 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-armed Bandit Requiring Monotone Arm Sequences
Jun 08, 2021
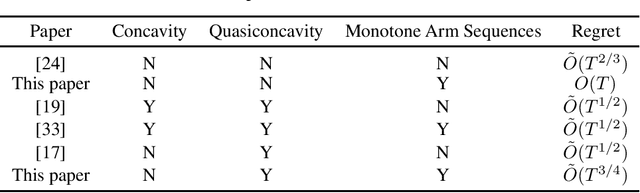
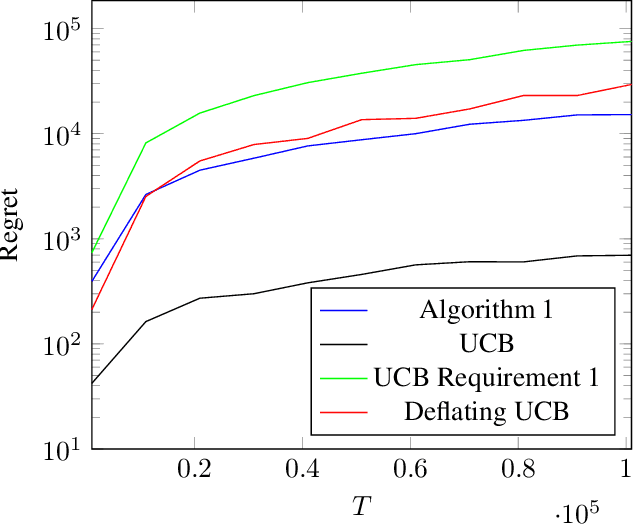
In many online learning or multi-armed bandit problems, the taken actions or pulled arms are ordinal and required to be monotone over time. Examples include dynamic pricing, in which the firms use markup pricing policies to please early adopters and deter strategic waiting, and clinical trials, in which the dose allocation usually follows the dose escalation principle to prevent dose limiting toxicities. We consider the continuum-armed bandit problem when the arm sequence is required to be monotone. We show that when the unknown objective function is Lipschitz continuous, the regret is $O(T)$. When in addition the objective function is unimodal or quasiconcave, the regret is $\tilde O(T^{3/4})$ under the proposed algorithm, which is also shown to be the optimal rate. This deviates from the optimal rate $\tilde O(T^{2/3})$ in the continuous-armed bandit literature and demonstrates the cost to the learning efficiency brought by the monotonicity requirement.
Sleeper Agent: Scalable Hidden Trigger Backdoors for Neural Networks Trained from Scratch
Jun 16, 2021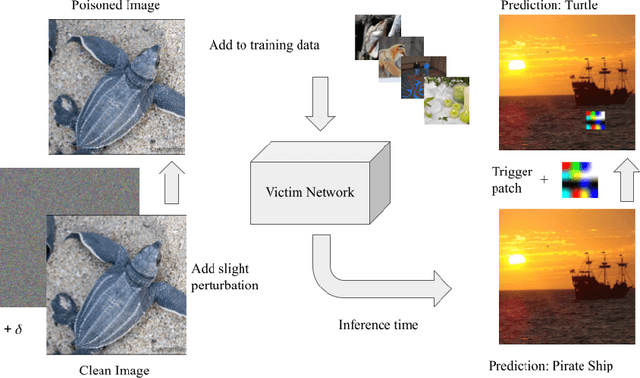
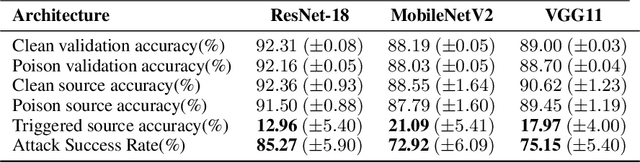


As the curation of data for machine learning becomes increasingly automated, dataset tampering is a mounting threat. Backdoor attackers tamper with training data to embed a vulnerability in models that are trained on that data. This vulnerability is then activated at inference time by placing a "trigger" into the model's input. Typical backdoor attacks insert the trigger directly into the training data, although the presence of such an attack may be visible upon inspection. In contrast, the Hidden Trigger Backdoor Attack achieves poisoning without placing a trigger into the training data at all. However, this hidden trigger attack is ineffective at poisoning neural networks trained from scratch. We develop a new hidden trigger attack, Sleeper Agent, which employs gradient matching, data selection, and target model re-training during the crafting process. Sleeper Agent is the first hidden trigger backdoor attack to be effective against neural networks trained from scratch. We demonstrate its effectiveness on ImageNet and in black-box settings. Our implementation code can be found at https://github.com/hsouri/Sleeper-Agent.
