 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Regularization of Mixture Models for Robust Principal Graph Learning
Jun 16, 2021
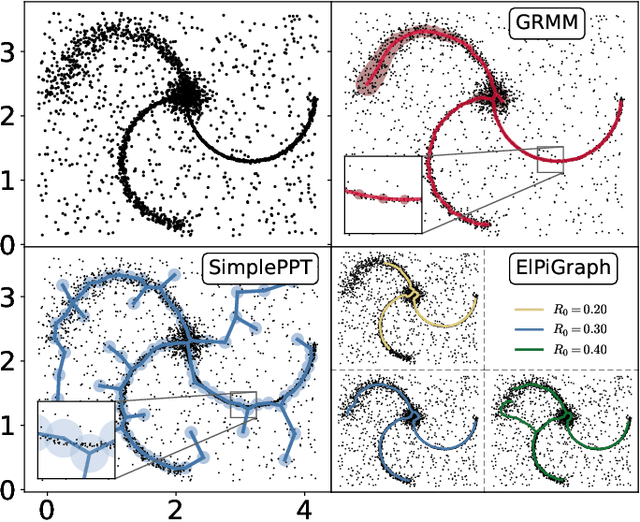
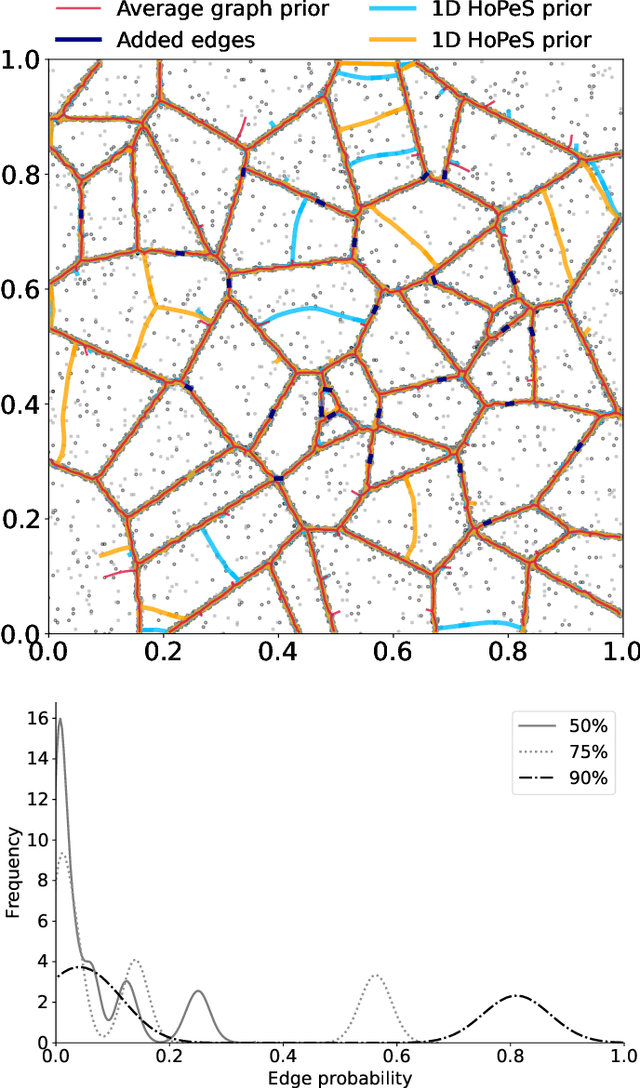
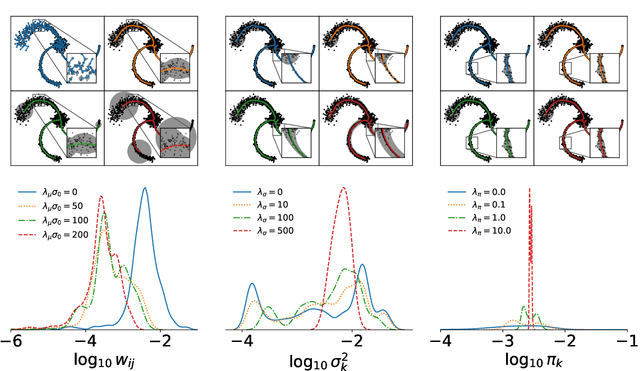
A regularized version of Mixture Models is proposed to learn a principal graph from a distribution of $D$-dimensional data points. In the particular case of manifold learning for ridge detection, we assume that the underlying manifold can be modeled as a graph structure acting like a topological prior for the Gaussian clusters turning the problem into a maximum a posteriori estimation. Parameters of the model are iteratively estimated through an Expectation-Maximization procedure making the learning of the structure computationally efficient with guaranteed convergence for any graph prior in a polynomial time. We also embed in the formalism a natural way to make the algorithm robust to outliers of the pattern and heteroscedasticity of the manifold sampling coherently with the graph structure. The method uses a graph prior given by the minimum spanning tree that we extend using random sub-samplings of the dataset to take into account cycles that can be observed in the spatial distribution.
