 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Domain Transformer: Predicting Samples of Unseen, Future Domains
Jun 10, 2021
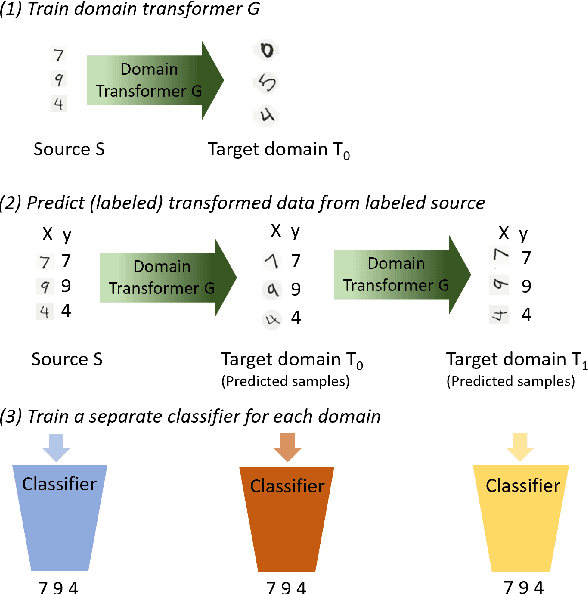
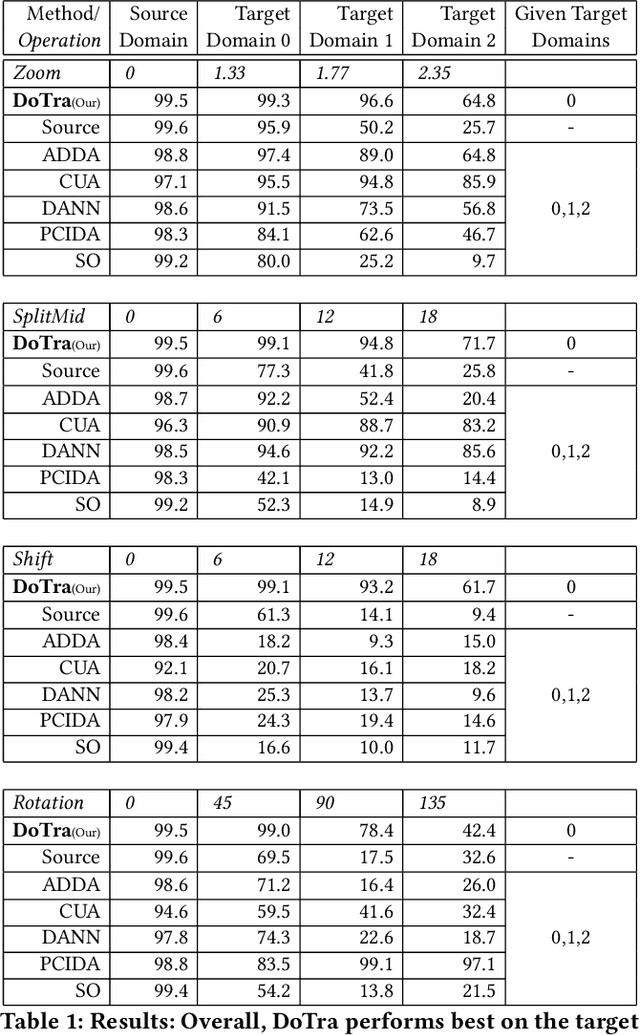
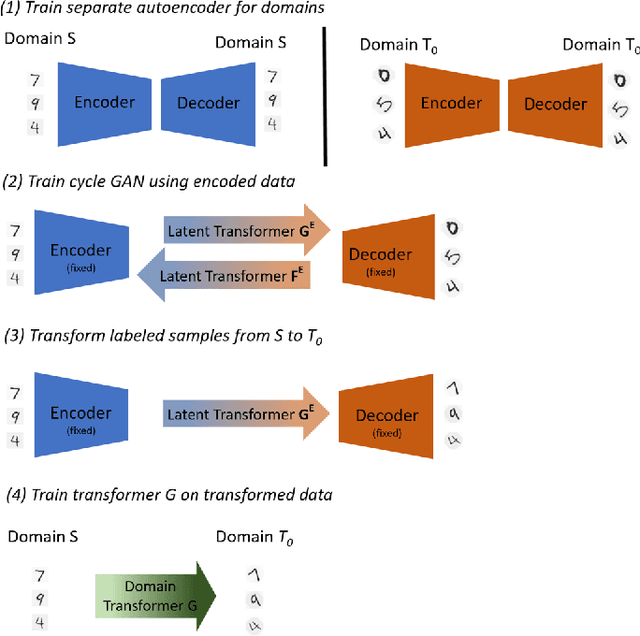

The data distribution commonly evolves over time leading to problems such as concept drift that often decrease classifier performance. We seek to predict unseen data (and their labels) allowing us to tackle challenges due to a non-constant data distribution in a \emph{proactive} manner rather than detecting and reacting to already existing changes that might already have led to errors. To this end, we learn a domain transformer in an unsupervised manner that allows generating data of unseen domains. Our approach first matches independently learned latent representations of two given domains obtained from an auto-encoder using a Cycle-GAN. In turn, a transformation of the original samples can be learned that can be applied iteratively to extrapolate to unseen domains. Our evaluation on CNNs on image data confirms the usefulness of the approach. It also achieves very good results on the well-known problem of unsupervised domain adaption, where labels but not samples have to be predicted.
