 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Minimum directed information: A design principle for compliant robots
Mar 27, 2021
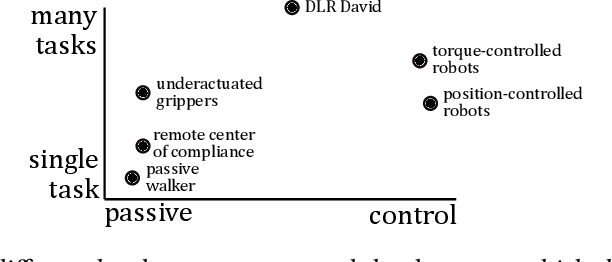
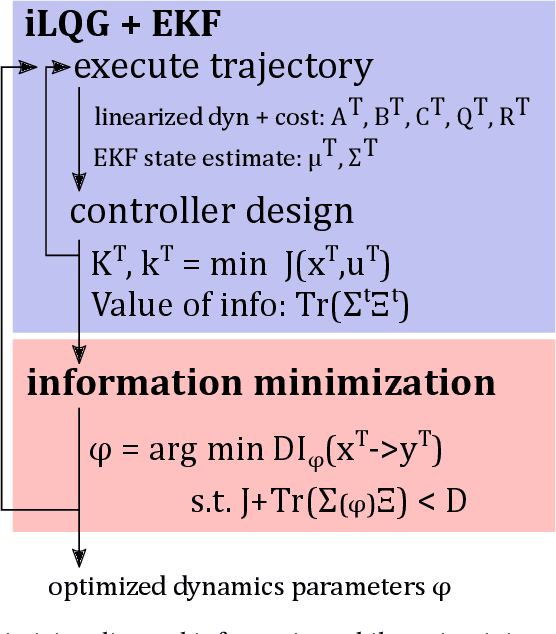
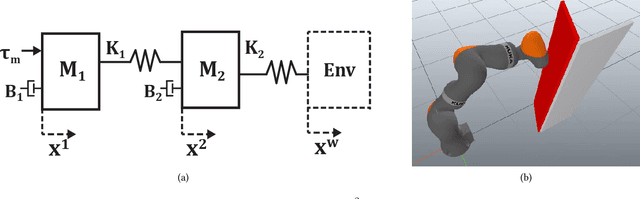
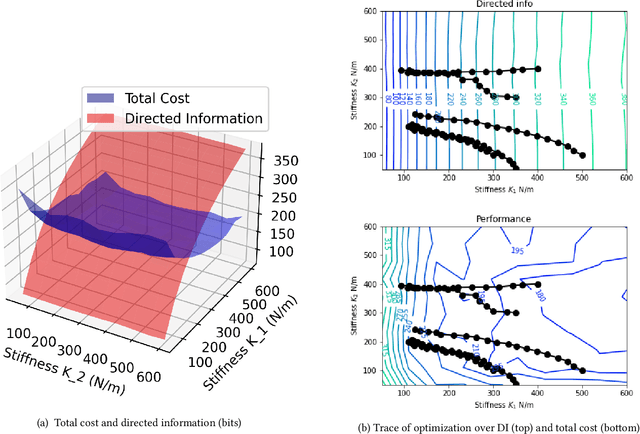
A robot's dynamics -- especially the degree and location of compliance -- can significantly affect performance and control complexity. Passive dynamics can be designed with good regions of attraction or limit cycles for a specific task, but achieving flexibility on a range of tasks requires co-design of control. This paper takes an information perspective: the robot dynamics should reduce the amount of information required for a controller to achieve a threshold of performance in a range of tasks. Towards this goal, an iterative method is proposed to minimize the directed information from state to control on discrete-time nonlinear systems. iLQG is used to find a controller and value of information, then the design parameters of the dynamics (e.g. stiffness of end-effector or joint) are optimized to reduce directed information while maintaining a minimum bound on performance. The approach is validated in simulation, on a two-mass system in contact with an uncertain wall position and a high-DOF door opening task, and shown to improve noise robustness and reduce time variance of control gains.
