 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Constant-Time Machine Translation with Conditional Masked Language Models
Apr 19, 2019

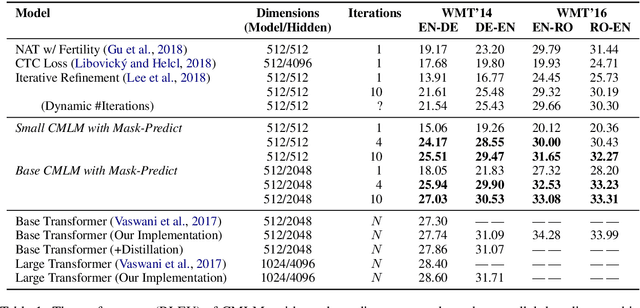
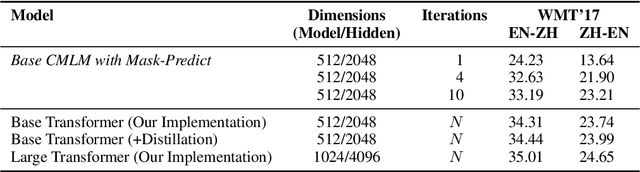
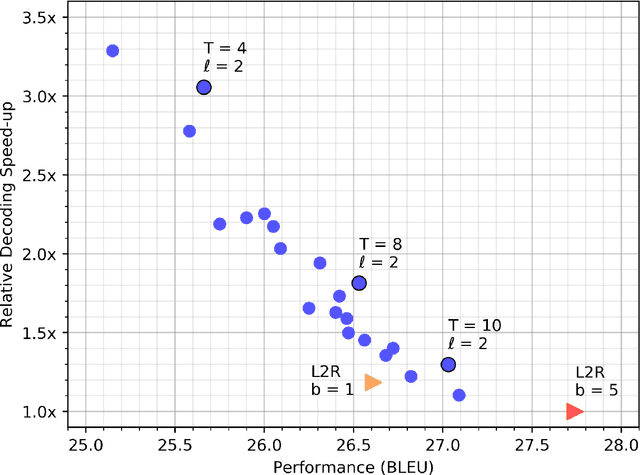
Most machine translation systems generate text autoregressively, by sequentially predicting tokens from left to right. We, instead, use a masked language modeling objective to train a model to predict any subset of the target words, conditioned on both the input text and a partially masked target translation. This approach allows for efficient iterative decoding, where we first predict all of the target words non-autoregressively, and then repeatedly mask out and regenerate the subset of words that the model is least confident about. By applying this strategy for a constant number of iterations, our model improves state-of-the-art performance levels for constant-time translation models by over 3 BLEU on average. It is also able to reach 92-95% of the performance of a typical left-to-right transformer model, while decoding significantly faster.
Boost-R: Gradient Boosted Trees for Recurrence Data
Jul 03, 2021
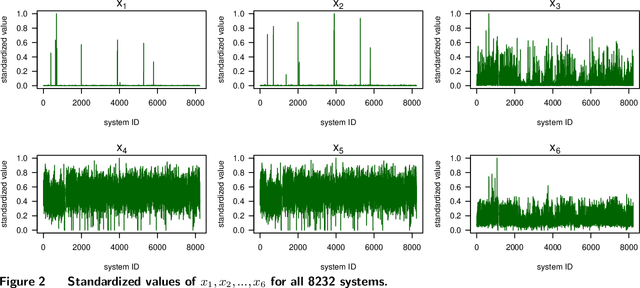
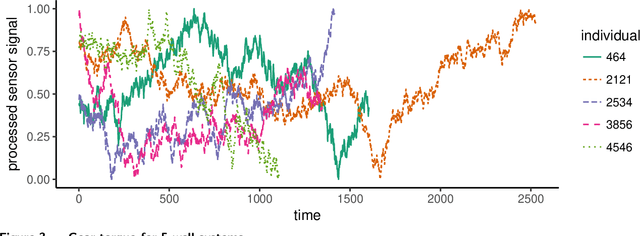
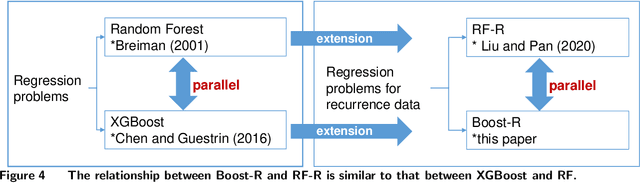
Recurrence data arise from multi-disciplinary domains spanning reliability, cyber security, healthcare, online retailing, etc. This paper investigates an additive-tree-based approach, known as Boost-R (Boosting for Recurrence Data), for recurrent event data with both static and dynamic features. Boost-R constructs an ensemble of gradient boosted additive trees to estimate the cumulative intensity function of the recurrent event process, where a new tree is added to the ensemble by minimizing the regularized L2 distance between the observed and predicted cumulative intensity. Unlike conventional regression trees, a time-dependent function is constructed by Boost-R on each tree leaf. The sum of these functions, from multiple trees, yields the ensemble estimator of the cumulative intensity. The divide-and-conquer nature of tree-based methods is appealing when hidden sub-populations exist within a heterogeneous population. The non-parametric nature of regression trees helps to avoid parametric assumptions on the complex interactions between event processes and features. Critical insights and advantages of Boost-R are investigated through comprehensive numerical examples. Datasets and computer code of Boost-R are made available on GitHub. To our best knowledge, Boost-R is the first gradient boosted additive-tree-based approach for modeling large-scale recurrent event data with both static and dynamic feature information.
