 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RSN: Range Sparse Net for Efficient, Accurate LiDAR 3D Object Detection
Jun 25, 2021
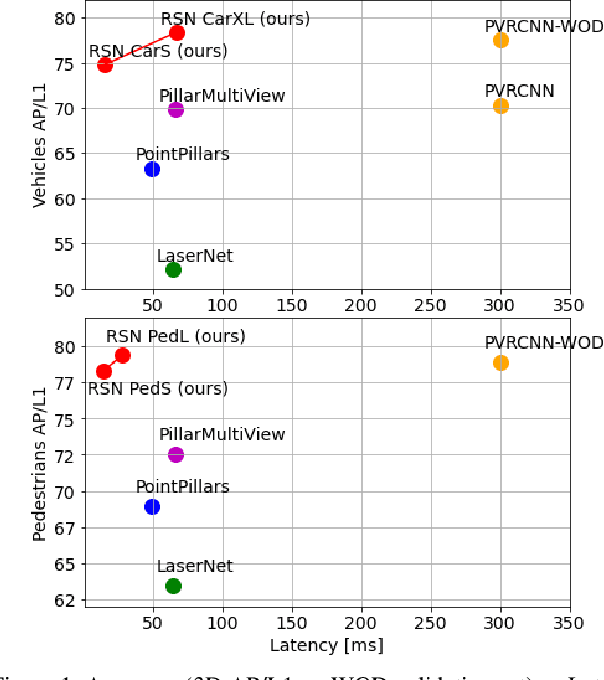
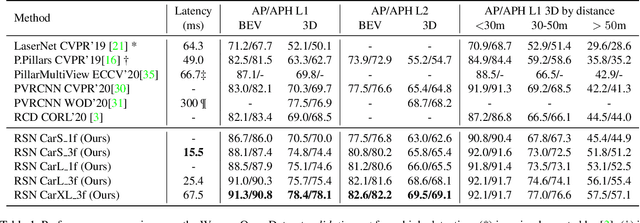
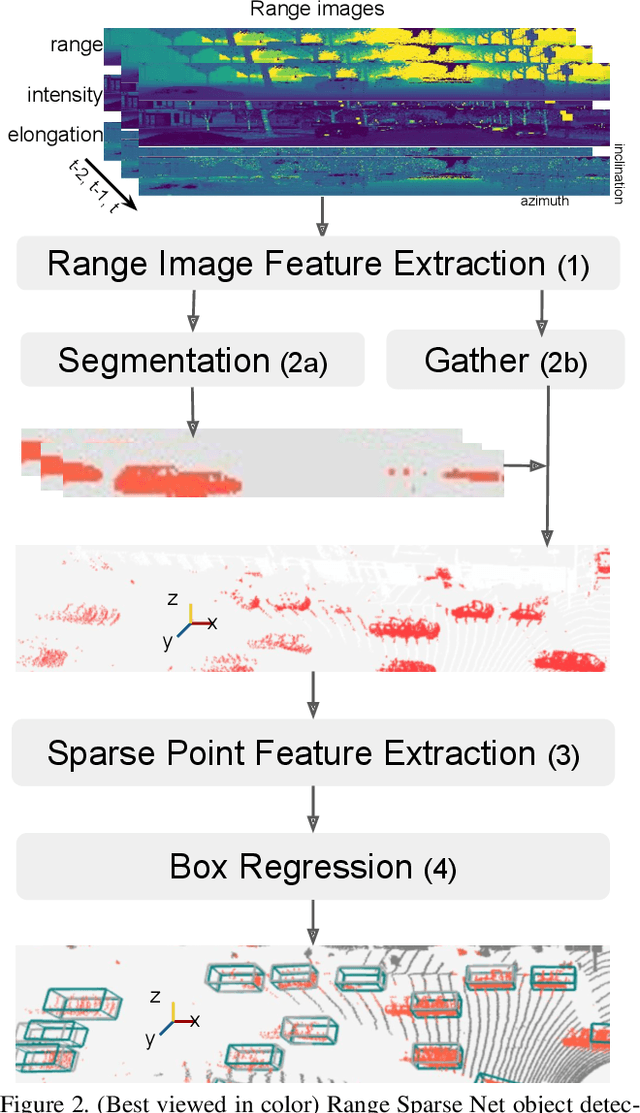
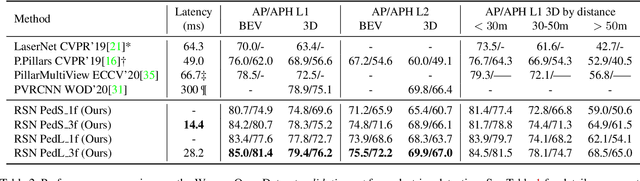
The detection of 3D objects from LiDAR data is a critical component in most autonomous driving systems. Safe, high speed driving needs larger detection ranges, which are enabled by new LiDARs. These larger detection ranges require more efficient and accurate detection models. Towards this goal, we propose Range Sparse Net (RSN), a simple, efficient, and accurate 3D object detector in order to tackle real time 3D object detection in this extended detection regime. RSN predicts foreground points from range images and applies sparse convolutions on the selected foreground points to detect objects. The lightweight 2D convolutions on dense range images results in significantly fewer selected foreground points, thus enabling the later sparse convolutions in RSN to efficiently operate. Combining features from the range image further enhance detection accuracy. RSN runs at more than 60 frames per second on a 150m x 150m detection region on Waymo Open Dataset (WOD) while being more accurate than previously published detectors. As of 11/2020, RSN is ranked first in the WOD leaderboard based on the APH/LEVEL 1 metrics for LiDAR-based pedestrian and vehicle detection, while being several times faster than alternatives.
