 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Sample: Data-Driven Sampling and Reconstruction of FRI Signals
Jun 28, 2021

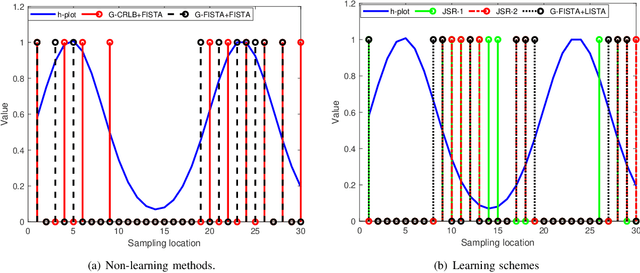
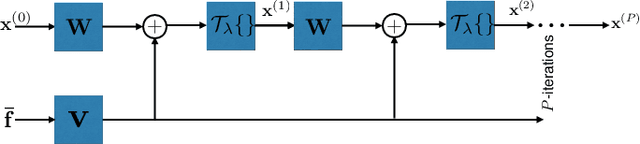
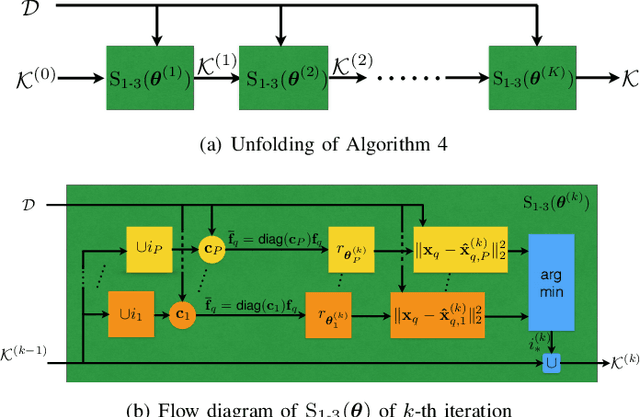
Finite-rate-of-innovation (FRI) signals are ubiquitous in applications such as radar, ultrasound, and time of flight imaging. Due to their finite degrees of freedom, FRI signals can be sampled at sub-Nyquist rates using appropriate sampling kernels and reconstructed using sparse-recovery algorithms. Typically, Fourier samples of the FRI signals are used for reconstruction. The reconstruction quality depends on the choice of Fourier samples and recovery method. In this paper, we consider to jointly optimize the choice of Fourier samples and reconstruction parameters. Our framework is a combination of a greedy subsampling algorithm and a learning-based sparse recovery method. Unlike existing techniques, the proposed algorithm can flexibly handle changes in the sampling rate and does not suffer from differentiability issues during training. Importantly, exact knowledge of the FRI pulse is not required. Numerical results show that, for a given number of samples, the proposed joint design leads to lower reconstruction error for FRI signals compared to independent data-driven design methods for both noisy and clean samples. Our learning to sample approach can be readily applied to other sampling setups as well including compressed sensing problems.