Differentiable Adaptive Computation Time for Visual Reasoning
Apr 27, 2020
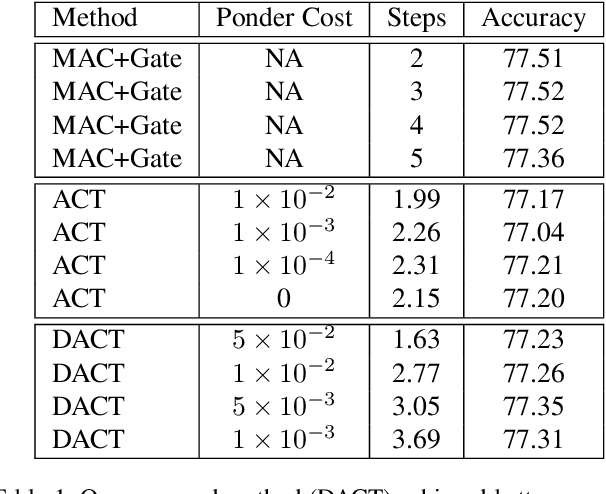
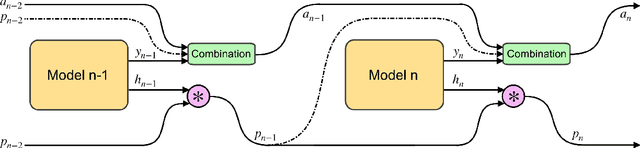
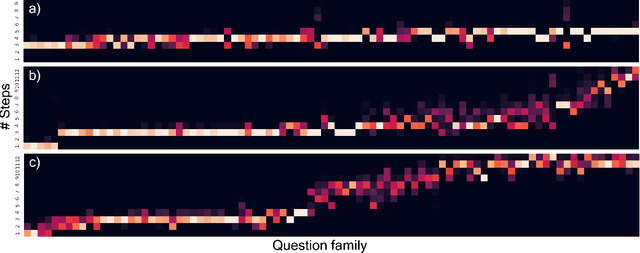
This paper presents a novel attention-based algorithm for achieving adaptive computation called DACT, which, unlike existing ones, is end-to-end differentiable.Our method can be used in conjunction with many networks; in particular, we study its application to the widely know MAC architecture, obtaining a significant reduction in the number of recurrent steps needed to achieve similar accuracies, therefore improving its performance to computation ratio.Furthermore, we show that by increasing the maximum number of steps used, we surpass the accuracy of even our best non-adaptive MAC in the CLEVR dataset, demonstrating that our approach is able to control the number of steps without significant loss of performance.Additional advantages provided by our approach include considerably improving interpretability by discarding useless steps and providing more insights into the underlying reasoning process.Finally, we present adaptive computation as an equivalent to an ensemble of models, similar to a mixture of expert formulation.Both the code and the configuration files for our experiments are made available to support further research in this area.
