 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multivariate Time Series Classification with WEASEL+MUSE
Aug 17, 2018
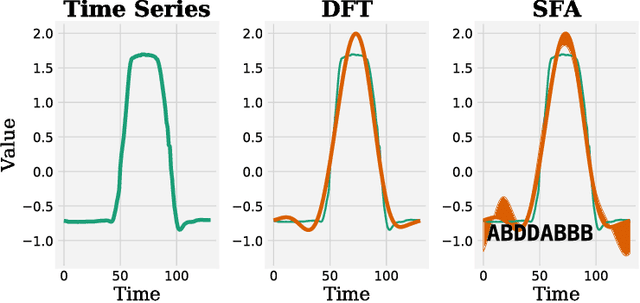
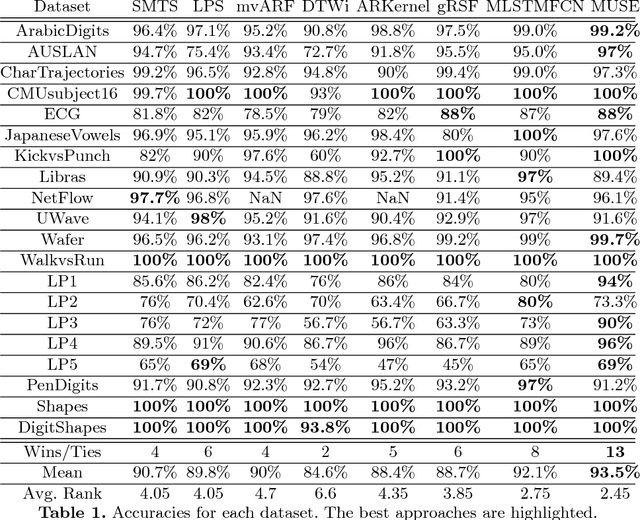

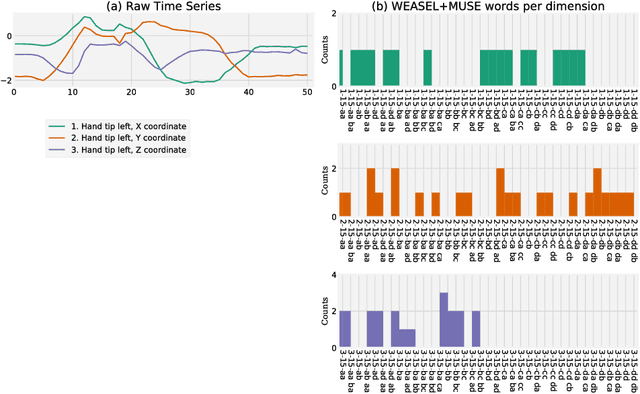
Multivariate time series (MTS) arise when multiple interconnected sensors record data over time. Dealing with this high-dimensional data is challenging for every classifier for at least two aspects: First, an MTS is not only characterized by individual feature values, but also by the interplay of features in different dimensions. Second, this typically adds large amounts of irrelevant data and noise. We present our novel MTS classifier WEASEL+MUSE which addresses both challenges. WEASEL+MUSE builds a multivariate feature vector, first using a sliding-window approach applied to each dimension of the MTS, then extracts discrete features per window and dimension. The feature vector is subsequently fed through feature selection, removing non-discriminative features, and analysed by a machine learning classifier. The novelty of WEASEL+MUSE lies in its specific way of extracting and filtering multivariate features from MTS by encoding context information into each feature. Still the resulting feature set is small, yet very discriminative and useful for MTS classification. Based on a popular benchmark of 20 MTS datasets, we found that WEASEL+MUSE is among the most accurate classifiers, when compared to the state of the art. The outstanding robustness of WEASEL+MUSE is further confirmed based on motion gesture recognition data, where it out-of-the-box achieved similar accuracies as domain-specific methods.