Designing Efficient and High-performance AI Accelerators with Customized STT-MRAM
Apr 06, 2021
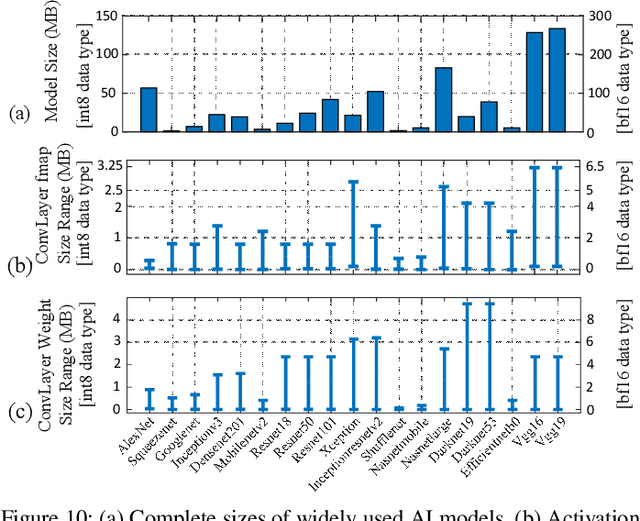
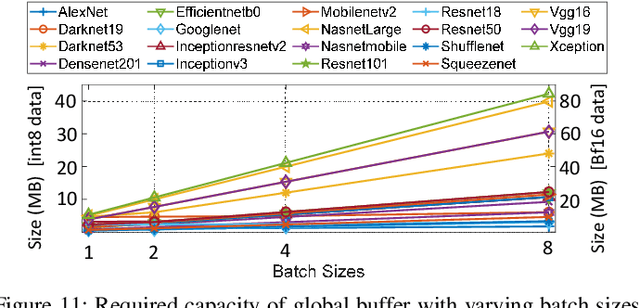
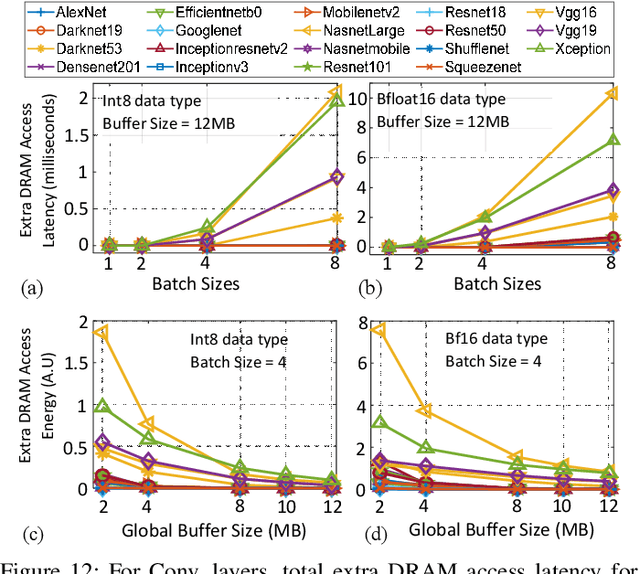
In this paper, we demonstrate the design of efficient and high-performance AI/Deep Learning accelerators with customized STT-MRAM and a reconfigurable core. Based on model-driven detailed design space exploration, we present the design methodology of an innovative scratchpad-assisted on-chip STT-MRAM based buffer system for high-performance accelerators. Using analytically derived expression of memory occupancy time of AI model weights and activation maps, the volatility of STT-MRAM is adjusted with process and temperature variation aware scaling of thermal stability factor to optimize the retention time, energy, read/write latency, and area of STT-MRAM. From the analysis of modern AI workloads and accelerator implementation in 14nm technology, we verify the efficacy of our designed AI accelerator with STT-MRAM STT-AI. Compared to an SRAM-based implementation, the STT-AI accelerator achieves 75% area and 3% power savings at iso-accuracy. Furthermore, with a relaxed bit error rate and negligible AI accuracy trade-off, the designed STT-AI Ultra accelerator achieves 75.4%, and 3.5% savings in area and power, respectively over regular SRAM-based accelerators.