Fast and Robust Online Inference with Stochastic Gradient Descent via Random Scaling
Jun 06, 2021
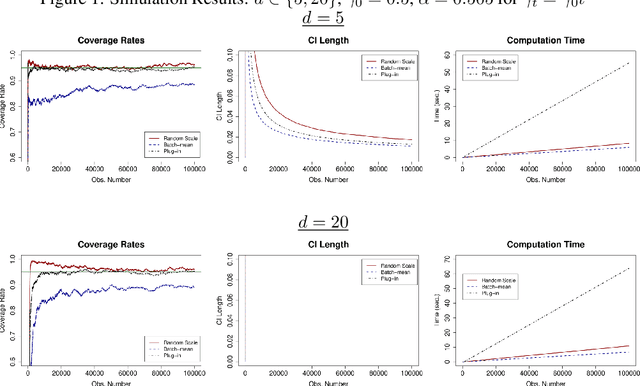
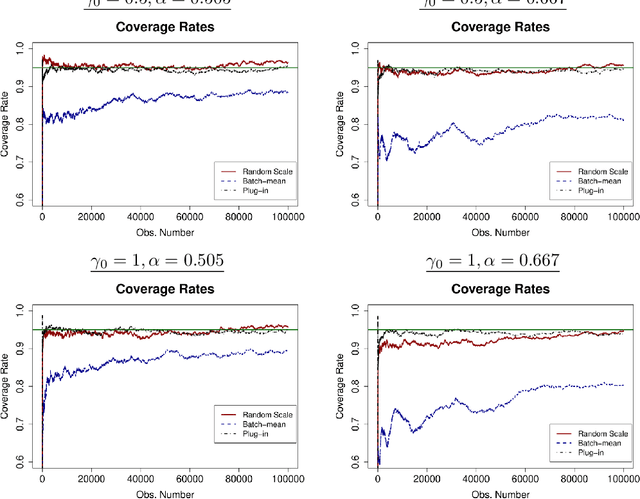
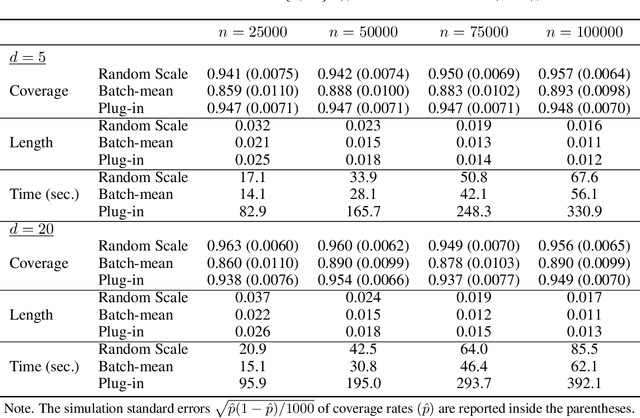
We develop a new method of online inference for a vector of parameters estimated by the Polyak-Ruppert averaging procedure of stochastic gradient descent (SGD) algorithms. We leverage insights from time series regression in econometrics and construct asymptotically pivotal statistics via random scaling. Our approach is fully operational with online data and is rigorously underpinned by a functional central limit theorem. Our proposed inference method has a couple of key advantages over the existing methods. First, the test statistic is computed in an online fashion with only SGD iterates and the critical values can be obtained without any resampling methods, thereby allowing for efficient implementation suitable for massive online data. Second, there is no need to estimate the asymptotic variance and our inference method is shown to be robust to changes in the tuning parameters for SGD algorithms in simulation experiments with synthetic data.