Boosting hazard regression with time-varying covariates
Feb 09, 2018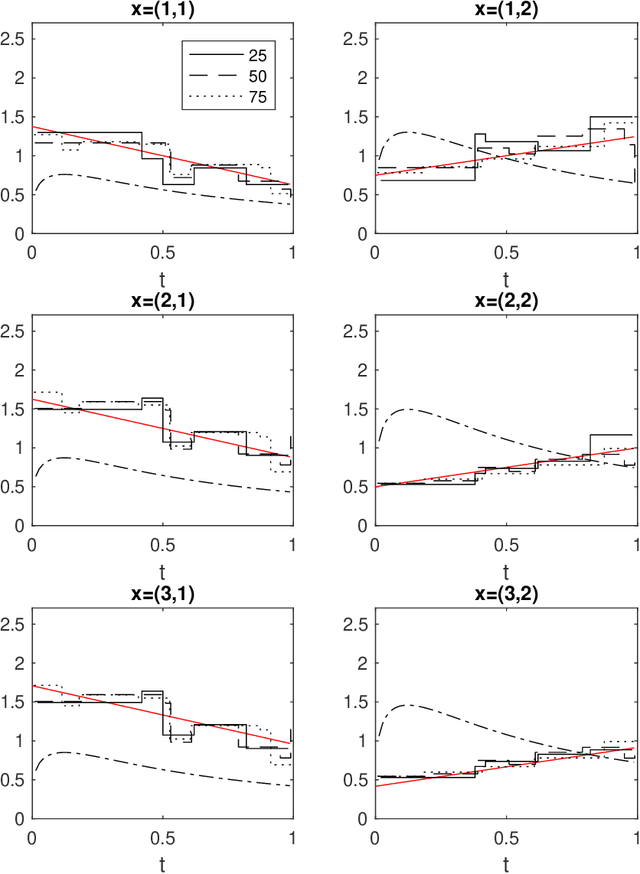

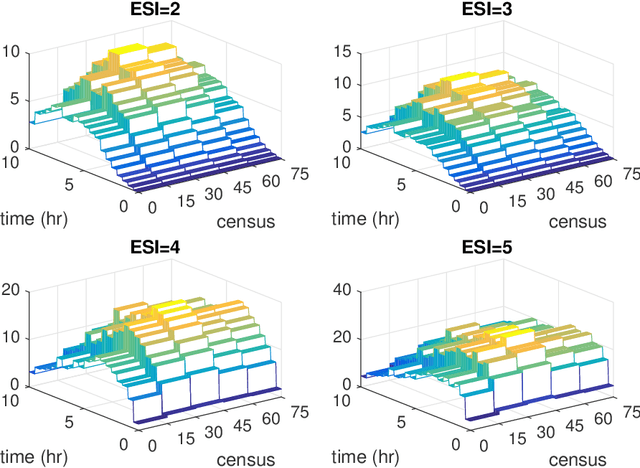
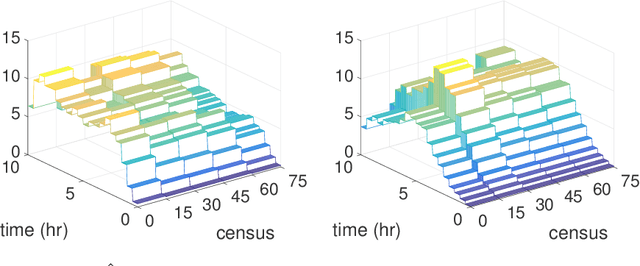
Consider a left-truncated right-censored survival process whose evolution depends on time-varying covariates. Given functional data samples from the process, we propose a practical boosting procedure for estimating its log-intensity function. Our method does not require any separability assumptions like Cox proportional- or Aalen additive-hazards, thus it can flexibly capture time-covariate interactions. The estimator is consistent if the model is correctly specified; alternatively an oracle inequality can be demonstrated for tree-based models. We use the procedure to shed new light on a question from the operations literature concerning the effect of workload on service rates in an emergency department.
