 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Validation of image systems simulation technology using a Cornell Box
May 10, 2021

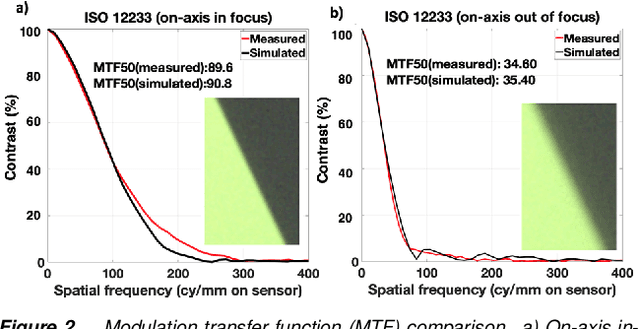
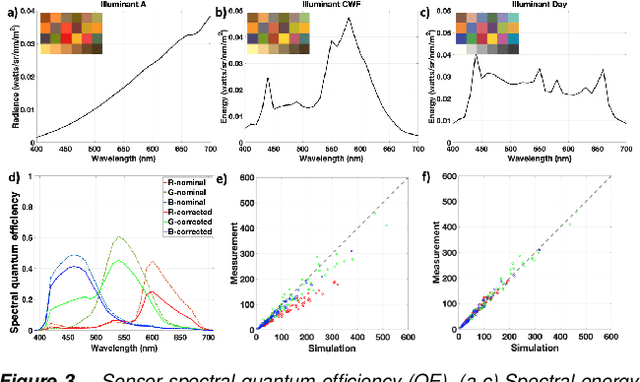

We describe and experimentally validate an end-to-end simulation of a digital camera. The simulation models the spectral radiance of 3D-scenes, formation of the spectral irradiance by multi-element optics, and conversion of the irradiance to digital values by the image sensor. We quantify the accuracy of the simulation by comparing real and simulated images of a precisely constructed, three-dimensional high dynamic range test scene. Validated end-to-end software simulation of a digital camera can accelerate innovation by reducing many of the time-consuming and expensive steps in designing, building and evaluating image systems.
Auditing Source Diversity Bias in Video Search Results Using Virtual Agents
Jun 04, 2021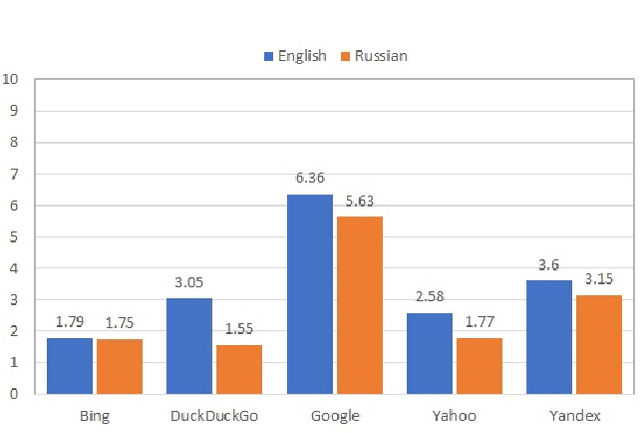
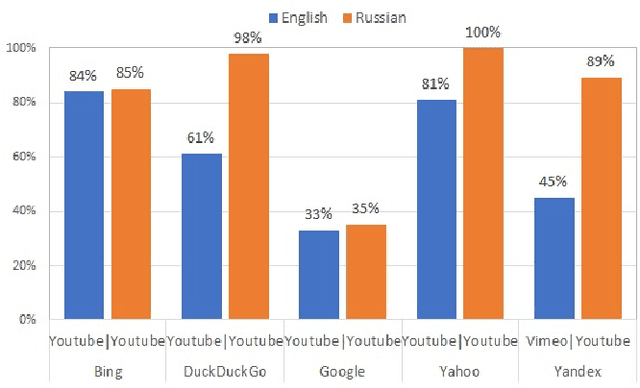
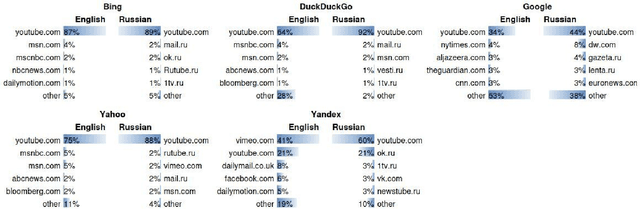
We audit the presence of domain-level source diversity bias in video search results. Using a virtual agent-based approach, we compare outputs of four Western and one non-Western search engines for English and Russian queries. Our findings highlight that source diversity varies substantially depending on the language with English queries returning more diverse outputs. We also find disproportionately high presence of a single platform, YouTube, in top search outputs for all Western search engines except Google. At the same time, we observe that Youtube's major competitors such as Vimeo or Dailymotion do not appear in the sampled Google's video search results. This finding suggests that Google might be downgrading the results from the main competitors of Google-owned Youtube and highlights the necessity for further studies focusing on the presence of own-content bias in Google's search results.