A Minimalist Approach to Offline Reinforcement Learning
Jun 12, 2021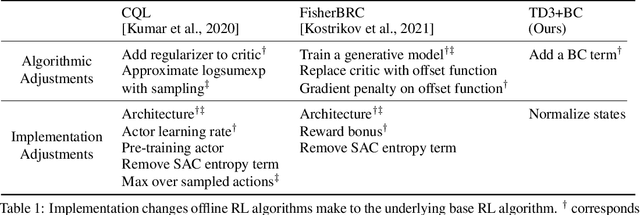
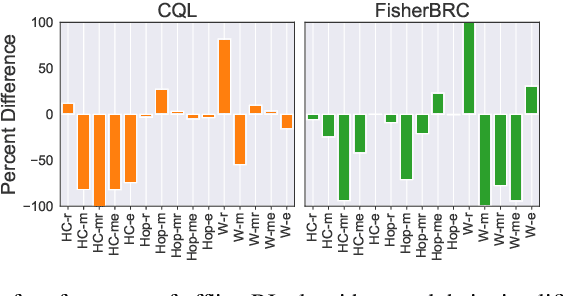
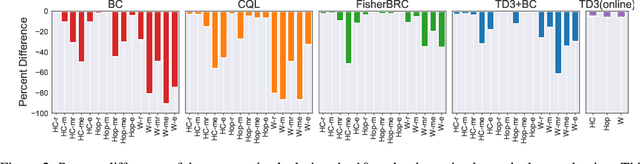
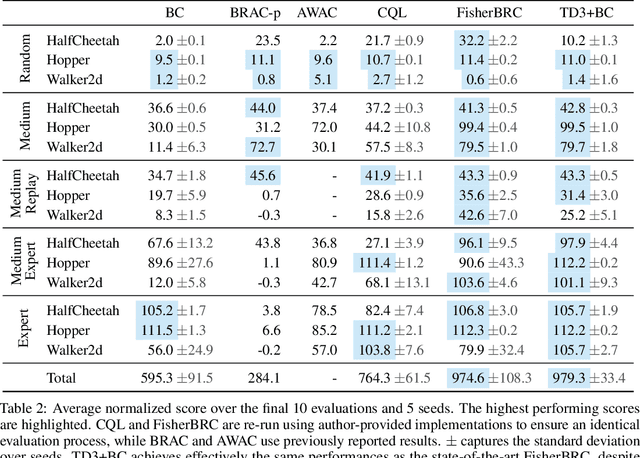
Offline reinforcement learning (RL) defines the task of learning from a fixed batch of data. Due to errors in value estimation from out-of-distribution actions, most offline RL algorithms take the approach of constraining or regularizing the policy with the actions contained in the dataset. Built on pre-existing RL algorithms, modifications to make an RL algorithm work offline comes at the cost of additional complexity. Offline RL algorithms introduce new hyperparameters and often leverage secondary components such as generative models, while adjusting the underlying RL algorithm. In this paper we aim to make a deep RL algorithm work while making minimal changes. We find that we can match the performance of state-of-the-art offline RL algorithms by simply adding a behavior cloning term to the policy update of an online RL algorithm and normalizing the data. The resulting algorithm is a simple to implement and tune baseline, while more than halving the overall run time by removing the additional computational overheads of previous methods.
