 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Metro Origin-Destination Prediction via Heterogeneous Information Aggregation
Jul 05, 2021
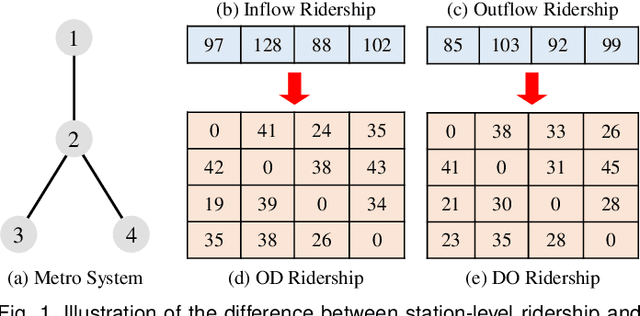
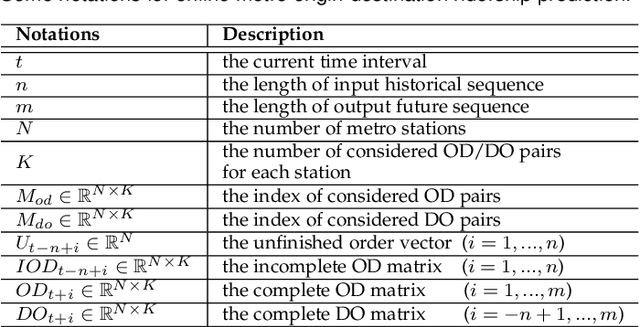
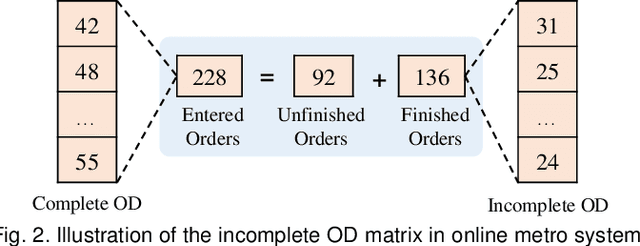
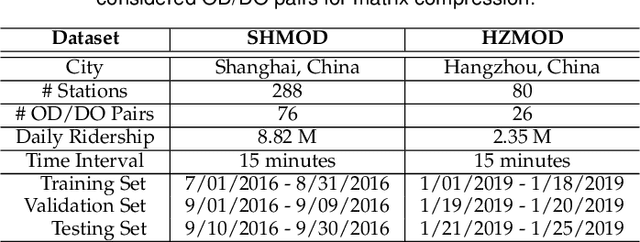
Metro origin-destination prediction is a crucial yet challenging task for intelligent transportation management, which aims to accurately forecast two specific types of cross-station ridership, i.e., Origin-Destination (OD) one and Destination-Origin (DO) one. However, complete OD matrices of previous time intervals can not be obtained immediately in online metro systems, and conventional methods only used limited information to forecast the future OD and DO ridership separately. In this work, we proposed a novel neural network module termed Heterogeneous Information Aggregation Machine (HIAM), which fully exploits heterogeneous information of historical data (e.g., incomplete OD matrices, unfinished order vectors, and DO matrices) to jointly learn the evolutionary patterns of OD and DO ridership. Specifically, an OD modeling branch estimates the potential destinations of unfinished orders explicitly to complement the information of incomplete OD matrices, while a DO modeling branch takes DO matrices as input to capture the spatial-temporal distribution of DO ridership. Moreover, a Dual Information Transformer is introduced to propagate the mutual information among OD features and DO features for modeling the OD-DO causality and correlation. Based on the proposed HIAM, we develop a unified Seq2Seq network to forecast the future OD and DO ridership simultaneously. Extensive experiments conducted on two large-scale benchmarks demonstrate the effectiveness of our method for online metro origin-destination prediction.
