 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Prediction of adverse events in Afghanistan: regression analysis of time series data grouped not by geographic dependencies
Feb 27, 2020
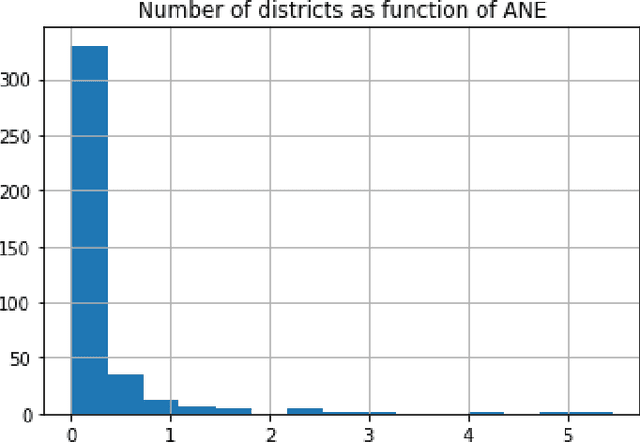

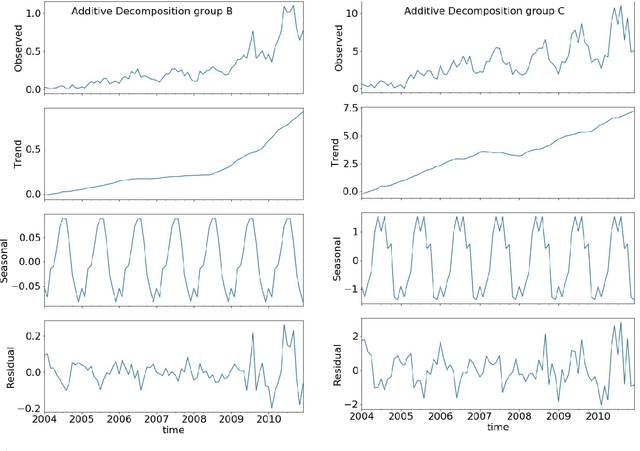
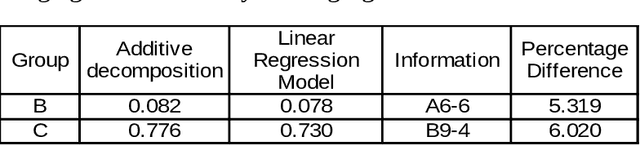
The aim of this study was to approach a difficult regression task on highly unbalanced data regarding active theater of war in Afghanistan. Our focus was set on predicting the negative events number without distinguishing precise nature of the events given historical data on investment and negative events per each of predefined 400 Afghanistan districts. In contrast with previous research on the matter, we propose an approach to analysis of time series data that benefits from non-conventional aggregation of these territorial entities. By carrying out initial exploratory data analysis we demonstrate that dividing data according to our proposal allows to identify strong trend and seasonal components in the selected target variable. Utilizing this approach we also tried to estimate which data regarding investments is most important for prediction performance. Based on our exploratory analysis and previous research we prepared 5 sets of independent variables that were fed to 3 machine learning regression models. The results expressed by mean absolute and mean square errors indicate that leveraging historical data regarding target variable allows for reasonable performance, however unfortunately other proposed independent variables does not seem to improve prediction quality.