Experimental Exploration of Compact Convolutional Neural Network Architectures for Non-temporal Real-time Fire Detection
Nov 20, 2019
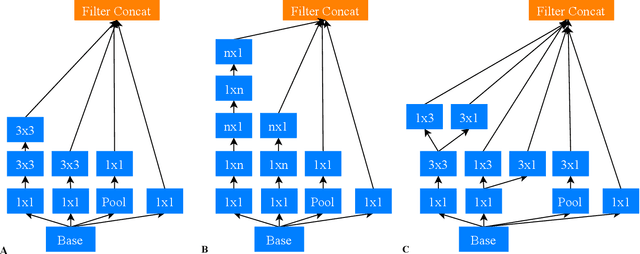
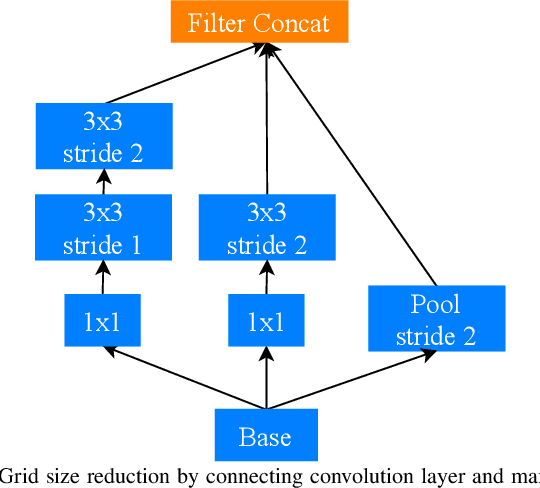
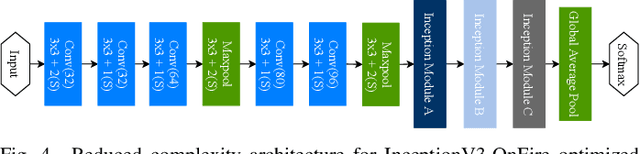
In this work we explore different Convolutional Neural Network (CNN) architectures and their variants for non-temporal binary fire detection and localization in video or still imagery. We consider the performance of experimentally defined, reduced complexity deep CNN architectures for this task and evaluate the effects of different optimization and normalization techniques applied to different CNN architectures (spanning the Inception, ResNet and EfficientNet architectural concepts). Contrary to contemporary trends in the field, our work illustrates a maximum overall accuracy of 0.96 for full frame binary fire detection and 0.94 for superpixel localization using an experimentally defined reduced CNN architecture based on the concept of InceptionV4. We notably achieve a lower false positive rate of 0.06 compared to prior work in the field presenting an efficient, robust and real-time solution for fire region detection.
