 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AI Empowered Resource Management for Future Wireless Networks
Jun 11, 2021
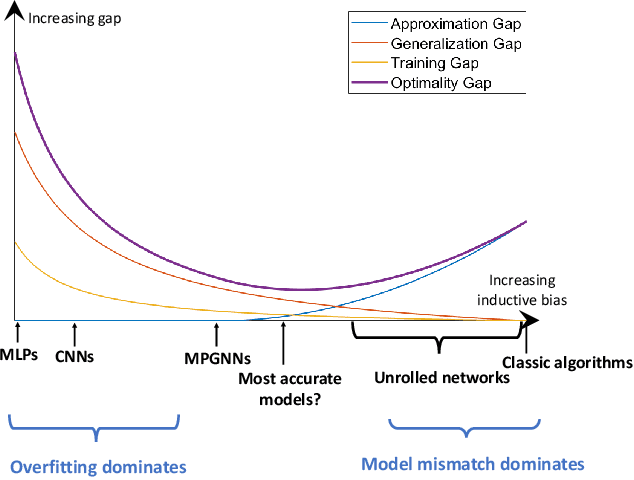
Resource management plays a pivotal role in wireless networks, which, unfortunately, leads to challenging NP-hard problems. Artificial Intelligence (AI), especially deep learning techniques, has recently emerged as a disruptive technology to solve such challenging problems in a real-time manner. However, although promising results have been reported, practical design guidelines and performance guarantees of AI-based approaches are still missing. In this paper, we endeavor to address two fundamental questions: 1) What are the main advantages of AI-based methods compared with classical techniques; and 2) Which neural network should we choose for a given resource management task. For the first question, four advantages are identified and discussed. For the second question, \emph{optimality gap}, i.e., the gap to the optimal performance, is proposed as a measure for selecting model architectures, as well as, for enabling a theoretical comparison between different AI-based approaches. Specifically, for $K$-user interference management problem, we theoretically show that graph neural networks (GNNs) are superior to multi-layer perceptrons (MLPs), and the performance gap between these two methods grows with $\sqrt{K}$.
DynaComm: Accelerating Distributed CNN Training between Edges and Clouds through Dynamic Communication Scheduling
Jan 20, 2021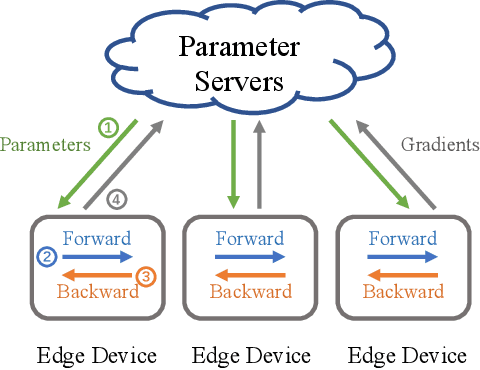
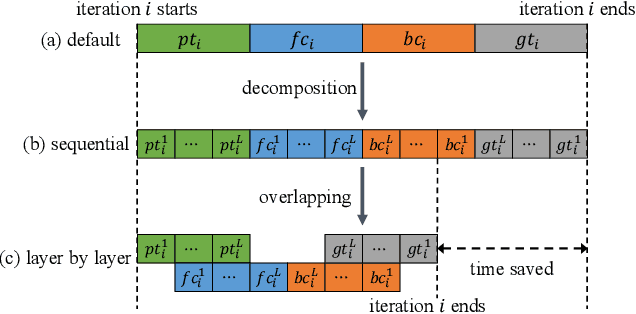
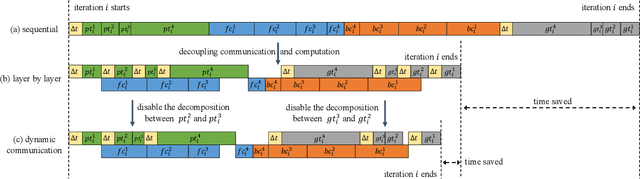
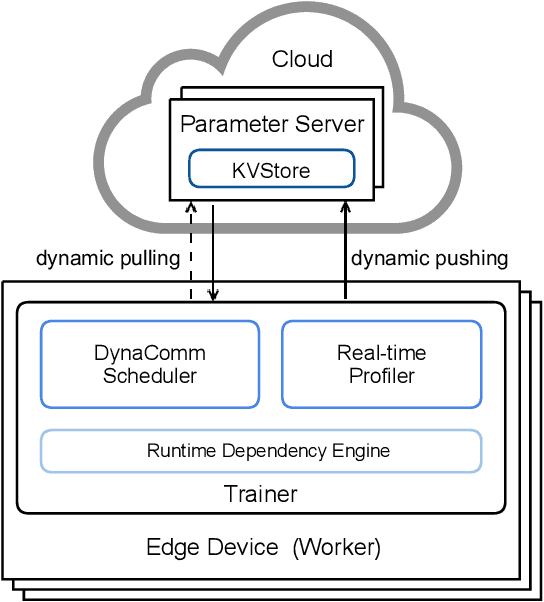
To reduce uploading bandwidth and address privacy concerns, deep learning at the network edge has been an emerging topic. Typically, edge devices collaboratively train a shared model using real-time generated data through the Parameter Server framework. Although all the edge devices can share the computing workloads, the