SSUL: Semantic Segmentation with Unknown Label for Exemplar-based Class-Incremental Learning
Jun 22, 2021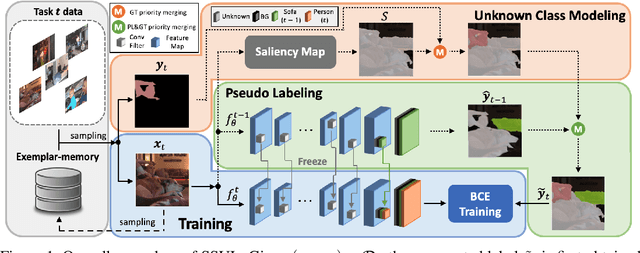


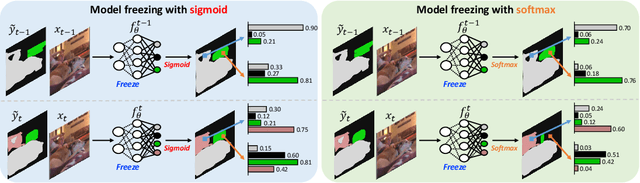
We consider a class-incremental semantic segmentation (CISS) problem. While some recently proposed algorithms utilized variants of knowledge distillation (KD) technique to tackle the problem, they only partially addressed the key additional challenges in CISS that causes the catastrophic forgetting; i.e., the semantic drift of the background class and multi-label prediction issue. To better address these challenges, we propose a new method, dubbed as SSUL-M (Semantic Segmentation with Unknown Label with Memory), by carefully combining several techniques tailored for semantic segmentation. More specifically, we make three main contributions; (1) modeling unknown class within the background class to help learning future classes (help plasticity), (2) freezing backbone network and past classifiers with binary cross-entropy loss and pseudo-labeling to overcome catastrophic forgetting (help stability), and (3) utilizing tiny exemplar memory for the first time in CISS to improve both plasticity and stability. As a result, we show our method achieves significantly better performance than the recent state-of-the-art baselines on the standard benchmark datasets. Furthermore, we justify our contributions with thorough and extensive ablation analyses and discuss different natures of the CISS problem compared to the standard class-incremental learning for classification.
$k$-Neighbor Based Curriculum Sampling for Sequence Prediction
Jan 22, 2021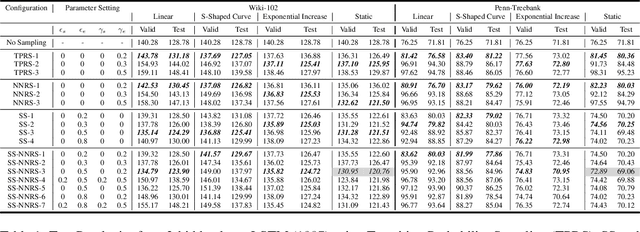
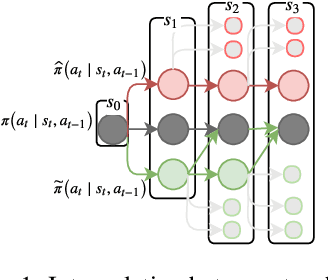
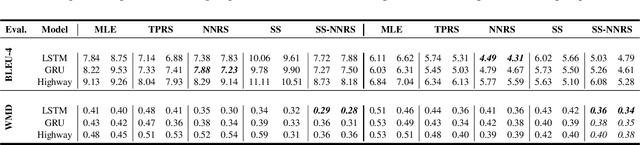
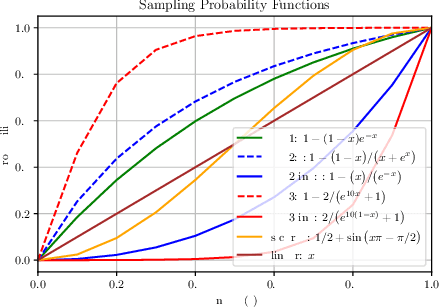
Multi-step ahead prediction in language models is challenging due to the discrepancy between training and test time processes. At test time, a sequence predictor is required to make predictions given past predictions as the input, instead of the past targets that are provided during training. This difference, known as exposure bias, can lead to the compounding of errors along a generated sequence at test time. To improve generalization in neural language models and address compounding errors, we propose \textit{Nearest-Neighbor Replacement Sampling} -- a curriculum learning-based method that gradually changes an initially deterministic teacher policy to a stochastic policy. A token at a given time-step is replaced with a sampled nearest neighbor of the past target with a truncated probability proportional to the cosine similarity between the original word and its top $k$ most similar words. This allows the learner to explore alternatives when the current policy provided by the teacher is sub-optimal or difficult to learn from. The proposed method is straightforward, online and requires little additional memory requirements. We report our findings on two language modelling benchmarks and find that the proposed method further improves performance when used in conjunction with scheduled sampling.