Energy Efficient Data Recovery from Corrupted LoRa Frames
Jul 19, 2021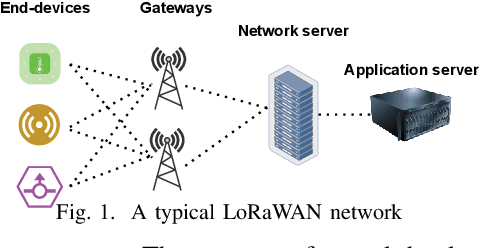
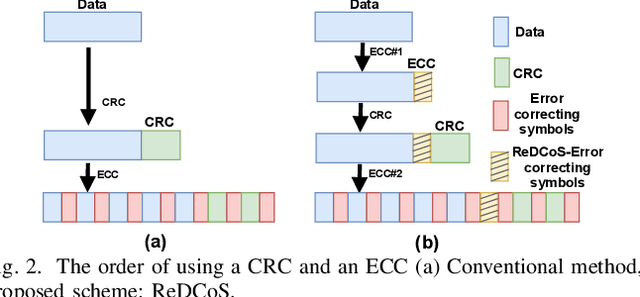
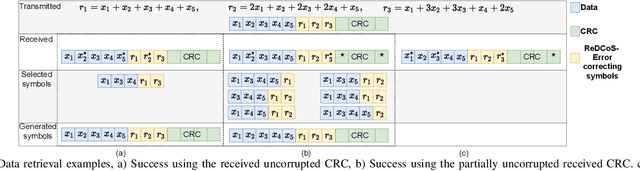
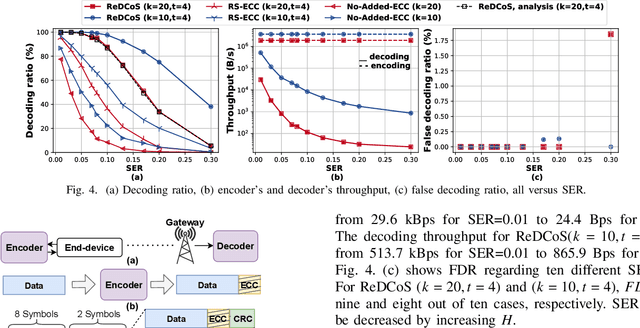
High frame-corruption is widely observed in Long Range Wide Area Networks (LoRaWAN) due to the coexistence with other networks in ISM bands and an Aloha-like MAC layer. LoRa's Forward Error Correction (FEC) mechanism is often insufficient to retrieve corrupted data. In fact, real-life measurements show that at least one-fourth of received transmissions are corrupted. When more frames are dropped, LoRa nodes usually switch over to higher spreading factors (SF), thus increasing transmission times and increasing the required energy. This paper introduces ReDCoS, a novel coding technique at the application layer that improves recovery of corrupted LoRa frames, thus reducing the overall transmission time and energy invested by LoRa nodes by several-fold. ReDCoS utilizes lightweight coding techniques to pre-encode the transmitted data. Therefore, the inbuilt Cyclic Redundancy Check (CRC) that follows is computed based on an already encoded data. At the receiver, we use both the CRC and the coded data to recover data from a corrupted frame beyond the built-in Error Correcting Code (ECC). We compare the performance of ReDCoS to (I) the standard FEC of vanilla-LoRaWAN, and to (ii) RS coding applied as ECC to the data of LoRaWAN. The results indicated a 54x and 13.5x improvement of decoding ratio, respectively, when 20 data symbols were sent. Furthermore, we evaluated ReDCoS on-field using LoRa SX1261 transceivers showing that it outperformed RS-coding by factor of at least 2x (and up to 6x) in terms of the decoding ratio while consuming 38.5% less energy per correctly received transmission.
