 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
UAV Communications with WPT-aided Cell-Free Massive MIMO Systems
Apr 23, 2021
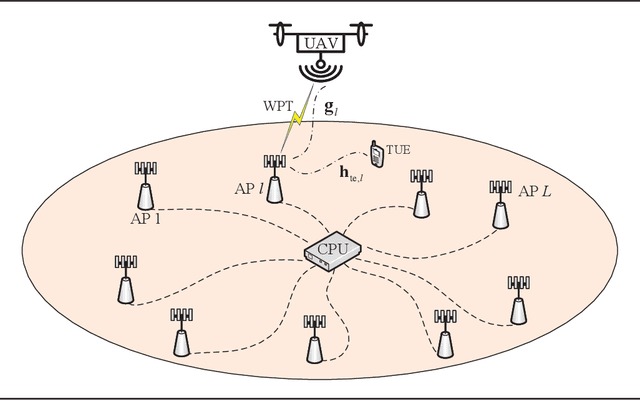
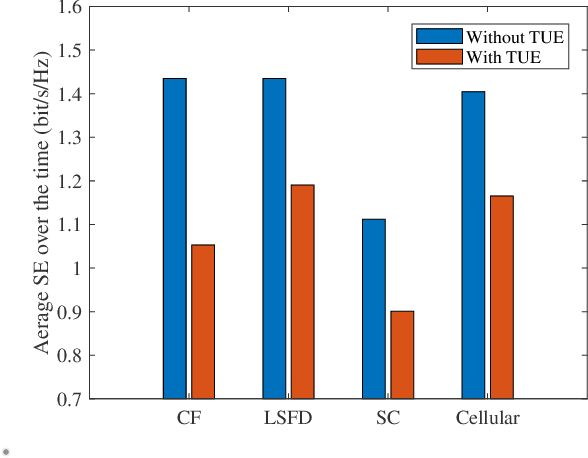
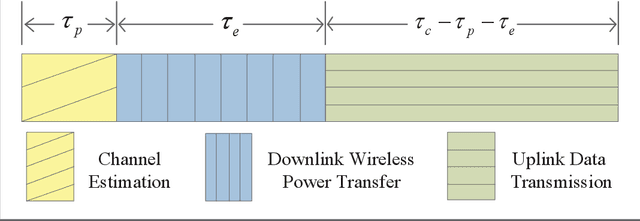
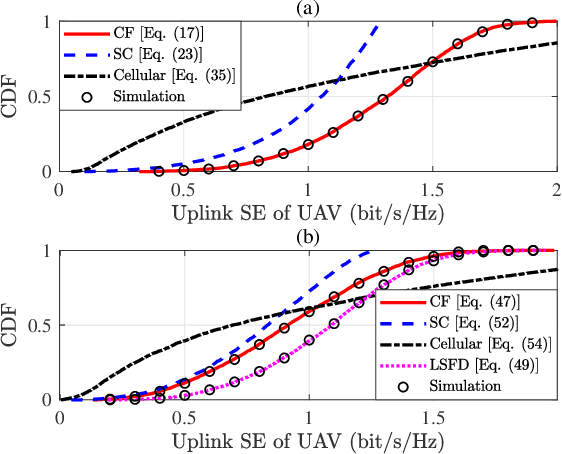
Cell-free (CF) massive multiple-input multiple-output (MIMO) is a promising solution to provide uniform good performance for unmanned aerial vehicle (UAV) communications. In this paper, we propose the UAV communication with wireless power transfer (WPT) aided CF massive MIMO systems, where the harvested energy (HE) from the downlink WPT is used to support both uplink data and pilot transmission. We derive novel closed-form downlink HE and uplink spectral efficiency (SE) expressions that take hardware impairments of UAV into account. UAV communications with current small cell (SC) and cellular massive MIMO enabled WPT systems are also considered for comparison. It is significant to show that CF massive MIMO achieves two and five times higher 95\%-likely uplink SE than the ones of SC and cellular massive MIMO, respectively. Besides, the large-scale fading decoding receiver cooperation can reduce the interference of the terrestrial user. Moreover, the maximum SE can be achieved by changing the time-splitting fraction. We prove that the optimal time-splitting fraction for maximum SE is determined by the number of antennas, altitude and hardware quality factor of UAVs. Furthermore, we propose three UAV trajectory design schemes to improve the SE. It is interesting that the angle search scheme performs best than both AP search and line path schemes. Finally, simulation results are presented to validate the accuracy of our expressions.
