scene object information. Unlike prior kinematics or dynamics-based approaches where the two components are used disjointly, we synergize the two approaches via dynamics-regulated training. At each timestep, a kinematic model is used to provide a target pose using video evidence and simulation state. Then, a prelearned dynamics model attempts to mimic the kinematic pose in a physics simulator. By comparing the pose instructed by the kinematic model against the pose generated by the dynamics model, we can use their misalignment to further improve the kinematic model. By factoring in the 6DoF pose of objects (e.g., chairs, boxes) in the scene, we demonstrate for the first time, the ability to estimate physically-plausible 3D human-object interactions using a single wearable camera. We evaluate our egocentric pose estimation method in both controlled laboratory settings and real-world scenarios.
XCiT: Cross-Covariance Image Transformers
Jun 18, 2021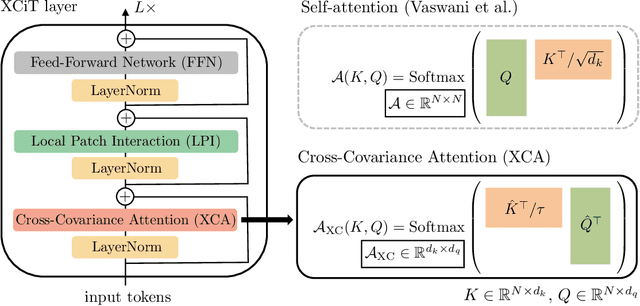
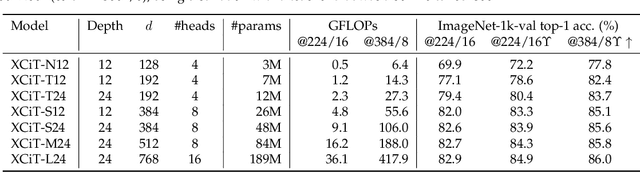
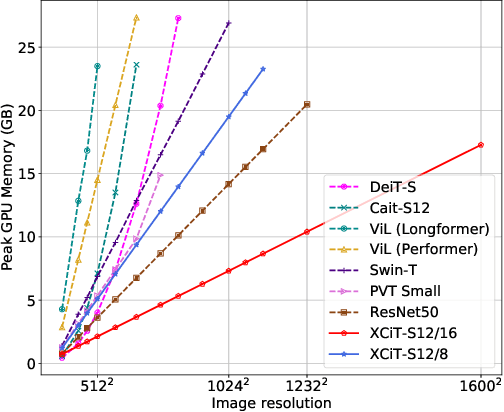
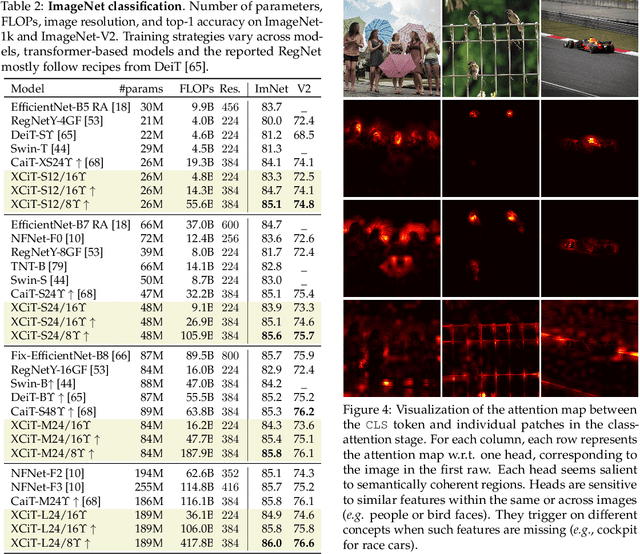
Following their success in natural language processing, transformers have recently shown much promise for computer vision. The self-attention operation underlying transformers yields global interactions between all tokens ,i.e. words or image patches, and enables flexible modelling of image data beyond the local interactions of convolutions. This flexibility, however, comes with a quadratic complexity in time and memory, hindering application to long sequences and high-resolution images. We propose a "transposed" version of self-attention that operates across feature channels rather than tokens, where the interactions are based on the cross-covariance matrix between keys and queries. The resulting cross-covariance attention (XCA) has linear complexity in the number of tokens, and allows efficient processing of high-resolution images. Our cross-covariance image transformer (XCiT) is built upon XCA. It combines the accuracy of conventional transformers with the scalability of convolutional architectures. We validate the effectiveness and generality of XCiT by reporting excellent results on multiple vision benchmarks, including image classification and self-supervised feature learning on ImageNet-1k, object detection and instance segmentation on COCO, and semantic segmentation on ADE20k.