Federated Learning with Positive and Unlabeled Data
Jun 21, 2021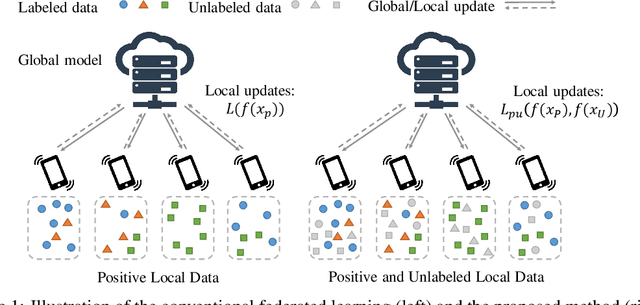
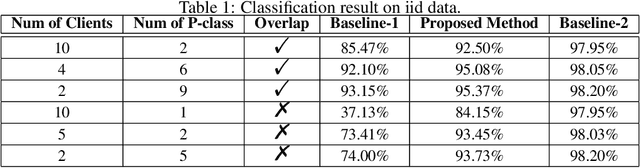
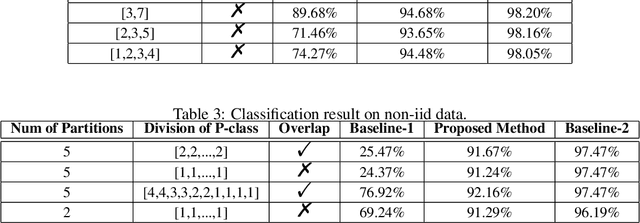
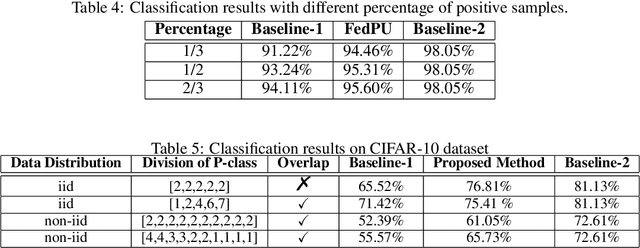
We study the problem of learning from positive and unlabeled (PU) data in the federated setting, where each client only labels a little part of their dataset due to the limitation of resources and time. Different from the settings in traditional PU learning where the negative class consists of a single class, the negative samples which cannot be identified by a client in the federated setting may come from multiple classes which are unknown to the client. Therefore, existing PU learning methods can be hardly applied in this situation. To address this problem, we propose a novel framework, namely Federated learning with Positive and Unlabeled data (FedPU), to minimize the expected risk of multiple negative classes by leveraging the labeled data in other clients. We theoretically prove that the proposed FedPU can achieve a generalization bound which is no worse than $C\sqrt{C}$ times (where $C$ denotes the number of classes) of the fully-supervised model. Empirical experiments show that the FedPU can achieve much better performance than conventional learning methods which can only use positive data.