Proximally Optimal Predictive Control Algorithm for Path Tracking of Self-Driving Cars
Mar 24, 2021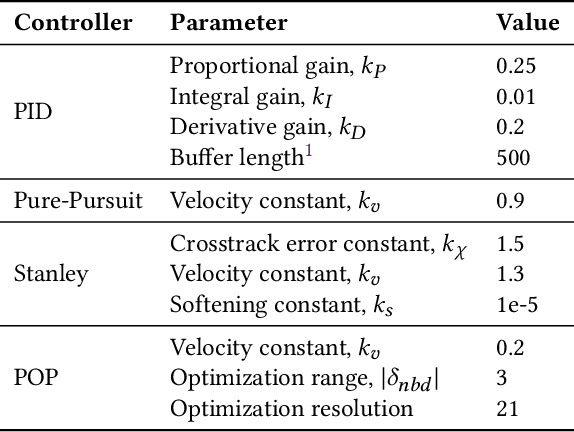
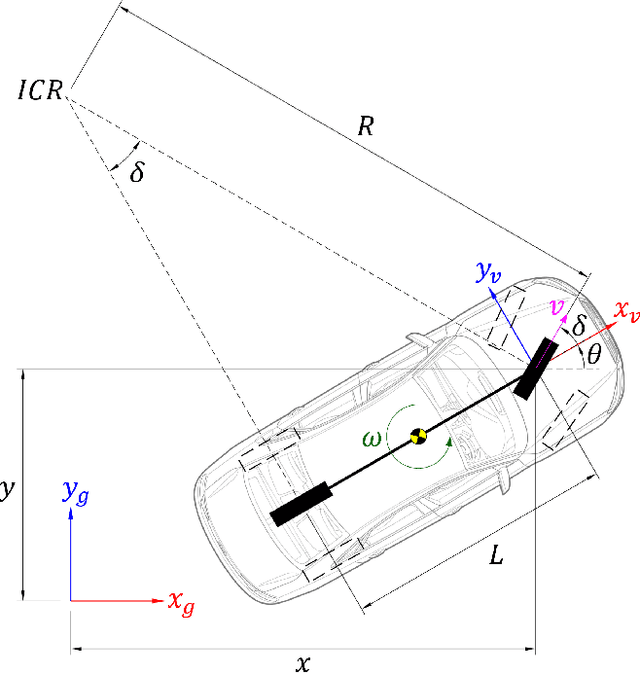

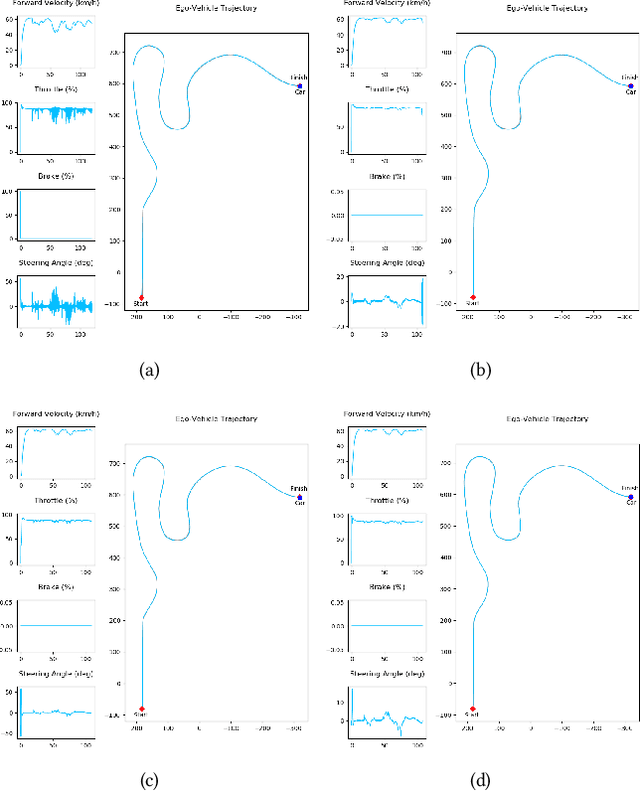
This work presents proximally optimal predictive control algorithm, which is essentially a model-based lateral controller for steered autonomous vehicles that selects an optimal steering command within the neighborhood of previous steering angle based on the predicted vehicle location. The proposed algorithm was formulated with an aim of overcoming the limitations associated with the existing control laws for autonomous steering - namely PID, Pure-Pursuit and Stanley controllers. Particularly, our approach was aimed at bridging the gap between tracking efficiency and computational cost, thereby ensuring effective path tracking in real-time. The effectiveness of our approach was investigated through a series of dynamic simulation experiments pertaining to autonomous path tracking, employing an adaptive control law for longitudinal motion control of the vehicle. We measured the latency of the proposed algorithm in order to comment on its real-time factor and validated our approach by comparing it against the established control laws in terms of both crosstrack and heading errors recorded throughout the respective path tracking simulations.