An End-to-End Khmer Optical Character Recognition using Sequence-to-Sequence with Attention
Jun 21, 2021
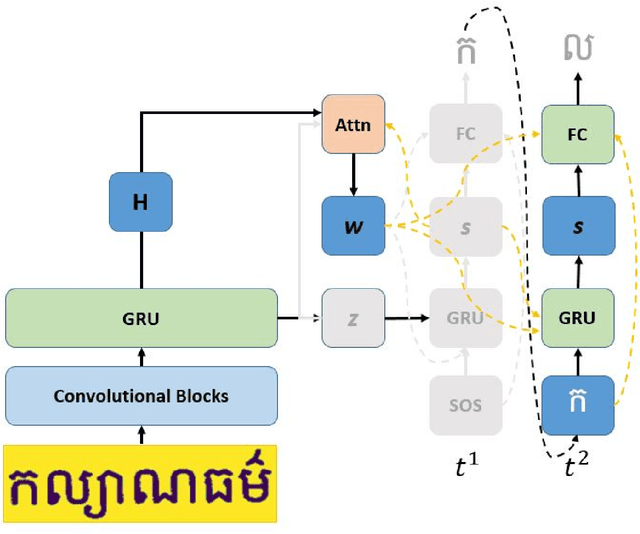
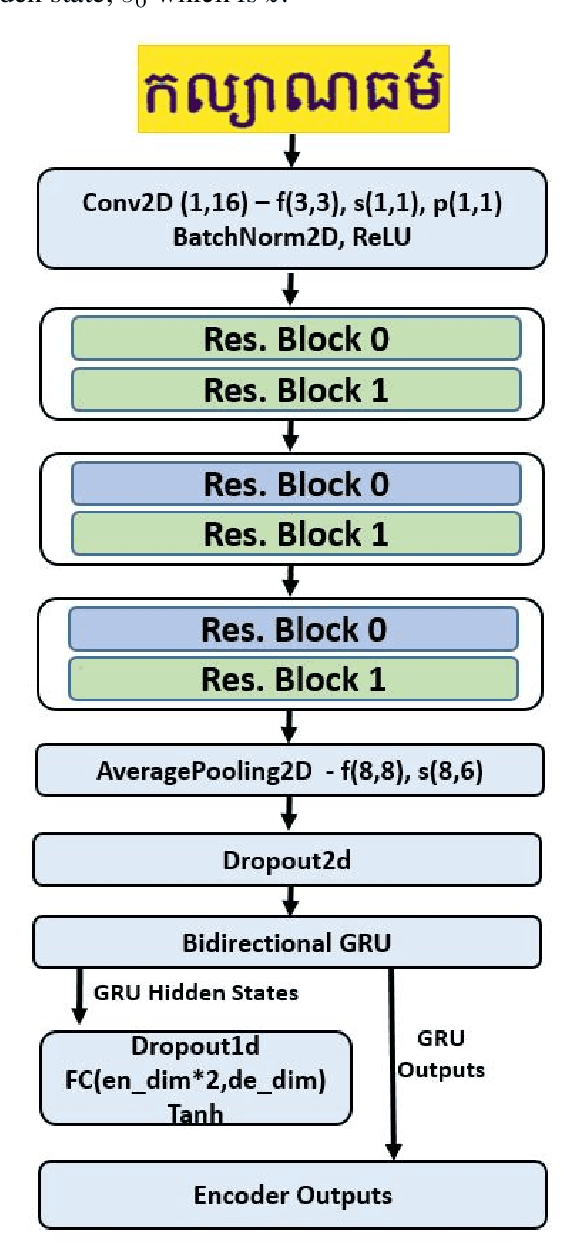
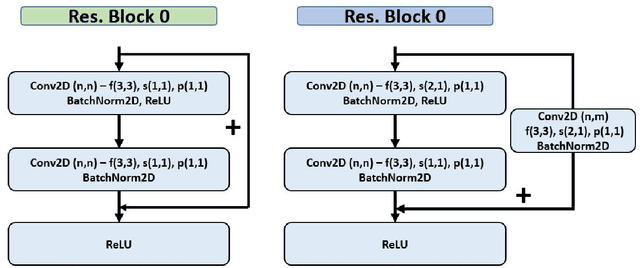
This paper presents an end-to-end deep convolutional recurrent neural network solution for Khmer optical character recognition (OCR) task. The proposed solution uses a sequence-to-sequence (Seq2Seq) architecture with attention mechanism. The encoder extracts visual features from an input text-line image via layers of residual convolutional blocks and a layer of gated recurrent units (GRU). The features are encoded in a single context vector and a sequence of hidden states which are fed to the decoder for decoding one character at a time until a special end-of-sentence (EOS) token is reached. The attention mechanism allows the decoder network to adaptively select parts of the input image while predicting a target character. The Seq2Seq Khmer OCR network was trained on a large collection of computer-generated text-line images for seven common Khmer fonts. The proposed model's performance outperformed the state-of-art Tesseract OCR engine for Khmer language on the 3000-images test set by achieving a character error rate (CER) of 1% vs 3%.
