 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Coresets for constrained k-median and k-means clustering in low dimensional Euclidean space
Jun 14, 2021
We study (Euclidean) $k$-median and $k$-means with constraints in the streaming model. There have been recent efforts to design unified algorithms to solve constrained $k$-means problems without using knowledge of the specific constraint at hand aside from mild assumptions like the polynomial computability of feasibility under the constraint (compute if a clustering satisfies the constraint) or the presence of an efficient assignment oracle (given a set of centers, produce an optimal assignment of points to the centers which satisfies the constraint). These algorithms have a running time exponential in $k$, but can be applied to a wide range of constraints. We demonstrate that a technique proposed in 2019 for solving a specific constrained streaming $k$-means problem, namely fair $k$-means clustering, actually implies streaming algorithms for all these constraints. These work for low dimensional Euclidean space. [Note that there are more algorithms for streaming fair $k$-means today, in particular they exist for high dimensional spaces now as well.]
Dueling Bandits with Adversarial Sleeping
Jul 05, 2021
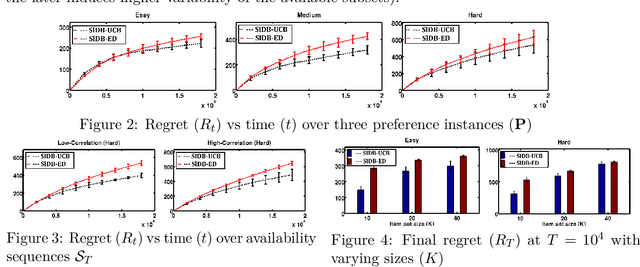
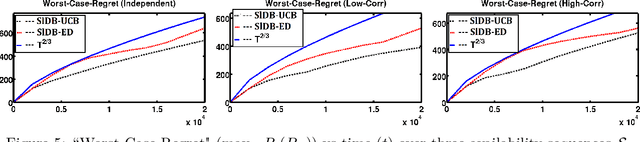
We introduce the problem of sleeping dueling bandits with stochastic preferences and adversarial availabilities (DB-SPAA). In almost all dueling bandit applications, the decision space often changes over time; eg, retail store management, online shopping, restaurant recommendation, search engine optimization, etc. Surprisingly, this `sleeping aspect' of dueling bandits has never been studied in the literature. Like dueling bandits, the goal is to compete with the best arm by sequentially querying the preference feedback of item pairs. The non-triviality however results due to the non-stationary item spaces that allow any arbitrary subsets items to go unavailable every round. The goal is to find an optimal `no-regret' policy that can identify the best available item at each round, as opposed to the standard `fixed best-arm regret objective' of dueling bandits. We first derive an instance-specific lower bound for DB-SPAA $\Omega( \sum_{i =1}^{K-1}\sum_{j=i+1}^K \frac{\log T}{\Delta(i,j)})$, where $K$ is the number of items and $\Delta(i,j)$ is the gap between items $i$ and $j$. This indicates that the sleeping problem with preference feedback is inherently more difficult than that for classical multi-armed bandits (MAB). We then propose two algorithms, with near optimal regret guarantees. Our results are corroborated empirically.