Data-driven Prediction of General Hamiltonian Dynamics via Learning Exactly-Symplectic Maps
Mar 09, 2021
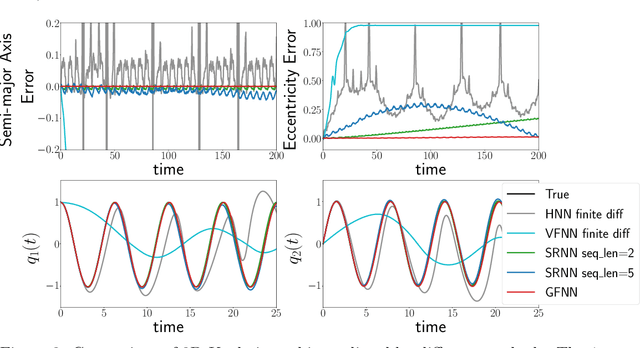
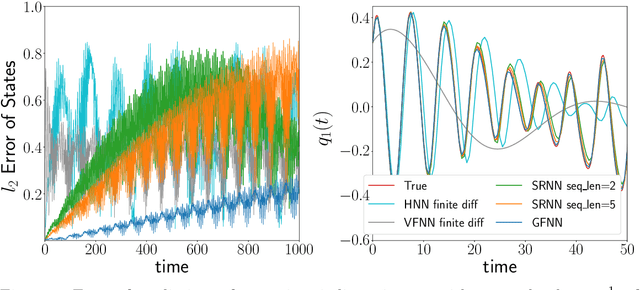
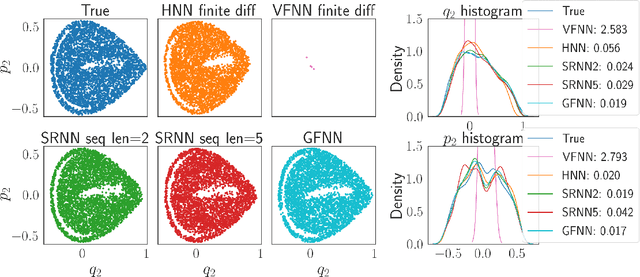
We consider the learning and prediction of nonlinear time series generated by a latent symplectic map. A special case is (not necessarily separable) Hamiltonian systems, whose solution flows give such symplectic maps. For this special case, both generic approaches based on learning the vector field of the latent ODE and specialized approaches based on learning the Hamiltonian that generates the vector field exist. Our method, however, is different as it does not rely on the vector field nor assume its existence; instead, it directly learns the symplectic evolution map in discrete time. Moreover, we do so by representing the symplectic map via a generating function, which we approximate by a neural network (hence the name GFNN). This way, our approximation of the evolution map is always \emph{exactly} symplectic. This additional geometric structure allows the local prediction error at each step to accumulate in a controlled fashion, and we will prove, under reasonable assumptions, that the global prediction error grows at most \emph{linearly} with long prediction time, which significantly improves an otherwise exponential growth. In addition, as a map-based and thus purely data-driven method, GFNN avoids two additional sources of inaccuracies common in vector-field based approaches, namely the error in approximating the vector field by finite difference of the data, and the error in numerical integration of the vector field for making predictions. Numerical experiments further demonstrate our claims.
ACE-NODE: Attentive Co-Evolving Neural Ordinary Differential Equations
May 31, 2021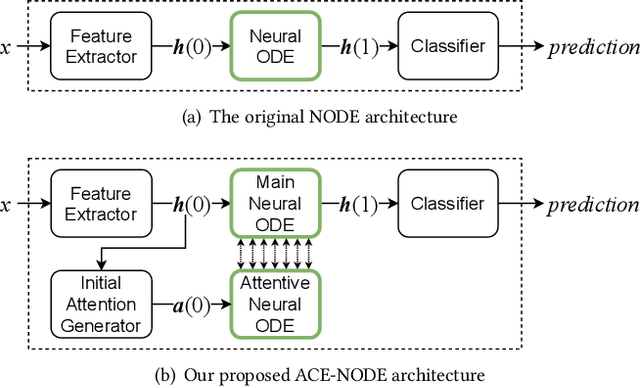


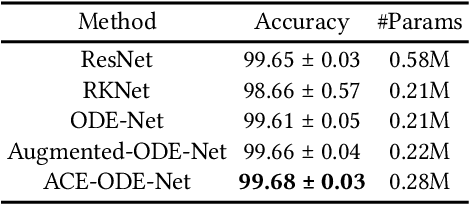
Neural ordinary differential equations (NODEs) presented a new paradigm to construct (continuous-time) neural networks. While showing several good characteristics in terms of the number of parameters and the flexibility in constructing neural networks, they also have a couple of well-known limitations: i) theoretically NODEs learn homeomorphic mapping functions only, and ii) sometimes NODEs show numerical instability in solving integral problems. To handle this, many enhancements have been proposed. To our knowledge, however, integrating attention into NODEs has been overlooked for a while. To this end, we present a novel method of attentive dual co-evolving NODE (ACE-NODE): one main NODE for a downstream machine learning task and the other for providing attention to the main NODE. Our ACE-NODE supports both pairwise and elementwise attention. In our experiments, our method outperforms existing NODE-based and non-NODE-based baselines in almost all cases by non-trivial margins.