False Negative Reduction in Video Instance Segmentation using Uncertainty Estimates
Jun 28, 2021

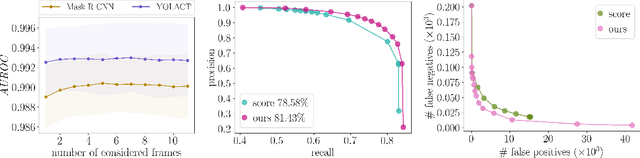
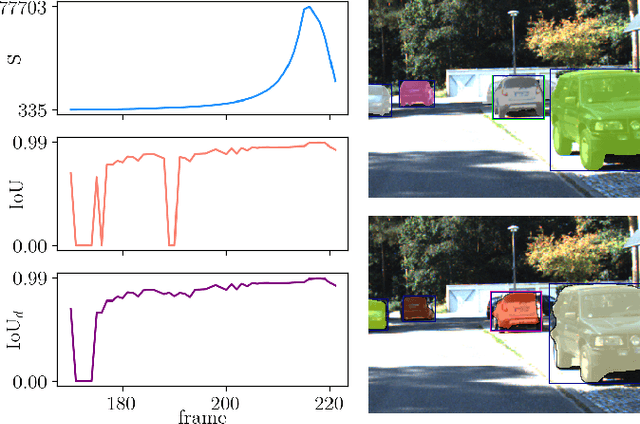
Instance segmentation of images is an important tool for automated scene understanding. Neural networks are usually trained to optimize their overall performance in terms of accuracy. Meanwhile, in applications such as automated driving, an overlooked pedestrian seems more harmful than a falsely detected one. In this work, we present a false negative detection method for image sequences based on inconsistencies in time series of tracked instances given the availability of image sequences in online applications. As the number of instances can be greatly increased by this algorithm, we apply a false positive pruning using uncertainty estimates aggregated over instances. To this end, instance-wise metrics are constructed which characterize uncertainty and geometry of a given instance or are predicated on depth estimation. The proposed method serves as a post-processing step applicable to any neural network that can also be trained on single frames only. In our tests, we obtain an improved trade-off between false negative and false positive instances by our fused detection approach in comparison to the use of an ordinary score value provided by the instance segmentation network during inference.
Adaptively Optimize Content Recommendation Using Multi Armed Bandit Algorithms in E-commerce
Jul 30, 2021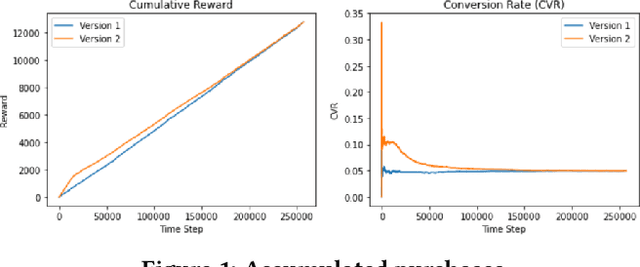
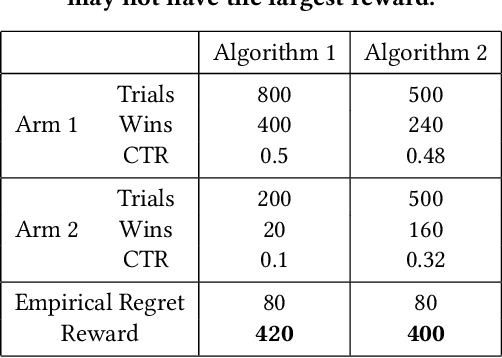
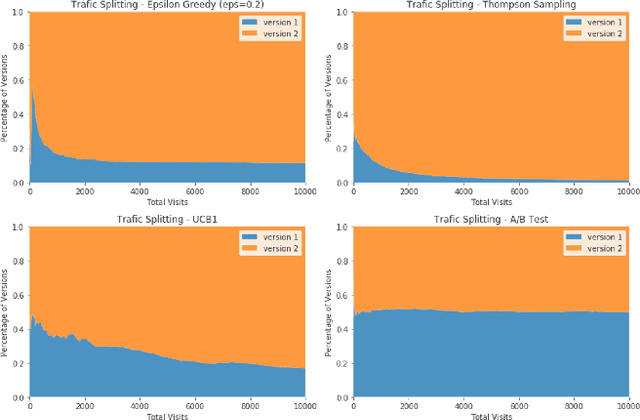
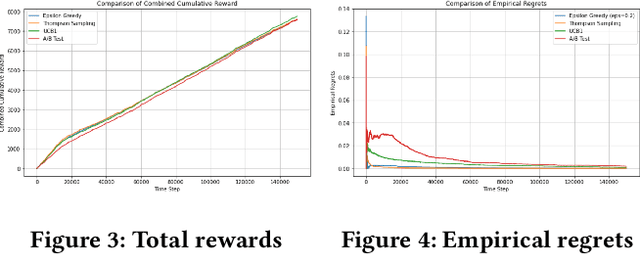
E-commerce sites strive to provide users the most timely relevant information in order to reduce shopping frictions and increase customer satisfaction. Multi armed bandit models (MAB) as a type of adaptive optimization algorithms provide possible approaches for such purposes. In this paper, we analyze using three classic MAB algorithms, epsilon-greedy, Thompson sampling (TS), and upper confidence bound 1 (UCB1) for dynamic content recommendations, and walk through the process of developing these algorithms internally to solve a real world e-commerce use case. First, we analyze the three MAB algorithms using simulated purchasing datasets with non-stationary reward distributions to simulate the possible time-varying customer preferences, where the traffic allocation dynamics and the accumulative rewards of different algorithms are studied. Second, we compare the accumulative rewards of the three MAB algorithms with more than 1,000 trials using actual historical A/B test datasets. We find that the larger difference between the success rates of competing recommendations the more accumulative rewards the MAB algorithms can achieve. In addition, we find that TS shows the highest average accumulative rewards under different testing scenarios. Third, we develop a batch-updated MAB algorithm to overcome the delayed reward issue in e-commerce and enable an online content optimization on our App homepage. For a state-of-the-art comparison, a real A/B test among our batch-updated MAB algorithm, a third-party MAB solution, and the default business logic are conducted. The result shows that our batch-updated MAB algorithm outperforms the counterparts and achieves 6.13% relative click-through rate (CTR) increase and 16.1% relative conversion rate (CVR) increase compared to the default experience, and 2.9% relative CTR increase and 1.4% relative CVR increase compared to the external MAB service.