Simplifying Deep Reinforcement Learning via Self-Supervision
Jun 10, 2021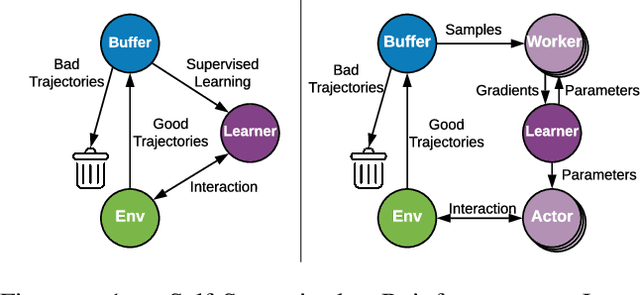

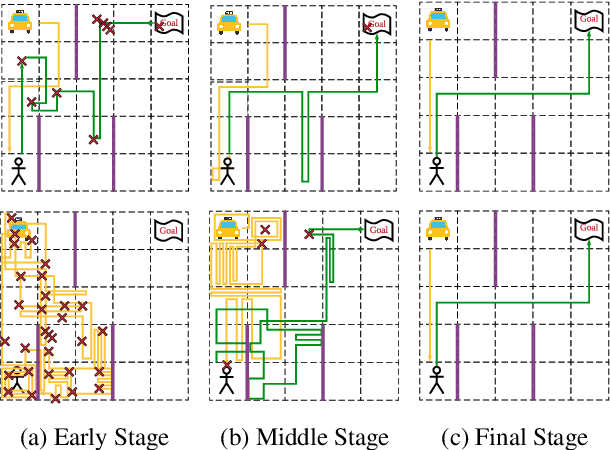

Supervised regression to demonstrations has been demonstrated to be a stable way to train deep policy networks. We are motivated to study how we can take full advantage of supervised loss functions for stably training deep reinforcement learning agents. This is a challenging task because it is unclear how the training data could be collected to enable policy improvement. In this work, we propose Self-Supervised Reinforcement Learning (SSRL), a simple algorithm that optimizes policies with purely supervised losses. We demonstrate that, without policy gradient or value estimation, an iterative procedure of ``labeling" data and supervised regression is sufficient to drive stable policy improvement. By selecting and imitating trajectories with high episodic rewards, SSRL is surprisingly competitive to contemporary algorithms with more stable performance and less running time, showing the potential of solving reinforcement learning with supervised learning techniques. The code is available at https://github.com/daochenzha/SSRL
Unified Spatio-Temporal Modeling for Traffic Forecasting using Graph Neural Network
Apr 28, 2021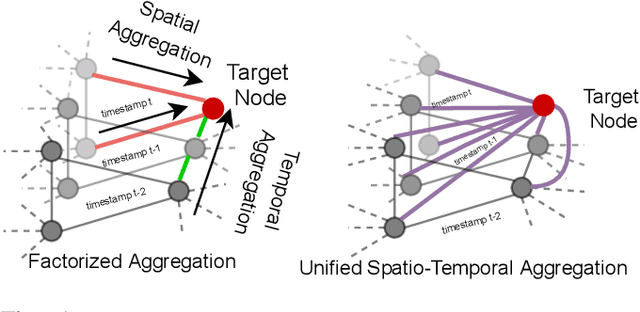
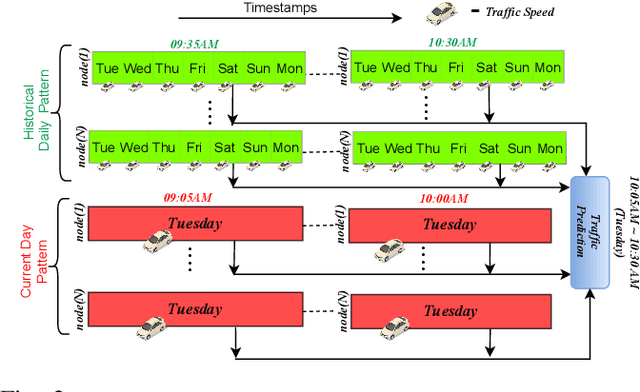
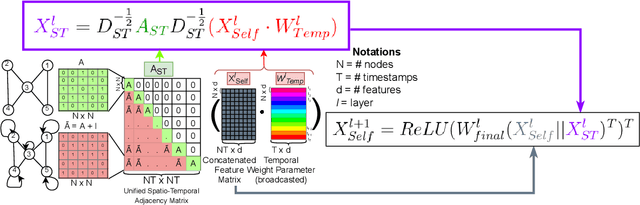

Research in deep learning models to forecast traffic intensities has gained great attention in recent years due to their capability to capture the complex spatio-temporal relationships within the traffic data. However, most state-of-the-art approaches have designed spatial-only (e.g. Graph Neural Networks) and temporal-only (e.g. Recurrent Neural Networks) modules to separately extract spatial and temporal features. However, we argue that it is less effective to extract the complex spatio-temporal relationship with such factorized modules. Besides, most existing works predict the traffic intensity of a particular time interval only based on the traffic data of the previous one hour of that day. And thereby ignores the repetitive daily/weekly pattern that may exist in the last hour of data. Therefore, we propose a Unified Spatio-Temporal Graph Convolution Network (USTGCN) for traffic forecasting that performs both spatial and temporal aggregation through direct information propagation across different timestamp nodes with the help of spectral graph convolution on a spatio-temporal graph. Furthermore, it captures historical daily patterns in previous days and current-day patterns in current-day traffic data. Finally, we validate our work's effectiveness through experimental analysis, which shows that our model USTGCN can outperform state-of-the-art performances in three popular benchmark datasets from the Performance Measurement System (PeMS). Moreover, the training time is reduced significantly with our proposed USTGCN model.