Efficient PAC Reinforcement Learning in Regular Decision Processes
May 21, 2021



Recently regular decision processes have been proposed as a well-behaved form of non-Markov decision process. Regular decision processes are characterised by a transition function and a reward function that depend on the whole history, though regularly (as in regular languages). In practice both the transition and the reward functions can be seen as finite transducers. We study reinforcement learning in regular decision processes. Our main contribution is to show that a near-optimal policy can be PAC-learned in polynomial time in a set of parameters that describe the underlying decision process. We argue that the identified set of parameters is minimal and it reasonably captures the difficulty of a regular decision process.
Real-time 3D Traffic Cone Detection for Autonomous Driving
Feb 06, 2019
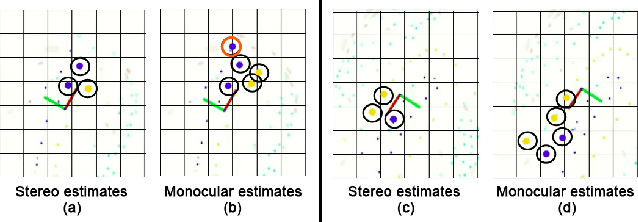
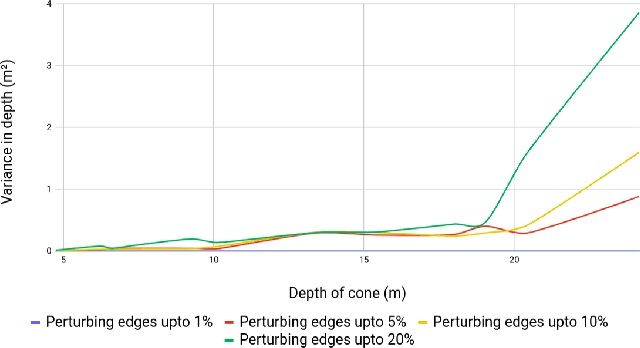

Considerable progress has been made in semantic scene understanding of road scenes with monocular cameras. It is, however, mainly related to certain classes such as cars and pedestrians. This work investigates traffic cones, an object class crucial for traffic control in the context of autonomous vehicles. 3D object detection using images from a monocular camera is intrinsically an ill-posed problem. In this work, we leverage the unique structure of traffic cones and propose a pipelined approach to the problem. Specifically, we first detect cones in images by a tailored 2D object detector; then, the spatial arrangement of keypoints on a traffic cone are detected by our deep structural regression network, where the fact that the cross-ratio is projection invariant is leveraged for network regularization; finally, the 3D position of cones is recovered by the classical Perspective n-Point algorithm. Extensive experiments show that our approach can accurately detect traffic cones and estimate their position in the 3D world in real time. The proposed method is also deployed on a real-time, critical system. It runs efficiently on the low-power Jetson TX2, providing accurate 3D position estimates, allowing a race-car to map and drive autonomously on an unseen track indicated by traffic cones. With the help of robust and accurate perception, our race-car won both Formula Student Competitions held in Italy and Germany in 2018, cruising at a top-speed of 54 kmph. Visualization of the complete pipeline, mapping and navigation can be found on our project page.