A Simplified Framework for Air Route Clustering Based on ADS-B Data
Jul 07, 2021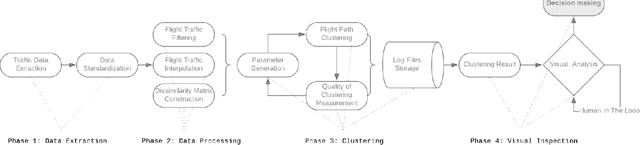
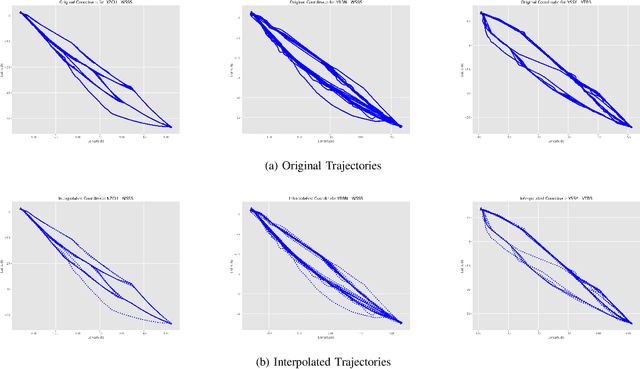
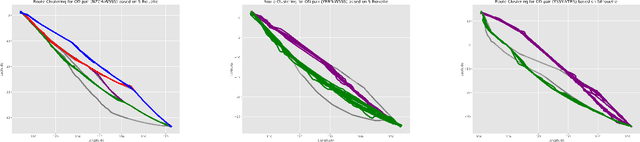
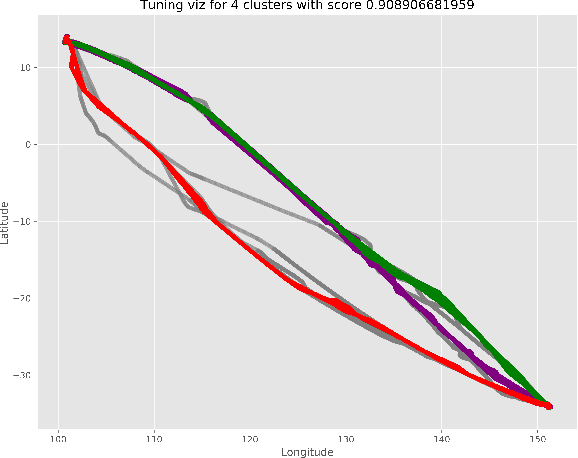
The volume of flight traffic gets increasing over the time, which makes the strategic traffic flow management become one of the challenging problems since it requires a lot of computational resources to model entire traffic data. On the other hand, Automatic Dependent Surveillance - Broadcast (ADS-B) technology has been considered as a promising data technology to provide both flight crews and ground control staff the necessary information safely and efficiently about the position and velocity of the airplanes in a specific area. In the attempt to tackle this problem, we presented in this paper a simplified framework that can support to detect the typical air routes between airports based on ADS-B data. Specifically, the flight traffic will be classified into major groups based on similarity measures, which helps to reduce the number of flight paths between airports. As a matter of fact, our framework can be taken into account to reduce practically the computational cost for air flow optimization and evaluate the operational performance. Finally, in order to illustrate the potential applications of our proposed framework, an experiment was performed using ADS-B traffic flight data of three different pairs of airports. The detected typical routes between each couple of airports show promising results by virtue of combining two indices for measuring the clustering performance and incorporating human judgment into the visual inspection.