Federated Myopic Community Detection with One-shot Communication
Jun 14, 2021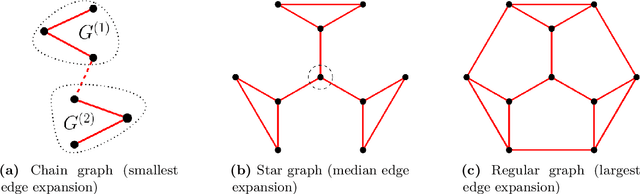
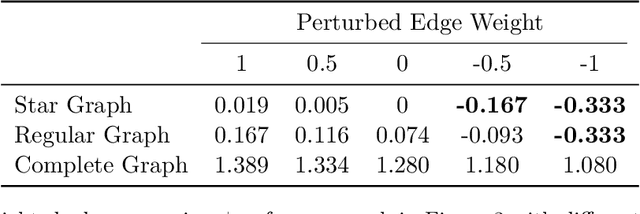
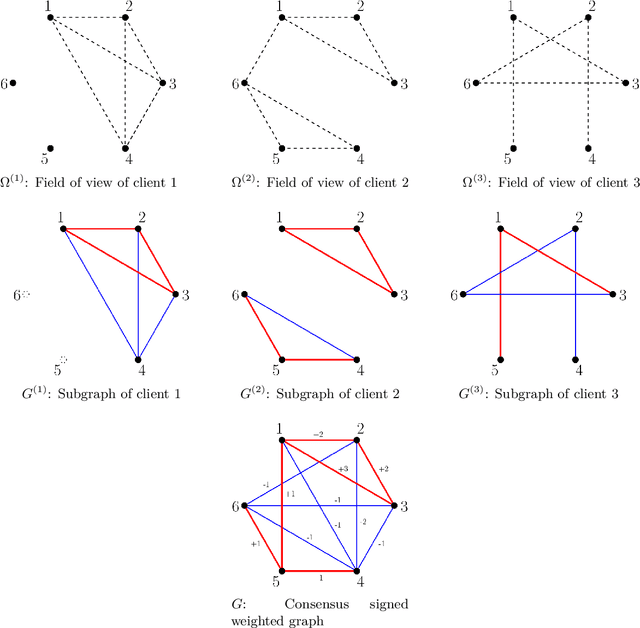
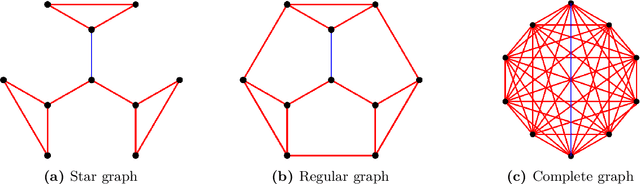
In this paper, we study the problem of recovering the community structure of a network under federated myopic learning. Under this paradigm, we have several clients, each of them having a myopic view, i.e., observing a small subgraph of the network. Each client sends a censored evidence graph to a central server. We provide an efficient algorithm, which computes a consensus signed weighted graph from clients evidence, and recovers the underlying network structure in the central server. We analyze the topological structure conditions of the network, as well as the signal and noise levels of the clients that allow for recovery of the network structure. Our analysis shows that exact recovery is possible and can be achieved in polynomial time. We also provide information-theoretic limits for the central server to recover the network structure from any single client evidence. Finally, as a byproduct of our analysis, we provide a novel Cheeger-type inequality for general signed weighted graphs.