BoXHED 2.0: Scalable boosting of functional data in survival analysis
Mar 23, 2021
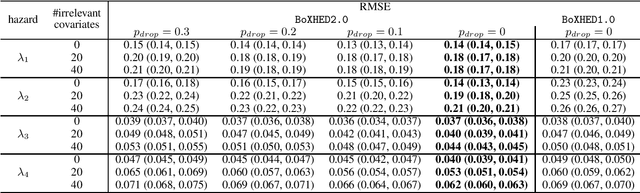
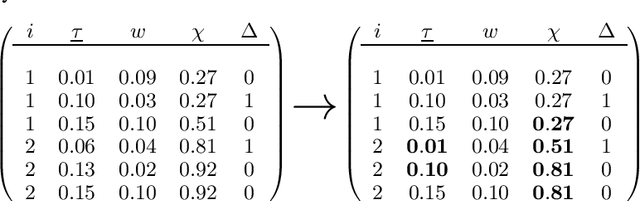
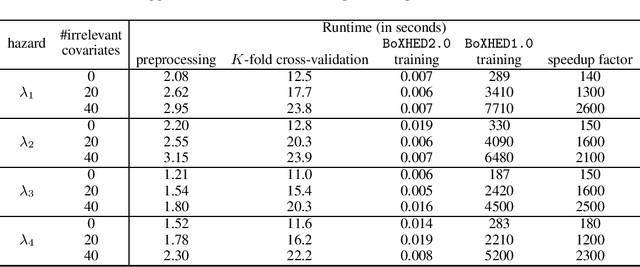
Modern applications of survival analysis increasingly involve time-dependent covariates, which constitute a form of functional data. Learning from functional data generally involves repeated evaluations of time integrals which is numerically expensive. In this work we propose a lightweight data preprocessing step that transforms functional data into nonfunctional data. Boosting implementations for nonfunctional data can then be used, whereby the required numerical integration comes for free as part of the training phase. We use this to develop BoXHED 2.0, a quantum leap over the tree-boosted hazard package BoXHED 1.0. BoXHED 2.0 extends BoXHED 1.0 to Aalen's multiplicative intensity model, which covers censoring schemes far beyond right-censoring and also supports recurrent events data. It is also massively scalable because of preprocessing and also because it borrows from the core components of XGBoost. BoXHED 2.0 supports the use of GPUs and multicore CPUs, and is available from GitHub: www.github.com/BoXHED.
Physics-Informed Deep Reversible Regression Model for Temperature Field Reconstruction of Heat-Source Systems
Jul 05, 2021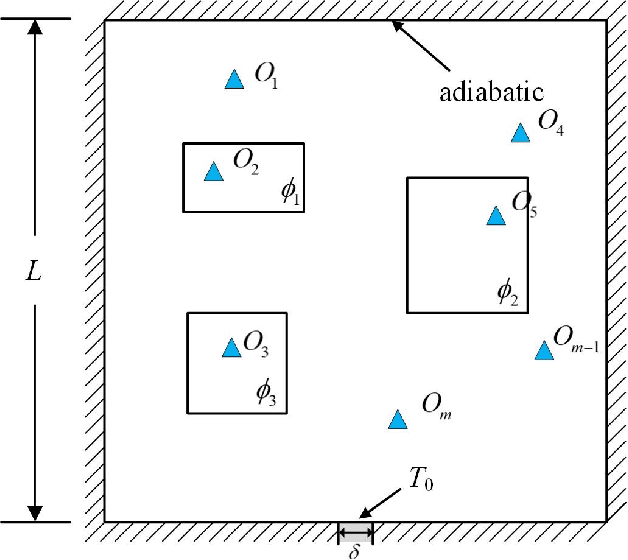
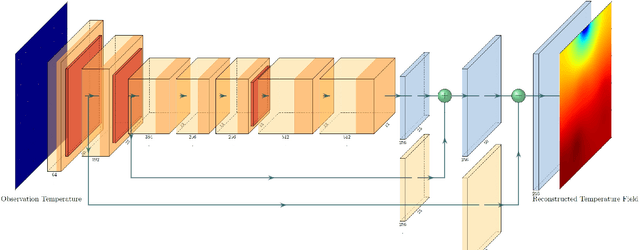
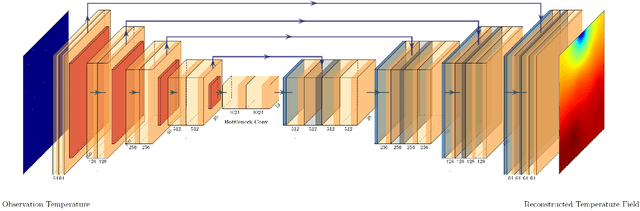
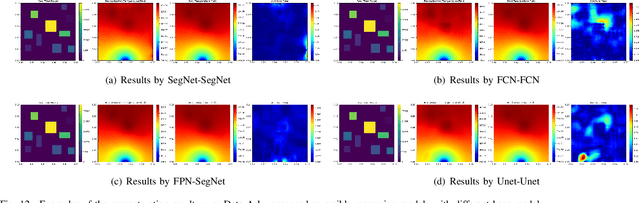
Temperature monitoring during the life time of heat source components in engineering systems becomes essential to guarantee the normal work and the working life of these components. However, prior methods, which mainly use the interpolate estimation to reconstruct the temperature field from limited monitoring points, require large amounts of temperature tensors for an accurate estimation. This may decrease the availability and reliability of the system and sharply increase the monitoring cost. To solve this problem, this work develops a novel physics-informed deep reversible regression models for temperature field reconstruction of heat-source systems (TFR-HSS), which can better reconstruct the temperature field with limited monitoring points unsupervisedly. First, we define the TFR-HSS task mathematically, and numerically model the task, and hence transform the task as an image-to-image regression problem. Then this work develops the deep reversible regression model which can better learn the physical information, especially over the boundary. Finally, considering the physical characteristics of heat conduction as well as the boundary conditions, this work proposes the physics-informed reconstruction loss including four training losses and jointly learns the deep surrogate model with these losses unsupervisedly. Experimental studies have conducted over typical two-dimensional heat-source systems to demonstrate the effectiveness of the proposed method.