MultiBench: Multiscale Benchmarks for Multimodal Representation Learning
Jul 15, 2021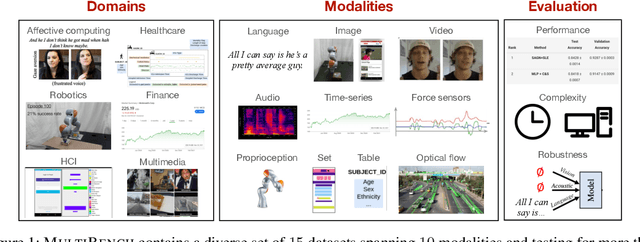
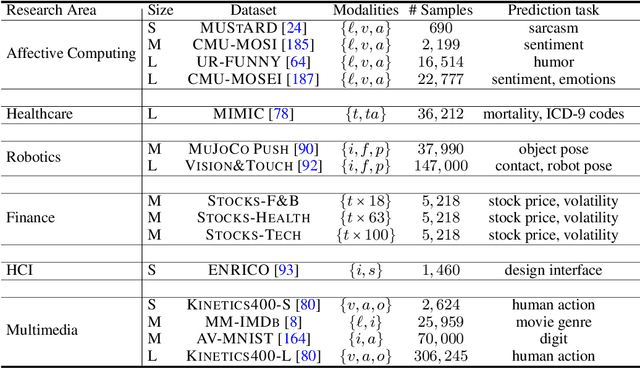
Learning multimodal representations involves integrating information from multiple heterogeneous sources of data. It is a challenging yet crucial area with numerous real-world applications in multimedia, affective computing, robotics, finance, human-computer interaction, and healthcare. Unfortunately, multimodal research has seen limited resources to study (1) generalization across domains and modalities, (2) complexity during training and inference, and (3) robustness to noisy and missing modalities. In order to accelerate progress towards understudied modalities and tasks while ensuring real-world robustness, we release MultiBench, a systematic and unified large-scale benchmark spanning 15 datasets, 10 modalities, 20 prediction tasks, and 6 research areas. MultiBench provides an automated end-to-end machine learning pipeline that simplifies and standardizes data loading, experimental setup, and model evaluation. To enable holistic evaluation, MultiBench offers a comprehensive methodology to assess (1) generalization, (2) time and space complexity, and (3) modality robustness. MultiBench introduces impactful challenges for future research, including scalability to large-scale multimodal datasets and robustness to realistic imperfections. To accompany this benchmark, we also provide a standardized implementation of 20 core approaches in multimodal learning. Simply applying methods proposed in different research areas can improve the state-of-the-art performance on 9/15 datasets. Therefore, MultiBench presents a milestone in unifying disjoint efforts in multimodal research and paves the way towards a better understanding of the capabilities and limitations of multimodal models, all the while ensuring ease of use, accessibility, and reproducibility. MultiBench, our standardized code, and leaderboards are publicly available, will be regularly updated, and welcomes inputs from the community.
Exploring Periodicity and Interactivity in Multi-Interest Framework for Sequential Recommendation
Jun 07, 2021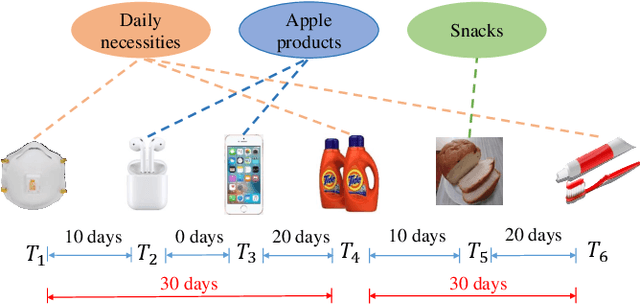

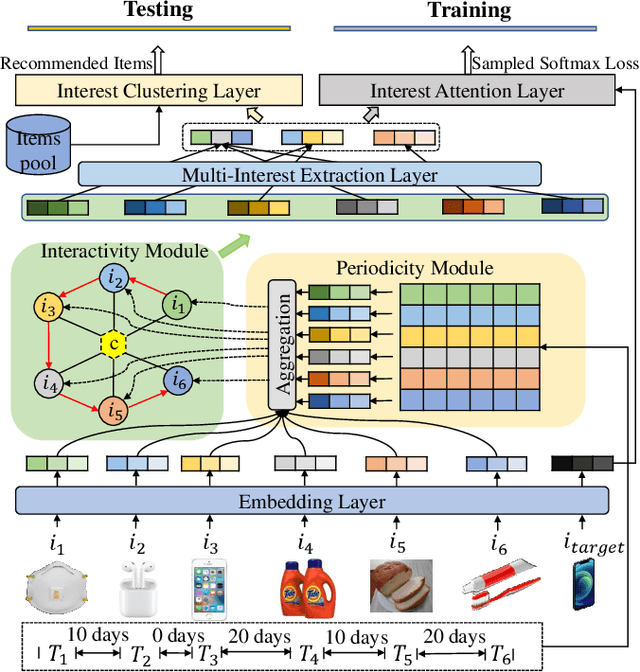

Sequential recommendation systems alleviate the problem of information overload, and have attracted increasing attention in the literature. Most prior works usually obtain an overall representation based on the user's behavior sequence, which can not sufficiently reflect the multiple interests of the user. To this end, we propose a novel method called PIMI to mitigate this issue. PIMI can model the user's multi-interest representation effectively by considering both the periodicity and interactivity in the item sequence. Specifically, we design a periodicity-aware module to utilize the time interval information