 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploring Semantic Relationships for Unpaired Image Captioning
Jun 20, 2021
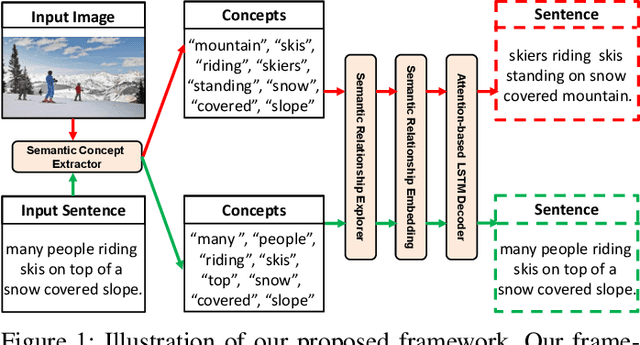
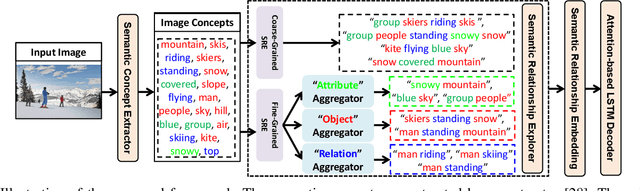
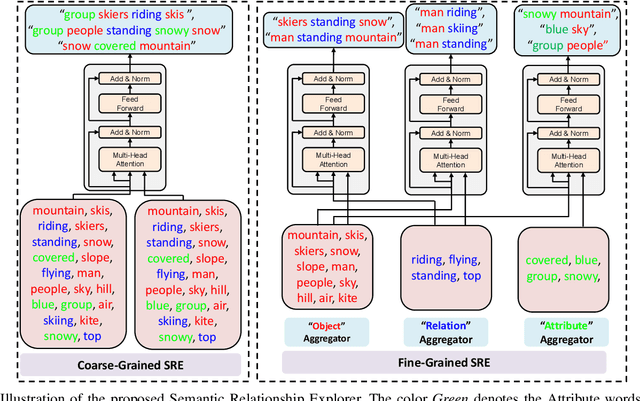

Recently, image captioning has aroused great interest in both academic and industrial worlds. Most existing systems are built upon large-scale datasets consisting of image-sentence pairs, which, however, are time-consuming to construct. In addition, even for the most advanced image captioning systems, it is still difficult to realize deep image understanding. In this work, we achieve unpaired image captioning by bridging the vision and the language domains with high-level semantic information. The motivation stems from the fact that the semantic concepts with the same modality can be extracted from both images and descriptions. To further improve the quality of captions generated by the model, we propose the Semantic Relationship Explorer, which explores the relationships between semantic concepts for better understanding of the image. Extensive experiments on MSCOCO dataset show that we can generate desirable captions without paired datasets. Furthermore, the proposed approach boosts five strong baselines under the paired setting, where the most significant improvement in CIDEr score reaches 8%, demonstrating that it is effective and generalizes well to a wide range of models.
