 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Interpretable Categorization of Heterogeneous Time Series Data
Jan 26, 2018
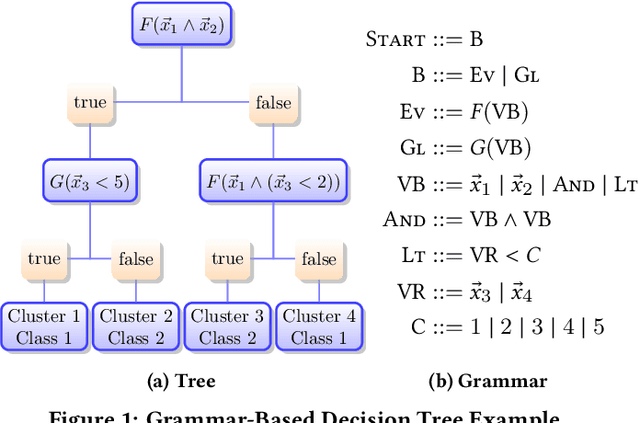
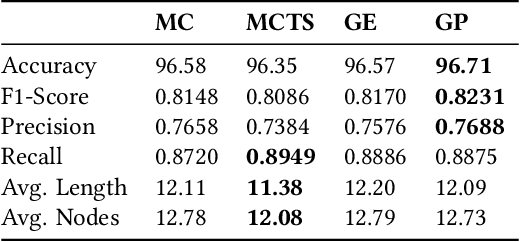
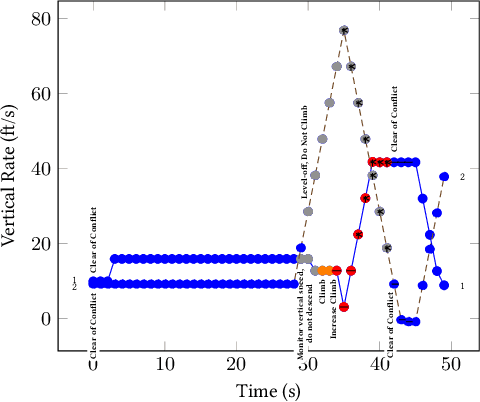
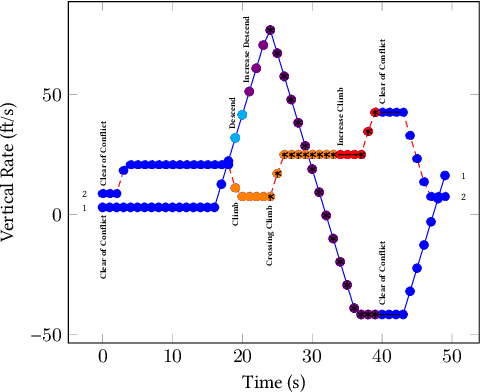
Understanding heterogeneous multivariate time series data is important in many applications ranging from smart homes to aviation. Learning models of heterogeneous multivariate time series that are also human-interpretable is challenging and not adequately addressed by the existing literature. We propose grammar-based decision trees (GBDTs) and an algorithm for learning them. GBDTs extend decision trees with a grammar framework. Logical expressions derived from a context-free grammar are used for branching in place of simple thresholds on attributes. The added expressivity enables support for a wide range of data types while retaining the interpretability of decision trees. In particular, when a grammar based on temporal logic is used, we show that GBDTs can be used for the interpretable classi cation of high-dimensional and heterogeneous time series data. Furthermore, we show how GBDTs can also be used for categorization, which is a combination of clustering and generating interpretable explanations for each cluster. We apply GBDTs to analyze the classic Australian Sign Language dataset as well as data on near mid-air collisions (NMACs). The NMAC data comes from aircraft simulations used in the development of the next-generation Airborne Collision Avoidance System (ACAS X).
