 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
NeuralLog: Natural Language Inference with Joint Neural and Logical Reasoning
Jun 07, 2021
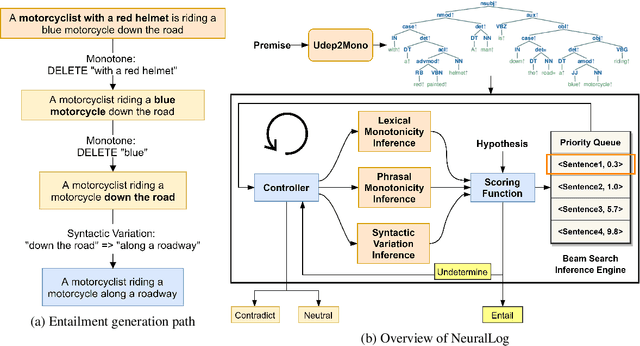
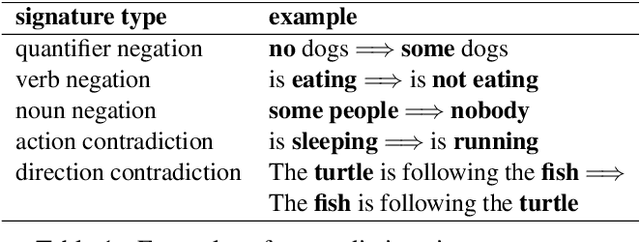
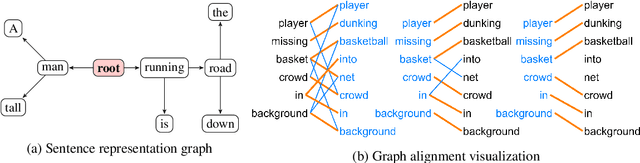

Deep learning (DL) based language models achieve high performance on various benchmarks for Natural Language Inference (NLI). And at this time, symbolic approaches to NLI are receiving less attention. Both approaches (symbolic and DL) have their advantages and weaknesses. However, currently, no method combines them in a system to solve the task of NLI. To merge symbolic and deep learning methods, we propose an inference framework called NeuralLog, which utilizes both a monotonicity-based logical inference engine and a neural network language model for phrase alignment. Our framework models the NLI task as a classic search problem and uses the beam search algorithm to search for optimal inference paths. Experiments show that our joint logic and neural inference system improves accuracy on the NLI task and can achieve state-of-art accuracy on the SICK and MED datasets.
Super-Resolution Remote Imaging using Time Encoded Remote Apertures
Jul 16, 2020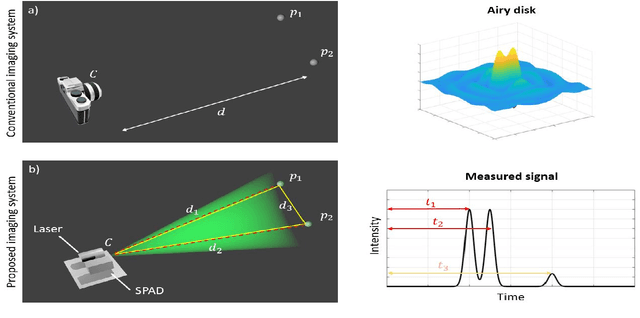
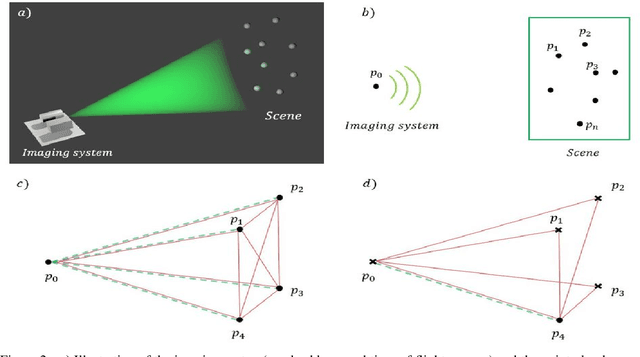
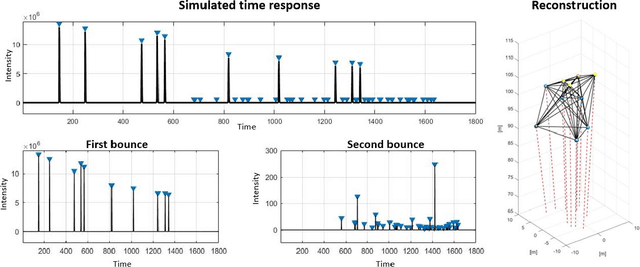

Imaging of scenes using light or other wave phenomena is subject to the diffraction limit. The spatial profile of a wave propagating between a scene and the imaging system is distorted by diffraction resulting in a loss of resolution that is proportional with traveled distance. We show here that it is possible to reconstruct sparse scenes from the temporal profile of the wave-front using only one spatial pixel or a spatial average. The temporal profile of the wave is not affected by diffraction yielding an imaging method that can in theory achieve wavelength scale resolution independent of distance from the scene.