Dynamic Graph Convolutional Recurrent Network for Traffic Prediction: Benchmark and Solution
May 03, 2021
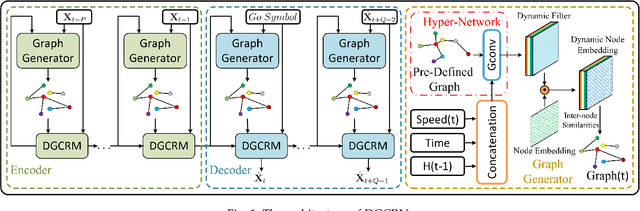

Traffic prediction is the cornerstone of an intelligent transportation system. Accurate traffic forecasting is essential for the applications of smart cities, i.e., intelligent traffic management and urban planning. Although various methods are proposed for spatio-temporal modeling, they ignore the dynamic characteristics of correlations among locations on road networks. Meanwhile, most Recurrent Neural Network (RNN) based works are not efficient enough due to their recurrent operations. Additionally, there is a severe lack of fair comparison among different methods on the same datasets. To address the above challenges, in this paper, we propose a novel traffic prediction framework, named Dynamic Graph Convolutional Recurrent Network (DGCRN). In DGCRN, hyper-networks are designed to leverage and extract dynamic characteristics from node attributes, while the parameters of dynamic filters are generated at each time step. We filter the node embeddings and then use them to generate a dynamic graph, which is integrated with a pre-defined static graph. As far as we know, we are the first to employ a generation method to model fine topology of dynamic graph at each time step. Further, to enhance efficiency and performance, we employ a training strategy for DGCRN by restricting the iteration number of decoder during forward and backward propagation. Finally, a reproducible standardized benchmark and a brand new representative traffic dataset are opened for fair comparison and further research. Extensive experiments on three datasets demonstrate that our model outperforms 15 baselines consistently.
A Computationally Efficient Approach to Non-cooperative Target Detection and Tracking with Almost No A-priori Information
Apr 20, 2021
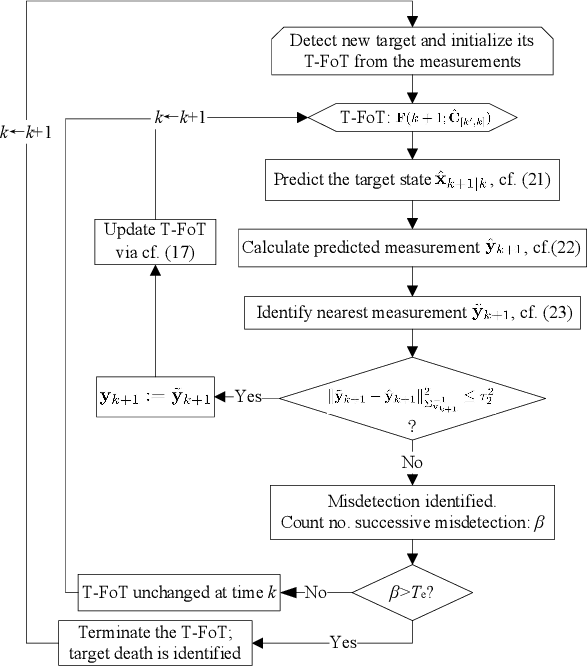
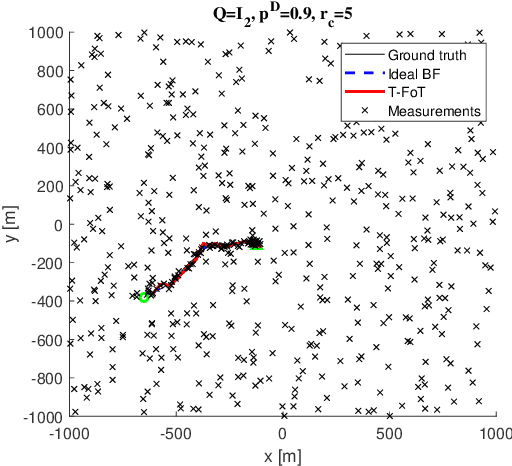
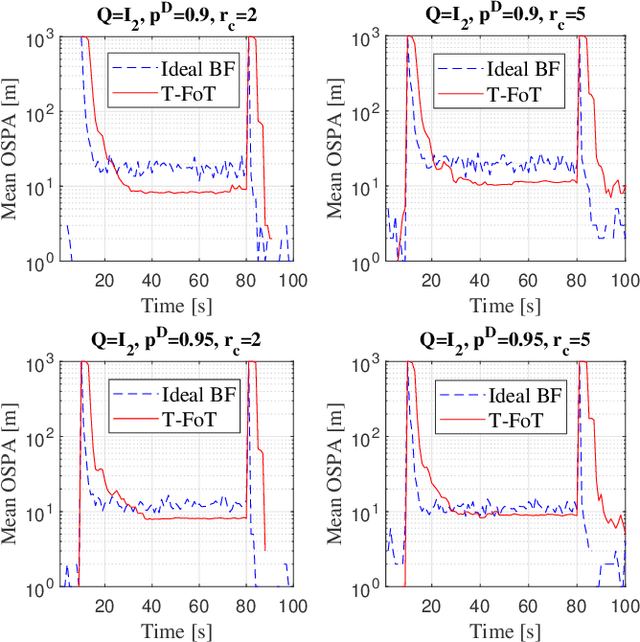