PatentMiner: Patent Vacancy Mining via Context-enhanced and Knowledge-guided Graph Attention
Jul 10, 2021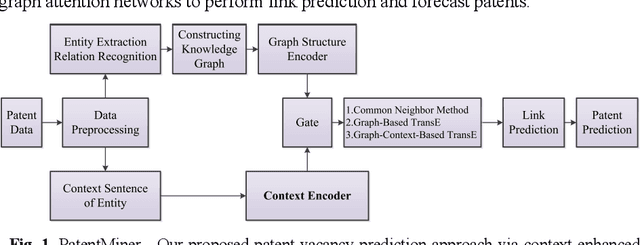
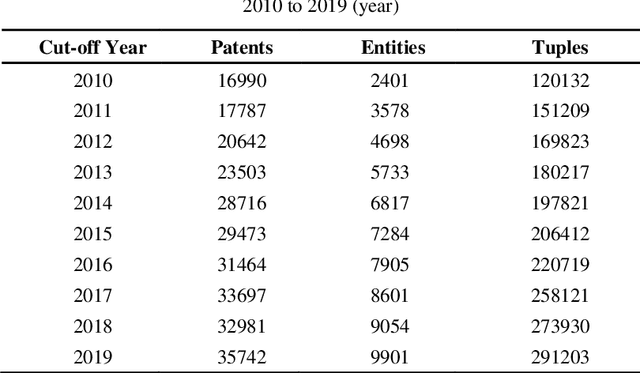
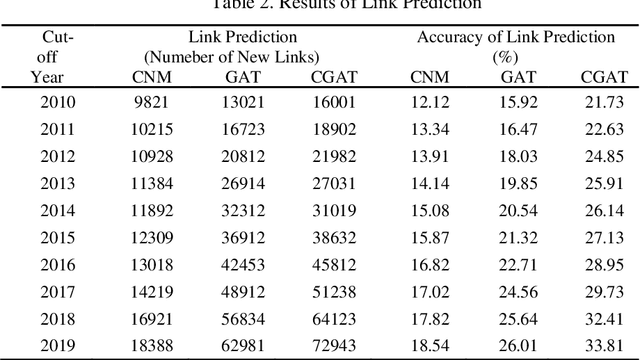
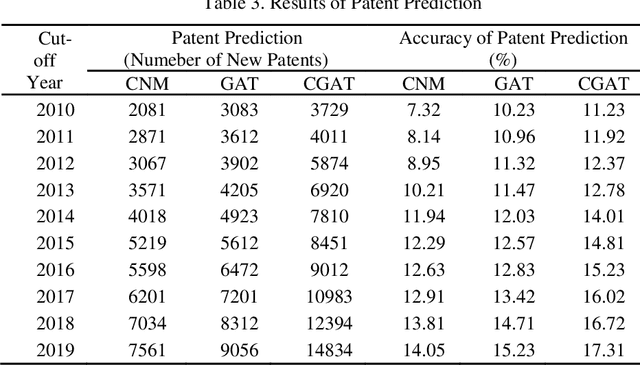
Although there are a small number of work to conduct patent research by building knowledge graph, but without constructing patent knowledge graph using patent documents and combining latest natural language processing methods to mine hidden rich semantic relationships in existing patents and predict new possible patents. In this paper, we propose a new patent vacancy prediction approach named PatentMiner to mine rich semantic knowledge and predict new potential patents based on knowledge graph (KG) and graph attention mechanism. Firstly, patent knowledge graph over time (e.g. year) is constructed by carrying out named entity recognition and relation extrac-tion from patent documents. Secondly, Common Neighbor Method (CNM), Graph Attention Networks (GAT) and Context-enhanced Graph Attention Networks (CGAT) are proposed to perform link prediction in the constructed knowledge graph to dig out the potential triples. Finally, patents are defined on the knowledge graph by means of co-occurrence relationship, that is, each patent is represented as a fully connected subgraph containing all its entities and co-occurrence relationships of the patent in the knowledge graph; Furthermore, we propose a new patent prediction task which predicts a fully connected subgraph with newly added prediction links as a new pa-tent. The experimental results demonstrate that our proposed patent predic-tion approach can correctly predict new patents and Context-enhanced Graph Attention Networks is much better than the baseline. Meanwhile, our proposed patent vacancy prediction task still has significant room to im-prove.