Tetrad: Actively Secure 4PC for Secure Training and Inference
Jun 08, 2021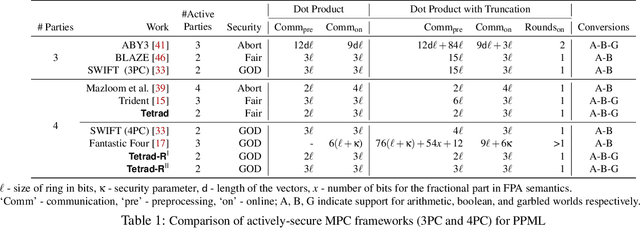



In this work, we design an efficient mixed-protocol framework, Tetrad, with applications to privacy-preserving machine learning. It is designed for the four-party setting with at most one active corruption and supports rings. Our fair multiplication protocol requires communicating only 5 ring elements improving over the state-of-the-art protocol of Trident (Chaudhari et al. NDSS'20). The technical highlights of Tetrad include efficient (a) truncation without any overhead, (b) multi-input multiplication protocols for arithmetic and boolean worlds, (c) garbled-world, tailor-made for the mixed-protocol framework, and (d) conversion mechanisms to switch between the computation styles. The fair framework is also extended to provide robustness without inflating the costs. The competence of Tetrad is tested with benchmarks for deep neural networks such as LeNet and VGG16 and support vector machines. One variant of our framework aims at minimizing the execution time, while the other focuses on the monetary cost. We observe improvements up to 6x over Trident across these parameters.
Diversity-Robust Acoustic Feature Signatures Based on Multiscale Fractal Dimension for Similarity Search of Environmental Sounds
Feb 05, 2021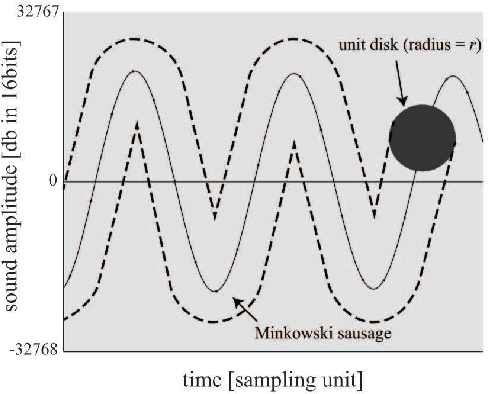
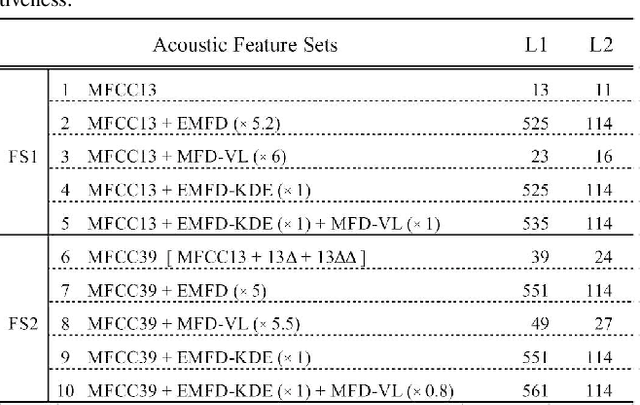
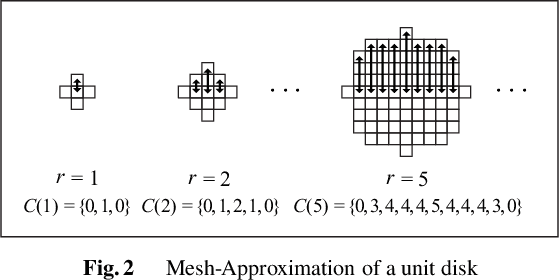
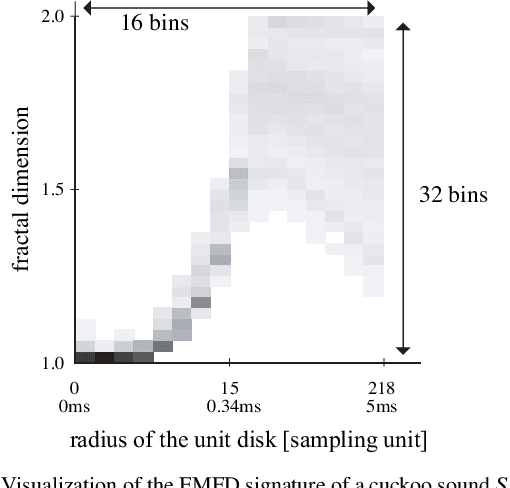
This paper proposes new acoustic feature signatures based on the multiscale fractal dimension (MFD), which are robust against the diversity of environmental sounds, for the content-based similarity search. The diversity of sound sources and acoustic compositions is a typical feature of environmental sounds. Several acoustic features have been proposed for environmental sounds. Among them is the widely-used Mel-Frequency Cepstral Coefficients (MFCCs), which describes frequency-domain features. However, in addition to these features in the frequency domain, environmental sounds have other important features in the time domain with various time scales. In our previous paper, we proposed enhanced multiscale fractal dimension signature (EMFD) for environmental sounds. This paper extends EMFD by using the kernel density estimation method (EMFD-KDE), which results in increased stability and robustness against small fluctuations in the parameters of sound sources. Furthermore, it newly proposes another acoustic feature signature based on MFD, namely very-long-range multiscale fractal dimension signature (MFD-VL). The MFD-VL signature describes several features of the time varying envelope for long periods of time. The descriptiveness of EMFD-KDE and MFD-VL is evaluated through experiments on the similarity search of environmental sounds. We define a similarity index to evaluate the performance of the similarity search. Our evaluation shows that EMFD-KDE and MFD-VL improve the similarity index by 17.2\%.
WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution
Jun 16, 2021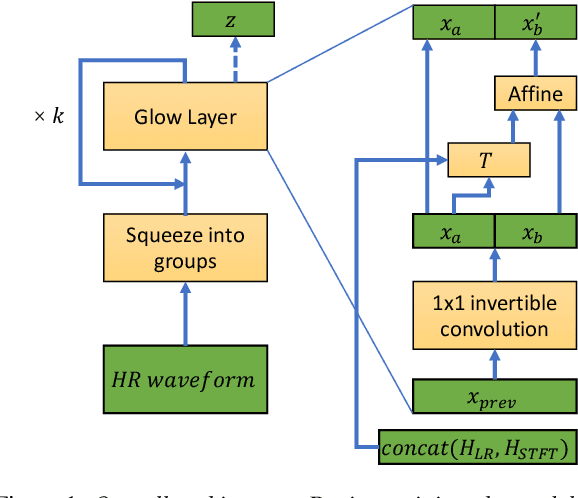

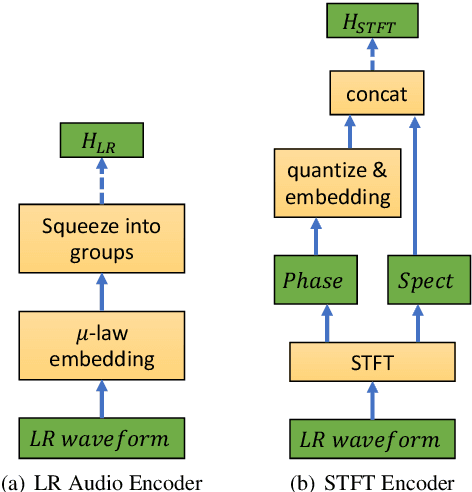
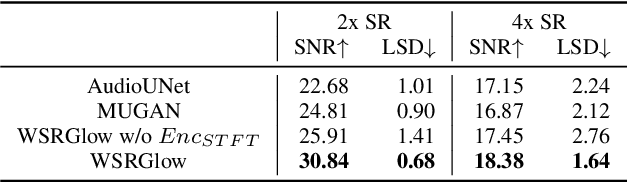
Audio super-resolution is the task of constructing a high-resolution (HR) audio from a low-resolution (LR) audio by adding the missing band. Previous methods based on convolutional neural networks and mean squared error training objective have relatively low performance, while adversarial generative models are difficult to train and tune. Recently, normalizing flow has attracted a lot of attention for its high performance, simple training and fast inference. In this paper, we propose WSRGlow, a Glow-based waveform generative model to perform audio super-resolution. Specifically, 1) we integrate WaveNet and Glow to directly maximize the exact likelihood of the target HR audio conditioned on LR information; and 2) to exploit the audio information from low-resolution audio, we propose an LR audio encoder and an STFT encoder, which encode the LR information from the time domain and frequency domain respectively. The experimental results show that the proposed model is easier to train and outperforms the previous works in terms of both objective and perceptual quality. WSRGlow is also the first model to produce 48kHz waveforms from 12kHz LR audio.