Intelligent Zero Trust Architecture for 5G/6G Tactical Networks: Principles, Challenges, and the Role of Machine Learning
May 04, 2021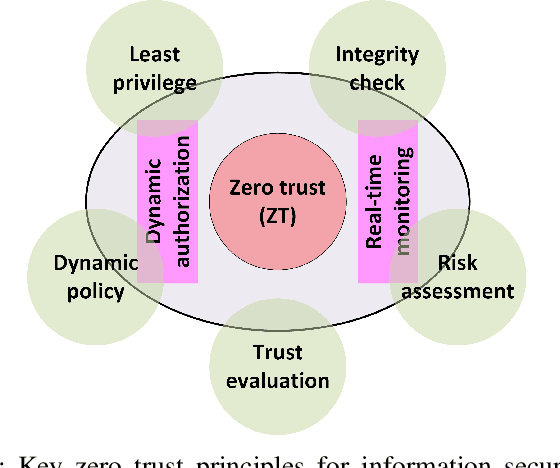
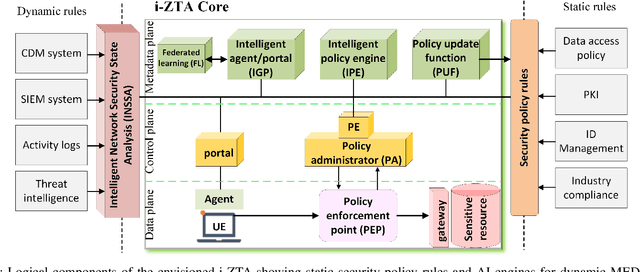
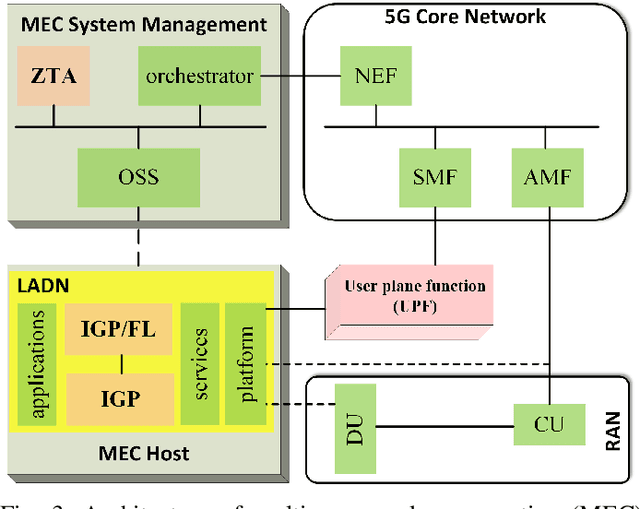
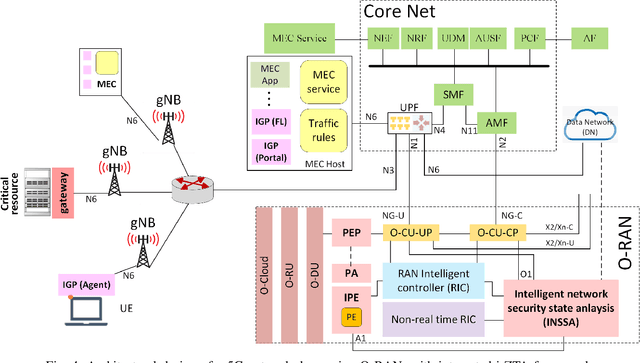
In this position paper, we discuss the critical need for integrating zero trust (ZT) principles into next-generation communication networks (5G/6G) for both tactical and commercial applications. We highlight the challenges and introduce the concept of an intelligent zero trust architecture (i-ZTA) as a security framework in 5G/6G networks with untrusted components. While network virtualization, software-defined networking (SDN), and service-based architectures (SBA) are key enablers of 5G networks, operating in an untrusted environment has also become a key feature of the networks. Further, seamless connectivity to a high volume of devices in multi-radio access technology (RAT) has broadened the attack surface on information infrastructure. Network assurance in a dynamic untrusted environment calls for revolutionary architectures beyond existing static security frameworks. This paper presents the architectural design of an i-ZTA upon which modern artificial intelligence (AI) algorithms can be developed to provide information security in untrusted networks. We introduce key ZT principles as real-time Monitoring of the security state of network assets, Evaluating the risk of individual access requests, and Deciding on access authorization using a dynamic trust algorithm, called MED components. The envisioned architecture adopts an SBA-based design, similar to the 3GPP specification of 5G networks, by leveraging the open radio access network (O-RAN) architecture with appropriate real-time engines and network interfaces for collecting necessary machine learning data. The i-ZTA is also expected to exploit the multi-access edge computing (MEC) technology of 5G as a key enabler of intelligent MED components for resource-constraint devices.