GateKeeper-GPU: Fast and Accurate Pre-Alignment Filtering in Short Read Mapping
Mar 31, 2021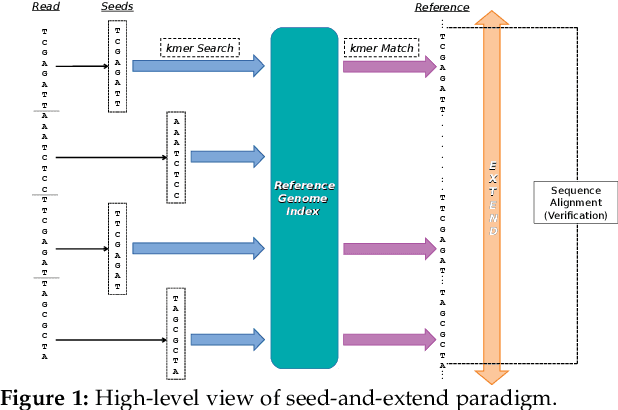
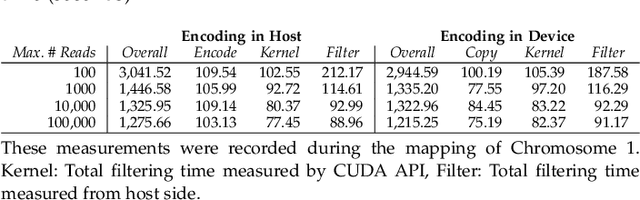

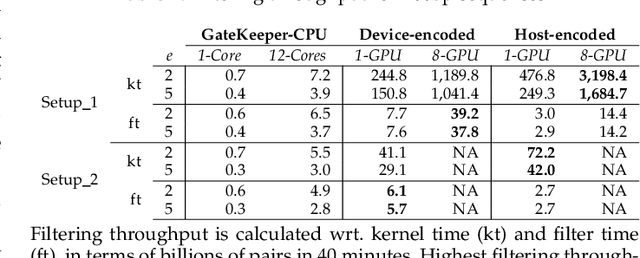
At the last step of short read mapping, the candidate locations of the reads on the reference genome are verified to compute their differences from the corresponding reference segments using sequence alignment algorithms. Calculating the similarities and differences between two sequences is still computationally expensive since approximate string matching techniques traditionally inherit dynamic programming algorithms with quadratic time and space complexity. We introduce GateKeeper-GPU, a fast and accurate pre-alignment filter that efficiently reduces the need for expensive sequence alignment. GateKeeper-GPU provides two main contributions: first, improving the filtering accuracy of GateKeeper(state-of-the-art lightweight pre-alignment filter), second, exploiting the massive parallelism provided by the large number of GPU threads of modern GPUs to examine numerous sequence pairs rapidly and concurrently. GateKeeper-GPU accelerates the sequence alignment by up to 2.9x and provides up to 1.4x speedup to the end-to-end execution time of a comprehensive read mapper (mrFAST). GateKeeper-GPU is available at https://github.com/BilkentCompGen/GateKeeper-GPU
HeunNet: Extending ResNet using Heun's Methods
May 13, 2021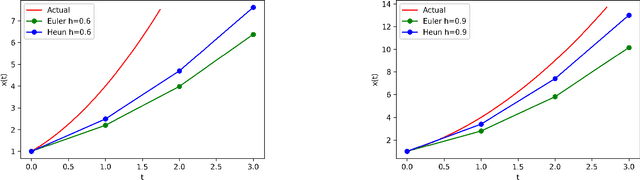
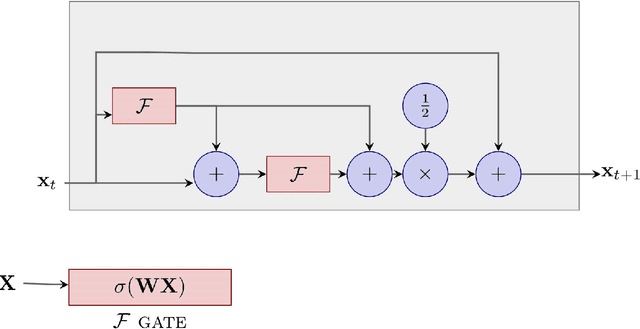