Towards a generalized monaural and binaural auditory model for psychoacoustics and speech intelligibility
Jun 29, 2021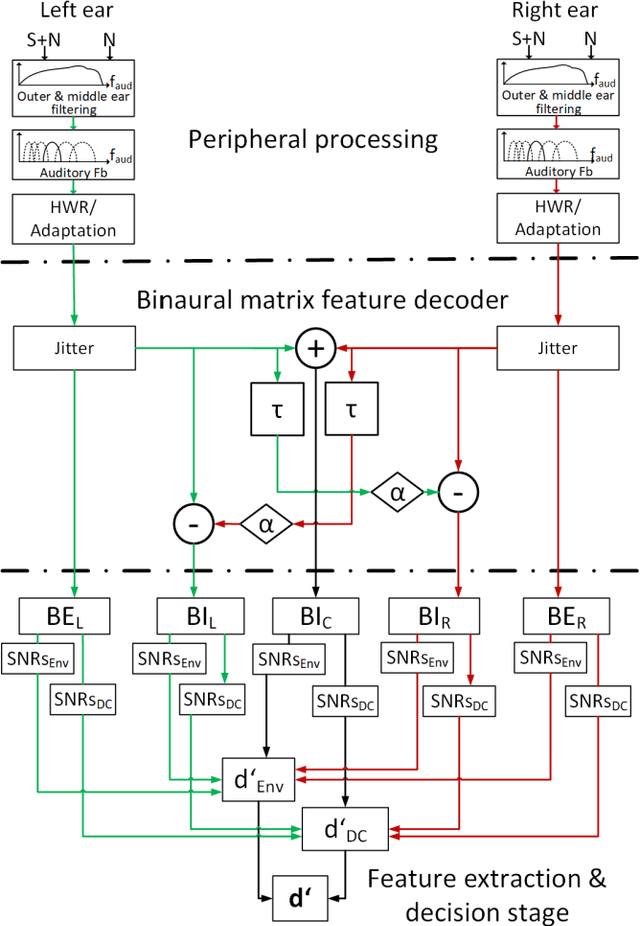

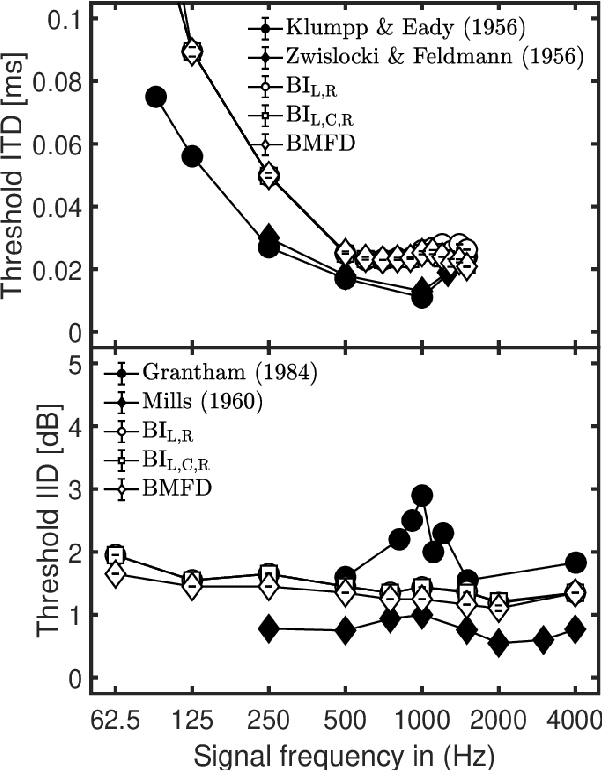
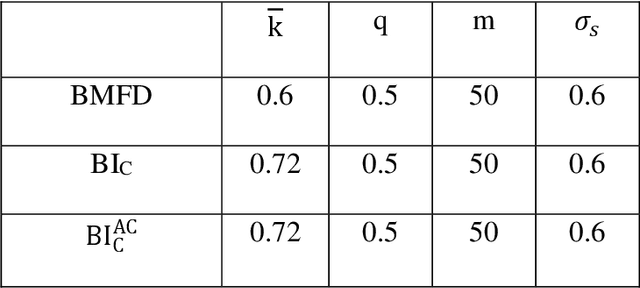
Auditory perception involves cues in the monaural auditory pathways as well as binaural cues based on differences between the ears. So far auditory models have often focused on either monaural or binaural experiments in isolation. Although binaural models typically build upon stages of (existing) monaural models, only a few attempts have been made to extend a monaural model by a binaural stage using a unified decision stage for monaural and binaural cues. In such approaches, a typical prototype of binaural processing has been the classical equalization-cancelation mechanism, which either involves signal-adaptive delays and provides a single channel output or can be implemented with tapped delays providing a high-dimensional multichannel output. This contribution extends the (monaural) generalized envelope power spectrum model by a non-adaptive binaural stage with only a few, fixed output channels. The binaural stage resembles features of physiologically motivated hemispheric binaural processing, as simplified signal processing stages, yielding a 5-channel monaural and binaural matrix feature "decoder" (BMFD). The back end of the existing monaural model is applied to the 5-channel BMFD output and calculates short-time envelope power and power features. The model is evaluated and discussed for a baseline database of monaural and binaural psychoacoustic experiments from the literature.