Learning to Extend Program Graphs to Work-in-Progress Code
May 28, 2021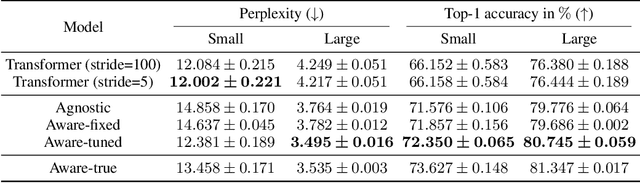
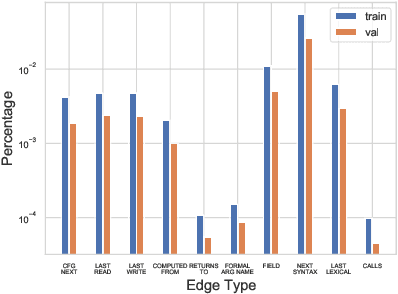
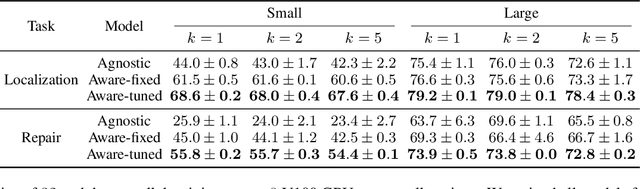
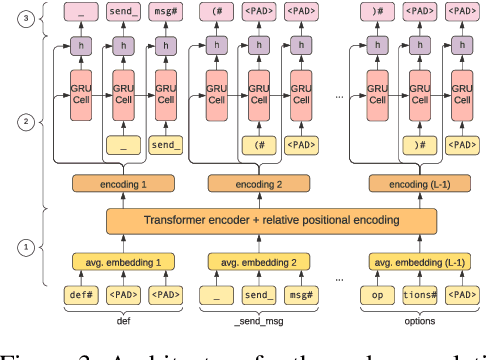
Source code spends most of its time in a broken or incomplete state during software development. This presents a challenge to machine learning for code, since high-performing models typically rely on graph structured representations of programs derived from traditional program analyses. Such analyses may be undefined for broken or incomplete code. We extend the notion of program graphs to work-in-progress code by learning to predict edge relations between tokens, training on well-formed code before transferring to work-in-progress code. We consider the tasks of code completion and localizing and repairing variable misuse in a work-in-process scenario. We demonstrate that training relation-aware models with fine-tuned edges consistently leads to improved performance on both tasks.