Combiner: Full Attention Transformer with Sparse Computation Cost
Jul 12, 2021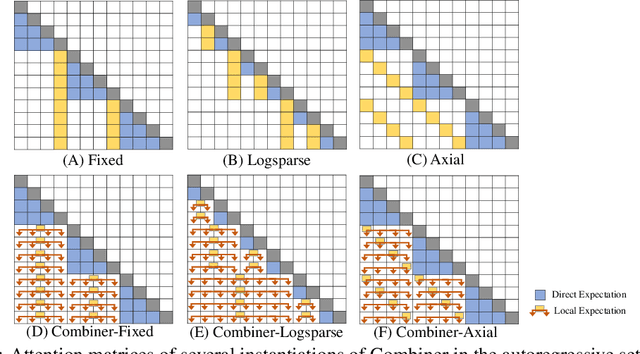
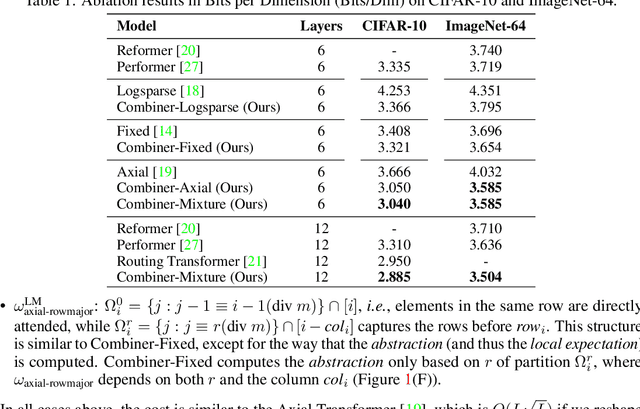
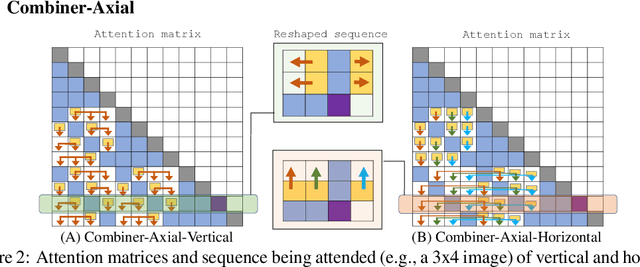

Transformers provide a class of expressive architectures that are extremely effective for sequence modeling. However, the key limitation of transformers is their quadratic memory and time complexity $\mathcal{O}(L^2)$ with respect to the sequence length in attention layers, which restricts application in extremely long sequences. Most existing approaches leverage sparsity or low-rank assumptions in the attention matrix to reduce cost, but sacrifice expressiveness. Instead, we propose Combiner, which provides full attention capability in each attention head while maintaining low computation and memory complexity. The key idea is to treat the self-attention mechanism as a conditional expectation over embeddings at each location, and approximate the conditional distribution with a structured factorization. Each location can attend to all other locations, either via direct attention, or through indirect attention to abstractions, which are again conditional expectations of embeddings from corresponding local regions. We show that most sparse attention patterns used in existing sparse transformers are able to inspire the design of such factorization for full attention, resulting in the same sub-quadratic cost ($\mathcal{O}(L\log(L))$ or $\mathcal{O}(L\sqrt{L})$). Combiner is a drop-in replacement for attention layers in existing transformers and can be easily implemented in common frameworks. An experimental evaluation on both autoregressive and bidirectional sequence tasks demonstrates the effectiveness of this approach, yielding state-of-the-art results on several image and text modeling tasks.