Interactive Variance Attention based Online Spoiler Detection for Time-Sync Comments
Aug 21, 2019
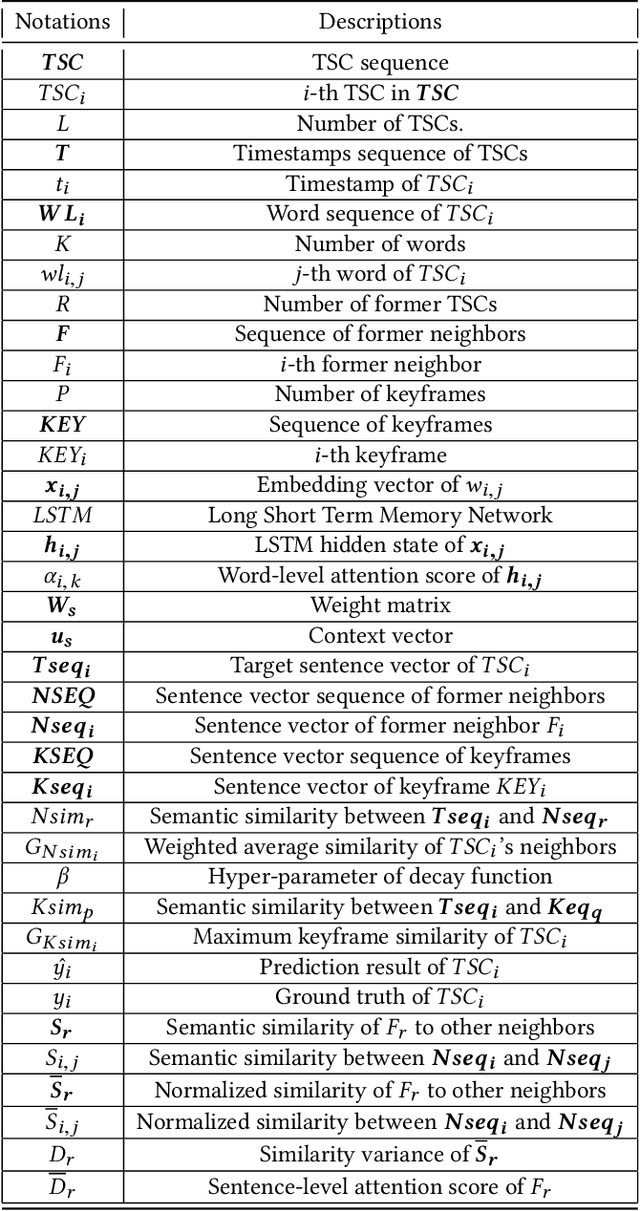
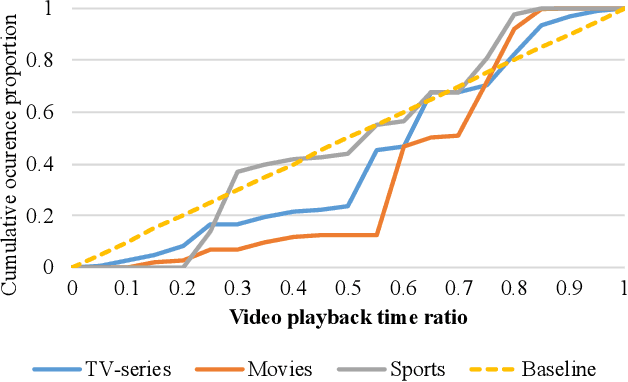
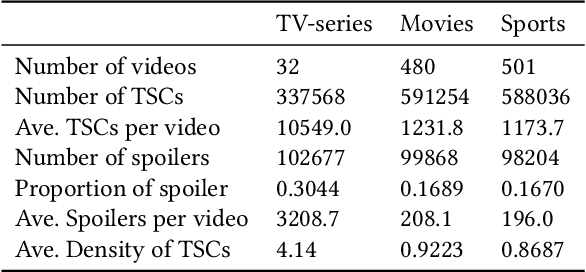
Nowadays, time-sync comment (TSC), a new form of interactive comments, has become increasingly popular in Chinese video websites. By posting TSCs, people can easily express their feelings and exchange their opinions with others when watching online videos. However, some spoilers appear among the TSCs. These spoilers reveal crucial plots in videos that ruin people's surprise when they first watch the video. In this paper, we proposed a novel Similarity-Based Network with Interactive Variance Attention (SBN-IVA) to classify comments as spoilers or not. In this framework, we firstly extract textual features of TSCs through the word-level attentive encoder. We design Similarity-Based Network (SBN) to acquire neighbor and keyframe similarity according to semantic similarity and timestamps of TSCs. Then, we implement Interactive Variance Attention (IVA) to eliminate the impact of noise comments. Finally, we obtain the likelihood of spoiler based on the difference between the neighbor and keyframe similarity. Experiments show SBN-IVA is on average 11.2\% higher than the state-of-the-art method on F1-score in baselines.