Conditional Coding and Variable Bitrate for Practical Learned Video Coding
Apr 20, 2021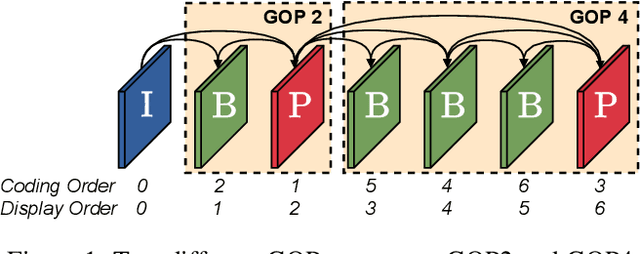
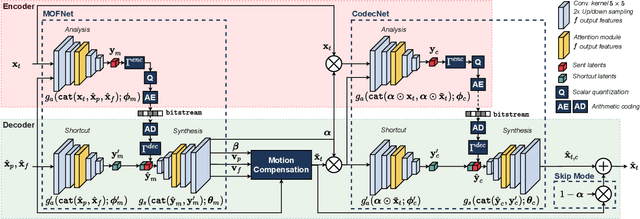
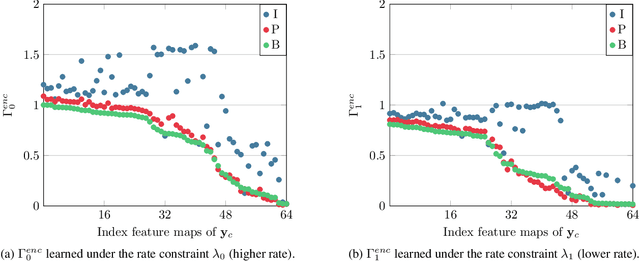
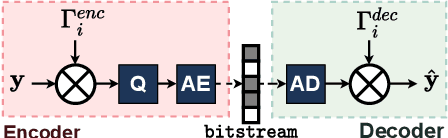
This paper introduces a practical learned video codec. Conditional coding and quantization gain vectors are used to provide flexibility to a single encoder/decoder pair, which is able to compress video sequences at a variable bitrate. The flexibility is leveraged at test time by choosing the rate and GOP structure to optimize a rate-distortion cost. Using the CLIC21 video test conditions, the proposed approach shows performance on par with HEVC.
Direction is what you need: Improving Word Embedding Compression in Large Language Models
Jun 15, 2021

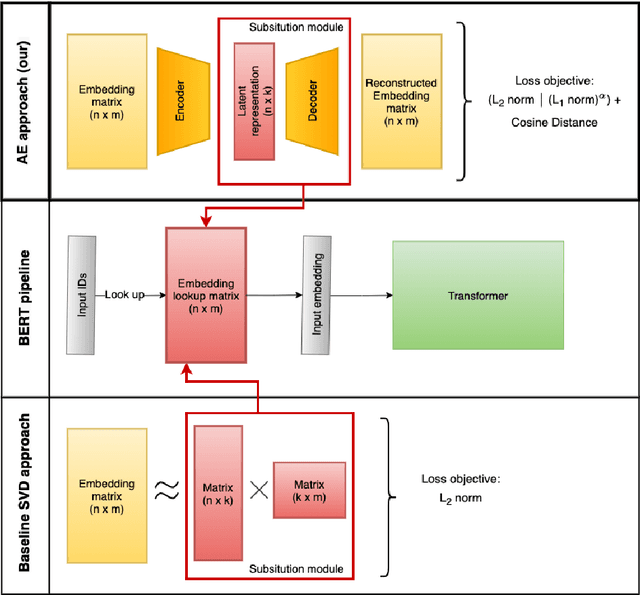
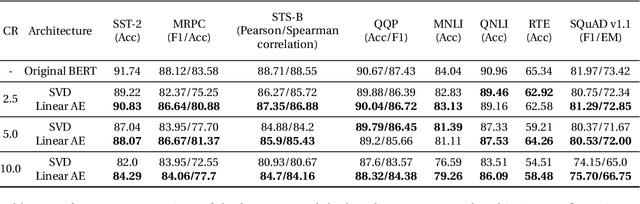
The adoption of Transformer-based models in natural language processing (NLP) has led to great success using a massive number of parameters. However, due to deployment constraints in edge devices, there has been a rising interest in the compression of these models to improve their inference time and memory footprint. This paper presents a novel loss objective to compress token embeddings in the Transformer-based models by leveraging an AutoEncoder architecture. More specifically, we emphasize the importance of the direction of compressed embeddings with respect to original uncompressed embeddings. The proposed method is task-agnostic and does not require further language modeling pre-training. Our method significantly outperforms the commonly used SVD-based matrix-factorization approach in terms of initial language model Perplexity. Moreover, we evaluate our proposed approach over SQuAD v1.1 dataset and several downstream tasks from the GLUE benchmark, where we also outperform the baseline in most scenarios. Our code is public.
