 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
$\mathcal{N}$IPM-HLSP: An Efficient Interior-Point Method for Hierarchical Least-Squares Programs
Jun 25, 2021

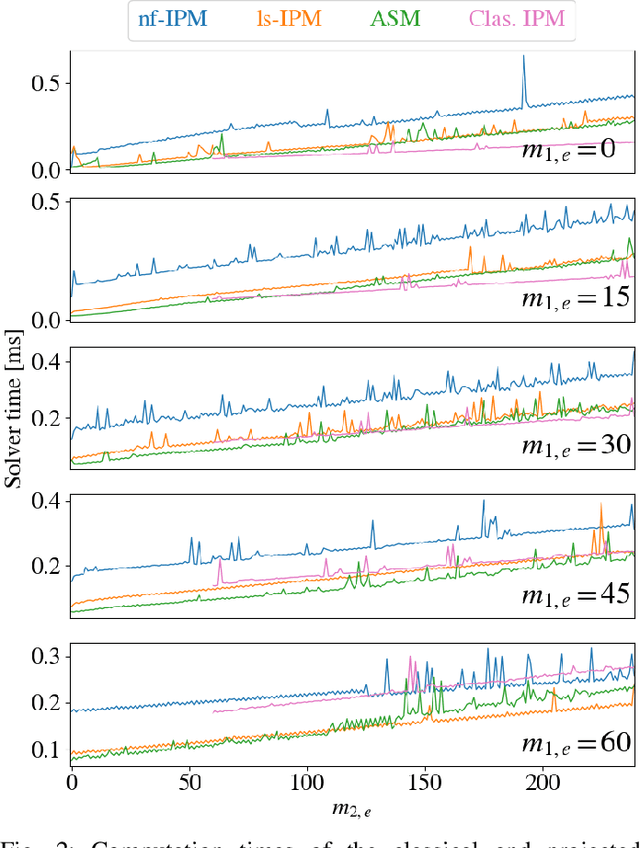


Hierarchical least-squares programs with linear constraints (HLSP) are a type of optimization problem very common in robotics. Each priority level contains an objective in least-squares form which is subject to the linear constraints of the higher priority hierarchy levels. Active-set methods (ASM) are a popular choice for solving them. However, they can perform poorly in terms of computational time if there are large changes of the active set. We therefore propose a computationally efficient primal-dual interior-point method (IPM) for HLSP's which is able to maintain constant numbers of solver iterations in these situations. We base our IPM on the null-space method which requires only a single decomposition per Newton iteration instead of two as it is the case for other IPM solvers. After a priority level has converged we compose a set of active constraints judging upon the dual and project lower priority levels into their null-space. We show that the IPM-HLSP can be expressed in least-squares form which avoids the formation of the quadratic Karush-Kuhn-Tucker (KKT) Hessian. Due to our choice of the null-space basis the IPM-HLSP is as fast as the state-of-the-art ASM-HLSP solver for equality only problems.