Data-Driven Shadowgraph Simulation of a 3D Object
Jun 01, 2021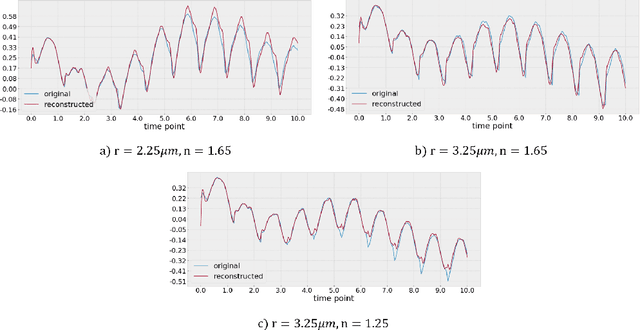
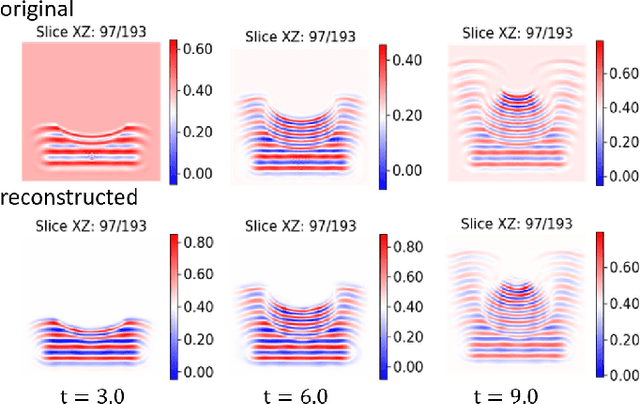
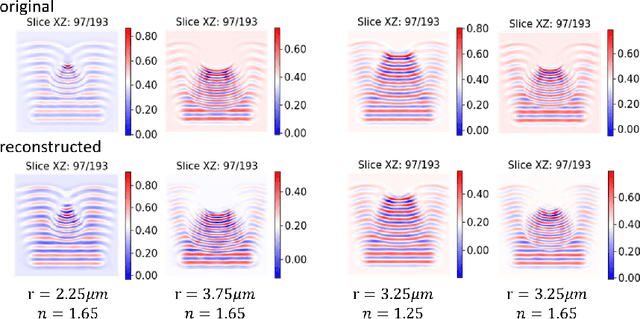
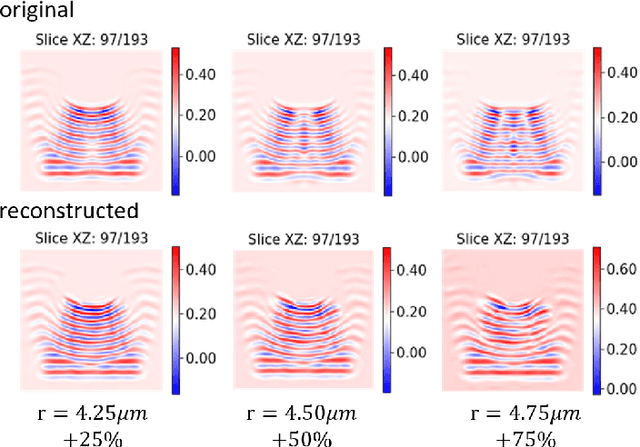
In this work we propose a deep neural network based surrogate model for a plasma shadowgraph - a technique for visualization of perturbations in a transparent medium. We are substituting the numerical code by a computationally cheaper projection based surrogate model that is able to approximate the electric fields at a given time without computing all preceding electric fields as required by numerical methods. This means that the projection based surrogate model allows to recover the solution of the governing 3D partial differential equation, 3D wave equation, at any point of a given compute domain and configuration without the need to run a full simulation. This model has shown a good quality of reconstruction in a problem of interpolation of data within a narrow range of simulation parameters and can be used for input data of large size.
Proximally Optimal Predictive Control Algorithm for Path Tracking of Self-Driving Cars
Mar 24, 2021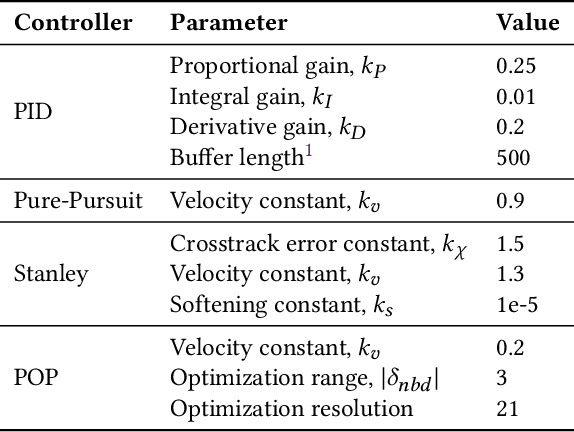
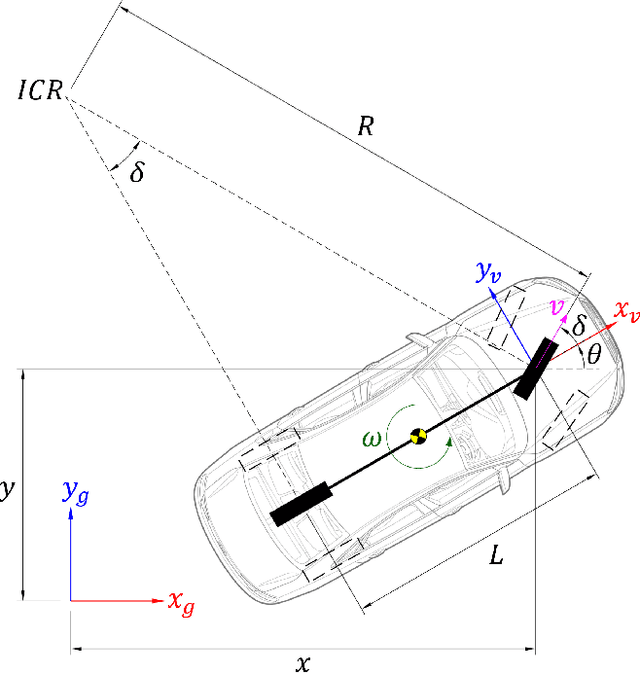

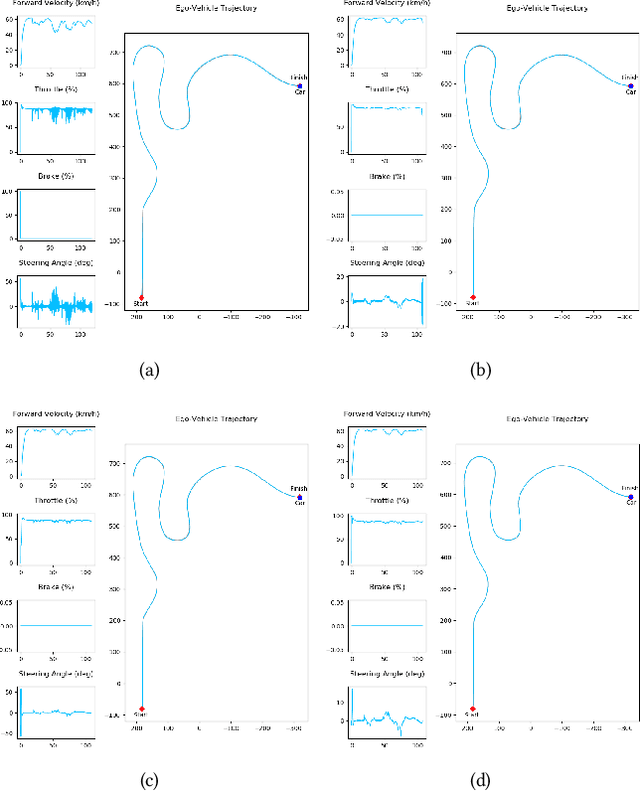
This work presents proximally optimal predictive control algorithm, which is essentially a model-based lateral controller for steered autonomous vehicles that selects an optimal steering command within the neighborhood of previous steering angle based on the predicted vehicle location. The proposed algorithm was formulated with an aim of overcoming the limitations associated with the existing control laws for autonomous steering - namely PID, Pure-Pursuit and Stanley controllers. Particularly, our