Recovering the Unbiased Scene Graphs from the Biased Ones
Jul 05, 2021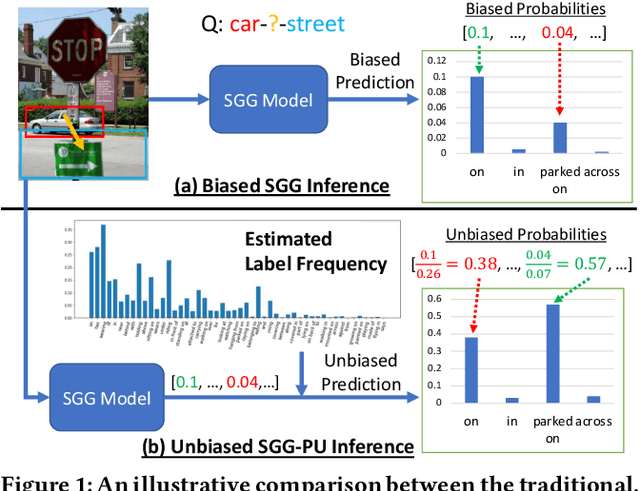
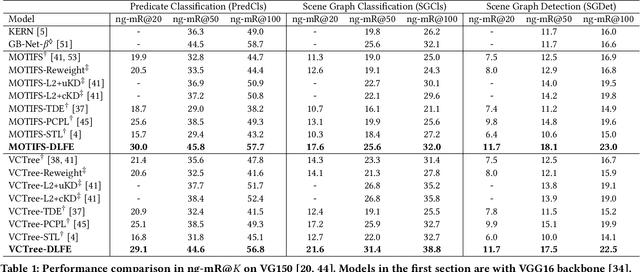
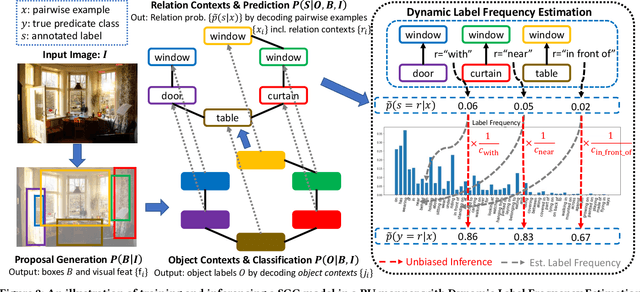
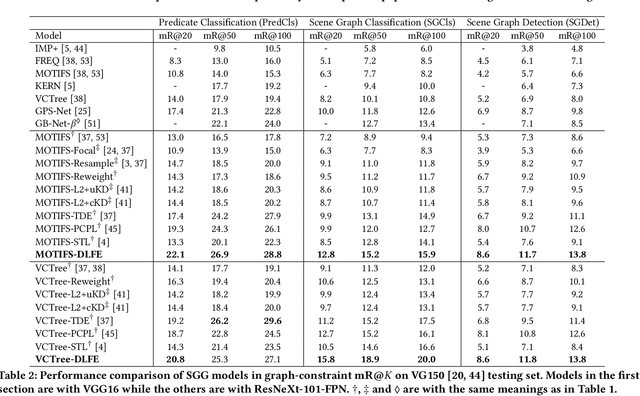
Given input images, scene graph generation (SGG) aims to produce comprehensive, graphical representations describing visual relationships among salient objects. Recently, more efforts have been paid to the long tail problem in SGG; however, the imbalance in the fraction of missing labels of different classes, or reporting bias, exacerbating the long tail is rarely considered and cannot be solved by the existing debiasing methods. In this paper we show that, due to the missing labels, SGG can be viewed as a "Learning from Positive and Unlabeled data" (PU learning) problem, where the reporting bias can be removed by recovering the unbiased probabilities from the biased ones by utilizing label frequencies, i.e., the per-class fraction of labeled, positive examples in all the positive examples. To obtain accurate label frequency estimates, we propose Dynamic Label Frequency Estimation (DLFE) to take advantage of training-time data augmentation and average over multiple training iterations to introduce more valid examples. Extensive experiments show that DLFE is more effective in estimating label frequencies than a naive variant of the traditional estimate, and DLFE significantly alleviates the long tail and achieves state-of-the-art debiasing performance on the VG dataset. We also show qualitatively that SGG models with DLFE produce prominently more balanced and unbiased scene graphs.