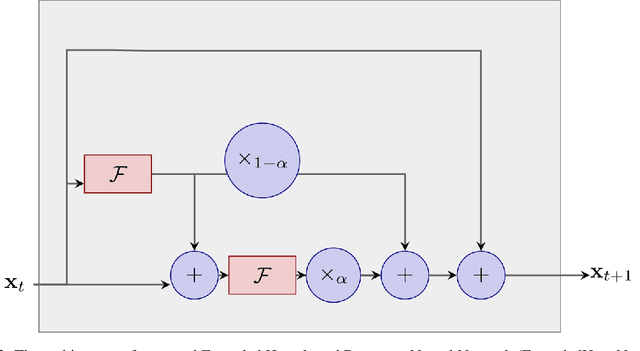
There is an analogy between the ResNet (Residual Network) architecture for deep neural networks and an Euler solver for an ODE. The transformation performed by each layer resembles an Euler step in solving an ODE. We consider the Heun Method, which involves a single predictor-corrector cycle, and complete the analogy, building a predictor-corrector variant of ResNet, which we call a HeunNet. Just as Heun's method is more accurate than Euler's, experiments show that HeunNet achieves high accuracy with low computational (both training and test) time compared to both vanilla recurrent neural networks and other ResNet variants.
Improving Adverse Drug Event Extraction with SpanBERT on Different Text Typologies
May 19, 2021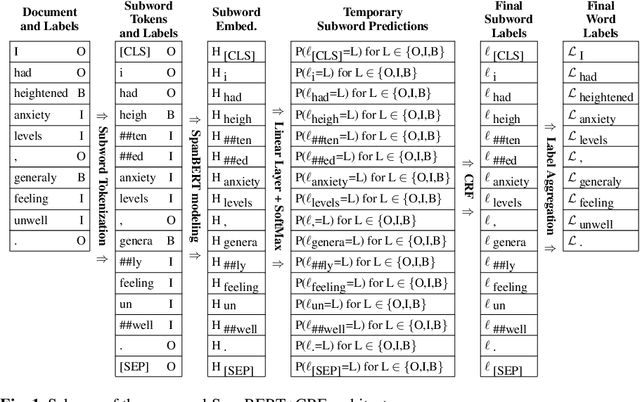
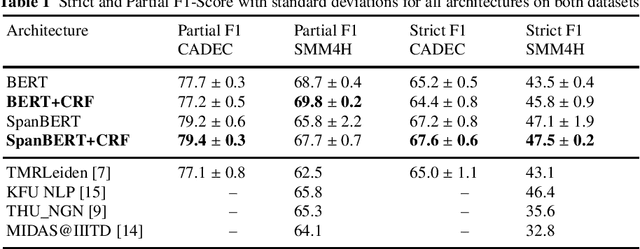
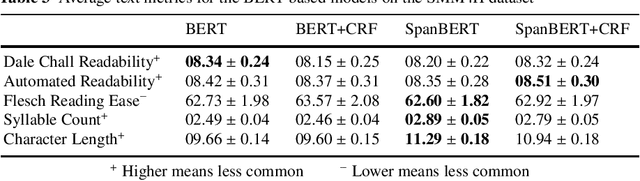
In recent years, Internet users are reporting Adverse Drug Events (ADE) on social media, blogs and health forums. Because of the large volume of reports, pharmacovigilance is seeking to resort to NLP to monitor these outlets. We propose for the first time the use of the SpanBERT architecture for the task of ADE extraction: this new version of the popular BERT transformer showed improved capabilities with multi-token text spans. We validate our hypothesis with experiments on two datasets (SMM4H and CADEC) with different text typologies (tweets and blog posts), finding that SpanBERT combined with a CRF outperforms all the competitors on both of them.