distributed training processes over edge networks are still time-consuming due to the parameters and gradients transmission procedures between parameter servers and edge devices. Focusing on accelerating distributed Convolutional Neural Networks (CNNs) training at the network edge, we present DynaComm, a novel scheduler that dynamically decomposes each transmission procedure into several segments to achieve optimal communications and computations overlapping during run-time. Through experiments, we verify that DynaComm manages to achieve optimal scheduling for all cases compared to competing strategies while the model accuracy remains untouched.
Uniform-in-Time Weak Error Analysis for Stochastic Gradient Descent Algorithms via Diffusion Approximation
Feb 02, 2019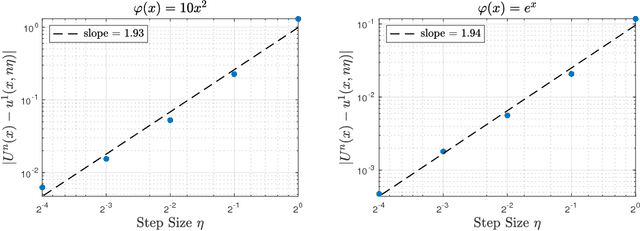
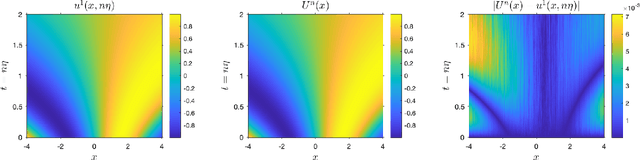
Diffusion approximation provides weak approximation for stochastic gradient descent algorithms in a finite time horizon. In this paper, we introduce new tools motivated by the backward error analysis of numerical stochastic differential equations into the theoretical framework of diffusion approximation, extending the validity of the weak approximation from finite to infinite time horizon. The new techniques developed in this paper enable us to characterize the asymptotic behavior of constant-step-size SGD algorithms for strongly convex objective functions, a goal previously unreachable within the diffusion approximation framework. Our analysis builds upon a truncated formal power expansion of the solution of a stochastic modified equation arising from diffusion approximation, where the main technical ingredient is a uniform-in-time weak error bound controlling the long-term behavior of the expansion coefficient functions near the global minimum. We expect these new techniques to greatly expand the range of applicability of diffusion approximation to cover wider and deeper aspects of stochastic optimization algorithms in data science.