Unveiling the structure of wide flat minima in neural networks
Jul 02, 2021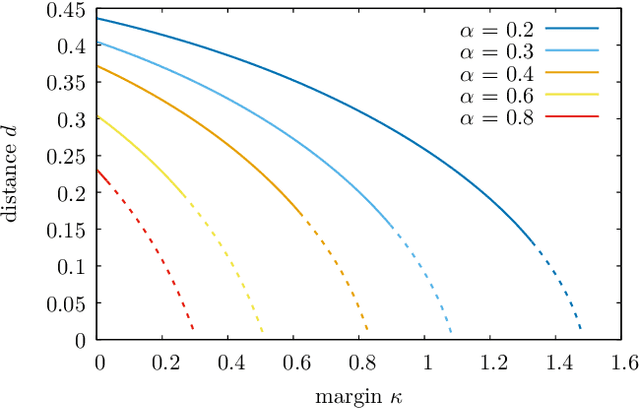
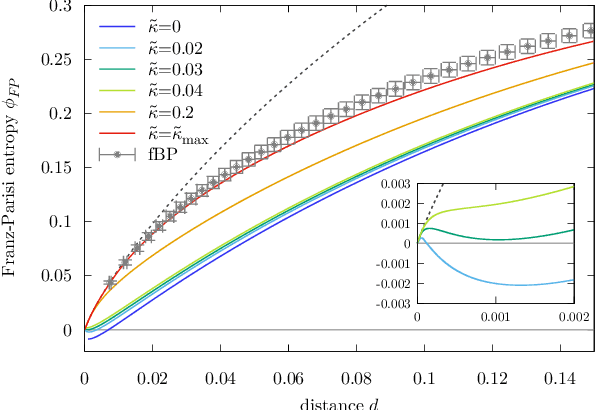
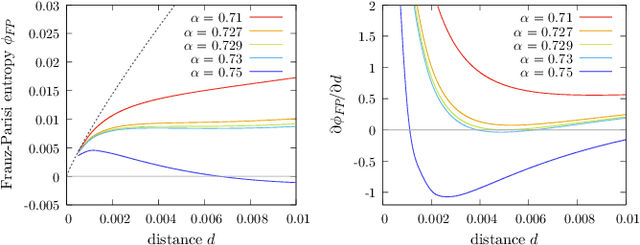
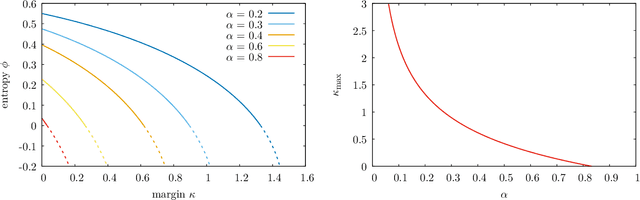
The success of deep learning has revealed the application potential of neural networks across the sciences and opened up fundamental theoretical problems. In particular, the fact that learning algorithms based on simple variants of gradient methods are able to find near-optimal minima of highly nonconvex loss functions is an unexpected feature of neural networks which needs to be understood in depth. Such algorithms are able to fit the data almost perfectly, even in the presence of noise, and yet they have excellent predictive capabilities. Several empirical results have shown a reproducible correlation between the so-called flatness of the minima achieved by the algorithms and the generalization performance. At the same time, statistical physics results have shown that in nonconvex networks a multitude of narrow minima may coexist with a much smaller number of wide flat minima, which generalize well. Here we show that wide flat minima arise from the coalescence of minima that correspond to high-margin classifications. Despite being exponentially rare compared to zero-margin solutions, high-margin minima tend to concentrate in particular regions. These minima are in turn surrounded by other solutions of smaller and smaller margin, leading to dense regions of solutions over long distances. Our analysis also provides an alternative analytical method for estimating when flat minima appear and when algorithms begin to find solutions, as the number of model parameters varies.