Experience-Driven PCG via Reinforcement Learning: A Super Mario Bros Study
Jul 05, 2021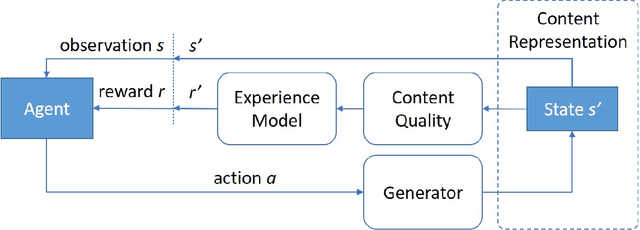
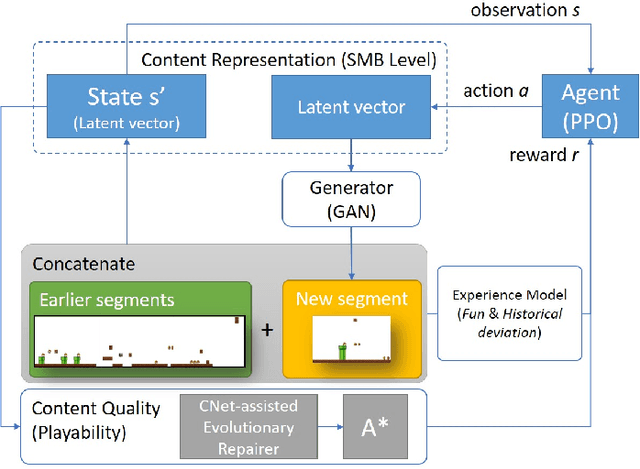
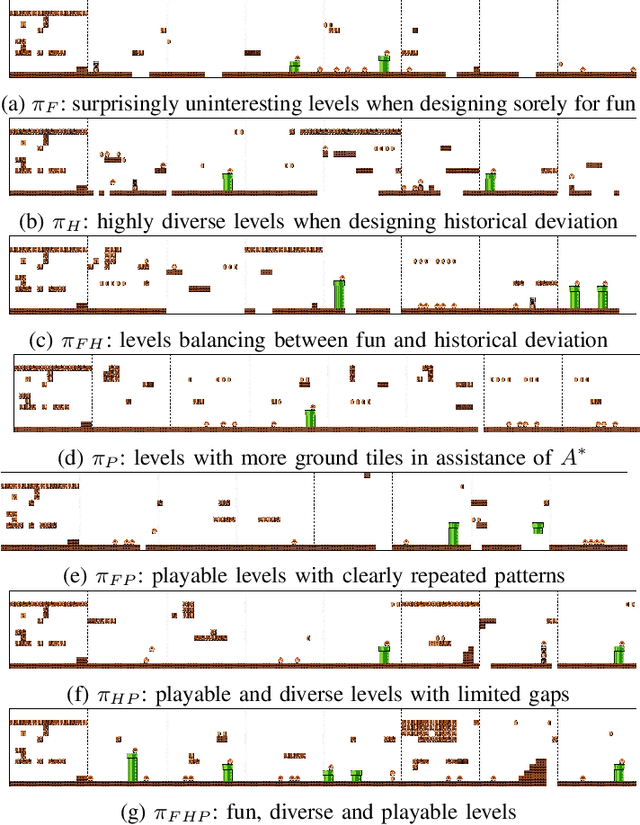
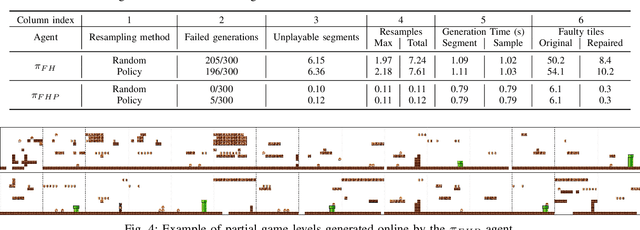
We introduce a procedural content generation (PCG) framework at the intersections of experience-driven PCG and PCG via reinforcement learning, named ED(PCG)RL, EDRL in short. EDRL is able to teach RL designers to generate endless playable levels in an online manner while respecting particular experiences for the player as designed in the form of reward functions. The framework is tested initially in the Super Mario Bros game. In particular, the RL designers of Super Mario Bros generate and concatenate level segments while considering the diversity among the segments. The correctness of the generation is ensured by a neural net-assisted evolutionary level repairer and the playability of the whole level is determined through AI-based testing. Our agents in this EDRL implementation learn to maximise a quantification of Koster's principle of fun by moderating the degree of diversity across level segments. Moreover, we test their ability to design fun levels that are diverse over time and playable. Our proposed framework is capable