Controllable Abstractive Dialogue Summarization with Sketch Supervision
Jun 03, 2021
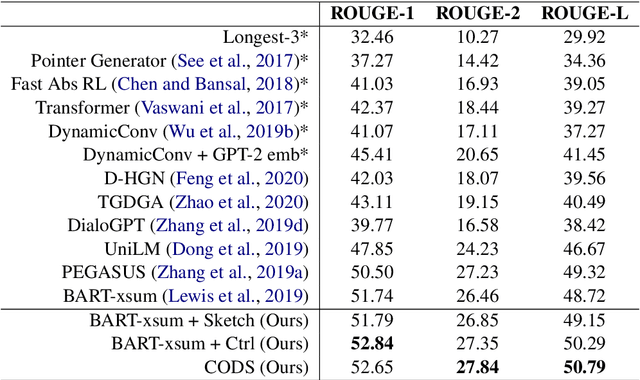
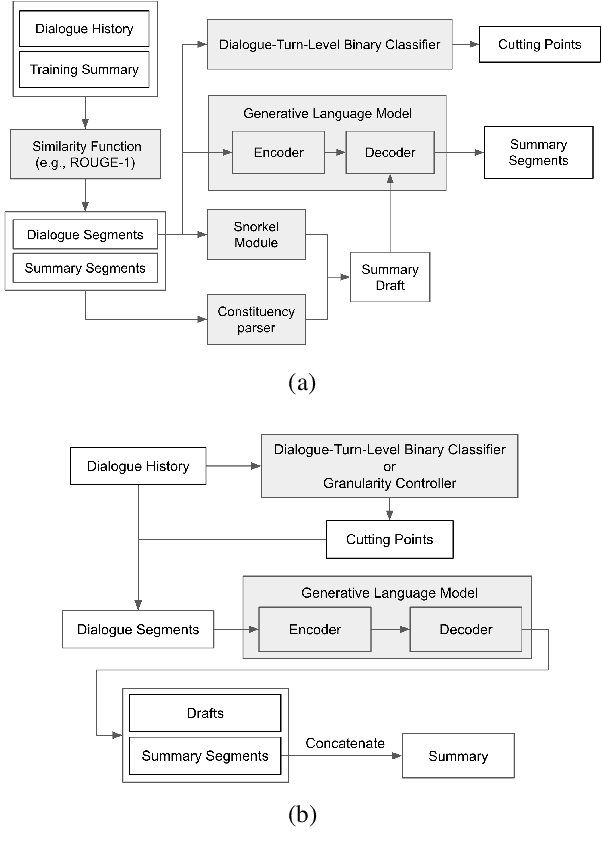

In this paper, we aim to improve abstractive dialogue summarization quality and, at the same time, enable granularity control. Our model has two primary components and stages: 1) a two-stage generation strategy that generates a preliminary summary sketch serving as the basis for the final summary. This summary sketch provides a weakly supervised signal in the form of pseudo-labeled interrogative pronoun categories and key phrases extracted using a constituency parser. 2) A simple strategy to control the granularity of the final summary, in that our model can automatically determine or control the number of generated summary sentences for a given dialogue by predicting and highlighting different text spans from the source text. Our model achieves state-of-the-art performance on the largest dialogue summarization corpus SAMSum, with as high as 50.79 in ROUGE-L score. In addition, we conduct a case study and show competitive human evaluation results and controllability to human-annotated summaries.
Bi-objective Search with Bi-directional A*
May 25, 2021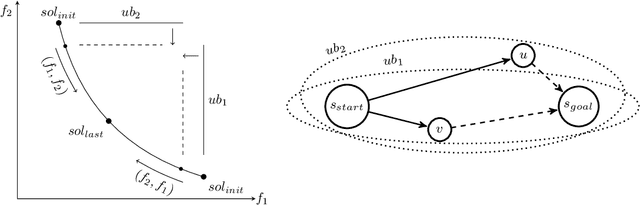
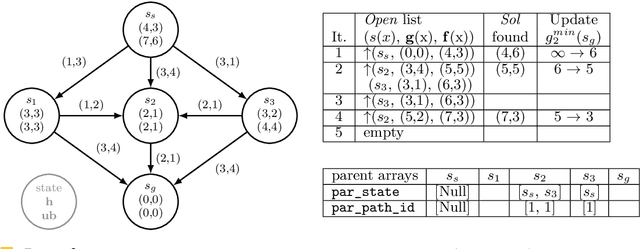
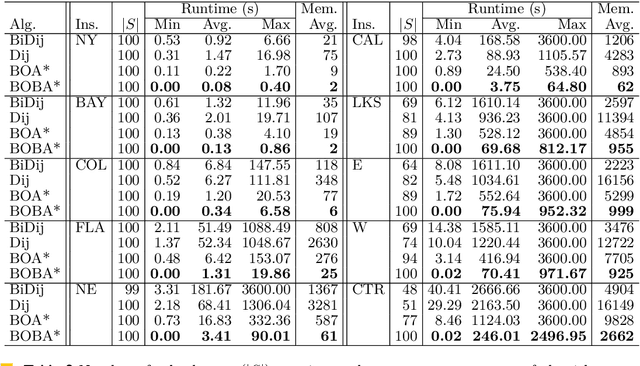
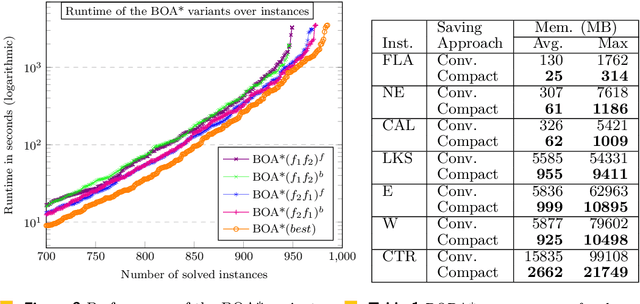
Bi-objective search is a well-known algorithmic problem, concerned with finding a set of optimal solutions in a two-dimensional domain. This problem has a wide variety of applications such as planning in transport systems or optimal control in energy systems. Recently, bi-objective A*-based search (BOA*) has shown