Online Learning with Radial Basis Function Networks
Mar 15, 2021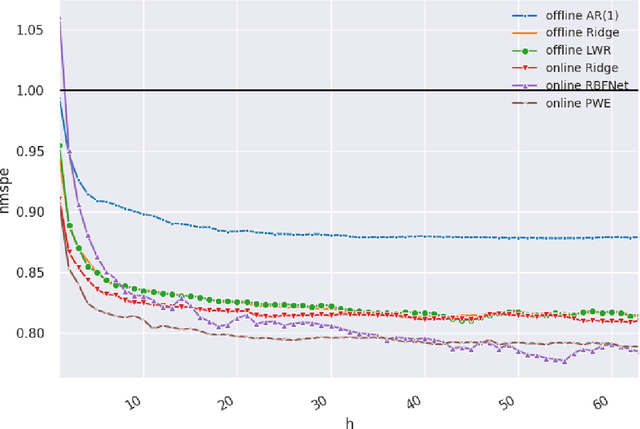
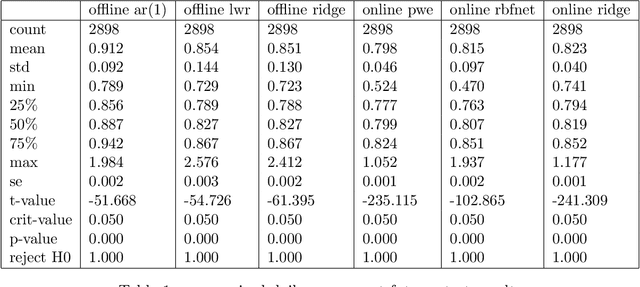
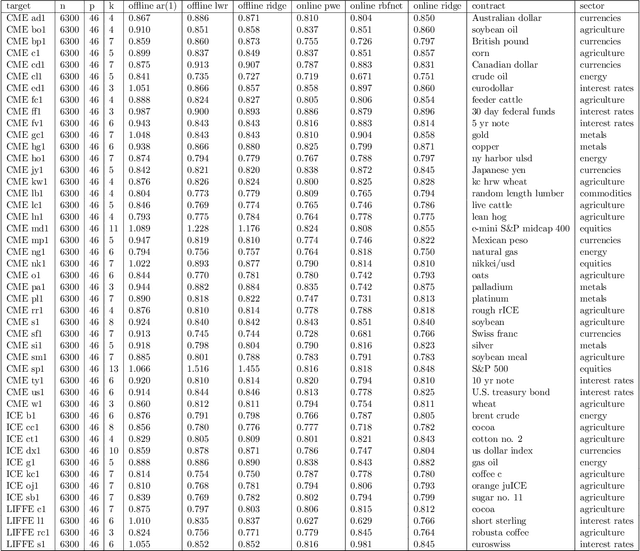
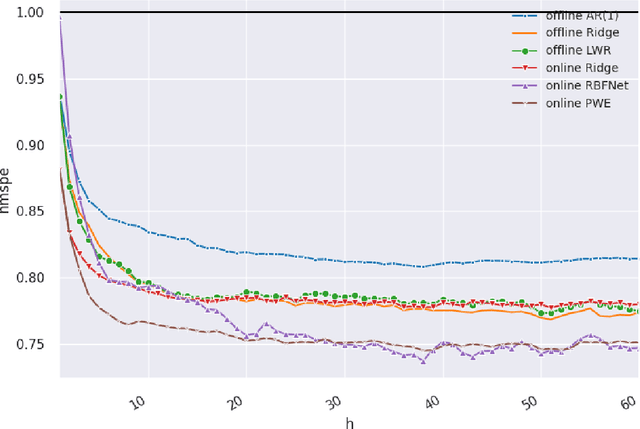
We investigate the benefits of feature selection, nonlinear modelling and online learning with forecasting in financial time series. We consider the sequential and continual learning sub-genres of online learning. Through empirical experimentation, which involves long term forecasting in daily sampled cross-asset futures, and short term forecasting in minutely sampled cash currency pairs, we find that the online learning techniques outperform the offline learning ones. We also find that, in the subset of models we use, sequential learning in time with online Ridge regression, provides the best next step ahead forecasts, and continual learning with an online radial basis function network, provides the best multi-step ahead forecasts. We combine the benefits of both in a precision weighted ensemble of the forecast errors and find superior forecast performance overall.