This paper addresses the problem of real-time detection and tracking of a non-cooperative target in the challenging scenario with almost no a-priori information about target birth, death, dynamics and detection probability. Furthermore, there are false and missing data at unknown yet low rates in the measurements. The only information given in advance is about the target-measurement model and the constraint that there is no more than one target in the scenario. To solve these challenges, we model the movement of the target by using a trajectory function of time (T-FoT). Data-driven T-FoT initiation and termination strategies are proposed for identifying the (re-)appearance and disappearance of the target. During the existence of the target, real target measurements are distinguished from clutter if the target indeed exists and is detected, in order to update the T-FoT at each scan for which we design a least-squares estimator. Simulations using either linear or nonlinear systems are conducted to demonstrate the effectiveness of our approach in comparison with the Bayes optimal Bernoulli filters. The results show that our approach is comparable to the perfectly-modeled filters, even outperforms them in some cases while requiring much less a-prior information and computing much faster.
Estimating MRI Image Quality via Image Reconstruction Uncertainty
Jun 21, 2021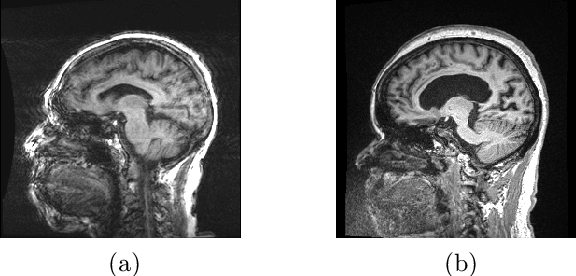
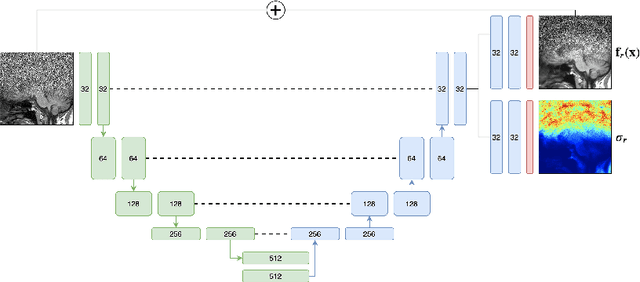
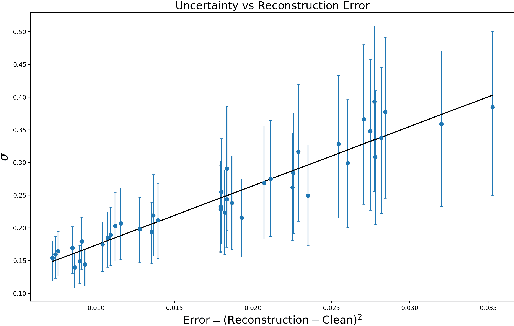
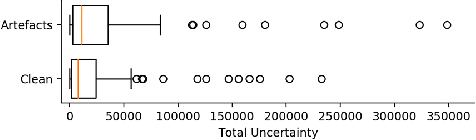
Quality control (QC) in medical image analysis is time-consuming and laborious, leading to increased interest in automated methods. However, what is deemed suitable quality for algorithmic processing may be different from human-perceived measures of visual quality. In this work, we pose MR image quality assessment from an image reconstruction perspective. We train Bayesian CNNs using a heteroscedastic uncertainty model to recover clean images from noisy data, providing measures of uncertainty over the predictions. This framework enables us to divide data corruption into learnable and non-learnable components and leads us to interpret the predictive uncertainty as an estimation of the achievable recovery of an image. Thus, we argue that quality control for visual assessment cannot be equated to quality control for algorithmic processing. We validate this statement in a multi-task experiment combining artefact recovery with uncertainty prediction and grey matter segmentation. Recognising this distinction between visual and algorithmic quality has the impact that, depending on the downstream task, less data can be excluded based on ``visual quality" reasons alone.