Forward Super-Resolution: How Can GANs Learn Hierarchical Generative Models for Real-World Distributions
Jun 04, 2021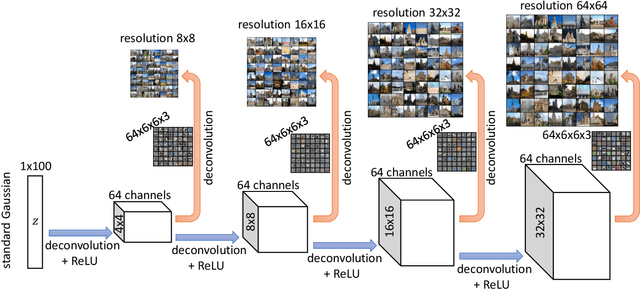

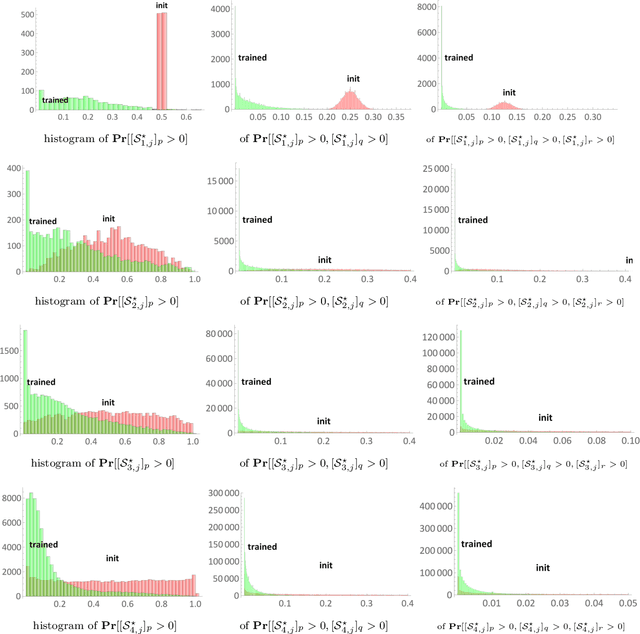
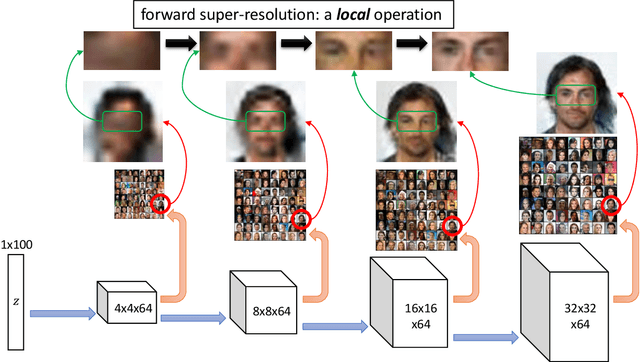
Generative adversarial networks (GANs) are among the most successful models for learning high-complexity, real-world distributions. However, in theory, due to the highly non-convex, non-concave landscape of the minmax training objective, GAN remains one of the least understood deep learning models. In this work, we formally study how GANs can efficiently learn certain hierarchically generated distributions that are close to the distribution of images in practice. We prove that when a distribution has a structure that we refer to as Forward Super-Resolution, then simply training generative adversarial networks using gradient descent ascent (GDA) can indeed learn this distribution efficiently, both in terms of sample and time complexities. We also provide concrete empirical evidence that not only our assumption "forward super-resolution" is very natural in practice, but also the underlying learning mechanisms that we study in this paper (to allow us efficiently train GAN via GDA in theory) simulates the actual learning process of GANs in practice on real-world problems.