Read, Attend, and Code: Pushing the Limits of Medical Codes Prediction from Clinical Notes by Machines
Jul 10, 2021

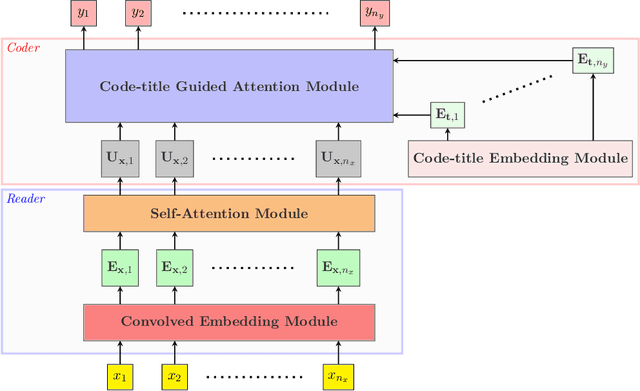
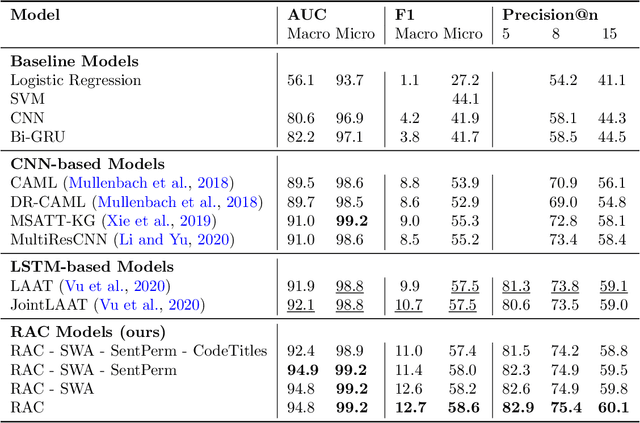
Prediction of medical codes from clinical notes is both a practical and essential need for every healthcare delivery organization within current medical systems. Automating annotation will save significant time and excessive effort spent by human coders today. However, the biggest challenge is directly identifying appropriate medical codes out of several thousands of high-dimensional codes from unstructured free-text clinical notes. In the past three years, with Convolutional Neural Networks (CNN) and Long Short-Term Memory (LTSM) networks, there have been vast improvements in tackling the most challenging benchmark of the MIMIC-III-full-label inpatient clinical notes dataset. This progress raises the fundamental question of how far automated machine learning (ML) systems are from human coders' working performance. We assessed the baseline of human coders' performance on the same subsampled testing set. We also present our Read, Attend, and Code (RAC) model for learning the medical code assignment mappings. By connecting convolved embeddings with self-attention and code-title guided attention modules, combined with sentence permutation-based data augmentations and stochastic weight averaging training, RAC establishes a new state of the art (SOTA), considerably outperforming the current best Macro-F1 by 18.7%, and reaches past the human-level coding baseline. This new milestone marks a meaningful step toward fully autonomous medical coding (AMC) in machines reaching parity with human coders' performance in medical code prediction.
A Machine Learning Model for Early Detection of Diabetic Foot using Thermogram Images
Jun 27, 2021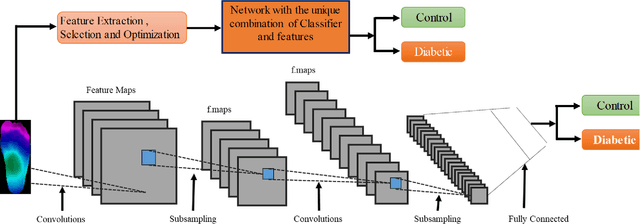
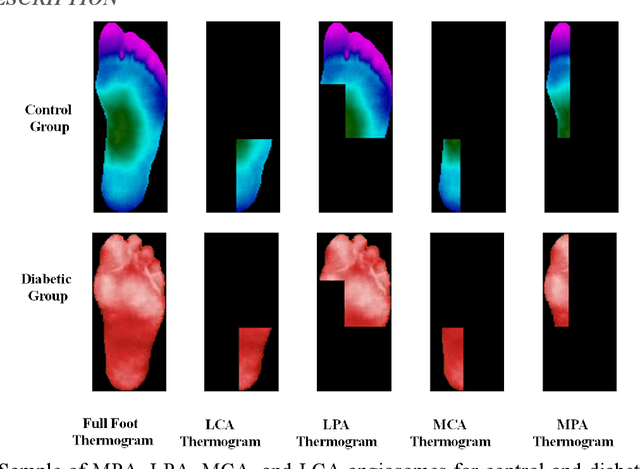
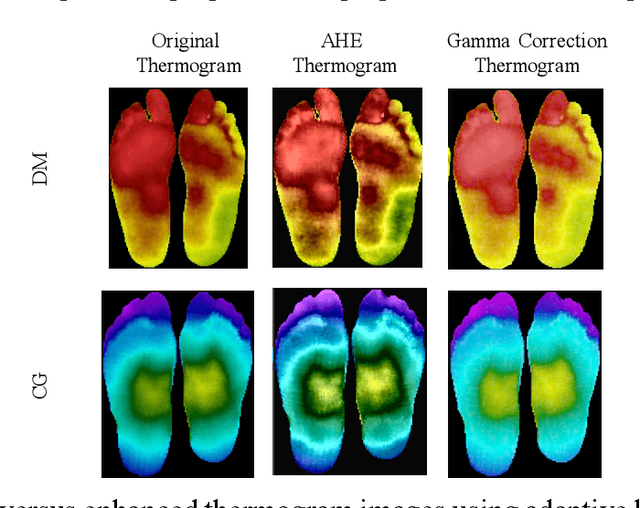