Augmenting Modelers with Semantic Autocompletion of Processes
May 24, 2021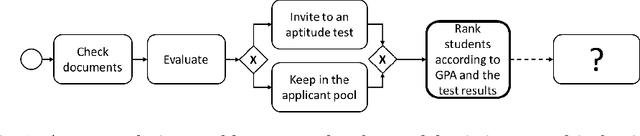

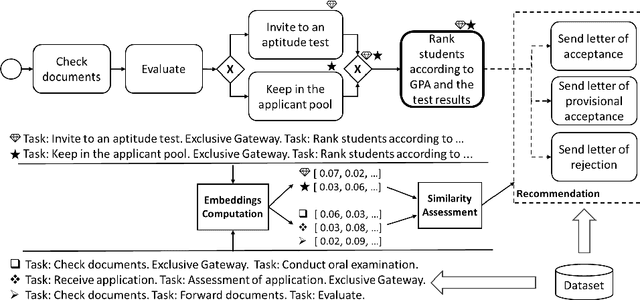

Business process modelers need to have expertise and knowledge of the domain that may not always be available to them. Therefore, they may benefit from tools that mine collections of existing processes and recommend element(s) to be added to a new process that they are constructing. In this paper, we present a method for process autocompletion at design time, that is based on the semantic similarity of sub-processes. By converting sub-processes to textual paragraphs and encoding them as numerical vectors, we can find semantically similar ones, and thereafter recommend the next element. To achieve this, we leverage a state-of-the-art technique for embedding natural language as vectors. We evaluate our approach on open source and proprietary datasets and show that our technique is accurate for processes in various domains.
Long range teleoperation for fine manipulation tasks under time-delay network conditions
Mar 21, 2019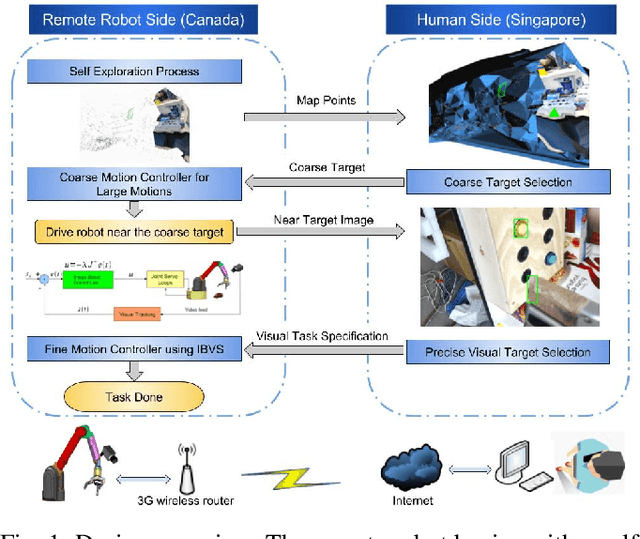
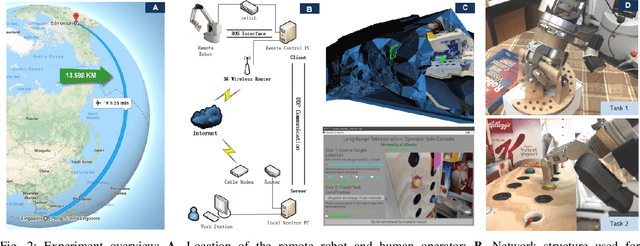
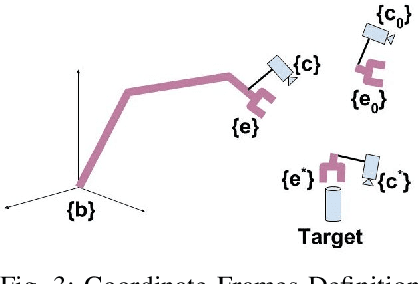
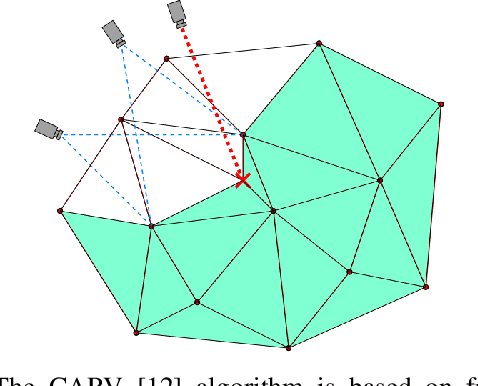
We present a coarse-to-fine approach based semi-autonomous teleoperation system using vision guidance. The system is optimized for long range teleoperation tasks under time-delay network conditions and does not require prior knowledge of the remote scene. Our system initializes with a self exploration behavior that senses the remote surroundings through a freely mounted eye-in-hand web cam. The self exploration stage estimates hand-eye calibration and provides a telepresence interface via real-time 3D geometric reconstruction. The human operator is able to specify a visual task through the interface and a coarse-to-fine controller guides the remote robot enabling our system to work in high latency networks. Large motions are guided by coarse 3D estimation, whereas fine motions use image cues (IBVS). Network data transmission cost is minimized by sending only sparse points and a final image to the human side. Experiments from Singapore to Canada on multiple tasks were conducted to show our system's capability to work in long range teleoperation tasks.