Short-term daily precipitation forecasting with seasonally-integrated autoencoder
Jan 23, 2021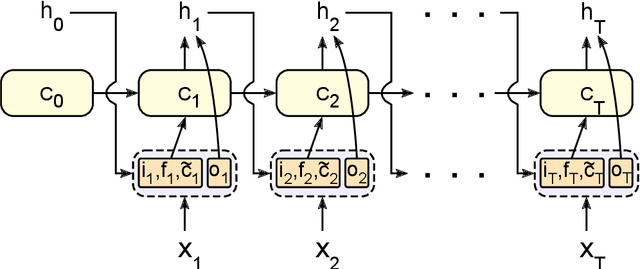
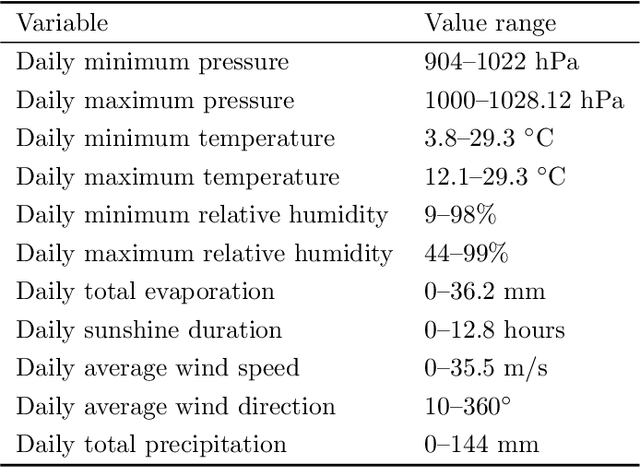
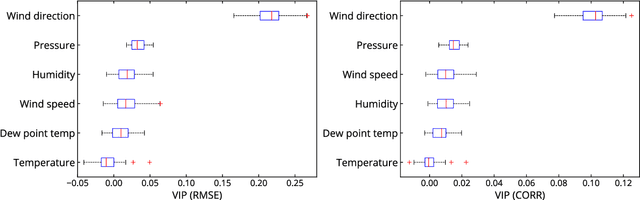
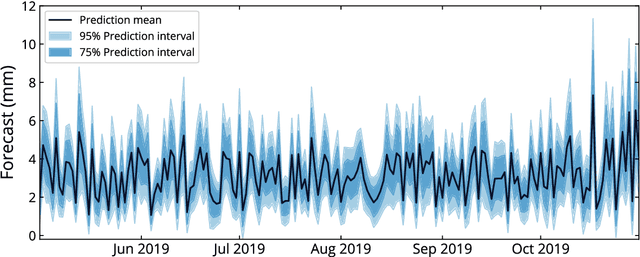
Short-term precipitation forecasting is essential for planning of human activities in multiple scales, ranging from individuals' planning, urban management to flood prevention. Yet the short-term atmospheric dynamics are highly nonlinear that it cannot be easily captured with classical time series models. On the other hand, deep learning models are good at learning nonlinear interactions, but they are not designed to deal with the seasonality in time series. In this study, we aim to develop a forecasting model that can both handle the nonlinearities and detect the seasonality hidden within the daily precipitation data. To this end, we propose a seasonally-integrated autoencoder (SSAE) consisting of two long short-term memory (LSTM) autoencoders: one for learning short-term dynamics, and the other for learning the seasonality in the time series. Our experimental results show that not only does the SSAE outperform various time series models regardless of the climate type, but it also has low output variance compared to other deep learning models. The results also show that the seasonal component of the SSAE helped improve the correlation between the forecast and the actual values from 4% at horizon 1 to 37% at horizon 3.