approach was aimed at bridging the gap between tracking efficiency and computational cost, thereby ensuring effective path tracking in real-time. The effectiveness of our approach was investigated through a series of dynamic simulation experiments pertaining to autonomous path tracking, employing an adaptive control law for longitudinal motion control of the vehicle. We measured the latency of the proposed algorithm in order to comment on its real-time factor and validated our approach by comparing it against the established control laws in terms of both crosstrack and heading errors recorded throughout the respective path tracking simulations.
Overparameterization of deep ResNet: zero loss and mean-field analysis
Jun 17, 2021Finding parameters in a deep neural network (NN) that fit training data is a nonconvex optimization problem, but a basic first-order optimization method (gradient descent) finds a global solution with perfect fit in many practical situations. We examine this phenomenon for the case of Residual Neural Networks (ResNet) with smooth activation functions in a limiting regime in which both the number of layers (depth) and the number of neurons in each layer (width) go to infinity. First, we use a mean-field-limit argument to prove that the gradient descent for parameter training becomes a partial differential equation (PDE) that characterizes gradient flow for a probability distribution in the large-NN limit. Next, we show that the solution to the PDE converges in the training time to a zero-loss solution. Together, these results imply that training of the ResNet also gives a near-zero loss if the Resnet is large enough. We give estimates of the depth and width needed to reduce the loss below a given threshold, with high probability.