Efficient PAC Reinforcement Learning in Regular Decision Processes
May 14, 2021



Recently regular decision processes have been proposed as a well-behaved form of non-Markov decision process. Regular decision processes are characterised by a transition function and a reward function that depend on the whole history, though regularly (as in regular languages). In practice both the transition and the reward functions can be seen as finite transducers. We study reinforcement learning in regular decision processes. Our main contribution is to show that a near-optimal policy can be PAC-learned in polynomial time in a set of parameters that describe the underlying decision process. We argue that the identified set of parameters is minimal and it reasonably captures the difficulty of a regular decision process.
DeepVideoMVS: Multi-View Stereo on Video with Recurrent Spatio-Temporal Fusion
Dec 03, 2020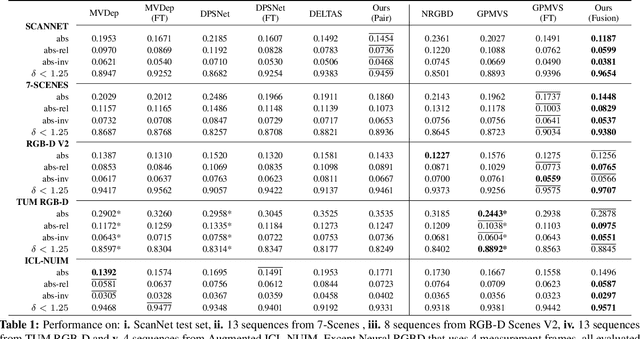
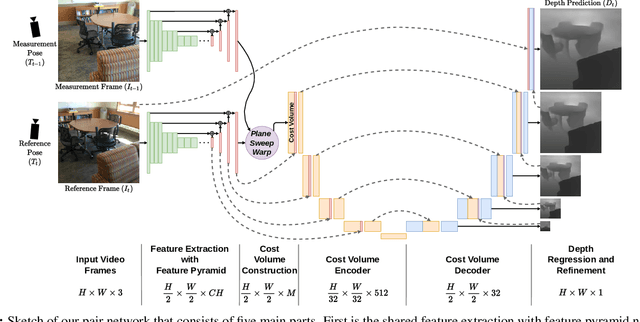
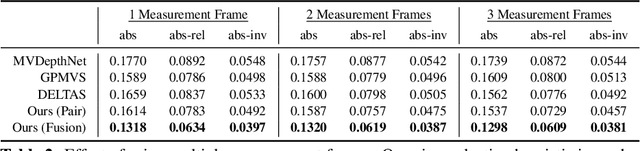
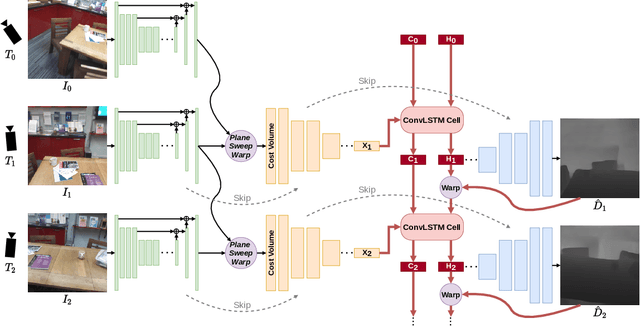
We propose an online multi-view depth prediction approach on posed video streams, where the scene geometry information computed in the previous time steps is propagated to the current time step in an efficient and geometrically plausible way. The backbone of our approach is a real-time capable, lightweight encoder-decoder that relies on cost volumes computed from pairs of images. We extend it by placing a ConvLSTM cell at the bottleneck layer, which compresses an arbitrary amount of past information in its states. The novelty lies in propagating the hidden state of the cell