Univariate Long-Term Municipal Water Demand Forecasting
May 18, 2021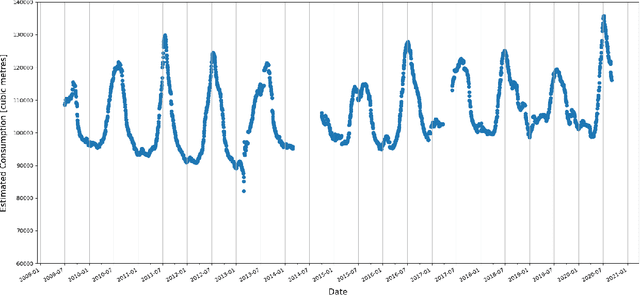
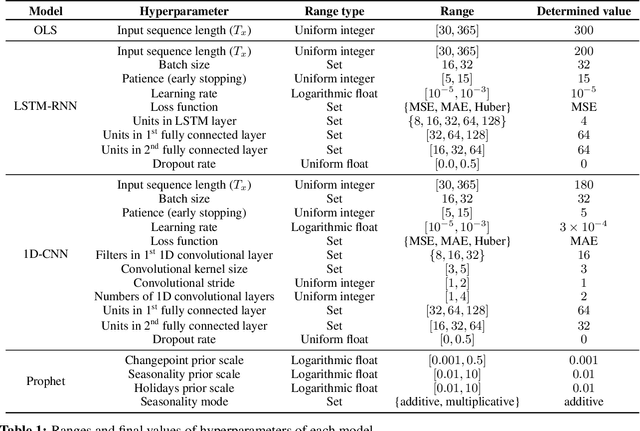
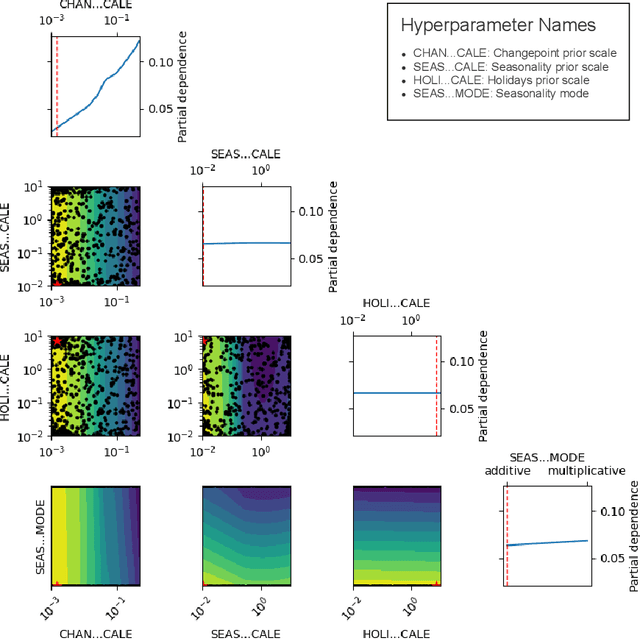
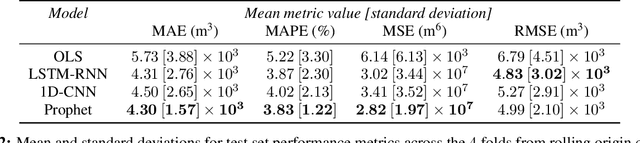
This study describes an investigation into the modelling of citywide water consumption in London, Canada. Multiple modelling techniques were evaluated for the task of univariate time series forecasting with water consumption, including linear regression, Facebook's Prophet method, recurrent neural networks, and convolutional neural networks. Prophet was identified as the model of choice, having achieved a mean absolute percentage error of 2.51%, averaged across a 5-fold cross validation. Prophet was also found to have other advantages deemed valuable to water demand management stakeholders, including inherent interpretability and graceful handling of missing data. The implementation for the methods described in this paper has been open sourced, as they may be adaptable by other municipalities.
Go with the Flows: Mixtures of Normalizing Flows for Point Cloud Generation and Reconstruction
Jun 06, 2021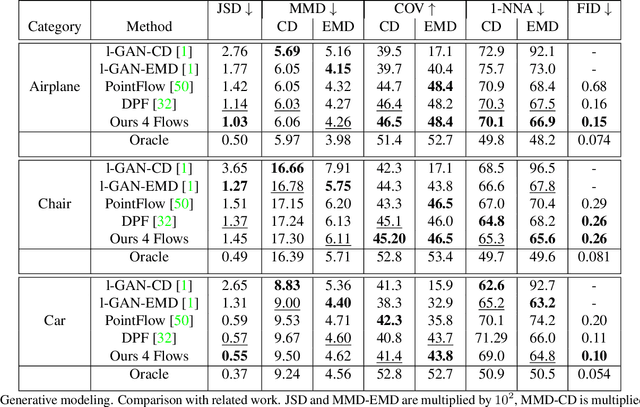
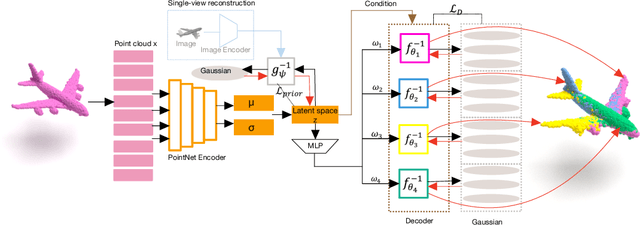
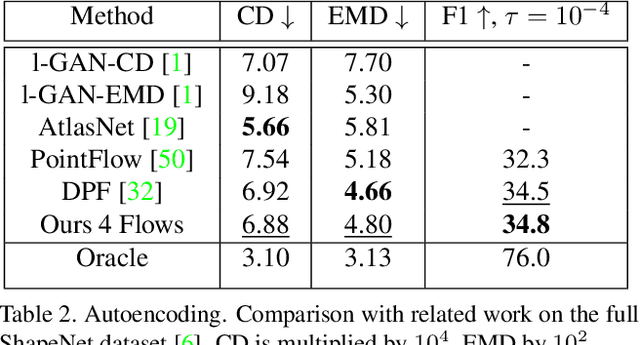
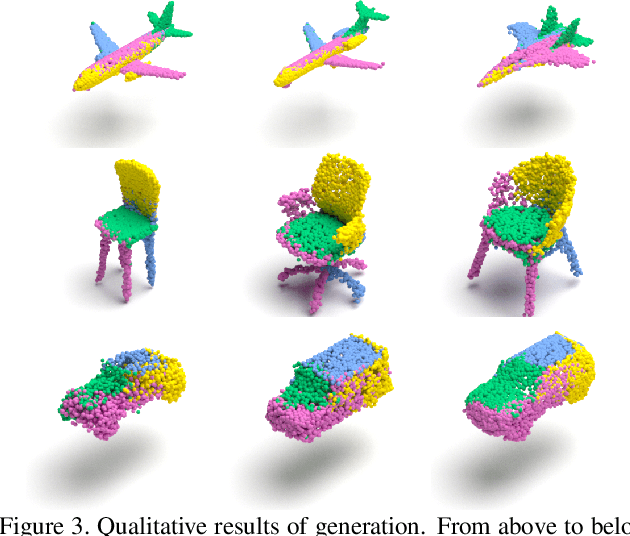
Recently normalizing flows (NFs) have demonstrated state-of-the-art performance on modeling 3D point clouds while allowing sampling with arbitrary resolution at inference time. However, these flow-based models still require long training times and large models for representing complicated geometries. This work enhances their representational power by applying