Fast improvement of TEM image with low-dose electrons by deep learning
Jun 03, 2021
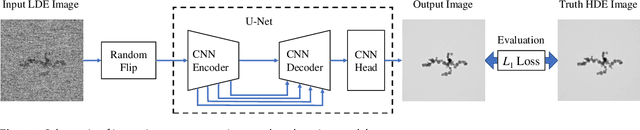
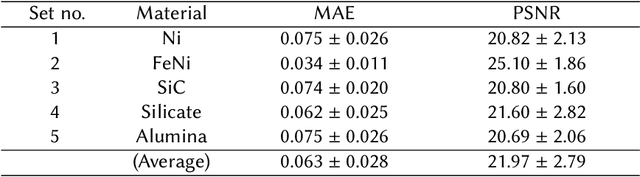
Low-electron-dose observation is indispensable for observing various samples using a transmission electron microscope; consequently, image processing has been used to improve transmission electron microscopy (TEM) images. To apply such image processing to in situ observations, we here apply a convolutional neural network to TEM imaging. Using a dataset that includes short-exposure images and long-exposure images, we develop a pipeline for processed short-exposure images, based on end-to-end training. The quality of images acquired with a total dose of approximately 5 e- per pixel becomes comparable to that of images acquired with a total dose of approximately 1000 e- per pixel. Because the conversion time is approximately 8 ms, in situ observation at 125 fps is possible. This imaging technique enables in situ observation of electron-beam-sensitive specimens.
Rethinking the limiting dynamics of SGD: modified loss, phase space oscillations, and anomalous diffusion
Jul 19, 2021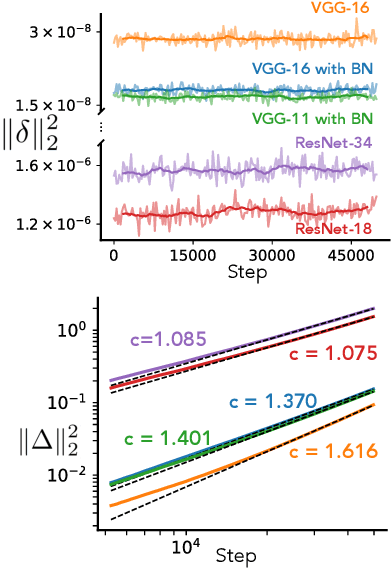
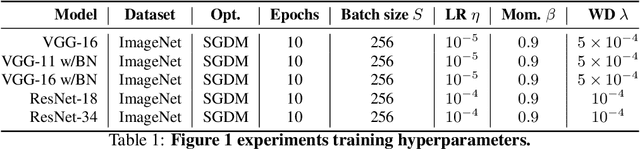
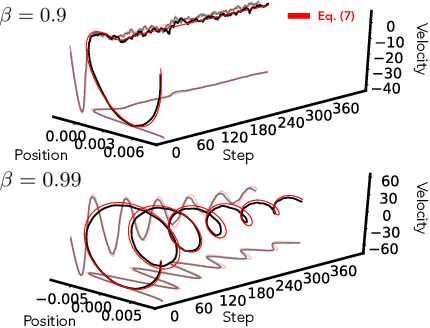

In this work we explore the limiting dynamics of deep neural networks trained with stochastic gradient descent (SGD). We find empirically that long after performance has converged, networks continue to move through parameter space by a process of anomalous diffusion in which distance travelled grows as a power law in the number of gradient updates with a nontrivial exponent. We reveal an intricate interaction between the hyperparameters of optimization, the structure in the gradient noise, and the Hessian matrix at the end of training that explains this anomalous diffusion. To build this understanding, we first derive a continuous-time model for SGD with finite learning rates and batch sizes as an underdamped Langevin equation. We study this equation in the setting of linear regression, where we can derive exact, analytic expressions for the phase space dynamics of the parameters and their instantaneous velocities from initialization to stationarity. Using the Fokker-Planck equation, we show that the key ingredient driving these dynamics is not the original training loss, but rather the combination of a modified loss, which implicitly regularizes the velocity, and probability currents, which cause oscillations in phase space. We identify qualitative and quantitative predictions of this theory in the dynamics of a ResNet-18 model trained on ImageNet. Through the lens of statistical physics, we uncover a mechanistic origin for the anomalous limiting dynamics of deep neural networks trained with SGD.