Variational Diffusion Models
Jul 12, 2021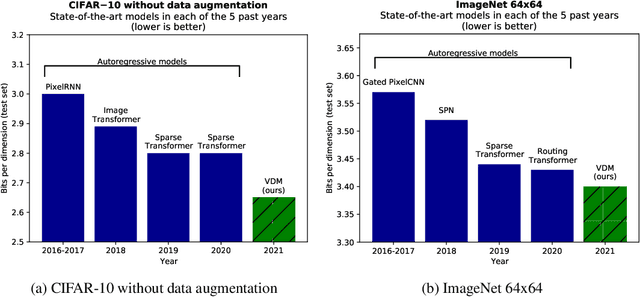
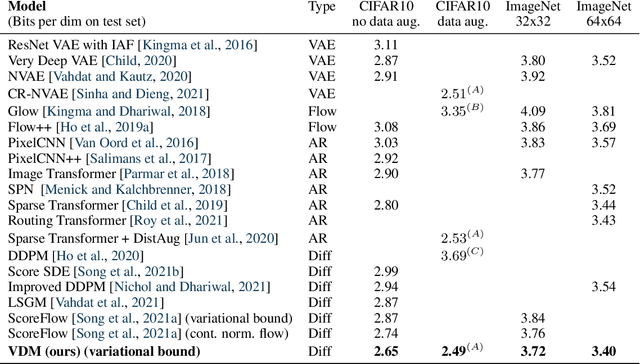

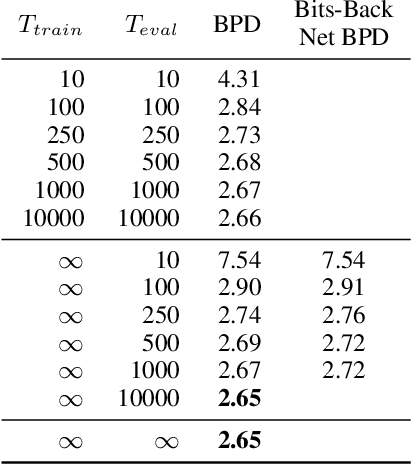
Diffusion-based generative models have demonstrated a capacity for perceptually impressive synthesis, but can they also be great likelihood-based models? We answer this in the affirmative, and introduce a family of diffusion-based generative models that obtain state-of-the-art likelihoods on standard image density estimation benchmarks. Unlike other diffusion-based models, our method allows for efficient optimization of the noise schedule jointly with the rest of the model. We show that the variational lower bound (VLB) simplifies to a remarkably short expression in terms of the signal-to-noise ratio of the diffused data, thereby improving our theoretical understanding of this model class. Using this insight, we prove an equivalence between several models proposed in the literature. In addition, we show that the continuous-time VLB is invariant to the noise schedule, except for the signal-to-noise ratio at its endpoints. This enables us to learn a noise schedule that minimizes the variance of the resulting VLB estimator, leading to faster optimization. Combining these advances with architectural improvements, we obtain state-of-the-art likelihoods on image density estimation benchmarks, outperforming autoregressive models that have dominated these benchmarks for many years, with often significantly faster optimization. In addition, we show how to turn the model into a bits-back compression scheme, and demonstrate lossless compression rates close to the theoretical optimum.