mixtures of NFs to point clouds. We show that in this more general framework each component learns to specialize in a particular subregion of an object in a completely unsupervised fashion. By instantiating each mixture component with a comparatively small NF we generate point clouds with improved details compared to single-flow-based models while using fewer parameters and considerably reducing the inference runtime. We further demonstrate that by adding data augmentation, individual mixture components can learn to specialize in a semantically meaningful manner. We evaluate mixtures of NFs on generation, autoencoding and single-view reconstruction based on the ShapeNet dataset.
Automatic-differentiated Physics-Informed Echo State Network (API-ESN)
Dec 28, 2020

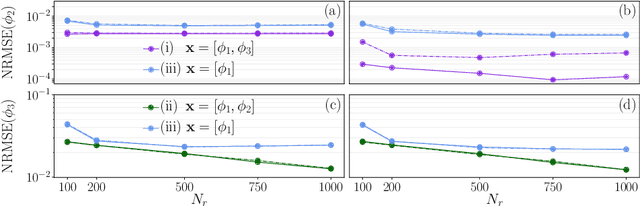
We propose the Automatic-differentiated Physics-Informed Echo State Network (API-ESN). The architecture constrains the knowledge of the physical equations through the reservoir's exact time derivative, which is computed by automatic differentiation. As compared to the original Physics-Informed Echo State Network, the accuracy of the time derivative is increased by up to seven orders of magnitude. This increased accuracy is key in chaotic dynamical systems, where errors grows exponentially in time. The architecture is showcased in the reconstruction of unmeasured (hidden) states of a chaotic system. The API-ESN eliminates a source of error, which is present in existing physics-informed echo state networks, in the computation of the time-derivative. This opens up new possibilities for an accurate reconstruction of chaotic dynamical states.