A Time-Segmented Consortium Blockchain for Robotic Event Registration
May 14, 2019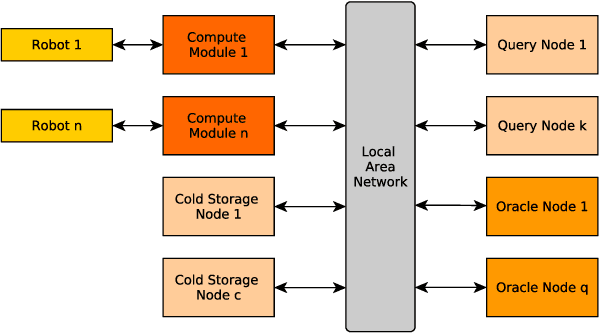
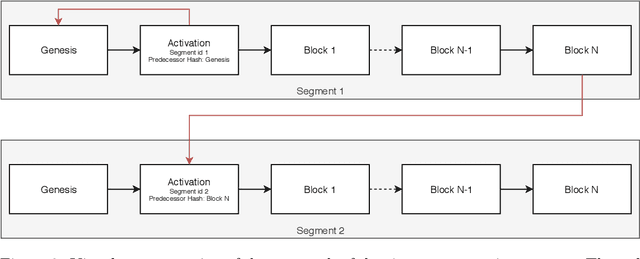
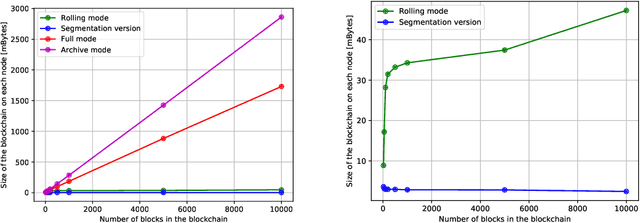
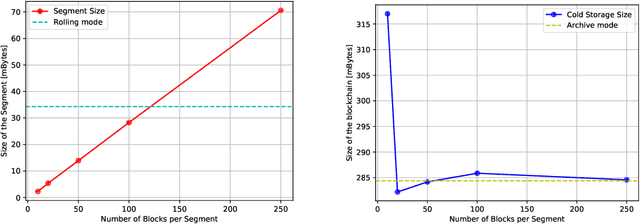
A blockchain, during its lifetime, records large amounts of data, that in a common usage its kept on its entirety. In a robotics environment, the old information is useful for human evaluation, or oracles interfacing with the blockchain but it is not useful for the robots that require only current information in order to continue their work. This causes a storage problem in blockchain nodes that have limited storage capacity, such as in the case of nodes attached to robots that are usually built around embedded solutions. This paper presents a time-segmentation solution for devices with limited storage capacity, integrated in a particular robot-directed blockchain called RobotChain. Results are presented regarding the proposed solution that show that the goal of restricting each node's capacity is reached without compromising all the benefits that arise from the use of blockchains in these contexts, and on the contrary, it allows for cheap nodes to use this blockchain, reduces storage costs and allows faster deployment of new nodes.