Interpretable Mixture Density Estimation by use of Differentiable Tree-module
May 08, 2021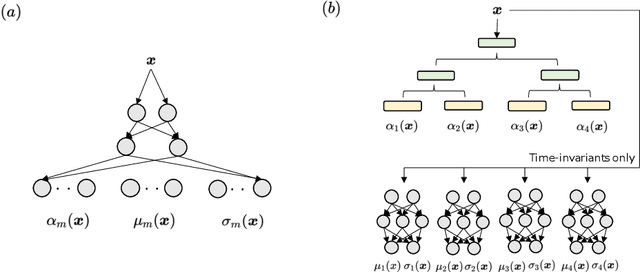

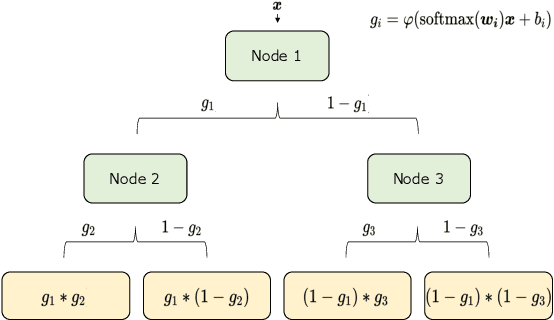

In order to develop reliable services using machine learning, it is important to understand the uncertainty of the model outputs. Often the probability distribution that the prediction target follows has a complex shape, and a mixture distribution is assumed as a distribution that uncertainty follows. Since the output of mixture density estimation is complicated, its interpretability becomes important when considering its use in real services. In this paper, we propose a method for mixture density estimation that utilizes an interpretable tree structure. Further, a fast inference procedure based on time-invariant information cache achieves both high speed and interpretability.
Robot kinematic structure classification from time series of visual data
Mar 11, 2019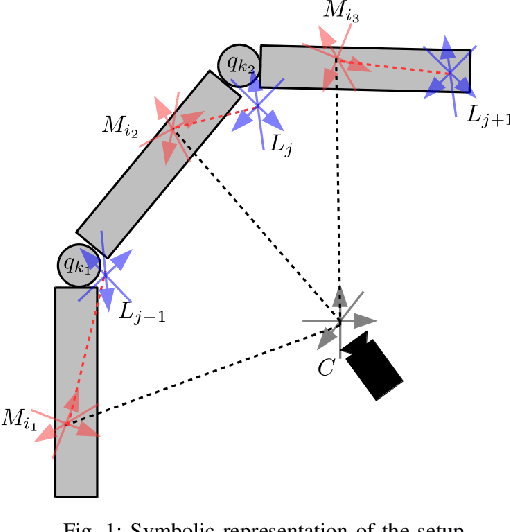
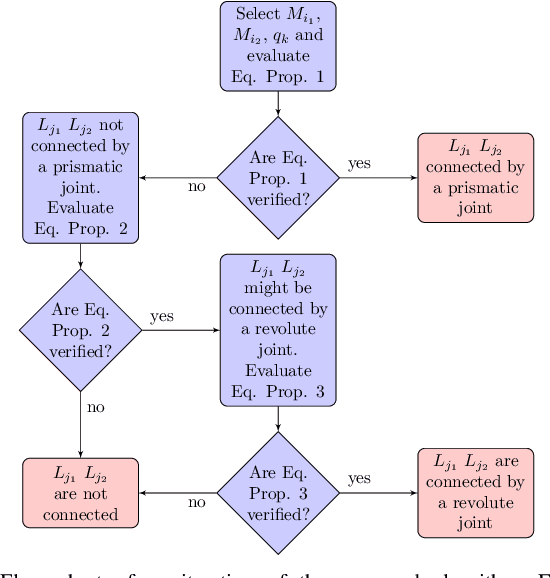
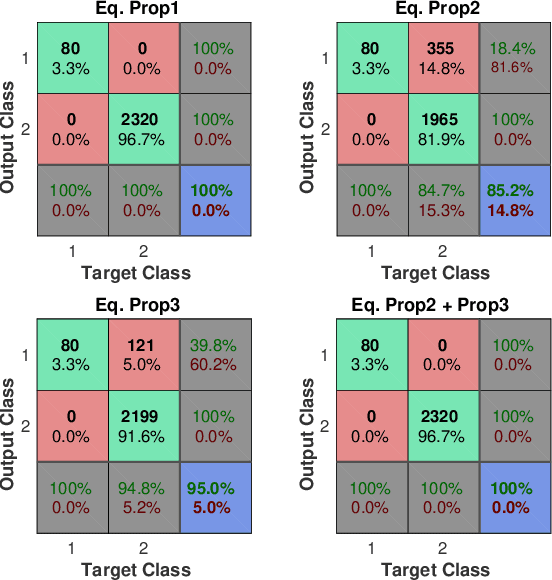
In this paper we present a novel algorithm to solve the robot kinematic structure identification problem. Given a time series of data, typically obtained processing a set of visual observations, the proposed approach identifies the ordered sequence of links associated to the kinematic chain, the joint type interconnecting each couple of consecutive links, and the input signal influencing the relative motion. Compared to the state of the art, the proposed algorithm has reduced computational costs, and is able to identify also the joints' type sequence.