A Case Study on Sampling Strategies for Evaluating Neural Sequential Item Recommendation Models
Jul 27, 2021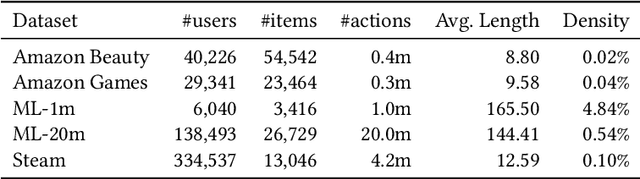
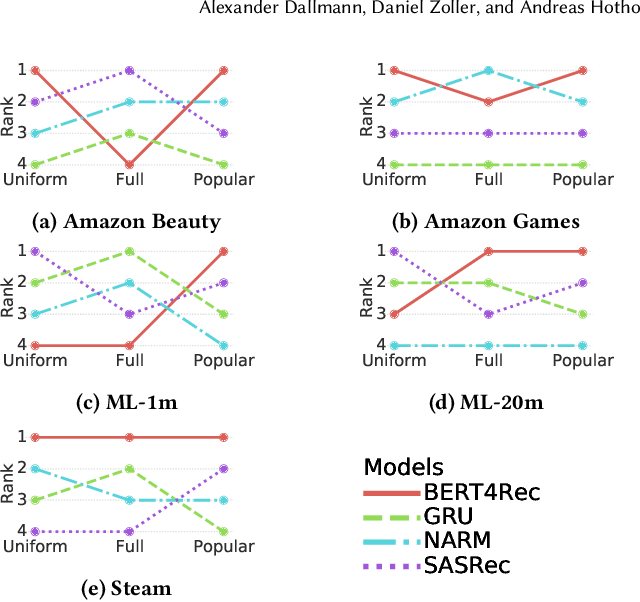
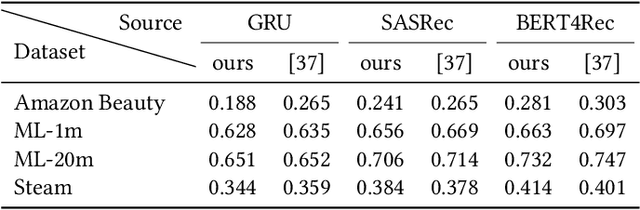
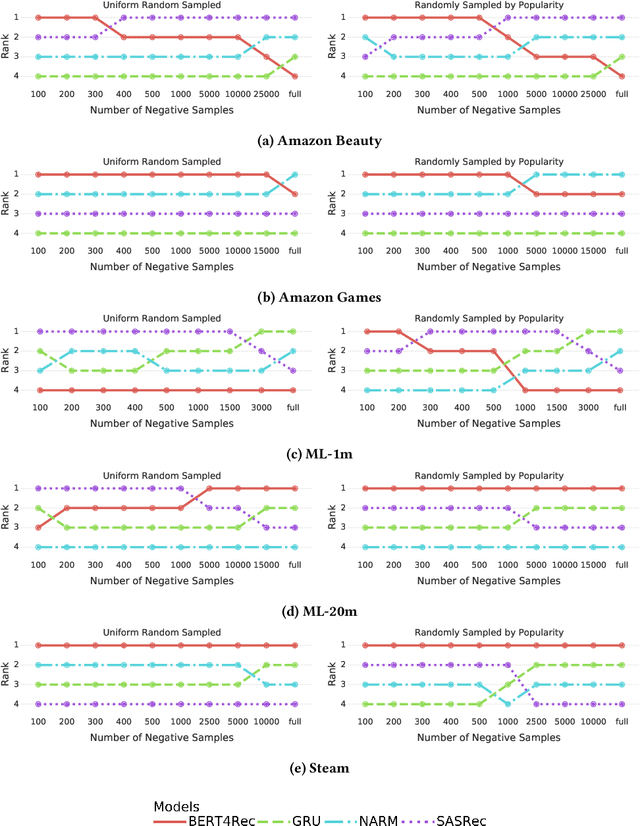
At the present time, sequential item recommendation models are compared by calculating metrics on a small item subset (target set) to speed up computation. The target set contains the relevant item and a set of negative items that are sampled from the full item set. Two well-known strategies to sample negative items are uniform random sampling and sampling by popularity to better approximate the item frequency distribution in the dataset. Most recently published papers on sequential item recommendation rely on sampling by popularity to compare the evaluated models. However, recent work has already shown that an evaluation with uniform random sampling may not be consistent with the full ranking, that is, the model ranking obtained by evaluating a metric using the full item set as target set, which raises the question whether the ranking obtained by sampling by popularity is equal to the full ranking. In this work, we re-evaluate current state-of-the-art sequential recommender models from the point of view, whether these sampling strategies have an impact on the final ranking of the models. We therefore train four recently proposed sequential recommendation models on five widely known datasets. For each dataset and model, we employ three evaluation strategies. First, we compute the full model ranking. Then we evaluate all models on a target set sampled by the two different sampling strategies, uniform random sampling and sampling by popularity with the commonly used target set size of 100, compute the model ranking for each strategy and compare them with each other. Additionally, we vary the size of the sampled target set. Overall, we find that both sampling strategies can produce inconsistent rankings compared with the full ranking of the models. Furthermore, both sampling by popularity and uniform random sampling do not consistently produce the same ranking ...