Guidelines and Benchmarks for Deployment of Deep Learning Models on Smartphones as Real-Time Apps
Jan 08, 2019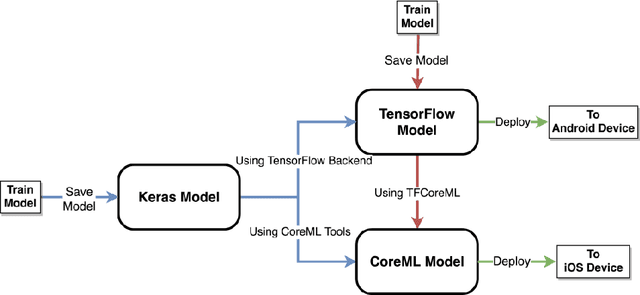
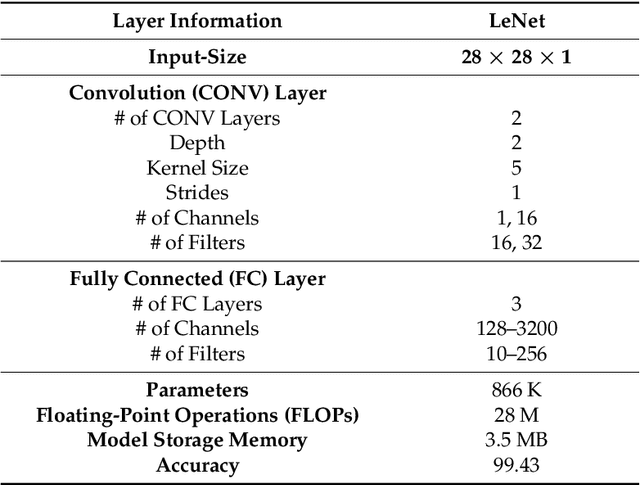
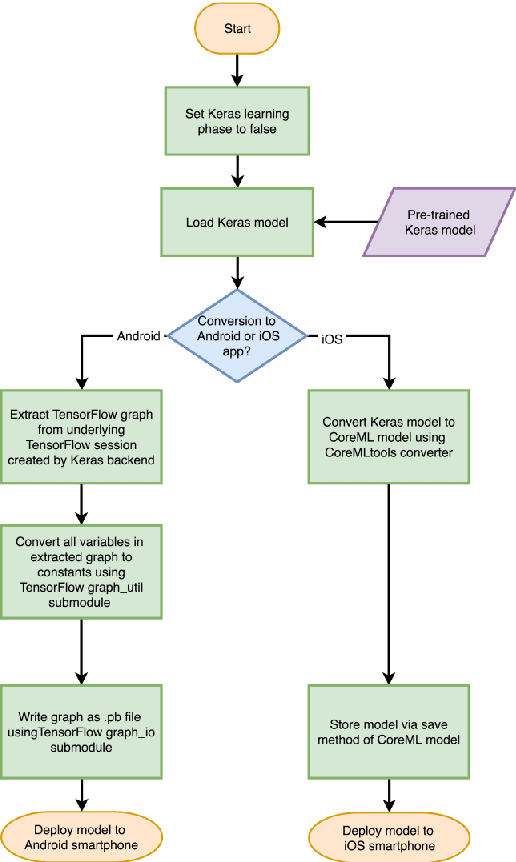
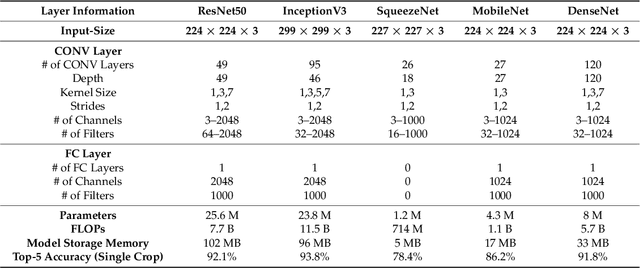
Deep learning solutions are being increasingly used in mobile applications. Although there are many open-source software tools for the development of deep learning solutions, there are no guidelines in one place in a unified manner for using these tools towards real-time deployment of these solutions on smartphones. From the variety of available deep learning tools, the most suited ones are used in this paper to enable real-time deployment of deep learning inference networks on smartphones. A uniform flow of implementation is devised for both Android and iOS smartphones. The advantage of using multi-threading to achieve or improve real-time throughputs is also showcased. A benchmarking framework consisting of accuracy, CPU/GPU consumption and real-time throughput is considered for validation purposes. The developed deployment approach allows deep learning models to be turned into real-time smartphone apps with ease based on publicly available deep learning and smartphone software tools. This approach is applied to six popular or representative convolutional neural network models and the validation results based on the benchmarking metrics are reported.
3D AGSE-VNet: An Automatic Brain Tumor MRI Data Segmentation Framework
Jul 26, 2021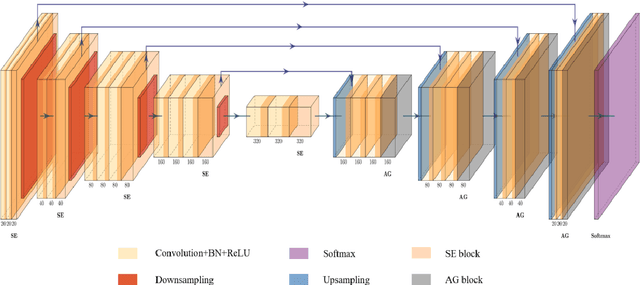
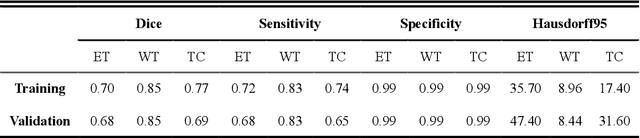
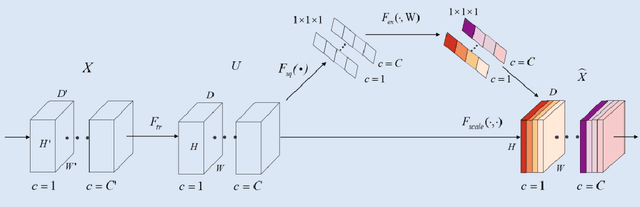
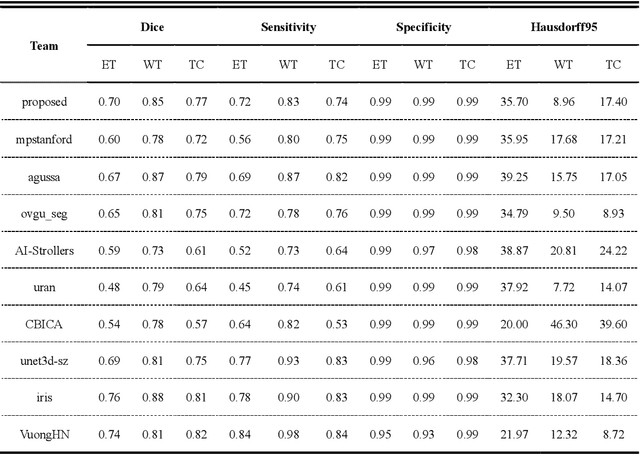