Developing Real-time Streaming Transformer Transducer for Speech Recognition on Large-scale Dataset
Oct 22, 2020
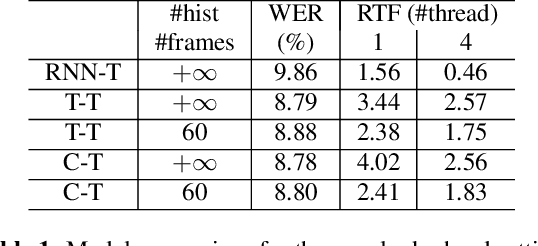
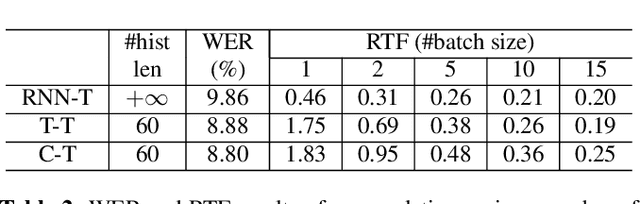
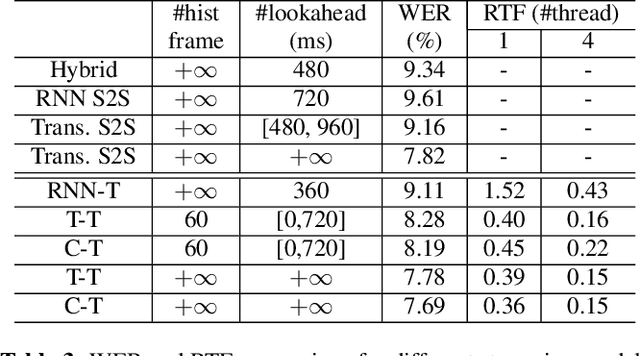
Recently, Transformer based end-to-end models have achieved great success in many areas including speech recognition. However, compared to LSTM models, the heavy computational cost of the Transformer during inference is a key issue to prevent their applications. In this work, we explored the potential of Transformer Transducer (T-T) models for the fist pass decoding with low latency and fast speed on a large-scale dataset. We combine the idea of Transformer-XL and chunk-wise streaming processing to design a streamable Transformer Transducer model. We demonstrate that T-T outperforms the hybrid model, RNN Transducer (RNN-T), and streamable Transformer attention-based encoder-decoder model in the streaming scenario. Furthermore, the runtime cost and latency can be optimized with a relatively small look-ahead.
Data-driven mapping between functional connectomes using optimal transport
Jul 02, 2021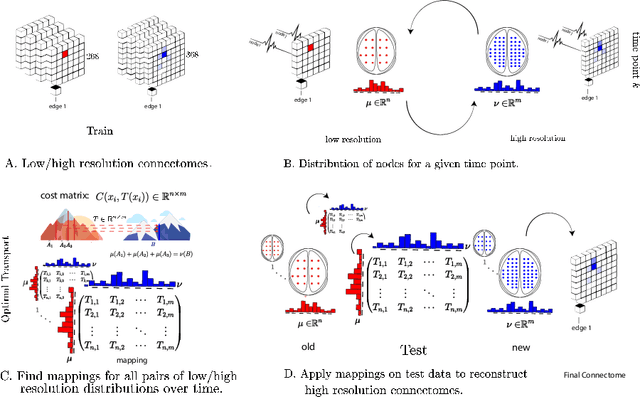
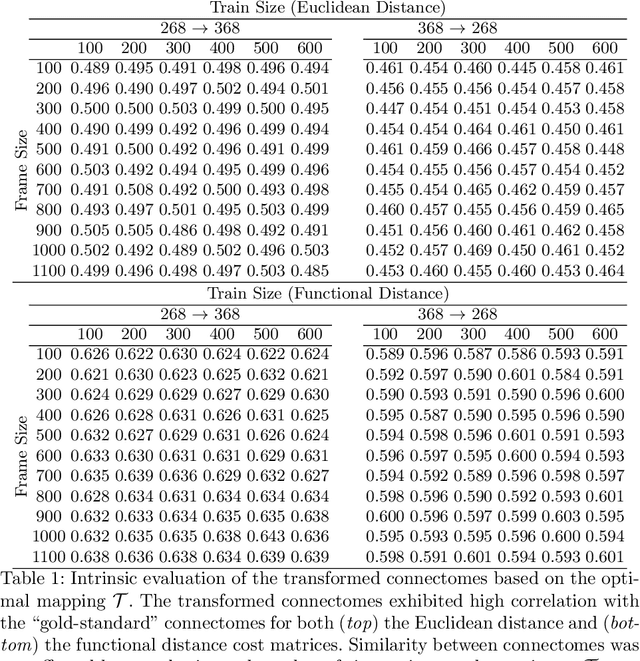

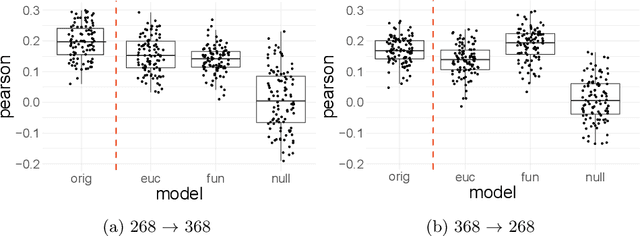
Functional connectomes derived from functional magnetic resonance imaging have long been used to understand the functional organization of the brain. Nevertheless, a connectome is intrinsically linked to the atlas used to create it. In other words, a connectome generated from one atlas is different in scale and resolution compared to a connectome generated from another atlas. Being able to map connectomes and derived results between different atlases without additional pre-processing is a crucial step in improving interpretation and generalization between studies that use different atlases. Here, we use optimal transport, a powerful mathematical technique, to find an optimum mapping between two atlases. This mapping is then used to transform time series from one atlas to another in order to reconstruct