Prediction of adverse events in Afghanistan: regression analysis of time series data grouped not by geographic dependencies
Feb 27, 2020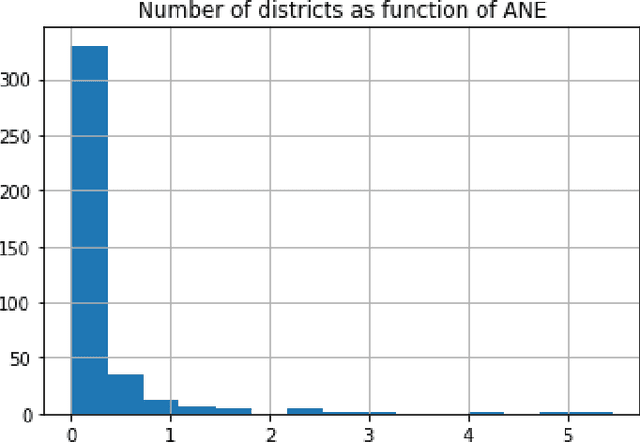

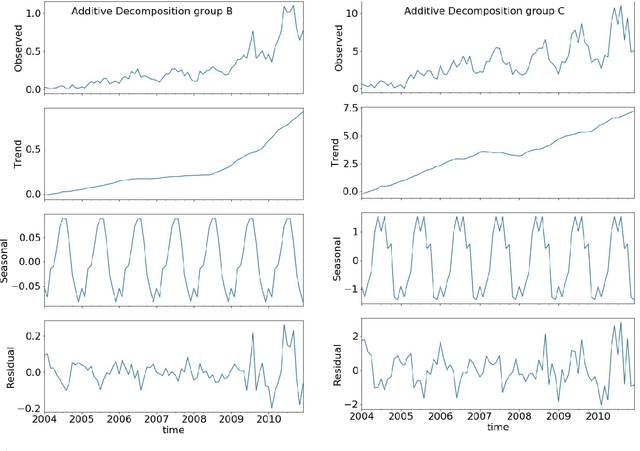
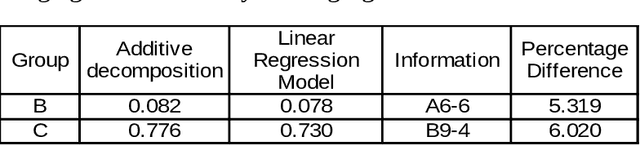
The aim of this study was to approach a difficult regression task on highly unbalanced data regarding active theater of war in Afghanistan. Our focus was set on predicting the negative events number without distinguishing precise nature of the events given historical data on investment and negative events per each of predefined 400 Afghanistan districts. In contrast with previous research on the matter, we propose an approach to analysis of time series data that benefits from non-conventional aggregation of these territorial entities. By carrying out initial exploratory data analysis we demonstrate that dividing data according to our proposal allows to identify strong trend and seasonal components in the selected target variable. Utilizing this approach we also tried to estimate which data regarding investments is most important for prediction performance. Based on our exploratory analysis and previous research we prepared 5 sets of independent variables that were fed to 3 machine learning regression models. The results expressed by mean absolute and mean square errors indicate that leveraging historical data regarding target variable allows for reasonable performance, however unfortunately other proposed independent variables does not seem to improve prediction quality.