state-of-the-art performance in large networks. This paper develops a bi-directional variant of BOA*, enriched with several speed-up heuristics. Our experimental results on 1,000 benchmark cases show that our bi-directional A* algorithm for bi-objective search (BOBA*) can optimally solve all of the benchmark cases within the time limit, outperforming the state of the art BOA*, bi-objective Dijkstra and bi-directional bi-objective Dijkstra by an average runtime improvement of a factor of five over all of the benchmark instances.
Spectrum Correction: Acoustic Scene Classification with Mismatched Recording Devices
May 25, 2021
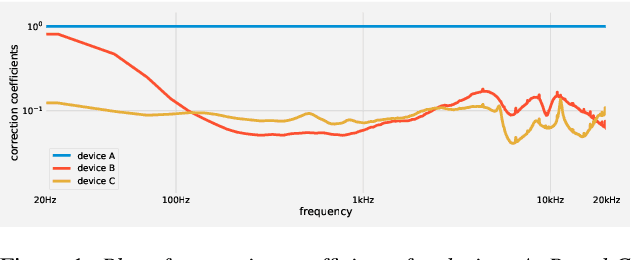
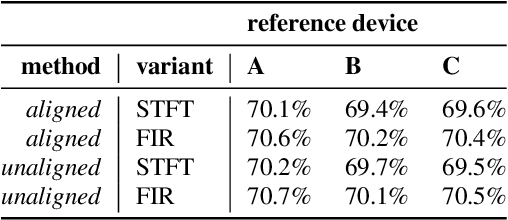
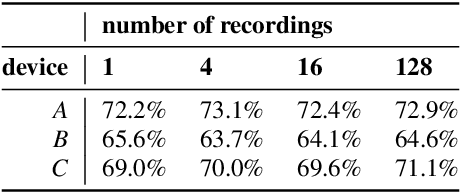
Machine learning algorithms, when trained on audio recordings from a limited set of devices, may not generalize well to samples recorded using other devices with different frequency responses. In this work, a relatively straightforward method is introduced to address this problem. Two variants of the approach are presented. First requires aligned examples from multiple devices, the second approach alleviates this requirement. This method works for both time and frequency domain representations of audio recordings. Further, a relation to standardization and Cepstral Mean Subtraction is analysed. The proposed approach becomes effective even when very few examples are provided. This method was developed during the Detection and Classification of Acoustic Scenes and Events (DCASE) 2019 challenge and won the 1st place in the scenario with mis-matched recording devices with the accuracy of 75%. Source code for the experiments can be found online.