Supersense and Sensibility: Proxy Tasks for Semantic Annotation of Prepositions
Mar 27, 2021Prepositional supersense annotation is time-consuming and requires expert training. Here, we present two sensible methods for obtaining prepositional supersense annotations by eliciting surface substitution and similarity judgments. Four pilot studies suggest that both methods have potential for producing prepositional supersense annotations that are comparable in quality to expert annotations.
Energy Efficient Data Recovery from Corrupted LoRa Frames
Jul 19, 2021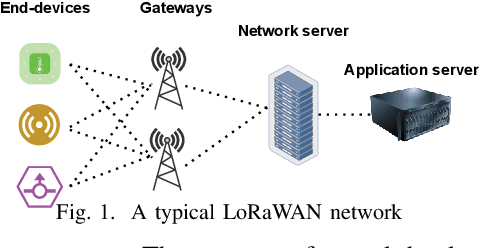
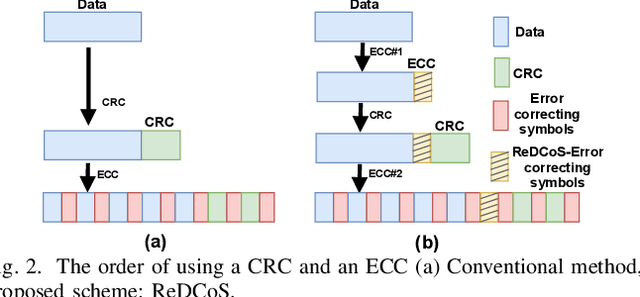
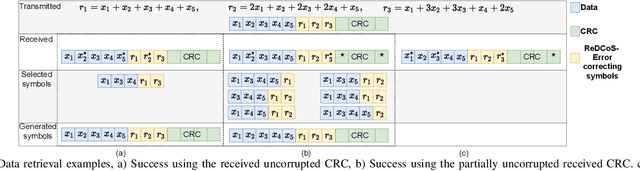
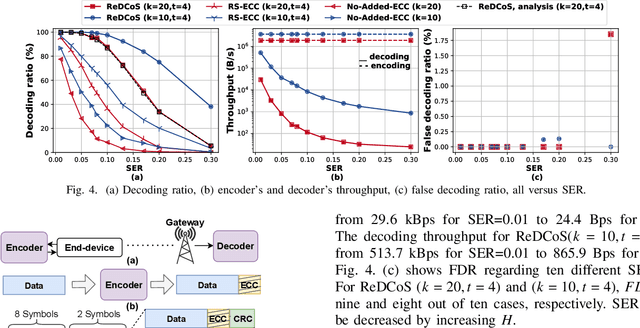
High frame-corruption is widely observed in Long Range Wide Area Networks (LoRaWAN) due to the coexistence with other networks in ISM bands and an Aloha-like MAC layer. LoRa's Forward Error Correction (FEC) mechanism is often insufficient to retrieve corrupted data. In fact, real-life measurements show that at least one-fourth of received transmissions are corrupted. When more frames are dropped, LoRa nodes usually switch over to higher spreading factors (SF), thus increasing transmission times and increasing the required energy. This paper introduces ReDCoS, a novel coding technique at the application layer that improves recovery of corrupted LoRa frames, thus reducing the overall transmission time and energy invested by LoRa nodes by several-fold. ReDCoS utilizes lightweight coding techniques to pre-encode the transmitted data. Therefore, the inbuilt Cyclic Redundancy Check (CRC) that follows is computed based on an already encoded data. At the receiver, we use both the CRC and the coded data to recover data from a corrupted frame beyond the built-in Error Correcting Code (ECC). We compare the performance of ReDCoS to (I) the standard FEC of vanilla-LoRaWAN, and to (ii) RS coding applied as ECC to the data of LoRaWAN. The results indicated a 54x and 13.5x improvement of decoding ratio, respectively, when 20 data symbols were sent. Furthermore, we evaluated ReDCoS on-field using LoRa SX1261 transceivers showing that it outperformed RS-coding by factor of at least 2x (and up to 6x) in terms of the decoding ratio while consuming 38.5% less energy per correctly received transmission.