Capturing Structure Implicitly from Time-Series having Limited Data
Mar 15, 2018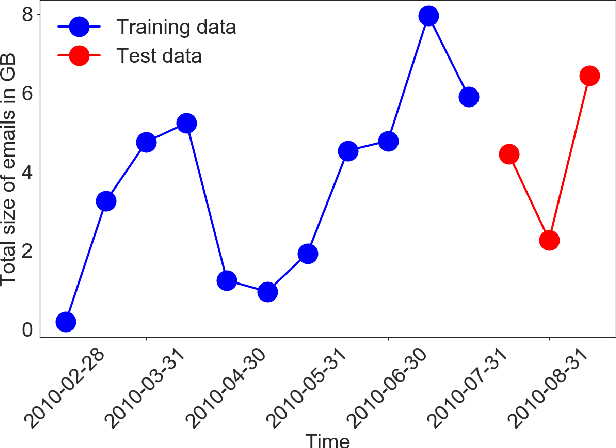

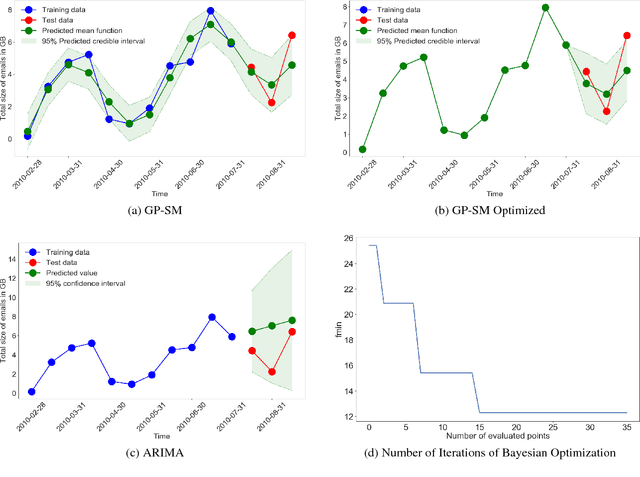
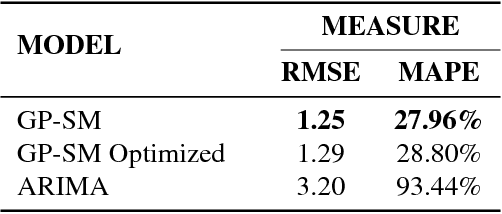
Scientific fields such as insider-threat detection and highway-safety planning often lack sufficient amounts of time-series data to estimate statistical models for the purpose of scientific discovery. Moreover, the available limited data are quite noisy. This presents a major challenge when estimating time-series models that are robust to overfitting and have well-calibrated uncertainty estimates. Most of the current literature in these fields involve visualizing the time-series for noticeable structure and hard coding them into pre-specified parametric functions. This approach is associated with two limitations. First, given that such trends may not be easily noticeable in small data, it is difficult to explicitly incorporate expressive structure into the models during formulation. Second, it is difficult to know $\textit{a priori}$ the most appropriate functional form to use. To address these limitations, a nonparametric Bayesian approach was proposed to implicitly capture hidden structure from time series having limited data. The proposed model, a Gaussian process with a spectral mixture kernel, precludes the need to pre-specify a functional form and hard code trends, is robust to overfitting and has well-calibrated uncertainty estimates.
Sequential Estimation of Convex Divergences using Reverse Submartingales and Exchangeable Filtrations
Mar 16, 2021We present a unified technique for sequential estimation of convex divergences between distributions, including integral probability metrics like the kernel maximum mean discrepancy, $\varphi$-divergences like the Kullback-Leibler divergence, and optimal transport costs, such as powers of Wasserstein distances. The technical underpinnings of our approach lie in the observation that empirical convex divergences are (partially ordered) reverse submartingales with respect to the exchangeable filtration, coupled with maximal inequalities for such processes. These techniques appear to be powerful additions to the existing literature on both confidence sequences and convex divergences. We construct an offline-to-sequential device that converts a wide array of existing offline concentration inequalities into time-uniform confidence sequences that can be continuously monitored, providing valid inference at arbitrary stopping times. The resulting sequential bounds pay only an iterated logarithmic price over the corresponding fixed-time bounds, retaining the same dependence on problem parameters (like dimension or alphabet size if applicable).
Multiview Video Compression Using Advanced HEVC Screen Content Coding
Jun 25, 2021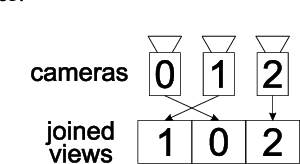

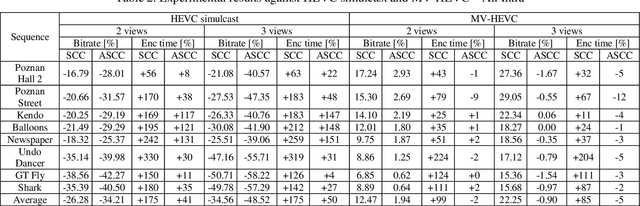
The paper presents a new approach to multiview video coding using Screen Content Coding. It is assumed that for a time instant the frames corresponding to all views are packed into a single frame, i.e. the frame-compatible approach to multiview coding is applied. For such coding scenario, the paper demonstrates that Screen Content Coding can be efficiently used for multiview video coding. Two approaches are considered: the first using standard HEVC Screen Content Coding, and the second using Advanced Screen Content Coding. The latter is the original proposal of the authors that exploits quarter-pel motion vectors and other nonstandard extensions of HEVC Screen Content Coding. The experimental results demonstrate that multiview video coding even using standard HEVC Screen Content Coding is much more efficient than simulcast HEVC coding. The proposed Advanced Screen Content Coding provides virtually the same coding efficiency as MV-HEVC, which is the state-of-the-art multiview video compression technique. The authors suggest that Advanced Screen Content Coding can be efficiently used within the new Versatile Video Coding (VVC) technology. Nevertheless a reference multiview extension of VVC does not exist yet, therefore, for VVC-based coding, the experimental comparisons are left for future work.