a connectome. We validate our approach by comparing transformed connectomes against their "gold-standard" counterparts (i.e., connectomes generated directly from an atlas) and demonstrate the utility of transformed connectomes by applying these connectomes to predictive models based on a different atlas. We show that these transformed connectomes are significantly similar to their "gold-standard" counterparts and maintain individual differences in brain-behavior associations, demonstrating both the validity of our approach and its utility in downstream analyses. Overall, our approach is a promising avenue to increase the generalization of connectome-based results across different atlases.
DSRN: an Efficient Deep Network for Image Relighting
Feb 18, 2021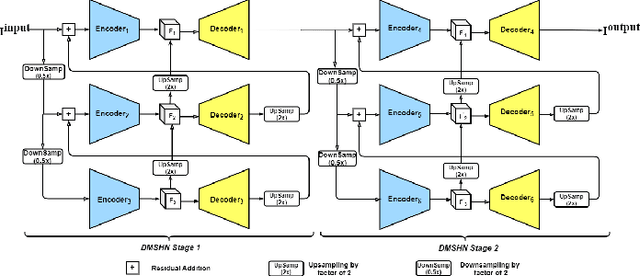
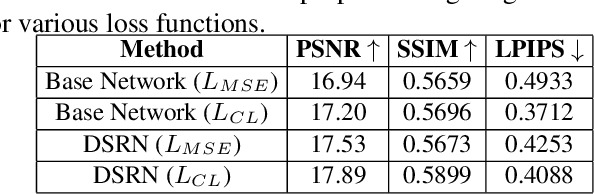
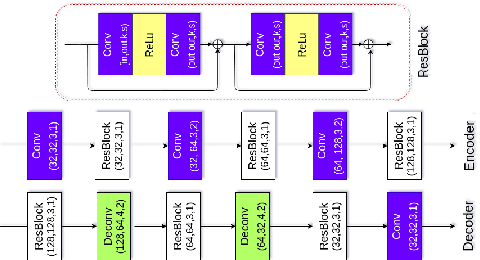
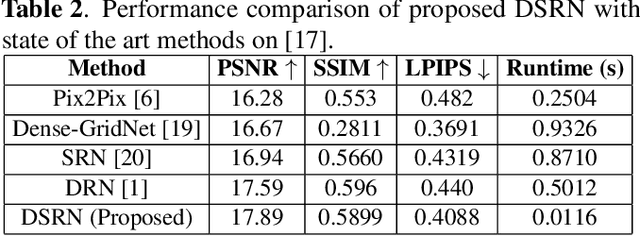
Custom and natural lighting conditions can be emulated in images of the scene during post-editing. Extraordinary capabilities of the deep learning framework can be utilized for such purpose. Deep image relighting allows automatic photo enhancement by illumination-specific retouching. Most of the state-of-the-art methods for relighting are run-time intensive and memory inefficient. In this paper, we propose an efficient, real-time framework Deep Stacked Relighting Network (DSRN) for image relighting by utilizing the aggregated features from input image at different scales. Our model is very lightweight with total size of about 42 MB and has an average inference time of about 0.0116s for image of resolution $1024 \times 1024$ which is faster as compared to other multi-scale models. Our solution is quite robust for translating image color temperature from input image to target image and also performs moderately for light gradient generation with respect to the target image. Additionally, we show that if images illuminated from opposite directions are used as input, the qualitative results improve over using a single input image.