Deep Learning Models in Software Requirements Engineering
May 17, 2021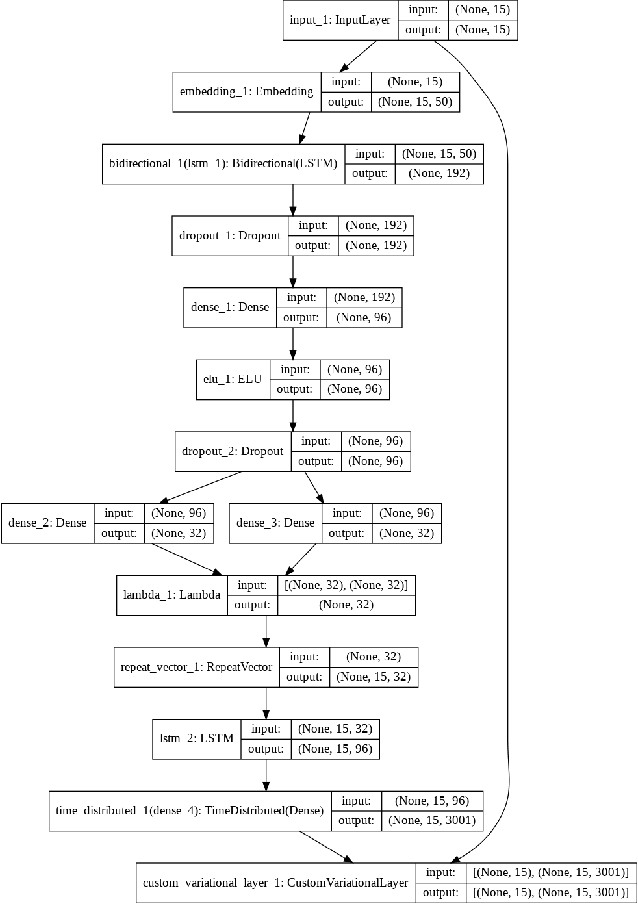
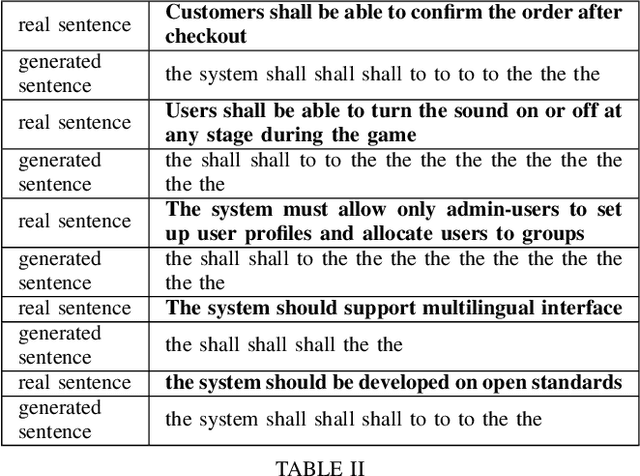
Requirements elicitation is an important phase of any software project: the errors in requirements are more expensive to fix than the errors introduced at later stages of software life cycle. Nevertheless, many projects do not devote sufficient time to requirements. Automated requirements generation can improve the quality of software projects. In this article we have accomplished the first step of the research on this topic: we have applied the vanilla sentence autoencoder to the sentence generation task and evaluated its performance. The generated sentences are not plausible English and contain only a few meaningful words. We believe that applying the model to a larger dataset may produce significantly better results. Further research is needed to improve the quality of generated data.