of generating endless, playable Super Mario Bros levels with varying degrees of fun, deviation from earlier segments, and playability. EDRL can be generalised to any game that is built as a segment-based sequential process and features a built-in compressed representation of its game content.
An End-to-End Khmer Optical Character Recognition using Sequence-to-Sequence with Attention
Jun 21, 2021
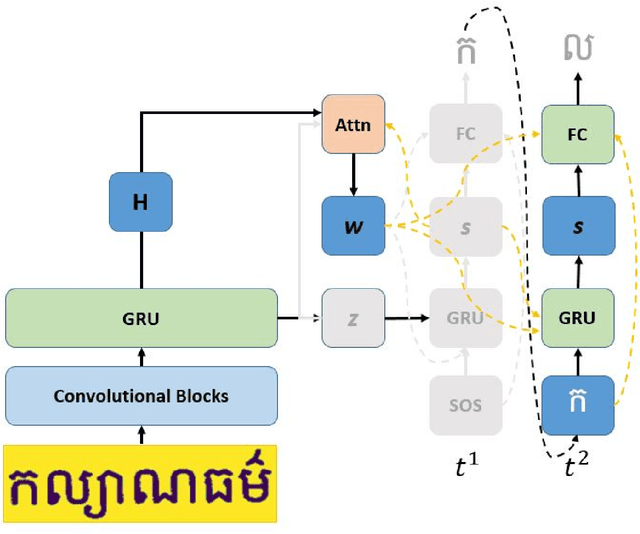
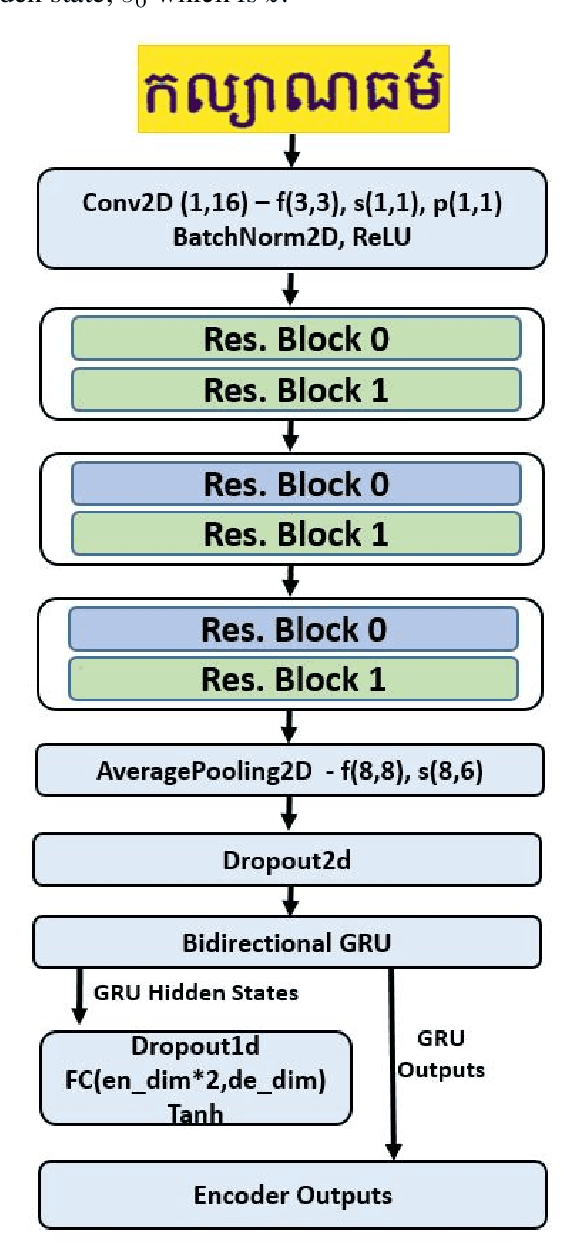
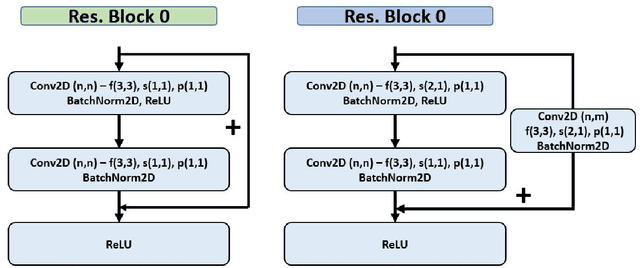
This paper presents an end-to-end deep convolutional recurrent neural network solution for Khmer optical character recognition (OCR) task. The proposed solution uses a sequence-to-sequence (Seq2Seq) architecture with attention mechanism. The encoder extracts visual features from an input text-line image via layers of residual convolutional blocks and a layer of gated recurrent units (GRU). The features are encoded in a single context vector and a sequence of hidden states which are fed to the decoder for decoding one character at a time until a special end-of-sentence (EOS) token is reached. The attention mechanism allows the decoder network to adaptively select parts of the input image while predicting a target character. The Seq2Seq Khmer OCR network was