 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Logspace Reducibility From Secret Leakage Planted Clique
Jul 25, 2021
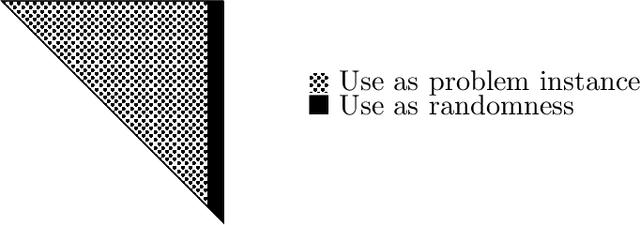
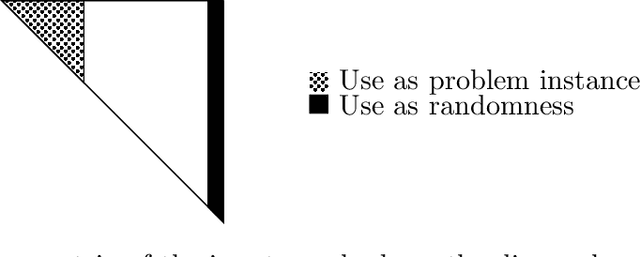
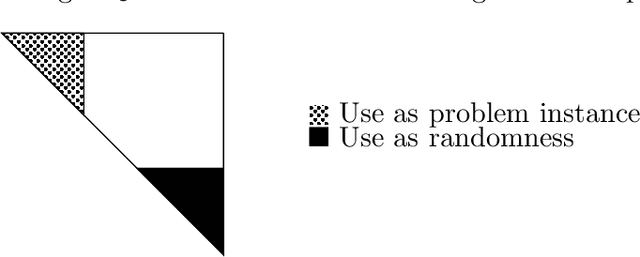
The planted clique problem is well-studied in the context of observing, explaining, and predicting interesting computational phenomena associated with statistical problems. When equating computational efficiency with the existence of polynomial time algorithms, the computational hardness of (some variant of) the planted clique problem can be used to infer the computational hardness of a host of other statistical problems. Is this ability to transfer computational hardness from (some variant of) the planted clique problem to other statistical problems robust to changing our notion of computational efficiency to space efficiency? We answer this question affirmatively for three different statistical problems, namely Sparse PCA, submatrix detection, and testing almost k-wise independence. The key challenge is that space efficient randomized reductions need to repeatedly access the randomness they use. Known reductions to these problems are all randomized and need polynomially many random bits to implement. Since we can not store polynomially many random bits in memory, it is unclear how to implement these existing reductions space efficiently. There are two ideas involved in circumventing this issue and implementing known reductions to these problems space efficiently. 1. When solving statistical problems, we can use parts of the input itself as randomness. 2. Secret leakage variants of the planted clique problem with appropriate secret leakage can be more useful than the standard planted clique problem when we want to use parts of the input as randomness. (abstract shortened due to arxiv constraints)
Worst-Case Polynomial-Time Exact MAP Inference on Discrete Models with Global Dependencies
Dec 27, 2019
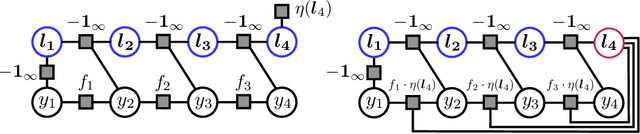
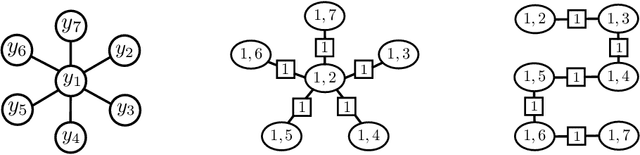
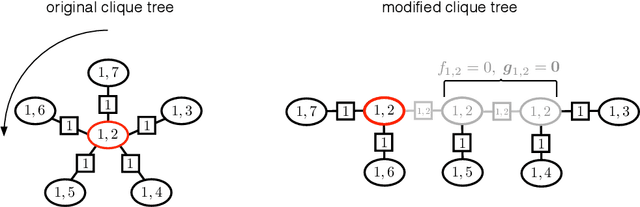
Considering the worst-case scenario, junction tree algorithm remains the most efficient and general solution for exact MAP inference on discrete graphical models. Unfortunately, its main tractability assumption requires the treewidth of a corresponding MRF to be bounded strongly limiting the range of admissible applications. In fact, many practical problems in the area of structured prediction require modelling of global dependencies by either directly introducing global factors or enforcing global constraints on the prediction variables. This, however, always results in a fully-connected graph making exact inference by means of this algorithm intractable. Nevertheless, depending on the structure of the global factors, we can further relax the conditions for an efficient inference. In this paper we reformulate the work in [1] and present a better way to establish the theory also extending the set of handleable problem instances for free - since it requires only a simple modification of the originally presented algorithm. To demonstrate that this extension is not of a purely theoretical interest we identify one further use case in the context of generalisation bounds for structured learning which cannot be handled by the previous formulation. Finally, we accordingly adjust the theoretical guarantees that the modified algorithm always finds an optimal solution in polynomial time.