Diabetes foot ulceration (DFU) and amputation are a cause of significant morbidity. The prevention of DFU may be achieved by the identification of patients at risk of DFU and the institution of preventative measures through education and offloading. Several studies have reported that thermogram images may help to detect an increase in plantar temperature prior to DFU. However, the distribution of plantar temperature may be heterogeneous, making it difficult to quantify and utilize to predict outcomes. We have compared a machine learning-based scoring technique with feature selection and optimization techniques and learning classifiers to several state-of-the-art Convolutional Neural Networks (CNNs) on foot thermogram images and propose a robust solution to identify the diabetic foot. A comparatively shallow CNN model, MobilenetV2 achieved an F1 score of ~95% for a two-feet thermogram image-based classification and the AdaBoost Classifier used 10 features and achieved an F1 score of 97 %. A comparison of the inference time for the best-performing networks confirmed that the proposed algorithm can be deployed as a smartphone application to allow the user to monitor the progression of the DFU in a home setting.
General-Purpose Speech Representation Learning through a Self-Supervised Multi-Granularity Framework
Feb 03, 2021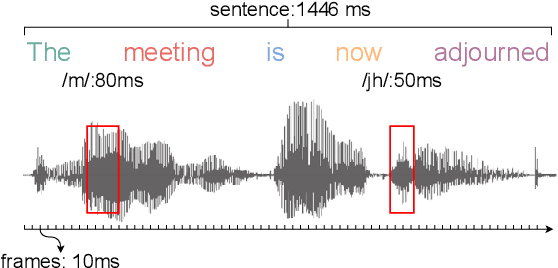
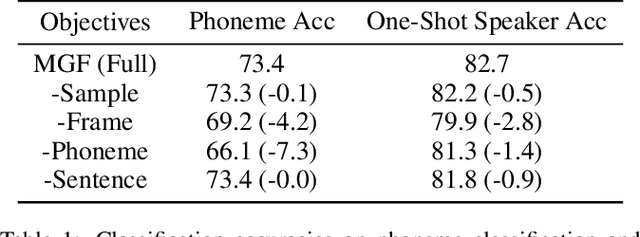
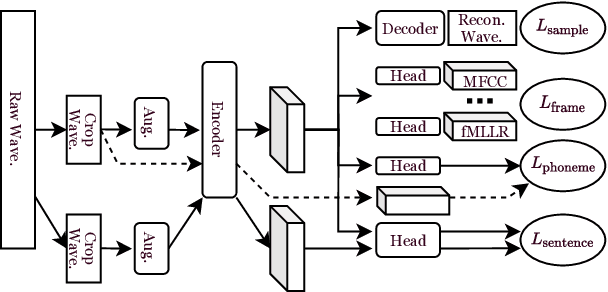
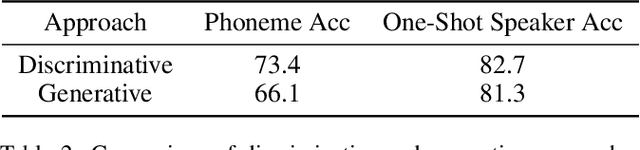
This paper presents a self-supervised learning framework, named MGF, for general-purpose speech representation learning. In the design of MGF, speech hierarchy is taken into consideration. Specifically, we propose to use generative learning approaches to capture fine-grained information at small time scales and use discriminative learning approaches to distill coarse-grained or semantic information at large time scales. For phoneme-scale learning, we borrow idea from the masked language model but tailor it for the continuous speech signal by replacing classification loss with a contrastive loss. We corroborate our design by evaluating MGF representation on various downstream tasks, including phoneme classification, speaker classification, speech recognition, and emotion classification. Experiments verify that training at different time scales needs different training targets and loss functions, which in general complement each other and lead to a better performance.