Transformer-based unsupervised patient representation learning based on medical claims for risk stratification and analysis
Jun 23, 2021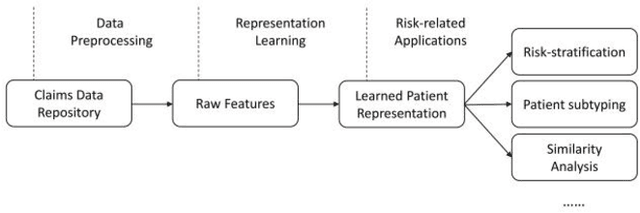
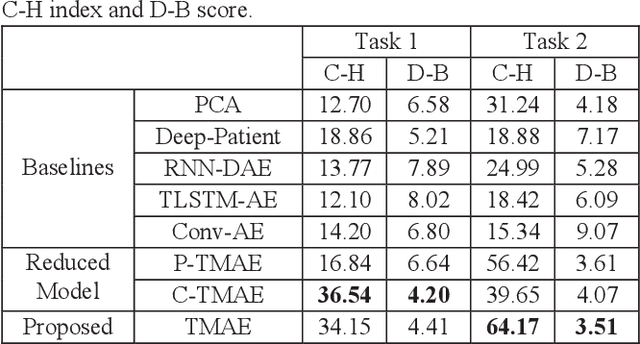
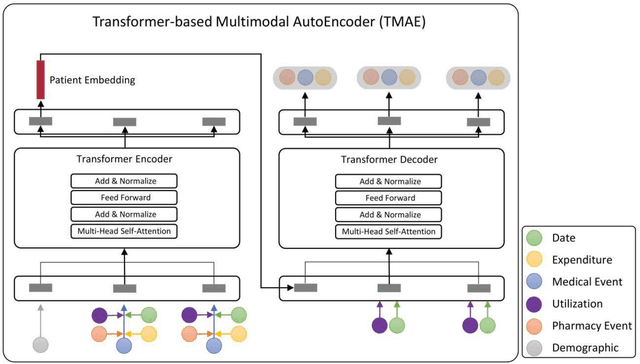
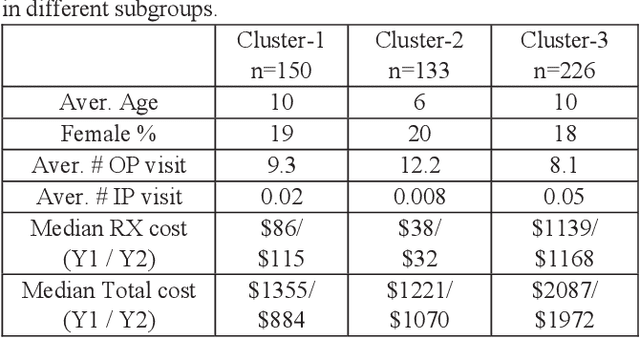
The claims data, containing medical codes, services information, and incurred expenditure, can be a good resource for estimating an individual's health condition and medical risk level. In this study, we developed Transformer-based Multimodal AutoEncoder (TMAE), an unsupervised learning framework that can learn efficient patient representation by encoding meaningful information from the claims data. TMAE is motivated by the practical needs in healthcare to stratify patients into different risk levels for improving care delivery and management. Compared to previous approaches, TMAE is able to 1) model inpatient, outpatient, and medication claims collectively, 2) handle irregular time intervals between medical events, 3) alleviate the sparsity issue of the rare medical codes, and 4) incorporate medical expenditure information. We trained TMAE using a real-world pediatric claims dataset containing more than 600,000 patients and compared its performance with various approaches in two clustering tasks. Experimental results demonstrate that TMAE has superior performance compared to all baselines. Multiple downstream applications are also conducted to illustrate the effectiveness of our framework. The promising results confirm that the TMAE framework is scalable to large claims data and is able to generate efficient patient embeddings for risk stratification and analysis.