Real-time Multiple People Hand Localization in 4D Point Clouds
Mar 05, 2019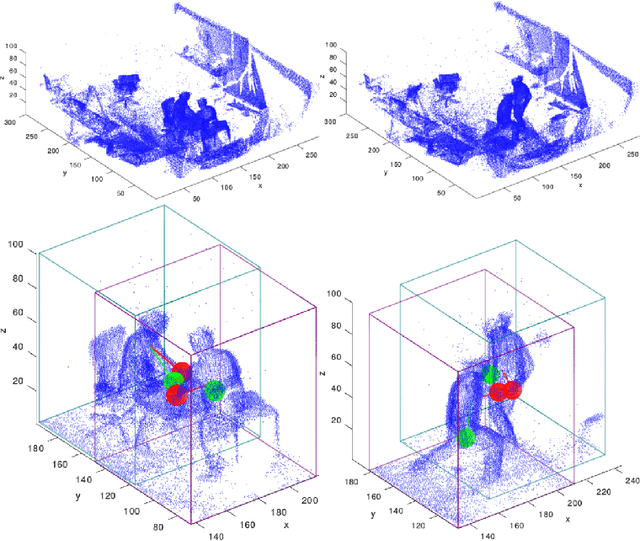

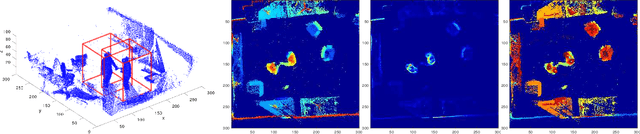
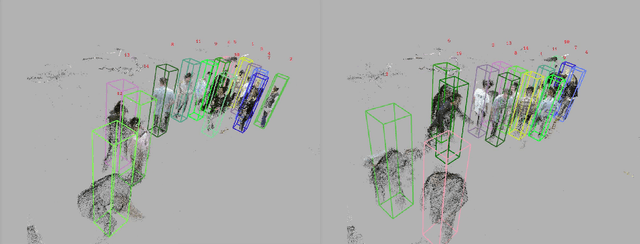
We propose novel real-time algorithm to localize hands and find their associations with multiple people in the cluttered 4D volumetric data (dynamic 3D volumes). Different from the traditional multiple view approaches, which find key points in 2D and then triangulate to recover the 3D locations, our method directly processes the dynamic 3D data that involve both clutter and crowd. The volumetric representation is more desirable than the partial observations from different view points and enables more robust and accurate results. However, due to the large amount of data in the volumetric representation brute force 3D schemes are slow. In this paper, we propose novel real-time methods to tackle the problem to achieve both higher accuracy and faster speed than previous approaches. Our method detects the 3D bounding box of each subject and localizes the hands of each person. We develop new 2D features for fast candidate proposals and optimize the trajectory linking using a new max-covering bipartite matching formulation, which is critical for robust performance. We propose a novel decomposition method to reduce the key point localization in each person 3D volume to a sequence of efficient 2D problems. Our experiments show that the proposed method is faster than different competing methods and it gives almost half the localization error.