Proximally Optimal Predictive Control Algorithm for Path Tracking of Self-Driving Cars
Mar 24, 2021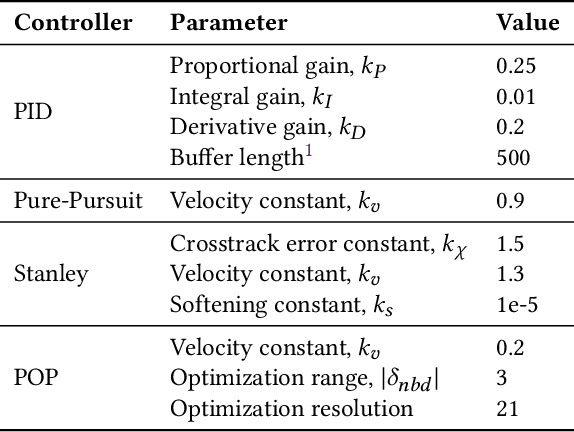
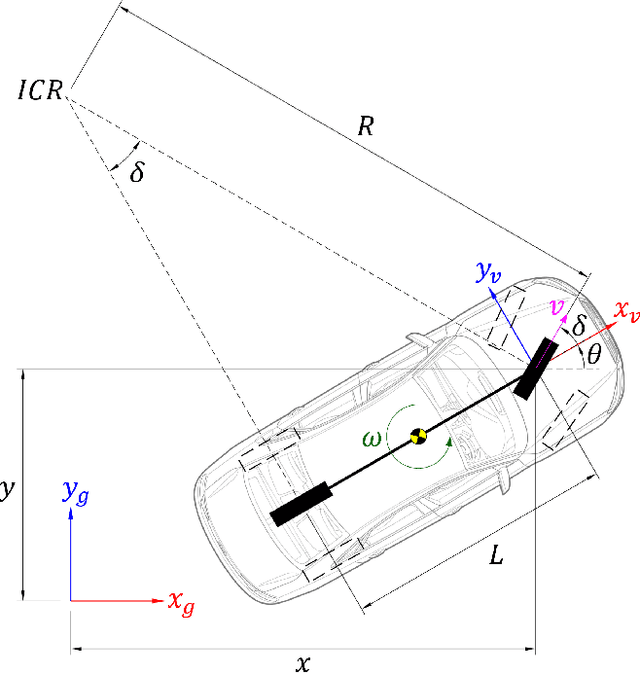

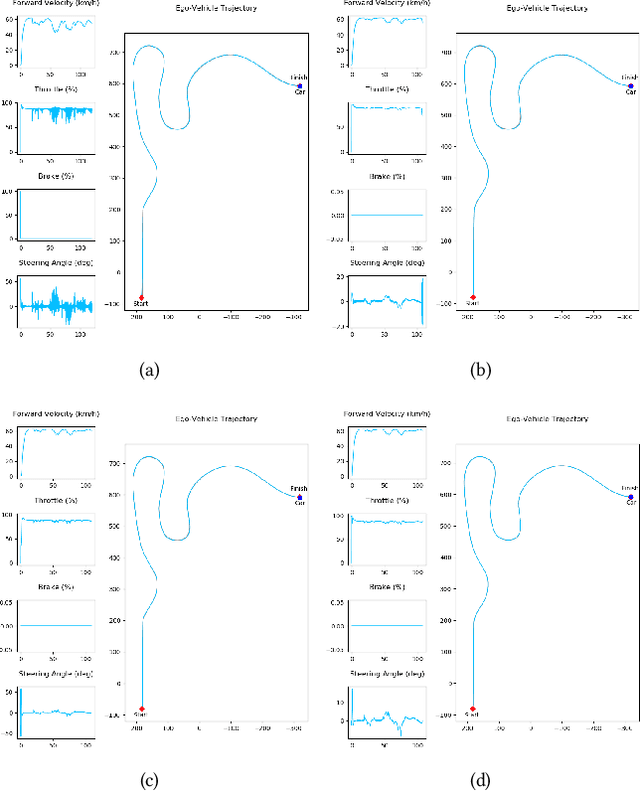
This work presents proximally optimal predictive control algorithm, which is essentially a model-based lateral controller for steered autonomous vehicles that selects an optimal steering command within the neighborhood of previous steering angle based on the predicted vehicle location. The proposed algorithm was formulated with an aim of overcoming the limitations associated with the existing control laws for autonomous steering - namely PID, Pure-Pursuit and Stanley controllers. Particularly, our approach was aimed at bridging the gap between tracking efficiency and computational cost, thereby ensuring effective path tracking in real-time. The effectiveness of our approach was investigated through a series of dynamic simulation experiments pertaining to autonomous path tracking, employing an adaptive control law for longitudinal motion control of the vehicle. We measured the latency of the proposed algorithm in order to comment on its real-time factor and validated our approach by comparing it against the established control laws in terms of both crosstrack and heading errors recorded throughout the respective path tracking simulations.