Vox Populi, Vox DIY: Benchmark Dataset for Crowdsourced Audio Transcription
Jul 02, 2021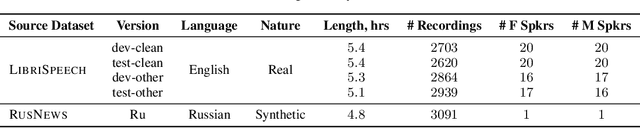
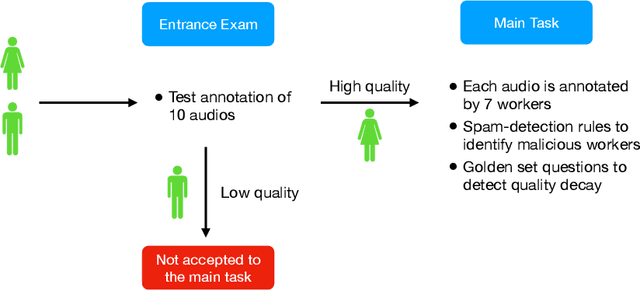
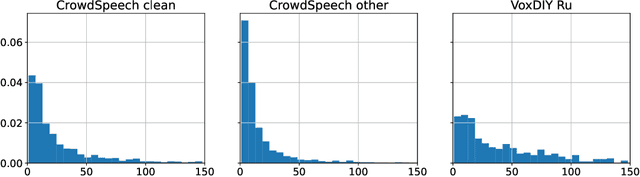
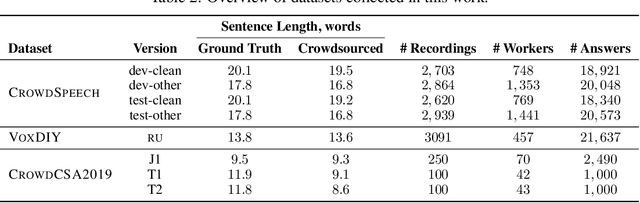
Domain-specific data is the crux of the successful transfer of machine learning systems from benchmarks to real life. Crowdsourcing has become one of the standard tools for cheap and time-efficient data collection for simple problems such as image classification: thanks in large part to advances in research on aggregation methods. However, the applicability of crowdsourcing to more complex tasks (e.g., speech recognition) remains limited due to the lack of principled aggregation methods for these modalities. The main obstacle towards designing advanced aggregation methods is the absence of training data, and in this work, we focus on bridging this gap in speech recognition. For this, we collect and release CrowdSpeech -- the first publicly available large-scale dataset of crowdsourced audio transcriptions. Evaluation of existing aggregation methods on our data shows room for improvement, suggesting that our work may entail the design of better algorithms. At a higher level, we also contribute to the more general challenge of collecting high-quality datasets using crowdsourcing: we develop a principled pipeline for constructing datasets of crowdsourced audio transcriptions in any novel domain. We show its applicability on an under-resourced language by constructing VoxDIY -- a counterpart of CrowdSpeech for the Russian language. We also release the code that allows a full replication of our data collection pipeline and share various insights on best practices of data collection via crowdsourcing.
The Canonical Amoebot Model: Algorithms and Concurrency Control
May 06, 2021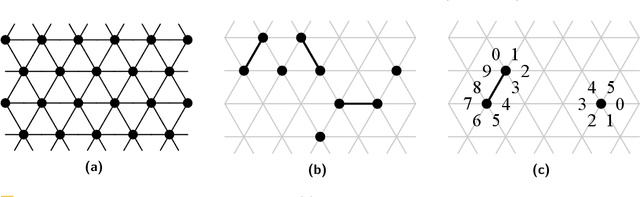
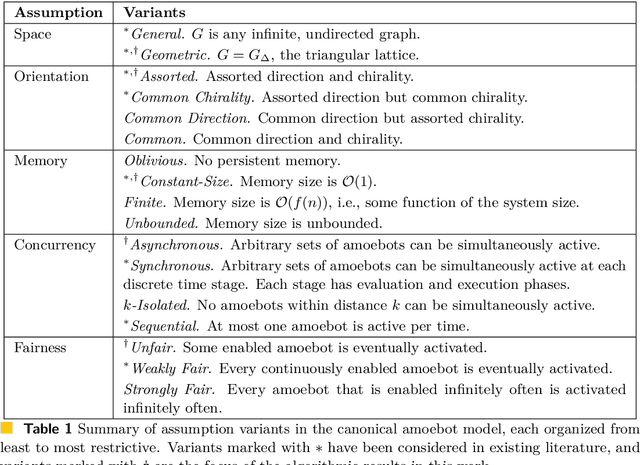

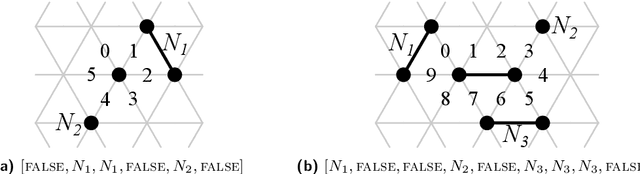
The amoebot model abstracts active programmable matter as a collection of simple computational elements called amoebots that interact locally to collectively achieve tasks of coordination and movement. Since its introduction (SPAA 2014), a growing body of literature has adapted its assumptions for a variety of problems; however, without a standardized hierarchy of assumptions, precise systematic comparison of results under the amoebot model is difficult. We propose the canonical amoebot model, an updated formalization that distinguishes between core model