Fully Convolutional Line Parsing
Apr 23, 2021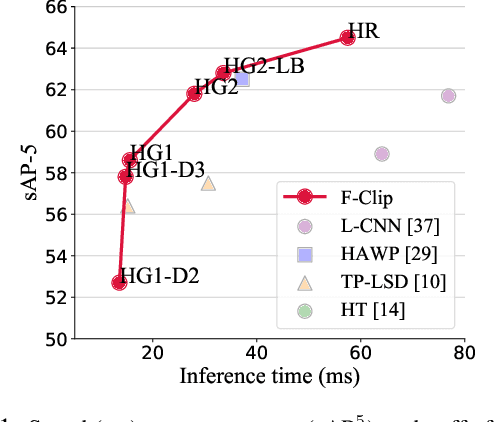
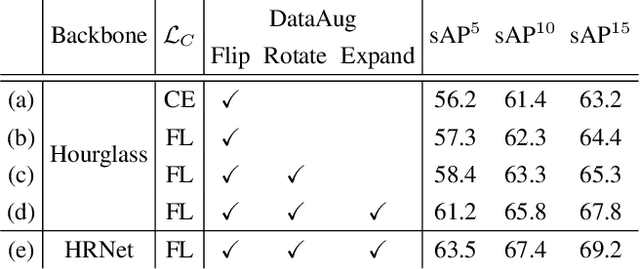
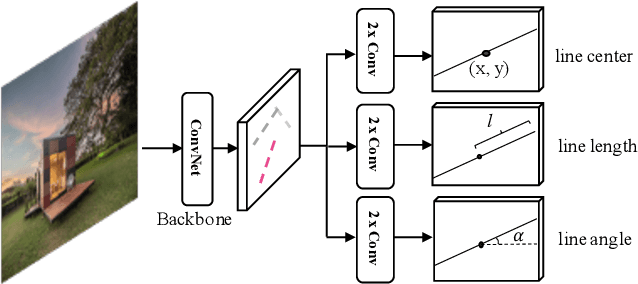

We present a one-stage Fully Convolutional Line Parsing network (F-Clip) that detects line segments from images. The proposed network is very simple and flexible with variations that gracefully trade off between speed and accuracy for different applications. F-Clip detects line segments in an end-to-end fashion by predicting them with each line's center position, length, and angle. Based on empirical observation of the distribution of line angles in real image datasets, we further customize the design of convolution kernels of our fully convolutional network to effectively exploit such statistical priors. We conduct extensive experiments and show that our method achieves a significantly better trade-off between efficiency and accuracy, resulting in a real-time line detector at up to 73 FPS on a single GPU. Such inference speed makes our method readily applicable to real-time tasks without compromising any accuracy of previous methods. Moreover, when equipped with a performance-improving backbone network, F-Clip is able to significantly outperform all state-of-the-art line detectors on accuracy at a similar or even higher frame rate. Source code https://github.com/Delay-Xili/F-Clip.