Finite-Horizon LQR Control of Quadrotors on $SE_2(3)$
May 28, 2021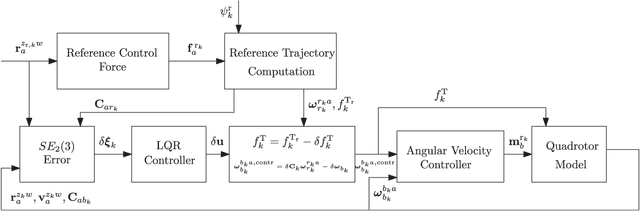

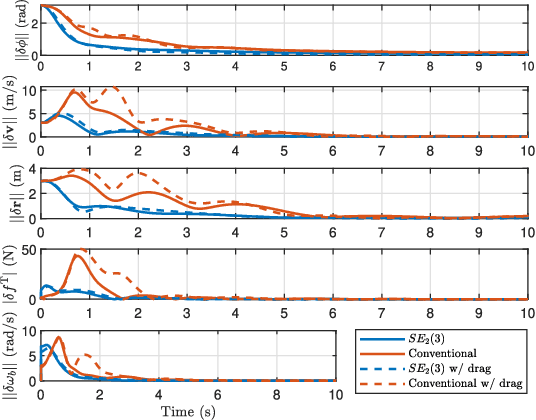
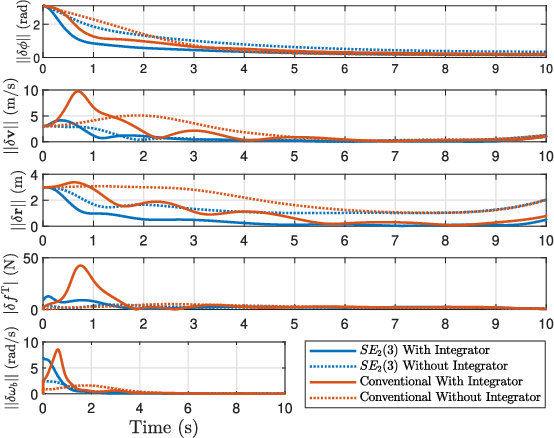
This paper considers optimal control of a quadrotor unmanned aerial vehicles (UAV) using the discrete-time, finite-horizon, linear quadratic regulator (LQR). The state of a quadrotor UAV is represented as an element of the matrix Lie group of double direct isometries, $SE_2(3)$. The nonlinear system is linearized using a left-invariant error about a reference trajectory, leading to an optimal gain sequence that can be calculated offline. The reference trajectory is calculated using the differentially flat properties of the quadrotor. Monte-Carlo simulations demonstrate robustness of the proposed control scheme to parametric uncertainty, state-estimation error, and initial error. Additionally, when compared to an LQR controller that uses a conventional error definition, the proposed controller demonstrates better performance when initial errors are large.
Multi-period Time Series Modeling with Sparsity via Bayesian Variational Inference
Oct 23, 2018
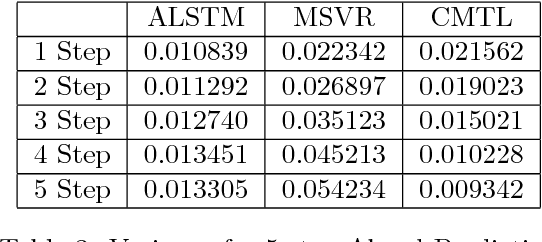
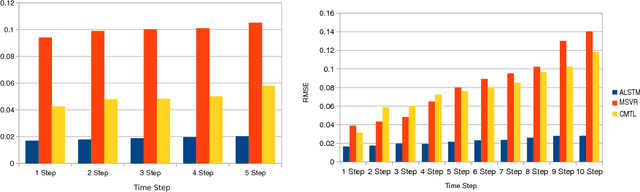

In this paper, we use augmented the hierarchical latent variable model to model multi-period time series, where the dynamics of time series are governed by factors or trends in multiple periods. Previous methods based on stacked recurrent neural network (RNN) and deep belief network (DBN) models cannot model the tendencies in multiple periods, and no models for sequential data pay special attention to redundant input variables which have no or even negative impact on prediction and modeling. Applying hierarchical latent variable model with multiple transition periods, our proposed algorithm can capture dependencies in different temporal resolutions. Introducing Bayesian neural network with Horseshoe prior as input network, we can discard the redundant input variables in the optimization process, concurrently with the learning of other parts of the model. Based on experiments with both synthetic and real-world data, we show that the proposed method significantly improves the modeling and prediction performance on multi-period time series.