XCiT: Cross-Covariance Image Transformers
Jun 18, 2021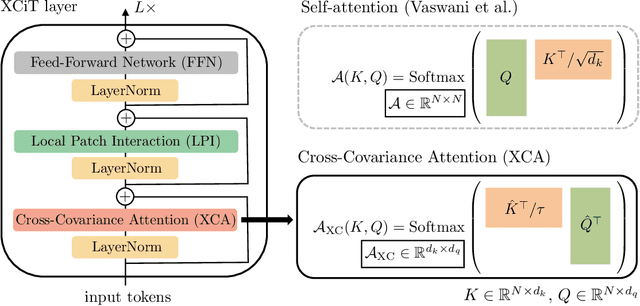
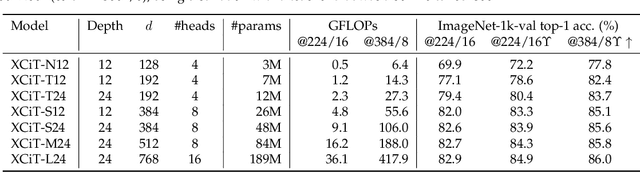
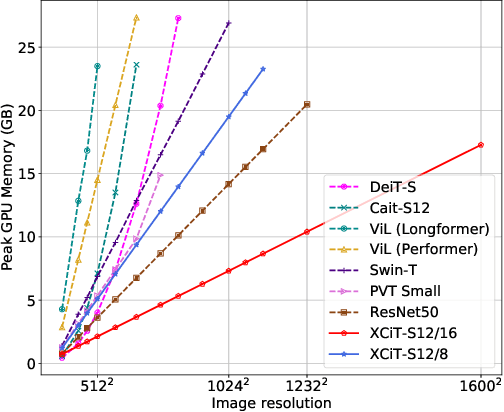
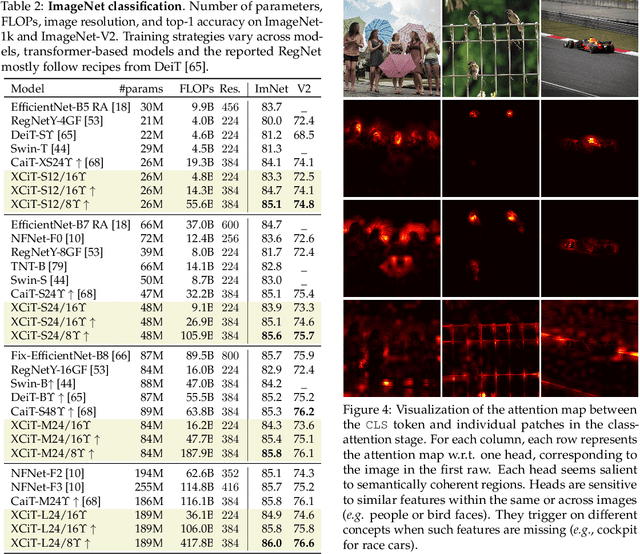
Following their success in natural language processing, transformers have recently shown much promise for computer vision. The self-attention operation underlying transformers yields global interactions between all tokens ,i.e. words or image patches, and enables flexible modelling of image data beyond the local interactions of convolutions. This flexibility, however, comes with a quadratic complexity in time and memory, hindering application to long sequences and high-resolution images. We propose a "transposed" version of self-attention that operates across feature channels rather than tokens, where the interactions are based on the cross-covariance matrix between keys and queries. The resulting cross-covariance attention (XCA) has linear complexity in the number of tokens, and allows efficient processing of high-resolution images. Our cross-covariance image transformer (XCiT) is built upon XCA. It combines the accuracy of conventional transformers with the scalability of convolutional architectures. We validate the effectiveness and generality of XCiT by reporting excellent results on multiple vision benchmarks, including image classification and self-supervised feature learning on ImageNet-1k, object detection and instance segmentation on COCO, and semantic segmentation on ADE20k.
Dynamics-Regulated Kinematic Policy for Egocentric Pose Estimation
Jun 10, 2021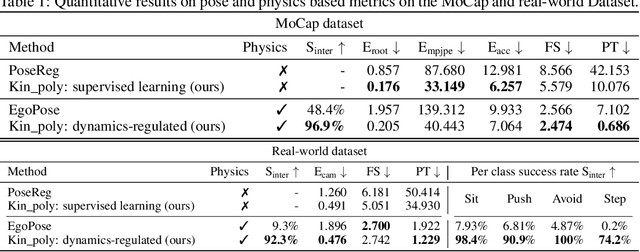
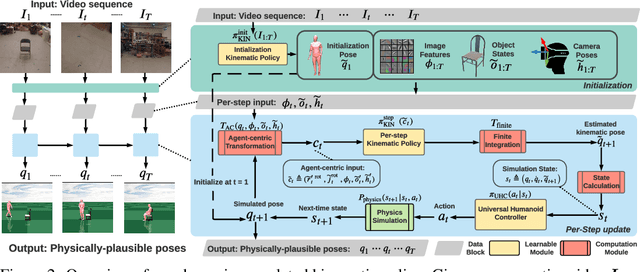
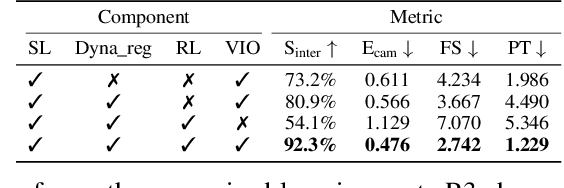
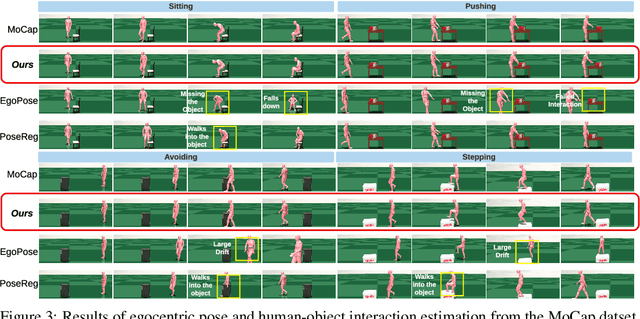
We propose a method for object-aware 3D egocentric pose estimation that tightly integrates kinematics modeling, dynamics modeling, and scene object information. Unlike prior kinematics or dynamics-based approaches where the two components are used disjointly, we synergize the two approaches via dynamics-regulated training. At each timestep, a kinematic model is used to provide a target pose using video evidence and simulation state. Then, a prelearned dynamics model attempts to mimic the kinematic pose in a physics simulator. By comparing the pose instructed by the kinematic model against the pose generated by the dynamics model, we can use their misalignment to further improve the kinematic model. By factoring in the 6DoF pose of objects (e.g., chairs, boxes) in the scene, we demonstrate for the first time, the ability to estimate physically-plausible 3D human-object interactions using a single wearable camera. We evaluate our egocentric pose estimation method in both controlled laboratory settings and real-world scenarios.