KaFiStO: A Kalman Filtering Framework for Stochastic Optimization
Jul 07, 2021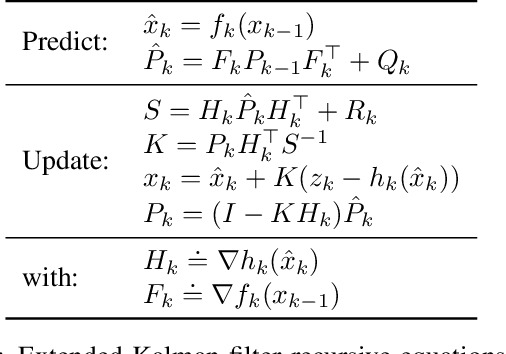
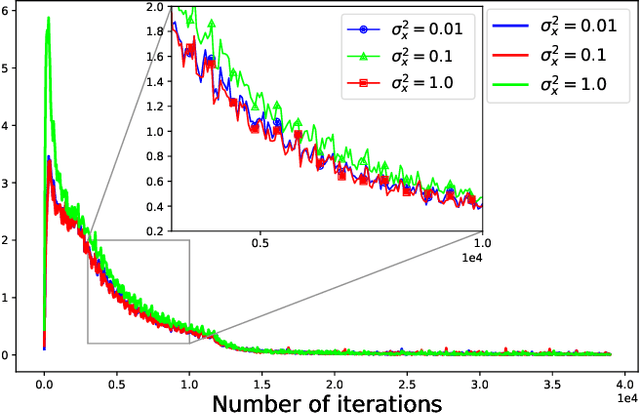
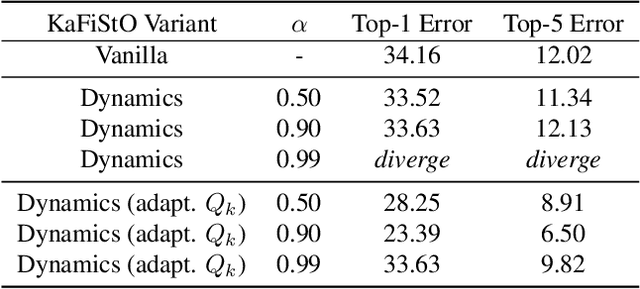
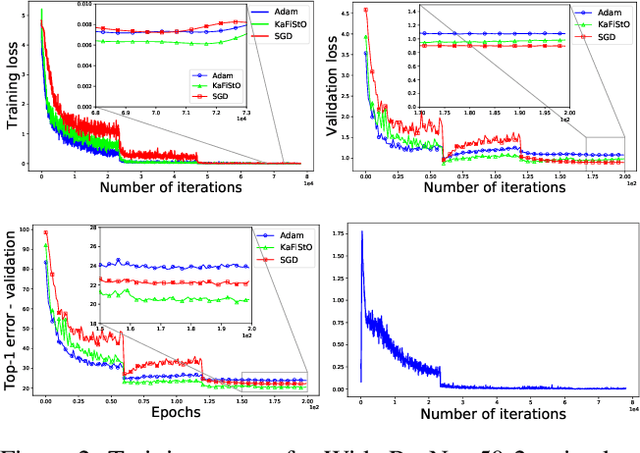
Optimization is often cast as a deterministic problem, where the solution is found through some iterative procedure such as gradient descent. However, when training neural networks the loss function changes over (iteration) time due to the randomized selection of a subset of the samples. This randomization turns the optimization problem into a stochastic one. We propose to consider the loss as a noisy observation with respect to some reference optimum. This interpretation of the loss allows us to adopt Kalman filtering as an optimizer, as its recursive formulation is designed to estimate unknown parameters from noisy measurements. Moreover, we show that the Kalman Filter dynamical model for the evolution of the unknown parameters can be used to capture the gradient dynamics of advanced methods such as Momentum and Adam. We call this stochastic optimization method KaFiStO. KaFiStO is an easy to implement, scalable, and efficient method to train neural networks. We show that it also yields parameter estimates that are on par with or better than existing optimization algorithms across several neural network architectures and machine learning tasks, such as computer vision and language modeling.