Modelling resource allocation in uncertain system environment through deep reinforcement learning
Jun 17, 2021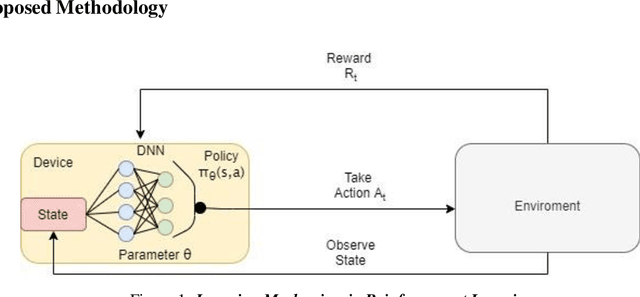
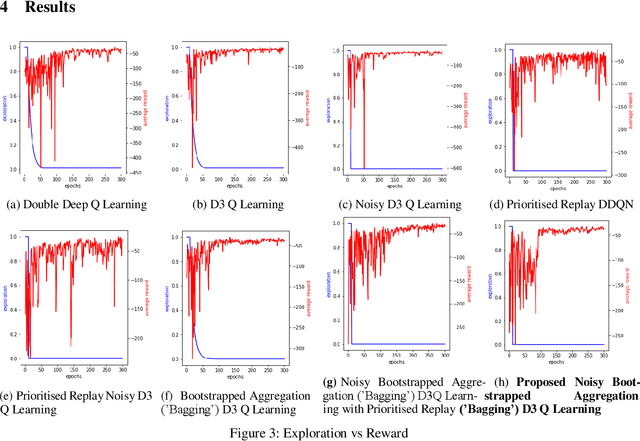
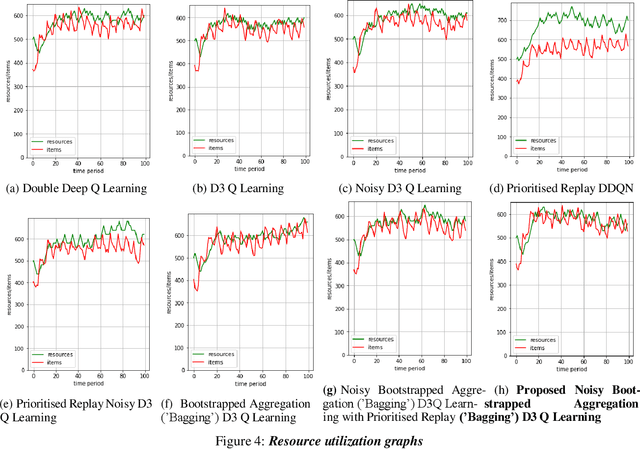
Reinforcement Learning has applications in field of mechatronics, robotics, and other resource-constrained control system. Problem of resource allocation is primarily solved using traditional predefined techniques and modern deep learning methods. The drawback of predefined and most deep learning methods for resource allocation is failing to meet the requirements in cases of uncertain system environment. We can approach problem of resource allocation in uncertain system environment alongside following certain criteria using deep reinforcement learning. Also, reinforcement learning has ability for adapting to new uncertain environment for prolonged period of time. The paper provides a detailed comparative analysis on various deep reinforcement learning methods by applying different components to modify architecture of reinforcement learning with use of noisy layers, prioritized replay, bagging, duelling networks, and other related combination to obtain improvement in terms of performance and reduction of computational cost. The paper identifies problem of resource allocation in uncertain environment could be effectively solved using Noisy Bagging duelling double deep Q network achieving efficiency of 97.7% by maximizing reward with significant exploration in given simulated environment for resource allocation.
Supersense and Sensibility: Proxy Tasks for Semantic Annotation of Prepositions
Mar 27, 2021Prepositional supersense annotation is time-consuming and requires expert training. Here, we present two sensible methods for obtaining prepositional supersense annotations by eliciting surface substitution and similarity judgments. Four pilot studies suggest that both methods have potential for producing prepositional supersense annotations that are comparable in quality to expert annotations.