Automatic-differentiated Physics-Informed Echo State Network (API-ESN)
Dec 28, 2020

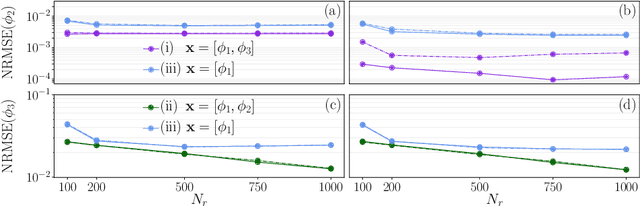
We propose the Automatic-differentiated Physics-Informed Echo State Network (API-ESN). The architecture constrains the knowledge of the physical equations through the reservoir's exact time derivative, which is computed by automatic differentiation. As compared to the original Physics-Informed Echo State Network, the accuracy of the time derivative is increased by up to seven orders of magnitude. This increased accuracy is key in chaotic dynamical systems, where errors grows exponentially in time. The architecture is showcased in the reconstruction of unmeasured (hidden) states of a chaotic system. The API-ESN eliminates a source of error, which is present in existing physics-informed echo state networks, in the computation of the time-derivative. This opens up new possibilities for an accurate reconstruction of chaotic dynamical states.
Tropical cyclone intensity estimations over the Indian ocean using Machine Learning
Jul 07, 2021
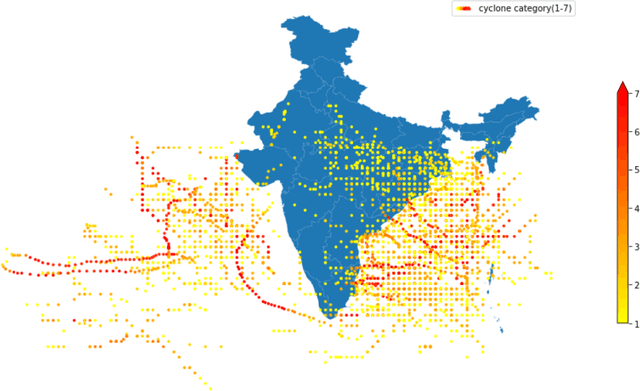
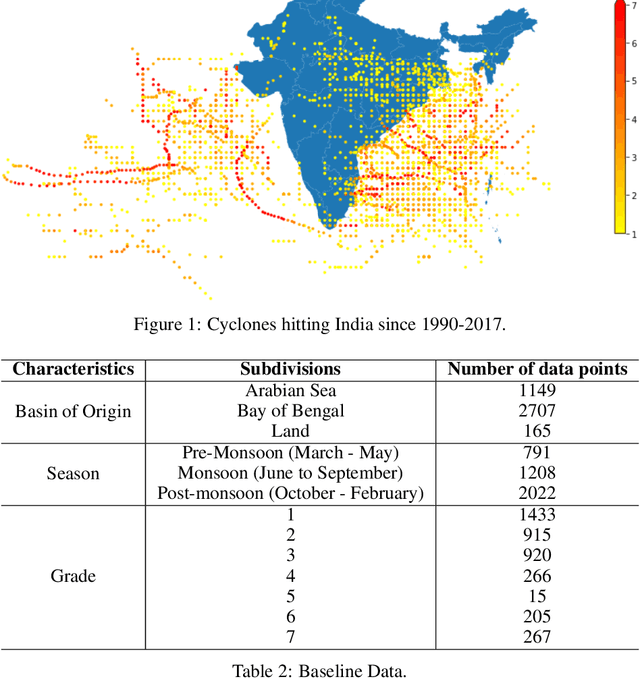
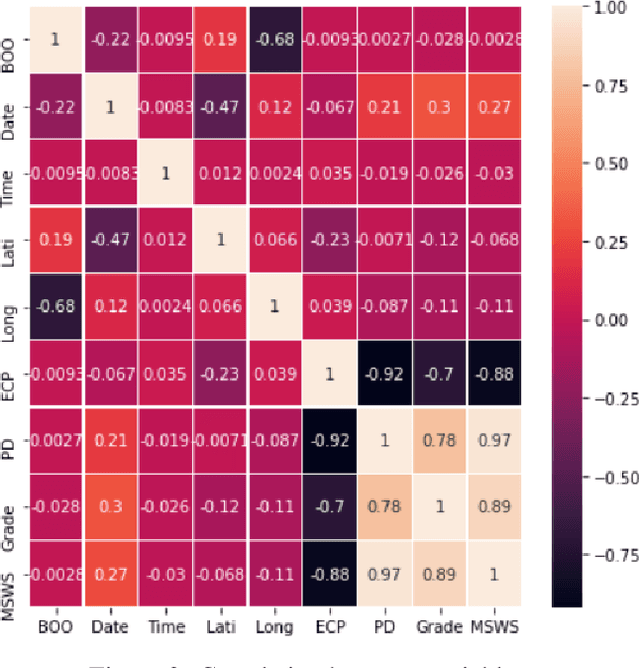
Tropical cyclones are one of the most powerful and destructive natural phenomena on earth. Tropical storms and heavy rains can cause floods, which lead to human lives and economic loss. Devastating winds accompanying cyclones heavily affect not only the coastal regions, even distant areas. Our study focuses on the intensity estimation, particularly cyclone grade and maximum sustained surface wind speed (MSWS) of a tropical cyclone over the North Indian Ocean. We use various machine learning algorithms to estimate cyclone grade and MSWS. We have used the basin of origin, date, time, latitude, longitude, estimated central pressure, and pressure drop as attributes of our models. We use multi-class classification