Learning Sublinear-Time Indexing for Nearest Neighbor Search
Jan 24, 2019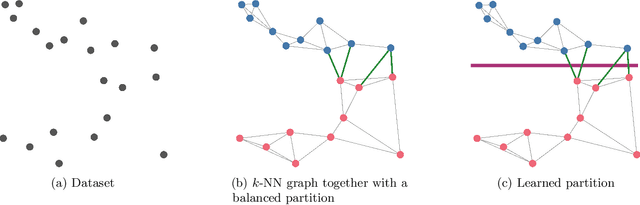
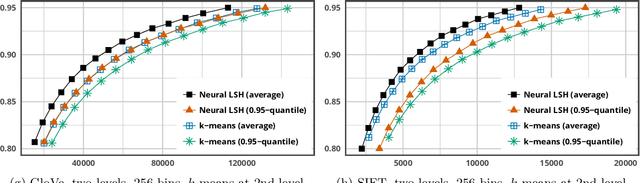
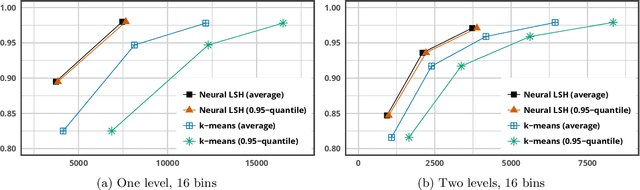
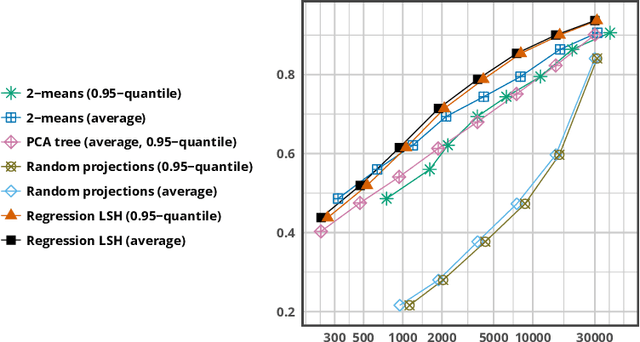
Most of the efficient sublinear-time indexing algorithms for the high-dimensional nearest neighbor search problem (NNS) are based on space partitions of the ambient space $\mathbb{R}^d$. Inspired by recent theoretical work on NNS for general metric spaces [Andoni, Naor, Nikolov, Razenshteyn, Waingarten STOC 2018, FOCS 2018], we develop a new framework for constructing such partitions that reduces the problem to balanced graph partitioning followed by supervised classification. We instantiate this general approach with the KaHIP graph partitioner [Sanders, Schulz SEA 2013] and neural networks, respectively, to obtain a new partitioning procedure called Neural Locality-Sensitive Hashing (Neural LSH). On several standard benchmarks for NNS, our experiments show that the partitions found by Neural LSH consistently outperform partitions found by quantization- and tree-based methods.