Learning To Count Everything
Apr 16, 2021
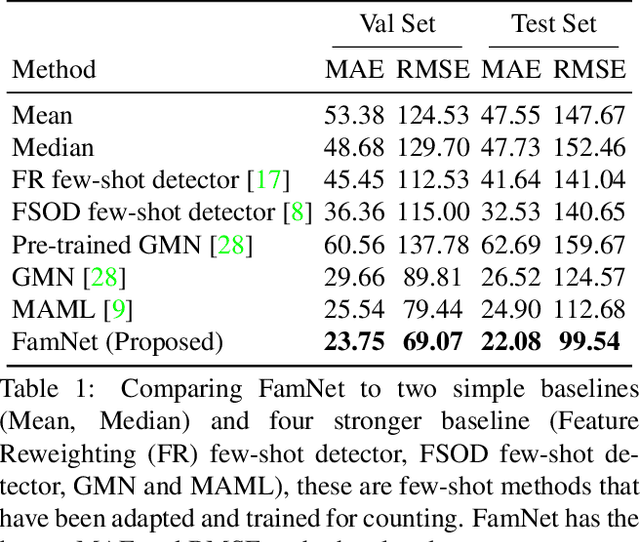
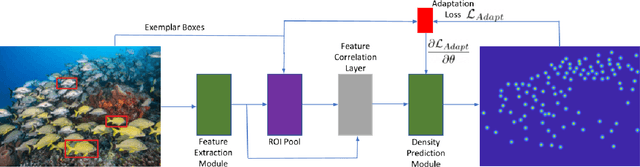
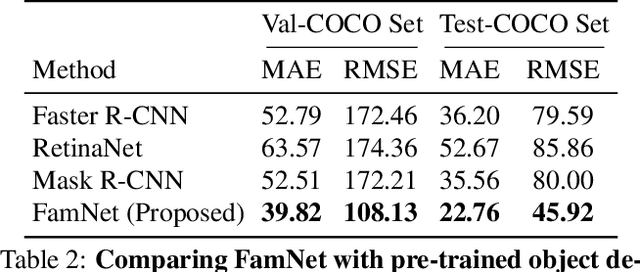
Existing works on visual counting primarily focus on one specific category at a time, such as people, animals, and cells. In this paper, we are interested in counting everything, that is to count objects from any category given only a few annotated instances from that category. To this end, we pose counting as a few-shot regression task. To tackle this task, we present a novel method that takes a query image together with a few exemplar objects from the query image and predicts a density map for the presence of all objects of interest in the query image. We also present a novel adaptation strategy to adapt our network to any novel visual category at test time, using only a few exemplar objects from the novel category. We also introduce a dataset of 147 object categories containing over 6000 images that are suitable for the few-shot counting task. The images are annotated with two types of annotation, dots and bounding boxes, and they can be used for developing few-shot counting models. Experiments on this dataset shows that our method outperforms several state-of-the-art object detectors and few-shot counting approaches. Our code and dataset can be found at https://github.com/cvlab-stonybrook/LearningToCountEverything.