between user's behaviors. Meanwhile, an ingenious graph is proposed to enhance the interactivity between items in user's behavior sequence, which can capture both global and local item features. Finally, a multi-interest extraction module is applied to describe user's multiple interests based on the obtained item representation. Extensive experiments on two real-world datasets Amazon and Taobao show that PIMI outperforms state-of-the-art methods consistently.
An Artificial Intelligence based approach to estimating time of arrival and bus occupancy for public transport systems in Africa
Jan 19, 2021This document entails a progressive report on the design and implementation of a bus tracking and monitoring system . This report has its contents within the limits of five chapters with each concisely exploring their various objectives. Chapter one is the introductory chapter. It entails a brief description of a bus tracking and monitoring system ,the need and the aims and objectives of this project. Chapter two consists the literature review of this project. This entails the critical analysis of previous related research and projects undertaken by other people. The merits and demerits of the various implementations.Chapter three consists of theory and design considerations of the proposed system for Kwame Nkrumah University campus. Chapter four talks about the methods used to collect data and the approach and technology stack adopted to build the proposed system.Chapter five concludes the thesis and discusses the results of test and deployment of the proposed system on Kwame Nkrumah University of Science and Technology campus
A Microarchitecture Implementation Framework for Online Learning with Temporal Neural Networks
Jun 02, 2021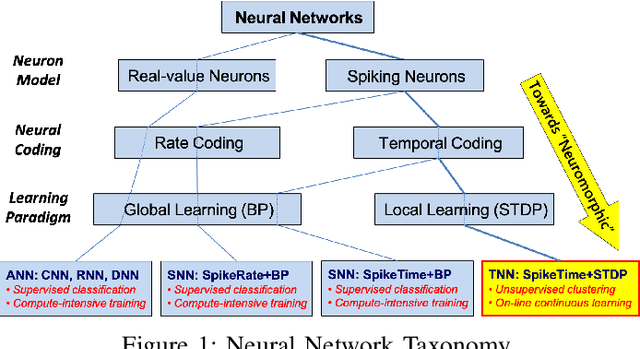

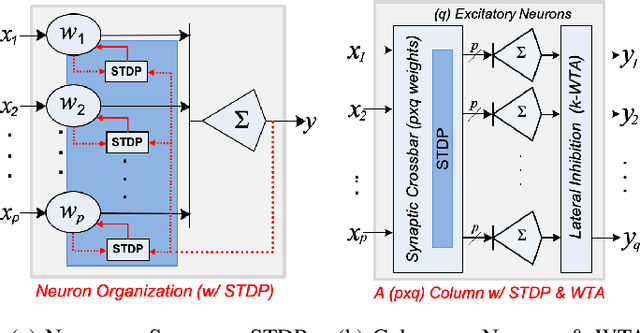
Temporal Neural Networks (TNNs) are spiking neural networks that use time as a resource to represent and process information, similar to the mammalian neocortex. In contrast to compute-intensive deep neural networks that employ separate training and inference phases, TNNs are capable of extremely efficient online incremental/continual learning and are excellent candidates for building edge-native sensory processing units. This work proposes a microarchitecture framework for implementing TNNs using standard CMOS. Gate-level implementations of three key building blocks are presented: 1) multi-synapse neurons, 2) multi-neuron columns, and 3) unsupervised and supervised online learning algorithms based on Spike Timing Dependent Plasticity (STDP). The proposed microarchitecture is embodied in a set of characteristic scaling equations for assessing the gate count, area, delay and power for any TNN design. Post-synthesis results (in 45nm CMOS) for the proposed designs are presented, and their online incremental learning capability is demonstrated.