Towards On-Device Face Recognition in Body-worn Cameras
Apr 07, 2021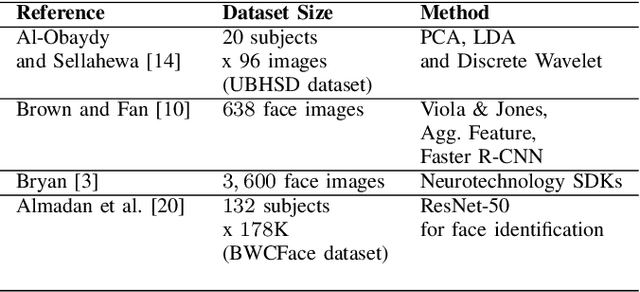
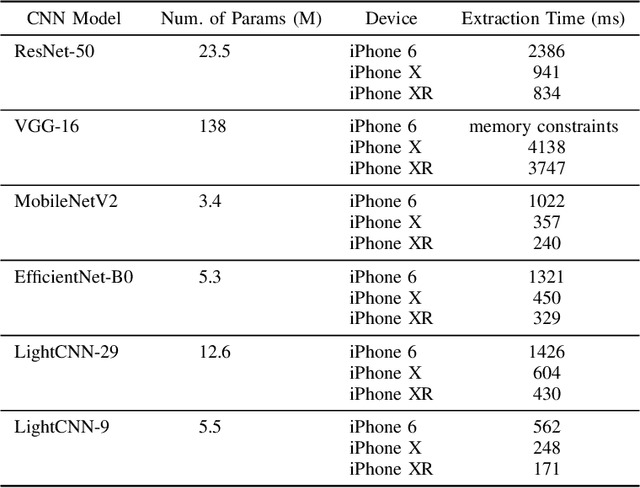
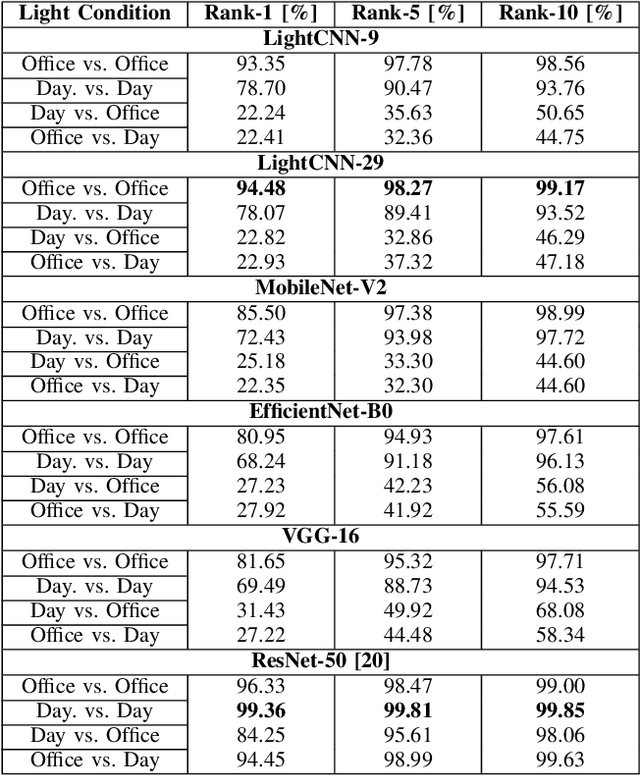
Face recognition technology related to recognizing identities is widely adopted in intelligence gathering, law enforcement, surveillance, and consumer applications. Recently, this technology has been ported to smartphones and body-worn cameras (BWC). Face recognition technology in body-worn cameras is used for surveillance, situational awareness, and keeping the officer safe. Only a handful of academic studies exist in face recognition using the body-worn camera. A recent study has assembled BWCFace facial image dataset acquired using a body-worn camera and evaluated the ResNet-50 model for face identification. However, for real-time inference in resource constraint body-worn cameras and privacy concerns involving facial images, on-device face recognition is required. To this end, this study evaluates lightweight MobileNet-V2, EfficientNet-B0, LightCNN-9 and LightCNN-29 models for face identification using body-worn camera. Experiments are performed on a publicly available BWCface dataset. The real-time inference is evaluated on three mobile devices. The comparative analysis is done with heavy-weight VGG-16 and ResNet-50 models along with six hand-crafted features to evaluate the trade-off between the performance and model size. Experimental results suggest the difference in maximum rank-1 accuracy of lightweight LightCNN-29 over best-performing ResNet-50 is \textbf{1.85\%} and the reduction in model parameters is \textbf{23.49M}. Most of the deep models obtained similar performances at rank-5 and rank-10. The inference time of LightCNNs is 2.1x faster than other models on mobile devices. The least performance difference of \textbf{14\%} is noted between LightCNN-29 and Local Phase Quantization (LPQ) descriptor at rank-1. In most of the experimental settings, lightweight LightCNN models offered the best trade-off between accuracy and the model size in comparison to most of the models.