Predicting sepsis in multi-site, multi-national intensive care cohorts using deep learning
Jul 12, 2021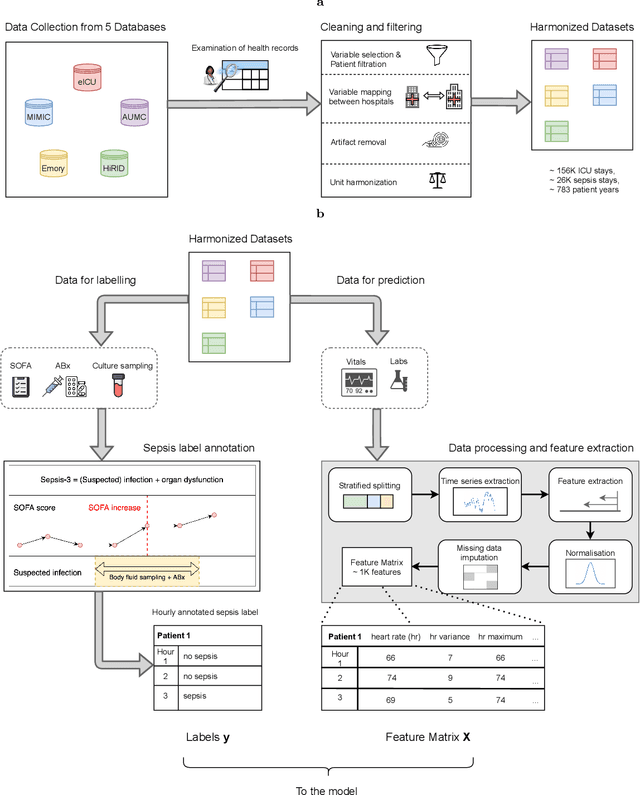
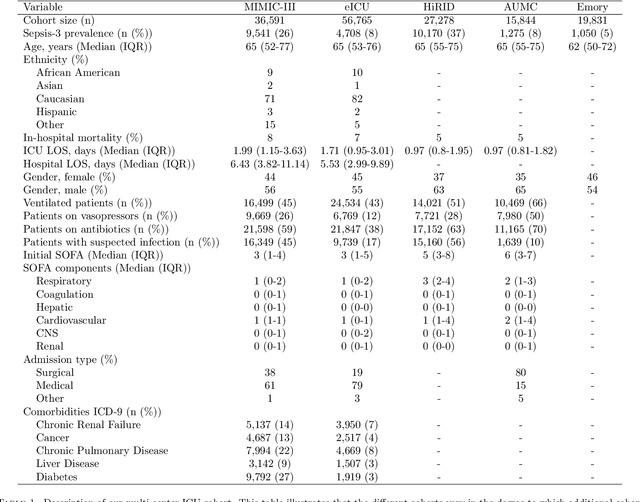
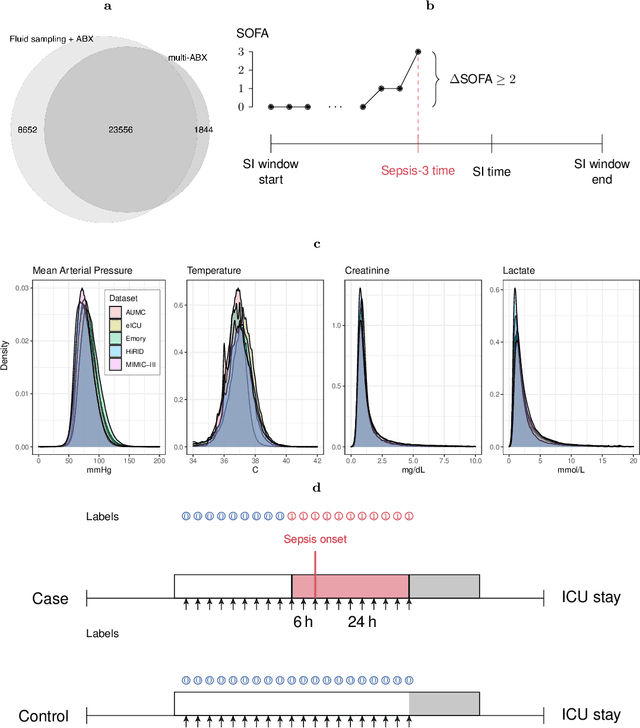
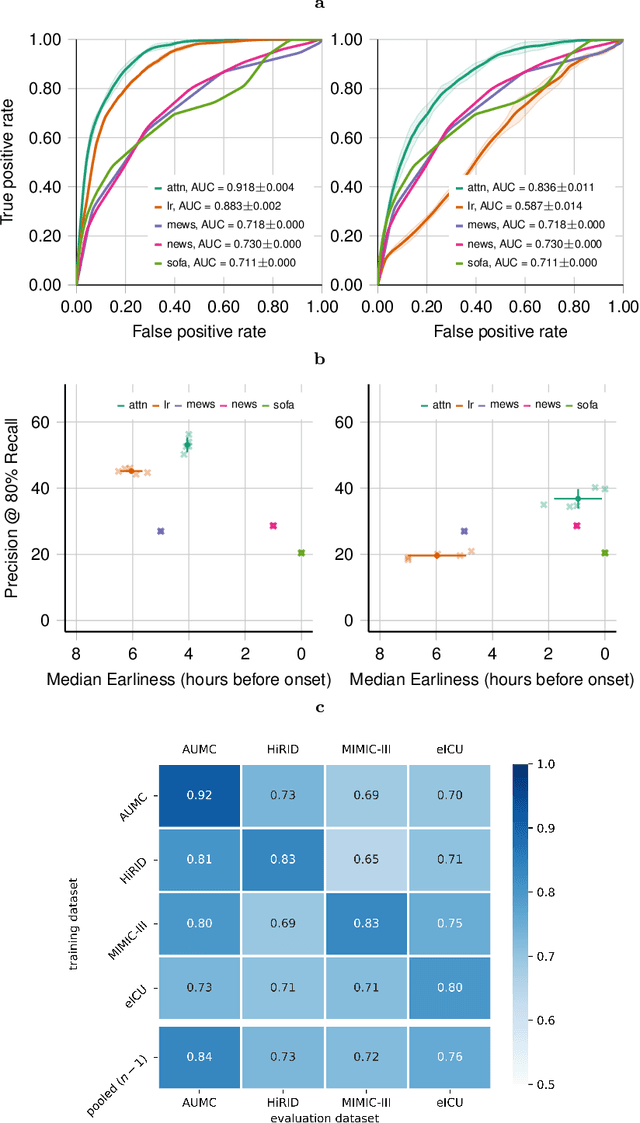
Despite decades of clinical research, sepsis remains a global public health crisis with high mortality, and morbidity. Currently, when sepsis is detected and the underlying pathogen is identified, organ damage may have already progressed to irreversible stages. Effective sepsis management is therefore highly time-sensitive. By systematically analysing trends in the plethora of clinical data available in the intensive care unit (ICU), an early prediction of sepsis could lead to earlier pathogen identification, resistance testing, and effective antibiotic and supportive treatment, and thereby become a life-saving measure. Here, we developed and validated a machine learning (ML) system for the prediction of sepsis in the ICU. Our analysis represents the largest multi-national, multi-centre in-ICU study for sepsis prediction using ML to date. Our dataset contains $156,309$ unique ICU admissions, which represent a refined and harmonised subset of five large ICU databases originating from three countries. Using the international consensus definition Sepsis-3, we derived hourly-resolved sepsis label annotations, amounting to $26,734$ ($17.1\%$) septic stays. We compared our approach, a deep self-attention model, to several clinical baselines as well as ML baselines and performed an extensive internal and external validation