End-to-End Unsupervised Document Image Blind Denoising
May 19, 2021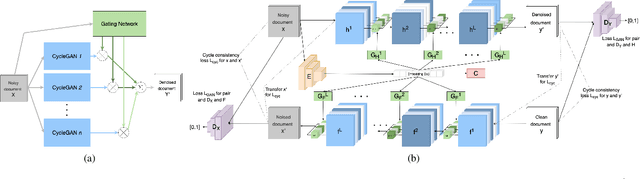
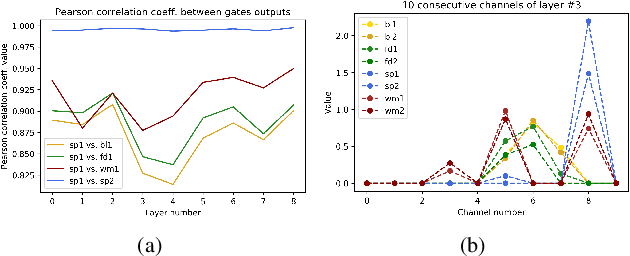
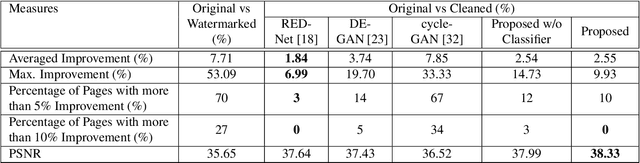
Removing noise from scanned pages is a vital step before their submission to optical character recognition (OCR) system. Most available image denoising methods are supervised where the pairs of noisy/clean pages are required. However, this assumption is rarely met in real settings. Besides, there is no single model that can remove various noise types from documents. Here, we propose a unified end-to-end unsupervised deep learning model, for the first time, that can effectively remove multiple types of noise, including salt \& pepper noise, blurred and/or faded text, as well as watermarks from documents at various levels of intensity. We demonstrate that the proposed model significantly improves the quality of scanned images and the OCR of the pages on several test datasets.
Deep Learning for Vision-Based Fall Detection System: Enhanced Optical Dynamic Flow
Mar 18, 2021Accurate fall detection for the assistance of older people is crucial to reduce incidents of deaths or injuries due to falls. Meanwhile, a vision-based fall detection system has shown some significant results to detect falls. Still, numerous challenges need to be resolved. The impact of deep learning has changed the landscape of the vision-based system, such as action recognition. The deep learning technique has not been successfully implemented in vision-based fall detection systems due to the requirement of a large amount of computation power and the requirement of a large amount of sample training data. This research aims to propose a vision-based fall detection system that improves the accuracy of fall detection in some complex environments such as the change of light condition in the room. Also, this research aims to increase the performance of the pre-processing of video images. The proposed system consists of the Enhanced Dynamic Optical Flow technique that encodes the temporal data of optical flow videos by the method of rank pooling, which thereby improves the processing time of fall detection and improves the classification accuracy in dynamic lighting conditions. The experimental results showed that the classification accuracy of the fall detection improved by around 3% and the processing time by 40 to 50ms. The proposed system concentrates on decreasing the processing time of fall detection and improving classification accuracy. Meanwhile, it provides a mechanism for summarizing a video into a single image by using a dynamic optical flow technique, which helps to increase the performance of image pre-processing steps.