* 5 pages, 1 figure, published at Interspeech 2020, see https://isca-speech.org/archive/Interspeech_2020/abstracts/3088.html
Enhanced Magnetic Resonance Image Synthesis with Contrast-Aware Generative Adversarial Networks
Mar 01, 2021
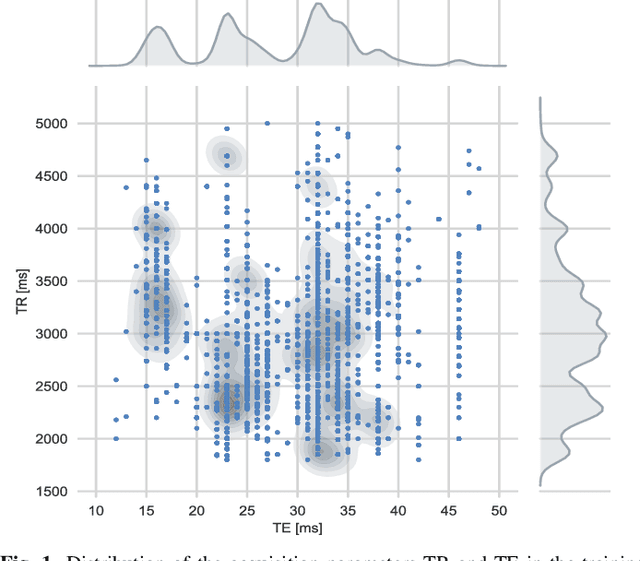
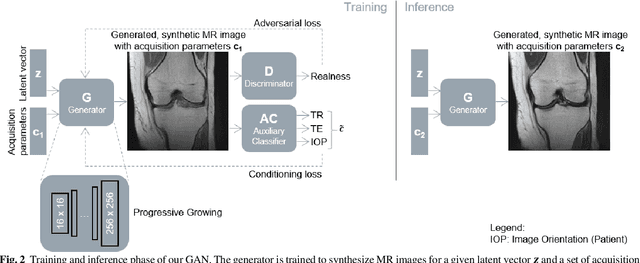
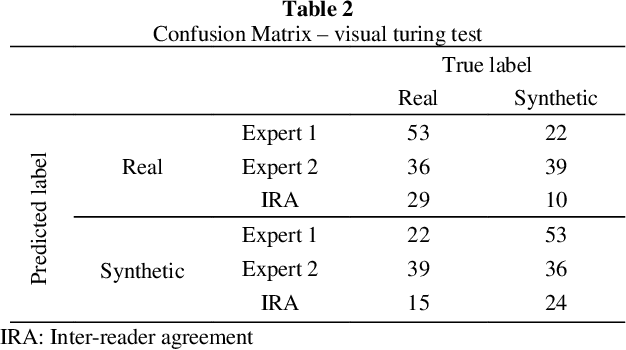
A Magnetic Resonance Imaging (MRI) exam typically consists of the acquisition of multiple MR pulse sequences, which are required for a reliable diagnosis. Each sequence can be parameterized through multiple acquisition parameters affecting MR image contrast, signal-to-noise ratio, resolution, or scan time. With the rise of generative deep learning models, approaches for the synthesis of MR images are developed to either synthesize additional MR contrasts, generate synthetic data, or augment existing data for AI training. However, current generative approaches for the synthesis of MR images are only trained on images with a specific set of acquisition parameter values, limiting the clinical value of these methods as various sets of acquisition parameter settings are used in clinical practice. Therefore, we trained a generative adversarial network (GAN) to generate synthetic MR knee images conditioned on various acquisition parameters (repetition time, echo time, image orientation). This approach enables us to synthesize MR images with adjustable image contrast. In a visual Turing test, two experts mislabeled 40.5% of real and synthetic MR images, demonstrating that the image quality of the generated synthetic and real MR images is comparable. This work can support radiologists and technologists during the parameterization of MR sequences by previewing the yielded MR contrast, can serve as a valuable tool for radiology training, and can be used for customized data generation to support AI training.