trained on a large collection of computer-generated text-line images for seven common Khmer fonts. The proposed model's performance outperformed the state-of-art Tesseract OCR engine for Khmer language on the 3000-images test set by achieving a character error rate (CER) of 1% vs 3%.
Classification Models for Partially Ordered Sequences
Jan 31, 2021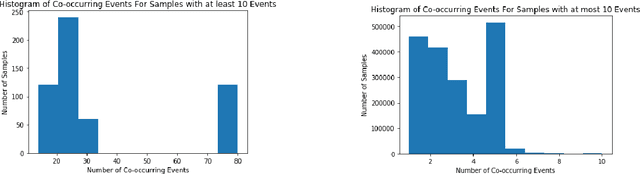
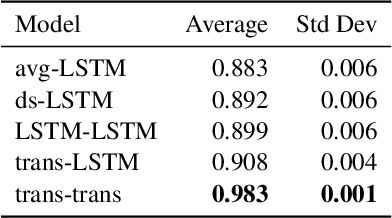

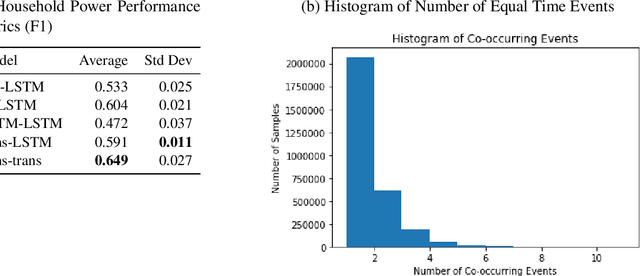
Many models such as Long Short Term Memory (LSTMs), Gated Recurrent Units (GRUs) and transformers have been developed to classify time series data with the assumption that events in a sequence are ordered. On the other hand, fewer models have been developed for set based inputs, where order does not matter. There are several use cases where data is given as partially-ordered sequences because of the granularity or uncertainty of time stamps. We introduce a novel transformer based model for such prediction tasks, and benchmark against extensions of existing order invariant models. We also discuss how transition probabilities between events in a sequence can be used to improve model performance. We show that the transformer-based equal-time model outperforms extensions of existing set models on three data sets.