MOROCCO: Model Resource Comparison Framework
Apr 29, 2021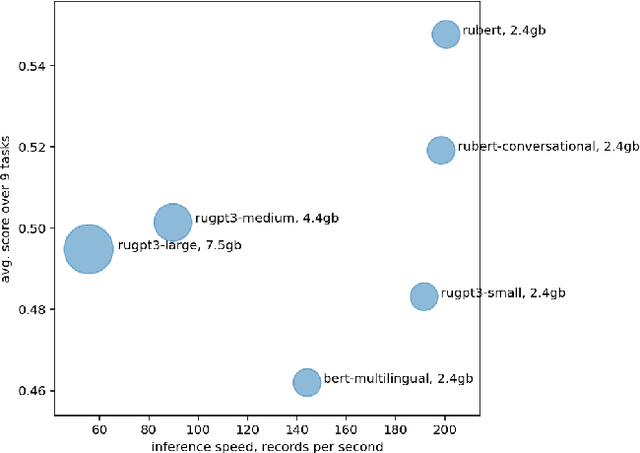
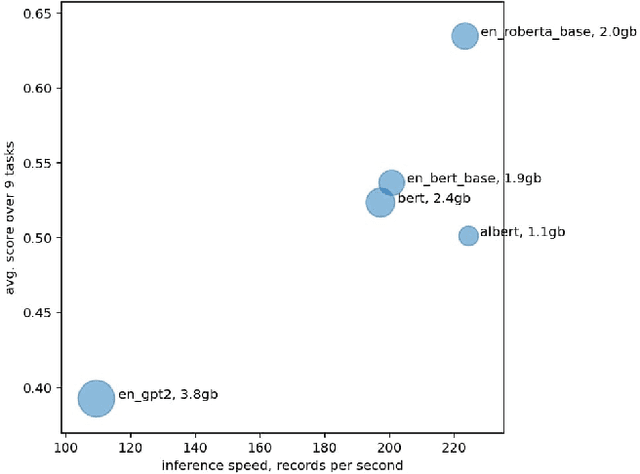
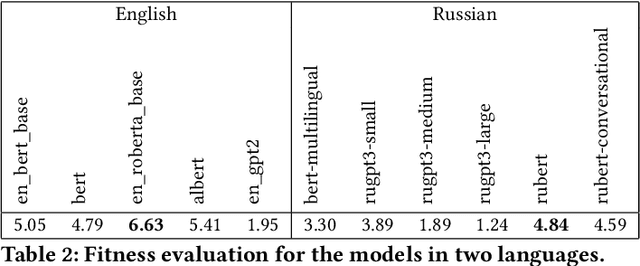
The new generation of pre-trained NLP models push the SOTA to the new limits, but at the cost of computational resources, to the point that their use in real production environments is often prohibitively expensive. We tackle this problem by evaluating not only the standard quality metrics on downstream tasks but also the memory footprint and inference time. We present MOROCCO, a framework to compare language models compatible with \texttt{jiant} environment which supports over 50 NLU tasks, including SuperGLUE benchmark and multiple probing suites. We demonstrate its applicability for two GLUE-like suites in different languages.