within and across databases. On average, our model was able to predict sepsis with an AUROC of $0.847 \pm 0.050$ (internal out-of sample validation) and $0.761 \pm 0.052$ (external validation). For a harmonised prevalence of $17\%$, at $80\%$ recall our model detects septic patients with $39\%$ precision 3.7 hours in advance.
Domain-independent User Simulation with Transformers for Task-oriented Dialogue Systems
Jun 16, 2021
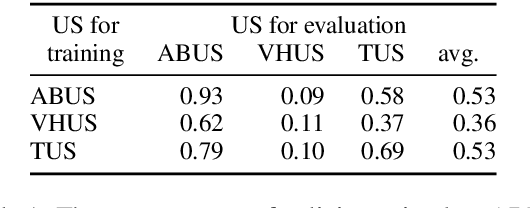

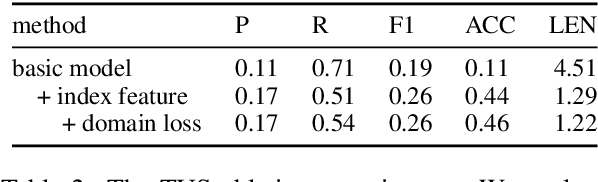
Dialogue policy optimisation via reinforcement learning requires a large number of training interactions, which makes learning with real users time consuming and expensive. Many set-ups therefore rely on a user simulator instead of humans. These user simulators have their own problems. While hand-coded, rule-based user simulators have been shown to be sufficient in small, simple domains, for complex domains the number of rules quickly becomes intractable. State-of-the-art data-driven user simulators, on the other hand, are still domain-dependent. This means that adaptation to each new domain requires redesigning and retraining. In this work, we propose a domain-independent transformer-based user simulator (TUS). The structure of our TUS is not tied to a specific domain, enabling domain generalisation and learning of cross-domain user behaviour from data. We compare TUS with the state of the art using automatic as well as human evaluations. TUS can compete with rule-based user simulators on pre-defined domains and is able to generalise to unseen domains in a zero-shot fashion.