Normalizing flows for novelty detection in industrial time series data
Jun 17, 2019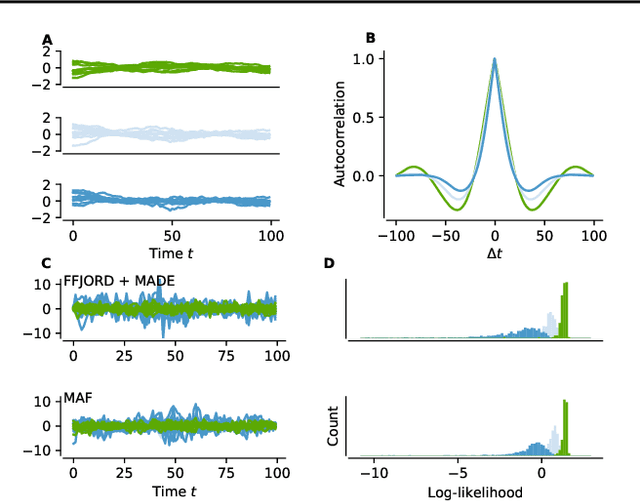
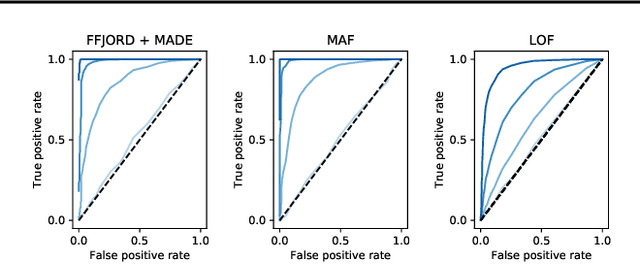
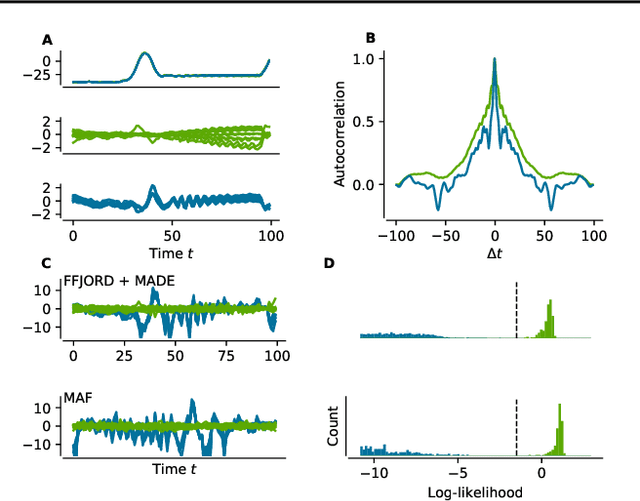
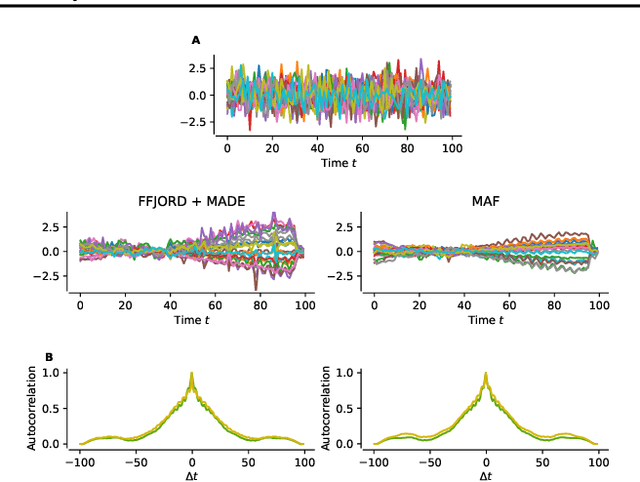
Flow-based deep generative models learn data distributions by transforming a simple base distribution into a complex distribution via a set of invertible transformations. Due to the invertibility, such models can score unseen data samples by computing their exact likelihood under the learned distribution. This makes flow-based models a perfect tool for novelty detection, an anomaly detection technique where unseen data samples are classified as normal or abnormal by scoring them against a learned model of normal data. We show that normalizing flows can be used as novelty detectors in time series. Two flow-based models, Masked Autoregressive Flows and Free-form Jacobian of Reversible Dynamics restricted by autoregressive MADE networks, are tested on synthetic data and motor current data from an industrial machine and achieve good results, outperforming a conventional novelty detection method, the Local Outlier Factor.