models for the categorical outcome variable, cyclone grade, and regression models for MSWS as it is a continuous variable. Using the best track data of 28 years over the North Indian Ocean, we estimate grade with an accuracy of 88% and MSWS with a root mean square error (RMSE) of 2.3. For higher grade categories (5-7), accuracy improves to an average of 98.84%. We tested our model with two recent tropical cyclones in the North Indian Ocean, Vayu and Fani. For grade, we obtained an accuracy of 93.22% and 95.23% respectively, while for MSWS, we obtained RMSE of 2.2 and 3.4 and $R^2$ of 0.99 and 0.99, respectively.
StreamBrain: An HPC Framework for Brain-like Neural Networks on CPUs, GPUs and FPGAs
Jun 09, 2021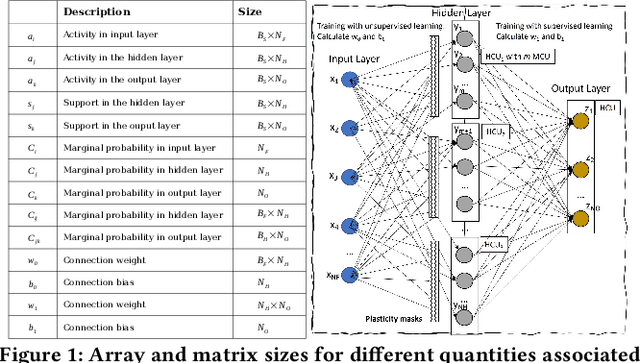
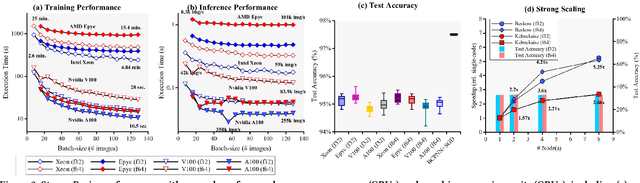
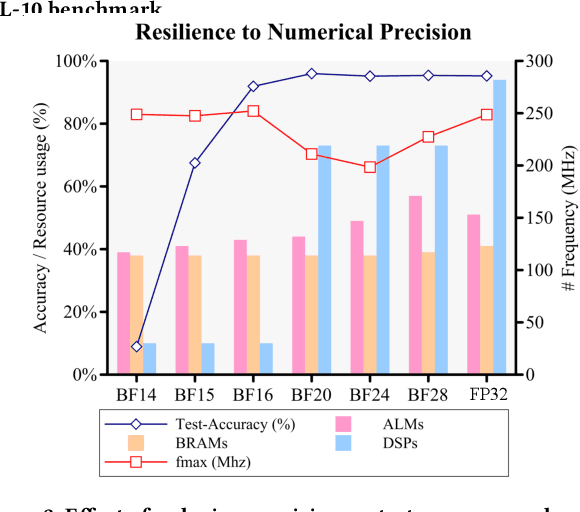
The modern deep learning method based on backpropagation has surged in popularity and has been used in multiple domains and application areas. At the same time, there are other -- less-known -- machine learning algorithms with a mature and solid theoretical foundation whose performance remains unexplored. One such example is the brain-like Bayesian Confidence Propagation Neural Network (BCPNN). In this paper, we introduce StreamBrain -- a framework that allows neural networks based on BCPNN to be practically deployed in High-Performance Computing systems. StreamBrain is a domain-specific language (DSL), similar in concept to existing machine learning (ML) frameworks, and supports backends for CPUs, GPUs, and even FPGAs. We empirically demonstrate that StreamBrain can train the well-known ML benchmark dataset MNIST within seconds, and we are the first to demonstrate BCPNN on STL-10 size networks. We also show how StreamBrain can be used to train with custom floating-point formats and illustrate the impact of using different bfloat variations on BCPNN using FPGAs.