Background: Glioma is the most common brain malignant tumor, with a high morbidity rate and a mortality rate of more than three percent, which seriously endangers human health. The main method of acquiring brain tumors in the clinic is MRI. Segmentation of brain tumor regions from multi-modal MRI scan images is helpful for treatment inspection, post-diagnosis monitoring, and effect evaluation of patients. However, the common operation in clinical brain tumor segmentation is still manual segmentation, lead to its time-consuming and large performance difference between different operators, a consistent and accurate automatic segmentation method is urgently needed. Methods: To meet the above challenges, we propose an automatic brain tumor MRI data segmentation framework which is called AGSE-VNet. In our study, the Squeeze and Excite (SE) module is added to each encoder, the Attention Guide Filter (AG) module is added to each decoder, using the channel relationship to automatically enhance the useful information in the channel to suppress the useless information, and use the attention mechanism to guide the edge information and remove the influence of irrelevant information such as noise. Results: We used the BraTS2020 challenge online verification tool to evaluate our approach. The focus of verification is that the Dice scores of the whole tumor (WT), tumor core (TC) and enhanced tumor (ET) are 0.68, 0.85 and 0.70, respectively. Conclusion: Although MRI images have different intensities, AGSE-VNet is not affected by the size of the tumor, and can more accurately extract the features of the three regions, it has achieved impressive results and made outstanding contributions to the clinical diagnosis and treatment of brain tumor patients.