Guaranteed Fixed-Confidence Best Arm Identification in Multi-Armed Bandits: Simple Sequential Elimination Algorithms
Jun 18, 2021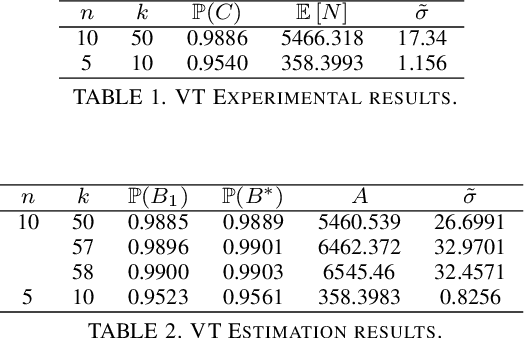
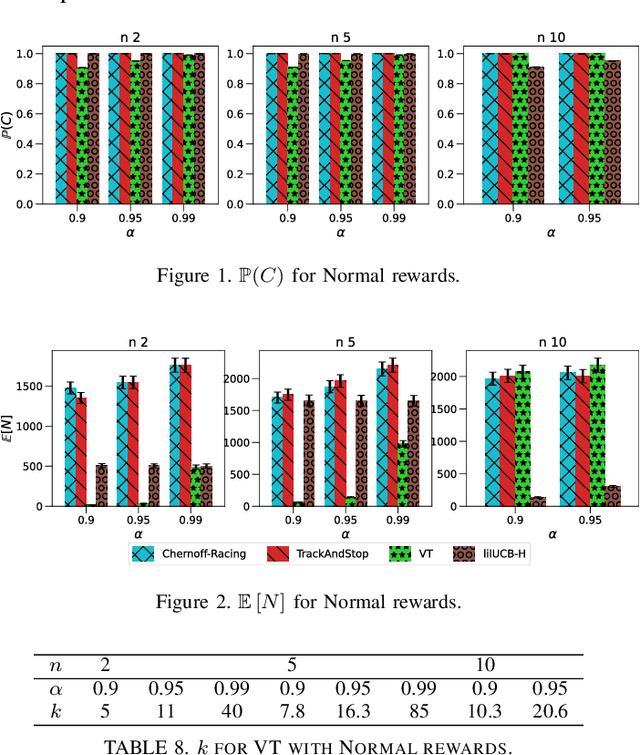
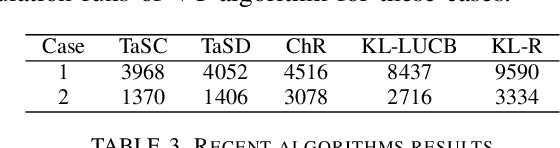
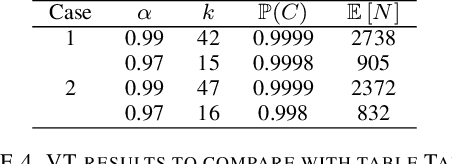
We consider the problem of finding, through adaptive sampling, which of n arms (arms) has the largest mean. Our objective is to determine a rule which identifies the best arm with a fixed minimum confidence using as few observations as possible, i.e. fixed-confidence (FC) best arm identification (BAI) in multi-armed bandits. We study such problems under the Bayesian setting with both Bernoulli and Gaussian arms. We propose to use the classical vector at a time (VT) rule, which samples each remaining arm once in each round. We show how VT can be implemented and analyzed in our Bayesian setting and be improved by early elimination. Our analysis show that these algorithms guarantee an optimal strategy under the prior. We also propose and analyze a variant of the classical play the winner (PW) algorithm. Numerical results show that these rules compare favorably with state-of-art algorithms.
SoundStream: An End-to-End Neural Audio Codec
Jul 07, 2021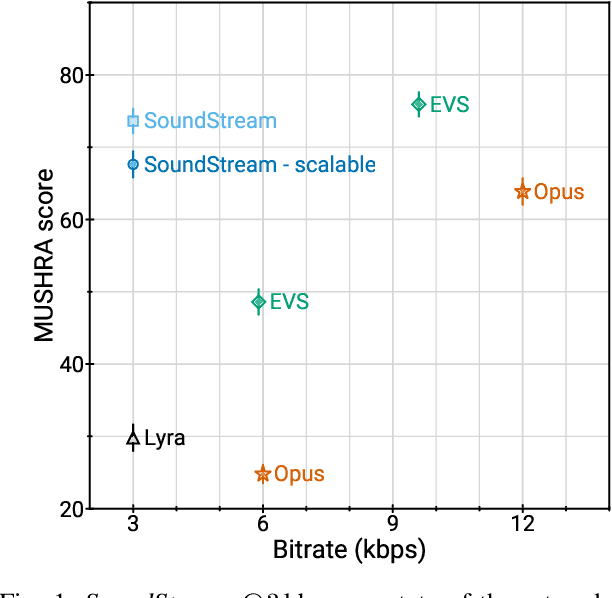
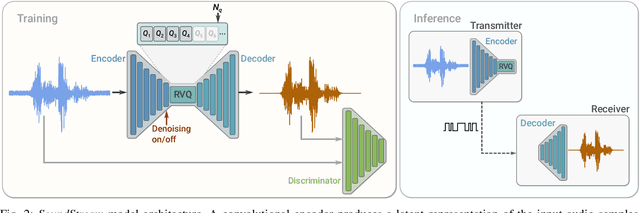