Anytime Ranking on Document-Ordered Indexes
Apr 18, 2021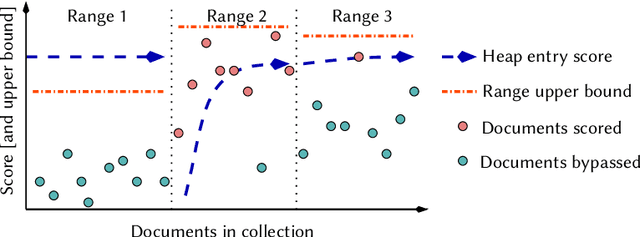


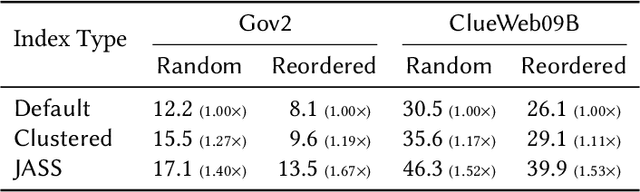
Inverted indexes continue to be a mainstay of text search engines, allowing efficient querying of large document collections. While there are a number of possible organizations, document-ordered indexes are the most common, since they are amenable to various query types, support index updates, and allow for efficient dynamic pruning operations. One disadvantage with document-ordered indexes is that high-scoring documents can be distributed across the document identifier space, meaning that index traversal algorithms that terminate early might put search effectiveness at risk. The alternative is impact-ordered indexes, which primarily support top-k disjunctions, but also allow for anytime query processing, where the search can be terminated at any time, with search quality improving as processing latency increases. Anytime query processing can be used to effectively reduce high-percentile tail latency which is essential for operational scenarios in which a service level agreement (SLA) imposes response time requirements. In this work, we show how document-ordered indexes can be organized such that they can be queried in an anytime fashion, enabling strict latency control with effective early termination. Our experiments show that processing document-ordered topical segments selected by a simple score estimator outperforms existing anytime algorithms, and allows query runtimes to be accurately limited in order to comply with SLA requirements.
RaspberryPI for mosquito neutralization by power laser
May 20, 2021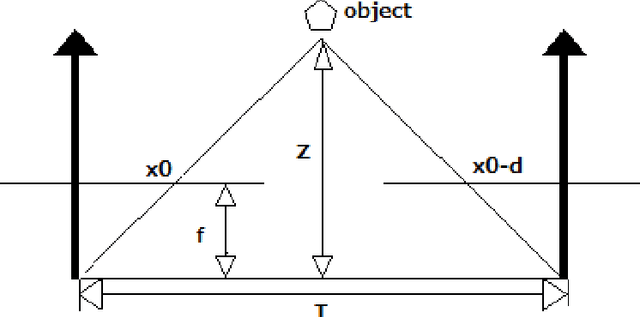
In this article for the first time, comprehensive studies of mosquito neutralization using machine vision and a 1 W power laser are considered. Developed laser installation with Raspberry Pi that changing the direction of the laser with a galvanometer. We developed a program for mosquito tracking in real. The possibility of using deep neural networks, Haar cascades, machine learning for mosquito recognition was considered. We considered in detail the classification problems of mosquitoes in images. A recommendation is given for the implementation of this device based on a microcontroller for subsequent use as part of an unmanned aerial vehicle. Any harmful insects in the fields can be used as objects for control.