UAV Communications with WPT-aided Cell-Free Massive MIMO Systems
Apr 23, 2021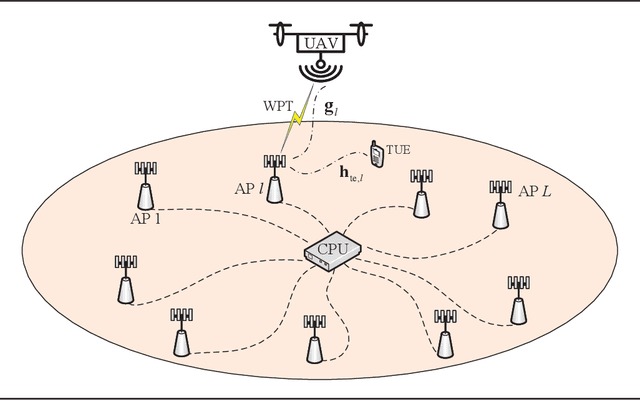
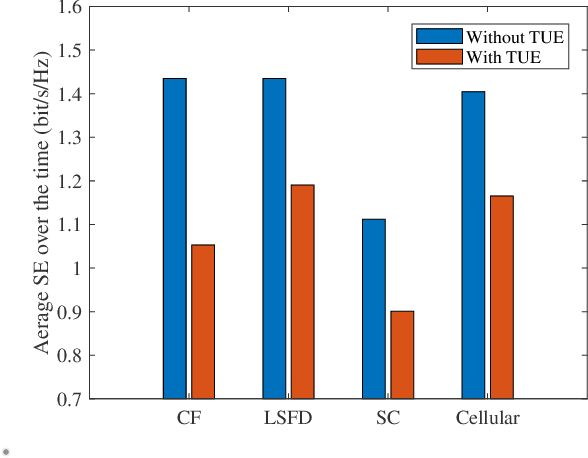
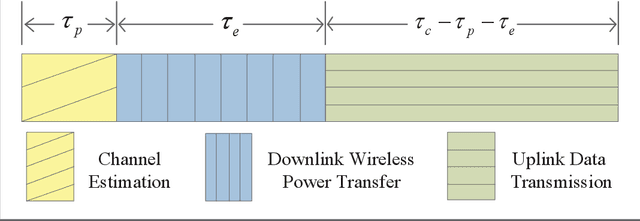
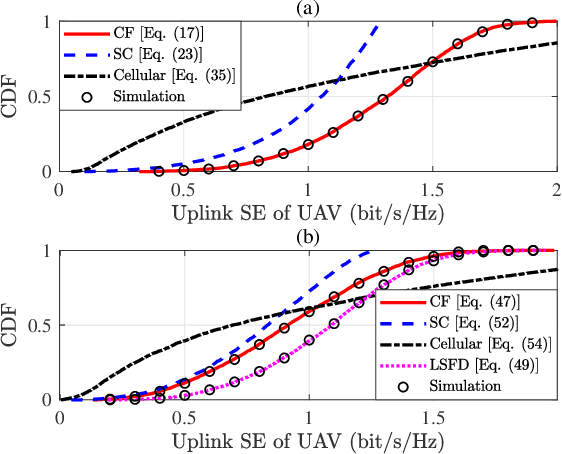
Cell-free (CF) massive multiple-input multiple-output (MIMO) is a promising solution to provide uniform good performance for unmanned aerial vehicle (UAV) communications. In this paper, we propose the UAV communication with wireless power transfer (WPT) aided CF massive MIMO systems, where the harvested energy (HE) from the downlink WPT is used to support both uplink data and pilot transmission. We derive novel closed-form downlink HE and uplink spectral efficiency (SE) expressions that take hardware impairments of UAV into account. UAV communications with current small cell (SC) and cellular massive MIMO enabled WPT systems are also considered for comparison. It is significant to show that CF massive MIMO achieves two and five times higher 95\%-likely uplink SE than the ones of SC and cellular massive MIMO, respectively. Besides, the large-scale fading decoding receiver cooperation can reduce the interference of the terrestrial user. Moreover, the maximum SE can be achieved by changing the time-splitting fraction. We prove that the optimal time-splitting fraction for maximum SE is determined by the number of antennas, altitude and hardware quality factor of UAVs. Furthermore, we propose three UAV trajectory design schemes to improve the SE. It is interesting that the angle search scheme performs best than both AP search and line path schemes. Finally, simulation results are presented to validate the accuracy of our expressions.