A High-order Tuner for Accelerated Learning and Control
Mar 23, 2021Gradient-descent based iterative algorithms pervade a variety of problems in estimation, prediction, learning, control, and optimization. Recently iterative algorithms based on higher-order information have been explored in an attempt to lead to accelerated learning. In this paper, we explore a specific a high-order tuner that has been shown to result in stability with time-varying regressors in linearly parametrized systems, and accelerated convergence with constant regressors. We show that this tuner continues to provide bounded parameter estimates even if the gradients are corrupted by noise. Additionally, we also show that the parameter estimates converge exponentially to a compact set whose size is dependent on noise statistics. As the HT algorithms can be applied to a wide range of problems in estimation, filtering, control, and machine learning, the result obtained in this paper represents an important extension to the topic of real-time and fast decision making.
Physics-Informed Deep Reversible Regression Model for Temperature Field Reconstruction of Heat-Source Systems
Jul 05, 2021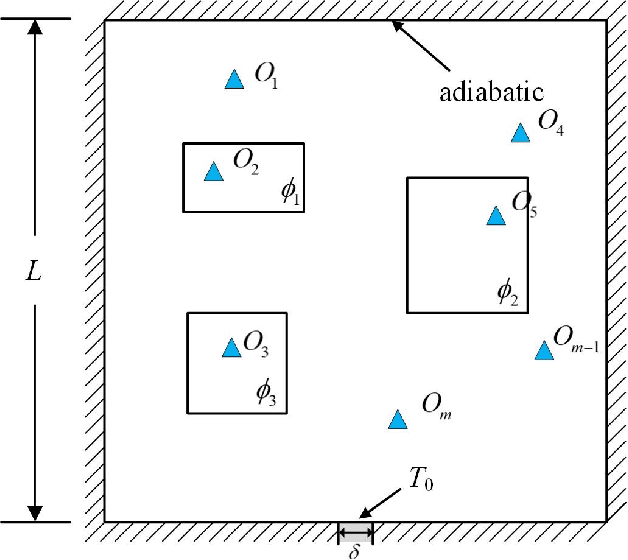
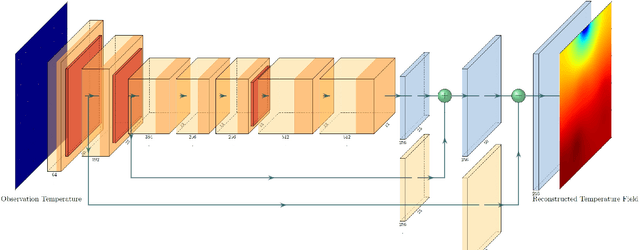
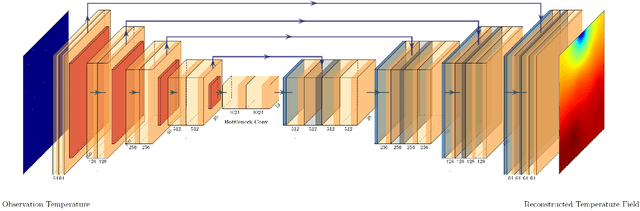
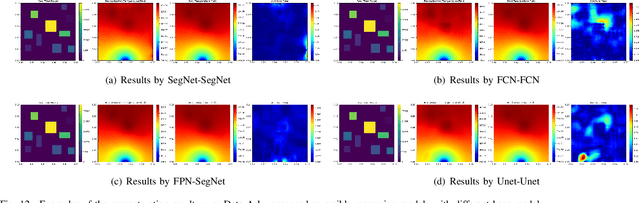
Temperature monitoring during the life time of heat source components in engineering systems becomes essential to guarantee the normal work and the working life of these components. However, prior methods, which mainly use the interpolate estimation to reconstruct the temperature field from limited monitoring points, require large amounts of temperature tensors for an accurate estimation. This may decrease the availability and reliability of the system and sharply increase the monitoring cost. To solve this problem, this work develops a novel physics-informed deep reversible regression models for temperature field reconstruction of heat-source systems (TFR-HSS), which can better reconstruct the temperature field with limited monitoring points unsupervisedly. First, we define the TFR-HSS task mathematically, and numerically model the task, and hence transform the task as an image-to-image regression problem. Then this work develops the deep reversible regression model which can better learn the physical information, especially over the boundary. Finally, considering the physical characteristics of heat conduction as well as the boundary conditions, this work proposes the physics-informed reconstruction loss including four training losses and jointly learns the deep surrogate model with these losses unsupervisedly. Experimental studies have conducted over typical two-dimensional heat-source systems to demonstrate the effectiveness of the proposed method.