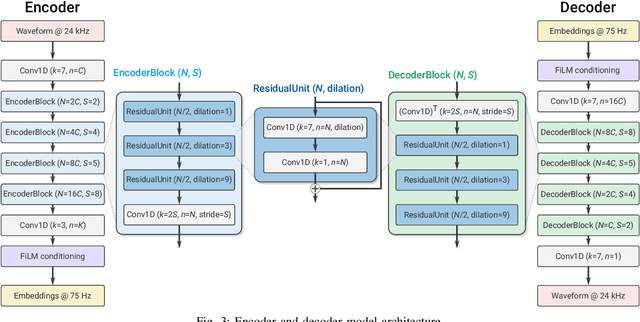
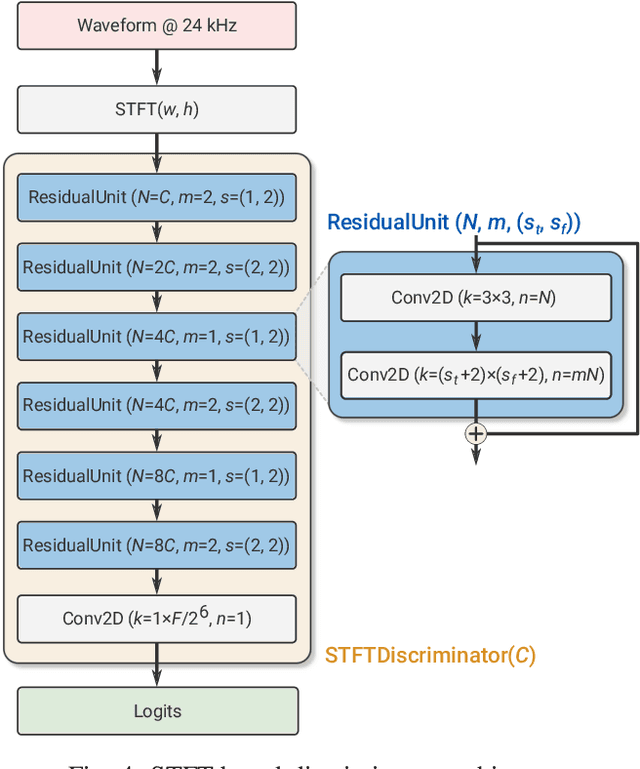
We present SoundStream, a novel neural audio codec that can efficiently compress speech, music and general audio at bitrates normally targeted by speech-tailored codecs. SoundStream relies on a model architecture composed by a fully convolutional encoder/decoder network and a residual vector quantizer, which are trained jointly end-to-end. Training leverages recent advances in text-to-speech and speech enhancement, which combine adversarial and reconstruction losses to allow the generation of high-quality audio content from quantized embeddings. By training with structured dropout applied to quantizer layers, a single model can operate across variable bitrates from 3kbps to 18kbps, with a negligible quality loss when compared with models trained at fixed bitrates. In addition, the model is amenable to a low latency implementation, which supports streamable inference and runs in real time on a smartphone CPU. In subjective evaluations using audio at 24kHz sampling rate, SoundStream at 3kbps outperforms Opus at 12kbps and approaches EVS at 9.6kbps. Moreover, we are able to perform joint compression and enhancement either at the encoder or at the decoder side with no additional latency, which we demonstrate through background noise suppression for speech.