Learning to Combine Per-Example Solutions for Neural Program Synthesis
Jun 14, 2021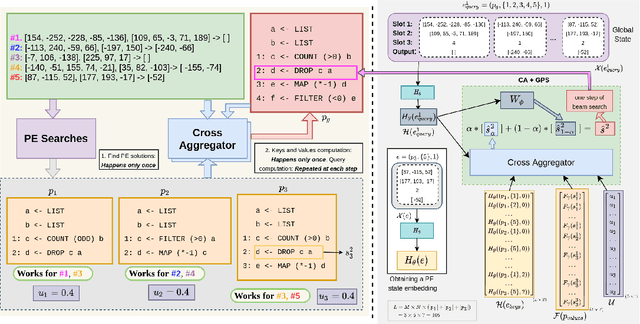

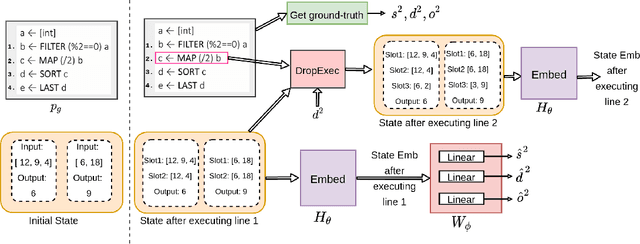
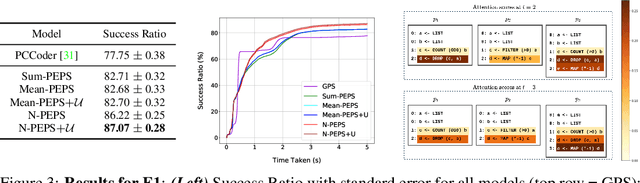
The goal of program synthesis from examples is to find a computer program that is consistent with a given set of input-output examples. Most learning-based approaches try to find a program that satisfies all examples at once. Our work, by contrast, considers an approach that breaks the problem into two stages: (a) find programs that satisfy only one example, and (b) leverage these per-example solutions to yield a program that satisfies all examples. We introduce the Cross Aggregator neural network module based on a multi-head attention mechanism that learns to combine the cues present in these per-example solutions to synthesize a global solution. Evaluation across programs of different lengths and under two different experimental settings reveal that when given the same time budget, our technique significantly improves the success rate over PCCoder arXiv:1809.04682v2 [cs.LG] and other ablation baselines. The code, data and trained models for our work can be found at https://github.com/shrivastavadisha/N-PEPS.
Modeling and Design of IRS-Assisted Multi-Link FSO Systems
Jul 31, 2021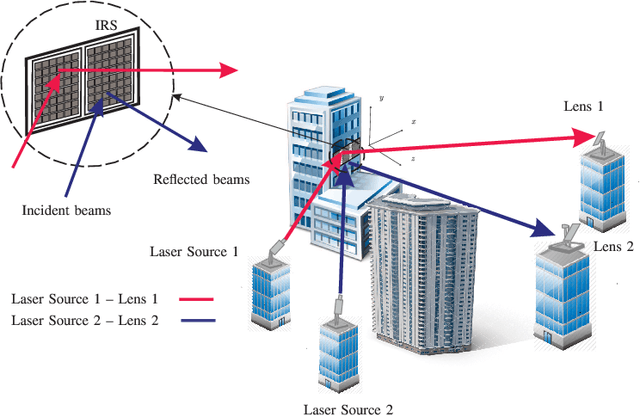
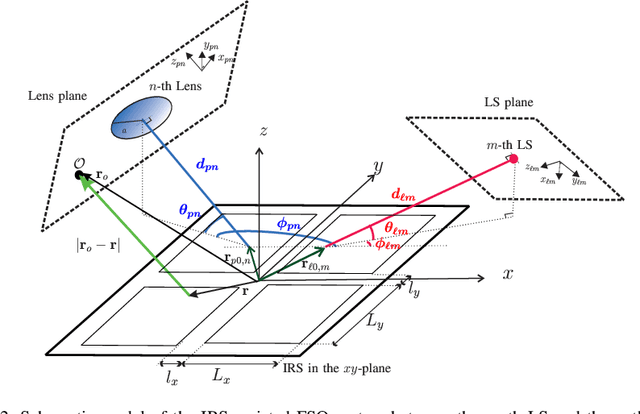
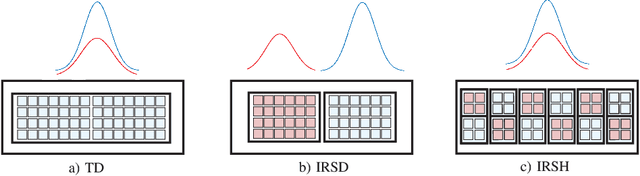
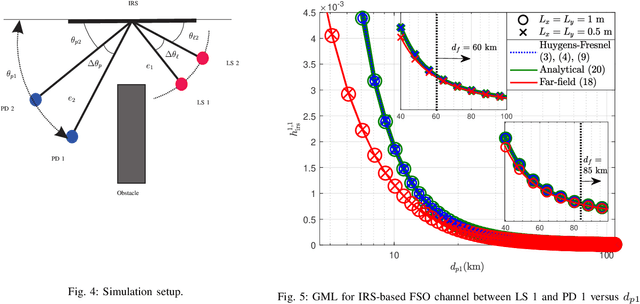
In this paper, we investigate the modeling and design of intelligent reflecting surface (IRS)-assisted optical communication systems which are deployed to relax the line-of-sight (LOS) requirement in multi-link free space optical (FSO) systems. The FSO laser beams incident on the optical IRSs have a Gaussian power intensity profile and a nonlinear phase profile, whereas the plane waves in radio frequency (RF) systems have a uniform power intensity profile and a linear phase profile. Given these substantial differences, the results available for IRS-assisted RF systems are not applicable to IRS-assisted FSO systems. Therefore, we develop a new analytical channel model for point-to-point IRS-assisted FSO systems based on the Huygens-Fresnel principle. Our analytical model captures the impact of the size, position, and orientation of the IRS as well as its phase shift profile on the end-to-end channel. To allow the sharing of the optical IRS by