Interpretable Categorization of Heterogeneous Time Series Data
Jan 26, 2018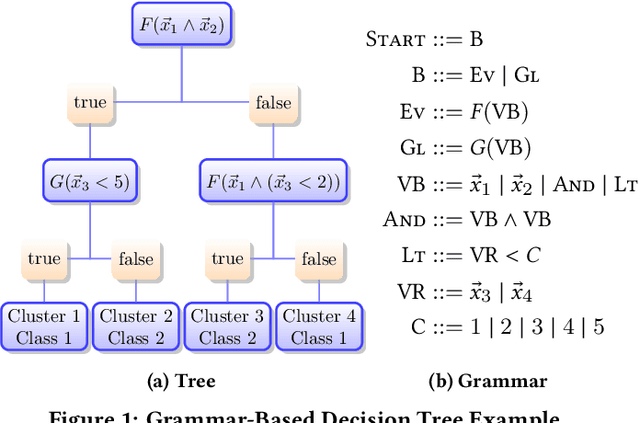
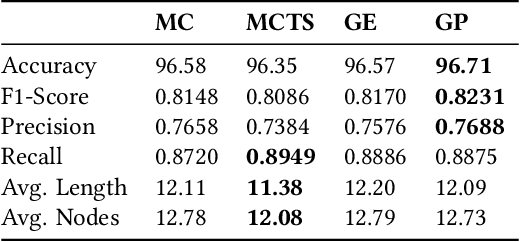
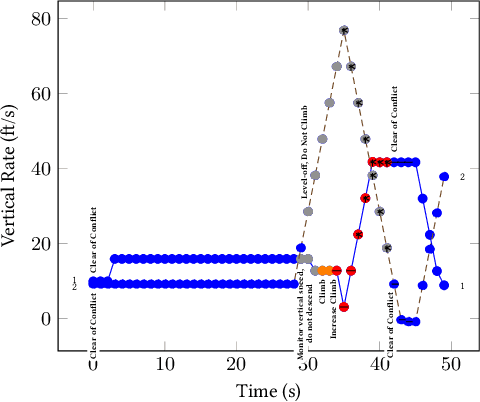
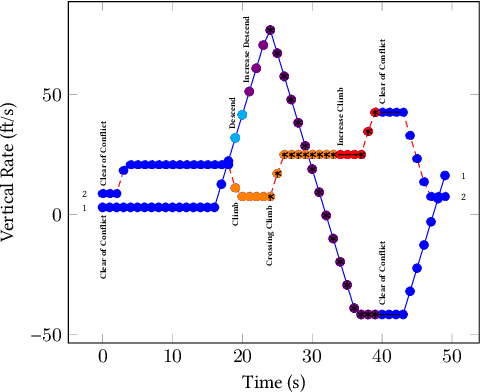
Understanding heterogeneous multivariate time series data is important in many applications ranging from smart homes to aviation. Learning models of heterogeneous multivariate time series that are also human-interpretable is challenging and not adequately addressed by the existing literature. We propose grammar-based decision trees (GBDTs) and an algorithm for learning them. GBDTs extend decision trees with a grammar framework. Logical expressions derived from a context-free grammar are used for branching in place of simple thresholds on attributes. The added expressivity enables support for a wide range of data types while retaining the interpretability of decision trees. In particular, when a grammar based on temporal logic is used, we show that GBDTs can be used for the interpretable classi cation of high-dimensional and heterogeneous time series data. Furthermore, we show how GBDTs can also be used for categorization, which is a combination of clustering and generating interpretable explanations for each cluster. We apply GBDTs to analyze the classic Australian Sign Language dataset as well as data on near mid-air collisions (NMACs). The NMAC data comes from aircraft simulations used in the development of the next-generation Airborne Collision Avoidance System (ACAS X).