Real-time Memory Efficient Large-pose Face Alignment via Deep Evolutionary Network
Oct 25, 2019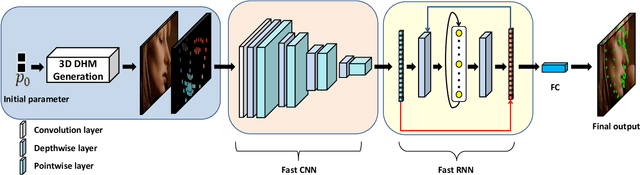
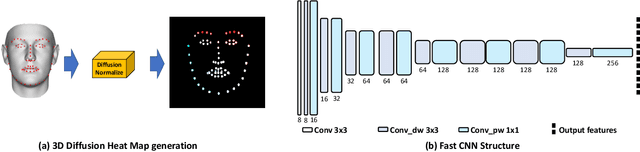
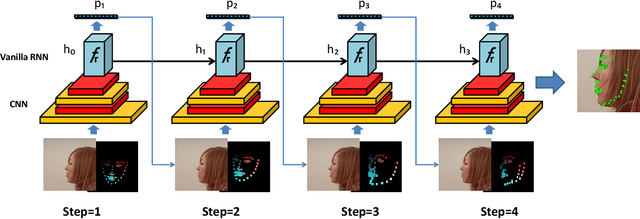
There is an urgent need to apply face alignment in a memory-efficient and real-time manner due to the recent explosion of face recognition applications. However, impact factors such as large pose variation and computational inefficiency, still hinder its broad implementation. To this end, we propose a computationally efficient deep evolutionary model integrated with 3D Diffusion Heap Maps (DHM). First, we introduce a sparse 3D DHM to assist the initial modeling process under extreme pose conditions. Afterward, a simple and effective CNN feature is extracted and fed to Recurrent Neural Network (RNN) for evolutionary learning. To accelerate the model, we propose an efficient network structure to accelerate the evolutionary learning process through a factorization strategy. Extensive experiments on three popular alignment databases demonstrate the advantage of the proposed models over the state-of-the-art, especially under large-pose conditions. Notably, the computational speed of our model is 10 times faster than the state-of-the-art on CPU and 14 times on GPU. We also discuss and analyze the limitations of our models and future research work.
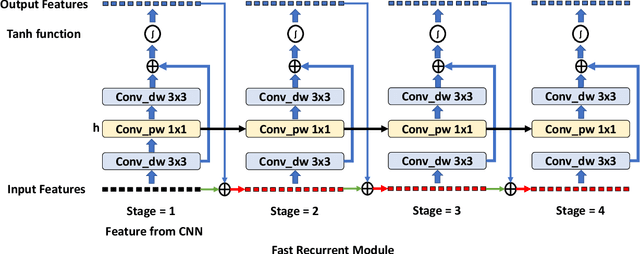
Efficient Spatio-Temporal Recurrent Neural Network for Video Deblurring
Jun 30, 2021
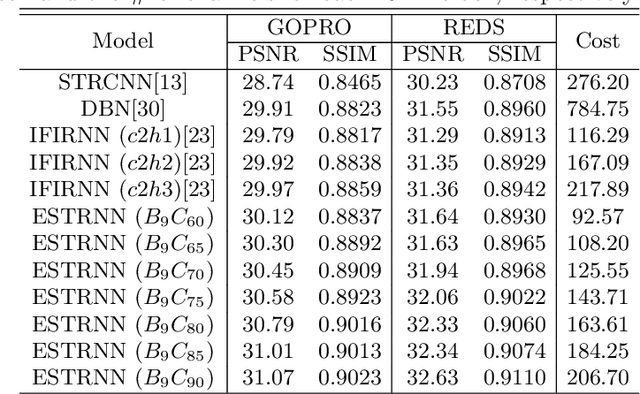
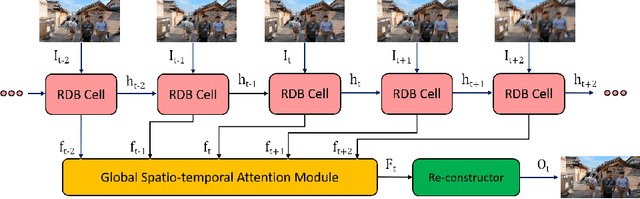
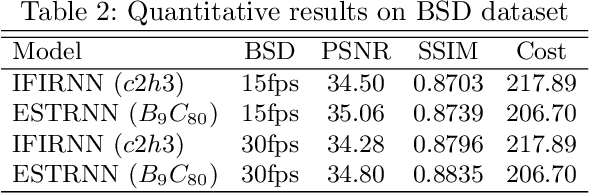
Real-time video deblurring still remains a challenging task due to the complexity of spatially and temporally varying blur itself and the requirement of low computational cost. To improve the network efficiency, we adopt residual dense blocks into RNN cells, so as to efficiently extract the spatial features of the current frame. Furthermore, a global spatio-temporal attention module is proposed to fuse the effective hierarchical features from past and future frames to help better deblur the current frame. Another issue needs to be addressed urgently is the lack of a real-world benchmark dataset. Thus, we contribute a novel dataset (BSD) to the community, by collecting paired blurry/sharp video clips using a co-axis beam splitter acquisition system. Experimental results show that the proposed method (ESTRNN) can achieve better deblurring performance both quantitatively and qualitatively with less computational cost against state-of-the-art video deblurring methods. In addition, cross-validation experiments between datasets illustrate the high generality of BSD over the synthetic datasets. The code and dataset are released at https://github.com/zzh-tech/ESTRNN.