A Novel CNN-LSTM-based Approach to Predict Urban Expansion
Mar 02, 2021Time-series remote sensing data offer a rich source of information that can be used in a wide range of applications, from monitoring changes in land cover to surveilling crops, coastal changes, flood risk assessment, and urban sprawl. This paper addresses the challenge of using time-series satellite images to predict urban expansion. Building upon previous work, we propose a novel two-step approach based on semantic image segmentation in order to predict urban expansion. The first step aims to extract information about urban regions at different time scales and prepare them for use in the training step. The second step combines Convolutional Neural Networks (CNN) with Long Short Term Memory (LSTM) methods in order to learn temporal features and thus predict urban expansion. In this paper, experimental results are conducted using several multi-date satellite images representing the three largest cities in Saudi Arabia, namely: Riyadh, Jeddah, and Dammam. We empirically evaluated our proposed technique, and examined its results by comparing them with state-of-the-art approaches. Following this evaluation, we determined that our results reveal improved performance for the new-coupled CNN-LSTM approach, particularly in terms of assessments based on Mean Square Error, Root Mean Square Error, Peak Signal to Noise Ratio, Structural Similarity Index, and overall classification accuracy.
Optimal control gradient precision trade-offs: application to fast generation of DeepControl libraries for MRI
Jul 02, 2021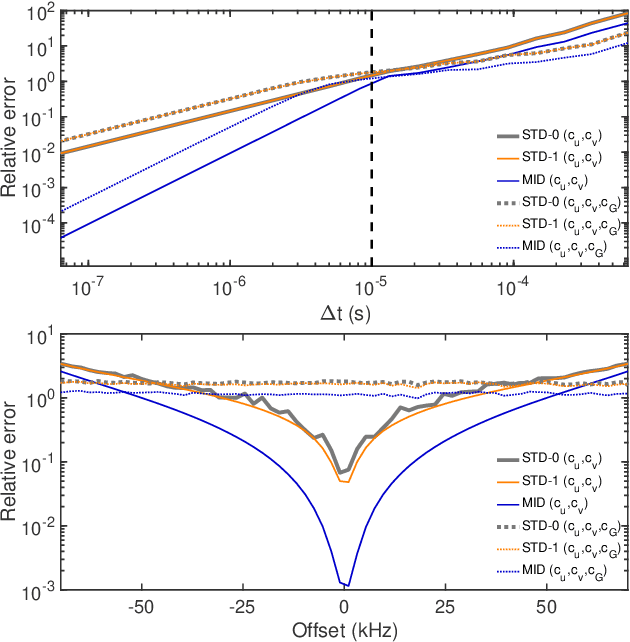
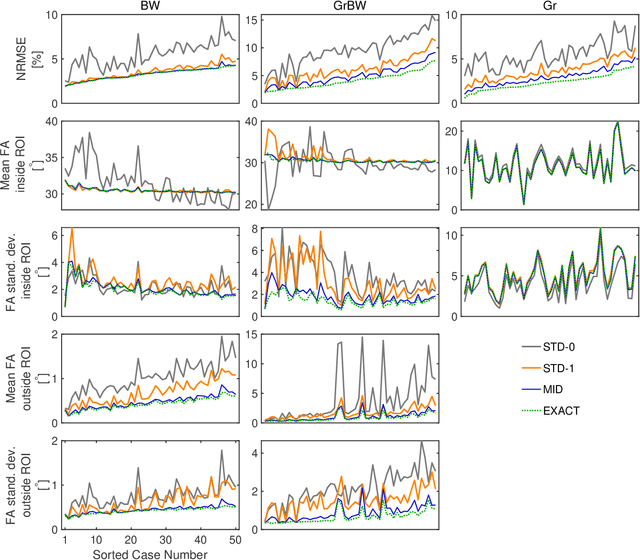
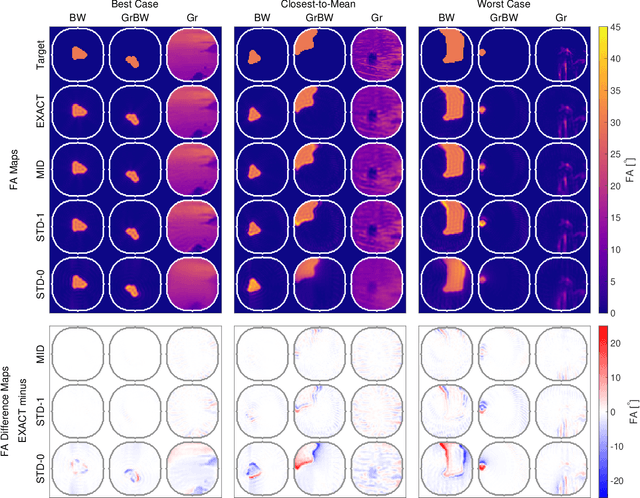
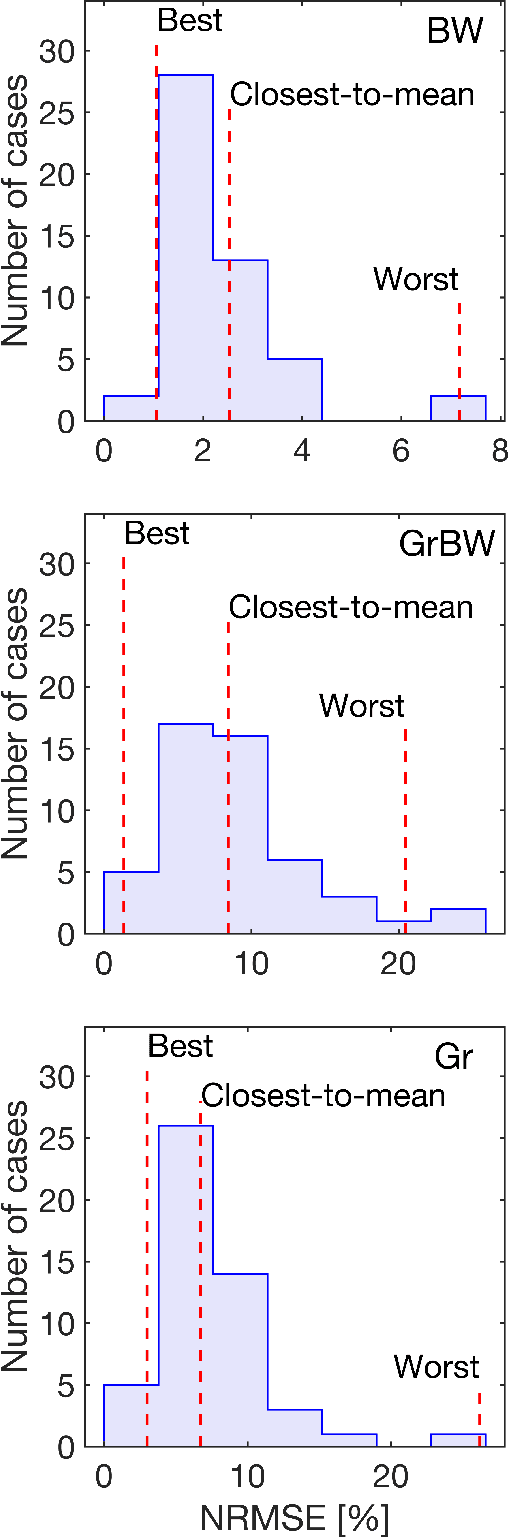
We have recently demonstrated supervised deep learning methods for rapid generation of radiofrequency pulses in magnetic resonance imaging (https://doi.org/10.1002/mrm.27740, https://doi.org/10.1002/mrm.28667). Unlike the previous iterative optimization approaches, deep learning methods generate a pulse using a fixed number of floating-point operations - this is important in MRI, where patient-specific pulses preferably must be produced in real time. However, deep learning requires vast training libraries, which must be generated using the traditional methods, e.g. iterative quantum optimal control methods. Those methods are usually variations of gradient descent, and the calculation of the fidelity gradient of the performance metric with respect to the pulse waveform can be the most numerically intensive step. In this communication, we explore various ways in which the calculation of fidelity gradients in quantum optimal control theory may be accelerated. Four optimization avenues are explored: truncated commutator series expansions at zeroth and first order, a novel midpoint truncation scheme at first order, and the exact complex-step method. For the spin systems relevant to MRI, the first-order truncation is found to be sufficiently accurate, but also up to five times faster than the machine precision gradient. This makes the generation of training databases for the machine learning methods considerably more realistic.