A Novel Multi-scale Dilated 3D CNN for Epileptic Seizure Prediction
May 05, 2021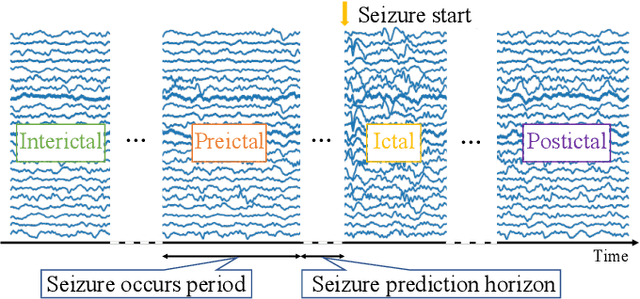

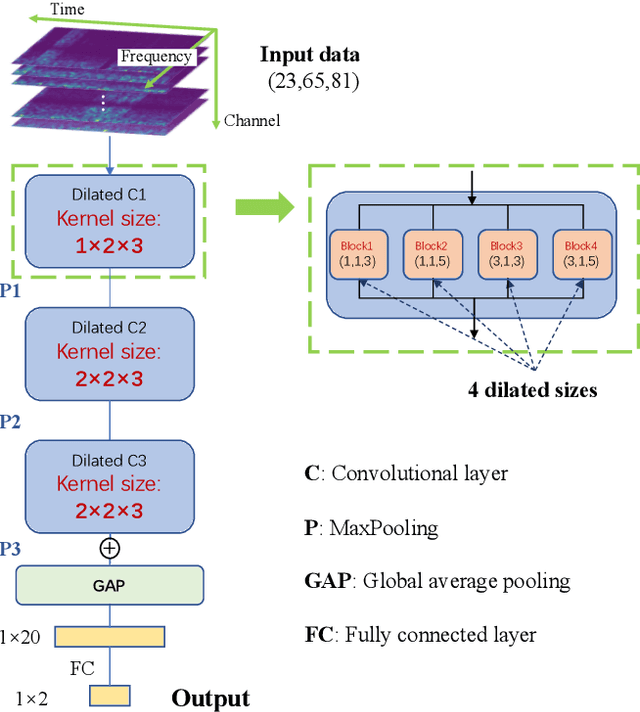
Accurate prediction of epileptic seizures allows patients to take preventive measures in advance to avoid possible injuries. In this work, a novel convolutional neural network (CNN) is proposed to analyze time, frequency, and channel information of electroencephalography (EEG) signals. The model uses three-dimensional (3D) kernels to facilitate the feature extraction over the three dimensions. The application of multiscale dilated convolution enables the 3D kernel to have more flexible receptive fields. The proposed CNN model is evaluated with the CHB-MIT EEG database, the experimental results indicate that our model outperforms the existing state-of-the-art, achieves 80.5% accuracy, 85.8% sensitivity and 75.1% specificity.
Dimensionality Reduction for Stationary Time Series via Stochastic Nonconvex Optimization
Oct 01, 2018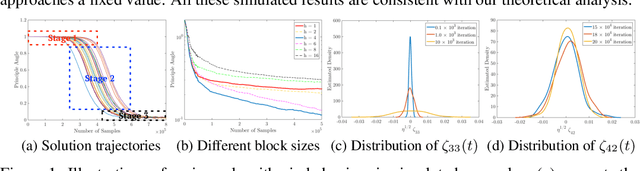
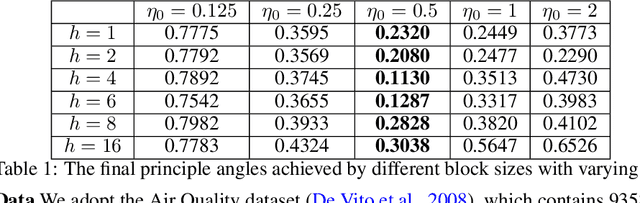

Stochastic optimization naturally arises in machine learning. Efficient algorithms with provable guarantees, however, are still largely missing, when the objective function is nonconvex and the data points are dependent. This paper studies this fundamental challenge through a streaming PCA problem for stationary time series data. Specifically, our goal is to estimate the principle component of time series data with respect to the covariance matrix of the stationary distribution. Computationally, we propose a variant of Oja's algorithm combined with downsampling to control the bias of the stochastic gradient caused by the data dependency. Theoretically, we quantify the uncertainty of our proposed stochastic algorithm based on diffusion approximations. This allows us to prove the asymptotic rate of convergence and further implies near optimal asymptotic sample complexity. Numerical experiments are provided to support our analysis.