Automatic size and pose homogenization with spatial transformer network to improve and accelerate pediatric segmentation
Jul 06, 2021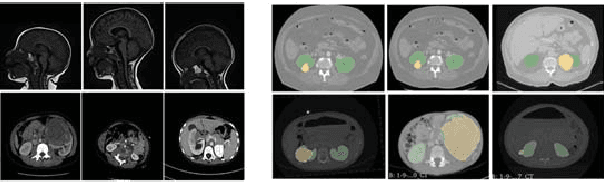


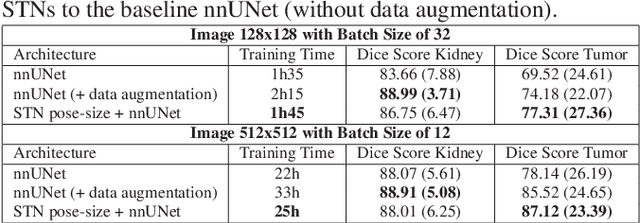
Due to a high heterogeneity in pose and size and to a limited number of available data, segmentation of pediatric images is challenging for deep learning methods. In this work, we propose a new CNN architecture that is pose and scale invariant thanks to the use of Spatial Transformer Network (STN). Our architecture is composed of three sequential modules that are estimated together during training: (i) a regression module to estimate a similarity matrix to normalize the input image to a reference one; (ii) a differentiable module to find the region of interest to segment; (iii) a segmentation module, based on the popular UNet architecture, to delineate the object. Unlike the original UNet, which strives to learn a complex mapping, including pose and scale variations, from a finite training dataset, our segmentation module learns a simpler mapping focusing on images with normalized pose and size. Furthermore, the use of an automatic bounding box detection through STN allows saving time and especially memory, while keeping similar performance. We test the proposed method in kidney and renal tumor segmentation on abdominal pediatric CT scanners. Results indicate that the estimated STN homogenization of size and pose accelerates the segmentation (25h), compared to standard data-augmentation (33h), while obtaining a similar quality for the kidney (88.01\% of Dice score) and improving the renal tumor delineation (from 85.52\% to 87.12\%).
* ISBI 2021
Synthetic aperture interference light (SAIL) microscopy for high-throughput label-free imaging
Apr 15, 2021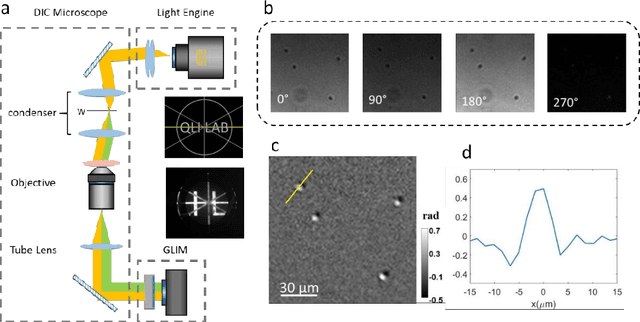
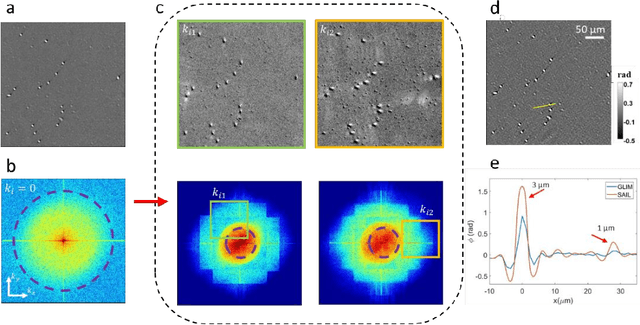


Quantitative phase imaging (QPI) is a valuable label-free modality that has gained significant interest due to its wide potentials, from basic biology to clinical applications. Most existing QPI systems measure microscopic objects via interferometry or nonlinear iterative phase reconstructions from intensity measurements. However, all imaging systems compromise spatial resolution for field of view and vice versa, i.e., suffer from a limited space bandwidth product. Current solutions to this problem involve computational phase retrieval algorithms, which are time-consuming and often suffer from convergence problems. In this article, we presented synthetic aperture interference light (SAIL) microscopy as a novel modality for high-resolution, wide field of view QPI. The proposed approach employs low-coherence interferometry to directly measure the optical phase delay under different illumination angles and produces large space-bandwidth product (SBP) label-free imaging. We validate the performance of SAIL on standard samples and illustrate the biomedical applications on various specimens: pathology slides, entire insects, and dynamic live cells in large cultures. The reconstructed images have a synthetic numeric aperture of 0.45, and a field of view of 2.6 x 2.6 mm2. Due to its direct measurement of the phase information, SAIL microscopy does not require long computational time, eliminates data redundancy, and always converges.