Towards Low-Latency Energy-Efficient Deep SNNs via Attention-Guided Compression
Jul 16, 2021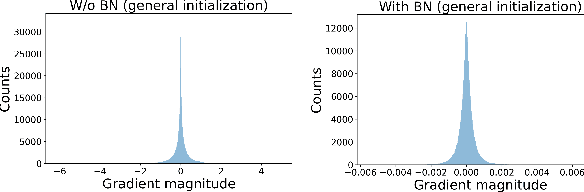
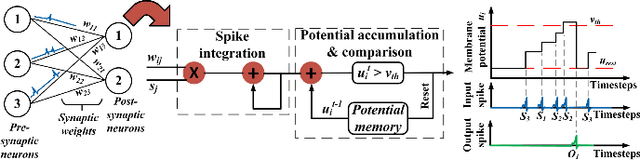
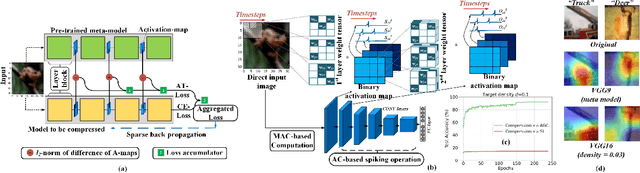
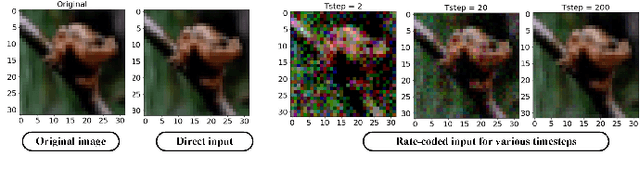
Deep spiking neural networks (SNNs) have emerged as a potential alternative to traditional deep learning frameworks, due to their promise to provide increased compute efficiency on event-driven neuromorphic hardware. However, to perform well on complex vision applications, most SNN training frameworks yield large inference latency which translates to increased spike activity and reduced energy efficiency. Hence,minimizing average spike activity while preserving accuracy indeep SNNs remains a significant challenge and opportunity.This paper presents a non-iterative SNN training technique thatachieves ultra-high compression with reduced spiking activitywhile maintaining high inference accuracy. In particular, our framework first uses the attention-maps of an un compressed meta-model to yield compressed ANNs. This step can be tuned to support both irregular and structured channel pruning to leverage computational benefits over a broad range of platforms. The framework then performs sparse-learning-based supervised SNN training using direct inputs. During the training, it jointly optimizes the SNN weight, threshold, and leak parameters to drastically minimize the number of time steps required while retaining compression. To evaluate the merits of our approach, we performed experiments with variants of VGG and ResNet, on both CIFAR-10 and CIFAR-100, and VGG16 on Tiny-ImageNet.The SNN models generated through the proposed technique yield SOTA compression ratios of up to 33.4x with no significant drops in accuracy compared to baseline unpruned counterparts. Compared to existing SNN pruning methods, we achieve up to 8.3x higher compression with improved accuracy.