A Novel Multi-scale Dilated 3D CNN for Epileptic Seizure Prediction
May 05, 2021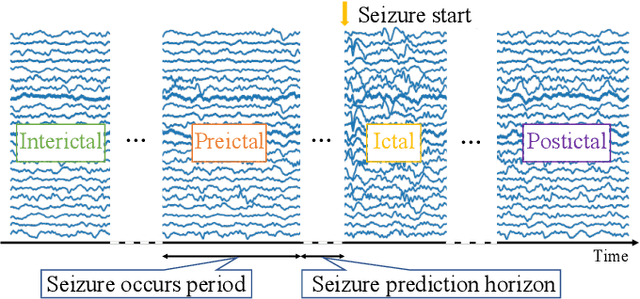

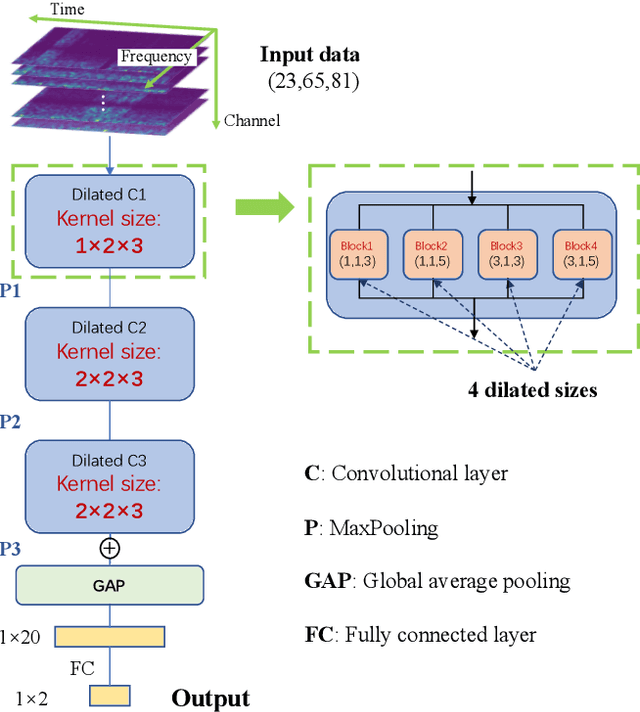
Accurate prediction of epileptic seizures allows patients to take preventive measures in advance to avoid possible injuries. In this work, a novel convolutional neural network (CNN) is proposed to analyze time, frequency, and channel information of electroencephalography (EEG) signals. The model uses three-dimensional (3D) kernels to facilitate the feature extraction over the three dimensions. The application of multiscale dilated convolution enables the 3D kernel to have more flexible receptive fields. The proposed CNN model is evaluated with the CHB-MIT EEG database, the experimental results indicate that our model outperforms the existing state-of-the-art, achieves 80.5% accuracy, 85.8% sensitivity and 75.1% specificity.
MOROCCO: Model Resource Comparison Framework
Apr 29, 2021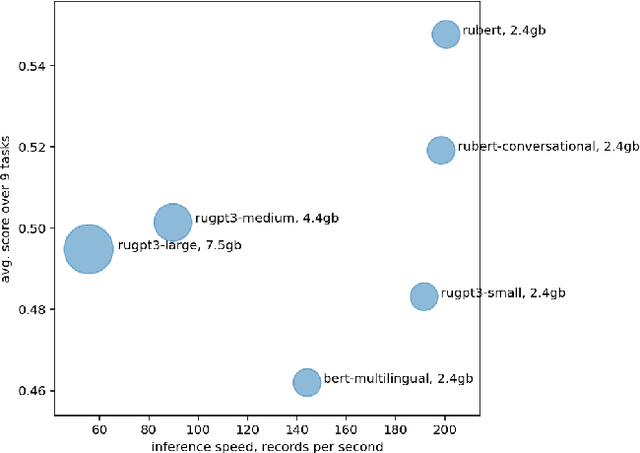
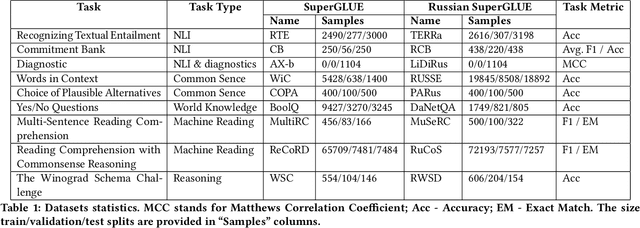
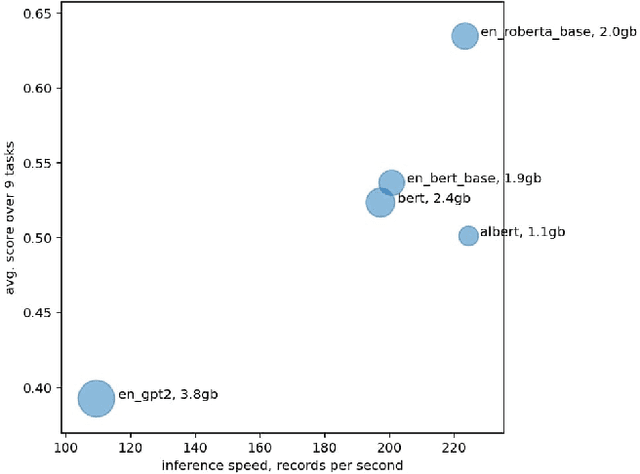
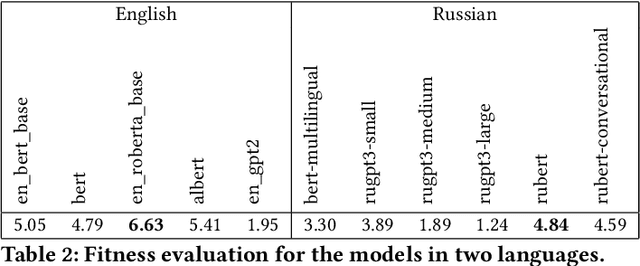
The new generation of pre-trained NLP models push the SOTA to the new limits, but at the cost of computational resources, to the point that their use in real production environments is often prohibitively expensive. We tackle this problem by evaluating not only the standard quality metrics on downstream tasks but also the memory footprint and inference time. We present MOROCCO, a framework to compare language models compatible with \texttt{jiant} environment which supports over 50 NLU tasks, including SuperGLUE benchmark and multiple probing suites. We demonstrate its applicability for two GLUE-like suites in different languages.