* 6 pages
Learned Sorted Table Search and Static Indexes in Small Space: Methodological and Practical Insights via an Experimental Study
Jul 19, 2021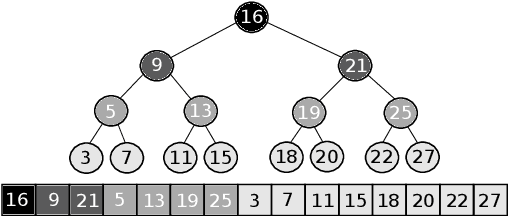

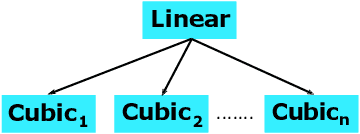

Sorted Table Search Procedures are the quintessential query-answering tool, still very useful, e.g, Search Engines (Google Chrome). Speeding them up, in small additional space with respect to the table being searched into, is still a quite significant achievement. Static Learned Indexes have been very successful in achieving such a speed-up, but leave open a major question: To what extent one can enjoy the speed-up of Learned Indexes while using constant or nearly constant additional space. By generalizing the experimental methodology of a recent benchmarking study on Learned Indexes, we shed light on this question, by considering two scenarios. The first, quite elementary, i.e., textbook code, and the second using advanced Learned Indexing algorithms and the supporting sophisticated software platforms. Although in both cases one would expect a positive answer, its achievement is not as simple as it seems. Indeed, our extensive set of experiments reveal a complex relationship between query time and model space. The findings regarding this relationship and the corresponding quantitative estimates, across memory levels, can be of interest to algorithm designers and of use to practitioners as well. As an essential part of our research, we introduce two new models that are of interest in their own right. The first is a constant space model that can be seen as a generalization of $k$-ary search, while the second is a synoptic {\bf RMI}, in which we can control model space usage.
AutoPtosis
Jun 07, 2021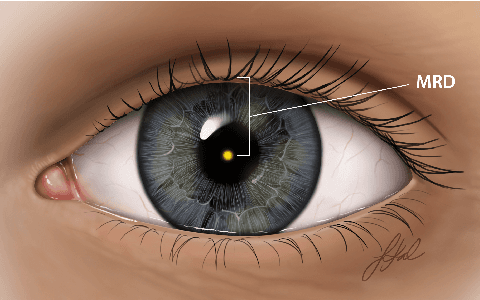


Blepharoptosis, or ptosis as it is more commonly referred to, is a condition of the eyelid where the upper eyelid droops. The current diagnosis for ptosis involves cumbersome manual measurements that are time-consuming and prone to human error. In this paper, we present AutoPtosis, an artificial intelligence based system with interpretable results for rapid diagnosis of ptosis. We utilize a diverse dataset collected at the University of Illinois Hospital and Health to successfully develop a robust deep learning model for prediction and also develop a clinically inspired model that calculates the marginal reflex distance and iris ratio. AutoPtosis achieved 95.5% accuracy on physician verified data that had an equal class balance. The proposed algorithm can help in the rapid and timely diagnosis of ptosis, significantly reduce the burden on the healthcare system, and save the patients and clinics valuable resources.