* 16 pages
Causal Reinforcement Learning: An Instrumental Variable Approach
Mar 06, 2021
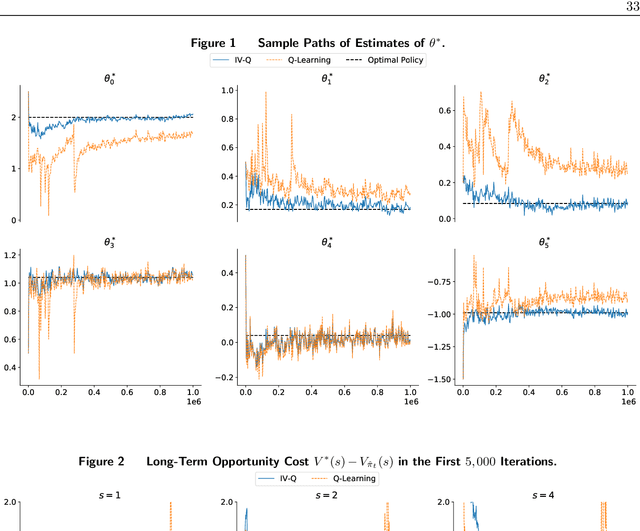
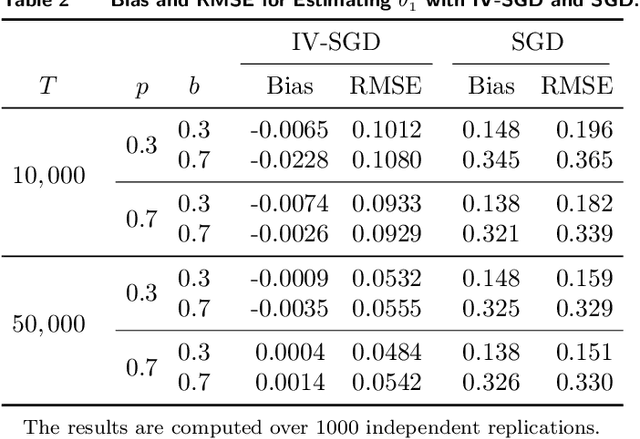
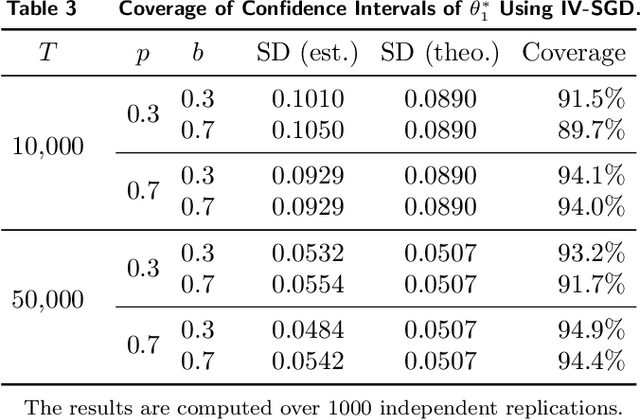
In the standard data analysis framework, data is first collected (once for all), and then data analysis is carried out. With the advancement of digital technology, decisionmakers constantly analyze past data and generate new data through the decisions they make. In this paper, we model this as a Markov decision process and show that the dynamic interaction between data generation and data analysis leads to a new type of bias -- reinforcement bias -- that exacerbates the endogeneity problem in standard data analysis. We propose a class of instrument variable (IV)-based reinforcement learning (RL) algorithms to correct for the bias and establish their asymptotic properties by incorporating them into a two-timescale stochastic approximation framework. A key contribution of the paper is the development of new techniques that allow for the analysis of the algorithms in general settings where noises feature time-dependency. We use the techniques to derive sharper results on finite-time trajectory stability bounds: with a polynomial rate, the entire future trajectory of the iterates from the algorithm fall within a ball that is centered at the true parameter and is shrinking at a (different) polynomial rate. We also use the technique to provide formulas for inferences that are rarely done for RL algorithms. These formulas highlight how the strength of the IV and the degree of the noise's time dependency affect the inference.