by accounting for the viewpoint changes between time steps. At a given time step, we warp the previous hidden state into the current camera plane using the previous depth prediction. Our extension brings only a small overhead of computation time and memory consumption, while improving the depth predictions significantly. As a result, we outperform the existing state-of-the-art multi-view stereo methods on most of the evaluated metrics in hundreds of indoor scenes while maintaining a real-time performance. Code available: https://github.com/ardaduz/deep-video-mvs
Nonlinear Time Series Modeling: A Unified Perspective, Algorithm, and Application
Dec 24, 2017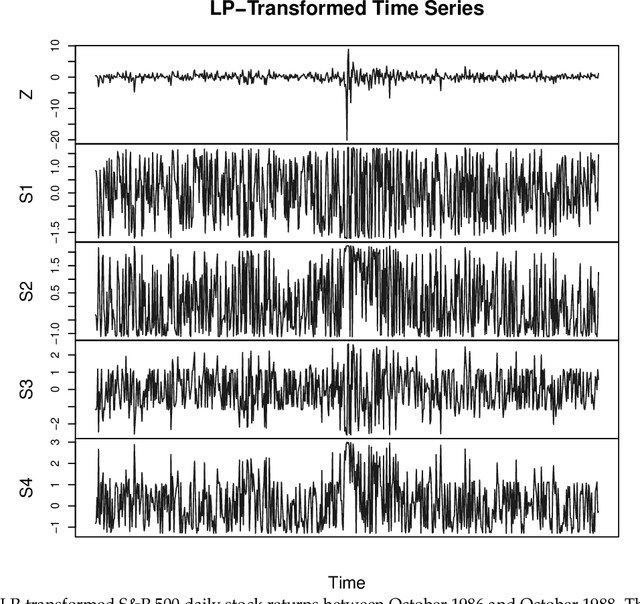
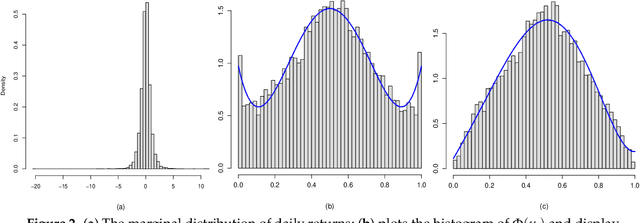
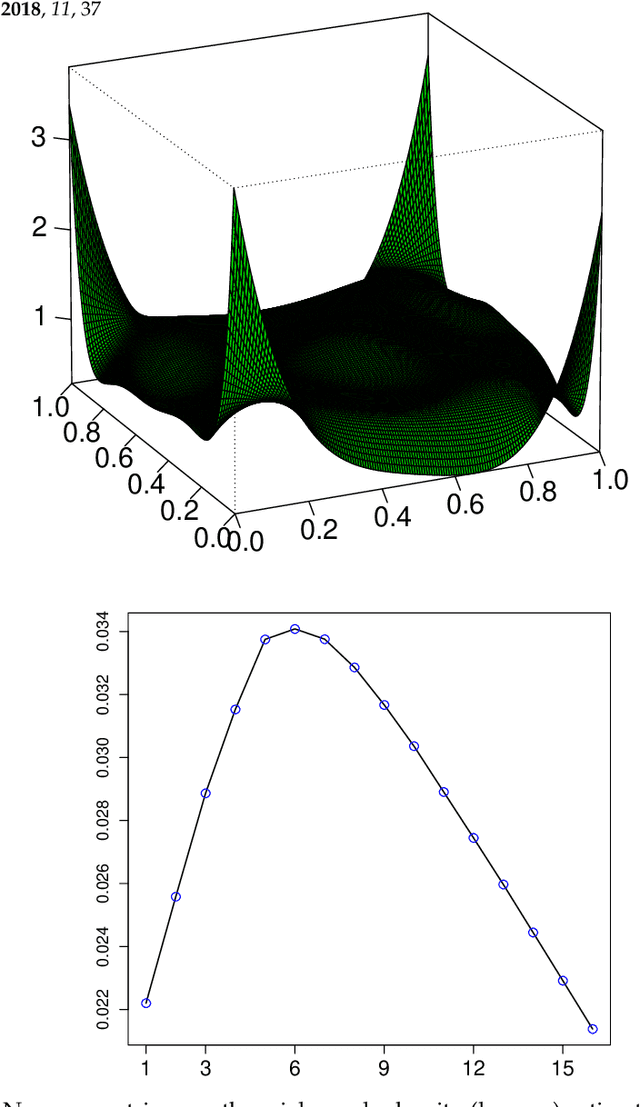
A new comprehensive approach to nonlinear time series analysis and modeling is developed in the present paper. We introduce novel data-specific mid-distribution based Legendre Polynomial (LP) like nonlinear transformations of the original time series Y(t) that enables us to adapt all the existing stationary linear Gaussian time series modeling strategy and made it applicable for non-Gaussian and nonlinear processes in a robust fashion. The emphasis of the present paper is on empirical time series modeling via the algorithm LPTime. We demonstrate the effectiveness of our theoretical framework using daily S&P 500 return data between Jan/2/1963 - Dec/31/2009. Our proposed LPTime algorithm systematically discovers all the `stylized facts' of the financial time series automatically all at once, which were previously noted by many researchers one at a time.