Design of a user-friendly control system for planetary rovers with CPS feature
Jun 28, 2021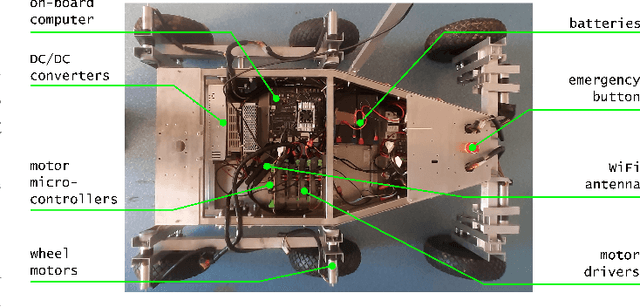
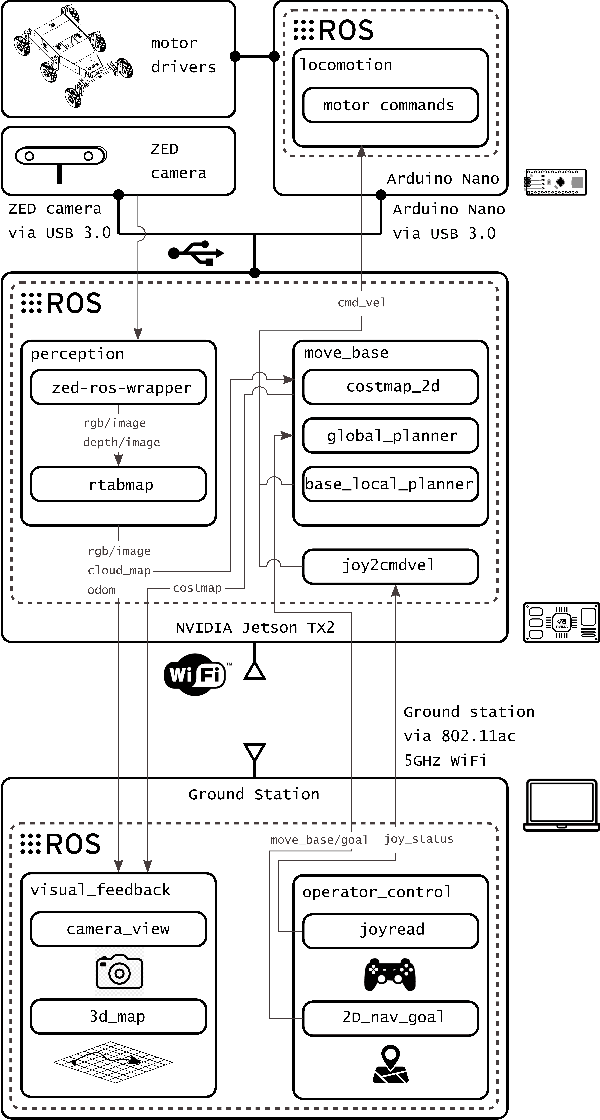
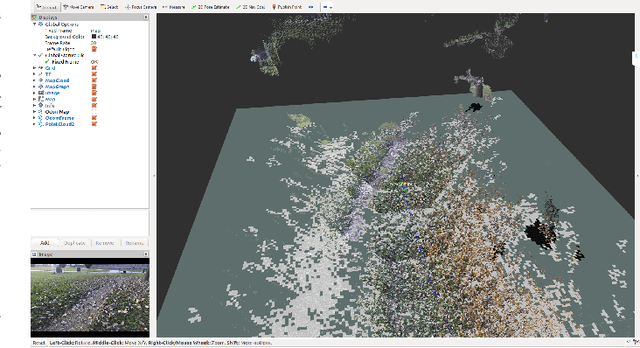
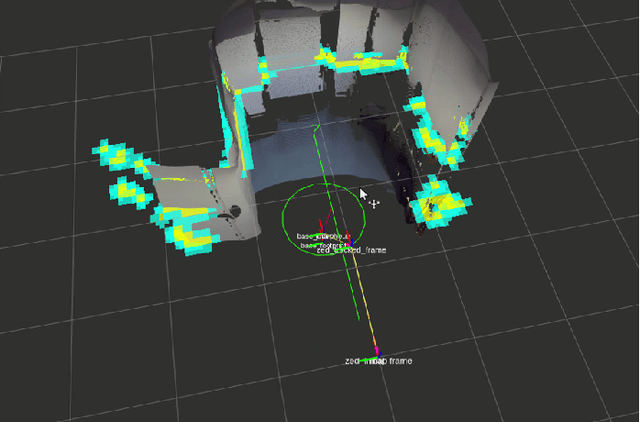
In this paper, we present a user-friendly planetary rover's control system for low latency surface telerobotic. Thanks to the proposed system, an operator can comfortably give commands through the control base station to a rover using commercially available off-the-shelf (COTS) joysticks or by command sequencing with interactive monitoring on the sensed map of the environment. During operations, high situational awareness is made possible thanks to 3D map visualization. The map of the environment is built on the on-board computer by processing the rover's camera images with a visual Simultaneous Localization and Mapping (SLAM) algorithm. It is transmitted via Wi-Fi and displayed on the control base station screen in near real-time. The navigation stack takes as input the visual SLAM data to build a cost map to find the minimum cost path. By interacting with the virtual map, the rover exhibits properties of a Cyber Physical System (CPS) for its self-awareness capabilities. The software architecture is based on the Robot Operative System (ROS) middleware. The system design and the preliminary field test results are shown in the paper.