Carnegie Mellon Team Tartan: Mission-level Robustness with Rapidly Deployed Autonomous Aerial Vehicles in the MBZIRC 2020
Jul 03, 2021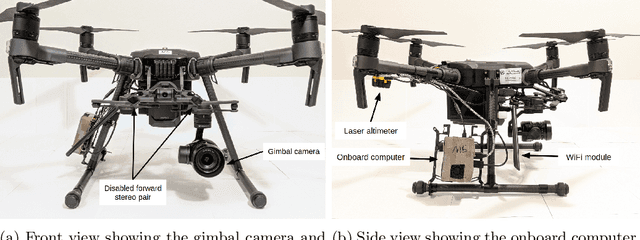

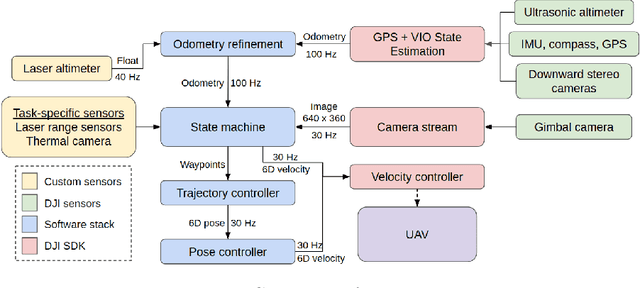
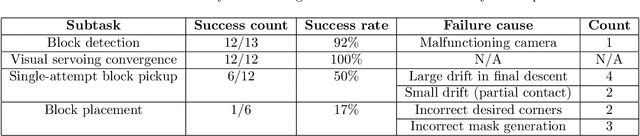
For robotics systems to be used in high risk, real-world situations, they have to be quickly deployable and robust to environmental changes, under-performing hardware, and mission subtask failures. Robots are often designed to consider a single sequence of mission events, with complex algorithms lowering individual subtask failure rates under some critical constraints. Our approach is to leverage common techniques in vision and control and encode robustness into mission structure through outcome monitoring and recovery strategies, aided by a system infrastructure that allows for quick mission deployments under tight time constraints and no central communication. We also detail lessons in rapid field robotics development and testing. Systems were developed and evaluated through real-robot experiments at an outdoor test site in Pittsburgh, Pennsylvania, USA, as well as in the 2020 Mohamed Bin Zayed International Robotics Challenge. All competition trials were completed in fully autonomous mode without RTK-GPS. Our system led to 4th place in Challenge 2 and 7th place in the Grand Challenge, and achievements like popping five balloons (Challenge 1), successfully picking and placing a block (Challenge 2), and dispensing the most water autonomously with a UAV of all teams onto an outdoor, real fire (Challenge 3).
Entropy-based Optimization via A* Algorithm for Parking Space Recommendation
Apr 19, 2021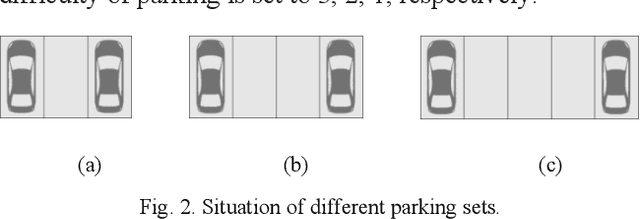
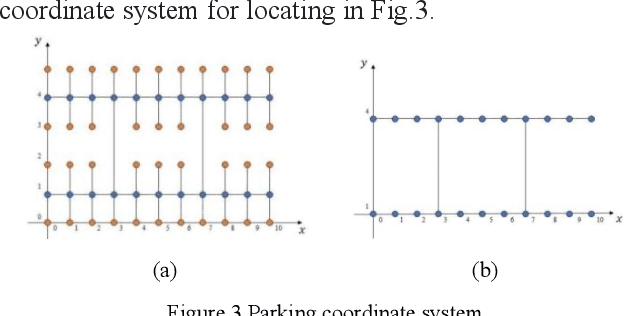
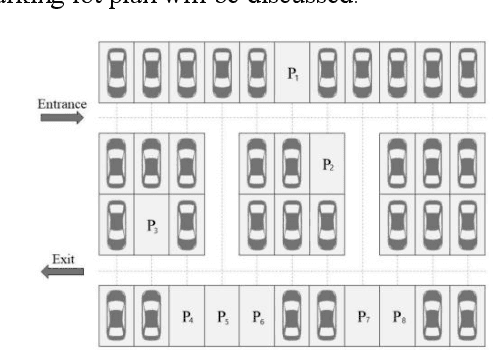
This paper addresses the path planning problems for recommending parking spaces, given the difficulties of identifying the most optimal route to vacant parking spaces and the shortest time to leave the parking space. Our optimization approach is based on the entropy method and realized by the A* algorithm. Experiments have shown that the combination of A* and the entropy value induces the optimal parking solution with the shortest route while being robust to environmental factors.