Luna: Linear Unified Nested Attention
Jun 03, 2021
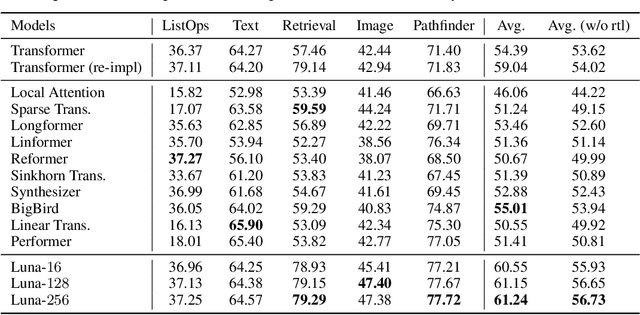
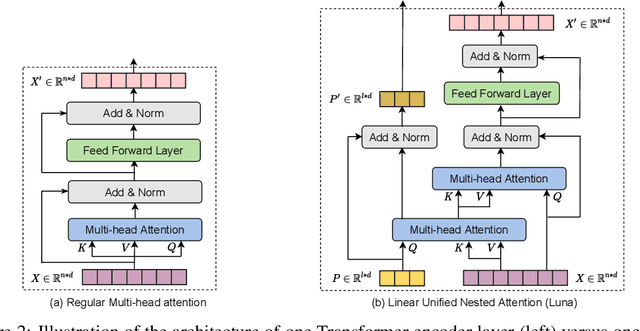
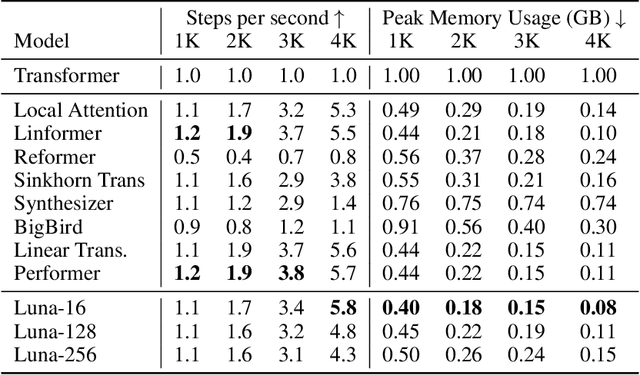
The quadratic computational and memory complexities of the Transformer's attention mechanism have limited its scalability for modeling long sequences. In this paper, we propose Luna, a linear unified nested attention mechanism that approximates softmax attention with two nested linear attention functions, yielding only linear (as opposed to quadratic) time and space complexity. Specifically, with the first attention function, Luna packs the input sequence into a sequence of fixed length. Then, the packed sequence is unpacked using the second attention function. As compared to a more traditional attention mechanism, Luna introduces an additional sequence with a fixed length as input and an additional corresponding output, which allows Luna to perform attention operation linearly, while also storing adequate contextual information. We perform extensive evaluations on three benchmarks of sequence modeling tasks: long-context sequence modeling, neural machine translation and masked language modeling for large-scale pretraining. Competitive or even better experimental results demonstrate both the effectiveness and efficiency of Luna compared to a variety