* 35 pages, 13 figures
Process Outcome Prediction: CNN vs. LSTM (with Attention)
Apr 14, 2021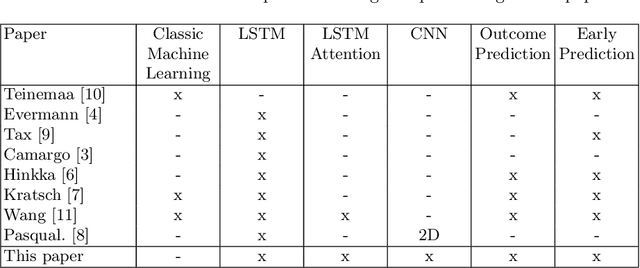
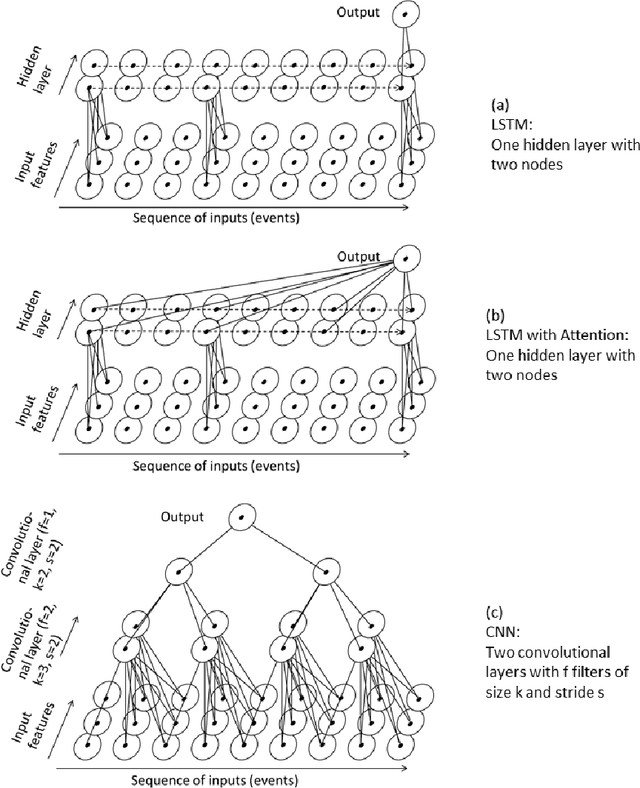

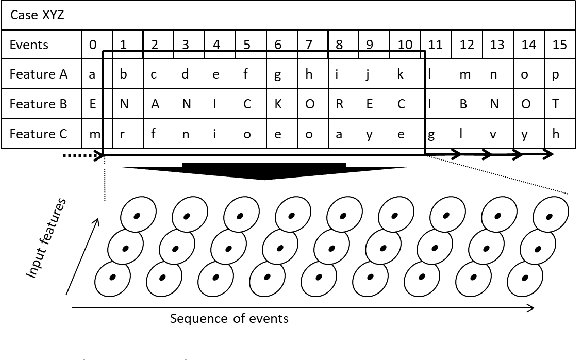
The early outcome prediction of ongoing or completed processes confers competitive advantage to organizations. The performance of classic machine learning and, more recently, deep learning techniques such as Long Short-Term Memory (LSTM) on this type of classification problem has been thorougly investigated. Recently, much research focused on applying Convolutional Neural Networks (CNN) to time series problems including classification, however not yet to outcome prediction. The purpose of this paper is to close this gap and compare CNNs to LSTMs. Attention is another technique that, in combination with LSTMs, has found application in time series classification and was included in our research. Our findings show that all these neural networks achieve satisfactory to high predictive power provided sufficiently large datasets. CNNs perfom on par with LSTMs; the Attention mechanism adds no value to the latter. Since CNNs run one order of magnitude faster than both types of LSTM, their use is preferable. All models are robust with respect to their hyperparameters and achieve their maximal predictive power early on in the cases, usually after only a few events, making them highly suitable for runtime predictions. We argue that CNNs' speed, early predictive power and robustness should pave the way for their application in process outcome prediction.