multiple FSO links, we propose three different protocols, namely the time division (TD), IRS-division (IRSD), and IRS homogenization (IRSH) protocols. The proposed protocols address the specific characteristics of FSO systems including the non-uniformity and possible misalignment of the laser beams. Furthermore, to compare the proposed IRS sharing protocols, we analyze the bit error rate (BER) and the outage probability of IRS-assisted multi-link FSO systems in the presence of inter-link interference. Our simulation results validate the accuracy of the proposed analytical channel model for IRS-assisted FSO systems and confirm that this model is applicable for both large and intermediate IRS-receiver lens distances. Moreover, in the absence of misalignment errors, the IRSD protocol outperforms the other protocols, whereas in the presence of misalignment errors, the IRSH protocol performs significantly better than the IRSD protocol.
Deep learning for prediction of complex geology ahead of drilling
Apr 06, 2021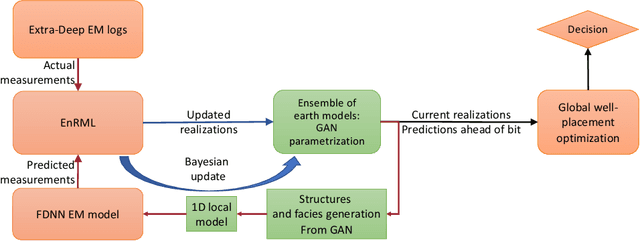
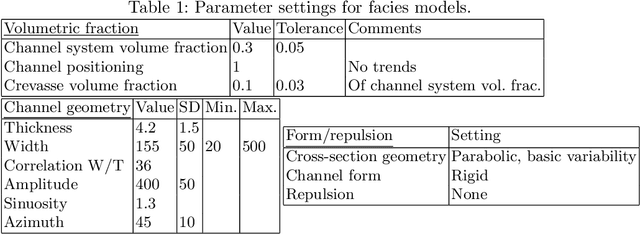
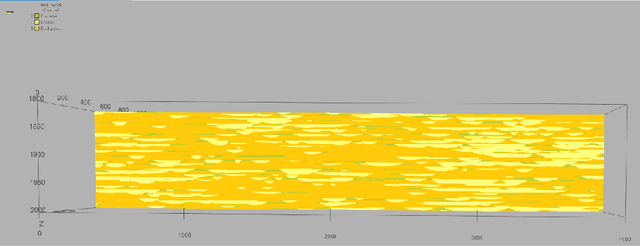

During a geosteering operation the well path is intentionally adjusted in response to the new data acquired while drilling. To achieve consistent high-quality decisions, especially when drilling in complex environments, decision support systems can help cope with high volumes of data and interpretation complexities. They can assimilate the real-time measurements into a probabilistic earth model and use the updated model for decision recommendations. Recently, machine learning (ML) techniques have enabled a wide range of methods that redistribute computational cost from on-line to off-line calculations. In this paper, we introduce two ML techniques into the geosteering decision support framework. Firstly, a complex earth model representation is generated using a Generative Adversarial Network (GAN). Secondly, a commercial extra-deep electromagnetic simulator is represented using a Forward Deep Neural Network (FDNN). The numerical experiments demonstrate that the combination of the GAN and the FDNN in an ensemble randomized maximum likelihood data assimilation scheme provides real-time estimates of complex geological uncertainty. This yields reduction of geological uncertainty ahead of the drill-bit from the measurements gathered behind and around the well bore.