A Lyapunov-Based Methodology for Constrained Optimization with Bandit Feedback
Jun 09, 2021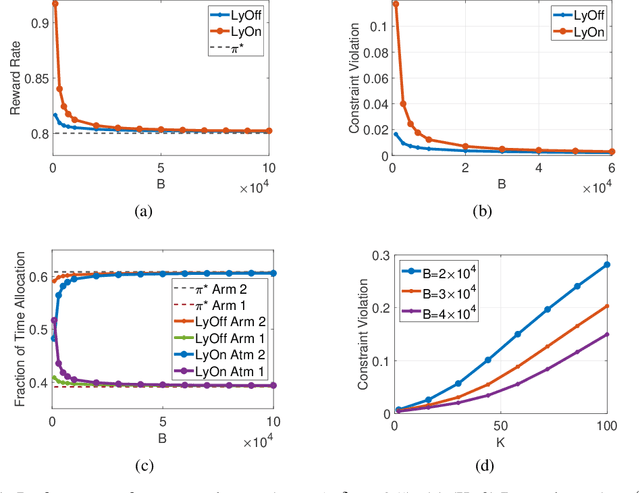
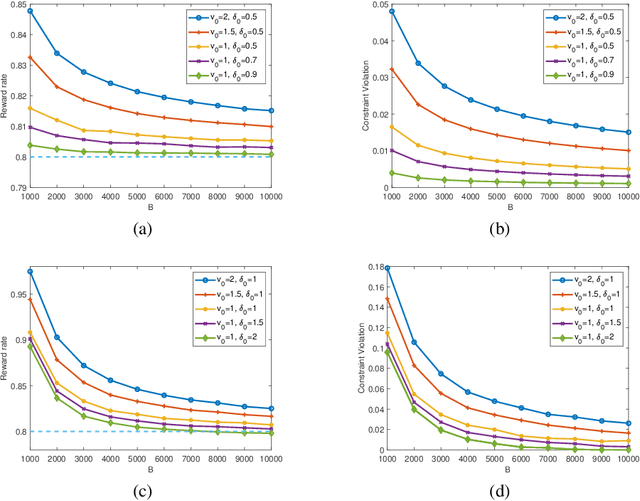
In a wide variety of applications including online advertising, contractual hiring, and wireless scheduling, the controller is constrained by a stringent budget constraint on the available resources, which are consumed in a random amount by each action, and a stochastic feasibility constraint that may impose important operational limitations on decision-making. In this work, we consider a general model to address such problems, where each action returns a random reward, cost, and penalty from an unknown joint distribution, and the decision-maker aims to maximize the total reward under a budget constraint $B$ on the total cost and a stochastic constraint on the time-average penalty. We propose a novel low-complexity algorithm based on Lyapunov optimization methodology, named ${\tt LyOn}$, and prove that it achieves $O(\sqrt{B\log B})$ regret and $O(\log B/B)$ constraint-violation. The low computational cost and sharp performance bounds of ${\tt LyOn}$ suggest that Lyapunov-based algorithm design methodology can be effective in solving constrained bandit optimization problems.
A multi-stage GAN for multi-organ chest X-ray image generation and segmentation
Jun 09, 2021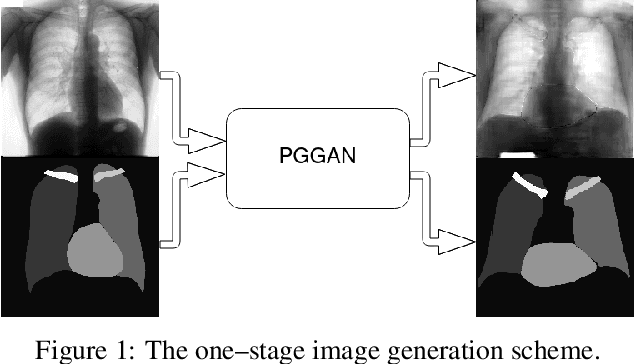
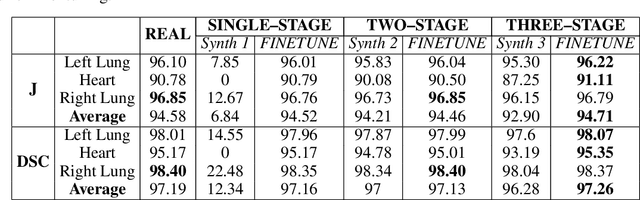
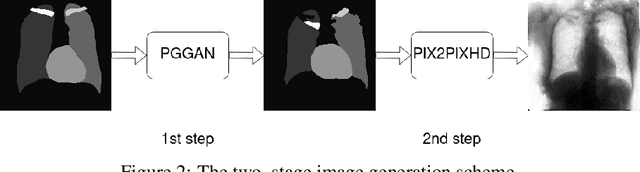
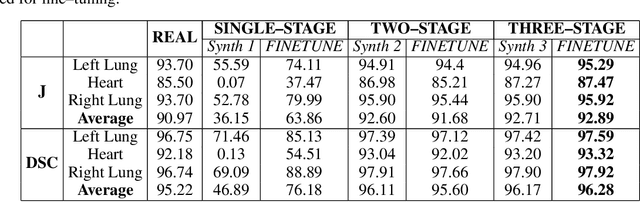
Multi-organ segmentation of X-ray images is of fundamental importance for computer aided diagnosis systems. However, the most advanced semantic segmentation methods rely on deep learning and require a huge amount of labeled images, which are rarely available due to both the high cost of human resources and the time required for labeling. In this paper, we present a novel multi-stage generation algorithm based on Generative Adversarial Networks (GANs) that can produce synthetic images along with their semantic labels and can be used for data augmentation. The main feature of the method is that, unlike other approaches, generation occurs in several stages, which simplifies the procedure and allows it to be used on very small datasets. The method has been evaluated on the segmentation of chest radiographic images, showing promising results. The multistage approach achieves state-of-the-art and, when very few images are used to train the GANs, outperforms the corresponding single-stage approach.