Drone-based Joint Density Map Estimation, Localization and Tracking with Space-Time Multi-Scale Attention Network
Dec 04, 2019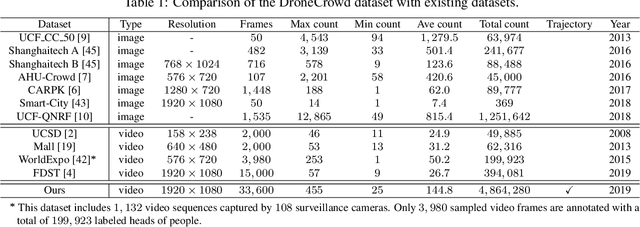

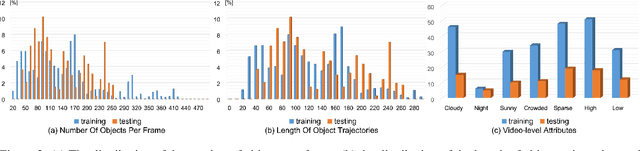
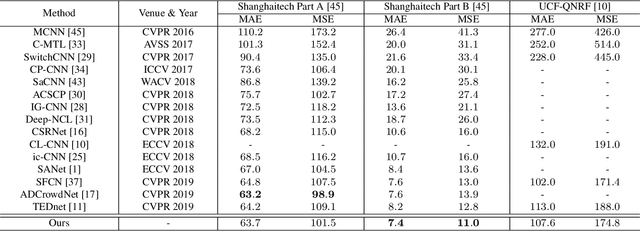
This paper proposes a space-time multi-scale attention network (STANet) to solve density map estimation, localization and tracking in dense crowds of video clips captured by drones with arbitrary crowd density, perspective, and flight altitude. Our STANet method aggregates multi-scale feature maps in sequential frames to exploit the temporal coherency, and then predict the density maps, localize the targets, and associate them in crowds simultaneously. A coarse-to-fine process is designed to gradually apply the attention module on the aggregated multi-scale feature maps to enforce the network to exploit the discriminative space-time features for better performance. The whole network is trained in an end-to-end manner with the multi-task loss, formed by three terms, i.e., the density map loss, localization loss and association loss. The non-maximal suppression followed by the min-cost flow framework is used to generate the trajectories of targets' in scenarios. Since existing crowd counting datasets merely focus on crowd counting in static cameras rather than density map estimation, counting and tracking in crowds on drones, we have collected a new large-scale drone-based dataset, DroneCrowd, formed by 112 video clips with 33,600 high resolution frames (i.e., 1920x1080) captured in 70 different scenarios. With intensive amount of effort, our dataset provides 20,800 people trajectories with 4.8 million head annotations and several video-level attributes in sequences. Extensive experiments are conducted on two challenging public datasets, i.e., Shanghaitech and UCF-QNRF, and our DroneCrowd, to demonstrate that STANet achieves favorable performance against the state-of-the-arts. The datasets and codes can be found at https://github.com/VisDrone.