GSVNet: Guided Spatially-Varying Convolution for Fast Semantic Segmentation on Video
Mar 16, 2021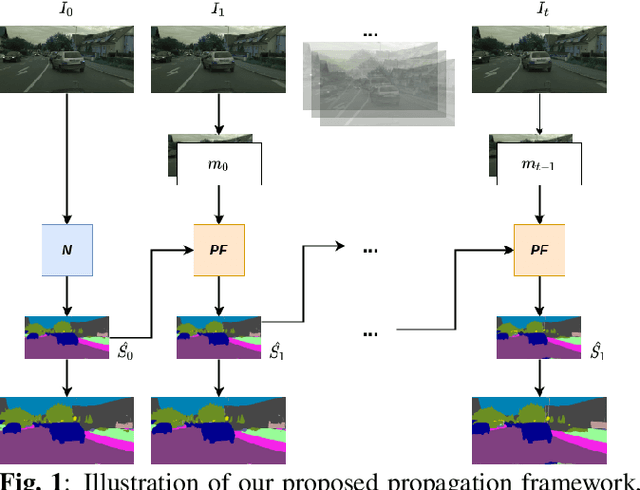
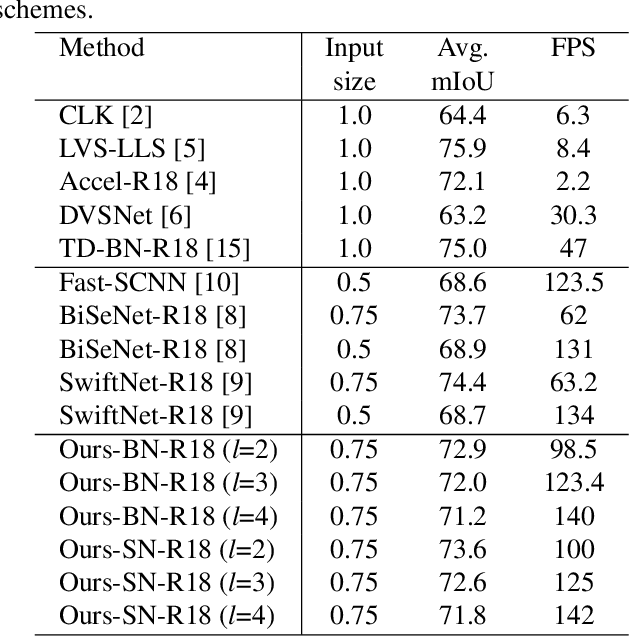
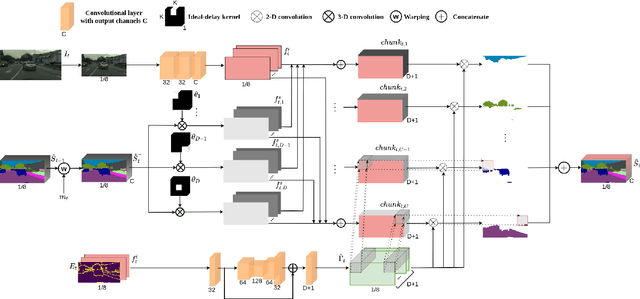
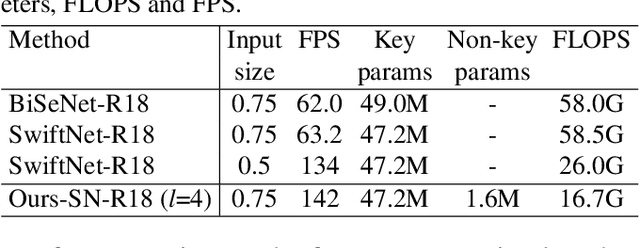
This paper addresses fast semantic segmentation on video.Video segmentation often calls for real-time, or even fasterthan real-time, processing. One common recipe for conserving computation arising from feature extraction is to propagate features of few selected keyframes. However, recent advances in fast image segmentation make these solutions less attractive. To leverage fast image segmentation for furthering video segmentation, we propose a simple yet efficient propagation framework. Specifically, we perform lightweight flow estimation in 1/8-downscaled image space for temporal warping in segmentation outpace space. Moreover, we introduce a guided spatially-varying convolution for fusing segmentations derived from the previous and current frames, to mitigate propagation error and enable lightweight feature extraction on non-keyframes. Experimental results on Cityscapes and CamVid show that our scheme achieves the state-of-the-art accuracy-throughput trade-off on video segmentation.