HERALD: An Annotation Efficient Method to Detect User Disengagement in Social Conversations
Jun 01, 2021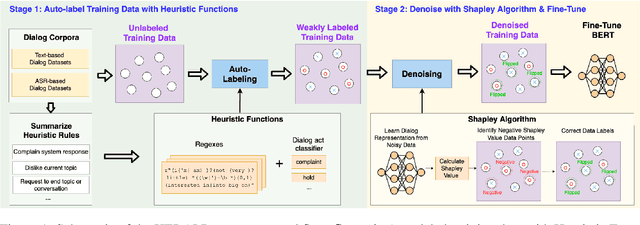
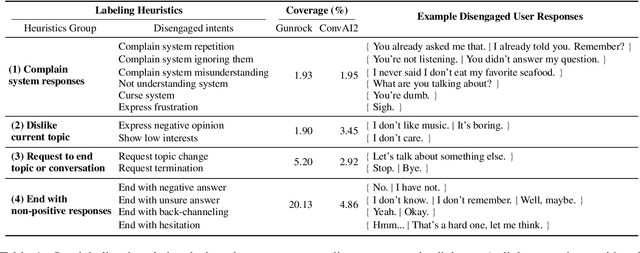
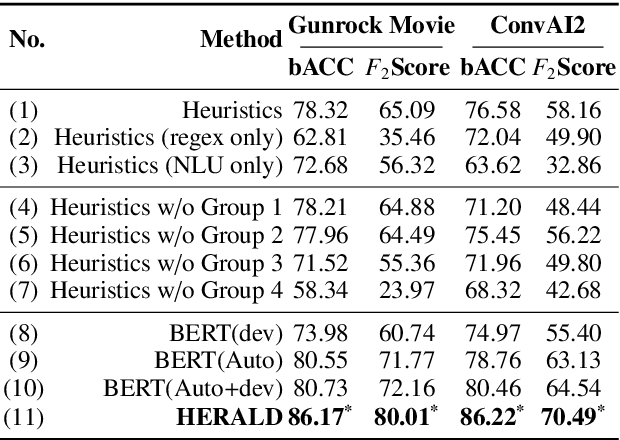
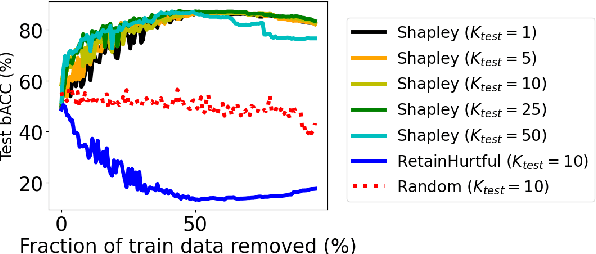
Open-domain dialog systems have a user-centric goal: to provide humans with an engaging conversation experience. User engagement is one of the most important metrics for evaluating open-domain dialog systems, and could also be used as real-time feedback to benefit dialog policy learning. Existing work on detecting user disengagement typically requires hand-labeling many dialog samples. We propose HERALD, an annotation efficient framework that reframes the training data annotation process as a denoising problem. Specifically, instead of manual labeling training samples, we first use a set of labeling heuristics to automatically label training samples. We then denoise the weakly labeled data using Shapley algorithm. Finally, we use the denoised data to train a user engagement detector. Our experiments show that HERALD improves annotation efficiency significantly and achieves 86% user disengagement detection accuracy in two dialog corpora.