Leaf-FM: A Learnable Feature Generation Factorization Machine for Click-Through Rate Prediction
Jul 26, 2021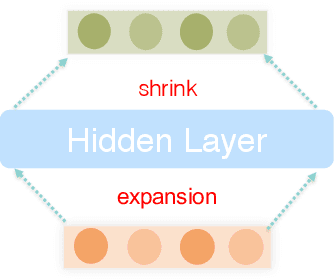

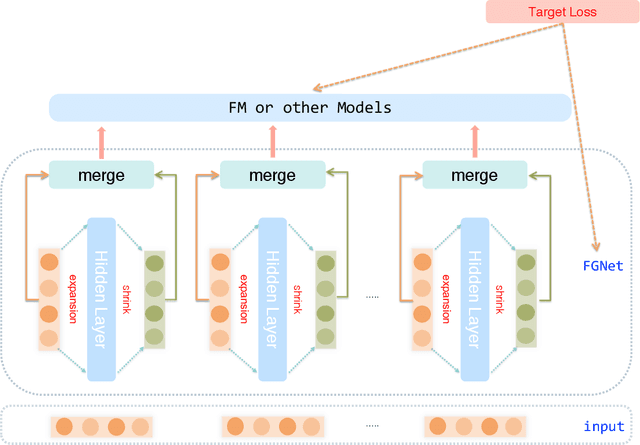
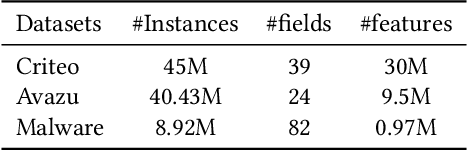
Click-through rate (CTR) prediction plays important role in personalized advertising and recommender systems. Though many models have been proposed such as FM, FFM and DeepFM in recent years, feature engineering is still a very important way to improve the model performance in many applications because using raw features can rarely lead to optimal results. For example, the continuous features are usually transformed to the power forms by adding a new feature to allow it to easily form non-linear functions of the feature. However, this kind of feature engineering heavily relies on peoples experience and it is both time consuming and labor consuming. On the other side, concise CTR model with both fast online serving speed and good model performance is critical for many real life applications. In this paper, we propose LeafFM model based on FM to generate new features from the original feature embedding by learning the transformation functions automatically. We also design three concrete Leaf-FM models according to the different strategies of combing the original and the generated features. Extensive experiments are conducted on three real-world datasets and the results show Leaf-FM model outperforms standard FMs by a large margin. Compared with FFMs, Leaf-FM can achieve significantly better performance with much less parameters. In Avazu and Malware dataset, add version Leaf-FM achieves comparable performance with some deep learning based models such as DNN and AutoInt. As an improved FM model, Leaf-FM has the same computation complexity with FM in online serving phase and it means Leaf-FM is applicable in many industry applications because of its better performance and high computation efficiency.
Efficient PAC Reinforcement Learning in Regular Decision Processes
May 21, 2021



Recently regular decision processes have been proposed as a well-behaved form of non-Markov decision process. Regular decision processes are characterised by a transition function and a reward function that depend on the whole history, though regularly (as in regular languages). In practice both the transition and the reward functions can be seen as finite transducers. We study reinforcement learning in regular decision processes. Our main contribution is to show that a near-optimal policy can be PAC-learned in polynomial time in a set of parameters that describe the underlying decision process. We argue that the identified set of parameters is minimal and it reasonably captures the difficulty of a regular decision process.