Attention or memory? Neurointerpretable agents in space and time
Jul 09, 2020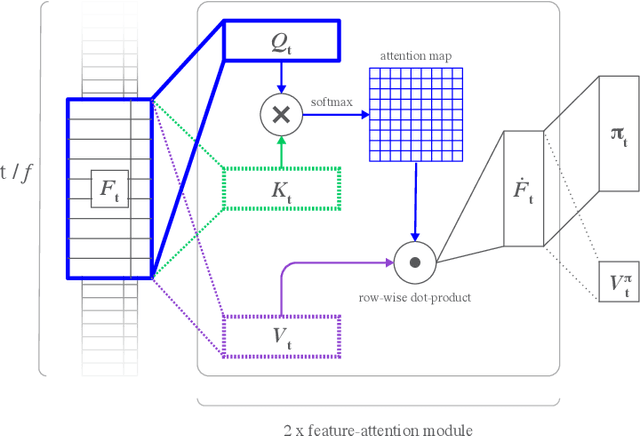
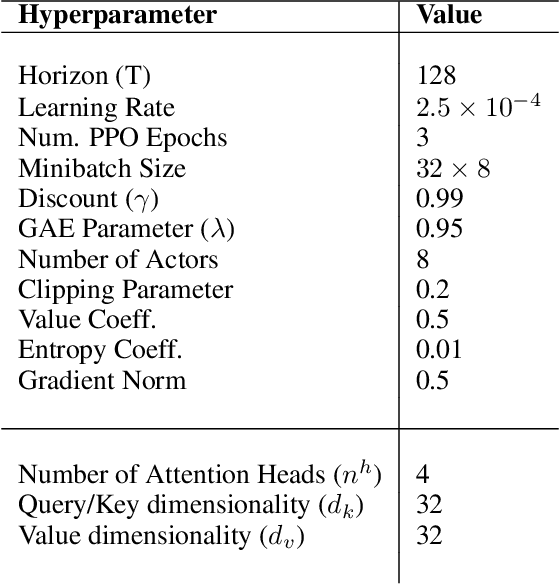
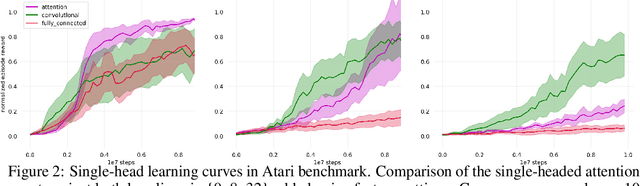
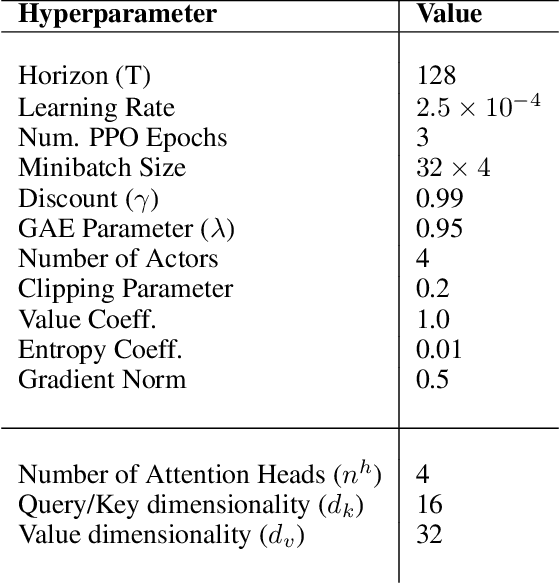
In neuroscience, attention has been shown to bidirectionally interact with reinforcement learning (RL) processes. This interaction is thought to support dimensionality reduction of task representations, restricting computations to relevant features. However, it remains unclear whether these properties can translate into real algorithmic advantages for artificial agents, especially in dynamic environments. We design a model incorporating a self-attention mechanism that implements task-state representations in semantic feature-space, and test it on a battery of Atari games. To evaluate the agent's selective properties, we add a large volume of task-irrelevant features to observations. In line with neuroscience predictions, self-attention leads to increased robustness to noise compared to benchmark models. Strikingly, this self-attention mechanism is general enough, such that it can be naturally extended to implement a transient working-memory, able to solve a partially observable maze task. Lastly, we highlight the predictive quality of attended stimuli. Because we use semantic observations, we can uncover not only which features the agent elects to base decisions on, but also how it chooses to compile more complex, relational features from simpler ones. These results formally illustrate the benefits of attention in deep RL and provide evidence for the interpretability of self-attention mechanisms.