SMET: Scenario-based Metamorphic Testing for Autonomous Driving Models
Apr 02, 2021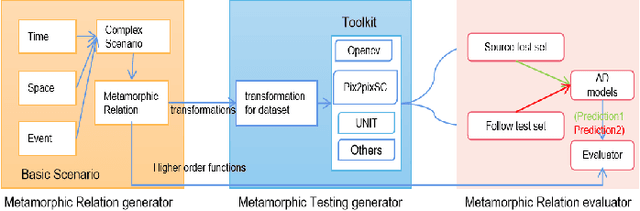
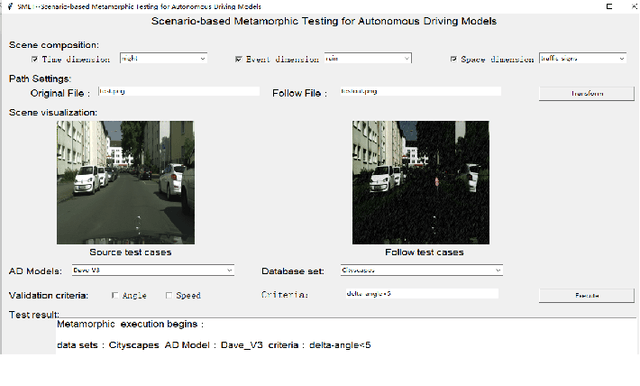
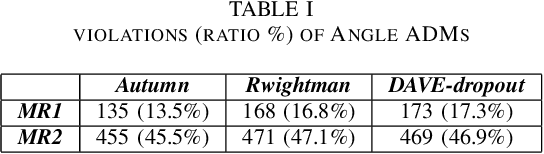
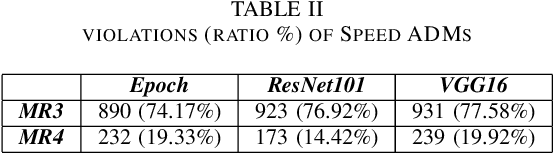
To improve the security and robustness of autonomous driving models, this paper presents SMET, a scenariobased metamorphic testing tool for autonomous driving models. The metamorphic relationship is divided into three dimensions (time, space, and event) and demonstrates its effectiveness through case studies in two types of autonomous driving models with different outputs.Experimental results show that this tool canwelldetectpotentialdefectsoftheautonomousdrivingmodel, and complex scenes are more effective than simple scenes.
Bi-objective Search with Bi-directional A*
May 25, 2021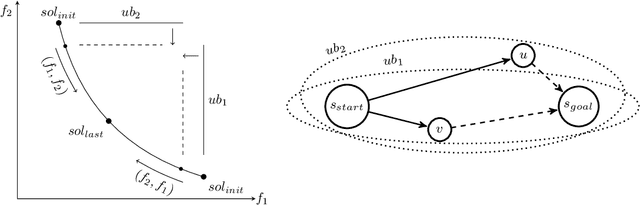
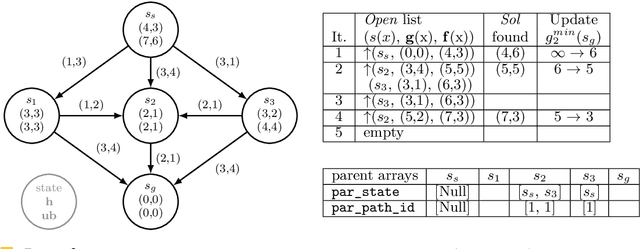
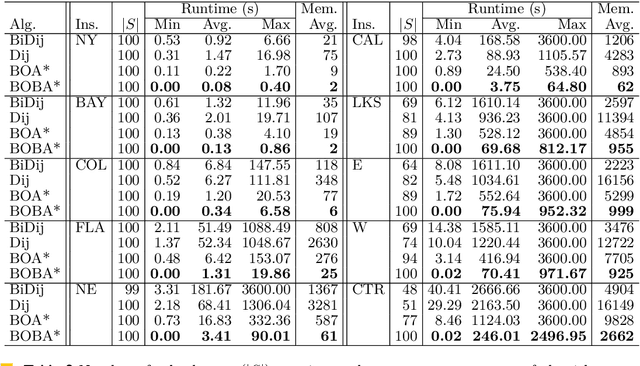
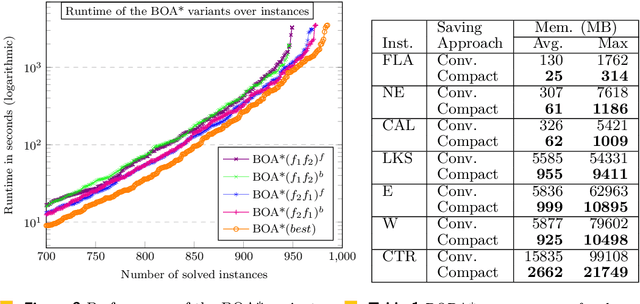
Bi-objective search is a well-known algorithmic problem, concerned with finding a set of optimal solutions in a two-dimensional domain. This problem has a wide variety of applications such as planning in transport systems or optimal control in energy systems. Recently, bi-objective A*-based search (BOA*) has shown state-of-the-art performance in large networks. This paper develops a bi-directional variant of BOA*, enriched with several speed-up heuristics. Our experimental results on 1,000 benchmark cases show that our bi-directional A* algorithm for bi-objective search (BOBA*) can optimally