Internet of Things (IoT) Based Video Analytics: a use case of Smart Doorbell
May 13, 2021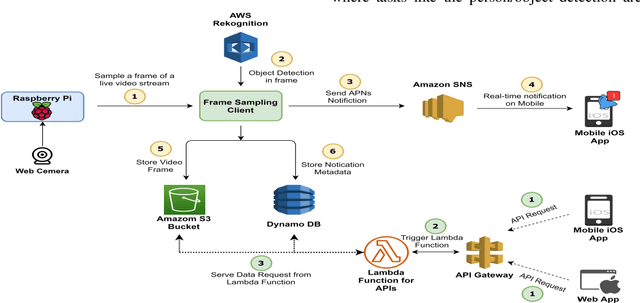

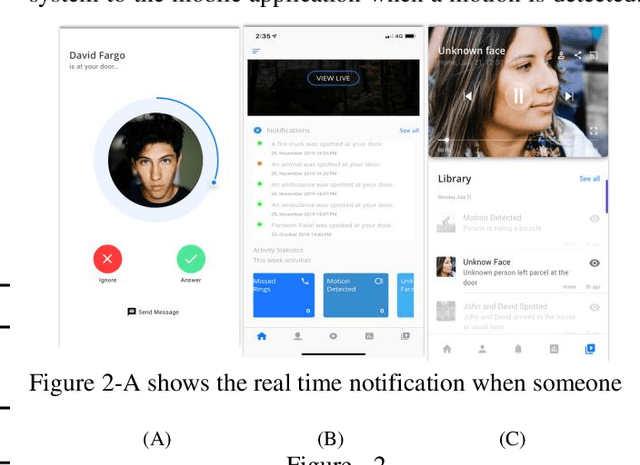
The vision of the internet of things (IoT) is a reality now. IoT devices are getting cheaper, smaller. They are becoming more and more computationally and energy-efficient. The global market of IoT-based video analytics has seen significant growth in recent years and it is expected to be a growing market segment. For any IoT-based video analytics application, few key points required, such as cost-effectiveness, widespread use, flexible design, accurate scene detection, reusability of the framework. Video-based smart doorbell system is one such application domain for video analytics where many commercial offerings are available in the consumer market. However, such existing offerings are costly, monolithic, and proprietary. Also, there will be a trade-off between accuracy and portability. To address the foreseen problems, I'm proposing a distributed framework for video analytics with a use case of a smart doorbell system. The proposed framework uses AWS cloud services as a base platform and to meet the price affordability constraint, the system was implemented on affordable Raspberry Pi. The smart doorbell will be able to recognize the known/unknown person with at most accuracy. The smart doorbell system is also having additional detection functionalities such as harmful weapon detection, noteworthy vehicle detection, animal/pet detection. An iOS application is specifically developed for this implementation which can receive the notification from the smart doorbell in real-time. Finally, the paper also mentions the classical approaches for video analytics, their feasibility in implementing with this use-case, and comparative analysis in terms of accuracy and time required to detect an object in the frame is carried out. Results conclude that AWS cloud-based approach is worthy for this smart doorbell use case.