Uncertainty for Identifying Open-Set Errors in Visual Object Detection
Apr 03, 2021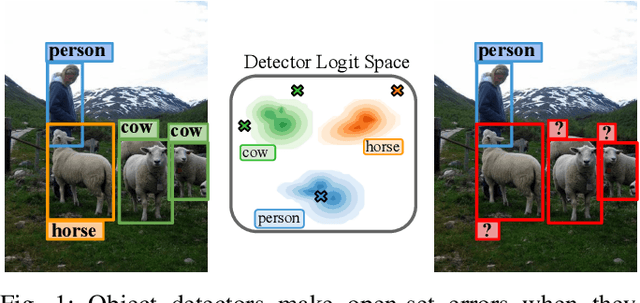
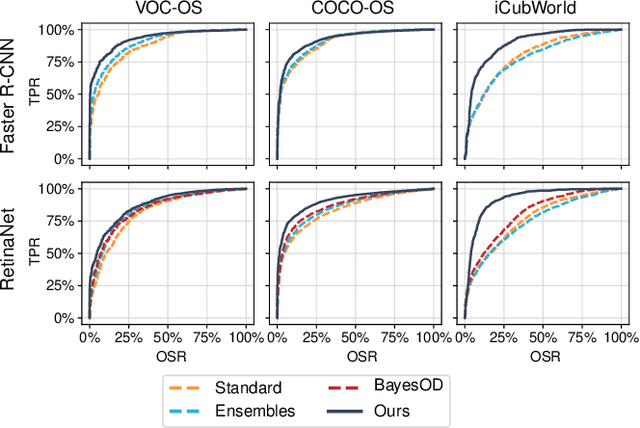
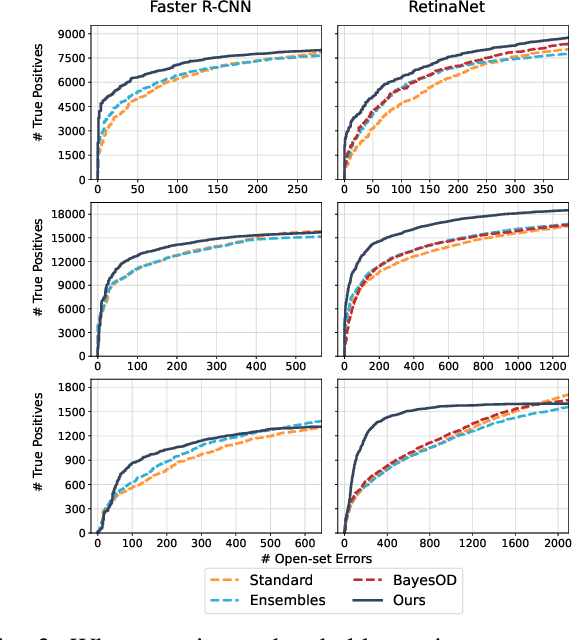
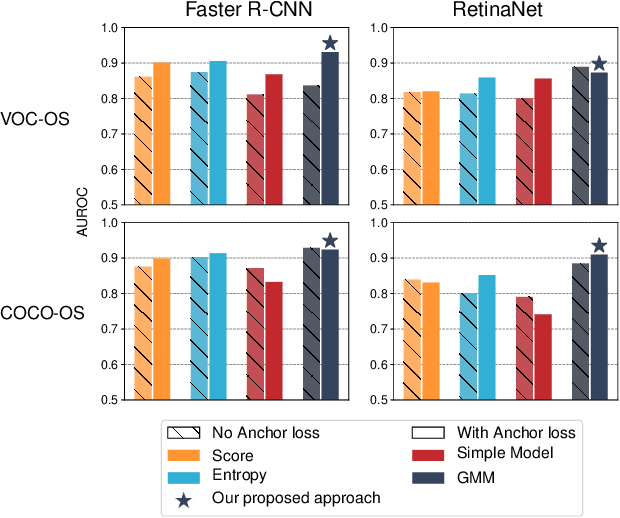
Deployed into an open world, object detectors are prone to a type of false positive detection termed open-set errors. We propose GMM-Det, a real-time method for extracting epistemic uncertainty from object detectors to identify and reject open-set errors. GMM-Det trains the detector to produce a structured logit space that is modelled with class-specific Gaussian Mixture Models. At test time, open-set errors are identified by their low log-probability under all Gaussian Mixture Models. We test two common detector architectures, Faster R-CNN and RetinaNet, across three varied datasets spanning robotics and computer vision. Our results show that GMM-Det consistently outperforms existing uncertainty techniques for identifying and rejecting open-set detections, especially at the low-error-rate operating point required for safety-critical applications. GMM-Det maintains object detection performance, and introduces only minimal computational overhead. We also introduce a methodology for converting existing object detection datasets into specific open-set datasets to consistently evaluate open-set performance in object detection. Code for GMM-Det and the dataset methodology will be made publicly available.