Distance-based Hyperspherical Classification for Multi-source Open-Set Domain Adaptation
Jul 05, 2021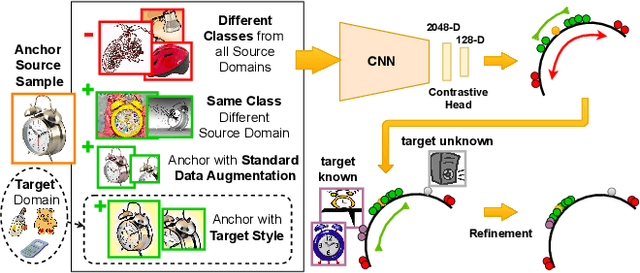
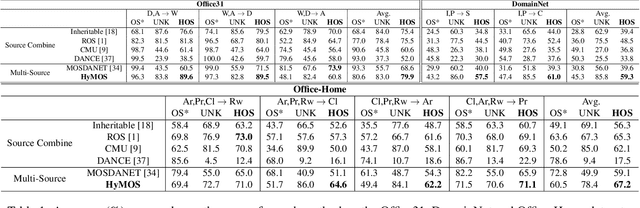
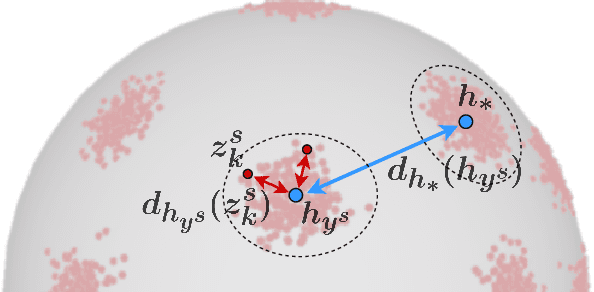
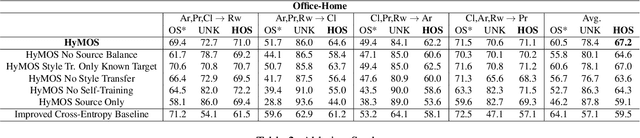
Vision systems trained in closed-world scenarios will inevitably fail when presented with new environmental conditions, new data distributions and novel classes at deployment time. How to move towards open-world learning is a long standing research question, but the existing solutions mainly focus on specific aspects of the problem (single domain Open-Set, multi-domain Closed-Set), or propose complex strategies which combine multiple losses and manually tuned hyperparameters. In this work we tackle multi-source Open-Set domain adaptation by introducing HyMOS: a straightforward supervised model that exploits the power of contrastive learning and the properties of its hyperspherical feature space to correctly predict known labels on the target, while rejecting samples belonging to any unknown class. HyMOS includes a tailored data balancing to enforce cross-source alignment and introduces style transfer among the instance transformations of contrastive learning for source-target adaptation, avoiding the risk of negative transfer. Finally a self-training strategy refines the model without the need for handcrafted thresholds. We validate our method over three challenging datasets and provide an extensive quantitative and qualitative experimental analysis. The obtained results show that HyMOS outperforms several Open-Set and universal domain adaptation approaches, defining the new state-of-the-art.