Lithography Hotspot Detection via Heterogeneous Federated Learning with Local Adaptation
Jul 15, 2021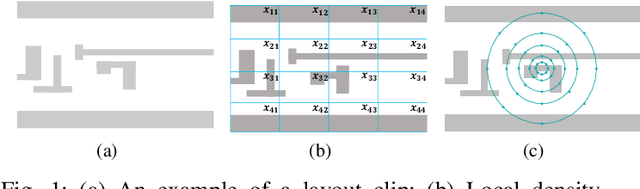
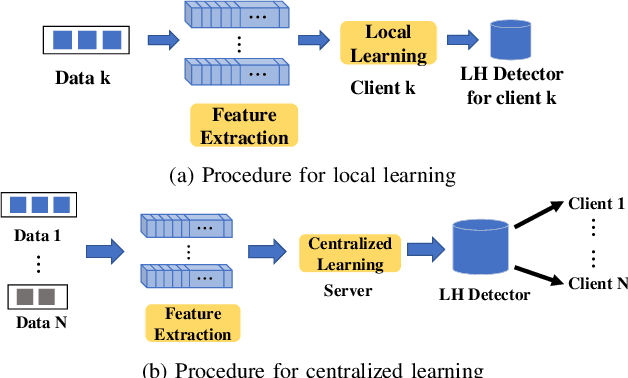
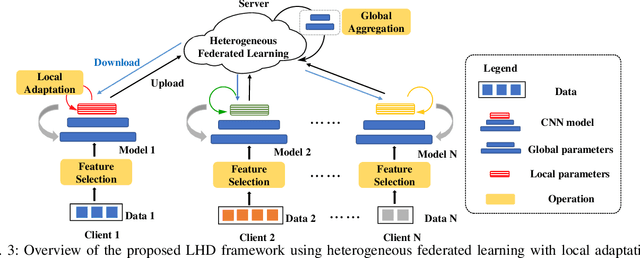
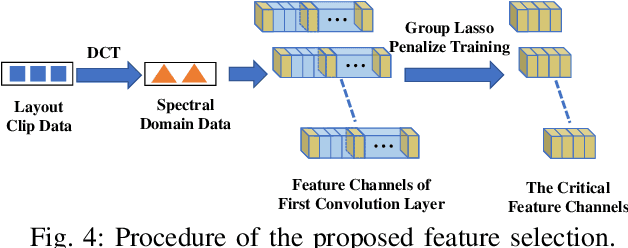
As technology scaling is approaching the physical limit, lithography hotspot detection has become an essential task in design for manufacturability. While the deployment of pattern matching or machine learning in hotspot detection can help save significant simulation time, such methods typically demand for non-trivial quality data to build the model, which most design houses are short of. Moreover, the design houses are also unwilling to directly share such data with the other houses to build a unified model, which can be ineffective for the design house with unique design patterns due to data insufficiency. On the other hand, with data homogeneity in each design house, the locally trained models can be easily over-fitted, losing generalization ability and robustness. In this paper, we propose a heterogeneous federated learning framework for lithography hotspot detection that can address the aforementioned issues. On one hand, the framework can build a more robust centralized global sub-model through heterogeneous knowledge sharing while keeping local data private. On the other hand, the global sub-model can be combined with a local sub-model to better adapt to local data heterogeneity. The experimental results show that the proposed framework can overcome the challenge of non-independent and identically distributed (non-IID) data and heterogeneous communication to achieve very high performance in comparison to other state-of-the-art methods while guaranteeing a good convergence rate in various scenarios.