Automated Estimation of Total Lung Volume using Chest Radiographs and Deep Learning
May 03, 2021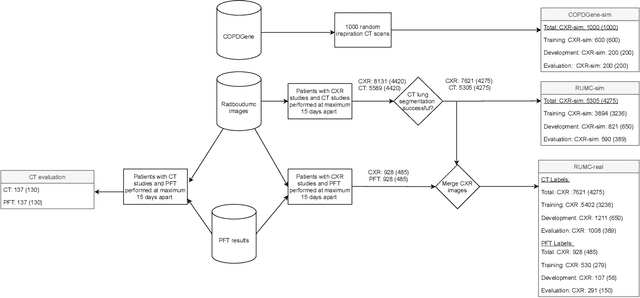
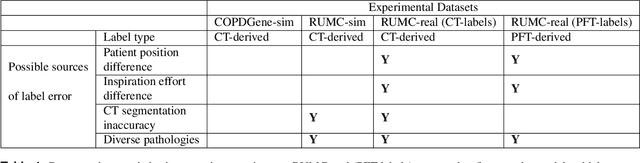
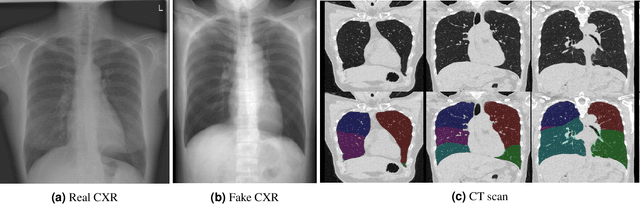
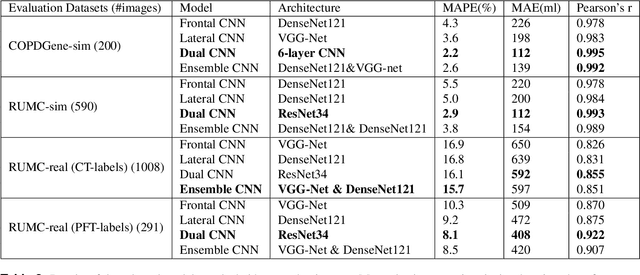
Total lung volume is an important quantitative biomarker and is used for the assessment of restrictive lung diseases. In this study, we investigate the performance of several deep-learning approaches for automated measurement of total lung volume from chest radiographs. 7621 posteroanterior and lateral view chest radiographs (CXR) were collected from patients with chest CT available. Similarly, 928 CXR studies were chosen from patients with pulmonary function test (PFT) results. The reference total lung volume was calculated from lung segmentation on CT or PFT data, respectively. This dataset was used to train deep-learning architectures to predict total lung volume from chest radiographs. The experiments were constructed in a step-wise fashion with increasing complexity to demonstrate the effect of training with CT-derived labels only and the sources of error. The optimal models were tested on 291 CXR studies with reference lung volume obtained from PFT. The optimal deep-learning regression model showed an MAE of 408 ml and a MAPE of 8.1\% and Pearson's r = 0.92 using both frontal and lateral chest radiographs as input. CT-derived labels were useful for pre-training but the optimal performance was obtained by fine-tuning the network with PFT-derived labels. We demonstrate, for the first time, that state-of-the-art deep learning solutions can accurately measure total lung volume from plain chest radiographs. The proposed model can be used to obtain total lung volume from routinely acquired chest radiographs at no additional cost and could be a useful tool to identify trends over time in patients referred regularly for chest x-rays.
Bregman Gradient Policy Optimization
Jun 23, 2021



In this paper, we design a novel Bregman gradient policy optimization framework for reinforcement learning based on Bregman divergences and momentum techniques. Specifically, we propose a Bregman gradient policy optimization (BGPO) algorithm based on the basic momentum technique and mirror descent iteration. At the same time, we present an accelerated Bregman gradient policy optimization (VR-BGPO) algorithm based on a momentum variance-reduced technique. Moreover, we introduce a convergence analysis framework for our Bregman gradient policy optimization under the nonconvex setting. Specifically, we prove that BGPO achieves the sample complexity of $\tilde{O}(\epsilon^{-4})$ for finding $\epsilon$-stationary point only requiring one trajectory at each iteration, and VR-BGPO reaches the best known sample complexity of $\tilde{O}(\epsilon^{-3})$ for finding an $\epsilon$-stationary point, which also only requires one trajectory at each iteration. In particular, by using different Bregman divergences, our methods unify many existing policy optimization algorithms and their new variants such as the existing (variance-reduced) policy gradient algorithms and (variance-reduced) natural policy gradient algorithms. Extensive experimental results on multiple reinforcement learning tasks demonstrate the efficiency of our new algorithms.