H-TD2: Hybrid Temporal Difference Learning for Adaptive Urban Taxi Dispatch
May 05, 2021
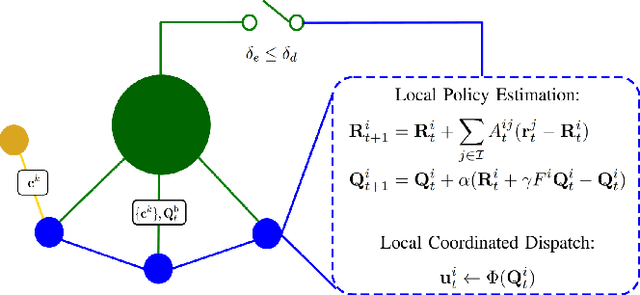
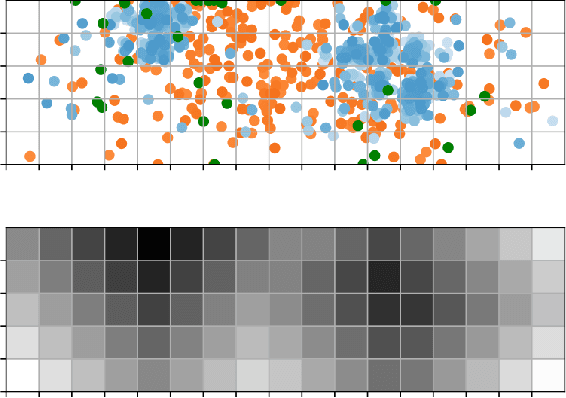
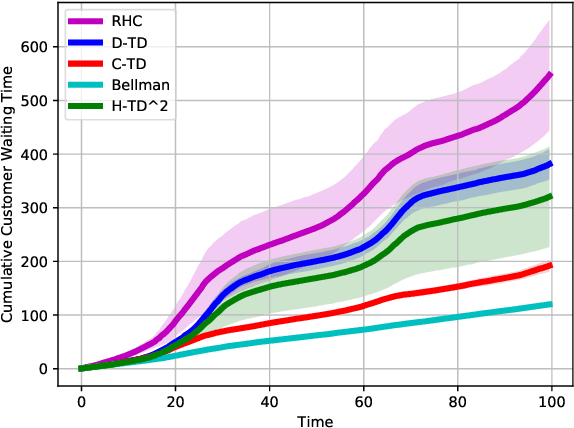
We present H-TD2: Hybrid Temporal Difference Learning for Taxi Dispatch, a model-free, adaptive decision-making algorithm to coordinate a large fleet of automated taxis in a dynamic urban environment to minimize expected customer waiting times. Our scalable algorithm exploits the natural transportation network company topology by switching between two behaviors: distributed temporal-difference learning computed locally at each taxi and infrequent centralized Bellman updates computed at the dispatch center. We derive a regret bound and design the trigger condition between the two behaviors to explicitly control the trade-off between computational complexity and the individual taxi policy's bounded sub-optimality; this advances the state of the art by enabling distributed operation with bounded-suboptimality. Additionally, unlike recent reinforcement learning dispatch methods, this policy estimation is adaptive and robust to out-of-training domain events. This result is enabled by a two-step modelling approach: the policy is learned on an agent-agnostic, cell-based Markov Decision Process and individual taxis are coordinated using the learned policy in a distributed game-theoretic task assignment. We validate our algorithm against a receding horizon control baseline in a Gridworld environment with a simulated customer dataset, where the proposed solution decreases average customer waiting time by 50% over a wide range of parameters. We also validate in a Chicago city environment with real customer requests from the Chicago taxi public dataset where the proposed solution decreases average customer waiting time by 26% over irregular customer distributions during a 2016 Major League Baseball World Series game.