Federated Learning with Positive and Unlabeled Data
Jun 21, 2021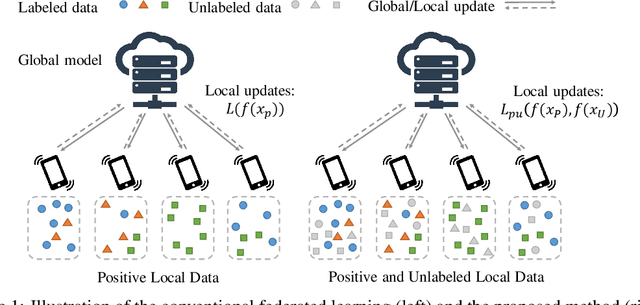
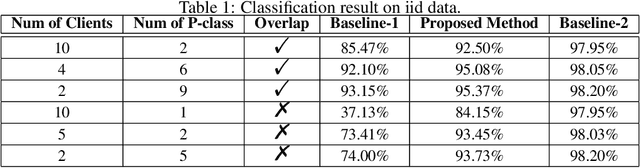
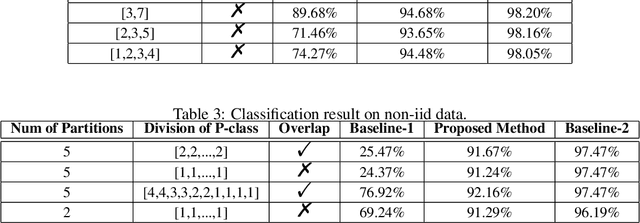
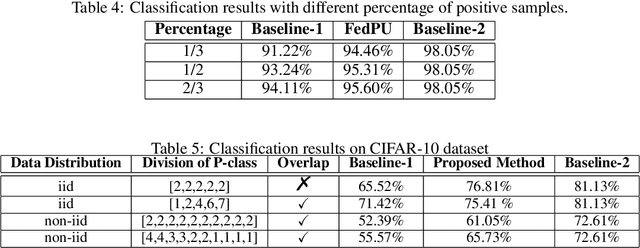
We study the problem of learning from positive and unlabeled (PU) data in the federated setting, where each client only labels a little part of their dataset due to the limitation of resources and time. Different from the settings in traditional PU learning where the negative class consists of a single class, the negative samples which cannot be identified by a client in the federated setting may come from multiple classes which are unknown to the client. Therefore, existing PU learning methods can be hardly applied in this situation. To address this problem, we propose a novel framework, namely Federated learning with Positive and Unlabeled data (FedPU), to minimize the expected risk of multiple negative classes by leveraging the labeled data in other clients. We theoretically prove that the proposed FedPU can achieve a generalization bound which is no worse than $C\sqrt{C}$ times (where $C$ denotes the number of classes) of the fully-supervised model. Empirical experiments show that the FedPU can achieve much better performance than conventional learning methods which can only use positive data.