features and families of assumption variants. A key improvement addressed by the canonical amoebot model is concurrency. Much of the existing literature implicitly assumes amoebot actions are isolated and reliable, reducing analysis to the sequential setting where at most one amoebot is active at a time. However, real programmable matter systems are concurrent. The canonical amoebot model formalizes all amoebot communication as message passing, leveraging adversarial activation models of concurrent executions. Under this granular treatment of time, we take two complementary approaches to concurrent algorithm design. In the first, using hexagon formation as a case study, we establish a set of sufficient conditions that guarantee an algorithm's correctness under any concurrent execution, embedding concurrency control directly in algorithm design. In the second, we present a concurrency control protocol that uses locks to convert amoebot algorithms that terminate in the sequential setting and satisfy certain conventions into algorithms that exhibit equivalent behavior in the concurrent setting. These complementary approaches to concurrent algorithm design under the canonical amoebot model open new directions for distributed computing research on programmable matter and form a rigorous foundation for connections to related literature.
Heterogeneous robot teams for modeling and prediction of multiscale environmental processes
Mar 18, 2021
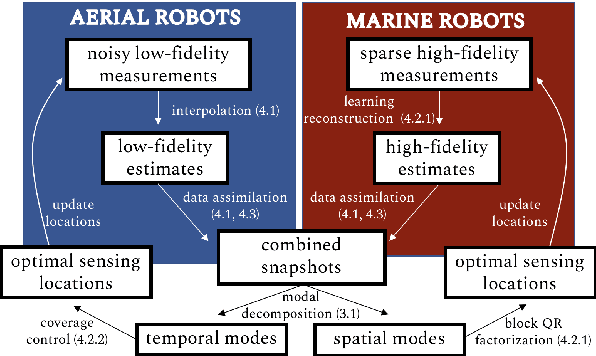
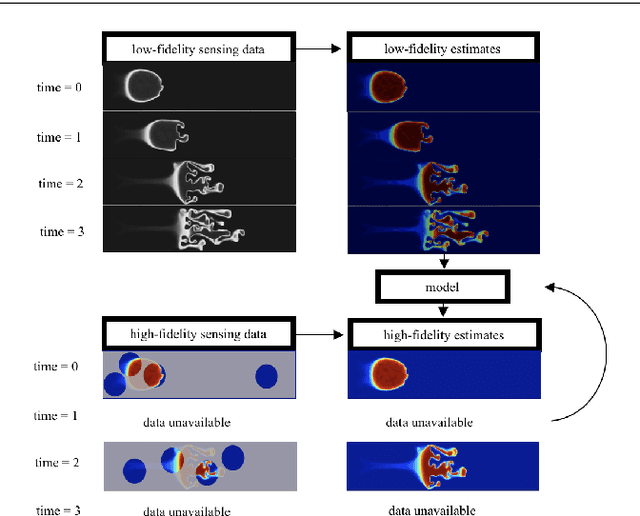
This paper presents a framework to enable a team of heterogeneous mobile robots to model and sense a multiscale system. We propose a coupled strategy, where robots of one type collect high-fidelity measurements at a slow time scale and robots of another type collect low-fidelity measurements at a fast time scale, for the purpose of fusing measurements together. The multiscale measurements are fused to create a model of a complex, nonlinear spatiotemporal process. The model helps determine optimal sensing locations and predict the evolution of the process. Key contributions are: i) consolidation of multiple types of data into one cohesive model, ii) fast determination of optimal sensing locations for mobile robots, and iii) adaptation of models online for various monitoring scenarios. We illustrate the proposed framework by modeling and predicting the evolution of an artificial plasma cloud. We test our approach using physical marine robots adaptively sampling a process in a water tank.