solve all of the benchmark cases within the time limit, outperforming the state of the art BOA*, bi-objective Dijkstra and bi-directional bi-objective Dijkstra by an average runtime improvement of a factor of five over all of the benchmark instances.
Spectrum Correction: Acoustic Scene Classification with Mismatched Recording Devices
May 25, 2021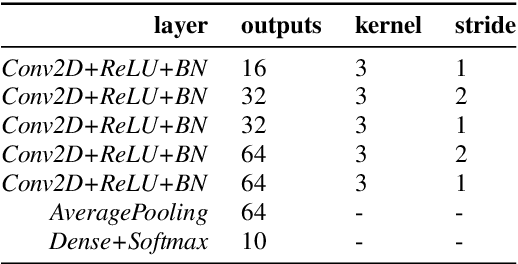
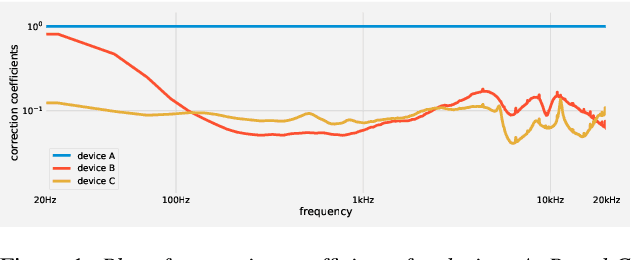
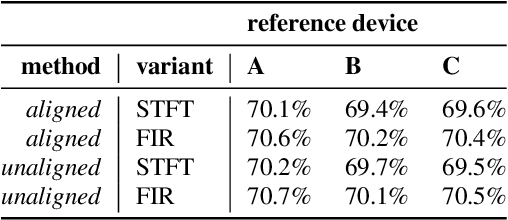
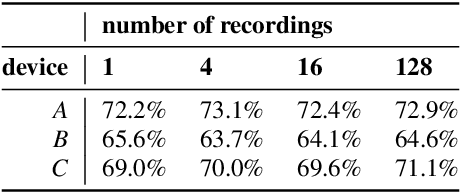
Machine learning algorithms, when trained on audio recordings from a limited set of devices, may not generalize well to samples recorded using other devices with different frequency responses. In this work, a relatively straightforward method is introduced to address this problem. Two variants of the approach are presented. First requires aligned examples from multiple devices, the second approach alleviates this requirement. This method works for both time and frequency domain representations of audio recordings. Further, a relation to standardization and Cepstral Mean Subtraction is analysed. The proposed approach becomes effective even when very few examples are provided. This method was developed during the Detection and Classification of Acoustic Scenes and Events (DCASE) 2019 challenge and won the 1st place in the scenario with mis-matched recording devices with the accuracy of 75%. Source code for the experiments can be found online.
* 5 pages, 1 figure, published at Interspeech 2020, see https://isca-speech.org/archive/Interspeech_2020/abstracts/3088.html