Context-Aware Attention-Based Data Augmentation for POI Recommendation
Jun 30, 2021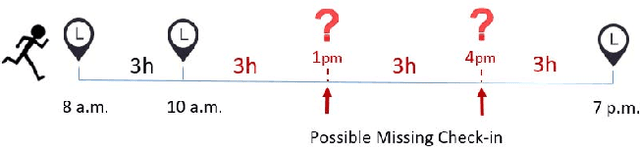
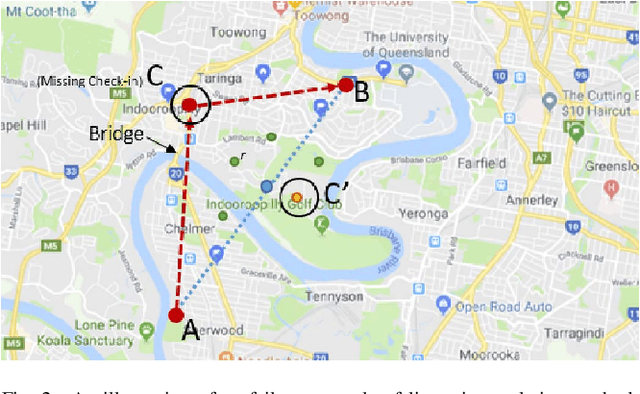
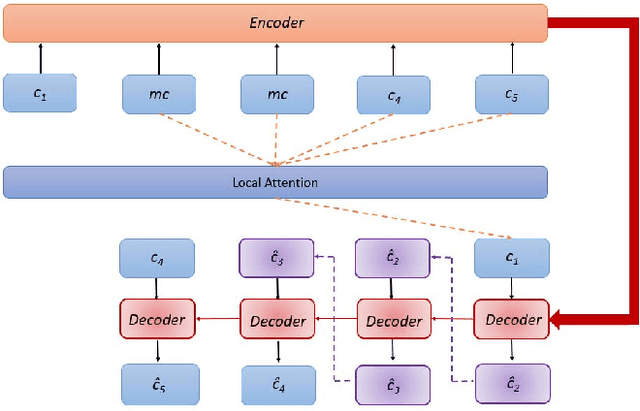
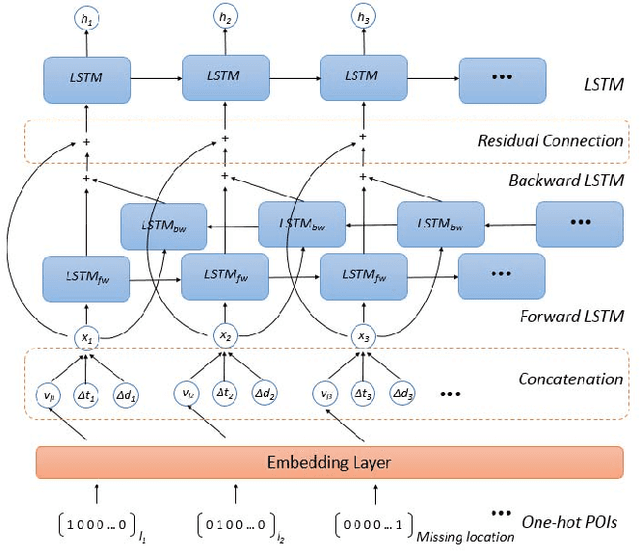
With the rapid growth of location-based social networks (LBSNs), Point-Of-Interest (POI) recommendation has been broadly studied in this decade. Recently, the next POI recommendation, a natural extension of POI recommendation, has attracted much attention. It aims at suggesting the next POI to a user in spatial and temporal context, which is a practical yet challenging task in various applications. Existing approaches mainly model the spatial and temporal information, and memorize historical patterns through user's trajectories for recommendation. However, they suffer from the negative impact of missing and irregular check-in data, which significantly influences the model performance. In this paper, we propose an attention-based sequence-to-sequence generative model, namely POI-Augmentation Seq2Seq (PA-Seq2Seq), to address the sparsity of training set by making check-in records to be evenly-spaced. Specifically, the encoder summarises each check-in sequence and the decoder predicts the possible missing check-ins based on the encoded information. In order to learn time-aware correlation among user history, we employ local attention mechanism to help the decoder focus on a specific range of context information when predicting a certain missing check-in point. Extensive experiments have been conducted on two real-world check-in datasets, Gowalla and Brightkite, for performance and effectiveness evaluation.