Automating Speedrun Routing: Overview and Vision
Jun 02, 2021Speedrunning in general means to play a video game fast, i.e. using all means at one's disposal to achieve a given goal in the least amount of time possible. To do so, a speedrun must be planned in advance, or routed, as it is referred to by the community. This paper focuses on discovering challenges and defining models needed when trying to approach the problem of routing algorithmically. It provides an overview of relevant speedrunning literature, extracting vital information and formulating criticism. Important categorizations are pointed out and a nomenclature is build to support professional discussion. Different concepts of graph representations are presented and their potential is discussed with regard to solving the speedrun routing optimization problem. Visions both for problem modeling as well as solving are presented and assessed regarding suitability and expected challenges. This results in a vision of potential solutions and what will be addressed in the future.
Face Age Progression With Attribute Manipulation
Jun 14, 2021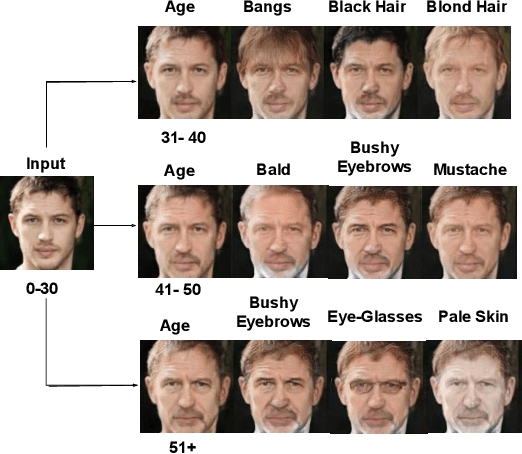
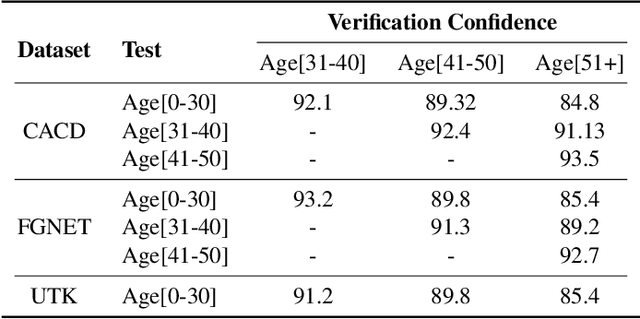
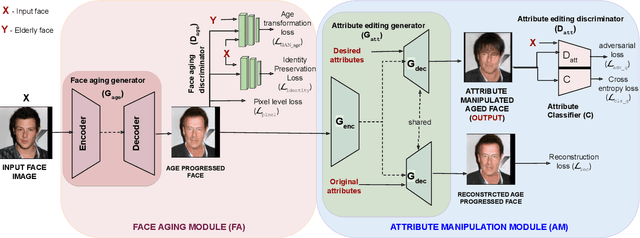
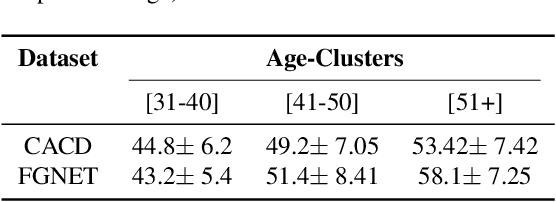
Face is one of the predominant means of person recognition. In the process of ageing, human face is prone to many factors such as time, attributes, weather and other subject specific variations. The impact of these factors were not well studied in the literature of face aging. In this paper, we propose a novel holistic model in this regard viz., ``Face Age progression With Attribute Manipulation (FAWAM)", i.e. generating face images at different ages while simultaneously varying attributes and other subject specific characteristics. We address the task in a bottom-up manner, as two submodules i.e. face age progression and face attribute manipulation. For face aging, we use an attribute-conscious face aging model with a pyramidal generative adversarial network that can model age-specific facial changes while maintaining intrinsic subject specific characteristics. For facial attribute manipulation, the age processed facial image is manipulated with desired attributes while preserving other details unchanged, leveraging an attribute generative adversarial network architecture. We conduct extensive analysis in standard large scale datasets and our model achieves significant performance both quantitatively and qualitatively.