Computational modelling and data-driven homogenisation of knitted membranes
Jul 12, 2021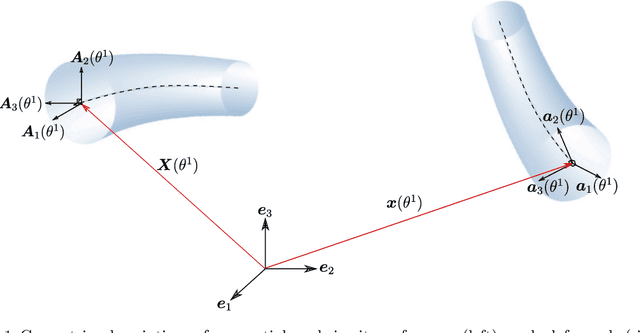
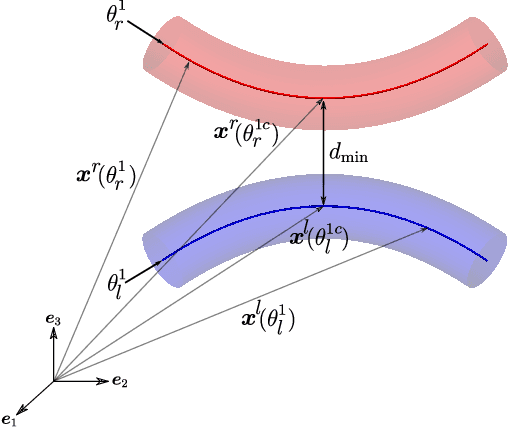
Knitting is an effective technique for producing complex three-dimensional surfaces owing to the inherent flexibility of interlooped yarns and recent advances in manufacturing providing better control of local stitch patterns. Fully yarn-level modelling of large-scale knitted membranes is not feasible. Therefore, we consider a two-scale homogenisation approach and model the membrane as a Kirchhoff-Love shell on the macroscale and as Euler-Bernoulli rods on the microscale. The governing equations for both the shell and the rod are discretised with cubic B-spline basis functions. The solution of the nonlinear microscale problem requires a significant amount of time due to the large deformations and the enforcement of contact constraints, rendering conventional online computational homogenisation approaches infeasible. To sidestep this problem, we use a pre-trained statistical Gaussian Process Regression (GPR) model to map the macroscale deformations to macroscale stresses. During the offline learning phase, the GPR model is trained by solving the microscale problem for a sufficiently rich set of deformation states obtained by either uniform or Sobol sampling. The trained GPR model encodes the nonlinearities and anisotropies present in the microscale and serves as a material model for the macroscale Kirchhoff-Love shell. After verifying and validating the different components of the proposed approach, we introduce several examples involving membranes subjected to tension and shear to demonstrate its versatility and good performance.